Wie Zalando eine vereinheitlichte Datengrundlage für KI und Analysen auf Databricks aufgebaut hat
Zalando trennt die Datenerstellung vom Datenkonsum, standardisiert Metrikdefinitionen und ermöglicht zuverlässige Abfragen in natürlicher Sprache über Dashboards und KI hinweg.
von Fabian Halkivaha, Mukrram Ur Rahman, Maria Vedenina und Timur Yüre
- Zalando hat eine vereinheitlichte Datengrundlage auf Databricks mit Unity Catalog, Metric Views und Genie aufgebaut, um Daten zu steuern, Metriken zu standardisieren und Analysen in natürlicher Sprache zu ermöglichen.\r\n* Sie zentralisierten die Geschäftslogik mithilfe von Metric Views („Metriken als Code“), wodurch inkonsistente Metrikdefinitionen über Dashboards, SQL und Pipelines hinweg gelöst wurden.\r\n* Durch die Verankerung von Genie in dieser semantischen Schicht liefert Zalando zuverlässige Abfragen in natürlicher Sprache, was die Zeit für die Beantwortung neuer Fragen verkürzt und das Vertrauen in die Ergebnisse verbessert.
Bei Zalando, einer führenden europäischen Online-Plattform für Mode und Lifestyle, orchestrieren wir ein riesiges digitales Ökosystem, das über 50 Millionen aktive Kunden mit mehr als 7.000 Marken und Partnern in ganz Europa verbindet. Jede Kundeninteraktion (Browsen, Bestellen, Zurücksenden usw.) erzeugt einen Datenimpuls, der unsere Entscheidungsfindung vorantreibt, von personalisierten Empfehlungen bis zur Logistikoptimierung.
Der Betrieb in dieser Größenordnung bringt einzigartige Herausforderungen mit sich. Unsere Datenlandschaft ist riesig und komplex, gespeist durch eine Microservices-Architektur, die Terabytes von Ereignissen in unseren zentralen Data Lake streamt. Obwohl diese Architektur uns ein schnelles Skalieren ermöglichte, erschwerte sie auch die Governance und verwischte die Unterscheidung zwischen Transaktionsdaten (tägliche Geschäftsabläufe) und Analysedaten (Erkenntnisse für die Entscheidungsfindung).
Jahrelang strebten wir einen verteilten Ansatz an, um dies durch die Dezentralisierung des Eigentums zu lösen, sodass Domänenteams (wie „Zahlungen“ oder „Logistik“) ihre eigenen Datenprodukte verwalten konnten. Eine zentralisierte Governance-Struktur ist in diesem Setup entscheidend, um eine überschaubare Arbeitslast für die Teams zu gewährleisten und Geschäftsrisiken vorzubeugen. Ohne eine einheitliche Schicht zur Definition der Wahrheit stehen wir zusätzlich vor der Herausforderung der Metrikdivergenz: Warum zeigt das Marketing-Dashboard einen anderen „Nettoumsatz“ als der Finanzbericht? Da Metriken in Silos existieren, ist es schwierig, sie zu verwalten und sicherzustellen, dass sie über ihren gesamten Lebenszyklus hinweg auffindbar und vertrauenswürdig für die Wiederverwendung sind.
In diesem Beitrag werden wir teilen, wie Zalando dies durch die Nutzung der gesamten Breite der Databricks Platform erreicht. Wir werden darauf eingehen, wie wir eine einheitliche semantische Schicht aufbauen, die die Lücke zwischen Transaktionsdaten und Analysedaten schließt. Im Einzelnen werden wir behandeln:
- Das Fundament: Wie Unity Catalog eine föderierte Governance und sichere Freigabe über Hunderte von Teams hinweg ermöglicht.
- Die semantische Schicht: Wie Unity Catalog Business Semantics, unterstützt durch Metric Views, es uns ermöglicht, Geschäftslogik einmal zu definieren und überall bereitzustellen.
- Die konversations-KI-gestützte Analytik: Wie wir die semantische Schicht über Genie nutzen, eine generative KI-gestützte Schnittstelle, die es Benutzern ermöglicht, Daten mithilfe natürlicher Sprache abzufragen, ohne SQL-Kenntnisse zu benötigen, und uns hilft, schnellere, datengesteuerte Entscheidungen zu treffen.
