Wie MakeMyTrip Millisekunden-Personalisierung in großem Maßstab mit Databricks erreicht hat
Erfahren Sie, wie Real-Time Mode sofortige Reiseempfehlungen und Kontext für KI-Agenten liefert
von Sitesh Sharma, Aditya Kumar und Navneeth Nair
- Vereinheitlichte Streaming-Architektur: MakeMyTrip überwand die Latenzengpässe traditioneller ETL-Prozesse durch die Einführung des Databricks Real-Time Mode (RTM) und schuf eine vereinheitlichte Spark-Architektur ohne die Notwendigkeit spezialisierter Engines.
- Millisekunden-Personalisierung: Durch die Verarbeitung von Reiseanfragen mit hohem Volumen und kontinuierlichem Datenfluss ermöglichte RTM Latenzzeiten von unter 50 ms (P50), was direkt zu einer Steigerung der Klickraten um 7 % führte.
- Vereinheitlichte Logik, schnellere Innovation: Durch die Verwendung einer vereinheitlichten Engine kann MakeMyTrip nahtlos von Batch- auf Echtzeitverarbeitung umstellen, ohne die Geschäftslogik neu schreiben zu müssen. Dies beseitigt nicht nur operative Komplexität, sondern fördert auch zukünftige Innovationen, indem es generative KI-Agenten einfach mit dem Echtzeitkontext versorgt, den sie für genaue Entscheidungen benötigen.
Echtzeit-Personalisierung in großem Maßstab
Jede Millisekunde zählt, wenn Reisende nach Hotels, Flügen oder Erlebnissen suchen. Als Indiens größte Online-Reiseagentur konkurriert MakeMyTrip bei Echtzeit-Geschwindigkeit und Relevanz. Eine der wichtigsten Funktionen ist die "zuletzt gesuchten" Hotels: Wenn Benutzer die Suchleiste antippen, erwarten sie eine Echtzeit-personalisierte Liste ihrer letzten Interessen, basierend auf ihrer Interaktion mit dem System.
Bei der Größenordnung von MakeMyTrip erfordert die Bereitstellung dieser Erfahrung eine Latenz von unter einer Sekunde in einer Produktionspipeline, die täglich Millionen von Benutzern bedient – sowohl im Consumer- als auch im Corporate-Reisebereich. Durch die Implementierung des Real-Time Mode (RTM) von Databricks – der Ausführungs-Engine der nächsten Generation in Apache Spark™ Structured Streaming – erreichte MakeMyTrip erfolgreich Latenzen im Millisekundenbereich, während gleichzeitig eine kostengünstige Infrastruktur aufrechterhalten und die technische Komplexität reduziert wurde.
Die Herausforderung: Extrem niedrige Latenz ohne architektonische Fragmentierung
Das Datenteam von MakeMyTrip benötigte eine Latenz von unter einer Sekunde für den "zuletzt gesuchten" Hotels-Workflow über alle Geschäftsbereiche hinweg. In ihrer Größenordnung führt selbst eine Verzögerung von wenigen hundert Millisekunden zu Reibungsverlusten in der User Journey, was sich direkt auf die Klickraten auswirkt.
Der Micro-Batch-Modus von Apache Spark führte zu inhärenten Latenzgrenzen, die das Team trotz umfangreicher Optimierung nicht überwinden konnte – die Latenz lag durchweg bei ein bis zwei Sekunden, viel zu langsam für ihre Anforderungen.
Als Nächstes evaluierten sie Apache Flink für etwa 10 Streaming-Pipelines, was ihre Latenzanforderungen erfüllte. Die Einführung von Apache Flink als zweiter Engine hätte jedoch erhebliche langfristige Herausforderungen mit sich gebracht:
- Architektonische Fragmentierung: Verwaltung separater Engines für Echtzeit- und Batch-Verarbeitung
- Duplizierte Geschäftslogik: Geschäftsregeln müssten in zwei Codebasen implementiert und gepflegt werden
- Höherer Betriebsaufwand: Verdoppelung des Aufwands für Überwachung, Debugging und Governance über mehrere Pipelines hinweg
- Konsistenzrisiken: Ergebnisse laufen Gefahr, zwischen Batch- und Echtzeitverarbeitung abzuweichen
- Infrastrukturkosten: Der Betrieb und die Optimierung von zwei Engines erhöhen die Rechenkosten und den Wartungsaufwand
Warum Real-Time Mode: Millisekunden-Latenz auf einem einzigen Spark-Stack
Da MakeMyTrip niemals eine Dual-Engine-Architektur wollte, war Apache Flink keine praktikable Langzeitoption. Das Team traf eine bewusste architektonische Entscheidung: auf Apache Spark zu warten, bis es schneller wird, anstatt den Stack zu fragmentieren.
