Das Gesamtbild: Vereinheitlichung der Kosten für Databricks und die Cloud-Infrastruktur
Erfahren Sie, wie Sie einheitliche Kosten-Dashboards automatisieren, die FinOps- und Plattform-Teams tatsächlich nutzen möchten.
von Steven Muschler, Daniel Martinez Arevalo und Sadhana Bala
- Die neue Cloud Infra Cost Field Solution (verfügbar für AWS und Azure) zeigt, wie Databricks- und zugehörige Cloud-Kostendaten aufgenommen, angereichert, gejoint und visualisiert werden können, um die Gesamtkosten auf Account-, Cluster- und sogar Tag-Ebene anzuzeigen.
- Die Implementierung der Field Solution bietet FinOps- und Plattform-Teams eine einzige, vertrauenswürdige TCO-Ansicht, die es ihnen ermöglicht, die vollständigen Kosten nach Workspace, Workload und Geschäftsbereich aufzuschlüsseln, um die Nutzung mit den Budgets in Einklang zu bringen. Dadurch entfällt der manuelle Abgleich und die Kostenberichterstattung wird zu einer ständig verfügbaren, betrieblichen Funktion.
- Unternehmen wie General Motors haben diesen Ansatz übernommen, um ein ganzheitliches Verständnis ihrer Databricks-Kosten zu entwickeln und sicherzustellen, dass diese sichtbar und gut verständlich sind.
Grundlagen der TCO auf Databricks
Den Wert Ihrer KI- und Dateninvestitionen zu verstehen, ist entscheidend – doch über 52 % der Unternehmen versäumen es, den Return on Investment (ROI) rigoros zu messen [Futurum]. Eine vollständige ROI-Transparenz erfordert die Verknüpfung von Plattformnutzung und Cloud-Infrastruktur zu einem klaren Finanzbild. Oft sind die Daten zwar verfügbar, aber fragmentiert, da die heutigen Datenplattformen eine wachsende Palette von Speicher- und Compute-Architekturen unterstützen müssen.
Auf Databricks verwalten Kunden Multicloud-, Multi-Workload- und Multi-Team-Umgebungen. In diesen Umgebungen ist eine konsistente, umfassende Kostenübersicht unerlässlich, um fundierte Entscheidungen zu treffen.
Im Mittelpunkt der Kostentransparenz auf Plattformen wie Databricks steht das Konzept der Gesamtbetriebskosten (Total Cost of Ownership, TCO).
Auf Multicloud-Datenplattformen wie Databricks besteht die TCO aus zwei Kernkomponenten:
- Plattformkosten, wie z. B. compute und verwalteter Speicher, sind Kosten, die durch die direkte Nutzung von Databricks-Produkten entstehen.
- Kosten für die Cloud-Infrastruktur, wie z. B. Gebühren für virtuelle Maschinen, Speicher und Netzwerke, sind Kosten, die durch die zugrunde liegende Nutzung von Cloud-Dienste entstehen, die zur Unterstützung von Databricks erforderlich sind.
Das Verständnis der TCO wird durch die Verwendung von serverlosen Produkten vereinfacht. Da compute von Databricks verwaltet wird, werden die Kosten für die Cloud-Infrastruktur in den Databricks-Kosten gebündelt. Dies bietet Ihnen eine zentralisierte Kostentransparenz direkt in den Databricks-Systemtabellen (obwohl die Speicherkosten weiterhin beim Cloud-Anbieter anfallen).
Die TCO für klassische Compute-Produkte zu verstehen, ist jedoch komplexer. Hier verwalten Kunden compute direkt beim Cloud-Anbieter, sodass sowohl die Kosten für die Databricks-Plattform als auch die Kosten für die Cloud-Infrastruktur abgeglichen werden müssen. In diesen Fällen müssen zwei verschiedene Datenquellen abgeglichen werden:
- Systemtabellen (AWS | AZURE | GCP) in Databricks stellen betriebliche Metadaten auf Workload-Ebene und die Databricks-Nutzung bereit.
- Kostenberichte des Cloud-Anbieters schlüsseln die Kosten für die Cloud-Infrastruktur auf, einschließlich Rabatten.
Zusammen bilden diese Quellen die vollständige TCO-Ansicht. Wenn Ihre Umgebung über viele Cluster, Jobs und Cloud-Konten hinweg wächst, wird das Verständnis dieser Datasets zu einem entscheidenden Teil der Kostenbeobachtbarkeit und der Finanz-Governance.
Die Komplexität der TCO
Die Messung Ihrer Databricks-TCO wird durch die unterschiedliche Art und Weise, wie Cloud-Anbieter Kostendaten bereitstellen und melden, zusätzlich erschwert. Um zu verstehen, wie diese Datensätze mit Systemtabellen gejoint werden können, um genaue Kosten-KPIs zu ermitteln, sind fundierte Kenntnisse der Cloud-Abrechnungsmechanik erforderlich – Kenntnisse, die viele auf Databricks spezialisierte Plattform-Administratoren möglicherweise nicht haben. Hier befassen wir uns eingehend mit der Messung Ihrer TCO für Azure Databricks und Databricks auf AWS.
Azure Databricks: Nutzung von Erstanbieter-Abrechnungsdaten
Da Azure Databricks ein First-Party-Dienst innerhalb des Microsoft Azure-Ökosystems ist, erscheinen mit Databricks verbundene Kosten direkt in Azure Cost Management neben anderen Azure-Diensten, sogar einschließlich Databricks-spezifischer Tags. Databricks-Kosten werden in der Azure Cost Analysis-UI und als Kostenverwaltungsdaten angezeigt.
