Produktions-KI-Agenten
Einheitliche Plattform zum Erstellen und Steuern von KI-Agenten, die sich kontinuierlich verbess
Verwalten Sie den Wildwuchs von Agenten. Erstellen Sie Agenten mit Zuversicht.
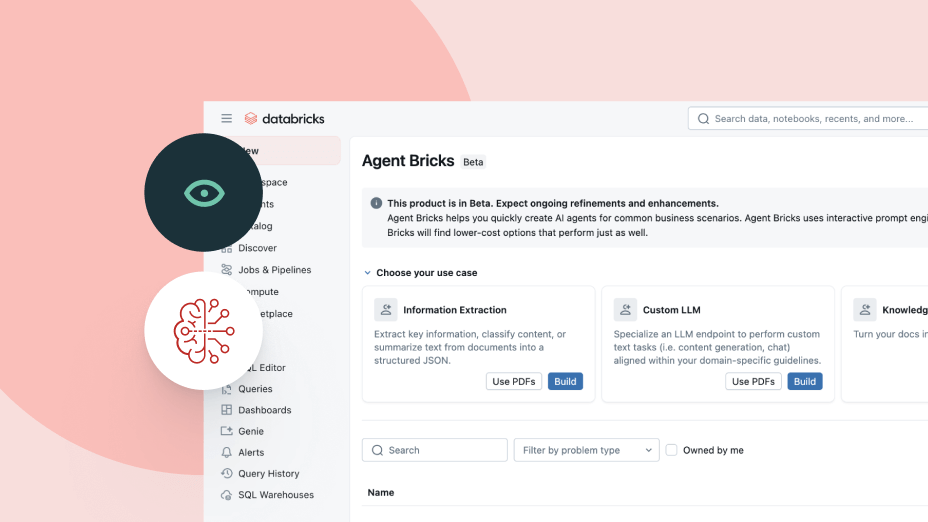
Vereinheitlichen Sie die Entwicklung, Verwaltung und Governance von KI-Agenten für Unternehmen.Agenten, die Ihre Daten kennen
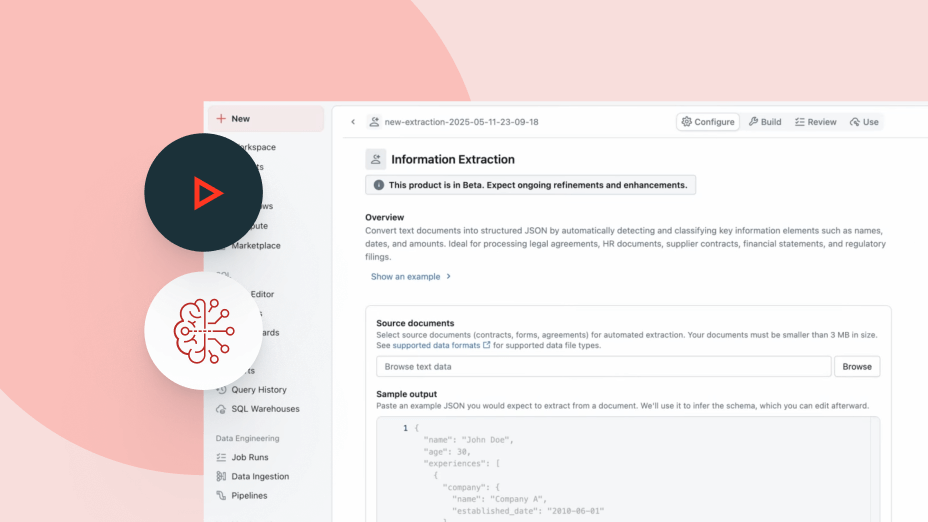
Agent Bricks nutzt Ihren Unternehmenskontext – Schemata, Geschäftsdefinitionen und benutzerdefinierte Semantik –, um intelligentere Entscheidungen zu treffen: : welche Tools und Tabellen verwendet werden sollen, wie Daten korrekt miteinander verknüpft werden und wie präzise, konsistente Antworten entstehen.
