Verbesserung von Retrieval und RAG durch Finetuning von Embedding-Modellen
von Jacob Portes, Andrew Drozdov, Erica Ji Yuen, Vincent Chen, Sean Kulinski, Milo Cress, Colton Peltier, Sam Havens, Michael Carbin, Vitaliy Chiley und Connor Jennings
- Wie das Finetuning von Embedding-Modellen die Abrufgenauigkeit und RAG-Genauigkeit verbessert
- Wichtige Leistungssteigerungen über Benchmarks hinweg
- Erste Schritte mit dem Finetuning von Embeddings auf Databricks
Feinabstimmung von Embedding-Modellen für besseres Retrieval und RAG
Kurz gesagt: Die Feinabstimmung eines Embedding-Modells auf domänenspezifischen Daten kann die Genauigkeit von Vektorsuchen und Retrieval-Augmented Generation (RAG) erheblich verbessern. Mit Databricks ist es einfach, Embedding-Modelle feinabzustimmen, bereitzustellen und zu bewerten, um das Retrieval für Ihren spezifischen Anwendungsfall zu optimieren – und das ganz ohne manuelles Labeling durch die Nutzung synthetischer Daten.
Warum das wichtig ist: Wenn Ihr Vektorsuch- oder RAG-System nicht die besten Ergebnisse liefert, ist die Feinabstimmung eines Embedding-Modells ein einfacher, aber wirkungsvoller Weg, um die Leistung zu steigern. Egal, ob Sie mit Finanzdokumenten, Wissensdatenbanken oder internen Code-Dokumentationen arbeiten, die Feinabstimmung kann Ihnen relevantere Suchergebnisse und bessere nachgelagerte LLM-Antworten liefern.
Was wir herausgefunden haben: Wir haben zwei Embedding-Modelle auf drei Unternehmensdatensätzen feinabgestimmt und getestet und deutliche Verbesserungen bei den Retrieval-Metriken (Recall@10) und der nachgelagerten RAG-Leistung festgestellt. Das bedeutet, dass die Feinabstimmung ein echter Leistungsträger für die Genauigkeit sein kann, ohne dass manuelles Labeling erforderlich ist – es werden nur Ihre vorhandenen Daten genutzt.
Möchten Sie die Feinabstimmung von Embeddings ausprobieren? Wir bieten eine Referenzlösung, die Ihnen den Einstieg erleichtert. Databricks macht Vektorsuche, RAG, Reranking und die Feinabstimmung von Embeddings einfach. Kontaktieren Sie Ihren Databricks Account Executive oder Solutions Architect für weitere Informationen.
{kind=link}
Warum Embeddings feinabstimmen?
Embedding-Modelle sind die Grundlage moderner Vektorsuch- und RAG-Systeme. Ein Embedding-Modell wandelt Text in Vektoren um, wodurch relevante Inhalte anhand der Bedeutung und nicht nur anhand von Schlüsselwörtern gefunden werden können. Allerdings sind Standardmodelle nicht immer für Ihre spezifische Domäne optimiert – hier kommt die Feinabstimmung ins Spiel.
Die Feinabstimmung eines Embedding-Modells mit domänenspezifischen Daten hilft auf verschiedene Weise:
- Verbesserung der Retrieval-Genauigkeit: Benutzerdefinierte Embeddings verbessern die Suchergebnisse, indem sie mit Ihren Daten übereinstimmen.
- Steigerung der RAG-Leistung: Besseres Retrieval reduziert Halluzinationen und ermöglicht fundiertere generative KI-Antworten.
- Optimierung von Kosten und Latenz: Ein kleineres, feinabgestimmtes Modell kann manchmal größere, teurere Alternativen übertreffen.
In diesem Blogbeitrag zeigen wir, dass die Feinabstimmung eines Embedding-Modells ein effektiver Weg ist, um die Retrieval- und RAG-Leistung für aufgabenbezogene Unternehmensanwendungsfälle zu verbessern.
Ergebnisse: Feinabstimmung funktioniert
Wir haben zwei Embedding-Modelle (gte-large-en-v1.5 und e5-mistral-7b-instruct) auf synthetischen Daten feinabgestimmt und sie auf drei Datensätzen unserer Domain Intelligence Benchmark Suite (DIBS) (FinanceBench, ManufactQA und Databricks DocsQA) evaluiert. Anschließend verglichen wir sie mit dem text-embedding-3-large von OpenAI.