Allerdings enthalten die Daten von Azure Cost Management nicht die detaillierteren Metadaten auf Workload-Ebene und die Performance-Metriken, die in den Systemtabellen von Databricks zu finden sind. Daher versuchen viele Unternehmen, Azure-Abrechnungsexporte in Databricks zu importieren.
Doch diese beiden Datenquellen vollständig zusammenzuführen, ist zeitaufwändig und erfordert tiefgreifendes Fachwissen – ein Aufwand, den die meisten Kunden einfach nicht haben, um ihn zu definieren, zu pflegen und zu replizieren. Mehrere Herausforderungen tragen dazu bei:
- Die Infrastruktur muss für automatisierte Kostenexporte nach ADLS eingerichtet werden, die dann direkt in Databricks referenziert und abgefragt werden können.
- Azure-Kostendaten werden täglich aggregiert und aktualisiert, im Gegensatz zu Systemtabellen, die stündlich aktualisiert werden – die Daten müssen sorgfältig dedupliziert und die Zeitstempel abgeglichen werden.
- Das Zusammenführen der beiden Quellen erfordert das Parsen von Azure-Tag-Daten mit hoher Kardinalität und das Identifizieren des richtigen Join-Schlüssels (z. B. ClusterId).
Databricks on AWS: Angleichung der Marketplace- und Infrastrukturkosten
Auf AWS erscheinen die Databricks-Kosten zwar im Cost and Usage Report (CUR) und im AWS Cost Explorer, die Kosten werden jedoch im Gegensatz zu Azure auf einer stärker aggregierten Artikelnummer-Ebene dargestellt. Zudem erscheinen Databricks-Kosten nur im CUR, wenn Databricks über den AWS Marketplace erworben wird; andernfalls spiegelt der CUR nur die Kosten der AWS-Infrastruktur wider.
In diesem Fall ist es für Kunden mit AWS-Umgebungen noch entscheidender zu verstehen, wie AWS CUR zusammen mit Systemtabellen analysiert werden kann. So können Teams Infrastrukturausgaben, DBU-Nutzung und Rabatte zusammen mit dem Kontext auf Cluster- und Workload-Ebene analysieren und erhalten so eine vollständigere TCO-Ansicht über AWS Accounts und -Regionen hinweg.
Die Verknüpfung von AWS CUR mit Systemtabellen kann jedoch auch eine Herausforderung sein. Häufige Probleme sind unter anderem:
- Die Infrastruktur muss die wiederkehrende Neuverarbeitung von CUR unterstützen, da AWS die Kostendaten für den aktuellen Monat und alle früheren Abrechnungszeiträume mit Änderungen mehrmals täglich (ohne Primär-Key) refresht und ersetzt.
- AWS-Kostendaten umfassen mehrere Postentypen und Kostenfelder, weshalb vor der Aggregation die richtigen effektiven Kosten pro Nutzungstyp (On-Demand, Savings Plan, Reserved Instances) ausgewählt werden müssen.
- Die Verknüpfung des CUR mit Databricks-Metadaten erfordert eine sorgfältige Zuordnung, da die Kardinalität unterschiedlich sein kann. Beispielsweise werden gemeinsam genutzte All-Purpose-Clusters als eine einzige AWS-Nutzungszeile dargestellt, können aber mehreren Jobs in Systemtabellen zugeordnet werden.
Vereinfachung der Databricks-TCO-Berechnungen
In Databricks-Umgebungen im Produktions-Scale gehen Kostenfragen schnell über die Gesamtausgaben hinaus. Teams möchten Kosten im Kontext verstehen – also wie die Nutzung von Infrastruktur und Plattformen mit realen Workloads und Entscheidungen zusammenhängt. Häufig gestellte Fragen:
- Wie schneiden die Gesamtkosten eines serverlosen Jobs im Vergleich zu einem klassischen Job ab?
- Welche Cluster, Jobs und Warehouses sind die größten Verbraucher von Cloud-verwalteten VMs?
- Wie ändern sich die Kostentrends, wenn Workloads skaliert, verschoben oder konsolidiert werden?
Die Beantwortung dieser Fragen erfordert die Zusammenführung von Finanzdaten der Cloud-Anbieter mit den Betriebsmetadaten von Databricks. Wie oben beschrieben, müssen Teams hierfür jedoch maßgeschneiderte Pipelines und eine detaillierte Wissensdatenbank zur Abrechnung von Cloud und Databricks pflegen.
Um diesen Bedarf zu decken, stellt Databricks die Cloud Infra Cost Field Solution vor – eine Open-Source-Lösung, die die Aufnahme und einheitliche Analyse von Cloud-Infrastruktur- und Databricks-Nutzungsdaten innerhalb der Databricks Platform automatisiert.
Durch die Bereitstellung einer einheitlichen Grundlage für die TCO-Analysen über serverlose und klassische Rechenumgebungen von Databricks hinweg hilft die Field Solution Unternehmen dabei, eine klarere Kostentransparenz zu erlangen und architektonische Kompromisse zu verstehen. Engineering-Teams können Cloud-Ausgaben und Rabatte nachverfolgen, während Finanzteams den Geschäftskontext und die Zuständigkeit der größten KostenDriver identifizieren können.
Im nächsten Abschnitt erklären wir, wie die Lösung funktioniert und wie Sie starten können.
Aufschlüsselung der technischen Lösung
Auch wenn die Komponenten unterschiedliche Namen haben, beruht die Cloud Infra Cost Field Solution für Azure- und AWS-Kunden auf denselben Prinzipien und kann in die folgenden Komponenten unterteilt werden:
- Kosten- und Nutzungsdaten in den Cloud-Speicher exportieren
- Erfassen und modellieren Sie Daten in Databricks mithilfe von Lakeflow Spark Declarative Pipelines
- Visualisieren Sie die gesamten Betriebskosten (TCO) (Kosten für Databricks und zugehörige Cloud-Anbieter) mit AI/BI-Dashboards.
