Modellbereitstellung
Einheitliche Bereitstellung und Governance für alle KI-Modelle und -Agents


Einführung
Databricks Model Serving bietet Unternehmen eine robuste Lösung für die Bereitstellung klassischer ML-Modelle, generativer KI-Modelle und KI-Agents. Unterstützt werden sowohl proprietäre Modelle wie Azure OpenAI, AWS Bedrock und Anthropic als auch Open-Source-Modelle wie Llama und Mistral. Darüber hinaus können Kunden auch fein abgestimmte Open-Source-Modelle oder klassische ML-Modelle, die auf ihren eigenen Daten trainiert wurden, bereitstellen. Die bereitgestellten Modelle lassen sich nahtlos als Endpunkte in Workflows einbinden – etwa für großvolumige Batch-Inferenz oder Echtzeitanwendungen. Model Serving bietet außerdem integrierte Funktionen für Governance, Datenherkunft und Monitoring, sodass konsistente und hochwertige Outputs gewährleistet sind.
Kundenzitate
Einfachere Bereitstellung sämtlicher KI-Modelle und -Agents
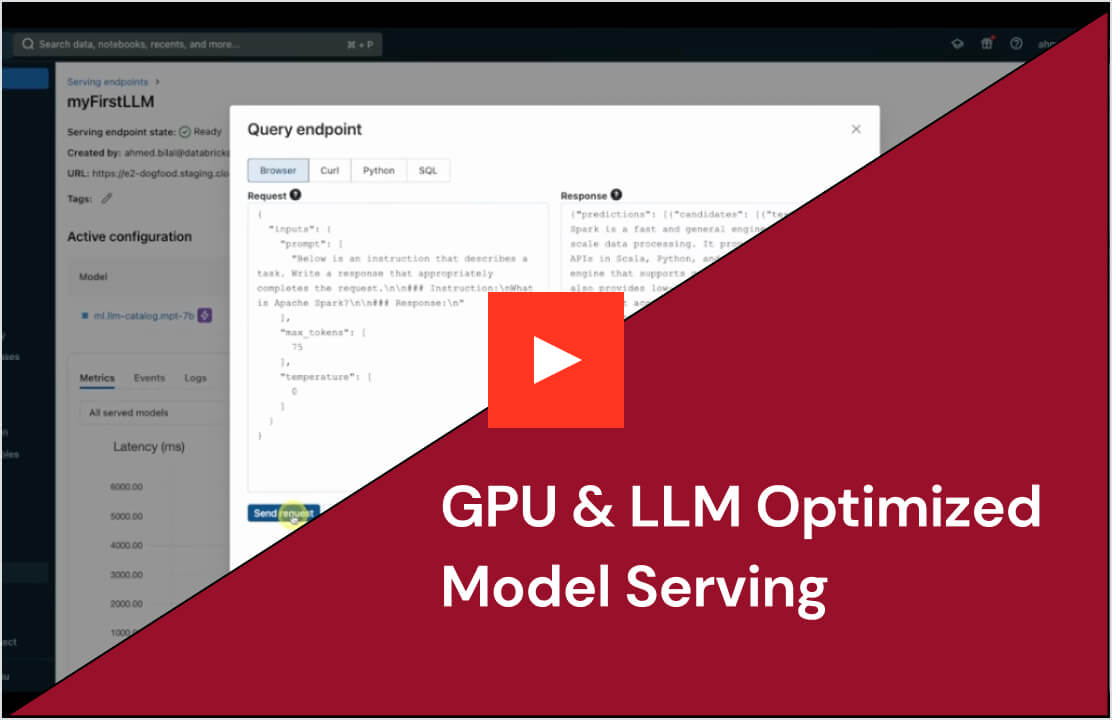
Stellen Sie beliebige Modelltypen bereit, von vortrainierten Open-Source-Modellen bis hin zu individuell entwickelten Modellen, die auf Ihren eigenen Daten basieren – sowohl auf CPU als auch auf GPU. Die automatisierte Erstellung von Containern und das Infrastrukturmanagement senken Wartungskosten und beschleunigen die Bereitstellung. So können Sie sich ganz auf den Aufbau Ihrer KI-Agent-Systeme konzentrieren und schneller geschäftlichen Mehrwert schaffen.