Das Fundament – Demokratisierung der Governance mit Unity Catalog
Um unsere riesige Datenlandschaft effektiv zu verwalten, haben wir uns entschieden, uns vom ressourcenzentrierten Gatekeeping zu lösen. In diesem Modell erforderte jeder neue Datensatz oder Konsument maßgeschneiderte IAM-Rollen, S3-Bucket-Richtlinien und Ausnahmebehandlungen. Wir identifizierten jedoch Herausforderungen: Berechtigungen waren über Tausende von Ressourcen fragmentiert, mühsam zu überprüfen und anfällig für Abweichungen. Daher wechselten wir zu einem identitätsbasierten Governance-Ansatz. Zugriffsentscheidungen werden als wiederverwendbare Richtlinien ausgedrückt, die an Personen und Gruppen gebunden sind. Sie werden konsistent über Datensätze hinweg bewertet und zentral durchgesetzt. Dies erleichtert die Verwaltung, Prüfung und Weiterentwicklung des Zugriffs, wenn sich Teams und Daten ändern. Wir haben dieses Fundament mit Databricks Unity Catalog aufgebaut und darauf ein föderiertes Zugriffssteuerungs-Framework implementiert.
Die Architektur
Wir haben ein Dual-Katalog-Muster entworfen, das die Erstellung von Daten streng von deren Konsum trennt, um sicherzustellen, dass Agilität nicht auf Kosten der Kontrolle geht:
- Private Kataloge für Autonomie: Jedes Domänenteam erstellt seinen eigenen privaten Katalog mithilfe einer internen Self-Service-Lösung. Innerhalb dieser privaten Umgebung kann das Team Schemata erstellen, Rohdaten aufnehmen und Tabellen in seinem eigenen Tempo aufbauen, ohne auf eine zentrale Genehmigung warten zu müssen. Dies dient als ihre „Fabrik“, optimiert für uneingeschränkte Entwicklung und Iteration. Die einzige Einschränkung, der sie begegnen, ist, dass alle hier erstellten Objekte ausschließlich vom Team selbst sowie einer begrenzten Anzahl verwandter Mitwirkender zugänglich sind. Dies bedeutet, dass die auf diesen Katalogen basierenden Anwendungsfälle nicht für den unternehmensweiten Einsatz bestimmt sind.
