Wie man produktionsreife Genie-Spaces erstellt und dabei Vertrauen aufbaut
Eine Reise vom Aufbau eines Genie-Space von Grund auf bis zur Produktionsreife, bei der die Genauigkeit durch Benchmark-Bewertung und systematische Optimierung verbessert wird
von Pulkit Pareek und Eric Lind
- Nutzen Sie Benchmarks, um die Einsatzbereitschaft Ihres Genie-Space objektiv statt subjektiv zu messen.
- Folgen Sie einem End-to-End-Beispiel für die Entwicklung eines produktionsreifen Genie-Space, das viele gängige Szenarien zur Fehlerbehebung abdeckt.
- Bauen Sie Vertrauen bei den Endbenutzern auf, indem Sie die endgültigen Genauigkeitsergebnisse zu Fragen teilen, die sie korrekt beantwortet haben müssen.
Die Vertrauensherausforderung in Self-Service Analytics
Genie ist ein Databricks-Feature, das es Geschäftsteams ermöglicht, in natürlicher Sprache mit ihren Daten zu interagieren. Es nutzt generative KI, die auf die Terminologie und die Daten Ihres Unternehmens zugeschnitten ist, und bietet die Möglichkeit, die Performance durch Benutzerfeedback zu überwachen und zu verbessern.
Eine häufige Herausforderung bei jedem Tool für die natürliche Sprach-Analytics ist es, das Vertrauen der Endbenutzer aufzubauen. Nehmen wir zum Beispiel Sarah, eine Marketing-Expertin, die Genie zum ersten Mal anstelle ihrer Dashboards ausprobiert.
Sarah: „Wie hoch war unsere Klickrate im letzten Quartal?“
Genie: 8,5 %
Sarahs Gedanke: Moment mal, ich erinnere mich, dass wir gefeiert haben, als wir letztes Quartal 6 % erreicht haben ...
Dies ist eine Frage, auf die Sarah die Antwort weiß, aber nicht das richtige Ergebnis angezeigt bekommt. Vielleicht umfasste die generierte Abfrage andere Kampagnen oder es wurde eine Standardkalenderdefinition für „letztes Quartal“ verwendet, obwohl der Geschäftskalender des Unternehmens hätte verwendet werden müssen. Aber Sarah weiß nicht, was das Problem ist. Der Moment der Unsicherheit hat Zweifel hervorgerufen. Ohne eine angemessene Bewertung der Antworten kann dieser Zweifel an der Benutzerfreundlichkeit zunehmen. Benutzer wenden sich wieder an den Analystensupport, was andere Projekte stört und die Kosten und die Time-to-Value für die Generierung einer einzelnen Erkenntnis erhöht. Die Self-Dienst-Investition bleibt ungenutzt.
Die Frage ist nicht nur, ob Ihr Genie-Space SQL generieren kann. Es geht darum, ob Ihre Nutzer den Ergebnissen genug vertrauen, um damit Entscheidungen zu treffen.
Um dieses Vertrauen aufzubauen, muss man von einer subjektiven Bewertung („es scheint zu funktionieren“) zu einer messbaren Validierung („wir haben es systematisch getestet“) übergehen. Wir werden zeigen, wie die integrierte Genie-Feature eine Basiskonfiguration in ein produktionsreifes System umwandelt, auf das sich Benutzer bei kritischen Entscheidungen verlassen. Benchmarks bieten eine datengesteuerte Methode, um die Qualität Ihres Genie-Space zu bewerten und helfen Ihnen, Lücken bei der Kuratierung des Genie-Space zu schließen.
In diesem Blog führen wir Sie durch ein durchgängiges Beispiel für die Erstellung eines Genie-Space mit Benchmarks, um ein vertrauenswürdiges System zu entwickeln.
Die Daten: Analyse von Marketingkampagnen
Unser Marketingteam muss die Kampagnen-Performance über vier miteinander verbundene Datasets hinweg analysieren.
- Interessenten – Unternehmensinformationen, einschließlich Branche und Standort
- Kontakte – Empfängerinformationen, einschließlich Abteilung und Gerätetyp
- Kampagnen – Kampagnendetails, einschließlich Budget, template und Daten
- Ereignisse – Nachverfolgung von E-Mail-Ereignissen (Versendungen, Öffnungen, Klicks, Spam-Meldungen)
Der Workflow: Zielunternehmen (potenzielle Kunden) identifizieren → Kontakte bei diesen Unternehmen finden → Marketingkampagnen versenden → nachverfolgen, wie die Empfänger auf diese Kampagnen reagieren (Ereignisse).