Als Apache Spark Structured Streaming RTM einführte, wurde MakeMyTrip der erste Kunde, der es einsetzte. RTM ermöglichte es ihnen, Latenzen im Millisekundenbereich auf Apache Spark zu erreichen – und erfüllte damit die Echtzeitanforderungen, ohne eine weitere Engine einzuführen oder die Plattform zu splitten.
Die Wartung von zwei Engines bedeutet eine Verdoppelung der Komplexität und des Risikos von Logikabweichungen zwischen Batch- und Echtzeitberechnungen. Wir wollten eine einzige Quelle der Wahrheit – eine Spark-basierte Pipeline – anstatt zwei Engines zu pflegen. Real-Time Mode gab uns die Leistung, die wir brauchten, mit der Einfachheit, die wir wollten." —Aditya Kumar, Associate Director of Engineering, MakeMyTrip
RTM liefert kontinuierliche, latenzarme Verarbeitung durch drei wichtige technische Innovationen, die zusammenarbeiten, um die Latenzquellen zu eliminieren, die der Micro-Batch-Ausführung inhärent sind:
- Kontinuierlicher Datenfluss: Daten werden verarbeitet, sobald sie eintreffen, anstatt in periodische Blöcke aufgeteilt zu werden.
- Pipeline-Scheduling: Stufen laufen gleichzeitig, ohne zu blockieren, sodass nachgelagerte Aufgaben Daten sofort verarbeiten können, ohne auf den Abschluss vorgelagerter Stufen warten zu müssen.
- Streaming Shuffle: Daten werden sofort zwischen Aufgaben übergeben, wodurch die Latenzengpässe traditioneller, festplattenbasierter Shuffles umgangen werden.
Zusammen ermöglichen diese Innovationen Apache Spark, Pipelines im Millisekundenbereich zu erreichen, die zuvor nur mit spezialisierten Engines möglich waren. Um mehr über die technische Grundlage von RTM zu erfahren, lesen Sie diesen Blogbeitrag: „Breaking the Microbatch Barrier: The Architecture of Apache Spark Real-Time Mode."