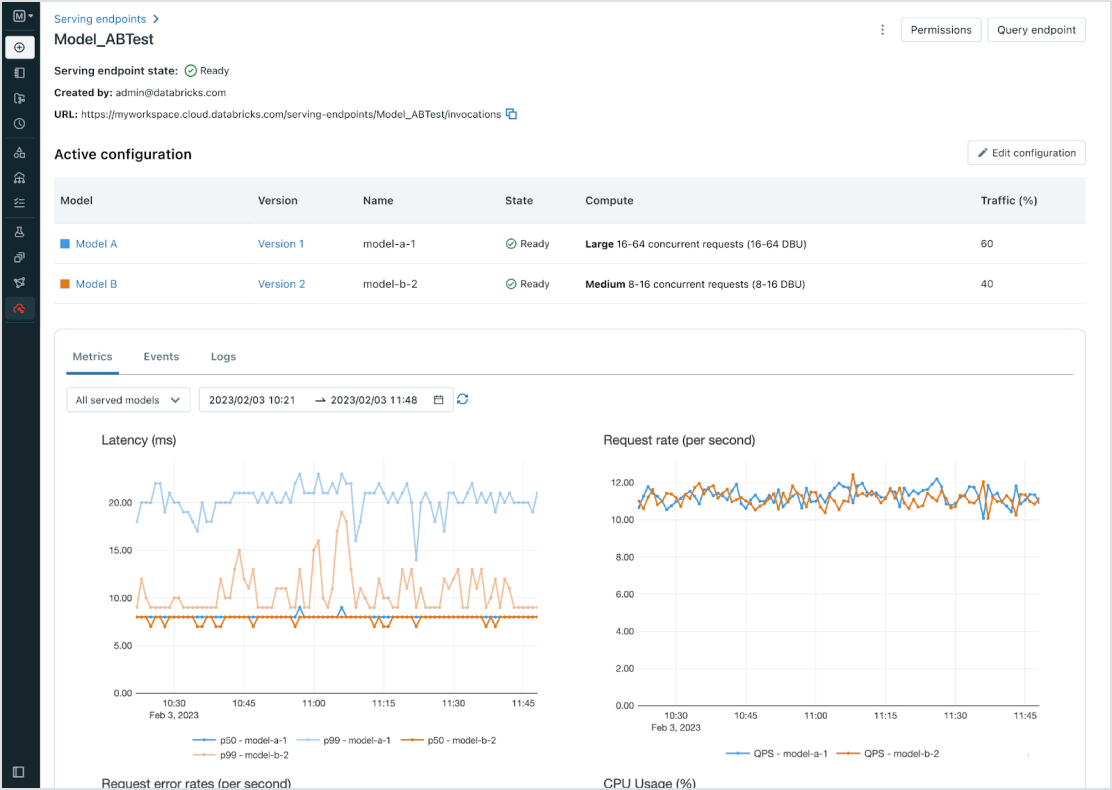
Einheitliche Verwaltung aller Modelle
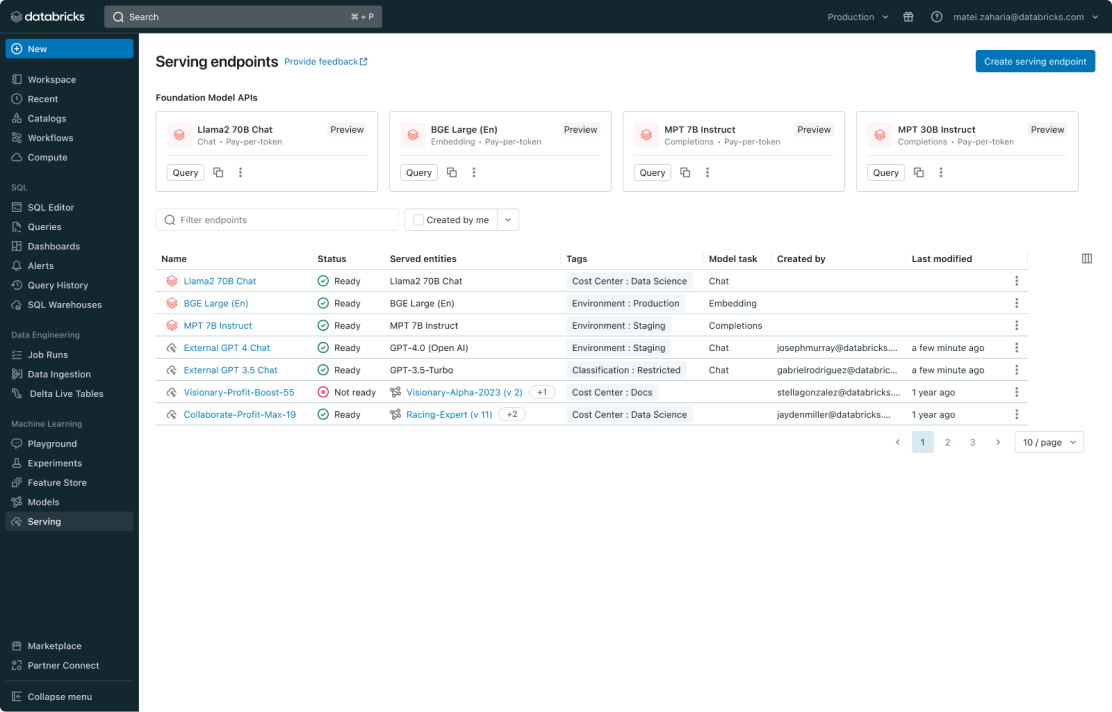
Verwalten Sie alle Modelle, einschließlich benutzerdefinierter ML-Modelle wie PyFunc, Scikit-Learn und LangChain, Foundation-Modelle (FMs) auf Databricks wie Llama 2, MPT und BGE sowie anderswo gehosteter Foundation-Modelle wie ChatGPT, Claude 2, Cohere und Stable Diffusion. Model Serving macht alle Modelle über eine einheitliche Benutzeroberfläche und API zugänglich, einschließlich der von Databricks oder von einem anderen Modellanbieter auf Azure und AWS gehosteten Modelle.