Offen und Multi-KI
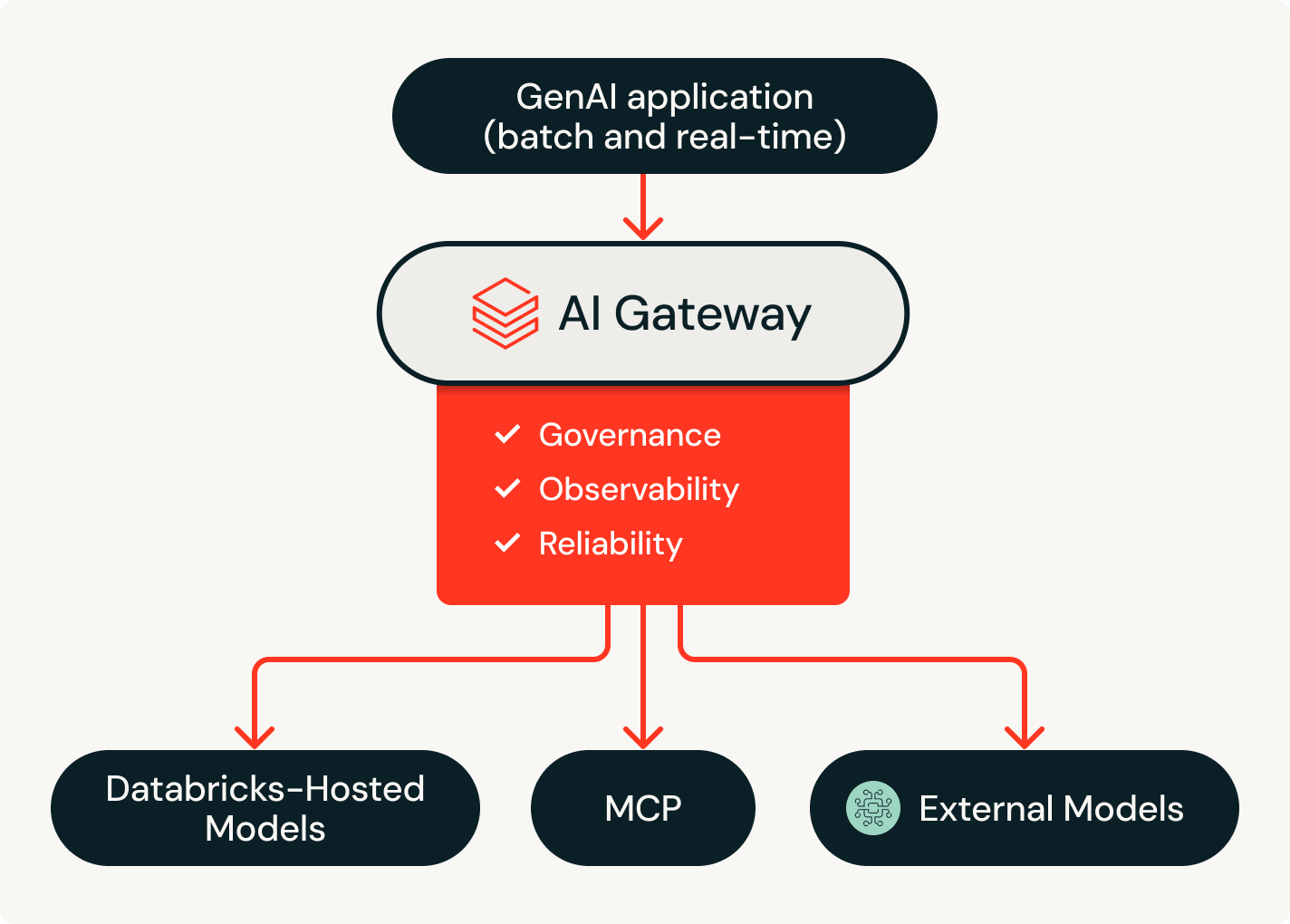
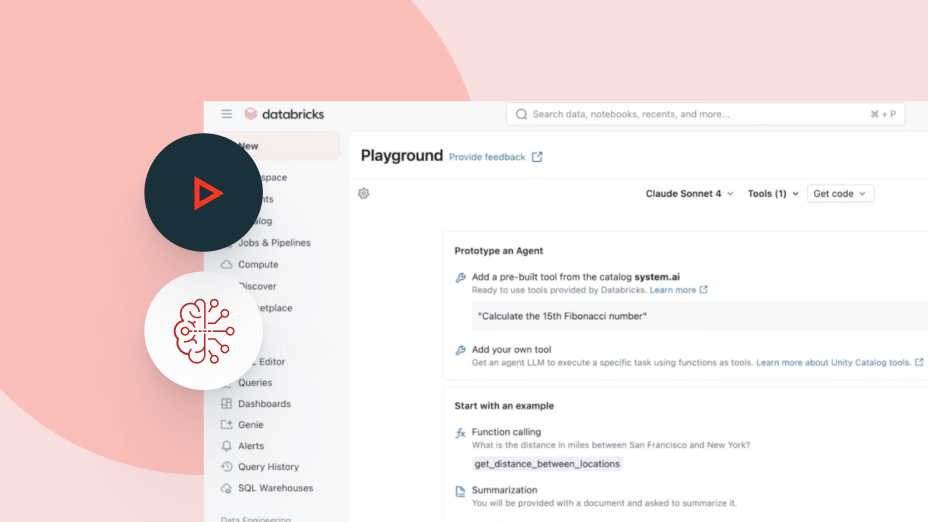
Greifen Sie über eine einzige Plattform auf alle führenden KI-Modelle zu, von OpenAI, Anthropic und Google bis hin zu Open Source. Mit Agent Bricks können Sie Modelle sofort wechseln, um Kosten, Qualität und Performance zu optimieren, ohne Ihren Stack neu aufbauen zu müssen.
Einheitliche Governance
Nur Databricks steuert den gesamten Stack – von Daten bis zu KI-Modellen – in einem einzigen System of Record. Verfolgen Sie jeden Agenten, MCP-Server, jedes Modell und jedes Tool mit klaren Zuständigkeiten und End-to-End-Berechtigungen, die sicherstellen, dass Agenten niemals auf mehr zugreifen, als ihnen gestattet ist.