Die Architektur: Eine einheitliche Echtzeit-Pipeline
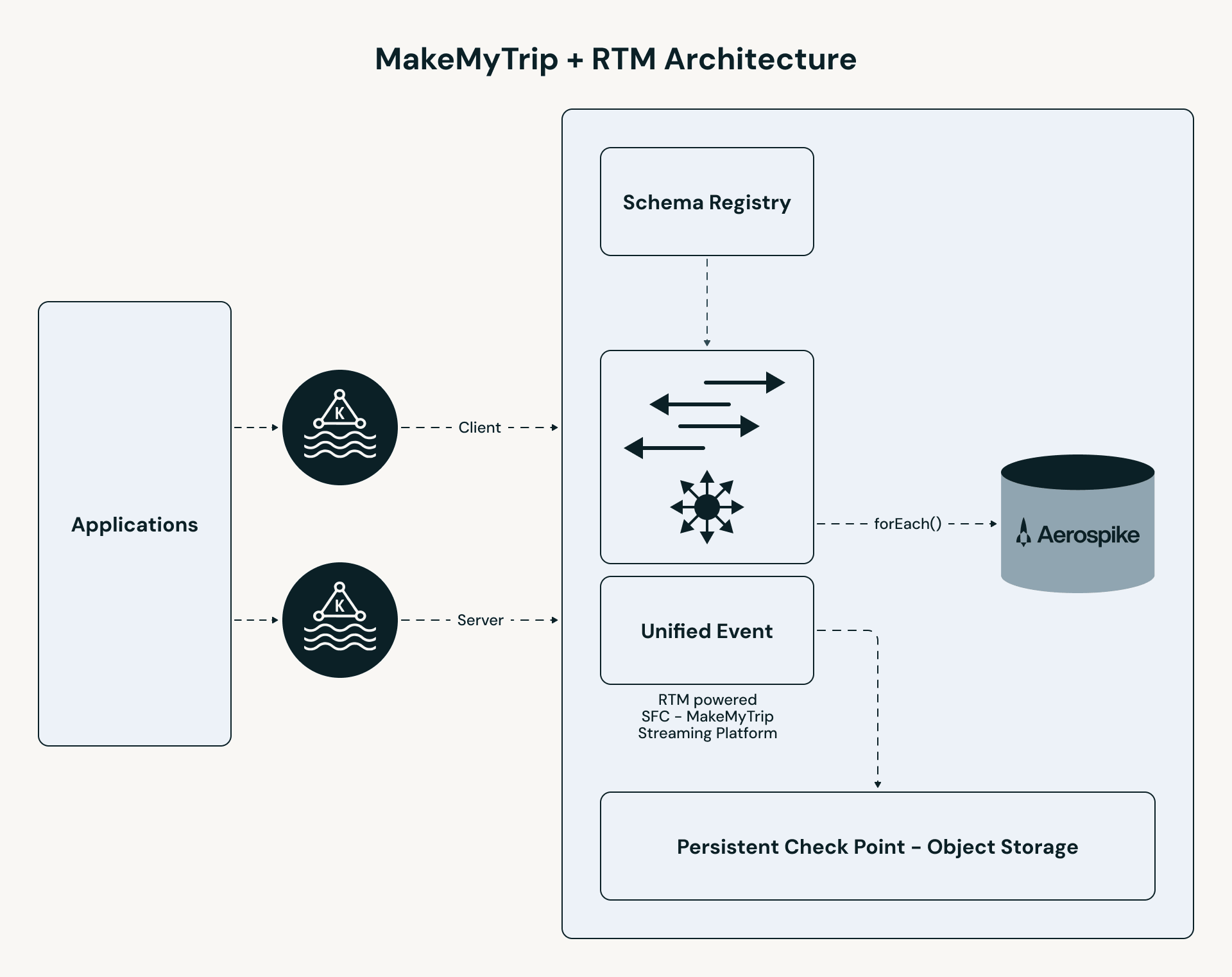
Die Pipeline von MakeMyTrip folgt einem Hochleistungspfad:
- Einheitliche Erfassung: B2C- und B2B-Clickstream-Themen werden zu einem einzigen Stream zusammengeführt. Die gesamte Personalisierungslogik – Anreicherung, zustandsbehaftete Suche und Ereignisverarbeitung – wird konsistent über beide Benutzersegmente angewendet.
- RTM-Verarbeitung: Die Apache Spark-Engine nutzt gleichzeitige Planung und Streaming Shuffle, um Ereignisse in Millisekunden zu verarbeiten.
- Zustandsbehaftete Anreicherung: Die Pipeline führt eine latenzarme Suche in Aerospike durch, um die "Letzten N" Hotels für jeden Benutzer abzurufen.
- Sofortige Bereitstellung: Ergebnisse werden in einen UI-Cache (Redis) gepusht, sodass die App personalisierte Ergebnisse in unter 50 ms bereitstellen kann.
Konfiguration von RTM: eine einzeilige Codeänderung
Die Verwendung von RTM in Ihrer Streaming-Abfrage erfordert keine Umschreibung der Geschäftslogik oder Umstrukturierung von Pipelines. Die einzige erforderliche Codeänderung ist die Einstellung des Trigger-Typs auf RealTimeTrigger, wie im folgenden Code-Snippet gezeigt:
Die einzige infrastrukturelle Überlegung: Cluster-Task-Slots müssen größer oder gleich der Gesamtzahl aktiver Tasks über Quell- und Shuffle-Stufen sein. Das Team von MakeMyTrip analysierte seine Kafka-Partitionen, Shuffle-Partitionen und die Pipeline-Komplexität im Voraus, um eine ausreichende Parallelität sicherzustellen, bevor es in die Produktion ging.
