Managed MLflow
Erstellen Sie bessere Modelle und generative KI-Apps


Was ist Managed MLflow?
Managed MLflow erweitert die Funktionalität von ,MLflow einer Open Source von entwickelten Plattform Databricks zum Erstellen besserer Modelle und generativer KI-Apps, mit Schwerpunkt auf Unternehmenszuverlässigkeit, Sicherheit und Skalierbarkeit. Das neueste Update für MLflow führt innovative GenAI- und LLMOps-Funktionen ein, die die Fähigkeit zur Verwaltung und Anwendung großer Sprachmodelle (LLMs) verbessern. Diese erweiterte LLM Unterstützung wird durch neue Integrationen mit den Branchenstandard- LLM Tools OpenAI und Hugging Face Transformers sowie dem MLflow Deployments Server erreicht. Darüber hinaus ermöglicht die Integration von MLflowmit LLM Frameworks (z. B. LangChain) eine vereinfachte Modellentwicklung zur Erstellung generativer KI-Anwendungen für eine Vielzahl von Anwendungsfällen, darunter Chatbots, Dokumentzusammenfassung, Textklassifizierung, Sentimentanalysen und mehr.
Vorteile
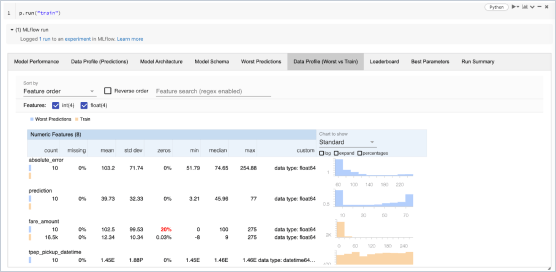
Modellentwicklung
Verbessern und beschleunigen Sie das Lebenszyklusmanagement maschinellen Lernens mit einem standardisierten Rahmen für produktionsreife Modelle. Verwaltete MLflow Rezepte ermöglichen nahtloses Bootstrapping ML Projekten, schnelle Iteration und Bereitstellung von Modellen im großenScale . Erstellen Sie mühelos Anwendungen wie Chatbots, Dokumentzusammenfassungen, Sentimentanalysen und Klassifizierungen. Entwickeln Sie ganz einfach generative KI-Apps (z. B. Chatbots, Dokumentzusammenfassung) mit den LLM-Angeboten von MLflow, die sich nahtlos in LangChain, Hugging Face und OpenAI integrieren lassen.
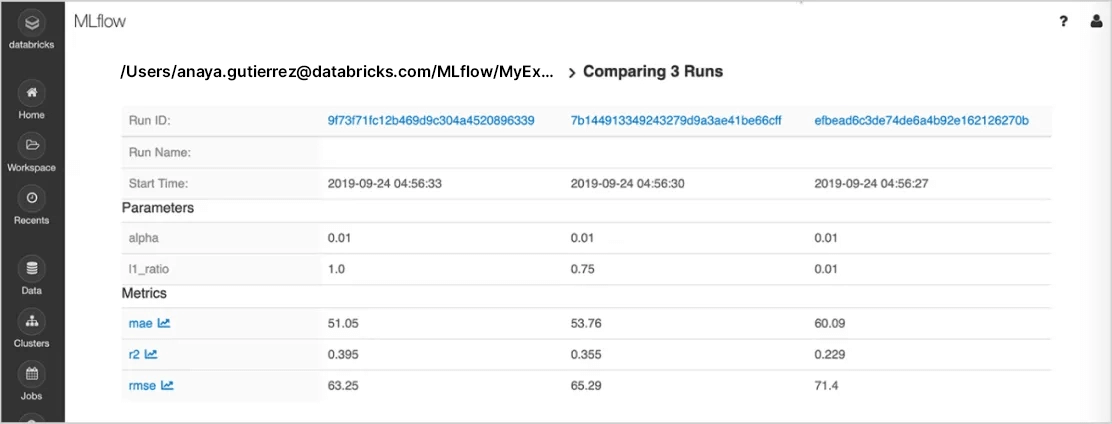
Nachverfolgung von Experimenten
Führen Sie Experimente mit jeder ML -Bibliothek, jedem Framework oder jeder Sprache durch und behalten Sie automatisch den Überblick über Parameter, Metriken, Code und Modelle aus jedem Experiment. Durch die Verwendung MLflow auf Databricks können Sie Experiment zusammen mit den entsprechenden Artefakten und Codeversionen sicher teilen, verwalten und vergleichen – dank integrierter Integrationen mit dem Databricks Arbeitsbereich und -Notebook. Sie können auch die Ergebnisse des GenAI-Experiments auswerten und die Qualität mit MLflow Auswertungsfunktion verbessern.