Wichtigste Erkenntnisse:
- Die Feinabstimmung verbesserte die Retrieval-Genauigkeit über alle Datensätze hinweg und übertraf die Basismodelle oft deutlich.
- Feinabgestimmte Embeddings schnitten in vielen Fällen genauso gut oder besser ab als Reranking und erwiesen sich somit als starke eigenständige Lösung.
- Besseres Retrieval führte zu besserer RAG-Leistung auf FinanceBench, was die Vorteile für den gesamten End-to-End-Prozess zeigt.
Retrieval-Leistung
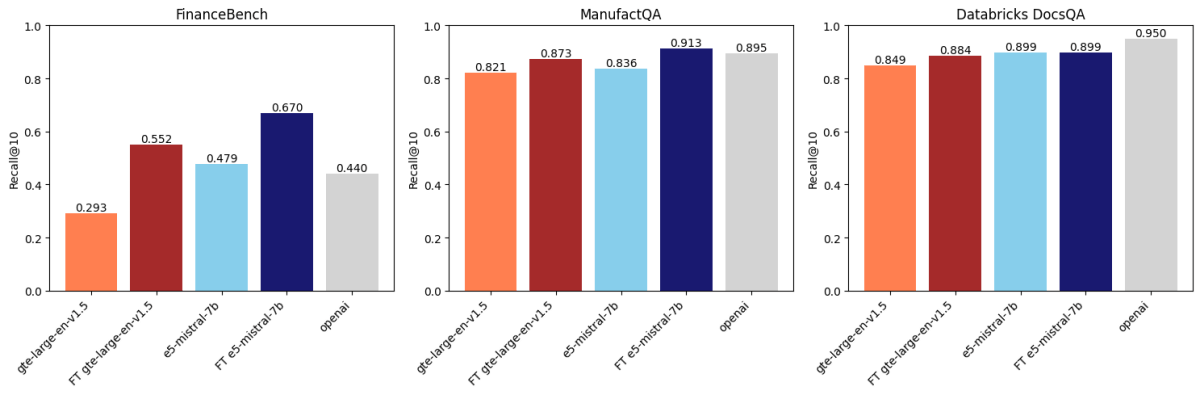
Nach dem Vergleich über drei Datensätze hinweg stellten wir fest, dass die Feinabstimmung von Embeddings die Genauigkeit bei zwei dieser Datensätze verbessert. Abbildung 1 zeigt, dass bei FinanceBench und ManufactQA feinabgestimmte Embeddings ihre Basisversionen übertrafen und manchmal sogar das API-Modell von OpenAI (hellgrau) übertrafen. Bei Databricks DocsQA übertrifft die Genauigkeit von OpenAI text-embedding-3-large jedoch alle feinabgestimmten Modelle. Dies liegt möglicherweise daran, dass das Modell auf öffentlichen Databricks-Dokumentationen trainiert wurde. Dies zeigt, dass die Feinabstimmung zwar effektiv sein kann, aber stark vom Trainingsdatensatz und der Bewertungsaufgabe abhängt.
