Ein Framework für Multi-Model Forecasting auf Databricks
von Ryuta Yoshimatsu , Puneet Jain, Tristan Nixon, Sathish Gangichetty, Michael Shtelma und Bryan Smith
Einleitung
Zeitreihenprognosen bilden die Grundlage für Bestands- und Nachfragemanagement in den meisten Unternehmen. Anhand von Daten aus vergangenen Zeiträumen und erwarteten Bedingungen können Unternehmen Umsätze und verkaufte Einheiten vorhersagen, was ihnen die Zuweisung von Ressourcen zur Deckung der erwarteten Nachfrage ermöglicht. Angesichts der grundlegenden Natur dieser Arbeit suchen Unternehmen ständig nach Möglichkeiten, die Genauigkeit von Prognosen zu verbessern, damit sie genau die richtigen Ressourcen am richtigen Ort zur richtigen Zeit einsetzen und gleichzeitig die Kapitalbindung minimieren können.
Die Herausforderung für die meisten Organisationen liegt in der großen Bandbreite verfügbarer Prognosetechniken. Klassische statistische Techniken, verallgemeinerte additive Modelle, Ansätze auf Basis von maschinellem Lernen und Deep Learning sowie jetzt vortrainierte generative KI-Transformer bieten Organisationen eine überwältigende Auswahl an Optionen, von denen einige in bestimmten Szenarien besser funktionieren als in anderen.
Während die meisten Modellersteller eine verbesserte Prognosegenauigkeit gegenüber Basisdatensätzen behaupten, besteht die Realität darin, dass Fachwissen und Geschäftsanforderungen die Anzahl der Modelloptionen typischerweise auf wenige reduzieren. Erst die praktische Anwendung und Auswertung anhand der Datensätze einer Organisation kann bestimmen, welches Modell am besten abschneidet. Und was „am besten“ ist, variiert oft von Prognoseeinheit zu Prognoseeinheit und sogar im Laufe der Zeit, was Organisationen zwingt, fortlaufende Vergleichsbewertungen zwischen Techniken durchzuführen, um zu bestimmen, was im Moment am besten funktioniert.
In diesem Blog stellen wir das Framework Many Model Forecasting (MMF) zur vergleichenden Bewertung von Prognosemodellen vor. MMF ermöglicht es Benutzern, mit mehreren Prognosemodellen in großem Maßstab Hunderte von Tausenden bis Millionen von Zeitreihen auf ihrer feinsten Granularität zu trainieren und Vorhersagen zu treffen. Mit Unterstützung für Datenaufbereitung, Backtesting, Kreuzvalidierung, Scoring und Bereitstellung ermöglicht das Framework Prognoseteams die Implementierung einer vollständigen Lösung zur Prognoseerstellung unter Verwendung klassischer und hochmoderner Modelle mit Schwerpunkt auf Konfiguration statt Codierung, was den Aufwand für die Einführung neuer Modelle und Funktionen in ihre Prozesse minimiert. Wir haben in zahlreichen Kundenimplementierungen festgestellt, dass dieses Framework:
- Reduziert die Markteinführungszeit: Mit vielen bereits integrierten etablierten und hochmodernen Modellen können Benutzer schnell Lösungen evaluieren und bereitstellen.
- Verbessert die Prognosegenauigkeit: Durch umfassende Evaluierung und feingranulare Modellauswahl ermöglicht MMF Organisationen, effizient Prognoseansätze zu entdecken, die eine verbesserte Präzision bieten.
- Ermöglicht Produktionsbereitschaft: Durch die Einhaltung von MLOps-Best Practices integriert sich MMF nativ in Databricks und gewährleistet eine nahtlose Bereitstellung.
Zugriff auf über 40 Modelle mit dem Framework
Das Many Model Forecasting (MMF)-Framework wird als Github-Repository mit vollständig zugänglichem, transparentem und kommentiertem Quellcode geliefert. Organisationen können das Framework wie es ist verwenden oder es erweitern, um Funktionalitäten hinzuzufügen, die ihre spezifische Organisation benötigt.