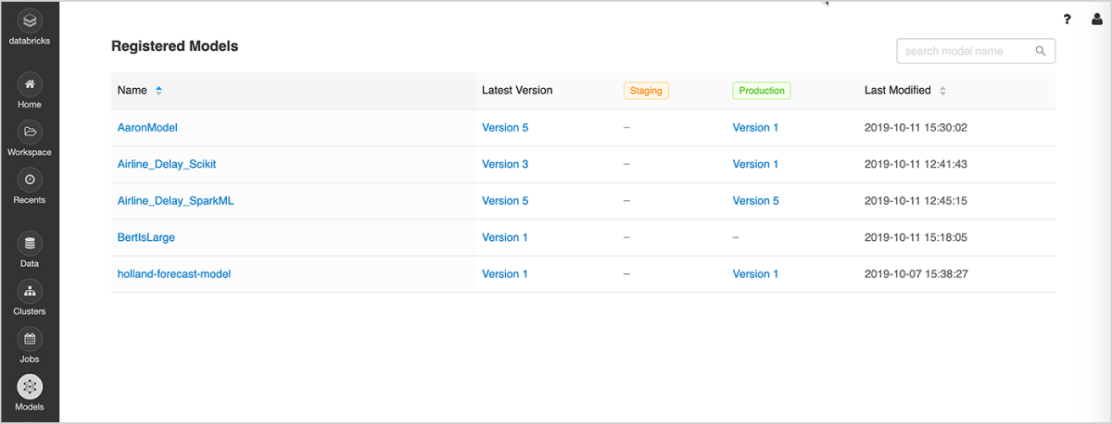
Modellverwaltung
Nutzen Sie eine zentrale Stelle, um ML-Modelle zu entdecken und gemeinsam zu nutzen, um sie gemeinsam vom Experiment zu Online-Tests und zur Produktion zu bringen, um sie in Genehmigungs- und Governance-Workflows und CI/CD-Pipelines zu integrieren und um ML-Einsätze und ihre Leistung zu überwachen. MLflow Model Registry erleichtert den Austausch von Know-how und Wissen und hilft Ihnen, die Kontrolle zu behalten.
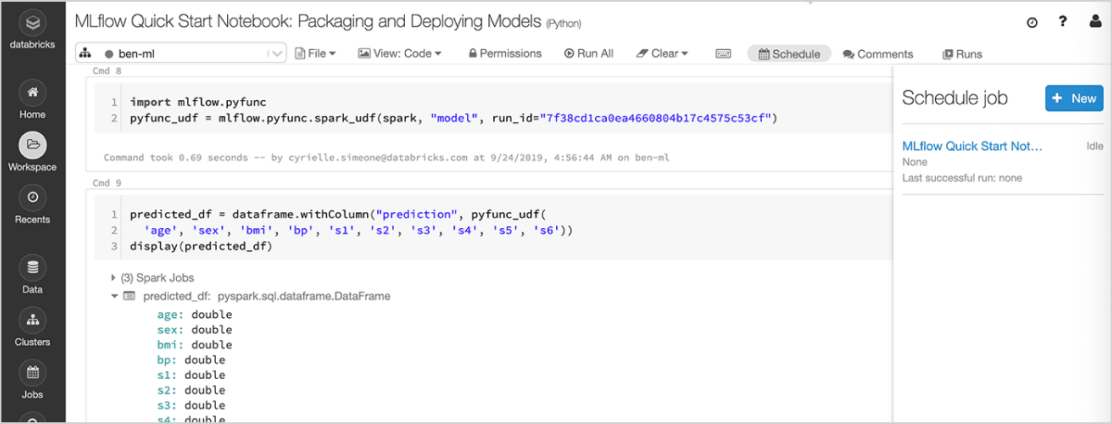
Modelle bereitstellen
Implementieren Sie schnell Produktionsmodelle für Batch-Inferenzen auf Apache Spark�™ oder als REST-APIs mithilfe der integrierten Integration mit Docker-Containern, Azure ML oder Amazon SageMaker. Mit Managed MLflow auf Databricks können Sie Produktionsmodelle mit dem Databricks Jobs Scheduler und automatisch verwalteten Clustern operationalisieren und überwachen, um sie je nach Geschäftsanforderungen zu skalieren.