Einige Beispielfragen, die Benutzer beantworten mussten, sind:
- "Welche Kampagnen lieferten den besten ROI nach Branche?"
- "Wie hoch ist unser Compliance-Risiko bei verschiedenen Kampagnentypen?"
- "Wie unterscheiden sich die Engagement-Muster (CTR) je nach Gerät und Abteilung?"
- „Welche Templates erzielen bei bestimmten Interessentensegmenten die beste Leistung?“
Diese Fragen erfordern das Verknüpfen von Tabellen, die Berechnung domänenspezifischer Metriken und die Anwendung von Domänenwissen darüber, was eine Kampagne „erfolgreich“ oder „risikoreich“ macht. Die richtigen Antworten auf diese Fragen sind wichtig, da sie direkten Einfluss auf die Budgetzuweisung, die Kampagnenstrategie und Compliance-Entscheidungen haben. Legen wir los!
Der Weg: Entwicklung von der Baseline zur Produktion
Es ist nicht zu erwarten, dass das anekdotische Hinzufügen von Tabellen und einer Handvoll Text-Prompts einen ausreichend genauen Genie-Space für Endbenutzer ergibt. Ein gründliches Verständnis der Bedürfnisse Ihrer Endbenutzer, kombiniert mit Kenntnissen der Datensätze und der Funktionen der Databricks-Plattform, führt zu den gewünschten Ergebnissen.
In diesem End-to-End-Beispiel bewerten wir die Genauigkeit unseres Genie space anhand von Benchmarks, diagnostizieren Kontextlücken, die zu falschen Antworten führen, und implementieren Korrekturen. Betrachten Sie dieses Framework als Ansatz für Ihre Genie-Entwicklung und -Auswertungen.
- Definieren Sie Ihre Benchmark-Suite (streben Sie 10–20 repräsentative Fragen an). Diese Fragen sollten von Fachexperten und den tatsächlichen Endbenutzern bestimmt werden, von denen erwartet wird, dass sie Genie für Analytics nutzen. Idealerweise werden diese Fragen vor der eigentlichen Entwicklung Ihres Genie-Bereichs erstellt.
- Legen Sie Ihre Baseline-Genauigkeit fest. Führen Sie alle Benchmark-Fragen in Ihrem Space aus, wobei nur die Baseline-Datenobjekte zum Genie-Space hinzugefügt werden. Dokumentieren Sie die Genauigkeit und welche Fragen erfolgreich sind, welche fehlschlagen und warum.
- Systematisch optimieren. Implementieren Sie eine Reihe von Änderungen (z. B. Hinzufügen von Spaltenbeschreibungen). Führen Sie alle Benchmark-Fragen erneut aus. Messen Sie die Auswirkungen und Verbesserungen und setzen Sie die iterative Entwicklung gemäß den veröffentlichten Best Practices fort.
- Messen und kommunizieren. Die Durchführung der Benchmarks liefert objektive Bewertungskriterien dafür, dass der Genie-Space die Erwartungen ausreichend erfüllt, was das Vertrauen bei Benutzern und Stakeholdern aufbaut.
Wir haben eine Suite von 13 Benchmark-Fragen erstellt, die repräsentieren, auf welche Fragen Endbenutzer in unseren Marketingdaten nach Antworten suchen. Jede Benchmark-Frage ist eine realistische Frage in einfachem Englisch, gekoppelt mit einer validierten SQL-Query, die diese Frage beantwortet.