- Der zentrale gemeinsame Katalog für Governance: Für Anwendungsfälle, bei denen verschiedene Teams im gesamten Unternehmen diese Datensätze verwenden müssen, haben wir einen zentralen gemeinsamen Katalog eingeführt. Dieser fungiert als unternehmensweiter „Showroom“. Alle organisationsweit geteilten Daten müssen hier über Dynamic Views offengelegt werden, wo sie einer strengen zentralen Governance unterliegen. Sobald Daten hier landen, sind sie sofort über Unity Catalog auffindbar.
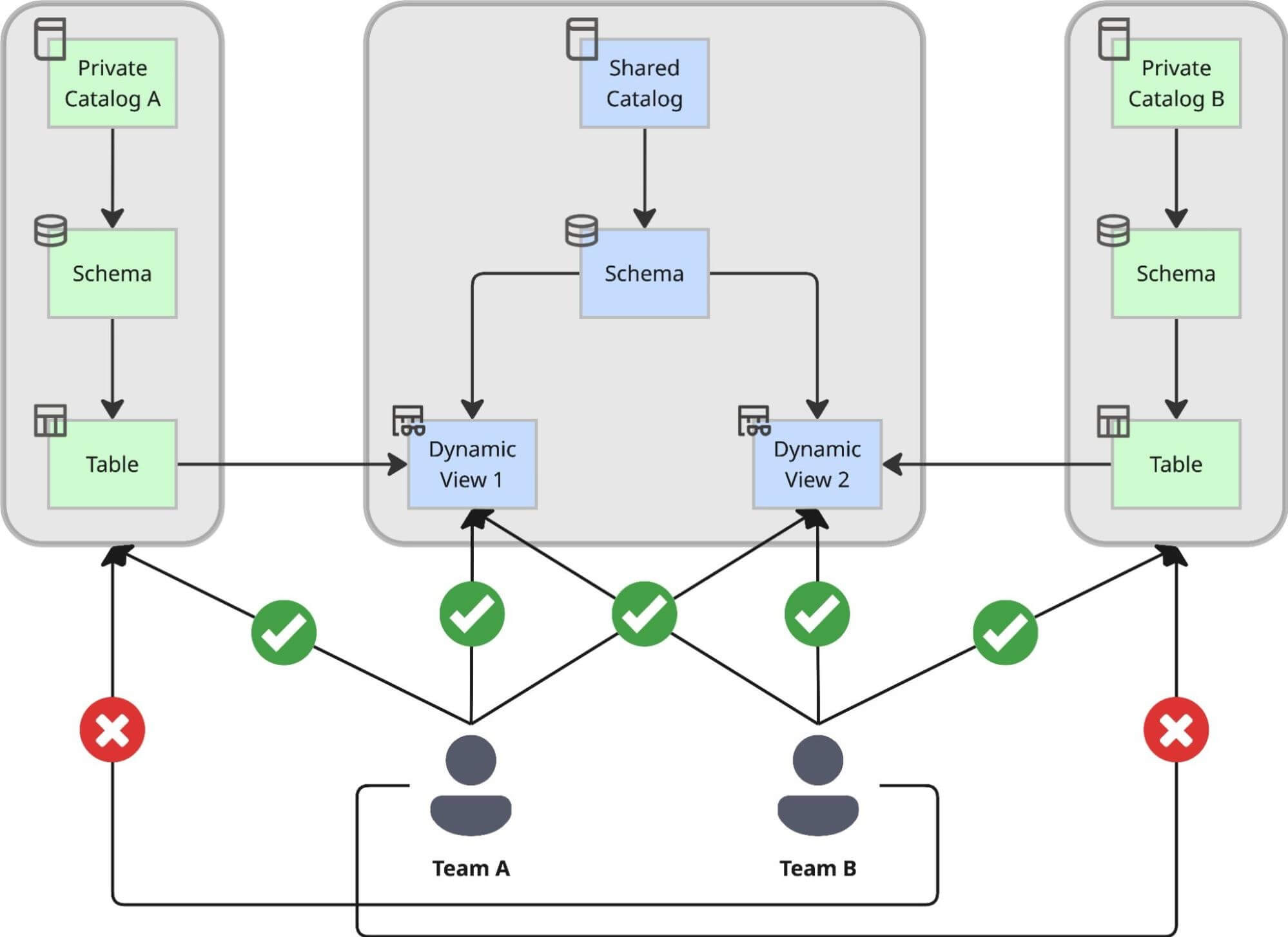
Warum Dynamic Views? Zentralisierte Kontrolle und Auditierbarkeit
Wir haben die strategische Entscheidung getroffen, Daten im gemeinsamen Katalog ausschließlich über Dynamic Views und nicht über direkte Tabellenzeiger offenzulegen. Dieser Ansatz ermöglicht es uns, einen zentralisierten Zugriffsprozess durchzusetzen, der komplexe Compliance-Regeln handhaben kann.
Durch die Verwendung von Dynamic Views als Bereitstellungsschicht haben wir erreicht:
- Benutzerdefinierte Prozessregeln für GDPR: Wir injizieren benutzerdefinierte Logik direkt in die View-Definition unter Verwendung von Funktionen wie is_account_group_member(). Dies gewährleistet eine robuste Zugriffskontrolle, indem überprüft wird, ob Benutzer die kartellrechtlichen Anforderungen erfüllen und zum Zugriff auf sensible Daten (wie E-Mail) berechtigt sind.
- Standardmäßig konformer Insider-Zugriff: Aufgrund eines automatisierten Klassifizierungsprozesses wird jede Spalte klassifiziert. Alle nicht-sensiblen Spalten sind standardmäßig für eine Vielzahl von Benutzern zugänglich, was die Datendemokratisierung und Entscheidungsfindung beschleunigt.
- Vollständige Auditierbarkeit: Da der gesamte teamübergreifende Zugriff über diese zentral verwalteten Views erfolgt, führen wir eine vollständige Audit-Spur der Zugriffsentscheidungen. Wir wissen genau, welche Richtlinie einem Benutzer Zugriff auf eine bestimmte Zeile oder Spalte gewährt hat.
- Zuverlässige Erkenntnisse: Um die Generierung falscher Daten oder irreführender Zahlen aufgrund partieller Aggregation zu verhindern, schlägt jede Abfrage, die versucht, auf eine sensible Spalte ohne die erforderliche spezifische Autorisierung zuzugreifen, explizit mit einem „permission denied“-Fehler fehl.
