Wie Sie von Apache Airflow® zu Databricks Lakeflow Jobs wechseln
Ein praktischer Leitfaden, der gängige Airflow-Praktiken mit Databricks Lakeflow Jobs und nebeneinander gestellten Codebeispielen abbildet.
von Zanita Rahimi, Zach Hasen, Lorenzo Rubio und Saad Ansari
- Erfahren Sie, wie gängige Apache Airflow-Orchestrierungsmuster direkt auf Lakeflow Jobs, den integrierten Orchestrator von Databricks, abgebildet werden.
- Verstehen Sie, wie Kontrollfluss, Trigger, Parameter und dynamische Ausführung funktionieren, wenn die Orchestrierung in das Lakehouse integriert ist.
- Verwenden Sie kopierbare Codebeispiele, um reale DAGs inkrementell von Airflow zu Lakeflow Jobs zu migrieren.
In the previous post, From Apache Airflow® to Lakeflow: Data-First Orchestration, orchestration was reframed around data and the lakehouse instead of external schedulers. This post builds on that foundation and focuses on execution details for teams already running Airflow in production and wishing to move to Databricks’ native orchestrator, Lakeflow Jobs.
This guide is written both for practitioners migrating from Airflow and for programming agents generating Lakeflow Jobs workflows. The goal is to show how those same workflows can be expressed naturally when orchestration is part of the lakehouse itself within Databricks.
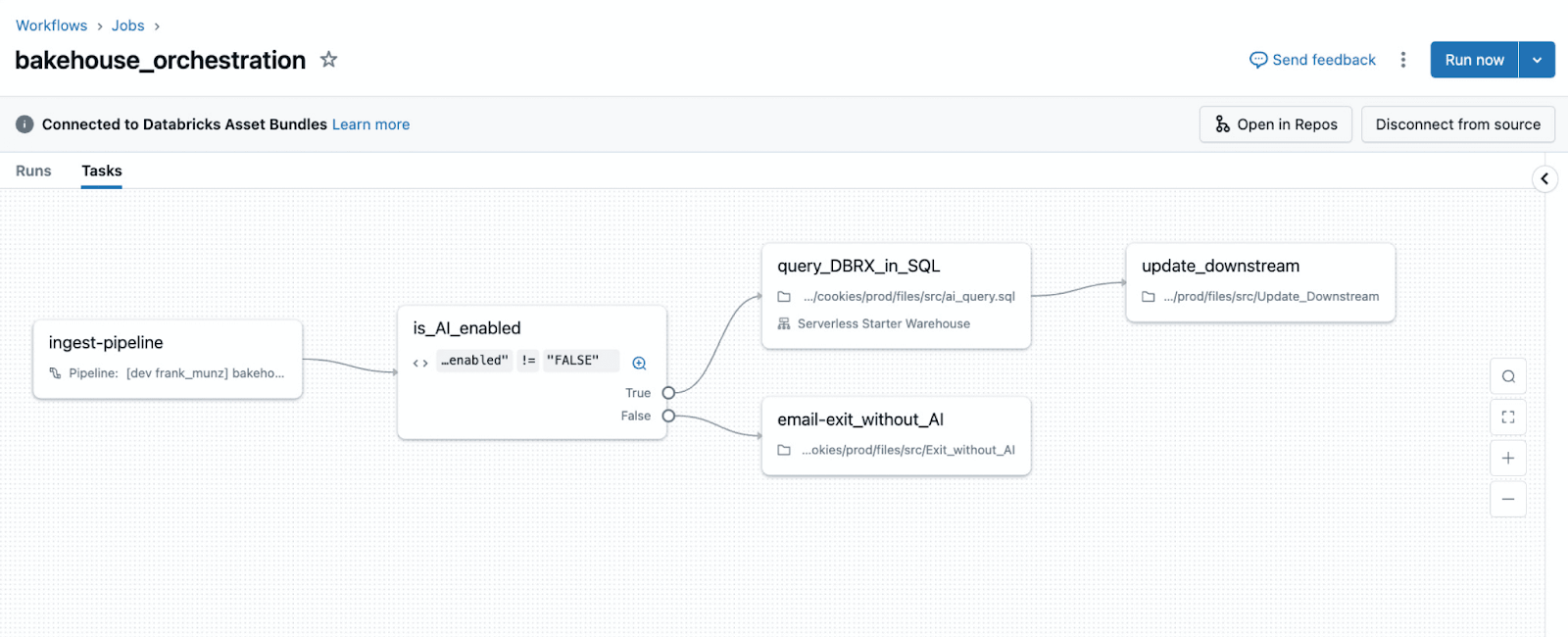
Airflow to Lakeflow Jobs migration map
The table below summarizes how common Airflow orchestration patterns translate to Lakeflow Jobs, and whether the migration is a direct translation or a conceptual refactor.
