Echtzeitmodus: Streaming mit extrem niedriger Latenz auf Spark-APIs ohne eine zweite Engine
Streaming-Daten in Millisekunden auf Apache Spark verarbeiten, ohne den Overhead von Apache Flink
von Navneeth Nair, Jerry Peng und Abhay Bothra
- Vereinheitlichung: Erfahren Sie, wie der Echtzeit Mode (RTM) in Apache Spark Offline-Training und Online-Feature-Engineering mit extrem niedriger Latenz in einer einzigen, hochleistungsfähigen Engine vereinheitlicht.
- Performance: Entdecken Sie die neu gestaltete Architektur, die eine extrem niedrige Latenz in Spark ermöglicht, mit einer Performance-Analysen, die Apache Spark RTM mit Apache Flink vergleicht.
- Einfachheit & Einführung: RTM bietet viele operative Vorteile, darunter eine vereinfachte Migration, eine einheitliche API zur Vermeidung von "Logic Drift" und reale Kundenanwendungsfälle.
Apache Spark Structured Streaming ist seit langem die Grundlage für geschäftskritische Datenpipelines im großen Maßstab, von Streaming-ETL über Analysen bis hin zum maschinellen Lernen. Doch mit der Weiterentwicklung der operativen Anwendungsfälle verlangten die Teams mehr: Latenzen im Subsekundenbereich für Anwendungen wie Betrugserkennung, Personalisierung, Anomalieerkennung, Echtzeit-Benachrichtigungen und -Berichterstattung.
Bisher bedeutete die Erfüllung dieser Anforderungen an extrem niedrige Latenz die Einführung spezialisierter Systeme neben Spark. Mit der Einführung des Echtzeitmodus in Spark Structured Streaming ist dieser Kompromiss nicht mehr notwendig. In diesem Blogbeitrag untersuchen wir, wie Spark die Echtzeit-Streaming-Architektur für gängige Anwendungsfälle wie Feature-Engineering vereinfacht, die seit langem bestehende betriebliche Komplexität beseitigt und eine branchenführende Performance liefert.
Für Echtzeit-Streaming müssen nicht mehr mehrere unterschiedliche Systeme betrieben werden
Die Fähigkeit, Daten in Echtzeit zu verarbeiten und darauf zu reagieren, ist heute eine zentrale Anforderung. Moderne Anwendungen, insbesondere KI-Agenten, sind für ihre Funktion auf einen kontinuierlichen Strom an neuem Kontext angewiesen. Wenn die zugrunde liegenden Daten unvollständig sind oder verzögert eintreffen, leidet die Benutzererfahrung. Echtzeit-Performance ist nicht nur für traditionelle Anwendungsfälle wie die Betrugserkennung erforderlich, sondern für jede allt�ägliche Interaktion, bei der ein Benutzer präzise und aktuelle Antworten erwartet. In diesem Umfeld wirkt sich die Latenz direkt auf den Umsatz, das Kundenvertrauen und den Wettbewerbsvorteil aus.
Datenteams, die Echtzeit-Streaming-Anwendungen entwickeln, mussten bisher zwei unterschiedliche Datenverarbeitungs-Stacks verwalten: Apache Spark™ für groß angelegte Analysen und spezialisierte Systeme wie Apache Flink® oder Kafka Streams für latenzempfindliche Anwendungen im Sub-Sekunden-Bereich. Diese Fragmentierung erfordert von den Teams die Pflege duplizierter Codebasen, die Verwaltung separater Governance-Modelle und die Einstellung von Fachkräften zur Abstimmung und Wartung der Engine-spezifischen Infrastruktur.
Der im August 2025 als Public Preview eingeführte Echtzeit Mode (RTM) für Apache Spark Structured Streaming wurde entwickelt, um diese Reibungsverluste zu beseitigen. Durch die grundlegende Weiterentwicklung der Spark Execution Engine haben wir die Notwendigkeit eines zweiten Systems beseitigt. Diese Umstellung ermöglicht es Entwicklern, das gesamte Spektrum an Anwendungsfällen abzudecken – von ETL mit hohem Durchsatz bis hin zu Echtzeit-Apps mit niedriger Latenz – und dabei dieselbe Spark API zu verwenden, die sie bereits kennen. Das bedeutet weniger Zeit für die Verwaltung der Infrastruktur und mehr Zeit für die Konzentration auf den Geschäftsanwendungsfall.