Governance als Code: Der Freigabe-Workflow
Um diesen Prozess effizient zu gestalten, haben wir den Freigabe-Workflow mithilfe eines GitOps-Ansatzes automatisiert:
- Pull Request zur Freigabe: Wenn ein Team bereit ist, einen Datensatz aus seinem privaten Katalog im gemeinsamen Katalog freizugeben, erstellt es kein Ticket. Es öffnet einen Pull Request (PR) in einem zentralen Repository mit einer Konfigurationsdatei, die auf seine Quelltabelle verweist.
- Genehmigungsregeln: Der Pull Request wird auf Freigabekriterien, Einzigartigkeit und andere wichtige Entscheidungsfaktoren geprüft.
- Automatisierte Validierung und Bereitstellung: Sobald der PR genehmigt und zusammengeführt wurde, generiert unser Plattformdienst automatisch die entsprechende Dynamic View im zentralen gemeinsamen Katalog und klassifiziert die Spalten automatisch.
Dieses Setup ermöglicht es uns, die Agilität verteilter Teams aufrechtzuerhalten und gleichzeitig einen zentralisierten, vollständig auditierbaren Governance-Standard durchzusetzen, der unsere Daten leicht auffindbar, sicher und konform hält.
Die semantische Schicht – „Die Wahrheit“ mit Metric Views definieren
Mit dem sicheren Fundament, das wir für den Datenzugriff geschaffen haben, konzentrieren wir uns nun darauf, eine konsistente Dateninterpretation sicherzustellen.
Wir zentralisieren aktiv Geschäftslogik, die zuvor über den Daten-Stack fragmentiert war:
- BI-Tools: Metrikdefinitionen, die in einzelne Dashboards eingebettet sind
- SQL-Skripte: Logik, die über Notebooks und Pipelines dupliziert ist
- Materialisierte Tabellen: Vorberechnete Metriken, die an spezifische Anwendungsfälle gebunden sind
Wir vereinheitlichen Tausende von Metrikdefinitionen in einer einzigen, verwalteten Schicht. Dies ermöglicht es uns, den „Logik-Lock-in“ zu durchbrechen: Die Definition des „Net Merchandise Value“ (NMV) in einem Dashboard-Tool wird für einen Datenwissenschaftler, der in einem Notebook arbeitet, oder für einen KI-Bot, der eine Benutzerfrage beantwortet, vollständig zugänglich.
Um dies zu erreichen, führen wir Databricks Metric Views als unsere vereinheitlichte semantische Schicht ein. Dies entkoppelt entscheidend die Definition einer Metrik von ihrer Nutzung und garantiert, dass Benutzer genau dasselbe berechnete Ergebnis erhalten, egal ob sie über einen SQL-Editor, ein Dashboard oder einen KI-Agenten abfragen. In der Praxis stellt dies sicher, dass sowohl technische als auch nicht-technische Benutzer dieselben Metrikdefinitionen verwenden.
Metrik als Code: Der Metrik-Lebenszyklus
Wir implementieren einen rigorosen „Metrik als Code“-Ansatz für unsere semantische Schicht, genau wie wir GitOps für die Datenfreigabe in Unity Catalog nutzen. Wir stellen die Konsistenz über alle Teams hinweg sicher, indem wir jede KPI-Definition zentralisieren und standardisieren.
Unsere Architektur verwaltet den gesamten Lebenszyklus einer Metrik:
- Definition in YAML: Metriken werden in Code (YAML-Dateien) definiert, die in einem zentralen Repository gespeichert sind. Dies erfasst nicht nur die Aggregationslogik (z. B. SUM(amount)) und Beziehungen zwischen Tabellen, Fakten und Metriken, sondern auch kritische Metadaten wie Eigentümerschaft, Beschreibung und Formatierung.
- Automatisierte Validierung: Bevor eine Metrik in die Produktion übernommen werden kann, führt unsere CI/CD-Pipeline eine Reihe automatisierter Prüfungen durch. Dazu gehören:
- Einzigartigkeit: Sicherstellen, dass keine Metrik mit demselben Namen oder derselben Definition bereits existiert.
- Konformität: Durchsetzen von Namenskonventionen (z. B. snake_case), um die Auffindbarkeit zu gewährleisten.
- Eigentümerschaft: Überprüfen, ob eine gültige Team-ID an die Metrik angehängt ist, um die Verantwortlichkeit sicherzustellen.
