Die Microbatch-Barriere durchbrechen: Die Architektur des Apache Spark Echtzeit Mode
Wie wir Spark weiterentwickelt haben, um High-Throughput-ETL- und Ultra-Low-Latency-Streaming-Workloads zu bewältigen
von Jerry Peng, Siying Dong und Indrajit Roy
- Der Echtzeit Mode von Apache Structured Streaming vereint ETL mit hohem Durchsatz und operative Arbeitslasten mit Latenz im Millisekundenbereich in einer einzigen Engine.
- Tauchen Sie tief in das hybride Ausführungsmodell ein, das gleichzeitige Verarbeitungsstufen und nicht blockierende Operatoren für Latenzen im Millisekundenbereich detailliert beschreibt.
- Kunden können jetzt eine Reaktionsfähigkeit von unter 100 ms für Anwendungen mit extrem niedriger Latenz erreichen, z. B. für die Betrugserkennung in Echtzeit.
Mit der Einführung des Echtzeitmodus (RTM) in Apache Spark 4.1 liefert Structured Streaming jetzt eine Latenz im Millisekundenbereich. In einem kürzlichen Blogpost haben wir gezeigt, wie RTM Flink bei vielen Feature-Engineering-Workloads mit geringer Latenz übertreffen kann (siehe unten).
In diesem Blogbeitrag erörtern wir die Architekturänderungen, die es Structured Streaming ermöglichen, sowohl ETL-Workloads mit hohem Durchsatz als auch Workloads mit extrem niedriger Latenz zu unterstützen.
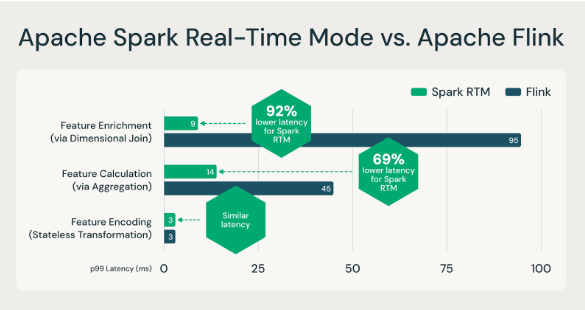
Apache Spark RTM ist für Anwendungsfälle im Bereich Feature Engineering schneller als Flink.
Das Dilemma zwischen Durchsatz und Latenz
Bisher bedeutete die Wahl einer Streaming-Engine einen Kompromiss: Man entschied sich entweder für Systeme wie Apache Spark für ETL-Workloads mit hohem Durchsatz oder für Systeme wie Apache Flink für Workloads mit niedriger Latenz. Die beiden Systeme haben sehr unterschiedliche Semantiken und Performance-Merkmale. Das ändert sich mit RTM in Structured Streaming. Mit der Einführung von RTM kann Apache Spark jetzt sowohl Anwendungsfälle mit hohem Durchsatz als auch solche mit extrem niedriger Latenz bewältigen. Das bedeutet, dass es jetzt möglich ist, eine einzige Engine ohne neue Lernkurve auszuwählen und die Verwaltung von zwei völlig unterschiedlichen Systemen zu vermeiden.
Die Microbatch-Architektur liefert einen hohen Durchsatz
Spark Structured Streaming verwendet eine Micro-Batch-Architektur: Das Streamingsystem empfängt Eingabedaten und teilt diese auf der Grundlage der Datenverfügbarkeit und der Konfigurationen für die maximale Batchgröße in diskrete Batches, sogenannte Epochen, auf. Die Spark-Engine wendet die Geschäftslogik durch Transformationen wie Projektion, Filter und Aggregation an. Die Ergebnisse werden als kontinuierlicher Stream von Batches ausgegeben. Structured Streaming eignet sich aufgrund dieser Microbatch-Architektur hervorragend für die Verarbeitung mit hohem Durchsatz: Da mehrere Datensätze zusammen verarbeitet werden, wird der feste Overhead amortisiert und die vektorisierte Ausführung kann den Durchsatz weiter verbessern. Diese Batches werden parallel ausgeführt und halten dabei die Hardwareauslastung hoch. Der Microbatch-Modus weist dynamisch Task-Slots über mehrere Streams hinweg zu, was zusätzlich zu einer hohen Auslastung und einem hohen Durchsatz beiträgt. Die grundlegende Innovation von Spark, die Lineage-basierte Fehlertoleranz, stellt sicher, dass diese Streams mit starken Exactly-Once-Garantien verarbeitet werden.