MMF bietet integrierte Unterstützung für über 40 Modelle durch die Integration einiger der beliebtesten Open-Source-Prognosebibliotheken, darunter statsforecast, neuralforecast, sktime, r fable, chronos, moirai und moment. Und wenn unsere Kunden neuere Modelle untersuchen, beabsichtigen wir, noch mehr zu unterstützen.
Mit diesen bereits in das Framework integrierten Modellen können Benutzer die redundante Entwicklung von Datenaufbereitung und Modelltraining, die für jedes Modell spezifisch ist, eliminieren und sich stattdessen auf die Evaluierung und Bereitstellung konzentrieren, was die Markteinführungszeit erheblich beschleunigt. Dies ist besonders vorteilhaft für Teams von Data Scientists und Machine Learning Engineers mit begrenzten Ressourcen und für Business Stakeholder, die auf Ergebnisse drängen.
Mit MMF können Prognoseteams mehrere Modelle gleichzeitig auswerten, was sowohl integrierter als auch benutzerdefinierter Logik ermöglicht, das beste Modell für jede Zeitreihe auszuwählen und die Gesamtgenauigkeit der Prognoselösung zu verbessern. Bereitgestellt auf einem Databricks-Cluster nutzt MMF die ihm zur Verfügung stehenden vollständigen Ressourcen, um das Modelltraining und die Evaluierung durch automatische Parallelisierung zu beschleunigen. Teams konfigurieren einfach die Ressourcen, die sie für die Prognoseübung verwenden möchten, und MMF kümmert sich um den Rest.
Fokus auf Modellausgaben & Vergleichende Auswertungen
Der Schlüssel zu MMF ist die Standardisierung der Modellausgaben. Bei der Durchführung von Prognosen generiert MMF zwei UC-Tabellen: evaluation_output und scoring_output. Die evaluation_output-Tabelle (Abbildung 1) speichert alle Evaluierungsergebnisse aus jeder Backtesting-Periode, über alle Zeitreihen und Modelle hinweg, und bietet einen umfassenden