- Mensch in der Schleife: Durch das Vier-Augen-Prinzip, wird jeder Pull Request von Fachexperten überprüft.
- Individuelle Entwicklungsumgebungen: Um Teams ein schnelles Iterieren zu ermöglichen, während sie in einer produktionsnahen Umgebung testen, stellt jeder Pull Request die Metric Views in einer separaten Testumgebung bereit. Diese Einrichtung ermöglicht es, die Auswirkungen der Änderung sofort zu überprüfen.
Aufbau eines Sternschemas für das Lakehouse
Im Hintergrund verlassen wir uns auf etablierte Prinzipien der dimensionalen Modellierung. Jede Metric View in unserer Produktionsumgebung fungiert als Standardschnittstelle, die typischerweise 1-zu-1 mit unseren Faktentabellen abgebildet wird, während sie Attribute von konformen Dimensionstabellen erbt.
Diese Einrichtung ist entscheidend für unsere Skalierung. Indem wir sicherstellen, dass Metric Views auf den vertrauenswürdigen Daten in unserem Shared Catalog (aus Abschnitt 1) aufbauen, gewährleisten wir, dass die semantische Schicht alle Sicherheits- und Compliance-Vorteile der zugrunde liegenden Plattform erbt. Ein Benutzer, der eine Metrikansicht abfragt, unterliegt weiterhin denselben Zeilen- und Spaltenberechtigungen sowie Zugriffsregeln, die wir in der Unity Catalog-Schicht definiert haben. Wir werden diese Einrichtung später in diesem Jahr auch mit einer zusätzlichen Autorisierungsschicht über die Metric Views erweitern, sodass Benutzer keinen Rohdaten-Zugriff mehr benötigen, sondern nur noch Zugriff auf Metrik- und Dimensionsebene.
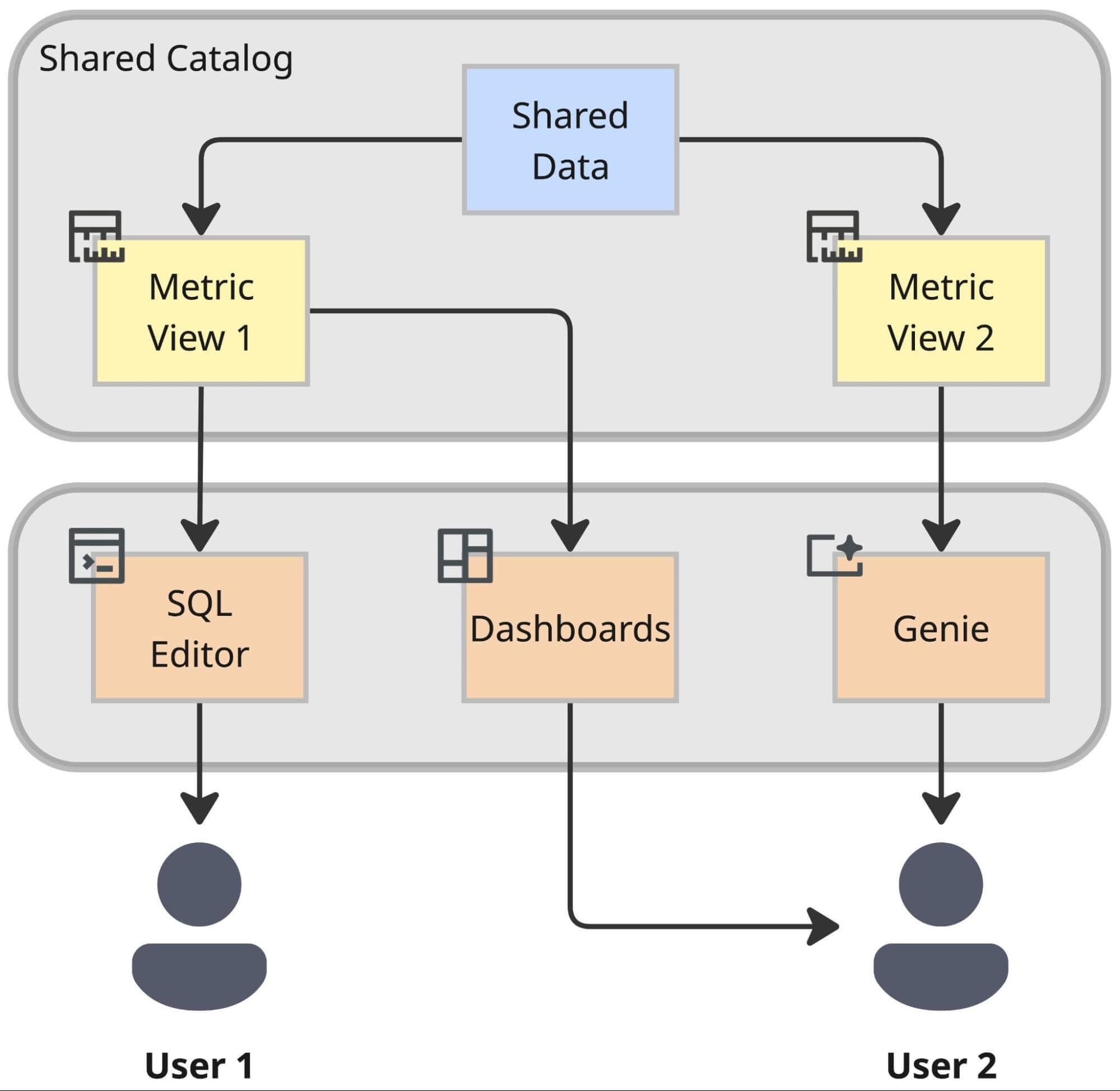
Das Ergebnis: Interoperabilität
Der Vorteil dieser Architektur ist die Interoperabilität. Indem wir die Geschäftslogik aus proprietären BI-Tools in die semantische Schicht des Lakehouse verlagern, bereiten wir uns auf die Zukunft vor. Eine einmal in dieser Schicht definierte Metrik wird sofort verfügbar für:
- Databricks Dashboards für Standardberichte.
- Genie für KI-gestützte Analysen in einer konversationellen Schnittstelle unter Verwendung natürlicher Sprache.
- Externe Tools und Anwendungen über standardisierte Konnektoren.