Sowohl die Field Solutions von AWS als auch von Azure eignen sich hervorragend für Organisationen, die in einer einzigen Cloud arbeiten, können aber auch für Multi-Cloud-Kunden von Databricks mithilfe von Delta Sharing kombiniert werden.
Azure Databricks Field-Lösung
Die Cloud Infra Cost Field Solution für Azure Databricks besteht aus den folgenden Architekturkomponenten:
Azure Databricks-Lösungsarchitektur
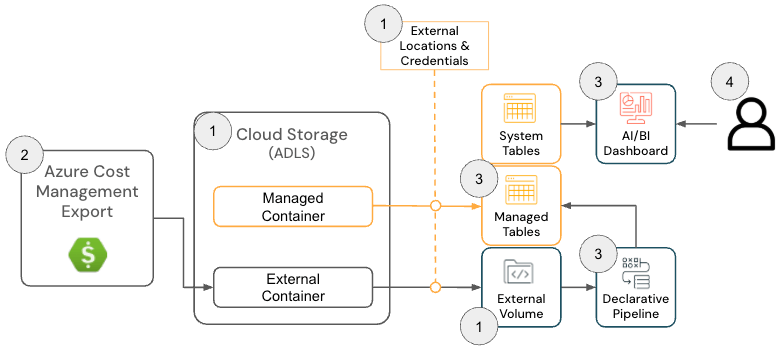
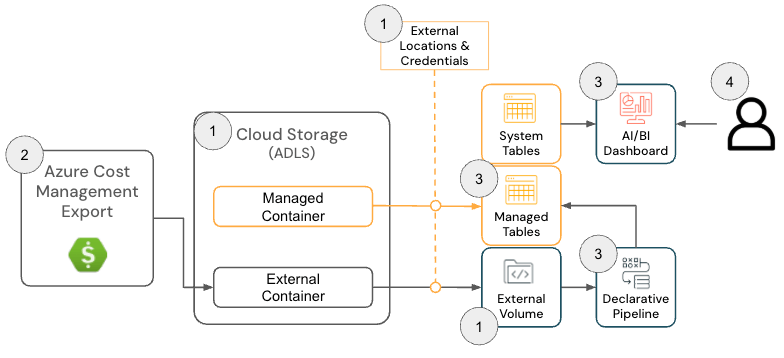{kind=link}
Für die Bereitstellung dieser Lösung müssen Administratoren über die folgenden Berechtigungen für Azure und Databricks verfügen:
- Azure
- Berechtigungen zum Erstellen eines Azure Cost Export
- Berechtigungen zum Erstellen der folgenden Ressourcen innerhalb einer Ressourcengruppe:
- Databricks
- Berechtigung zum Erstellen der folgenden Ressourcen:
- Speicherzugriffsrecht
- Externer Speicherort
- Berechtigung zum Erstellen der folgenden Ressourcen:
Das GitHub-Repository enthält ausführlichere Einrichtungsanweisungen. Die Lösung für Azure Databricks umfasst auf hoher Ebene jedoch die folgenden Schritte:
- [Terraform] Stellen Sie Terraform bereit, um abhängige Komponenten zu konfigurieren, darunter ein Storage Account, eine External Location und ein Volume.
- Der Zweck dieses Schrittes ist es, einen Speicherort zu konfigurieren, an den die Azure-Abrechnungsdaten exportiert werden, damit sie von Databricks gelesen werden können. Dieser Schritt ist optional, wenn bereits ein Volume vorhanden ist, da der Azure Cost Management Export-Speicherort im nächsten Schritt konfiguriert werden kann.
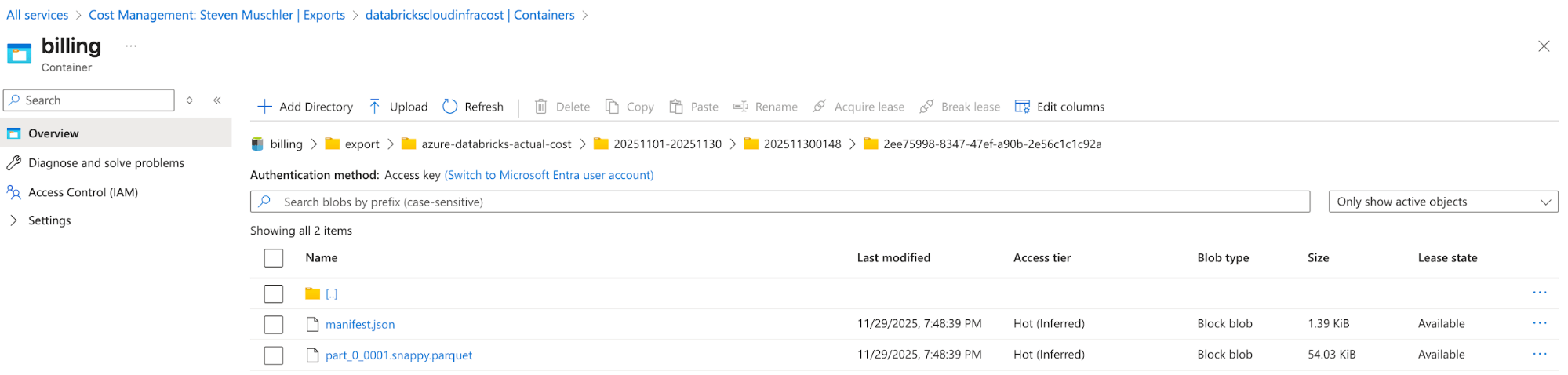
[Azure] Konfigurieren Sie den Azure Cost Management Export, um Azure-Abrechnungsdaten in das Speicher-Account zu exportieren, und bestätigen Sie, dass die Daten erfolgreich exportiert werden.