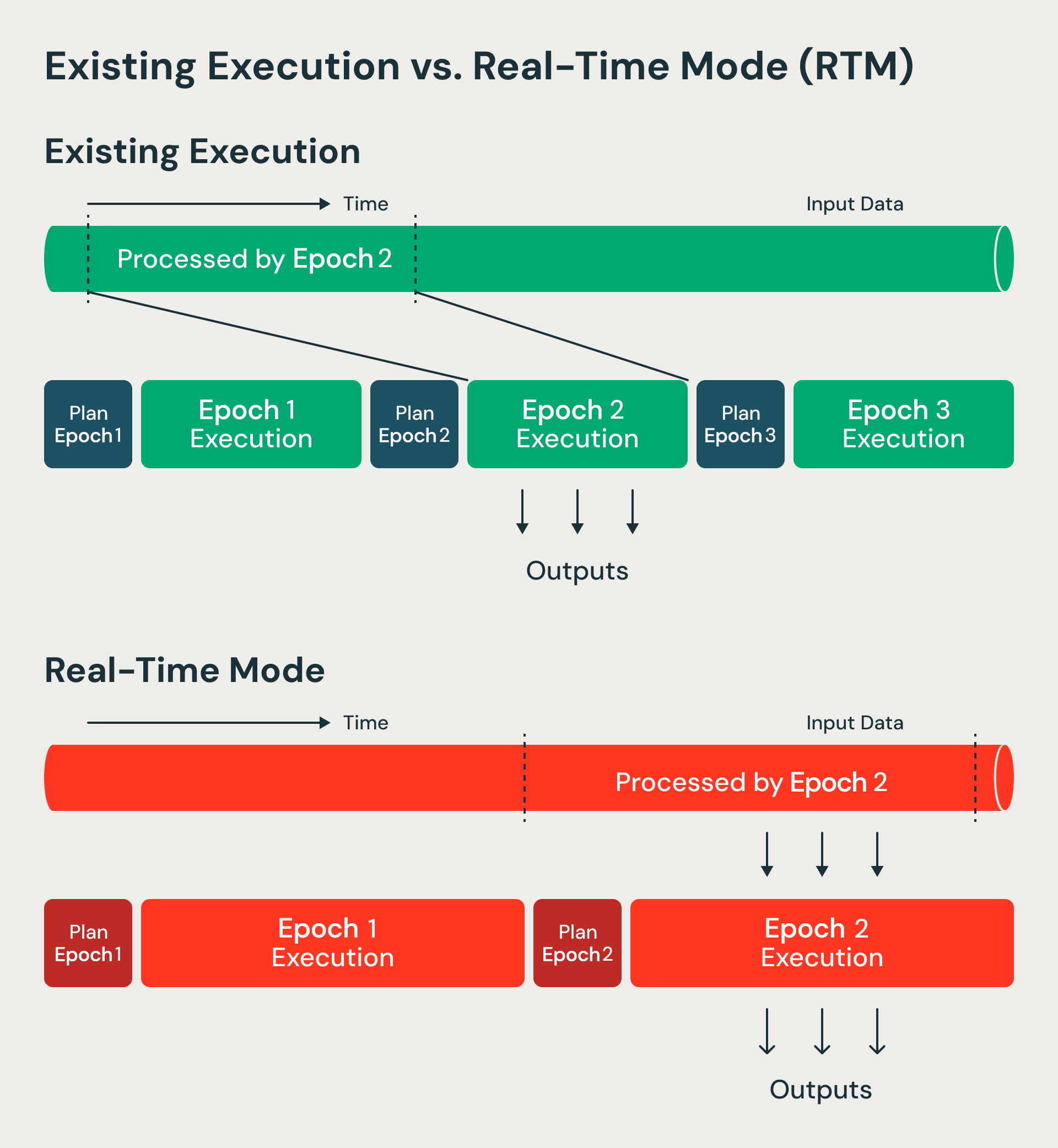
RTM verarbeitet Daten im Vergleich zum Microbatch-Modus nicht blockierend.