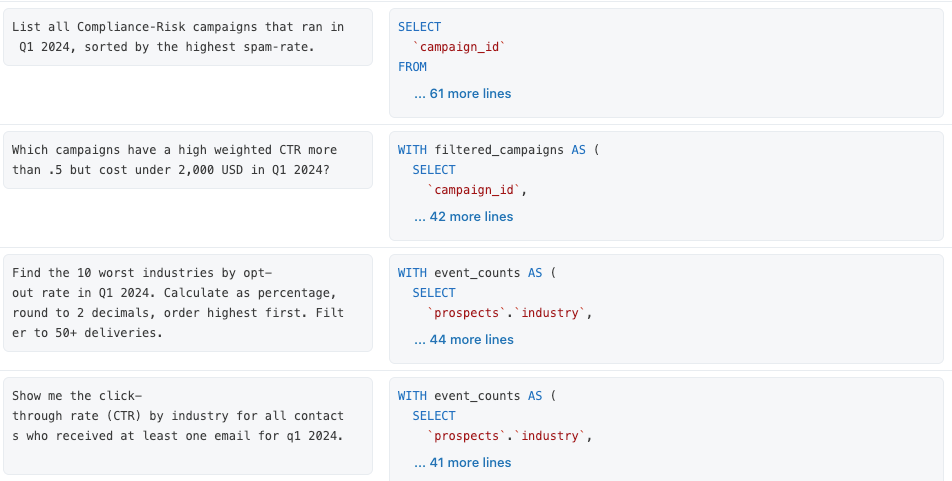
Genie schließt diese Benchmark-SQL-Abfragen absichtlich nicht als bestehenden Kontext ein. Sie werden ausschließlich zur Auswertung verwendet. Es ist unser Job, den richtigen Kontext bereitzustellen, damit diese Fragen korrekt beantwortet werden können. Legen wir los!
Iteration 0: Festlegen der Baseline
Wir haben absichtlich mit schlechten Tabellennamen wie cmp und proc_delta und Spaltennamen wie uid_seq (für campaign_id), label_txt (für campaign_name), num_val (für cost) und proc_ts (für event_date) begonnen. Dieser Ausgangspunkt spiegelt wider, womit viele Organisationen tatsächlich konfrontiert sind – Daten, die eher nach technischen Konventionen als nach geschäftlicher Bedeutung modelliert sind.
Tabellen allein bieten auch keinen Kontext dafür, wie domänenspezifische KPIs und Metriken berechnet werden. Genie weiß, wie Hunderte von integrierten SQL-Funktionen genutzt werden können, benötigt aber immer noch die richtigen Spalten und die richtige Logik, um sie als Eingaben zu verwenden. Was passiert also, wenn Genie nicht genügend Kontext hat?
Benchmark-Analyse: Genie konnte keine unserer 13 Benchmark-Fragen korrekt beantworten. Nicht, weil die KI nicht leistungsstark genug war, sondern weil ihr jeglicher relevanter Kontext fehlte, wie unten gezeigt.

Einblick: Jede Frage, die Endbenutzer stellen, hängt davon ab, dass Genie aus den von Ihnen bereitgestellten Datenobjekten eine SQL-Abfrage erstellt. Schlechte Benennungskonventionen für Daten wirken sich daher auf jede einzelne dieser generierten Abfragen aus. Sie können die grundlegende Datenqualität nicht überspringen und erwarten, Vertrauen bei den Endbenutzern aufzubauen! Genie generiert nicht für jede Frage eine SQL-Abfrage. Dies geschieht nur, wenn genügend Kontext vorhanden ist. Dies ist ein erwartetes Verhalten, um Halluzinationen und irreführende Antworten zu vermeiden.
Nächste Aktion: Niedrige anfängliche Benchmark-Ergebnisse deuten darauf hin, dass Sie sich zunächst auf die Bereinigung von Unity Catalog-Objekten konzentrieren sollten, also beginnen wir dort.
Iteration 1: Mehrdeutige Spaltenbedeutungen
Wir haben die Tabellennamen in campaigns, events, contacts und prospects verbessert und klare Tabellenbeschreibungen in Unity Catalog hinzugefügt.

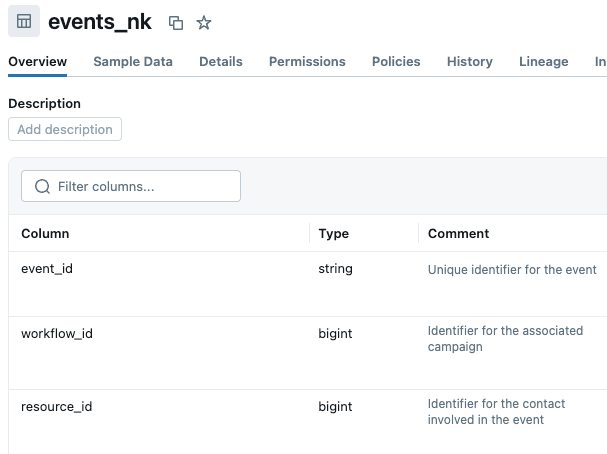
Wir stießen jedoch auf eine weitere damit zusammenhängende Herausforderung: irreführende Spaltennamen oder Kommentare, die nicht existierende Beziehungen andeuten.