Airflow pattern | Primary use | Lakeflow Jobs equivalent | Migration guidance |
XComs | Pass small control metadata between tasks | Task values / UC tables / task output references (e.g., tasks.my_query.output.updated_rows) | Use task values for small metadata; move any actual data into Unity Catalog tables |
Sensors | Wait for files or conditions | Replace polling sensors with built-in triggers | |
Backfills | Rerun for historical dates | Job backfills + parameters | Treat time as data, use parameterized backfills |
Branching | Conditional task execution | Condition (if/else) tasks | Replace task.branch with If-Else tasks |
Dynamic task mapping | Runtime fan-out | For-each tasks | Use for‑each when task count depends on runtime data |
Migration strategy: incremental, not all at once
Most teams migrate incrementally rather than replacing Airflow wholesale. Common approaches include:
- Starting with self-contained or event-driven workflows
- Migrating file arrival and data-driven triggers early
- Keeping stable Airflow pipelines unchanged initially
- Avoiding rewrites of mature, low-risk jobs
Lakeflow Jobs is designed to coexist during migration and to take over orchestration responsibilities where it adds the most value.
Checklist
XComs with small metadata → task values; XComs with data → Unity Catalog tables or volumes.
- File sensors/assets → file arrival or table update triggers where data is in UC.
Execution‑date macros (
ds, etc.) → explicit parameters + backfill runs.Branching (
@task.branch) → condition tasks.Dynamic task mapping → for‑each tasks where fan‑out is data‑driven.
(Optional) Jobs and schemas managed via Python Asset Bundles for consistent environments.
Lakeflow Jobs overview
When migrating from Airflow, it is useful to internalize a few core assumptions that shape how Lakeflow Jobs works:
Control plane vs data plane
Operations in the data plane (queries, reads, writes, and transformations) drive compute usage. Control-plane operations such as triggers, task values, and parameters do not.
Jobs are the unit of orchestration
- Jobs encapsulate tasks and dependencies; coordination across jobs typically uses data (tables, files), not cross‑DAG signals
- This shifts designs from “DAG talking to DAG” to “producer writes a table, consumer job triggers when that table changes.”
- A Run Job task exists for cases where job-to-job invocation is intentional, but it complements rather than replaces the data-driven coordination model.
Triggers are first-class
- File arrival and table update triggers are built-in features, not implemented via long-running sensors.
- This shifts orchestration from polling-based to event-driven by default.
These assumptions explain why some Airflow patterns translate directly, while others are intentionally simplified or replaced.
Migration steps
1. XComs to task values for control, tables for data
Airflow: XComs for small control metadata
In Apache Airflow, XComs are used to pass small pieces of metadata between tasks within a DAG run. A minimal Airflow example that passes a small value between tasks:
This works well for small IDs, values, flags, and counts but becomes hard to reason about when many tasks rely on XComs or when large payloads are pushed.