Das Nadelöhr niedriger Latenz
Während Structured Streaming sehr gut für die Verarbeitung von ETL- und Ingestion-Workloads im Sekundenbereich geeignet ist, erfordern viele operative Anwendungsfälle eine Latenz im Millisekundenbereich. Betrugserkennung bei Finanztransaktionen, Echtzeit-Einblicke in der Reisebranche oder die Analyse von Telemetriedaten von vernetzten Fahrzeugen sind alles Beispiele, bei denen Kunden Antworten in Millisekunden benötigen.
Architektonische Herausforderung: Warum kleinere Batches nicht funktionieren
Die naheliegende Lösung scheint einfach zu sein: Man muss nur die Batches verkleinern. Wenn wir einen Datensatz nach dem anderen verarbeiten, sollten wir eine Echtzeit-Performance erzielen. Leider ist es nicht so einfach.
Jeder Microbatch in Structured Streaming verursacht Fixkosten, die die Ausführungszeit bei der Verarbeitung kleiner Datenmengen dominieren. Das System schreibt vor und nach jeder Batch-Ausführung Logs in einen beständigen Objektspeicher. Zusätzlich müssen Zustandsaktualisierungen für jede zustandsbehaftete Abfrage ebenfalls am Ende eines Microbatches als Upload in den Objektspeicher durchgeführt werden. Dies sind entscheidende Schritte, um die Konsistenzsemantik zu gewährleisten, können aber die Ausführungszeit um Hunderte von Millisekunden, wenn nicht sogar Sekunden, verlängern. Selbst wenn wir