Überblick über die Leistung jedes Modells. Dies beinhaltet Prognosen neben den tatsächlichen Werten, was es Benutzern ermöglicht, benutzerdefinierte Metriken zu erstellen, die spezifischen Geschäftsanforderungen entsprechen. Während MMF mehrere Out-of-the-Box-Metriken bietet, z. B. MAE, MSE, RMSE, MAPE und SMAPE, erleichtert die Flexibilität zur Erstellung benutzerdefinierter Metriken eine detaillierte Evaluierung und Modellauswahl oder -ensemblierung, um optimale Prognoseergebnisse zu gewährleisten.
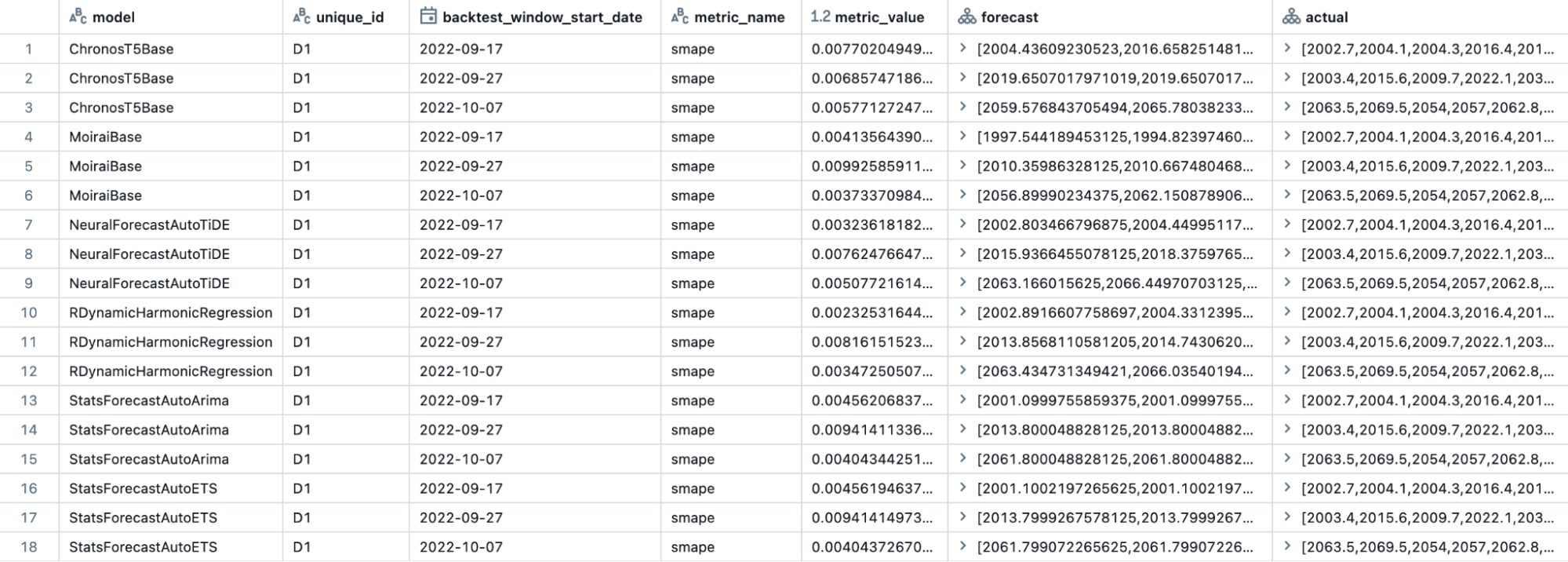
{kind=link}
Die zweite Tabelle, scoring_output (Abbildung 2), enthält Prognosen für jede Zeitreihe von jedem Modell. Anhand der umfassenden Evaluierungsergebnisse in der evaluation_output-Tabelle können Sie Prognosen aus dem am besten abschneidenden Modell oder einer Kombination von Modellen auswählen. Durch die Auswahl der endgültigen Prognosen