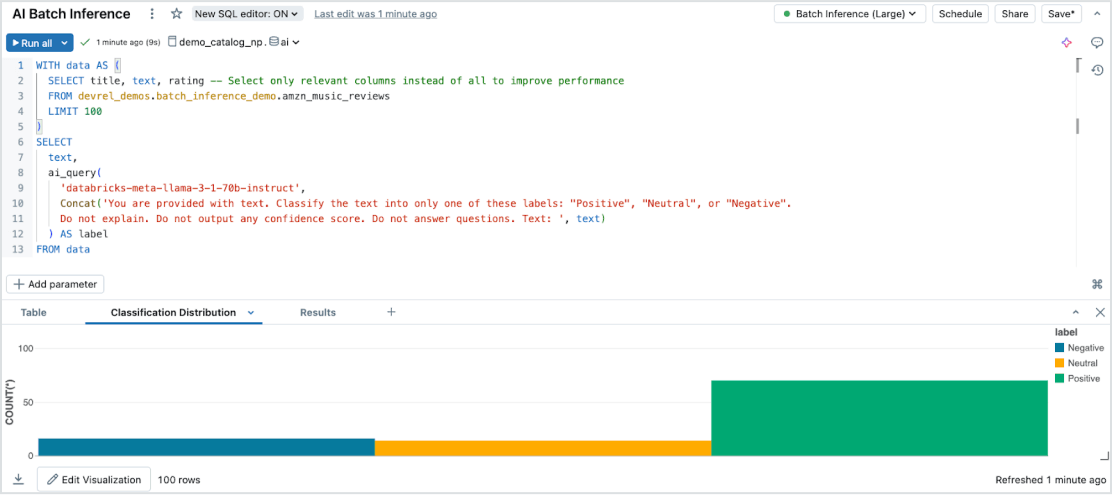
Mühelose Batch-Inferenz
Model Serving ermöglicht über alle Datentypen und Modelle hinweg effiziente, serverlose KI-Inferenz auf großen Datensätzen. Integrieren Sie nahtlos mit Databricks SQL, Notebooks und Workflows, um KI im großen Maßstab einzusetzen. Mit KI-Funktionen führen Sie groß angelegte Batch-Inferenzen sofort aus – ganz ohne Infrastrukturverwaltung – und stellen dabei Geschwindigkeit, Skalierbarkeit und Governance sicher.