Diese Zentralisierung ist der entscheidende Schritt für unseren nächsten großen Schritt: Unternehmen zu befähigen, mit ihren Daten zu „sprechen“.
Die konversationelle KI-gestützte Analyse
Dashboards sind unerlässlich, um alltägliche, wiederkehrende Fragen zu beantworten. Die Geschwindigkeit des Geschäfts übertrifft jedoch oft die Fähigkeit des Standardreportings, alles zu erfassen. Zum Beispiel könnte ein Category Manager wissen wollen: „Welche Sneaker-Marken hatten eine hohe Klickrate, schafften es aber letzte Woche in Deutschland nicht unter die Top 10 nach Anzahl der verkauften Artikel?“ Die Beantwortung neuartiger Fragen wie dieser, die nicht durch bestehende Standardberichte abgedeckt werden, erforderte häufig den Bau eines neuen Dashboards. Selbst mit Self-Service-Tools blieb eine erhebliche „Time-to-Insight“-Verzögerung bestehen. Benutzer mussten den richtigen Datensatz finden, Widgets konfigurieren und Filter anwenden, bevor sie eine Antwort erhalten konnten. Dies führte oft zu einmaligen Dashboards, was zur Dashboard-Ausbreitung und reduzierten Auffindbarkeit beitrug.
Um die Benutzererfahrung zu optimieren, haben wir mehrere „Talk-to-Data“-Lösungen evaluiert, die LLM-gestützte konversationelle Schnittstellen anbieten, oft als KI-Chatbots bezeichnet. Genie schnitt am besten ab, da es auf einer vereinheitlichten semantischen Schicht basiert, während Lösungen ohne diese Schicht Schwierigkeiten hatten, präzises SQL für komplexe Geschäftslogik zu generieren.
Deshalb erwies sich die Einführung von Metric Views als entscheidend für die konversationelle KI-gestützte Analyse wie Genie. Indem wir Genie auf die vorab etablierten Metric Views (wie in Abschnitt 2 beschrieben) ausrichteten, erzielten wir einen entscheidenden Durchbruch: konsistente, zuverlässige Antworten, die auf geregelten Geschäftsdefinitionen basieren.
Warum Metric Views die KI-Genauigkeit drastisch erhöht
Die größte Hürde bei der Einführung von KI in der Analyse ist Vertrauen. Wenn ein LLM eine SQL-Abfrage halluziniert, sind die Zahlen falsch, und die Benutzer verlieren das Vertrauen.