Lakeflow: task values for control, tables for data
In Lakeflow Jobs, task values play the XCom role for control metadata. Jobs and tasks are typically defined via asset bundles, and their implementations live in notebooks or Python files. Bundle snippet (Python) defining two tasks and a dependency:
Producer notebook:
Consumer notebook:
Die Task-Werte sind in der Lakeflow Jobs UI pro Ausführung sichtbar und auf kleine Payloads beschränkt, was sie ideal für Flags, Zähler und IDs macht. Für größere Objekte oder wiederverwendbare Ausgaben sollten Tasks in Tabellen oder Views von Unity Catalog schreiben:
💡 Faustregel: Verwenden Sie Task-Werte nur für Steuerungsmetadaten; legen Sie alles, was wie Daten aussieht, in Tabellen, Views oder Volumes ab.
Migrationstipps
- Einfache XComs → Task-Werte.
- XComs, die DataFrames oder große JSON-Objekte übertragen → stattdessen Lese-/Schreibzugriffe auf Unity Catalog.
- Vermeiden Sie die Reproduktion von XCom-lastigen DAGs; verlassen Sie sich auf das Lakehouse als gemeinsamen Zustand.
2. Sensoren und Assets zu Datei- und Tabellen-Triggern
Airflow: Dateisensoren und Assets
Typisches Airflow-Muster für eine dateigesteuerte Pipeline:
Dies beschäftigt einen Worker-Slot mit ständigem Abfragen und wird oft mit benutzerdefinierter Asset-Verfolgung kombiniert, wenn mehrere Konsumenten von denselben Daten abhängen.
Lakeflow: Datei-Ankunfts-Trigger
Snippet, das einen Datei-Ankunfts-Trigger zeigt
Notebook-Implementierung
Die Plattform kümmert sich um den Trigger-Status, Debouncing und Cooldown, und Sie benötigen keine langlaufenden Sensoren oder externen Scheduler mehr, um nach Dateien Ausschau zu halten.
Lakeflow: Tabellen-Update-Trigger (Asset-Style Scheduling)
Wenn Produzenten in Unity Catalog-Tabellen schreiben, können Konsumenten bei Tabellen-Updates statt bei zeitbasierten Zeitplänen ausgelöst werden.
💡Faustregel: Triggern Sie Jobs wann immer möglich bei Datei-Ankünften oder Tabellen-Updates; verwenden Sie Zeitpläne nur, wenn Sie sie wirklich benötigen.
Migrationstipps
- Dateisensoren → Datei-Ankunfts-Trigger an UC-Standorten oder Volumes.
- Asset-Register → Unity Catalog-Tabellen mit Tabellen-Update-Triggern.
- Nicht-Daten-Ereignisse → explizite externe Trigger oder Parameter.
3. Ausführungsdaten zu Parametern und Backfill-Läufen
Airflow: Ausführungsdatum und ds
Airflow fördert die Templatisierung von Logik mit Ausführungsdaten:
Backfills werden durch den Airflow-Scheduler und die Ausführungsdaten gesteuert; die Logik hängt implizit vom Zeitkonzept des Schedulers ab.
Lakeflow: explizite Parameter und Backfill
In Lakeflow Jobs sollte das „logische Ausführungsdatum“ als Parameter modelliert werden. Job-Definition (Bundles) mit einem Parameter:
Hinweis: Sie können auch {{ job.trigger.time.iso_date }} verwenden, wenn Sie den Airflow-Stil {{ds}} oder {{ execution_date }} anstelle von hartcodierten Daten im obigen Beispiel verwenden möchten.
SQL verwendet den Parameter:
Um einen Backfill durchzuführen, definieren Sie eine Reihe von Parameterwerten und führen Backfills über diese in der UI oder über die API aus, anstatt sich auf implizites Scheduler-Catchup zu verlassen. Parameter werden einmal definiert und beim Auslösen eines Backfill-Laufs überschrieben.
💡Faustregel: Behandeln Sie Zeit als Daten; modellieren Sie sie als Parameter, übergeben Sie sie explizit an Tasks und steuern Sie Backfills über Parameterbereiche.