Feinabstimmung vs. Reranking
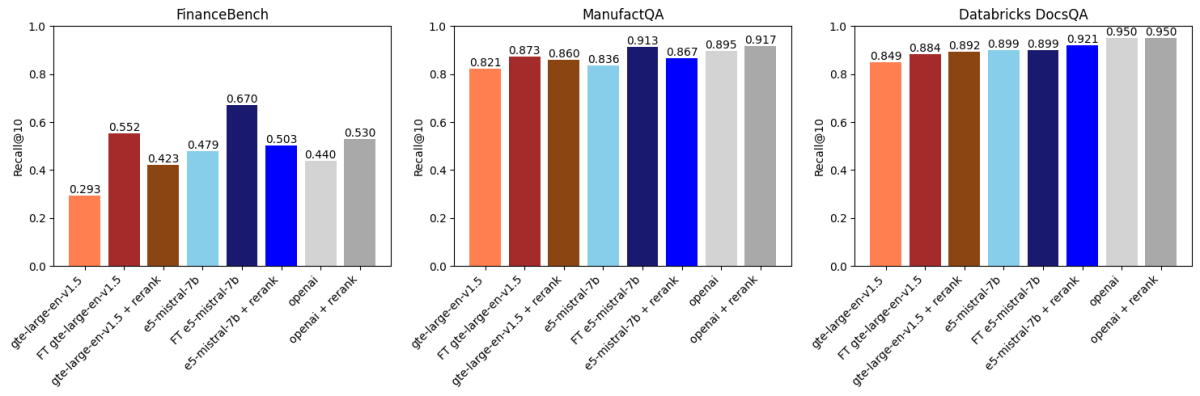
Anschließend verglichen wir die obigen Ergebnisse mit API-basiertem Reranking unter Verwendung von voyageai/rerank-1 (Abbildung 2). Ein Reranker nimmt typischerweise die Top-k-Ergebnisse eines Embedding-Modells, ordnet diese Ergebnisse nach Relevanz zur Suchanfrage neu und gibt dann die neu geordneten Top-k zurück (in unserem Fall k=30 gefolgt von k=10). Dies funktioniert, weil Reranker in der Regel größere, leistungsfähigere Modelle als Embedding-Modelle sind und auch die Interaktion zwischen der Anfrage und dem Dokument auf eine ausdrucksstärkere Weise modellieren.
{kind=link}
Wir stellten fest:
- Die Feinabstimmung von gte-large-en-v1.5 übertraf das Reranking bei FinanceBench und ManufactQA.
- OpenAIs text-embedding-3-large profitierte vom Reranking, die Verbesserungen waren jedoch bei einigen Datensätzen geringfügig.
- Bei Databricks DocsQA hatte Reranking einen geringeren Einfluss, aber die Feinabstimmung brachte dennoch Verbesserungen, was die datensatzabhängige Natur dieser Methoden zeigt.
Reranker verursachen in der Regel zusätzliche Inferenzlatenz und Kosten pro Abfrage im Vergleich zu Embedding-Modellen. Sie können jedoch mit vorhandenen Vektordatenbanken verwendet werden und sind in einigen Fällen kostengünstiger als das erneute Einbetten von Daten mit einem neueren Embedding-Modell. Die Entscheidung für oder gegen die Verwendung eines Rerankers hängt von Ihrer Domäne und Ihren Latenz-/Kostenanforderungen ab.
Feinabstimmung verbessert die RAG-Leistung
Bei FinanceBench führte besseres Retrieval direkt zu besserer RAG-Genauigkeit in Kombination mit GPT-4o (siehe Anhang). In Domänen, in denen das Retrieval bereits stark war, wie z. B. bei Databricks DocsQA, brachte die Feinabstimmung jedoch nicht viel – was hervorhebt, dass die Feinabstimmung am besten funktioniert, wenn das Retrieval ein klares Engpass ist.
Wie wir Embedding-Modelle feinabgestimmt und evaluiert haben
Hier sind einige der technischeren Details zur Generierung synthetischer Daten, zur Feinabstimmung und zur Bewertung.
Embedding-Modelle
Wir haben zwei Open-Source-Embedding-Modelle feinabgestimmt:
- gte-large-en-v1.5 ist ein beliebtes Embedding-Modell, das auf BERT Large basiert (434 Mio. Parameter, 1,75 GB). Wir haben uns entschieden, Experimente mit diesem Modell durchzuführen, da es eine moderate Größe und eine offene Lizenz hat. Dieses Embedding-Modell wird auch derzeit von der Databricks Foundation Model API unterstützt.
- e5-mistral-7b-instruct gehört zu einer neueren Klasse von Embedding-Modellen, die auf starken LLMs basieren (in diesem Fall Mistral-7b-instruct-v0.1). Obwohl e5-mistral-7b-instruct bei Standard-Embedding-Benchmarks wie MTEB besser abschneidet und längere und nuanciertere Prompts verarbeiten kann, ist es wesentlich größer als gte-large-en-v1.5 (da es 7 Milliarden Parameter hat) und etwas langsamer und teurer im Betrieb.