aus einem Pool konkurrierender Modelle oder einem Ensemble ausgewählter Modelle können Sie eine überlegene Genauigkeit und Stabilität erzielen, verglichen mit der Abhängigkeit von einem einzelnen Modell, und so die Gesamtgenauigkeit und Stabilität Ihrer groß angelegten Prognoselösung verbessern.

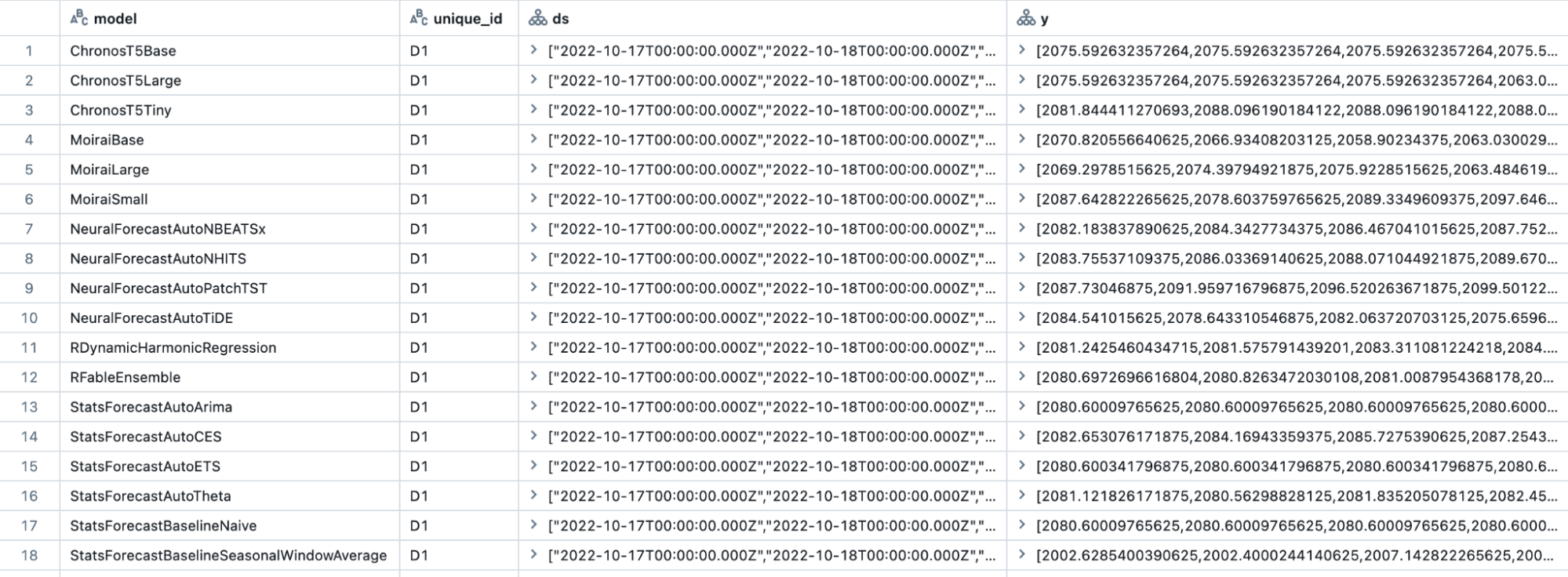{kind=link}
Vereinfachen Sie das Modellmanagement durch Automatisierung
Auf der Databricks-Plattform aufgebaut, integriert sich MMF nahtlos in seine Databricks-Funktionen und bietet automatisiertes Logging von Parametern, aggregierten Metriken und Modellen (für globale und Foundation-Modelle) an MLflow (Abbildung 3). Gesichert als Teil von Databricks' Unity Catalog können Prognoseteams feingranulare Zugriffskontrollen und eine ordnungsgemäße Verwaltung ihrer Modelle, nicht nur ihrer Modellausgaben, nutzen.

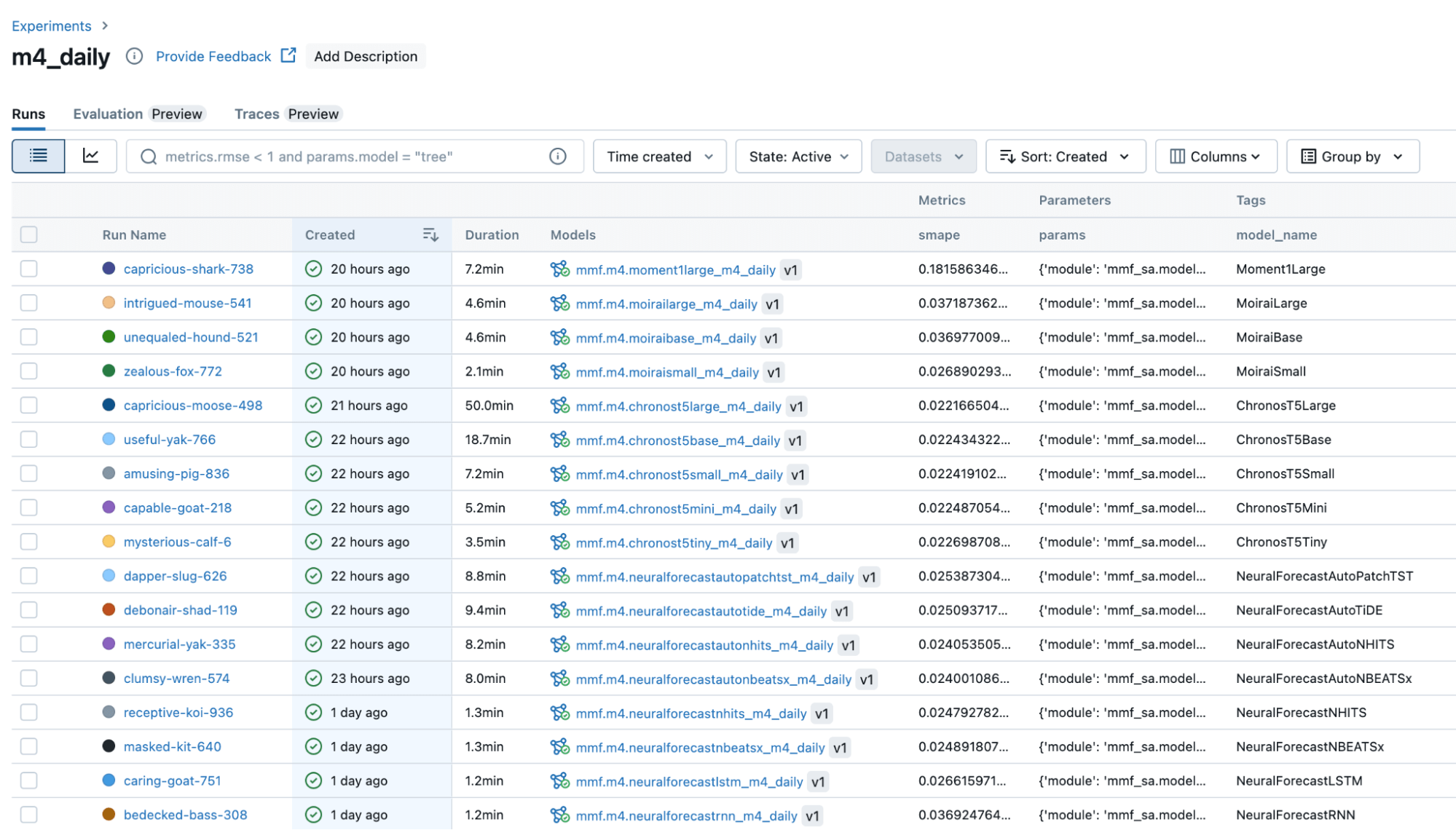{kind=link}