Migrationstipps
- Ersetzen Sie
{{ ds }}und zugehörige Makros durch Parameter (z. B. :run_date). - Machen Sie Tasks idempotent für einen gegebenen Parametersatz, damit Backfills sicher sind.
- Verwenden Sie Lakeflow Backfill-Läufe anstelle der Neuerstellung von Scheduler-gesteuerter Catchup-Logik.
4. Verzweigung und dynamisches Mapping zu Bedingungs- und For-Each-Tasks
Airflow: Verzweigung und dynamisches Task-Mapping
Verzweigung mit @task.branch:
Dynamisches Task-Mapping für Laufzeit-Fan-Out mit expand():
Lakeflow: Bedingungsaufgaben
Lakeflow Jobs verwendet Bedingungsaufgaben für datengesteuerte Verzweigungen
Das Notebook check_quality gibt einen Aufgabenwert aus:
Der Graph zeigt die Verzweigung explizit an, und die Entscheidungslogik wird über Daten (Aufgabenwerte) ausgedrückt und nicht über eingebettete Python-Kontrollflüsse.
💡Faustregel: Verwenden Sie Bedingungsaufgaben, wenn ein boolescher Ausdruck über Parameter oder Aufgabenwerte den Pfad bestimmt.
Lakeflow: For-Each-Aufgaben für Laufzeit-Fan-Out
For-Each-Aufgaben implementieren Fan-Out, wenn die Anzahl der Aufgaben von Laufzeitdaten abhängt.
Das Notebook generate_items:
Das Notebook process_item sieht das aktuelle Element als {{input}} (oder die entsprechende Laufzeitvariable, abhängig vom Sprach-Wrapper).
💡Faustregel: Verwenden Sie For-Each, wenn der Fan-Out durch Laufzeitdaten gesteuert wird; halten Sie Aufgaben statisch, wenn der Fan-Out zur Entwurfszeit festgelegt ist.
Migrationstipps
@task.branch→ Bedingungsaufgaben mit Aufgabenwerten oder Parametern.- Dynamische Aufgabenabbildung → For-Each-Aufgaben, gesteuert durch Aufgabenwerte oder Tabellen.
- Große Iterationsmetadaten → Tabellen/Volumes; kleine IDs/Indizes → Aufgabenwerte.
5. (Optional) Programmatische Generierung mit Python Asset Bundles
Viele Airflow-Bereitstellungen generieren DAGs dynamisch (ein DAG pro Tabelle oder SQL-Datei) und verwalten Umgebungsunterschiede durch Konventionen und Skripte. Python Asset Bundles bieten eine strukturierte Möglichkeit, Jobs und zugehörige Ressourcen programmatisch zu generieren.
Beispiel: Ein Job pro SQL-Datei:
Sie können dies mit Mutatoren kombinieren, um Benachrichtigungen, Ausführungsidentitäten oder Wiederholungsversuche pro Umgebung anzupassen und Standards zu zentralisieren, während die Jobdefinitionen in Python bleiben.
💡Faustregel: Verwenden Sie programmatische Generierung, um Plattformkonventionen zu kodifizieren, nicht um einmalige Hacks zu verbergen.
Nächste Schritte
Wenn Sie derzeit Airflow verwenden, wählen Sie einen DAG, der auf Sensoren, XComs oder dynamischer Aufgabenabbildung basiert, und implementieren Sie ihn mit einem Trigger, einer For-Each-Aufgabe und expliziten Parametern neu. Dies ist normalerweise ausreichend, um das Lakeflow Jobs-Gedankenmodell zu verinnerlichen.
Klonen und Ausführen der vollständigen funktionierenden Beispiele aus diesem Leitfaden
Erfahren Sie mehr über datenorientierte Orchestrierung
Erkunden Sie die Lakeflow Jobs-Dokumentation
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.