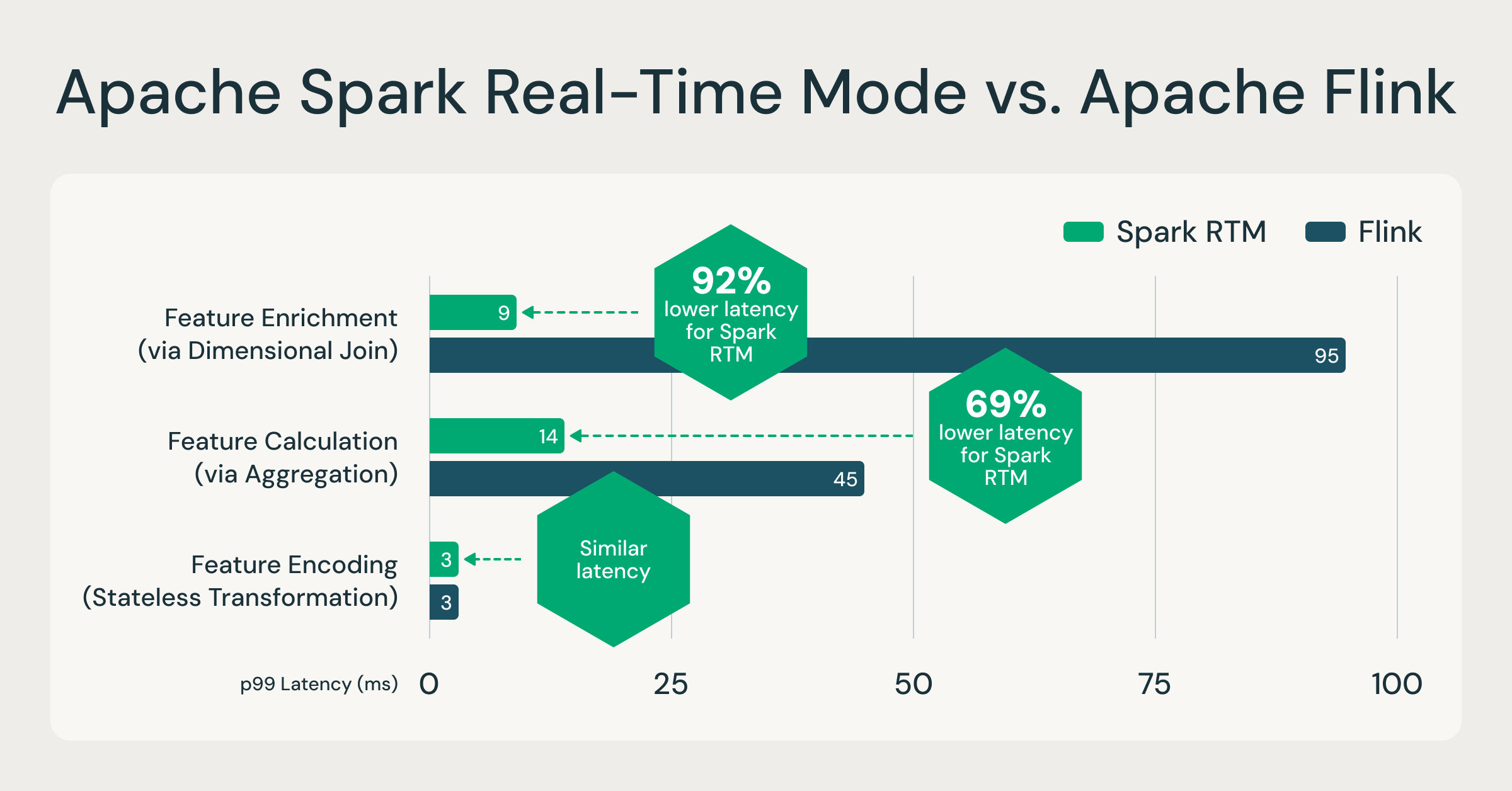
Spark kann jetzt Ereignisse in Millisekunden verarbeiten – bis zu 92 % schneller als Flink.
