DSPy auf Databricks
Ein Framework für die Programmierung von RAG und anderen komplexen KI-Systemen
von Arnav Singhvi, Michael Carbin und Matei Zaharia
Große Sprachmodelle (LLMs) haben das Interesse an effektiver Mensch-KI-Interaktion durch die Optimierung von Prompting-Techniken geweckt. „Prompt Engineering“ ist eine wachsende Methodik zur Anpassung von Modellausgaben, während fortgeschrittene Techniken wie Retrieval Augmented Generation (RAG) die generativen Fähigkeiten von LLMs verbessern, indem sie relevante Informationen abrufen und darauf antworten.
DSPy, entwickelt von der Stanford NLP Group, hat sich als Framework für den Aufbau von zusammengesetzten KI-Systemen durch „Programmierung, nicht Prompting, von Foundation Models“ etabliert. DSPy unterstützt jetzt Integrationen mit Databricks-Entwicklerendpunkten für Model Serving und AI Search.
Zusammengesetzte KI entwickeln
Diese Prompting-Techniken signalisieren eine Verlagerung hin zu komplexen „Prompting-Pipelines“, bei denen KI-Entwickler LLMs, Retrieval-Modelle (RMs) und andere Komponenten integrieren, während sie zusammengesetzte KI-Systeme entwickeln.
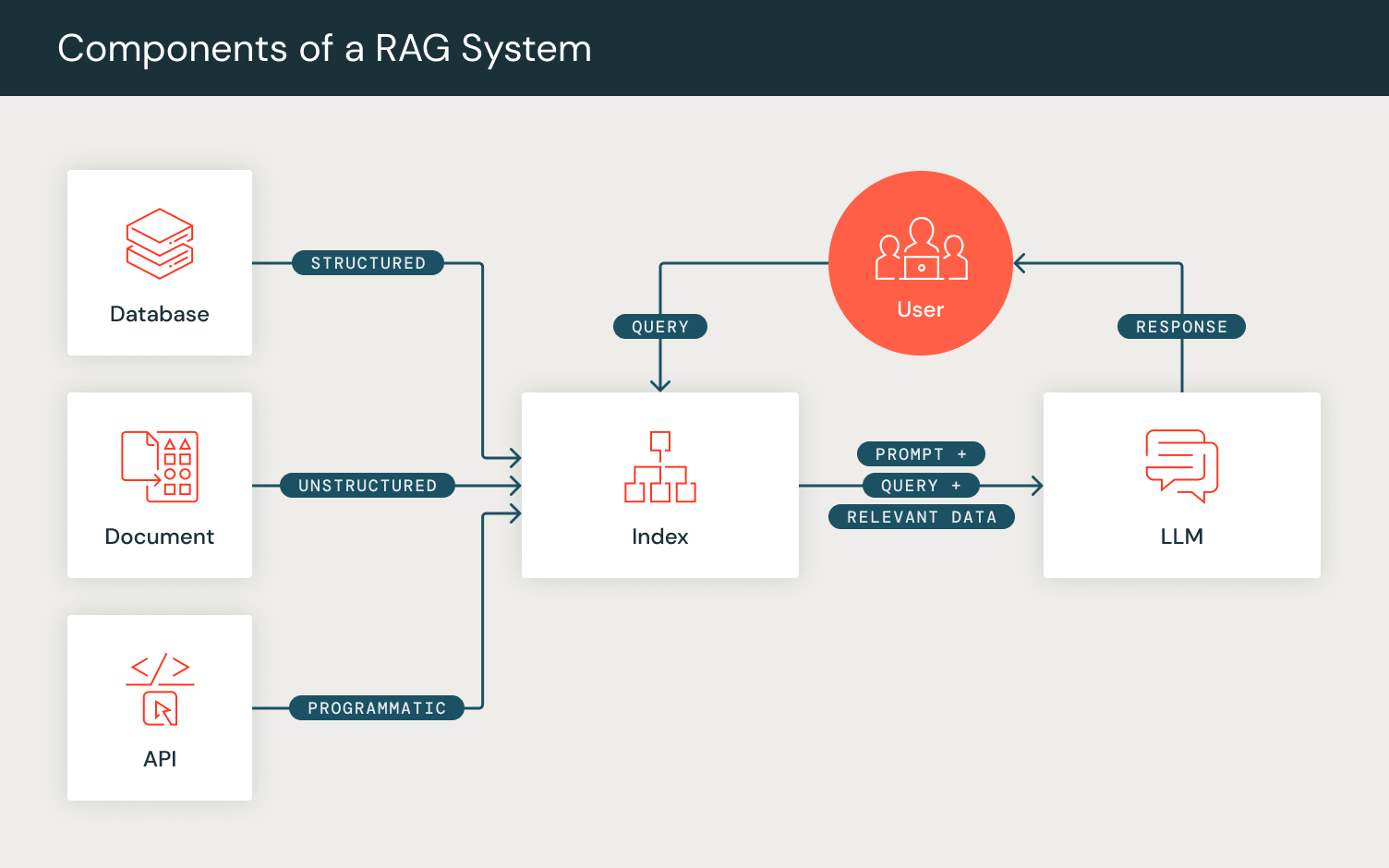
Programmieren statt Prompten: DSPy
DSPy optimiert die Leistung KI-gesteuerter Systeme, indem es LLM-Aufrufe neben anderen Rechenwerkzeugen für nachgelagerte Aufgabenmetriken komponiert. Im Gegensatz zum traditionellen „Prompt Engineering“ automatisiert DSPy die Prompt-Optimierung, indem es vom Benutzer definierte natürliche Sprachsignaturen in vollständige Anweisungen und Few-Shot-Beispiele übersetzt. Analog zur End-to-End-Pipeline-Optimierung wie in PyTorch erm�öglicht DSPy den Benutzern, KI-Systeme Schicht für Schicht zu definieren und zu komponieren, während sie für das gewünschte Ziel optimieren.
