Databricks Notebooks
Einheitliche Developer Experience zum Erstellen von Daten- und KI-Projekten


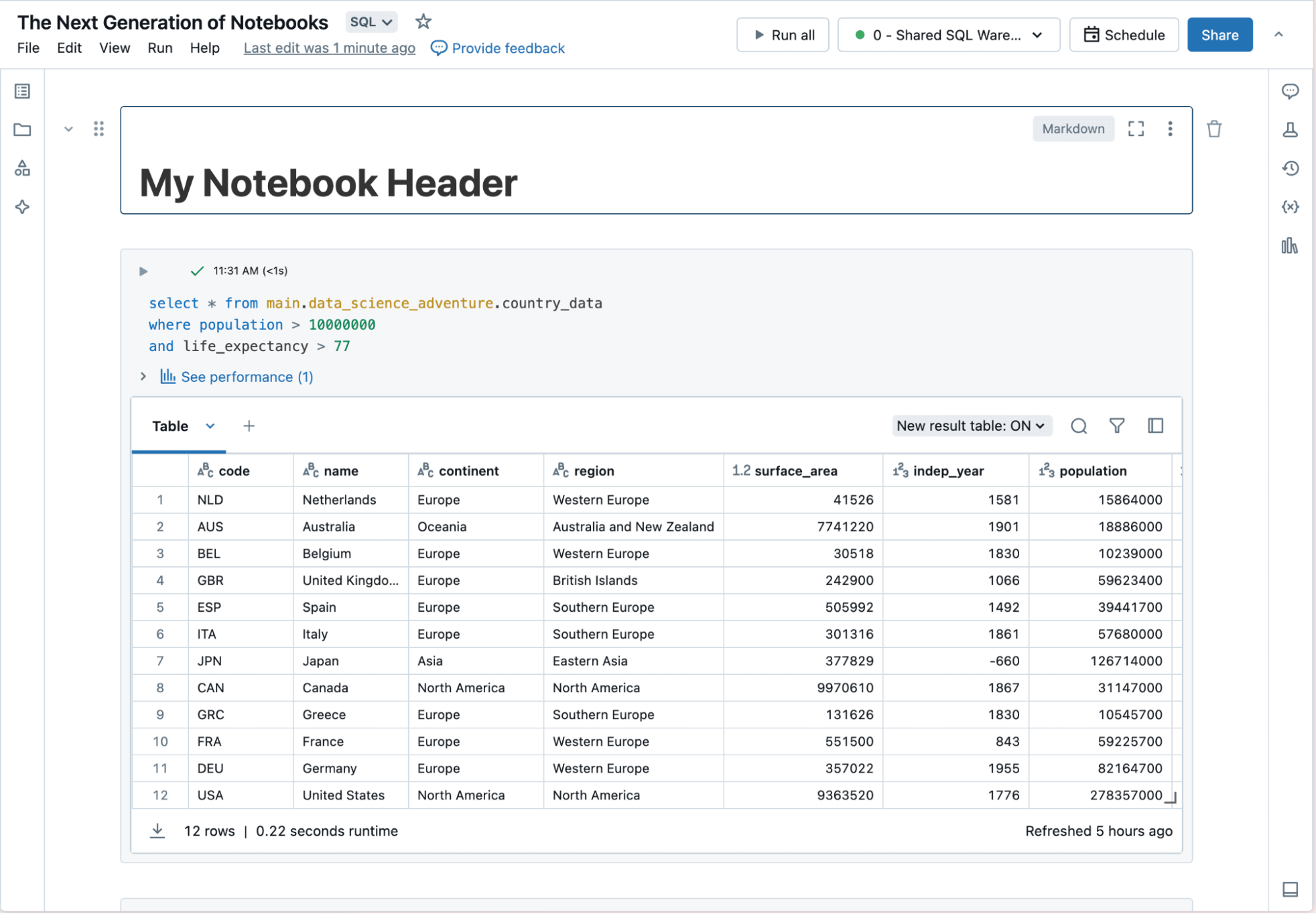
Databricks Notebooks vereinfachen Entwicklern die Erstellung von Daten- und KI-Projekten durch vollständig verwaltete und hochautomatisierte Workflows. Notebooks werden nativ auf der Databricks Data Intelligence Platform ausgeführt. So finden Datenexperten einen schnellen Einstieg und können Anwendungen mithilfe kontextsensitiver Tools entwickeln und die Ergebnisse bequem weitergeben.