Zum Beispiel existieren Spalten wie workflow_id, resource_id und owner_id in mehreren Tabellen. Es klingt so, als ob diese Tabellen miteinander verbinden sollten, aber das tun sie nicht. Die Tabelle events verwendet workflow_id als Fremdschlüssel für Kampagnen (nicht für eine separate Workflow-Tabelle) und resource_id als Fremdschlüssel für Kontakte (nicht für eine separate Ressourcen-Tabelle). In der Zwischenzeit hat campaigns eine eigene workflow_id -Spalte, die in keinerlei Zusammenhang steht. Wenn diese Spaltennamen und Beschreibungen nicht entsprechend gekennzeichnet sind, kann dies zu einer ungenauen Verwendung dieser Attribute führen. Wir haben die Spaltenbeschreibungen im Unity Catalog aktualisiert, um den Zweck jeder dieser mehrdeutigen Spalten zu verdeutlichen. Hinweis: Wenn Sie Metadaten im UC nicht bearbeiten können, können Sie Tabellen- und Spaltenbeschreibungen in der Wissensdatenbank des Genie-Bereichs hinzufügen.
Benchmark-Analyse: Einfache Abfragen einzelner Tabellen funktionierten dank eindeutiger Namen und Beschreibungen. Fragen wie „Anzahl der Ereignisse nach Typ im Jahr 2023“ und „Welche Kampagnen wurden in den letzten drei Monaten gestartet?“ erhielten jetzt korrekte Antworten. Allerdings schlug jede Abfrage, die Joins über Tabellen hinweg erforderte, fehl – Genie konnte immer noch nicht korrekt bestimmen, welche Spalten Beziehungen darstellten.
Erkenntnis: Klare Namenskonventionen helfen, aber ohne explizite Beziehungsdefinitionen muss Genie raten, welche Spalten Tabellen miteinander verbinden. Wenn mehrere Spalten Namen wie workflow_id oder resource_id haben, können diese Vermutungen zu ungenauen Ergebnissen führen. Ordnungsgemäße Metadaten dienen als Grundlage, aber Beziehungen sollten explizit definiert werden.
Nächste Aktion: Definieren Sie Join-Beziehungen zwischen Ihren Datenobjekten. Spaltennamen wie id oder resource_id kommen ständig vor. Lassen Sie uns klären, welche dieser Spalten auf andere Tabellenobjekte verweisen.
Iteration 2: Mehrdeutiges Datenmodell
Der beste Weg, um zu verdeutlichen, welche Spalten Genie beim Verbinden von Tabellen verwenden sollte, ist die Verwendung von Primär- und Fremdschlüsseln. Wir haben in Unity Catalog Primär- und Fremdschlüsseleinschränkungen hinzugefügt und teilen Genie so explizit mit, wie Tabellen verbunden werden: campaigns.campaign_id bezieht sich auf events.campaign_id, das mit contacts.contact_id verknüpft ist, das mit prospects.prospect_id verbunden ist. Dadurch entfällt das Rätselraten und es wird standardmäßig vorgegeben, wie Joins über mehrere Tabellen erstellt werden. Hinweis: Wenn Sie Beziehungen in UC nicht bearbeiten können oder die Tabellenbeziehung komplex ist (z. B. mehrere JOIN-Bedingungen), können Sie diese im Wissensspeicher des Genie-Space definieren.