Co-Entwicklung von RTM für die Produktion
Als erster Anwender von RTM arbeitete MakeMyTrip direkt mit dem Databricks-Engineering zusammen, um die Pipeline produktionsreif zu machen. Mehrere Funktionen erforderten eine aktive Zusammenarbeit zwischen den beiden Teams, um sie zu entwickeln, zu optimieren und zu validieren.
- Stream Union: Zusammenführen von B2C und B2B in einer einzigen Pipeline
MakeMyTrip musste zwei separate Kafka-Topic-Streams – B2C Consumer Clickstream und B2B Corporate Travel – zu einer einzigen RTM-Pipeline vereinigen, damit dieselbe Personalisierungslogik konsistent über beide Benutzersegmente angewendet werden konnte. Nach einem Monat enger Zusammenarbeit mit dem Databricks-Engineering wurde die Funktion entwickelt und ausgeliefert. Das Ergebnis war eine einzige Pipeline, in der die gesamte Geschäftslogik an einem Ort lebt, ohne Risiko von Abweichungen zwischen den Benutzersegmenten. - Task-Multiplexing: Mehr Partitionen, weniger Kerne
Das Standardmodell von RTM weist jedem Kafka-Partition einen Slot/Kern zu. Bei 64 Partitionen in MakeMyTrips Produktionsumgebung wären das 64 Slots/Kerne – bei ihrer Größenordnung nicht kosteneffizient. Um dies zu beheben, führte das Databricks-Team die Option MaxPartitions für Kafka ein, die es ermöglicht, mehrere Partitionen von einem einzigen Kern verarbeiten zu lassen. Dies gab MakeMyTrip den Hebel, den sie brauchten, um die Infrastrukturkosten zu senken, ohne den Durchsatz zu beeinträchtigen. - Pipeline-Härtung: Checkpointing, Backpressure und Fehlertoleranz
Das Team arbeitete an einer Reihe von betrieblichen Herausforderungen, die spezifisch für hochvolumige, latenzarme Workloads sind: Optimierung der Checkpoint-Häufigkeit und -Aufbewahrung, Behandlung von Timeouts und Verwaltung von Backpressure bei Spitzen im Clickstream-Volumen. Durch die Skalierung auf 64 Kafka-Partitionen, die Aktivierung von Backpressure und die Begrenzung der MaxRatePerPartition auf 500 Ereignisse optimierte das Team den Durchsatz und die Stabilität. Durch diese iterative Optimierung von Batch-Konfigurationen, Partitionierung und Wiederholungsverhalten erreichten sie eine stabile, produktionsreife Pipeline, die täglich Millionen von Benutzern bedient.
Ergebnisse
RTM ermöglichte sofortige Personalisierung und verbesserte Reaktionsfähigkeit, höhere Engagement-Raten (gemessen an Klickraten) und operative Einfachheit durch eine einzige, einheitliche Engine. Die wichtigsten Metriken sind unten aufgeführt.
Apache Spark als Echtzeit-Engine
MakeMyTrips Bereitstellung beweist, dass RTM auf Spark die extrem niedrige Latenz liefert, die Ihre Echtzeitanwendungen benötigen. Da RTM auf denselben bekannten Spark-APIs aufbaut, können Sie dieselbe Geschäftslogik für Batch- und Echtzeit-Pipelines verwenden. Sie benötigen nicht mehr den Overhead der Wartung einer zweiten Plattform oder einer separaten Codebasis für die Echtzeitverarbeitung und können RTM auf Spark einfach mit einer einzigen Codezeile aktivieren.
Real-Time Mode hat es uns ermöglicht, unsere Infrastruktur zu komprimieren und Echtzeit-Erlebnisse zu liefern, ohne mehrere Streaming-Engines verwalten zu müssen. Da wir in das Zeitalter der KI-Agenten eintreten, erfordert deren effektive Steuerung den Aufbau von Echtzeit-Kontexten aus Datenströmen. Wir experimentieren mit Spark RTM, um unseren Agenten den reichhaltigsten und aktuellsten Kontext zu liefern, der für die bestmöglichen Entscheidungen notwendig ist. —Aditya Kumar, Associate Director of Engineering, MakeMyTrip
Erste Schritte mit Real-Time Mode
Um mehr über Real-Time Mode zu erfahren, sehen Sie sich dieses On-Demand-Video zum Einstieg an oder lesen Sie die Dokumentation.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.