- Der Zweck dieses Schrittes ist es, die Exportfunktionalität von Azure Cost Management zu nutzen, um die Azure-Abrechnungsdaten in einem einfach zu verarbeitenden Format (z. B. Parquet) verfügbar zu machen.
Speicher-Account mit konfiguriertem Azure Cost Management-Export
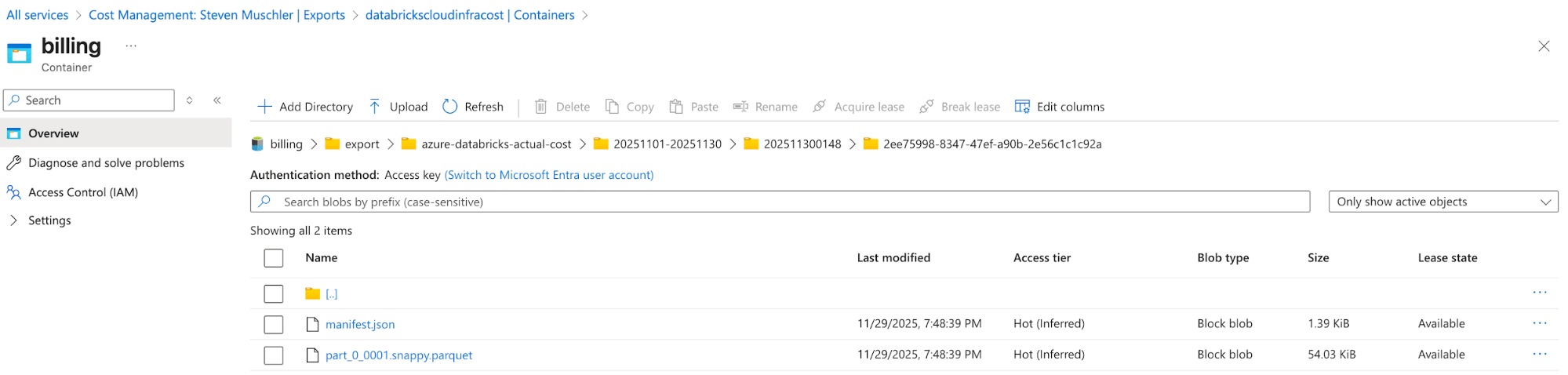
Azure Cost Management Export automatically delivers cost files to this location - [Databricks] Databricks Asset Bundle (DAB)-Konfiguration, um einen Lakeflow Job, eine deklarative Spark-Pipeline und ein AI/BI-Dashboard zu deployen
- Der Zweck dieses Schritts ist die Erfassung und Modellierung von Azure-Abrechnungsdaten zur Visualisierung mithilfe eines AI/BI dashboard.
- [Databricks] Daten im AI/BI-Dashboard und den Lakeflow Job validieren
- In diesem letzten Schritt entsteht der Mehrwert. Kunden verfügen jetzt über einen automatisierten Prozess, mit dem sie die TCO ihrer Lakehouse-Architektur einsehen können!