Programme in DSPy haben zwei Hauptmethoden:
- Initialisierung: Benutzer können die Komponenten ihrer Prompting-Pipelines als DSPy-Schichten definieren. Um beispielsweise die Schritte von RAG zu berücksichtigen, definieren wir eine Retrieval-Schicht und eine Generierungs-Schicht.
- Wir definieren eine Retrieval-Schicht `dspy.Retrieve`, die das vom Benutzer konfigurierte RM verwendet, um eine Reihe relevanter Passagen/Dokumente für eine eingegebene Suchanfrage abzurufen.
- Anschließend initialisieren wir unsere Generierungs-Schicht, für die wir das `dspy.Predict`-Modul verwenden, das intern den Prompt für die Generierung vorbereitet. Um diese Generierungsschicht zu konfigurieren, definieren wir unsere RAG-Aufgabe in einem natürlichsprachlichen Signaturformat, das durch eine Reihe von Eingabefeldern („context, query“) und das erwartete Ausgabefeld („answer“) spezifiziert wird. Dieses Modul formatiert intern den Prompt, um dieser definierten Formatierung zu entsprechen, und gibt dann die Generierung vom benutzerkonfigurierten LM zurück.
- Forward: Ähnlich wie bei PyTorch-Forward-Passes ermöglicht die DSPy-Programm-Forward-Funktion die benutzerdefinierte Komposition der Prompting-Pipeline-Logik. Durch die Verwendung der initialisierten Schichten richten wir den Rechenfluss von RAG ein, indem wir eine Reihe von Passagen basierend auf einer Abfrage abrufen und diese Passagen dann als Kontext zusammen mit der Abfrage verwenden, um eine Antwort zu generieren, und die erwartete Ausgabe in einem DSPy-Dictionary-Objekt ausgeben.
Werfen wir einen Blick auf RAG in Aktion, indem wir das DSPy-Programm und die Generierung von DBRX verwenden.