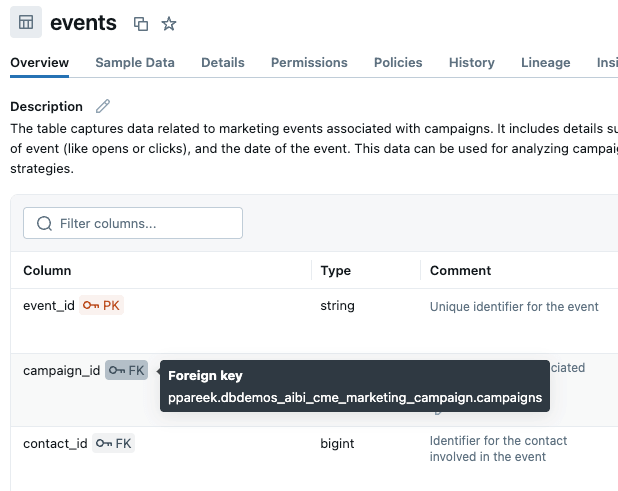
Alternativ könnten wir die Erstellung einer Metrikansicht in Betracht ziehen, die Join-Details explizit in der Objektdefinition enthalten kann. Mehr dazu später.
Benchmark-Analyse: Stetiger Fortschritt. Fragen, die Joins über mehrere Tabellen erforderten, funktionierten jetzt: „Zeige Kampagnenkosten nach Branche für Q1 2024“ und „Welche Kampagnen hatten im Januar mehr als 1.000 Ereignisse?“ wurden nun erfolgreich ausgeführt.
Erkenntnis: Beziehungen ermöglichen die komplexen Abfragen über mehrere Tabellen, die einen echten Geschäftswert liefern. Genie generiert korrekt strukturiertes SQL und führt einfache Dinge wie Kostensummierungen und Ereigniszählungen korrekt aus.
Aktion: Von den verbleibenden fehlerhaften Benchmarks enthalten viele Verweise auf Werte, die Benutzer als Datenfilter nutzen möchten. Die Art und Weise, wie Endbenutzer Fragen stellen, stimmt nicht direkt mit den Werten im Dataset überein.
Iteration 3: Verständnis der Datenwerte
Ein Genie-Space sollte so kuratiert werden, dass er domänenspezifische Fragen beantwortet. Allerdings verwenden Menschen nicht immer genau dieselbe Terminologie, wie sie in unseren Daten vorkommt. Benutzer sagen vielleicht „Bioengineering-Unternehmen“, aber der Datenwert lautet „Biotechnologie“.
Die Aktivierung von Wertewörterbüchern und Data Sampling ermöglicht eine schnellere und genauere Suche nach den Werten, so wie sie in den Daten vorhanden sind, anstatt dass Genie nur den exakten Wert verwendet, der vom Endbenutzer eingegeben wurde.

Beispielwerte und Werteverzeichnisse sind jetzt standardmäßig aktiviert, aber es lohnt sich, noch einmal zu überprüfen, ob die richtigen, häufig zum Filtern verwendeten Spalten aktiviert sind und bei Bedarf benutzerdefinierte Werteverzeichnisse haben.
Benchmark-Analyse: Über 50 % der Benchmark-Fragen werden jetzt erfolgreich beantwortet. Fragen, die bestimmte Kategoriewerte wie „Biotechnologie“ enthielten, begannen, diese Filter korrekt zu identifizieren. Die Herausforderung besteht nun darin, benutzerdefinierte Metriken und Aggregationen zu implementieren. Zum Beispiel liefert Genie eine bestmögliche Schätzung, wie die CTR zu berechnen ist, basierend auf dem Fund von „click“ als Datenwert und seinem Verständnis von ratenbasierten Metriken. Aber es ist nicht sicher genug, um die Abfragen einfach zu generieren:
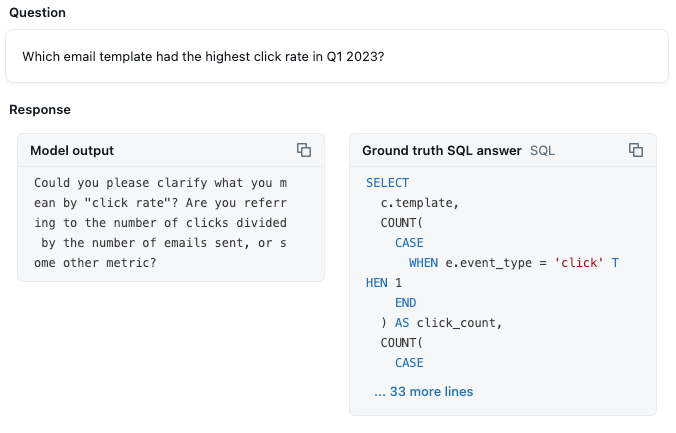
Dies ist eine Metrik, die zu 100 % der Zeit korrekt berechnet werden soll. Daher müssen wir dieses Detail für Genie klären.