TOP-TEAMS SIND MIT AGENT BRICKS ERFOLGREICH
Alles, was Sie zum Erstellen, Steuern und Skalieren von Agenten benötigen
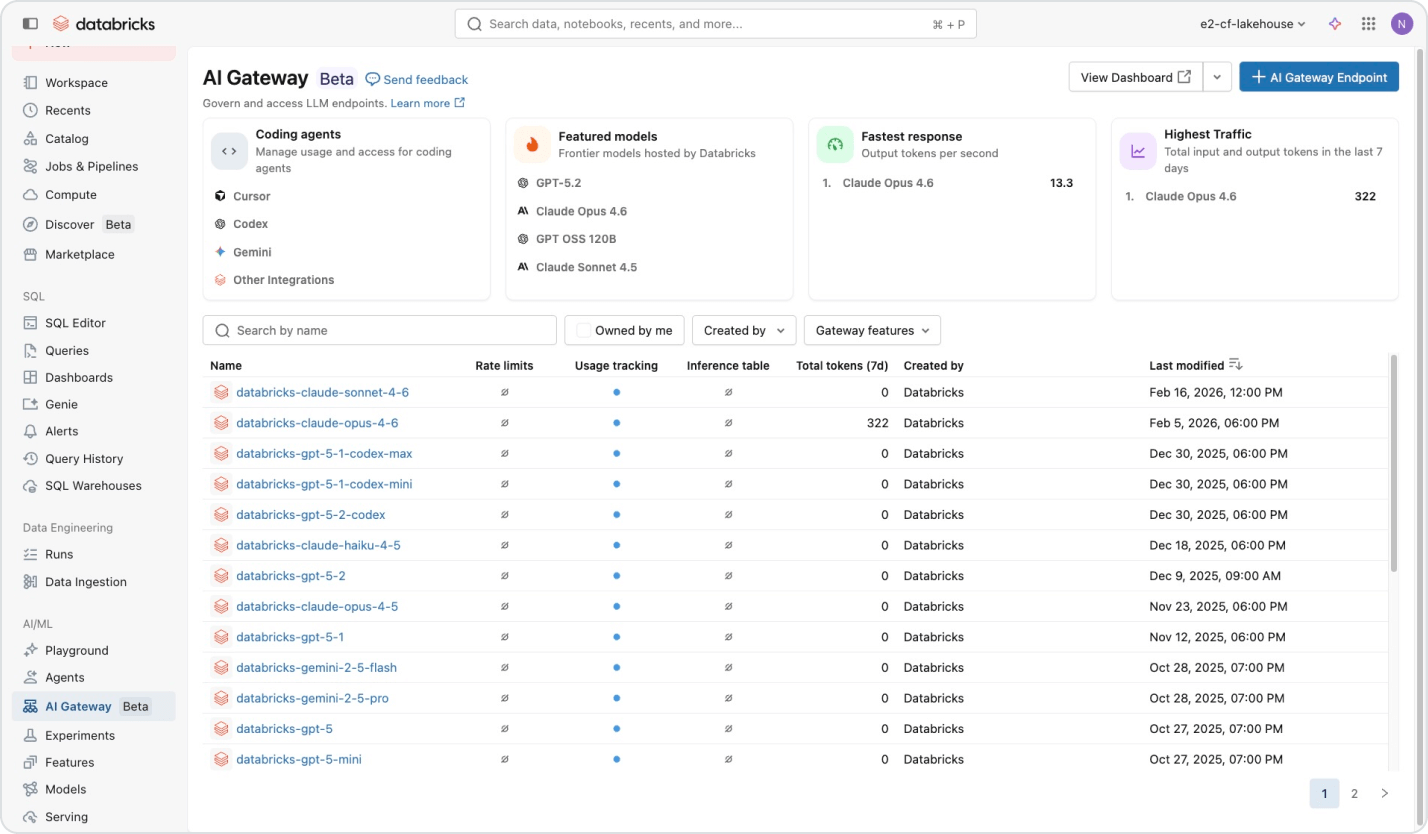
Greifen Sie über einen einzigen Vertrag auf jedes Modell zu – ganz ohne Anbieterbindung.
Greifen Sie über eine einzige Plattform auf KI-Modelle von OpenAI, Anthropic, Google, Meta und mehr zu. Intelligentes Routing und automatische Fallbacks sorgen dafür, dass Agenten auch bei Anbieterausfällen weiterlaufen. Unity Catalog erzwingt granulare Berechtigungen und Ratenbegrenzungen pro Benutzer oder Team – so können Sie den Modellzugriff skalieren, ohne die Kontrolle zu verlieren.