Anschließend verglichen wir sie mit dem text-embedding-3-large von OpenAI.
Evaluierungsdatensätze
Wir haben alle Modelle auf den folgenden Datensätzen aus unserer Domain Intelligence Benchmark Suite (DIBS) evaluiert: FinanceBench, ManufactQA und Databricks DocsQA.
| Datensatz | Beschreibung | # Abfragen | # Korpus |
|---|---|---|---|
| FinanceBench | Fragen zu SEC 10-K-Dokumenten, die von menschlichen Experten erstellt wurden. Die Abfrage erfolgt über einzelne Seiten aus einer Obermenge von 360 SEC 10-K-Einreichungen. | 150 | 53.399 |
| ManufactQA | Fragen und Antworten, die aus öffentlichen Foren eines Herstellers von elektronischen Geräten entnommen wurden. | 6.787 | 6.787 |
| Databricks DocsQA | Fragen, die auf �öffentlich zugänglichen Databricks-Dokumentationen basieren und von Databricks-Experten erstellt wurden. | 139 | 7.561 |
Wir berichten über Recall@10 als unsere Hauptmetrik für die Abfrage; diese misst, ob das richtige Dokument unter den Top 10 abgerufenen Dokumenten ist.
Der Goldstandard für die Qualität von Embedding-Modellen ist der MTEB-Benchmark, der Abfrageaufgaben wie BEIR sowie viele andere Nicht-Abfrageaufgaben umfasst. Während Modelle wie gte-large-en-v1.5 und e5-mistral-7b-instruct auf MTEB gut abschneiden, waren wir neugierig, wie sie bei unseren internen Unternehmensaufgaben abschneiden.
Trainingsdaten
Wir haben separate Modelle auf synthetischen Daten trainiert, die auf die einzelnen Benchmarks zugeschnitten sind:
| Trainingsdatensatz | Beschreibung | # Eindeutige Beispiele |
|---|---|---|
| Synthetischer FinanceBench | Abfragen, die aus 2.400 SEC 10-K-Dokumenten generiert wurden | ~6.000 |
| Synthetische Databricks Docs QA | Abfragen, die aus öffentlichen Databricks-Dokumentationen generiert wurden. | 8.727 |
| ManufactQA | Abfragen, die aus PDFs zur Elektronikfertigung generiert wurden | 14.220 |
Um den Trainingsdatensatz für jede Domäne zu generieren, haben wir vorhandene Dokumente verwendet und Beispielabfragen generiert, die auf dem Inhalt jedes Dokuments basieren, unter Verwendung von LLMs wie Llama 3 405B. Die synthetischen Abfragen wurden dann von einem LLM-as-a-judge (GPT4o) auf Qualität geprüft. Die gefilterten Abfragen und ihre zugehörigen Dokumente wurden dann als kontrastierende Paare für das Finetuning verwendet. Wir haben In-Batch-Negatives für das kontrastierende Training verwendet, aber das Hinzufügen von Hard Negatives könnte die Leistung weiter verbessern (siehe Anhang).
Hyperparameter-Tuning
Wir haben Sweeps durchgeführt über:
- Lernrate, Batch-Größe, Softmax-Temperatur
- Epochenanzahl (1-3 Epochen getestet)
- Variationen von Abfrage-Prompts (z. B. "Query:" vs. anweisungsbasierte Prompts)
- Pooling-Strategie (Mean-Pooling vs. Last-Token-Pooling)
Das gesamte Finetuning wurde mit den Open-Source-Bibliotheken mosaicml/composer, mosaicml/llm-foundry und mosaicml/streaming auf der Databricks-Plattform durchgeführt.
So verbessern Sie Vektorsuche und RAG auf Databricks
Finetuning ist nur ein Ansatz zur Verbesserung der Leistung von Vektorsuche und RAG; wir listen im Folgenden einige zusätzliche Ansätze auf.
Für bessere Abfrageergebnisse:
- Verwenden Sie ein besseres Embedding-Modell: Viele Benutzer arbeiten unwissentlich mit veralteten Embeddings. Der einfache Austausch durch ein leistungsfähigeres Modell kann sofortige Gewinne erzielen. Überprüfen Sie die MTEB-Rangliste für Top-Modelle.