einige dieser Latenzen kaschieren, sind die Latenz bei der Planung jedes Batchs, der Overhead für die logische und physische Planung, die Task-Serialisierung und das Schedule schwer zu reduzieren. Wie Sie sich vorstellen können, stößt die Verringerung der Batch-Größen schnell an eine Grenze. Die nachstehende Abbildung zeigt, dass wenn Microbatches zu klein werden (linker Balken), die fixen Verarbeitungskosten der Microbatches die Ausführung dominieren und die End-to-End-Latenz erhöhen.
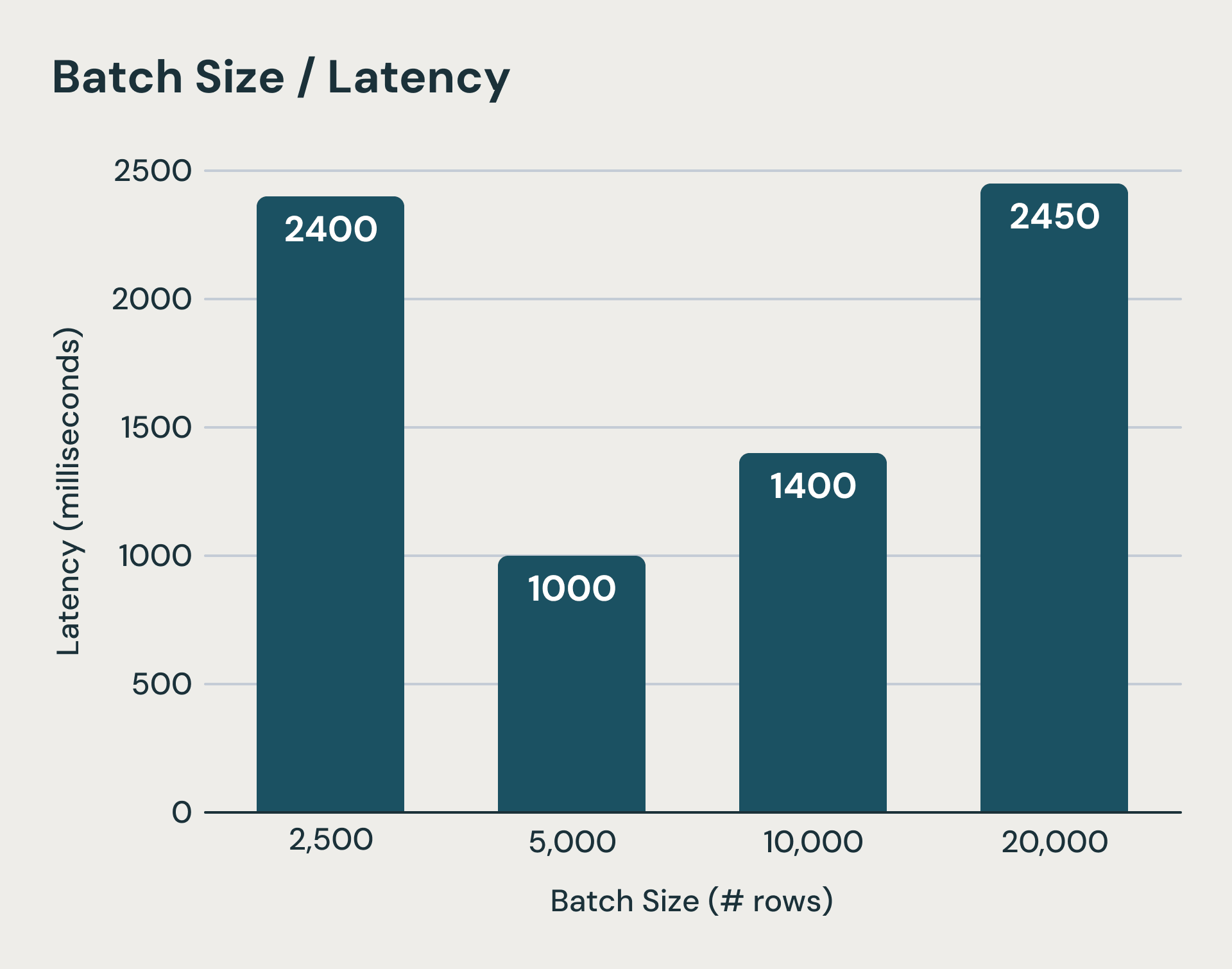
Oberhalb eines threshold können niedrigere Batch-Größen die Latenz aufgrund von fixen Overheads erhöhen.
Das stellte uns vor eine architektonische Herausforderung: Wir wollten die Kosten- und Fehlertoleranzvorteile der Micro-Batch-Architektur beibehalten und gleichzeitig die niedrige Latenz erreichen, die man von Modellen erwartet, die Datensätze einzeln verarbeiten (wie Apache Storm und Apache Flink). Unsere Key-Erkenntnis ist, dass wir die Micro-Batch-Architektur zur Unterstützung von Echtzeit-Workloads weiterentwickeln können. Wir haben weiterhin viele der Kern-Micro-Batch-Architektur-Features verwendet, wie z. B. Checkpointing für die Fehlertoleranz. Wir haben jedoch die Schritte eliminiert, in denen die Daten warten mussten und die zu einer hohen Latenz führten. Diese Änderungen werden im Folgenden erörtert.