Erkenntnis: Value Sampling verbessert die SQL-Generierung von Genie, indem es Zugriff auf reale Datenwerte bietet. Wenn Benutzer Konversationsfragen mit Tippfehlern oder abweichender Terminologie stellen, hilft Value Sampling Genie, die Eingabeaufforderungen den tatsächlichen Datenwerten in Ihren Tabellen zuzuordnen.
Nächste Aktion: Das häufigste Problem ist jetzt, dass Genie immer noch nicht das korrekte SQL für unsere benutzerdefinierten Metriken generiert. Lassen Sie uns unsere Metrikdefinitionen explizit angehen, um genauere Ergebnisse zu erzielen.
Iteration 4: Definieren von benutzerdefinierten Metriken
An diesem Punkt hat Genie Kontext für kategoriale Datenattribute, die in den Daten vorhanden sind, kann nach unseren Datenwerten filtern und einfache Aggregationen aus Standard-SQL-Funktionen durchführen (z. B. „Anzahl der Ereignisse nach Typ“ verwendet COUNT()). Um mehr Klarheit darüber zu schaffen, wie Genie unsere Metriken berechnen soll, haben wir Beispiel-SQL-Abfragen zu unserem genie space hinzugefügt. Dieses Beispiel demonstriert die korrekte Metrikdefinition für CTR:
Hinweis: Es wird empfohlen, Kommentare in Ihren SQL-Queries zu belassen, da dies zusammen mit dem Code ein relevanter Kontext ist.
Benchmark-Analyse: Dies führte zur bisher größten einzelnen Genauigkeitsverbesserung. Bedenken Sie, dass unser Ziel darin besteht, Genie in die Lage zu versetzen, Fragen für eine definierte Zielgruppe auf einer sehr detaillierten Ebene zu beantworten. Es wird erwartet, dass ein Großteil der Fragen von Endbenutzern auf benutzerdefinierten Metriken wie CTR, Spam-Raten, Engagement-Metriken usw. beruhen wird. Noch wichtiger ist, dass auch Variationen dieser Fragen funktionierten. Genie hat die Definition für unsere Metrik gelernt und wird sie zukünftig auf jede Abfrage anwenden.
Einblick: Beispielabfragen vermitteln Geschäftslogik, die Metadaten allein nicht vermitteln können. Eine gut formulierte Beispielabfrage löst oft eine ganze Kategorie von Benchmark-Lücken auf einmal. Dies brachte mehr Wert als jeder andere einzelne Iterationsschritt bisher.
Nächste Aktion: Nur noch wenige Benchmark-Fragen sind falsch. Bei näherer Betrachtung stellen wir fest, dass die verbleibenden Benchmarks aus zwei Gründen fehlschlagen:
- Benutzer stellen Fragen zu Datenattributen, die nicht direkt in den Daten vorhanden sind. Zum Beispiel: „Wie viele Kampagnen haben im letzten Quartal eine hohe CTR erzielt?“ Genie weiß nicht, was ein Benutzer mit einer „hohen“ CTR meint, da kein entsprechendes Datenattribut vorhanden ist.
- Diese Datentabellen enthalten Datensätze, die wir ausschließen sollten. Zum Beispiel haben wir viele Testkampagnen, die nicht an Kunden gerichtet sind. Wir müssen diese aus unseren KPIs ausschließen.
Iteration 5: Dokumentation domänenspezifischer Regeln
Diese verbleibenden Lücken sind Kontextelemente, die global dafür gelten, wie alle unsere Abfragen erstellt werden sollen, und beziehen sich auf Werte, die nicht direkt in unseren Daten vorhanden sind.
Nehmen wir das erste Beispiel zur hohen CTR oder etwas Ähnliches wie kostenintensive Kampagnen. Es ist aus mehreren Gründen nicht immer einfach oder sogar empfehlenswert, domänenspezifische Daten zu unseren Tabellen hinzuzufügen:
- Änderungen wie das Hinzufügen eines Feldes
campaign_cost_segmentation(hoch, mittel, niedrig) zu Datentabellen werden Zeit in Anspruch nehmen und andere Prozesse beeinflussen, da Tabellenschemata und Datenpipelines alle geändert werden müssen. - Bei aggregierten Berechnungen wie der CTR ändern sich die CTR-Werte, wenn neue Daten einfließen. Wir sollten diese Berechnung sowieso nicht vorausberechnen; wir möchten, dass diese Berechnung on-the-fly durchgeführt wird, während wir Filter wie Zeiträume und Kampagnen klären.