- Probieren Sie hybride Suche: Kombinieren Sie dichte Embeddings mit schlüsselwortbasierter Suche für verbesserte Genauigkeit. Databricks AI Search macht dies mit einer Ein-Klick-Lösung einfach.
- Verwenden Sie einen Reranker: Ein Reranker kann Ergebnisse verfeinern, indem er sie nach Relevanz neu ordnet. Databricks bietet dies als integrierte Funktion (derzeit in privater Vorschau). Wenden Sie sich an Ihren Account Executive, um es auszuprobieren.
Für besseres RAG:
- Optimieren Sie Ihre Prompts: Kleine Änderungen an LLM-Prompts können die Antworten dramatisch verbessern. DSPy kann helfen, diesen Prozess zu automatisieren (siehe Erstellen von GenAI-Apps mit DSPy auf Databricks).
- Aktualisieren Sie Ihr LLM: Wenn die Abfrageergebnisse gut sind, die Antworten jedoch schwach, sollten Sie die Verwendung eines besseren generativen Modells in Betracht ziehen.
- Finetunen Sie ein LLM: Wenn Ihre Domäne einzigartig ist und Sie genügend Daten haben, kann das Finetuning eines Modells wie Llama 3 die RAG-Qualität weiter verbessern. Weitere Details finden Sie unter Databricks Model Training: Finetune Ihr LLM auf Databricks für spezifische Aufgaben und Wissen.
Erste Schritte mit Finetuning auf Databricks
Das Finetuning von Embeddings kann ein einfacher Gewinn für die Verbesserung von Vektorsuche und RAG in Ihren KI-Systemen sein. Auf Databricks können Sie:
- Embedding-Modelle auf skalierbarer Infrastruktur finetunen und bereitstellen.
- Integrierte Tools für Vektorsuche, Reranking und RAG verwenden.
- Schnell verschiedene Modelle testen, um herauszufinden, was für Ihren Anwendungsfall am besten funktioniert.
Bereit zum Ausprobieren? Wir haben eine Referenzlösung entwickelt, um das Finetuning zu erleichtern – wenden Sie sich an Ihren Databricks Account Executive oder Solutions Architect, um Zugang zu erhalten.
Anhang
Tabelle 1: Vergleich von gte-large-en-v1.5, e5-mistral-7b-instruct und text-embedding-3-large. Gleiche Daten wie Abbildung 1.
Generierung synthetischer Trainingsdaten
Für alle Datensätze waren die Abfragen im Trainingsdatensatz nicht identisch mit den Abfragen im Testdatensatz. Bei Databricks DocsQA (aber nicht bei FinanceBench oder ManufactQA) waren die Dokumente, die zur Generierung synthetischer Abfragen verwendet wurden, jedoch dieselben Dokumente, die im Evaluationsdatensatz verwendet wurden. Der Schwerpunkt unserer Studie liegt auf der Verbesserung des Retrievals für bestimmte Aufgaben und Domänen (im Gegensatz zu einem Zero-Shot, generalisierbaren Embedding-Modell); wir betrachten dies daher als einen gültigen Ansatz für bestimmte Produktionsanwendungsfälle. Für FinanceBench und ManufactQA überschnitten sich die Dokumente, die zur Generierung synthetischer Daten verwendet wurden, nicht mit dem für die Evaluation verwendeten Korpus.
Es gibt verschiedene Möglichkeiten, negative Passagen für das kontrastive Training auszuwählen. Sie können entweder zufällig ausgewählt oder vordefiniert werden. Im ersten Fall werden die negativen Passagen innerhalb des Trainings-Batches ausgewählt; diese werden oft als "In-Batch-Negatives" oder "Soft Negatives" bezeichnet. Im zweiten Fall wählt der Benutzer vorab Textbeispiele aus, die semantisch schwierig sind, d. h. sie sind potenziell mit der Abfrage verwandt, aber leicht falsch oder irrelevant. Dieser zweite Fall wird manchmal als "Hard Negatives" bezeichnet. In dieser Arbeit haben wir einfach In-Batch-Negatives verwendet; die Literatur deutet darauf hin, dass die Verwendung von Hard Negatives wahrscheinlich zu noch besseren Ergebnissen führen würde.