Unsere Lösung: ein hybrides Ausführungsmodell
So haben wir die Latenz von Structured Streaming verbessert:
1. Längere Laufzeit-Epochen mit kontinuierlichem Datenfluss
Der Microbatch-Modus verarbeitet Daten-Batches, die als Epochen bezeichnet werden. Epochengrenzen werden im Voraus mithilfe von Start- und End-Offsets festgelegt. Stattdessen verarbeitet der Echtzeitmodus Epochen längerer Laufzeit, ändert jedoch den Datenfluss innerhalb jeder Epoche. Die Daten fließen jetzt kontinuierlich ohne Blockierung in Streams durch verschiedene Stufen und Operatoren. Da Epochen von längerer Laufzeit sind, wird der Overhead für Checkpointing und Barrieren amortisiert. An den Epochengrenzen verwenden wir weiterhin Barrieren für die Wiederherstellungsbuchführung und die Neuplanung von Tasks – und behalten so die Vorteile bei, die Micro-Batch-Architekturen resilient und effizient machen. Wir haben den Micro-Batch in Structured Streaming im Wesentlichen zu einem Checkpoint-Intervall weiterentwickelt.
2. Gleichzeitige Verarbeitungsstufen
In der Structured-Streaming-Architektur wurden die Verarbeitungsstufen sequenziell ausgeführt – die Reducer warteten auf den Abschluss der Mapper, was zu unnötigen Verzögerungen führte. Wir haben diese Stufen im Echtzeitmodus gleichzeitig ausgeführt. Jetzt fordert der Spark-Treiber Quell-Offsets an und Schedule Mapper, aber die Reducer können mit der Verarbeitung von Shuffle-Dateien start, sobald sie verfügbar sind, anstatt darauf zu warten, dass alle Mapper fertig sind. Diese Änderung reduziert die End-to-End-Latenz drastisch. Die nachstehende RTM-Abbildung zeigt, dass die beiden Stufen gleichzeitig in Ausführung sind und Stufe 2 mit der Verarbeitung der Zeilen startet, sobald diese von Stufe 1 verarbeitet wurden.
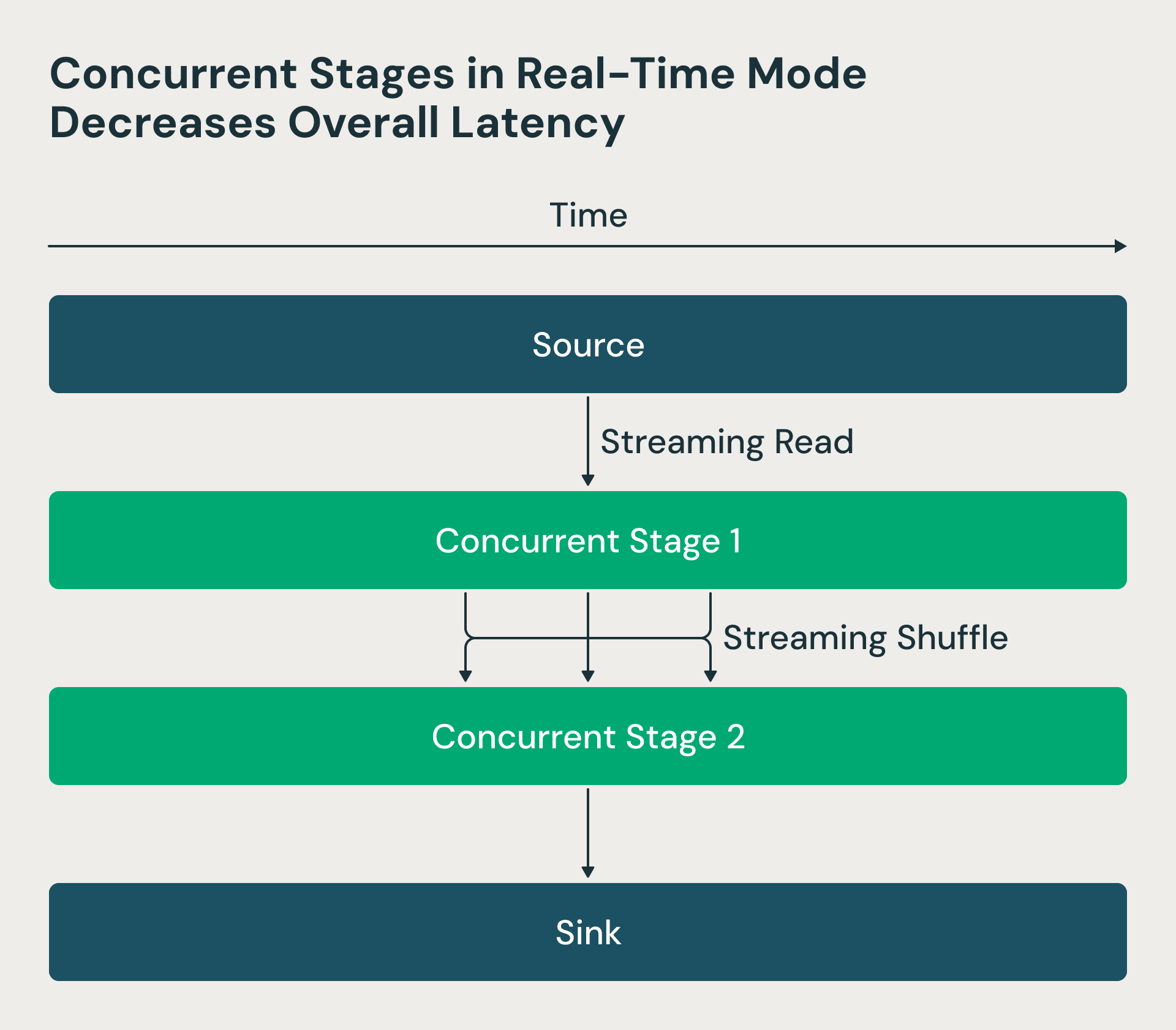
Der Echtzeitmodus verwendet gleichzeitige Stufen, was die Latenz verringert
3. Nicht blockierende Operatoren