Ausgaben im Griff dank nutzungsbasierter Abrechnung
Sie zahlen nur für die Produkte, die Sie tatsächlich nutzen – und das sekundengenau.Mehr entdecken
Erfahren Sie mehr darüber, wie die Databricks Data Intelligence Platform Ihre Datenteams bei all Ihren Daten- und KI-Workloads unterstützt.
Genie
Erhalten Sie Einblicke in Ihre Daten, indem Sie Fragen in natürlicher Sprache stellen.

Databricks Apps
Verwandeln Sie benutzerdefinierte Agenten in sichere KI-Anwendungen mit Benutzeroberfläche auf Databricks. Erstellen Sie umfassende Erlebnisse auf der Grundlage von gesteuerten Daten und Modellen, mit serverloser Infrastruktur und integrierter Skalierung.

Modellbereitstellung
Stellen Sie KI-Modelle oder -Agenten in der Produktion bereit und steuern Sie sie mit integrierter Observability, Skalierbarkeit und Enterprise-Kontrollen.

AI Search
Betreiben Sie Echtzeit-KI-Anwendungen mit einer leistungsstarken Vektordatenbank, die Ihre Quelldaten kontinuierlich synchronisiert.

Unity Catalog
Verwalten Sie strukturierte und unstrukturierte Daten, ML-Modelle, Notebooks, Dashboards und Dateien nahtlos in jeder Cloud und auf jeder Plattform.

Künstliche Intelligenz
Entdecken Sie die gesamte Suite der KI-Tools von Databricks für durchgängige KI-Agentensysteme.

Die Databricks Data Intelligence-Plattform
Entdecken Sie die gesamte Palette der auf Databricks verfügbaren Tools, um Daten und KI nahtlos in Ihrem Unternehmen zu integrieren.
Wagen Sie den nächsten Schritt




Agent Bricks FAQ
Möchten Sie ein Daten- und KI-Unternehmen werden?
Machen Sie die ersten Schritte Ihrer Datentransformation