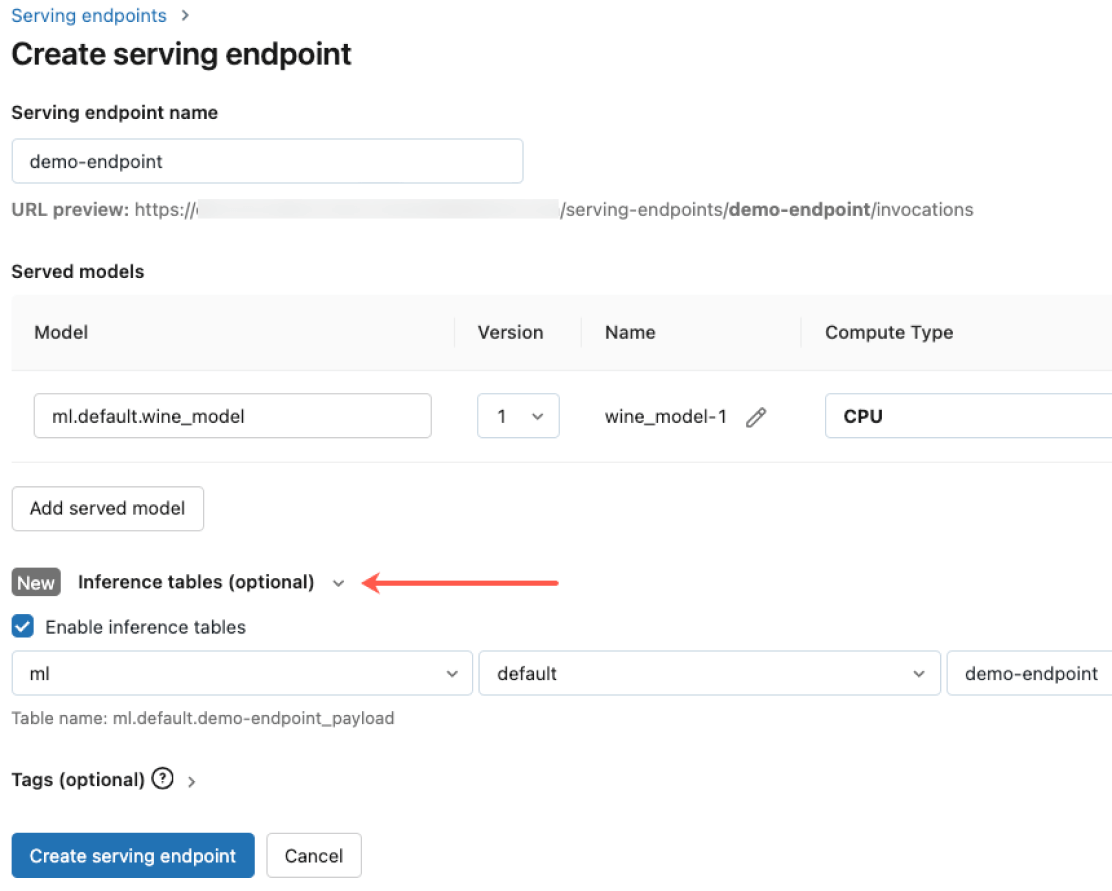
Integrierte Governance
Integrieren Sie mit Agent Bricks AI Gateway, um strengen Sicherheits- und erweiterten Governance-Anforderungen gerecht zu werden. Sie können geeignete Berechtigungen durchsetzen, die Modellqualität überwachen, Zugriffslimits festlegen und die Herkunft aller Modelle nachverfolgen, unabhängig davon, ob sie von Databricks gehostet werden oder von einem anderen Modellanbieter.
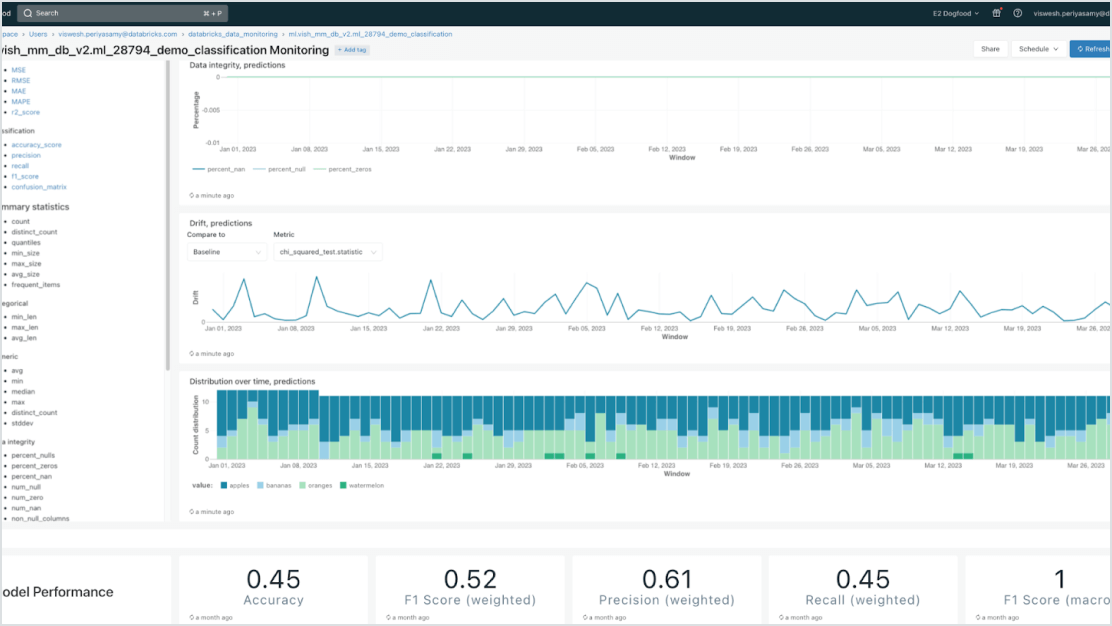
Datenzentrierte Modelle
Beschleunigen Sie Bereitstellungen und reduzieren Sie Fehler durch eine umfassende Integration mit der Data-Intelligence-Plattform. Sie können problemlos verschiedene klassische ML- und generative KI-Modelle hosten, die augmentiert (RAG) oder mit Unternehmensdaten optimiert wurden. Model Serving bietet automatisierte Suchanfragen, Monitoring und Governance über den gesamten KI-Lebenszyklus hinweg.