Wir haben Key-Operatoren wie Shuffle, die für die Batch-Ausführung mit erheblicher Pufferung konzipiert wurden, neu strukturiert. Im Batch-Modus würde eine Group-by-Aggregation alle Datensätze puffern, eine Vorab-Aggregation durchführen und die Ergebnisse erst am Ende ausgeben. Für die Echtzeitverarbeitung haben wir diese Operatoren so modifiziert, dass die Pufferung minimiert und Ergebnisse kontinuierlich erzeugt werden, wodurch Daten ohne unnötige Wartezeiten durch die Pipeline fließen können.
Übersicht
Durch die Verwendung von Epochen mit längerer Laufzeit mit kontinuierlichem Datenfluss, gleichzeitigem Verarbeitungsstufen und nicht blockierenden Operatoren haben wir die Apache Spark Structured Streaming Engine verallgemeinert, um sowohl High-Throughput- als auch Ultra-Low-Latency-Streaming-Anwendungsfälle zu bewältigen. Dieser hybride Ansatz macht die Wahl zwischen verschiedenen Streaming-Engines überflüssig. Benutzer müssen nur Apache Spark erlernen und es ist nicht mehr nötig, ein weiteres Framework für Ultra-Low-Latency-Streaming zu lernen.
Der Echtzeitmodus ist bei Databricks bereits im Produktiveinsatz und wird von zahlreichen Kunden genutzt, von innovativen Finanzunternehmen bis hin zu Reise-Websites. Unsere Kunden können für ihre Anwendungsfälle Latenzzeiten im Millisekundenbereich erreichen.
Obwohl dies ein wichtiger Fortschritt für die Leistungsfähigkeit von Spark ist, fügen wir weiterhin neue Streaming-Features hinzu. Wenn Ihre Organisation nach Lösungen für Echtzeit-Workloads sucht, probieren Sie Apache Spark Structured Streaming doch einfach mal aus!
Technische Ressourcen erkunden
Um einen tieferen Einblick in das Engineering hinter RTM zu erhalten, sehen Sie sich diese On-Demand-Session an, die von unseren Fachexperten geleitet wird. Sie werden das Design und die Implementierung der Echtzeit Mode erläutern.
Oder lesen Sie die technische Anleitung zum Echtzeit-Modus, um loszulegen. Sie finden alles, was Sie benötigen, um die Echtzeitverarbeitung für Ihre Streaming-Workloads zu aktivieren.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.