{kind=link}
AI/BI-Dashboard zur Anzeige der Azure Databricks-TCO
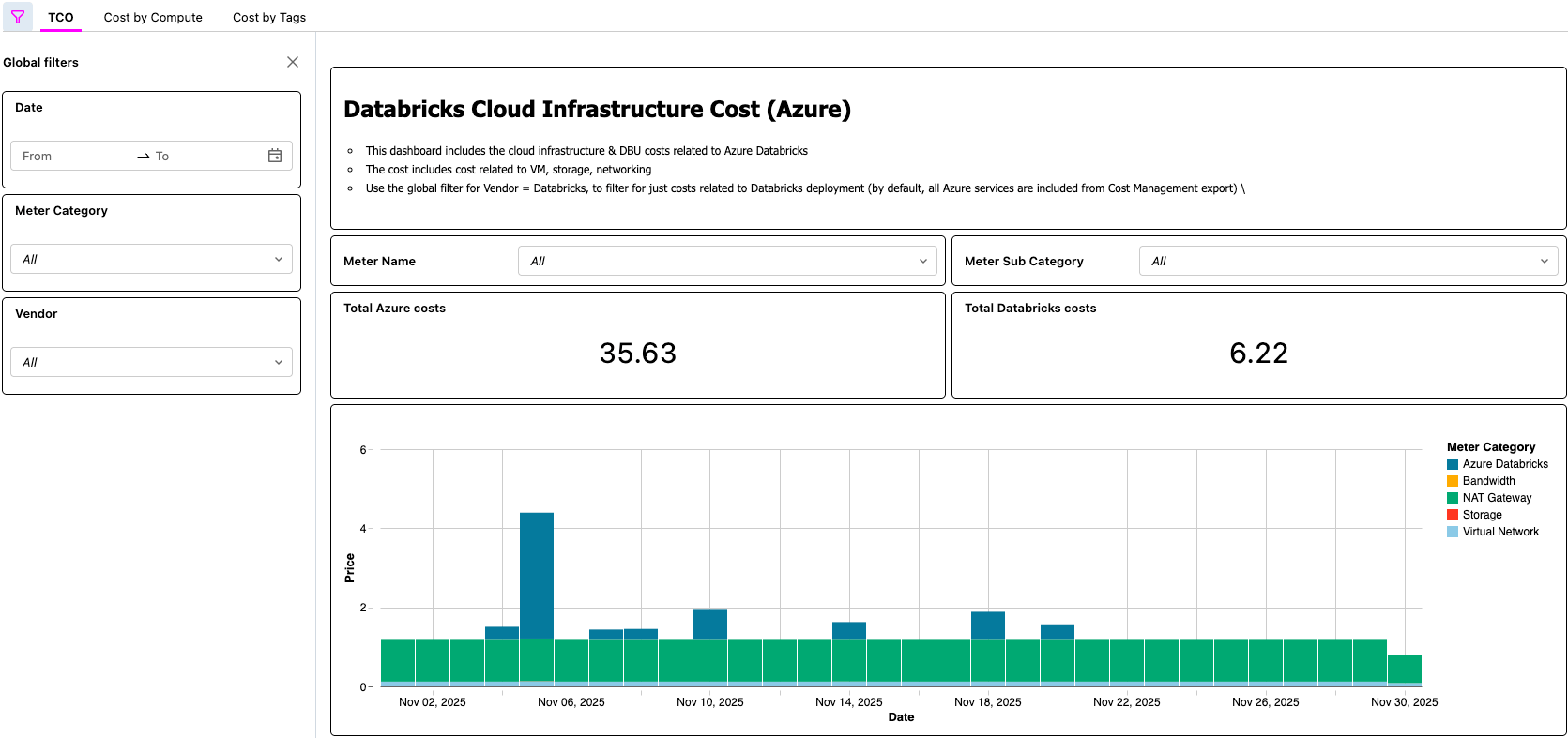
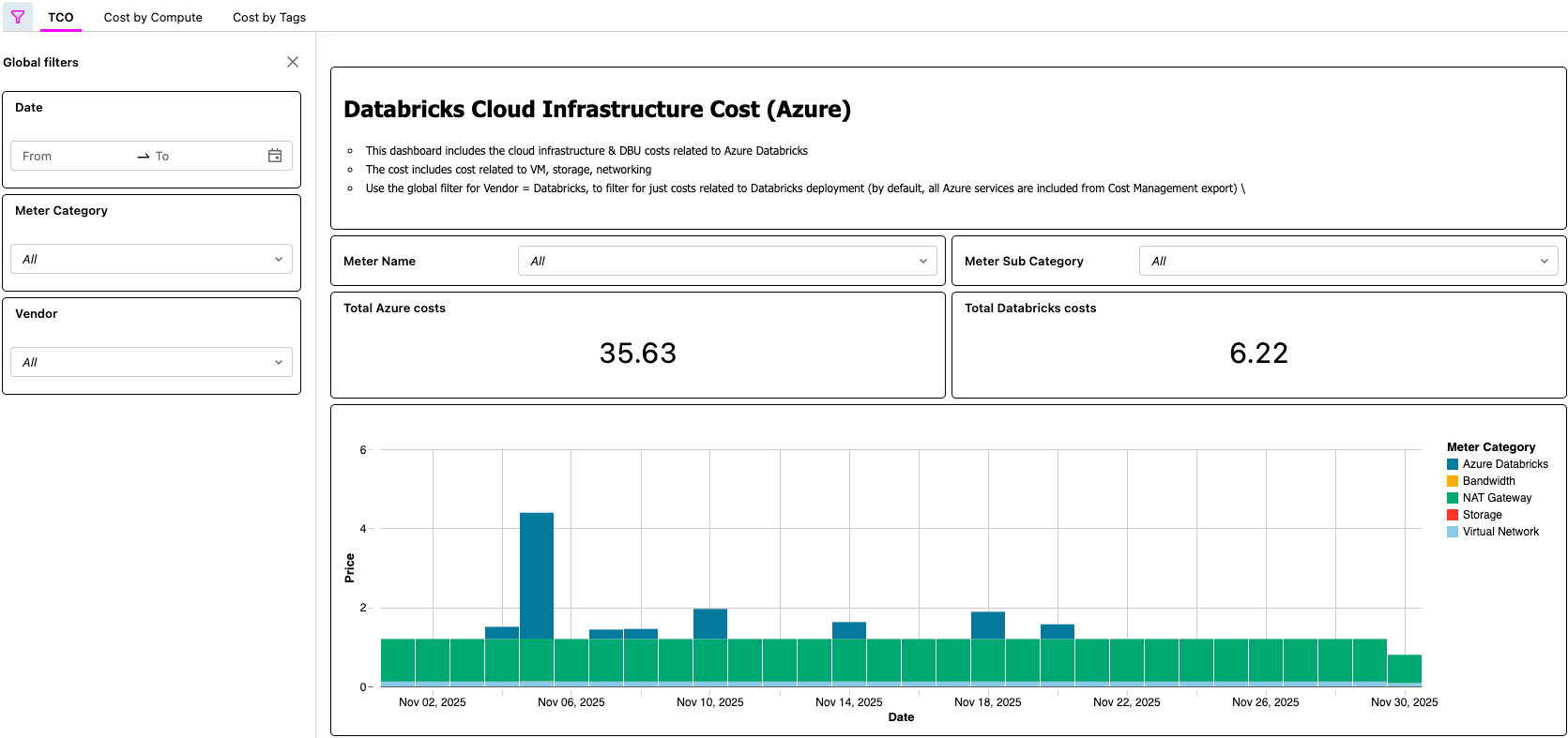{kind=link}
Databricks on AWS-Lösung
Die Lösung für Databricks auf AWS besteht aus mehreren Architekturkomponenten, die zusammenarbeiten, um Daten aus dem AWS Cost & Usage Report (CUR) 2.0 zu erfassen und sie mithilfe der Medallion-Architektur in Databricks zu persistieren.
Um diese Lösung bereitzustellen, müssen die folgenden Berechtigungen und Konfigurationen für AWS und Databricks vorhanden sein:
- AWS
- Berechtigungen zum Erstellen eines CUR
- Berechtigungen zum Erstellen eines Amazon S3 -Buckets (oder Berechtigungen zum Bereitstellen des CUR in einem vorhandenen Bucket)
- Hinweis: Die Lösung erfordert AWS CUR 2.0. Wenn Sie noch einen CUR 1.0-Export haben, beschreibt die AWS-Dokumentation die erforderlichen Schritte für ein Upgrade.