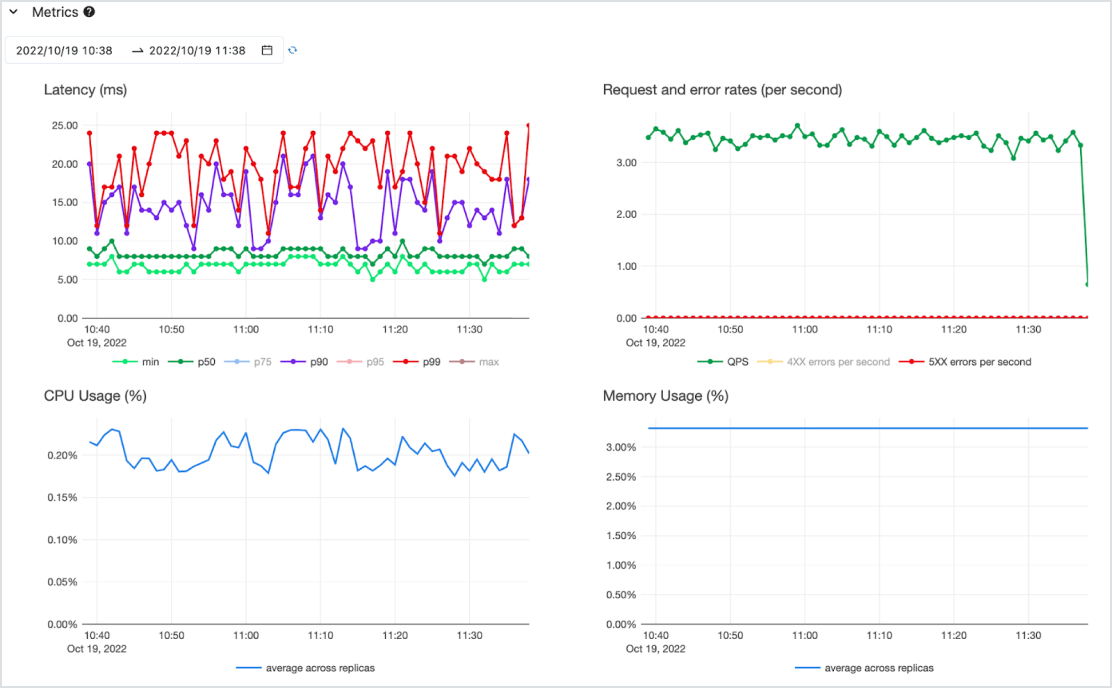
Kosteneffizient
Stellen Sie Modelle als API mit geringer Latenz auf einem hochverfügbaren Serverless-Dienst mit CPU- und GPU-Unterstützung bereit. Skalieren Sie mühelos von Null, um Ihre wichtigsten Anforderungen zu erfüllen, und wieder herunter, wenn sich die Anforderungen ändern. Sie können schnell mit einem oder mehreren vorab bereitgestellten Modellen und Pay-per-Token (on demand ohne Verpflichtungen) oder Pay-for-provisioned-Compute zur Gewährleistung von Durchsatz loslegen. Databricks übernimmt die Infrastrukturverwaltung und die Wartungskosten, sodass Sie sich auf die Schaffung von Mehrwert für Ihr Unternehmen konzentrieren können.