Nahtlose Integration
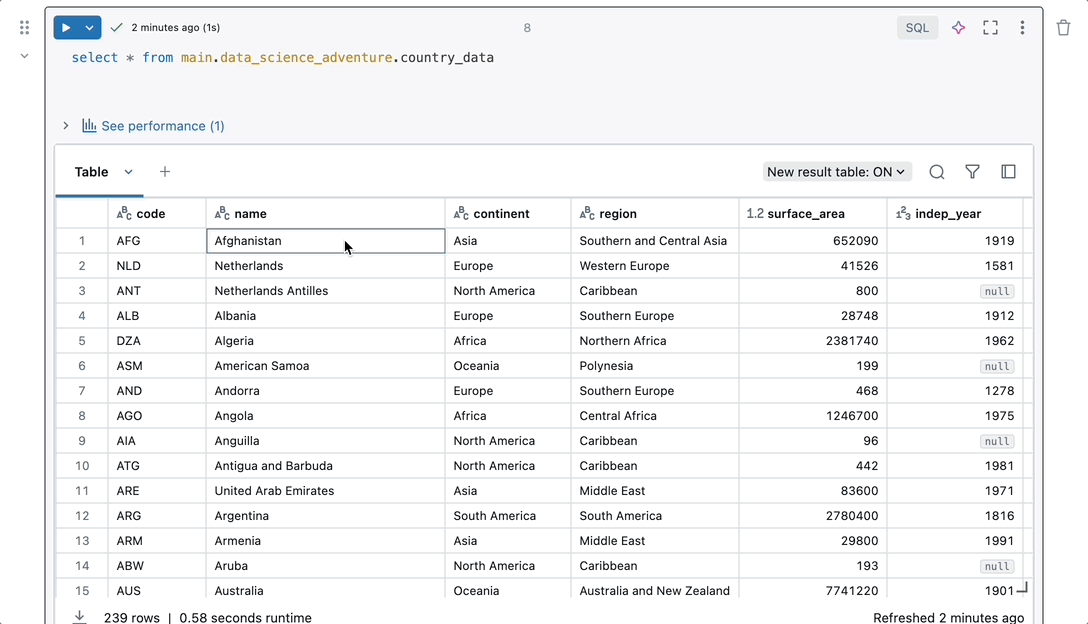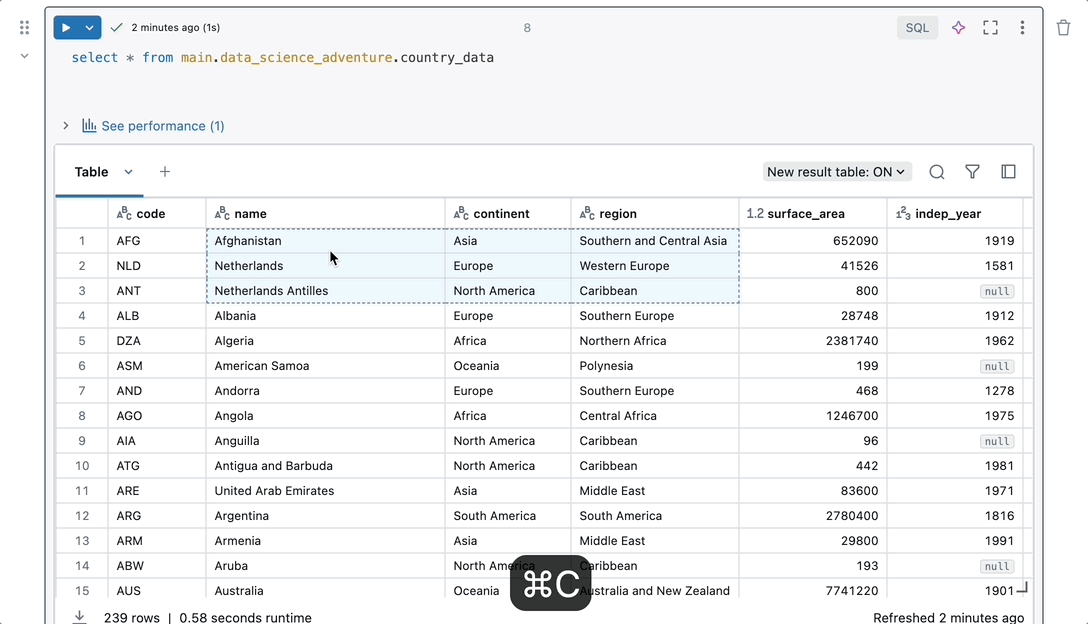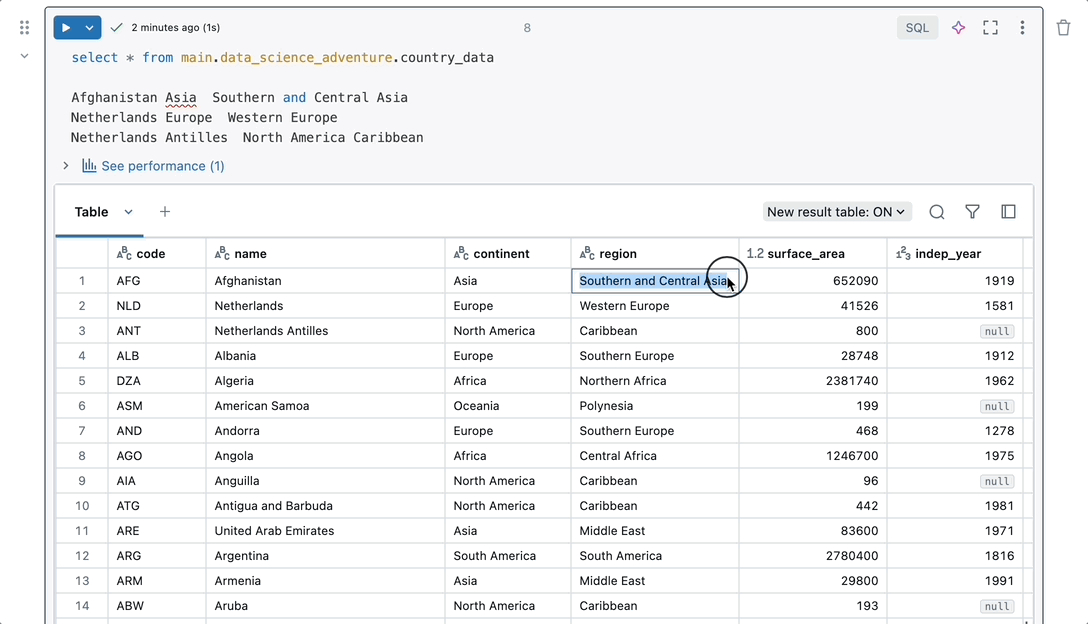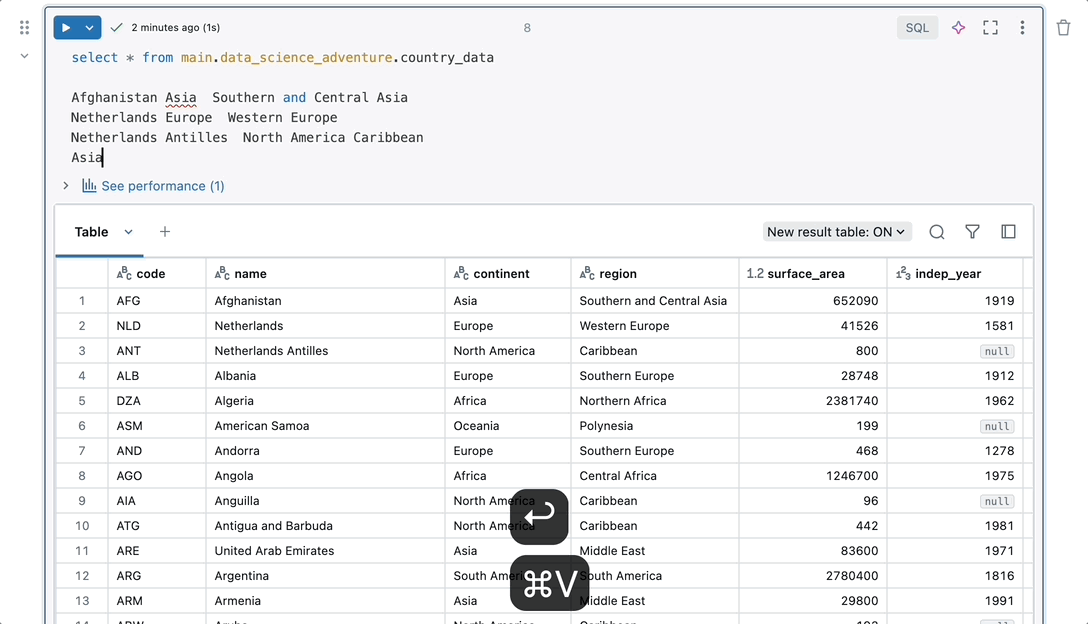
Beginnen Sie mit der Arbeit, ohne Ihren Arbeitsbereich einrichten und konfigurieren zu müssen. Notebooks verfügen über native Features für den gesamten Umgang mit Daten an einem Ort. Sie können ohne zusätzliche Einrichtung auf Daten-, Compute- und Visualisierungs-Tools zugreifen, sodass Sie sich auf die Analyse Ihrer Daten konzentrieren können.