Für dieses Beispiel verwenden wir eine Beispielfrage aus dem HotPotQA-Datensatz, der Fragen enthält, die mehrere Schritte erfordern, um die richtige Antwort abzuleiten.
Lassen Sie uns zunächst unser LM und RM in DSPy konfigurieren. DSPy bietet eine Vielzahl von Sprach- und Retrieval-Modellintegrationen, und Benutzer können diese Parameter festlegen, um sicherzustellen, dass jedes von DSPy definierte Programm über diese Konfigurationen ausgeführt wird.
Lassen Sie uns nun unser definiertes DSPy RAG-Programm deklarieren und einfach die Frage als Eingabe übergeben.
Während des Retrieval-Schritts wird die query an die self.retrieve-Schicht übergeben, die die 3 relevantesten Passagen ausgibt, die intern wie folgt formatiert sind:
Mit diesen abgerufenen Passagen können wir diese zusammen mit unserer Abfrage an das dspy.Predict-Modul self.generate_answer übergeben, was den Eingabefeldern der natürlichsprachlichen Signatur „context, query“ entspricht. Dies wendet intern einige grundlegende Formatierungen und Formulierungen an und ermöglicht es Ihnen, das Modell mit Ihrer genauen Aufgabenbeschreibung zu steuern, ohne das LM per Prompt Engineering zu optimieren.
Sobald die Formatierung deklariert ist, werden die Eingabefelder „context“ und „query“ gefüllt und der endgültige Prompt wird an DBRX gesendet:
DBRX generiert eine Antwort, die im Feld „Answer:“ (Antwort:) angezeigt wird. Wir können diese Prompt-Generierung durch den Aufruf von: beobachten
Dies gibt den letzten Prompt aus, der vom LM mit der generierten Antwort „Steve Yzerman“ erzeugt wurde, was die richtige Antwort ist!
DSPy wurde bereits in verschiedenen Aufgaben für Sprachmodelle eingesetzt, wie z. B. Fine-Tuning, In-Context Learning, Informationsextraktion, Self-Refinement und zahlreiche andere. Dieser automatisierte Ansatz übertrifft herkömmliches Few-Shot-Prompting mit von Menschen erstellten Demonstrationen um bis zu 46 % für GPT-3.5 und 65 % für Llama2-13b-chat bei natürlichsprachlichen Aufgaben wie Multi-Hop RAG und Mathematik-Benchmarks wie GSM8K.
DSPy auf Databricks
DSPy unterstützt jetzt Integrationen mit Databricks-Entwicklerendpunkten für Model Serving und AI Search. Benutzer können Databricks-gehostete Foundation-Model-APIs über das OpenAI SDK mit dspy.Databricks konfigurieren. Dies stellt sicher, dass Benutzer ihre End-to-End-DSPy-Pipelines auf Databricks-gehosteten Modellen auswerten können. Derzeit werden Modelle auf den Model Serving Endpoints unterstützt: Chat (DBRX Instruct, Mixtral-8x7B Instruct, Llama 2 70B Chat), Completion (MPT 7B Instruct) und Embedding (BGE Large (En)) Modelle.
Chat-Modelle
Completion-Modelle
Embedding-Modelle
Retriever-Modelle/AI Search
Zusätzlich können Benutzer Retriever-Modelle über Databricks AI Search konfigurieren. Nach der Erstellung eines AI Search-Index und -Endpunkts können Benutzer die entsprechenden RM-Parameter über dspy.DatabricksRM angeben:
Benutzer können dies global konfigurieren, indem sie LM und RM auf entsprechende Databricks-Endpunkte setzen und DSPy-Programme ausführen.
Mit dieser Integration können Benutzer End-to-End-DSPy-Anwendungen, wie z. B. RAG, unter Verwendung von Databricks-Endpunkten erstellen und auswerten!
Schauen Sie sich das offizielle DSPy GitHub-Repository, die Dokumentation und Discord an, um mehr darüber zu erfahren, wie Sie generative KI-Aufgaben mit Databricks in vielseitige DSPy-Pipelines umwandeln können!
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.