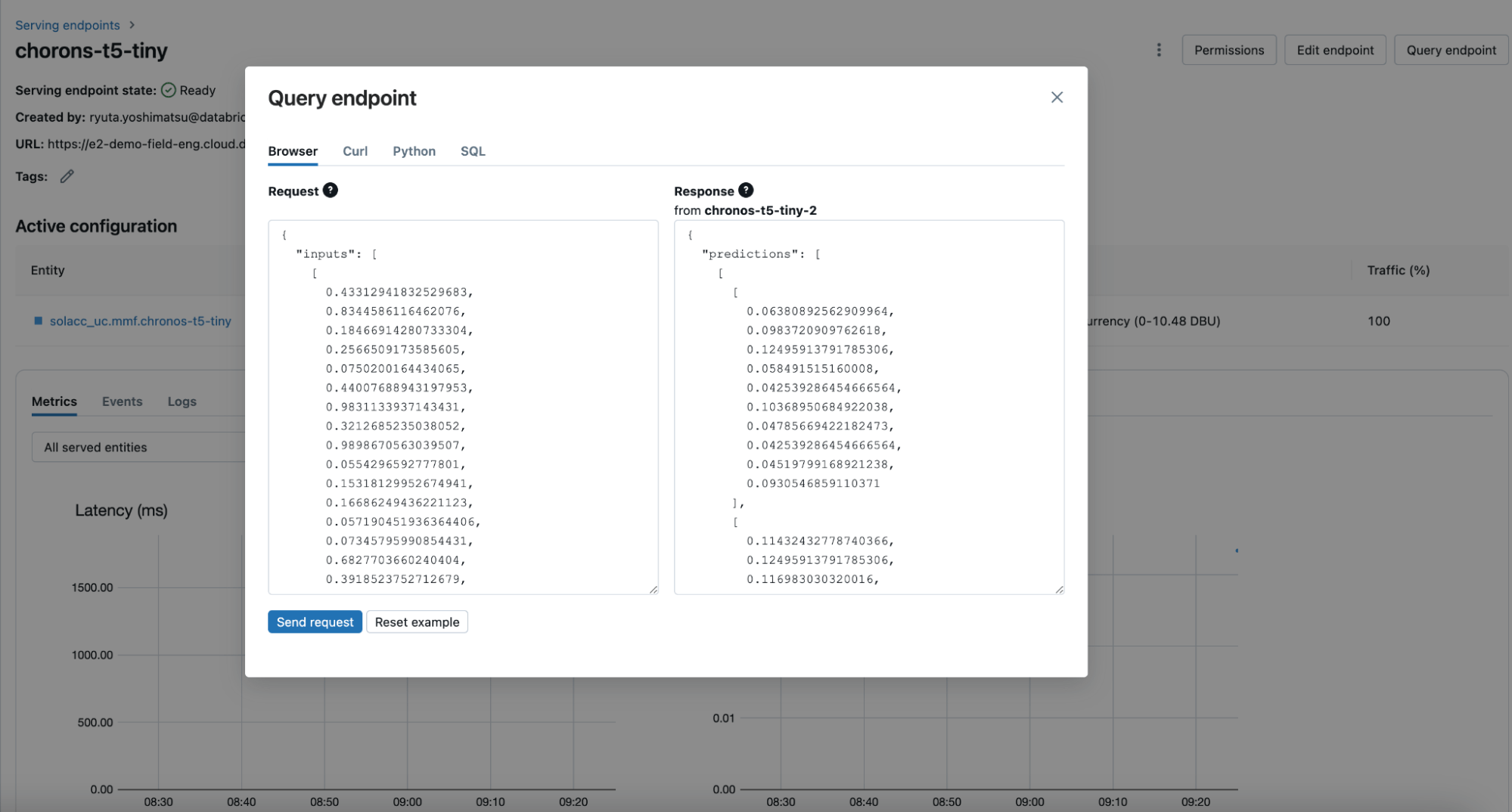
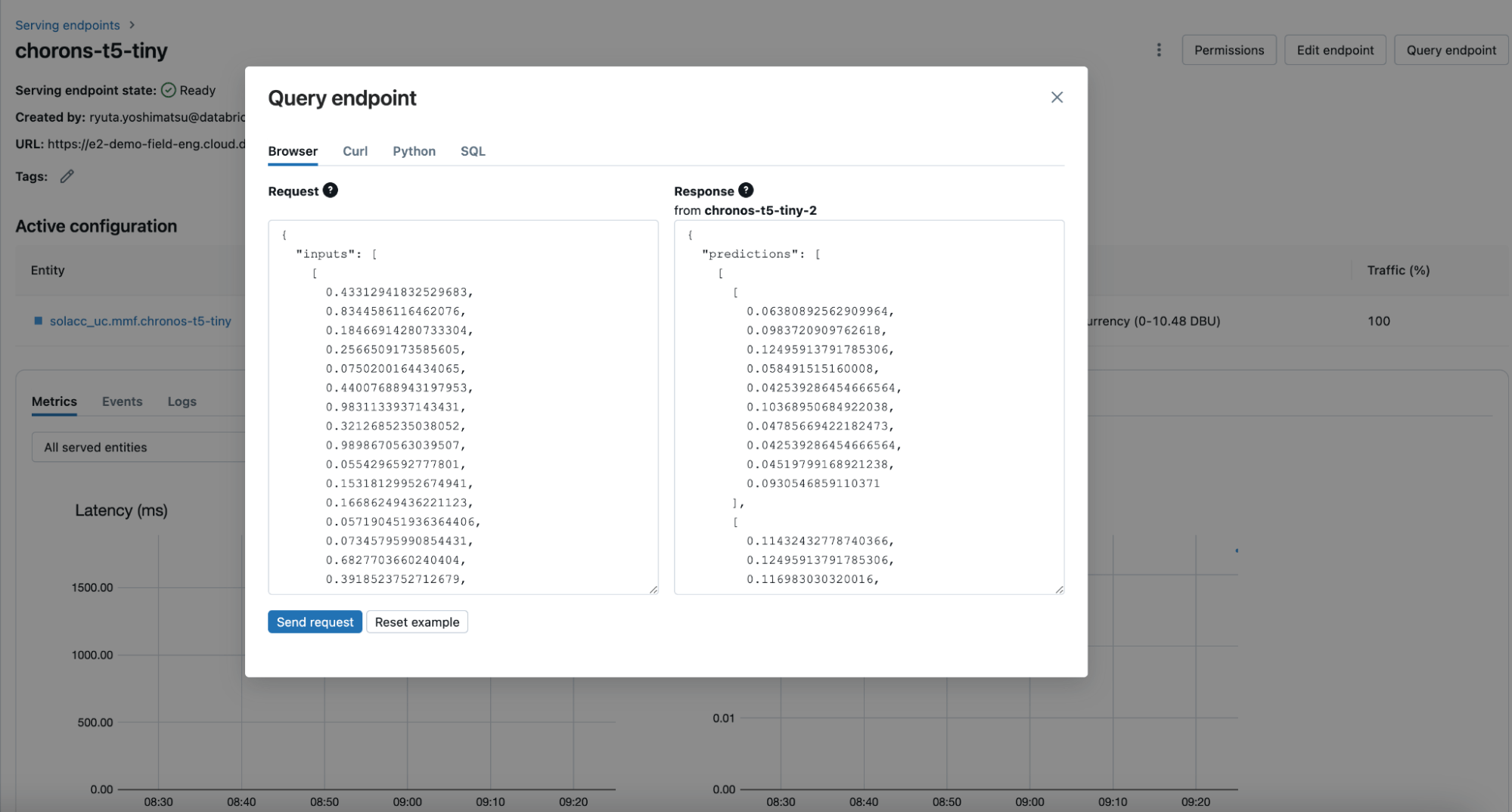
Sollte ein Team ein Modell wiederverwenden müssen (wie es in Szenarien des maschinellen Lernens üblich ist), können sie es einfach mit der load_model-Methode von MLflow auf ihren Cluster laden oder es hinter einem Echtzeit-Endpunkt über Databricks Model Serving (Abbildung 4) bereitstellen. Mit Zeitreihen-Foundation-Modellen, die in Model Serving gehostet werden, können Sie jederzeit Mehrschritt-Prognosen generieren, vorausgesetzt, Sie liefern die Historie in der richtigen Auflösung. Diese Fähigkeit verbessert Anwendungen in der On-Demand-Prognose, Echtzeitüberwachung und -verfolgung erheblich.
{kind=link}
Jetzt loslegen
Bei Databricks ist die Prognoseerstellung einer der beliebtesten Anwendungsfälle für Kunden. Die grundlegende Natur der Prognose für so viele Geschäftsprozesse bedeutet, dass Organisationen ständig nach Verbesserungen der Prognosegenauigkeit suchen.
Mit diesem Framework hoffen wir, Forecasting-Teams einfachen Zugang zu den skalierbarsten, robustesten und umfangreichsten Funktionen zu bieten, die sie für ihre Arbeit benötigen. Durch das MMF können sich Teams nun auf die Erzielung von Ergebnissen konzentrieren und weniger auf die Entwicklungsarbeit, die zur Bewertung neuer Ansätze und zur Produktionsreife erforderlich ist.
Danksagungen
Wir danken den Teams hinter statsforecast und neuralforecast (Nixtla), r fable, sktime, chronos, moirai, moment und timesfm für ihre Beiträge zu den Open-Source-Communities, die uns den Zugang zu ihren hervorragenden Werkzeugen ermöglicht haben.
Schauen Sie sich das MMF-Repository und die Beispiel-Notebooks an, die zeigen, wie Organisationen damit in ihrer Databricks-Umgebung loslegen können.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.