- Databricks
- Berechtigung zum Erstellen der folgenden Ressourcen:
- Speicherzugriffsrecht
- Externer Speicherort
- Berechtigung zum Erstellen der folgenden Ressourcen:
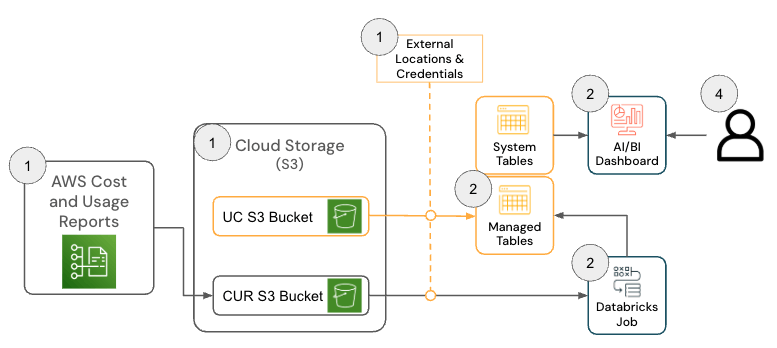
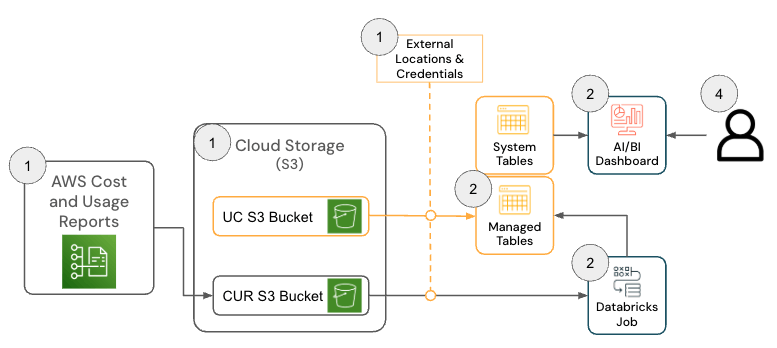{kind=link}
Das GitHub-Repository bietet detailliertere Einrichtungsanweisungen; auf allgemeiner Ebene umfasst die Lösung für AWS Databricks jedoch die folgenden Schritte.
- [AWS] AWS Cost & Usage Report (CUR) 2.0 einrichten
- Der Zweck dieses Schrittes ist es, die AWS-CUR-Funktionalität zu nutzen, damit die AWS-Abrechnungsdaten in einem einfach zu nutzenden Format verfügbar sind.
- [Databricks] Konfiguration des Databricks Asset Bundle (DAB)
- Der Zweck dieses Schrittes ist es, die AWS-Abrechnungsdaten zu erfassen und zu modellieren, damit sie mithilfe eines AI/BI-Dashboards visualisiert werden können.
- [Databricks] Dashboard überprüfen und Lakeflow-Job validieren
- In diesem letzten Schritt entsteht der Mehrwert. Kunden verfügen jetzt über einen automatisierten Prozess, der ihnen die TCO ihrer Lakehouse-Architektur zur Verfügung stellt!
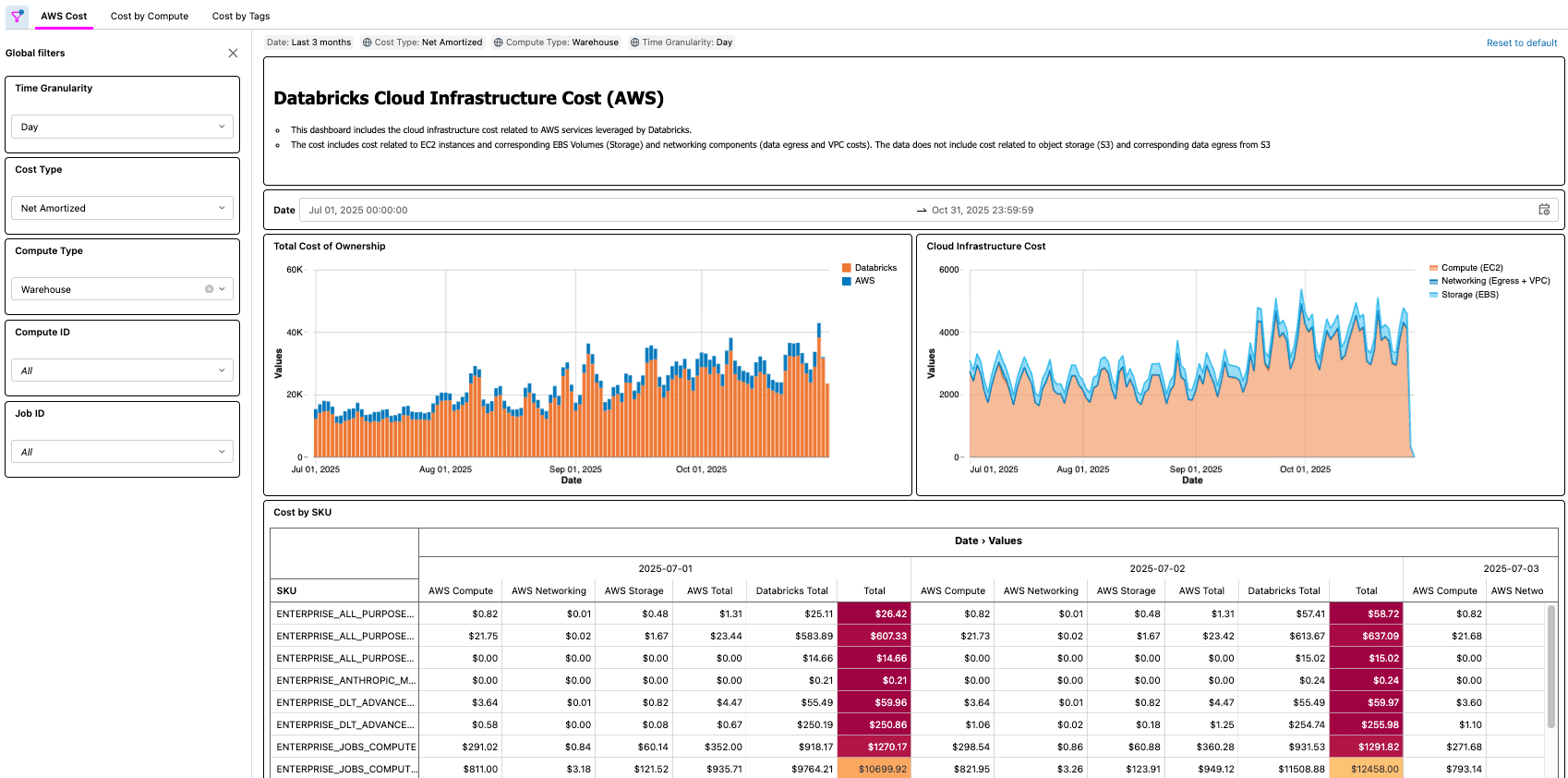
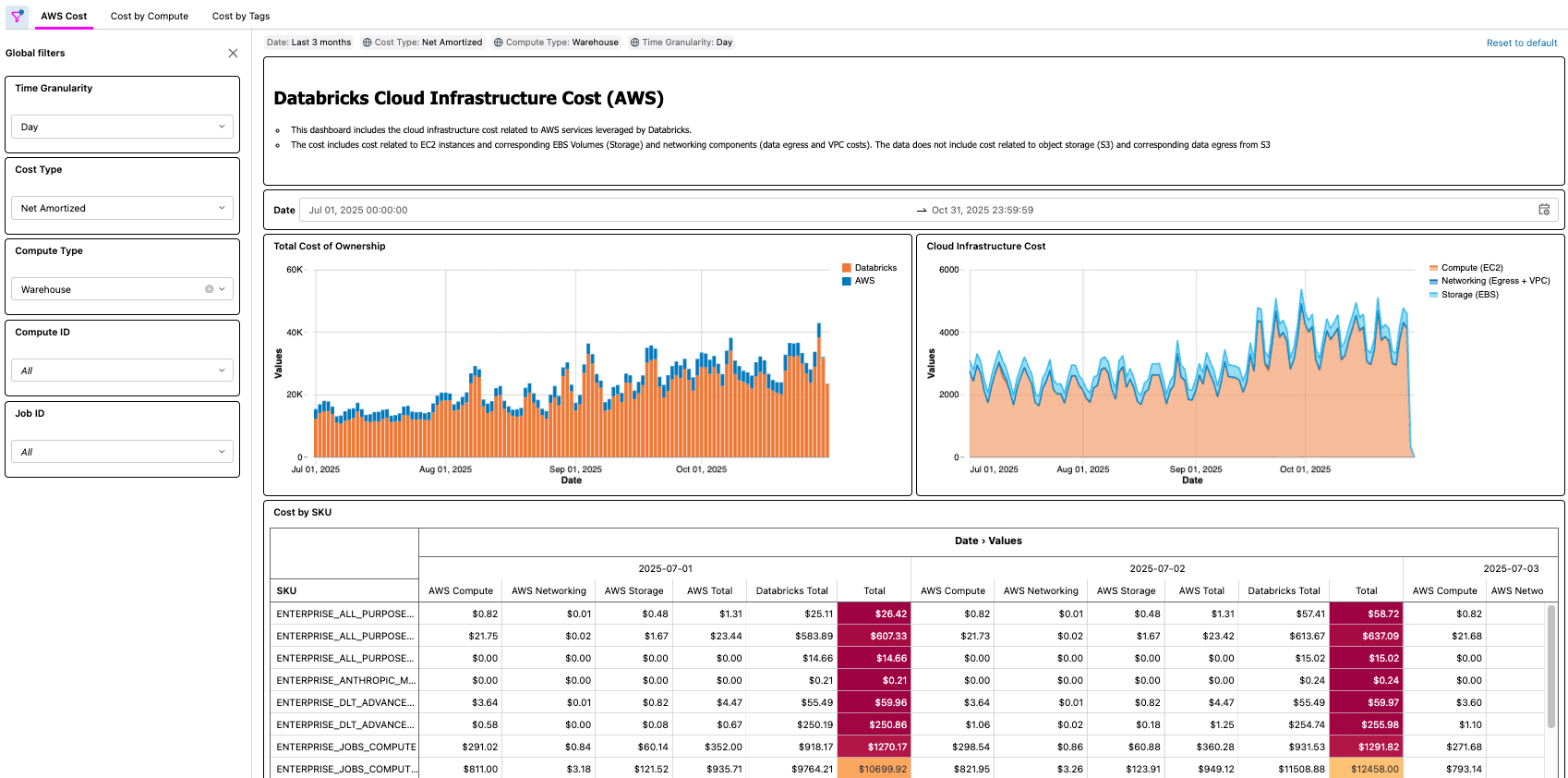{kind=link}
Praxisszenarien
Wie die Lösungen für Azure und AWS zeigen, gibt es viele Praxisbeispiele, die durch eine solche Lösung ermöglicht werden, wie zum Beispiel:
- Identifizieren und Berechnen der gesamten Kosteneinsparungen nach der Optimierung eines Jobs mit geringer CPU- und/oder Speicherauslastung
- Identifizierung von Workloads, die auf VM-Typen ohne Reservierung ausgeführt werden
- Identifizierung von Workloads mit ungewöhnlich hohen Kosten für Netzwerk und/oder lokalen Speicher
Als praktisches Beispiel könnte ein FinOps-Experte in einem großen Unternehmen mit Tausenden von Workloads die Task haben, einfache Optimierungsmöglichkeiten zu finden, indem er nach Workloads sucht, die einen bestimmten Betrag kosten, aber auch eine geringe CPU- und/oder Speicherauslastung aufweisen. Da die TCO-Informationen des Unternehmens jetzt über die Cloud Infra Cost Field Solution bereitgestellt werden, kann der Experte diese Daten dann mit der Node Timeline System Table (AWS, AZURE, GCP) join, um diese Informationen sichtbar zu machen und die Kosteneinsparungen nach Abschluss der Optimierungen genau zu quantifizieren. Die wichtigsten Fragen hängen von den Geschäftsanforderungen des jeweiligen Kunden ab. Zum Beispiel nutzt General Motors diese Art von Lösung, um viele der oben genannten Fragen und mehr zu beantworten und sicherzustellen, dass sie den maximalen Nutzen aus ihrer Lakehouse-Architektur ziehen.