Die neuesten Upgrades für MLflow ermöglichen eine nahtlose Bereitstellung von Paket-GenAI-Anwendungen. Sie können jetzt Ihre Chatbots und andere GenAI-Anwendungen wie Dokumentzusammenfassung, Sentimentanalysen und Klassifizierung im Scale mithilfe von Databricks Model Serving anwenden.
Features
Tracing
Capture inputs, outputs, and step-by-step execution—including prompts, retrievals, and tool calls—with MLflow’s open-source, OpenTelemetry-compatible tracing. Automatically instrument popular GenAI libraries or ingest traces directly. Debug and iterate faster with interactive timeline views, side-by-side comparisons, and zero vendor lock-in.
Generative AI Evaluation
Evaluate GenAI agents using LLM-as-a-judge and human feedback—right in the MLflow UI. Build datasets from production traces, compare outputs across versions, and assess quality with prebuilt or custom metrics like hallucination or relevance. Incorporate expert feedback via web UIs or app APIs to align with human judgment and continuously improve results.
Prompt Registry and Agent Versioning
Version prompts, agents, and application code in one place with MLflow. Link traces, evaluations, and performance data to specific versions for full lifecycle lineage. Reuse and compare prompts across workflows, manage agent versions with associated metrics and parameters, and integrate with Git and CI/CD to accelerate governed iteration.
Generative AI Monitoring and Alerting
Monitor GenAI quality in real time with MLflow’s dashboards, trace explorers, and automated alerts. Track issues like PII leakage, latency spikes, or unhelpful responses using LLM-judge evaluations and custom metrics. Configure online evaluations and act quickly—before users are affected.
Features
Experiment Tracking
Automatically track parameters, metrics, artifacts, and models from any ML or deep learning framework. MLflow gives you a complete audit trail and supports deep comparisons across architectures, checkpoints, and training workflows—at scale.
Model evaluation for ML and DL
Automatically log built-in and custom metrics for tasks like classification or regression. Compare results against baselines, log artifacts like ROC curves, and validate models on new datasets—before they reach production.
Effortless Model Management & Governance
Discover, share, and manage models centrally with the MLflow Model Registry—integrated with Unity Catalog for end-to-end governance. Track deployment status and collaborate across teams with full visibility into model performance across environments
Deployment at Scale
Deploy models with a reproducible packaging format that includes all code, dependencies, and weights. Serve them as REST APIs or run high-throughput batch inference with ai_query—optimized for both CPU and GPU via Databricks Model Serving.
Sehen Sie sich doch unsere Produktneuigkeiten von Azure Databricks und AWS an, um mehr über unsere neuesten Funktionen zu erfahren.
Vergleichen von MLflow-Angeboten
Open Source MLflow | Managed MLflow on Databricks | |
|---|---|---|
Nachverfolgung von Experimenten | ||
MLflow-Tracking-API | ||
MLflow-Tracking-Server | Eigenes Hosting | Vollständig verwaltet |
Notebooks-Integration | ||
Workflow-Integration | ||
Projekte reproduzieren | ||
MLflow-Projekte | ||
Modellverwaltung | ||
Git- und Conda-Integration | ||
Skalierbare Cloud/Cluster für Projektdurchläufe | ||
MLflow-Modellregister | ||
Modellversionierung | ||
Flexible Bereitstellung | ||
ACL-basierte Stage Transition | ||
CI/CD-Workflow-Integrationen | ||
Sicherheit und Management | ||
Eingebaute Batch-Inferenz | ||
MLflow-Modelle | ||
Eingebaute Streaming-Analyse | ||
Hochverfügbarkeit | ||
Automatische Updates | ||
Rollenbasierte Zugriffskontrolle | ||
Sicherheit und Management | ||
Rollenbasierte Zugriffskontrolle | ||
Rollenbasierte Zugriffskontrolle | ||
Rollenbasierte Zugriffskontrolle | ||
Rollenbasierte Zugriffskontrolle | ||
Sicherheit und Management | ||
Rollenbasierte Zugriffskontrolle | ||
Rollenbasierte Zugriffskontrolle | ||
Rollenbasierte Zugriffskontrolle | ||
Rollenbasierte Zugriffskontrolle | ||
Sicherheit und Management | ||
Rollenbasierte Zugriffskontrolle | ||
Rollenbasierte Zugriffskontrolle | ||
Rollenbasierte Zugriffskontrolle |
Ressourcen
Blogs
VIDEOS
TutorialTutorial
Webinare
Webinare
Webinare
Frequently Asked Questions
Ready to get started?