Data-Intelligence-Tools
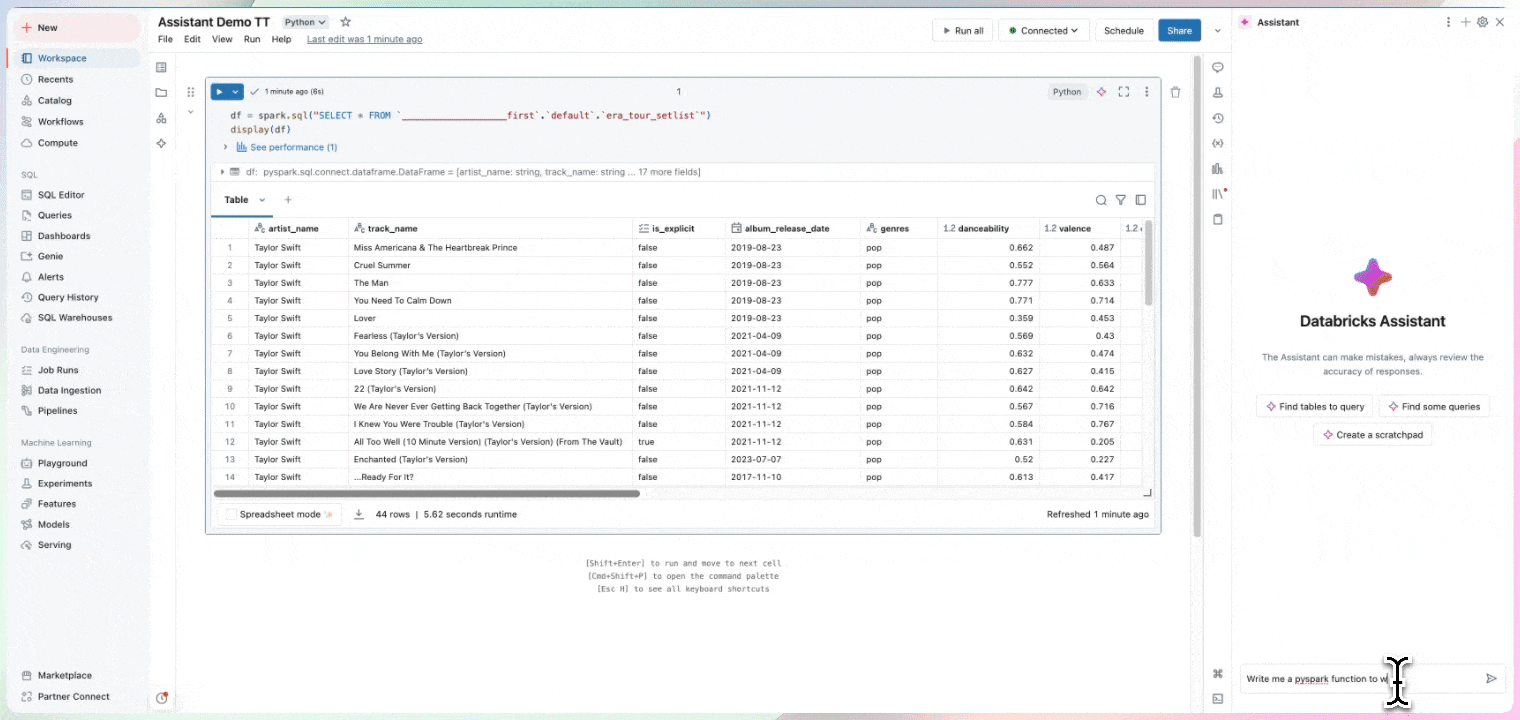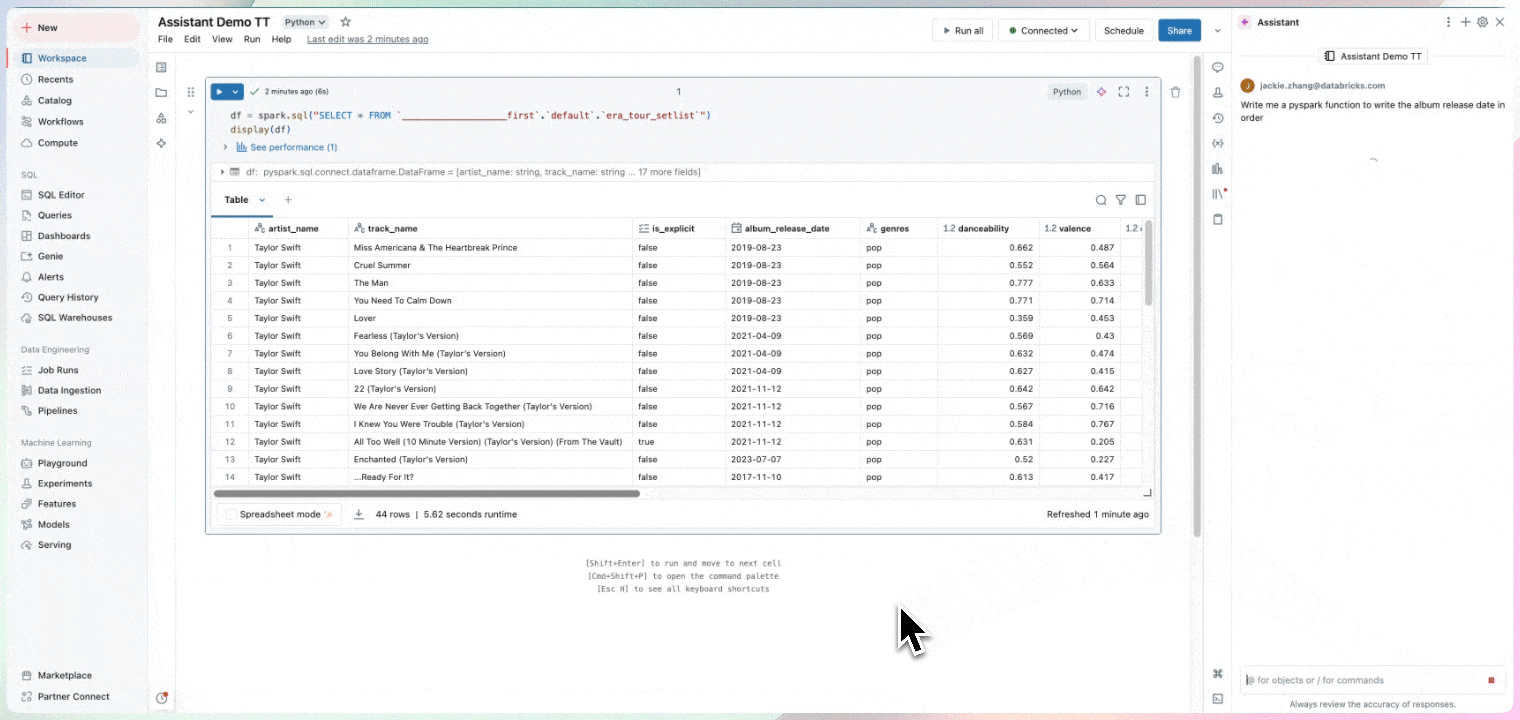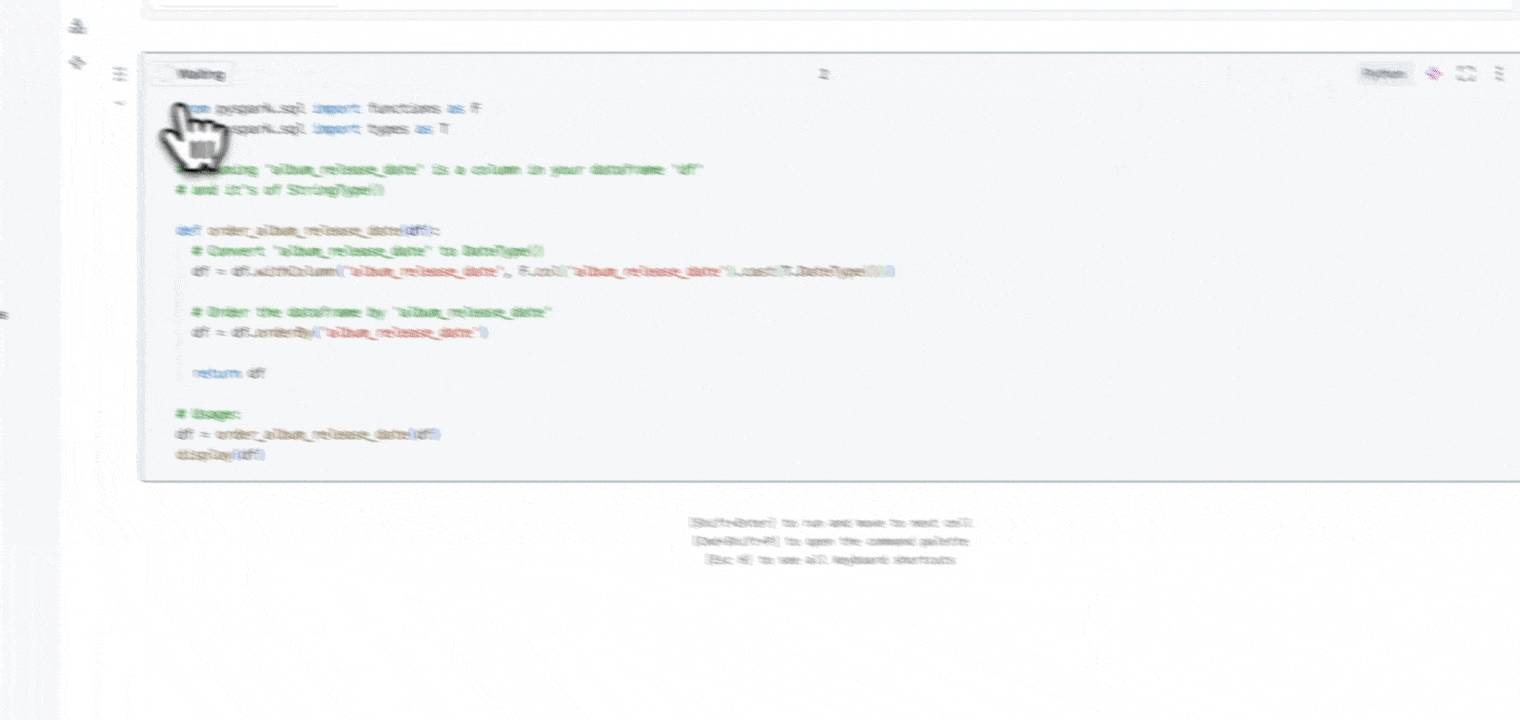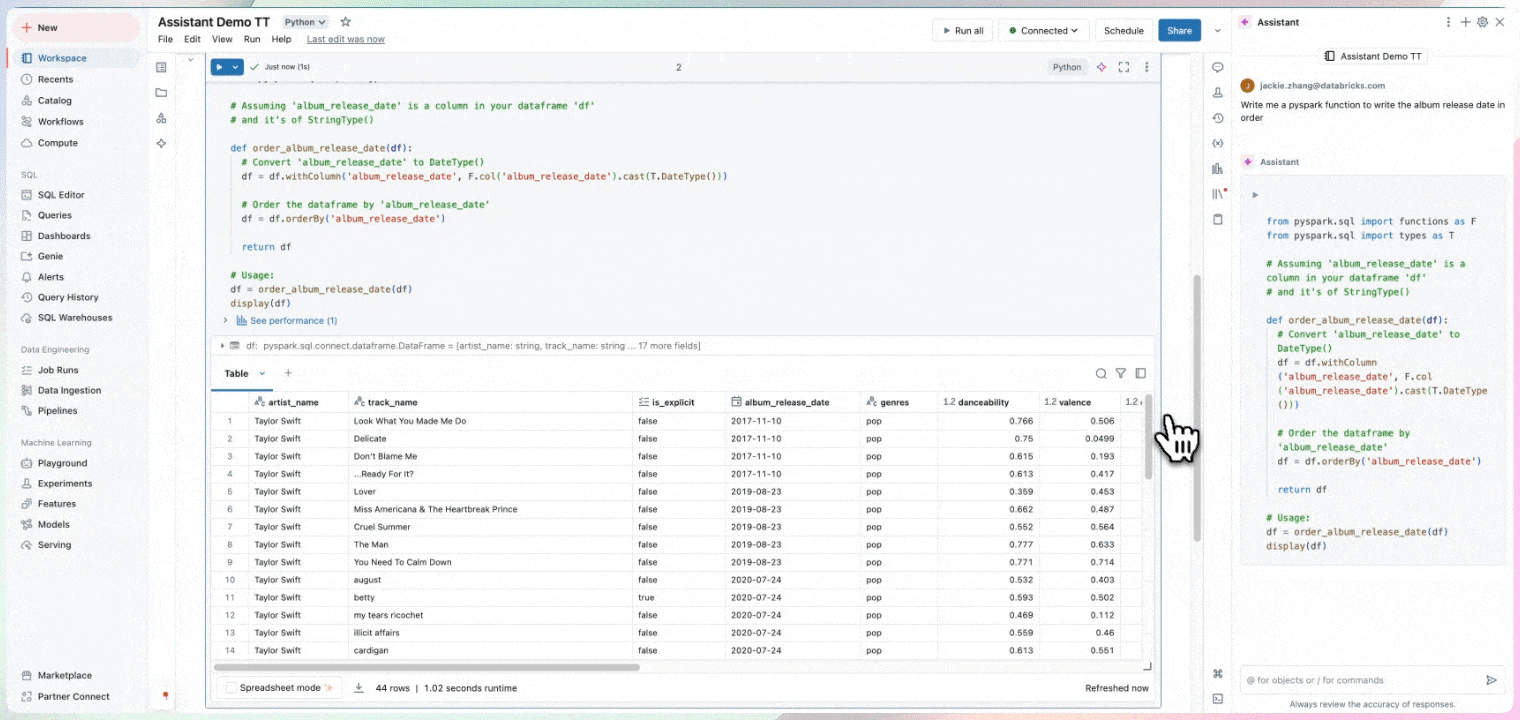
Nutzen Sie Ihre Zeit, um Erkenntnisse zu gewinnen und nicht um Standardcode zu schreiben. Notebooks nutzen Informationen über Ihre Daten, einschließlich Herkunft, zugehörige Tabellen und Beliebtheit für Vorschläge, die für Ihre Arbeit relevant sind. Notebooks enthalten den Databricks Assistant, einen kontextsensitiven KI-Assistenten, mit dem Sie über eine Konversationsschnittstelle Daten abfragen können, um Ihre Produktivität zu steigern.
Gemeinschaftlicher Arbeitsbereich:
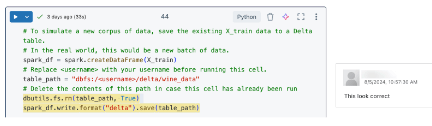
Erstellen Sie gemeinsam Projekte an einem Ort und teilen Sie sie mit dem gesamten Datenteam. Speichern Sie Markdown-Kommentare und Code in mehreren Sprachen in Notebooks, um wichtigen Kontext mit anderen zu teilen. Sehen Sie sich Nutzungsprotokolle und Forks in Berichten an, um zu verstehen, wie die Analyse genutzt wird.