Wichtigste Erkenntnisse
Nach der Implementierung der Cloud Infra Cost Field Solution erhalten Unternehmen eine einzige, vertrauenswürdige TCO-Ansicht, die Databricks und die zugehörigen Ausgaben für die Cloud-Infrastruktur kombiniert, wodurch die Notwendigkeit eines manuellen Kostenabgleichs über verschiedene Plattformen hinweg entfällt. Beispiele für Fragen, die Sie mithilfe der Lösung beantworten können:
- Wie teilen sich die Kosten für meine Databricks-Nutzung auf den Cloud-Anbieter und Databricks auf?
- Wie hoch sind die Gesamtkosten für die Ausführung einer Workload, einschließlich der Kosten für VM, lokalen Speicher und Netzwerk?
- Wie hoch ist der Unterschied bei den Gesamtkosten eines Workloads, wenn er auf Serverless im Vergleich zu Classic Compute ausgeführt wird?
Plattform- und FinOps-Teams können die vollständigen Kosten nach Workspace, Workload und Geschäftsbereich direkt in Databricks aufschlüsseln. Dies erleichtert es erheblich, die Nutzung mit Budgets, Verantwortlichkeitsmodellen und FinOps-Praktiken in Einklang zu bringen. Da alle zugrunde liegenden Daten als verwaltete Tabellen verfügbar sind, können Teams ihre eigenen Kostenanwendungen – Dashboards, interne Apps oder integrierte KI-Assistenten wie Databricks Genie– erstellen. Dies beschleunigt die Gewinnung von Erkenntnissen und verwandelt FinOps von einer regelmäßigen Berichtsaufgabe in eine ständig verfügbare, operative Fähigkeit.
Nächste Schritte & Ressourcen
Implementieren Sie die Cloud Infra Cost Field Solution noch heute von GitHub (Link hier, verfügbar für AWS und Azure) und erhalten Sie volle Transparenz über Ihre gesamten Databricks-Ausgaben. Mit dieser vollständigen Transparenz können Sie Ihre Databricks-Kosten optimieren, indem Sie auch Serverless für die automatisierte Infrastrukturverwaltung in Betracht ziehen.
Das Dashboard und die Pipeline, die als Teil dieser Lösung erstellt wurden, bieten eine schnelle und effektive Möglichkeit, mit der Analyse der Databricks-Ausgaben neben den übrigen Infrastrukturkosten zu beginnen. Allerdings verteilt und interpretiert jede Organisation die Kosten anders, sodass Sie die Modelle und Transformationen weiter an Ihre Bedürfnisse anpassen können. Gängige Erweiterungen umfassen das Verknüpfen von Infrastrukturkostendaten mit zusätzlichen Databricks-Systemtabellen (AWS | AZURE | GCP) zur Verbesserung der Zuordnungsgenauigkeit, das Erstellen von Logik zur Trennung oder Neuverteilung gemeinsamer VM-Kosten bei der Verwendung von Instanzpools, die unterschiedliche Modellierung von VM-Reservierungen oder die Einbeziehung historischer Backfills zur Unterstützung langfristiger Kostentrends. Wie bei jedem Kostenmodell eines Hyperscalers gibt es erheblichen Spielraum, die Pipelines über die Standardimplementierung hinaus anzupassen, um sie auf internes Reporting, Tagging-Strategien und FinOps-Anforderungen abzustimmen.
Die Delivery Solutions Architects (DSAs) von Databricks beschleunigen Daten- und KI-Initiativen in Unternehmen. Sie übernehmen die architektonische Leitung, optimieren Plattformen im Hinblick auf Kosten und Performance, verbessern die Entwicklererfahrung und sorgen für eine erfolgreiche Projektdurchführung. DSAs überbrücken die Lücke zwischen der Erstimplementierung und produktionsreifen Lösungen und arbeiten dabei eng mit verschiedenen Teams zusammen, darunter Data Engineering, technische Leiter, Führungskräfte und andere Stakeholder, um maßgeschneiderte Lösungen und eine schnellere Wertschöpfung zu gewährleisten. Um von einem maßgeschneiderten Ausführungsplan, strategischer Beratung und Unterstützung durch einen DSA während Ihrer gesamten Daten- und KI-Journey zu profitieren, wenden Sie sich bitte an Ihr Databricks Account Team.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.