Der Echtzeit-Mode (RTM) hat eine neue optimierte Execution Engine eingeführt, die es Spark ermöglicht, konsistente Latenzen im Sub-Sekunden-Bereich zu liefern. Um die Leistung zu bewerten, haben wir einen direkten Vergleich zwischen Spark RTM und Apache Flink durchgeführt. Die Tests basierten auf Echtzeit-Feature-Berechnungs-Workloads, die wir häufig in der Produktion sehen. Diese Muster für die Feature-Berechnung sind repräsentativ für die meisten ETL-Anwendungsfälle mit geringer Latenz, wie z. B. Betrugserkennung, Personalisierung und operative Analysen.
Wir haben drei gängige Feature-Muster bewertet:
- Feature-Kodierung (zustandslose Transformation): Abschneiden von Eingabezeilen und Kodierung
- Feature-Anreicherung (durch Join): Verknüpfen eines Streams mit einer statischen Tabelle
- Feature-Berechnung (durch Aggregation): GroupBy + Count-Aggregation
Die Ergebnisse zeigen, dass die weiterentwickelte Architektur von Spark ein Latenzprofil aufweist, das mit dem von spezialisierten Streaming-Frameworks vergleichbar ist.
Diese Performance wird durch drei Keye technische Innovationen im RTM ermöglicht:
- Kontinuierlicher Datenfluss: Die Daten werden bei ihrem Eintreffen verarbeitet und nicht in diskretisierten, periodischen Blöcken.
- Pipeline-Scheduling: Stufen werden gleichzeitig und ohne Blockierung ausgeführt, sodass nachgelagerte Aufgaben die Daten sofort verarbeiten können, ohne auf den Abschluss der vorgelagerten Stufen warten zu müssen.
- Streaming Shuffle: Daten werden sofort zwischen Tasks übergeben, wodurch die Latenzengpässe herkömmlicher festplattenbasierter Shuffles umgangen werden.
Zusammen machen diese Spark zu einer High-Performance Engine mit geringer Latenz, die in der Lage ist, die anspruchsvollsten operativen Anwendungsfälle zu bewältigen.
Teams betreiben weniger Infrastruktur und sind mit Spark schneller.
Obwohl die reine Geschwindigkeit entscheidend ist, liegt der wahre Wert des Echtzeitmodus in seiner Fähigkeit, die betriebliche Komplexität zu beseitigen, die den Aufbau von Pipelines mit extrem niedriger Latenz typischerweise behindert. Spark RTM vereinfacht Ihre Architektur durch drei wesentliche Vorteile erheblich. Um dies zu konkretisieren, beschreiben wir diese im Kontext von Echtzeit-Anwendungen für machine learning.
Minimierung von "Logic Drift" zwischen Training und Inferenz: Echtzeit-ML, wie z. B. die Betrugserkennung, erfordert eine nahtlose Übergabe zwischen der Batch-Verarbeitung mit hohem Durchsatz (für das Modelltraining) und dem Streaming mit geringer Latenz (für die Live-Inferenz). Spark ist die bevorzugte Wahl von Data Scientists für das Modelltraining, und ein erzwungener Wechsel von Spark zu Flink für die Inferenz würde eine Lücke in der Geschäftslogik schaffen. Am Ende hat man eine Version der Logik in Spark für das Training und eine völlig andere Codebasis in Flink für die Produktion. Diese Replikation der Geschäftslogik kann fehleranfällig sein und führt zu Logic Drift, bei dem Ihr Modell auf einer Realität trainiert wird, die Bewertung aber auf einer anderen erfolgt. Mit Spark RTM bleibt Ihr Transformationscode identisch, sodass Sie Features schneller und mit hoher Genauigkeit in Produktion bringen können.
Aktualität bei Bedarf mit einer einzeiligen Code-Änderung: Geschäftsanforderungen sind selten statisch. Eine Feature-Pipeline, die heute mit einem 1-Minuten-SLA beginnt, könnte morgen eine Latenz im Sub-Sekunden-Bereich erfordern, da sich die Anforderungen an die Aktualität des Modells weiterentwickeln. Umgekehrt ist es für viele Anwendungsfälle deutlich kostengünstiger, „langsamer zu arbeiten“ (z. B. in täglichen oder stündlichen Batches), wenn keine sofortige Aktualität erforderlich ist. Spark bietet den Raum, um mit Ihrem Produkt zu wachsen und zu skalieren. Es ermöglicht Ihnen, Ihre Feature-Engineering-Strategie mit einer einzeiligen Code-Änderung einfach umzustellen. Sie können Ihren Trigger zum Beispiel auf AvailableNow setzen, um eine Pipeline nach einem täglichen oder stündlichen Schedule auszuführen. Wenn sich die Geschäftsanforderungen ändern, können Sie auf kontinuierliches Streaming mit extrem niedriger Latenz umstellen, indem Sie einfach in den Echtzeitmodus wechseln: .trigger(RealTimeTrigger.apply()). Im Gegensatz dazu ist dies in Flink ein manueller Prozess. Oft müssen Sie die Parallelität abstimmen und das Herunterfahren und Neustarten von compute Ressourcen orchestrieren, nur um eine neue Verarbeitungsfrequenz zu erreichen.