Wir können also eine textbasierte Anweisung in Genie verwenden, um diese domänenspezifische Segmentierung für uns durchzuführen.

Ebenso können wir festlegen, wie Genie Abfragen immer schreiben sollte, um sie an die Geschäfts-Expectations anzupassen. Dazu können Dinge wie benutzerdefinierte Kalender, obligatorische globale Filter usw. gehören. Diese Kampagnendaten enthalten beispielsweise Testkampagnen, die von unseren KPI-Berechnungen ausgeschlossen werden sollten.


Benchmark-Analyse: 100 % Benchmark-Genauigkeit! Edge Cases und schwellenwertbasierte Fragen funktionierten durchgehend. Fragen zu „leistungsstarken Kampagnen“ oder „Kampagnen mit Compliance-Risiko“ wendeten nun unsere Geschäftsdefinitionen korrekt an.
Einblick: Textbasierte Anweisungen sind eine einfache und effektive Möglichkeit, verbleibende Lücken aus früheren Schritten zu schließen, um sicherzustellen, dass die richtigen Abfragen für Endbenutzer generiert werden. Es sollte jedoch nicht die erste oder einzige Stelle sein, auf die Sie sich für die Kontexteingabe verlassen.
Beachten Sie, dass es in einigen Fällen möglicherweise nicht möglich ist, eine 100-prozentige Genauigkeit zu erreichen. Zum Beispiel erfordern Benchmark-Fragen manchmal sehr komplexe Abfragen oder mehrere Prompts, um die richtige Antwort zu generieren. Wenn Sie nicht einfach eine einzelne Beispiel-SQL-Abfrage erstellen können, weisen Sie einfach auf diese Lücke hin, wenn Sie die Ergebnisse Ihrer Benchmark-Evaluierung mit anderen teilen. Die typische Erwartung ist, dass die Genie-Benchmarks über 80 % liegen sollten, bevor zu den Benutzerakzeptanztests (UAT) übergegangen wird.
Nächste Aktion: Nachdem Genie bei unseren Benchmark-Fragen das erwartete Genauigkeitsniveau erreicht hat, werden wir zum UAT übergehen und weiteres Feedback von den Endbenutzern einholen!
(Optional) Iteration 6: Vorkalkulation komplexer Metriken
Für unsere letzte Iteration haben wir eine benutzerdefinierte Ansicht erstellt, die wichtige Marketingmetriken vordefiniert und Geschäftsklassifizierungen anwendet. Das Erstellen einer Ansicht oder einer Metrikansicht kann in Fällen einfacher sein, in denen Ihre Datasets alle in ein einziges Datenmodell passen und Sie Dutzende von benutzerdefinierten Metriken haben. Es ist einfacher, all diese in eine Datenobjektdefinition zu integrieren, anstatt für jede einzelne eine beispielhafte SQL Query zu schreiben, die spezifisch für den Genie space ist.
Benchmark-Ergebnis: Wir haben immer noch eine 100%ige Benchmark-Genauigkeit erreicht, indem wir Ansichten anstelle von reinen Basistabellen genutzt haben, da der Metadateninhalt derselbe blieb.
Einblick: Anstatt komplexe Berechnungen durch Beispiele oder Anweisungen zu erklären, können Sie sie in einer Ansicht oder Metrikansicht kapseln und so eine einzige Quelle der Wahrheit definieren.
Was wir gelernt haben: Der Einfluss der Benchmark-gesteuerten Entwicklung
Es gibt keine „Patentlösung“ bei der Konfiguration eines Genie-Space, die alles löst. Produktionsreife Genauigkeit wird normalerweise nur erreicht, wenn Sie über hochwertige Daten, angemessen angereicherte Metadaten, eine definierte Metrikenlogik und in den Space injizierten domänenspezifischen Kontext verfügen. In unserem End-to-End-Beispiel sind wir auf häufige Probleme gestoßen, die all diese Bereiche umfassten.