Genie löst dies, indem es mit unserer semantischen Schicht in Metric Views arbeitet.
- Kein Rätselraten: Wenn ein Benutzer nach „NMV“ (Net Merchandise Value) fragt, versucht Genie nicht, es aus Rohdaten-Tabellen zu berechnen. Es erkennt „NMV“ als eine geregelte Metrik in unserer Metrikansicht und fragt einfach die vordefinierte Logik ab. Somit reduziert die Metrikansicht die Komplexität der Generierung einer SQL-Anweisung, was zu einer höheren Genauigkeit führt.
- Kontextsensitiv: Wir haben stark in die Anreicherung unserer Unity Catalog-Metadaten investiert, indem wir Beschreibungen, Synonyme und Beispielabfragen hinzugefügt haben. Genie nutzt diesen Kontext, um zu verstehen, dass, wenn ein Benutzer „Stornierungen“ sagt, er speziell Bestellungen meint, die vor dem Versand storniert wurden, passend zu unserer internen Definition.
Die Frontline stärken
Wir haben Genie mit nicht-technischen Teams wie Merchandisern, Einkäufern und Preisanalysten getestet, die sich historisch auf Excel-Exporte oder BI-Tools verlassen hatten. Das Feedback war sofort: Benutzer konnten schnelle Antworten auf detaillierte Fragen (z. B. spezifische Marktleistung gepaart mit spezifischem Gerätetyp) erhalten, ohne eine einzige Zeile SQL kennen oder Zeit mit dem Erstellen einer benutzerdefinierten Berichtsansicht verbringen zu müssen.
Die Einführung des neuen Agent Mode hat die Benutzererfahrung erheblich verbessert. Der Agent Mode analysiert Daten automatisch, um die Grundursache von Analyseergebnissen zu ermitteln, sodass Benutzer einfach fragen können, „warum“ etwas passiert ist. Bei Zalando könnte dies die Vorbereitungszeit für unsere regelmäßigen Performance-Meetings – in denen kritische Steuerungsentscheidungen getroffen werden – von mehreren Stunden auf nur wenige Minuten reduzieren.
Allerdings kann Genie mit seiner umfangreichen Funktionalität auch teuer werden, wenn es nicht korrekt eingerichtet wird, zum Beispiel bei nicht aggregierten Tabellen und Ansichten. Deshalb ist es entscheidend, die Daten und den Kontext, den Genie verwendet, sorgfältig zu kuratieren. Darüber hinaus erkennen wir das Potenzial für weitere Verbesserungen, wie zum Beispiel den Vorteil der Einführung einer vollständigen Genie-Versionskontrolle und der Ermöglichung programmatischer Updates von Genie-Konfigurationen, woran Databricks bereits arbeitet und was derzeit bereits teilweise unterstützt wird.
Genie für die unternehmensweite Einführung skalieren
Wir behandeln Genie nicht nur als Sandbox-Experiment; wir integrieren es in unsere Unternehmensabläufe. Unsere Schwerpunkte für die Skalierung umfassen:
- Governance etablieren: Kuratierte Genie-Spaces werden durch verwaltete und ordnungsgemäß gepflegte Metric Views untermauert.
- Datenzuverlässigkeit sicherstellen: Wir arbeiten mit datenverantwortlichen Teams zusammen, um kuratierte Genie-Spaces zu etablieren. Diese Spaces bieten analytische Darstellungen ihrer Daten über Metric Views, wobei die Datenqualität von den Datenverantwortlichen selbst aufrechterhalten wird.
- Integration mit Agent Bricks oder Nutzung von Genies in Databricks One: Wir planen, diese kuratierten Genie-Spaces entweder mit Agent Bricks oder mit Genies innerhalb von Databricks One zu orchestrieren. Dieser Ansatz stellt sicher, dass Benutzer einen einzigen, vereinheitlichten Zugangspunkt für all ihre Datenanfragen haben.
Durch die Kombination der Governance von Unity Catalog, der Standardisierung der Geschäftslogik durch Metric Views und der Intelligenz von Genie bauen wir eine Datenkultur auf, in der "die Daten befragen" so einfach ist wie einen Kollegen zu fragen.
Vielen Dank an Merve Karali, Tobias Efinger und Roberto Bruno Martins für ihre Beiträge zu diesem Beitrag.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.