Entwicklung beschleunigen: RTM basiert auf derselben Spark-API, mit der Ihr Team bereits vertraut ist. Dies beseitigt die Reibungsverluste bei der Wartung mehrerer Systeme und ermöglicht es Ihnen, schneller voranzukommen, indem Sie Echtzeitanwendungen in einer einzigen, konsistenten Umgebung erstellen und skalieren.
Kunden führen mehrere Echtzeitanwendungen auf Spark aus
Frühanwender nutzen RTM, um eine Reihe von Anwendungen mit geringer Latenz in verschiedenen Branchen zu betreiben.
Betrugserkennung: Eine führende Plattform für digitale Vermögenswerte berechnet dynamische Risikomerkmale wie Velocity Checks und aggregierte Ausgabenmuster aus Kafka-Streams und aktualisiert ihren Online-Feature Store in weniger als 200 Millisekunden, um betrügerische Transaktionen am Point of Sale zu blockieren.
Personalisierte Erlebnisse: Eine E-Commerce-Plattform berechnet Echtzeit-Intent-Features basierend auf der aktuellen Sitzung eines Benutzers, wodurch Modelle Empfehlungen in dem Moment aktualisieren können, in dem ein Benutzer mit einem Produkt interagiert.
IoT-Überwachung: Ein Transport- und Logistikunternehmen erfasst Live-Telemetriedaten, um die Anomalieerkennung voranzutreiben, und wechselt so in Millisekunden von einer reaktiven zu einer proaktiven Entscheidungsfindung.
DraftKings, einer der größten Sportwetten- und Fantasy-Sport-Dienste in Nordamerika, nutzt RTM für die Feature-Berechnung seiner Modelle zur Betrugserkennung.
„Bei Live-Sportwetten erfordert die Betrugserkennung eine extreme Geschwindigkeit. Die Einführung des Echtzeitmodus zusammen mit der transformWithState-API in Spark Structured Streaming war für uns ein entscheidender Wendepunkt. Wir haben wesentliche Verbesserungen sowohl bei der Latenz als auch beim Pipeline-Design erzielt und zum ersten Mal einheitliche Feature-Pipelines für das ML-Training und die Online-Inferenz erstellt, wobei wir extrem niedrige Latenzen erreichten, die früher einfach nicht möglich waren.“ – Maria Marinova, leitende Software-Ingenieurin, DraftKings
Starten Sie mit Spark im Echtzeit-Mode
Die Ära, in der man sich zwischen „einfach“ und „schnell“ entscheiden musste, ist vorbei. Warum zwei Engines, zwei Sicherheitsmodelle und zwei Sätze spezialisierter Fähigkeiten verwalten, wenn eine Engine jetzt alles kann? RTM liefert die Geschwindigkeit im Sub-Sekunden-Bereich, die Ihre Echtzeitanwendungen erfordern, mit der architektonischen Einfachheit, die Ihr Team verdient. Durch die Beseitigung der „Betriebssteuer“ können Sie sich endlich darauf konzentrieren, Werte zu schaffen, anstatt die Infrastruktur zu verwalten.
Bereit, die Komplexität Ihres Echtzeit-Stacks zu beseitigen?
- Tauchen Sie ein in die Details: Sehen Sie sich die RTM-Dokumentation an, um die vollständigen technischen Spezifikationen, unterstützten Quellen und Senken sowie Beispielabfragen zu verstehen. Dort finden Sie alles, was Sie brauchen, um den neuen Trigger zu aktivieren und Ihre Streaming-Workloads zu konfigurieren.
- Sehen Sie es in Aktion: Um tiefer in das Engineering hinter RTM einzutauchen, sehen Sie sich diese technische Deep-Dive-Session an, die Sie durch das Design und die Implementierung führt.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.