Benchmarks sind entscheidend, um zu bewerten, ob Ihr Space die Erwartungen erfüllt und für Benutzerfeedback bereit ist. Es leitete auch unsere Entwicklungsanstrengungen, um Lücken in der Interpretation von Fragen durch Genie zu schließen. Im Überblick:
- Iterationen 1–3 – 54 % Benchmark-Genauigkeit. Diese Iterationen konzentrierten sich darauf, Genie unsere Daten und Metadaten klarer bewusst zu machen. Die Implementierung geeigneter Tabellennamen, Tabellenbeschreibungen, Spaltenbeschreibungen, Join-Schlüssel und die Aktivierung von Beispielwerten sind allesamt grundlegende Schritte für jeden Genie-Space. Mit diesen Fähigkeiten sollte Genie in der Lage sein, die richtigen Tabellen, Spalten und Join-Bedingungen korrekt zu identifizieren, die sich auf jede von ihm generierte Abfrage auswirken. Es kann auch einfache Aggregationen und Filterungen durchführen. Mit diesem grundlegenden Wissen konnte Genie mehr als die Hälfte unserer domänenspezifischen Benchmark-Fragen korrekt beantworten.
- Iteration 4 – 77 % Benchmark-Genauigkeit. Diese Iteration konzentrierte sich auf die Klärung unserer benutzerdefinierten Metrikdefinitionen. CTR ist zum Beispiel nicht Teil jeder Benchmark-Frage, aber es ist ein Beispiel für eine nicht standardmäßige (d. h. sum(), avg(), etc.) Metrik, die jedes Mal korrekt beantwortet werden muss.
- Iteration 5 – 100 % Benchmark-Genauigkeit. Diese Iteration demonstrierte die Verwendung von textbasierten Anweisungen, um verbleibende Lücken bei Ungenauigkeiten zu füllen. Diese Anweisungen erfassten gängige Szenarien, wie z. B. die Einbeziehung globaler Filter für Daten zur analytischen Verwendung, domänenspezifische Definitionen (z. B. was eine Kampagne mit hohemEngagement ausmacht) und spezifizierte Informationen zu Geschäftskalendern.
Durch einen systematischen Ansatz zur Evaluierung unseres Genie-Space haben wir unbeabsichtigtes Abfrageverhalten proaktiv erkannt, anstatt reaktiv von Sarah davon zu erfahren. Wir haben die subjektive Bewertung („es scheint zu funktionieren“) in eine objektive Messung („wir haben validiert, dass es für 13 repräsentative Szenarien funktioniert, die unsere wichtigsten Anwendungsfälle abdecken, wie sie ursprünglich von den Endbenutzern definiert wurden“) umgewandelt.
Der weitere Weg
Beim Aufbau von Vertrauen in Self-Service-Analytics geht es nicht darum, vom ersten Tag an Perfektion zu erreichen. Es geht um eine systematische Verbesserung mit messbarer Validierung. Es geht darum, Probleme zu erkennen, bevor es die Benutzer tun.
Die Benchmarks-Feature bietet die Messebene, die dies erreichbar macht. Es verwandelt den iterativen Ansatz, den die Databricks-Dokumentation empfiehlt, in einen quantifizierbaren, vertrauensbildenden Prozess. Lassen Sie uns diesen benchmark-gesteuerten, systematischen Entwicklungsprozess zusammenfassen:
- Erstellen Sie Benchmark-Fragen (streben Sie 10–15 an), die die realistischen Fragen Ihrer Benutzer repräsentieren
- Testen Sie Ihren Space, um eine Basisgenauigkeit zu ermitteln.
- Nehmen Sie Konfigurationsverbesserungen gemäß dem iterativen Ansatz vor, den Databricks in unseren Best Practicesempfiehlt
- Testen Sie alle Benchmarks nach jeder Änderung erneut, um die Auswirkungen zu messen und Kontextlücken zu identifizieren, die sich aus fehlerhaften Fragen ergeben. Dokumentieren Sie Ihre Genauigkeitsfortschritte, um das Vertrauen der Stakeholder aufzubauen.
Beginnen Sie mit starken Grundlagen im Unity Catalog. Fügen Sie Geschäftskontext hinzu. Testen Sie umfassend durch Benchmarks. Messen Sie jede Änderung. Bauen Sie Vertrauen durch validierte Genauigkeit auf.
Sie und Ihre Endbenutzer werden davon profitieren!
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.