Details zum Finetuning
Für alle Finetuning-Experimente wurde die maximale Sequenzlänge auf 2048 eingestellt. Wir haben dann alle Checkpoints evaluiert. Für alle Benchmarks wurden die Korpusdokumente auf 2048 Tokens gekürzt (nicht geclustert), was eine angemessene Einschränkung für unsere speziellen Datensätze darstellte. Wir wählen die stärksten Baselines auf jedem Benchmark nach dem Sweeping über Query-Prompts und Pooling-Strategie aus.
Verbesserung der RAG-Leistung
Ein RAG-System besteht sowohl aus einem Retriever als auch aus einem generativen Modell. Der Retriever wählt eine Reihe von Dokumenten aus, die für eine bestimmte Abfrage relevant sind, und übergibt sie dann an das generative Modell. Wir haben die besten finetuned gte-large-en-v1.5-Modelle ausgewählt und sie für die erste Retrieval-Stufe eines einfachen RAG-Systems verwendet (gemäß dem allgemeinen Ansatz, der in Long Context RAG Performance of LLMs und The Long Context RAG Capabilities of OpenAI o1 and Google Gemini beschrieben wird). Insbesondere haben wir k=10 Dokumente mit jeweils einer maximalen Länge von 512 Tokens abgerufen und GPT4o als generatives LLM verwendet. Die endgültige Genauigkeit wurde mit einem LLM-as-a-judge (GPT4o) evaluiert.
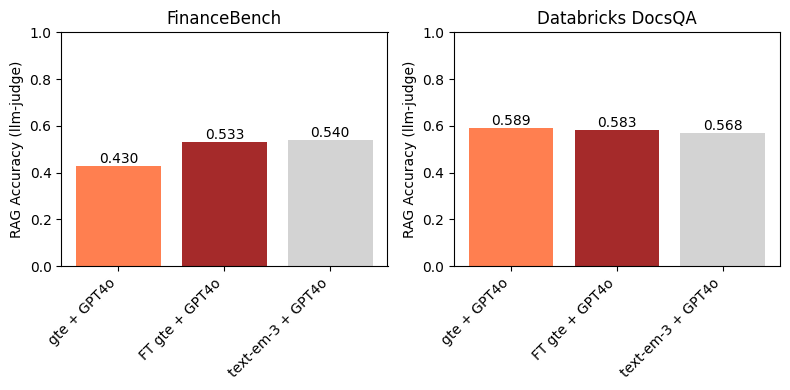
Bei FinanceBench zeigt Abbildung 3, dass die Verwendung eines finetuned Embedding-Modells zu einer Verbesserung der nachgelagerten RAG-Genauigkeit führt. Außerdem ist es wettbewerbsfähig mit text-embedding-3-large. Dies ist zu erwarten, da das Finetuning von gte zu einer großen Verbesserung des Recall@10 gegenüber dem Baseline-gte führte (Abbildung 1). Dieses Beispiel unterstreicht die Wirksamkeit des Finetunings von Embedding-Modellen für bestimmte Domänen und Datensätze.
Beim Databricks DocsQA-Datensatz finden wir keine Verbesserungen bei der Verwendung des finetuned gte-Modells gegenüber dem Baseline-gte-Modell. Dies ist einigermaßen zu erwarten, da die Abstände zwischen den Baseline- und finetuned-Modellen in den Abbildungen 1 und 2 gering sind. Interessanterweise führt text-embedding-3-large, obwohl es einen (geringfügig) höheren Recall@10 als jedes der gte-Modelle aufweist, nicht zu einer höheren nachgelagerten RAG-Genauigkeit. Wie in Abbildung 1 gezeigt, hatten alle Embedding-Modelle einen relativ hohen Recall@10 auf dem Databricks DocsQA-Datensatz; dies deutet darauf hin, dass Retrieval wahrscheinlich nicht der Engpass für RAG ist und dass das Finetuning eines Embedding-Modells auf diesem Datensatz nicht unbedingt der fruchtbarste Ansatz ist.
Wir danken Quinn Leng und Matei Zaharia für ihr Feedback zu diesem Blogbeitrag.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.