Kostenoptimierung & Zuverlässigkeit auf Databricks intelligent ausbalancieren
Tauchen Sie ein in die Schnittstelle von Finanzmanagement und Cloud Computing auf der Databricks Data Intelligence Platform
von Vuong Nguyen und Wasim Ahmad
Die Databricks Data Intelligence Platform bietet unübertroffene Flexibilität und ermöglicht Benutzern den Zugriff auf nahezu sofortige, horizontal skalierbare Rechenressourcen. Diese einfache Erstellung kann zu unkontrollierten Cloud-Kosten führen, wenn sie nicht richtig verwaltet wird.
Observability implementieren, um Kosten zu verfolgen und abzurechnen
Effektive Nutzung von Observability zur Verfolgung und Verrechnung von Kosten in Databricks
Bei der Arbeit mit komplexen technischen Ökosystemen ist das proaktive Verständnis des Unbekannten der Schlüssel zur Aufrechterhaltung der Plattformstabilität und zur Kostenkontrolle. Observability bietet eine Möglichkeit, Systeme basierend auf den von ihnen generierten Daten zu analysieren und zu optimieren. Dies unterscheidet sich von Monitoring, das sich auf die Identifizierung neuer Muster konzentriert, anstatt bekannte Probleme zu verfolgen.
Wichtige Funktionen zur Kostenverfolgung in Databricks
Tagging: Verwenden Sie Tags, um Ressourcen und Gebühren zu kategorisieren. Dies ermöglicht eine granularere Kostenallokation.
Systemtabellen: Nutzen Sie Systemtabellen für die automatisierte Kostenverfolgung und Verrechnung. Cloud-native Kostenüberwachungstools: Verwenden Sie diese Tools, um Einblicke in die Kosten aller Ressourcen zu erhalten.
Was sind Systemtabellen und wie werden sie verwendet?
Databricks bietet großartige Observability-Funktionen mithilfe von Systemtabellen. Systemtabellen sind analytische Speicher von Betriebsdaten eines Kundenkontos, die sich im Systemkatalog befinden und von Databricks gehostet werden. Sie bieten historische Observability für das gesamte Konto und enthalten benutzerfreundliche tabellarische Informationen zur Plattformtelemetrie. Wichtige Einblicke wie Abrechnungsnutzungsdaten sind in Systemtabellen verfügbar (dies beinhaltet derzeit nur DBU's Listenpreis), wobei jeder Nutzungsdatensatz eine stündliche Aggregation der abrechenbaren Nutzung einer Ressource darstellt.
Systemtabellen aktivieren
Systemtabellen werden von Unity Catalog verwaltet und erfordern ein Unity Catalog-fähiges Workspace, um darauf zugreifen zu können. Sie enthalten Daten von allen Workspaces, können aber nur von aktivierten Workspaces abgefragt werden. Die Aktivierung von Systemtabellen erfolgt auf Schemaebene – die Aktivierung eines Schemas aktiviert alle seine Tabellen. Administratoren müssen neue Schemas über die API manuell aktivieren.

Was sind Databricks-Tags und wie werden sie verwendet?
Databricks-Tagging ermöglicht es Ihnen, Attribute (Schlüssel-Wert-Paare) auf Ressourcen anzuwenden, um die Organisation, Suche und Verwaltung zu verbessern. Für die Kostenverfolgung und Verrechnung können Teams ihre Databricks-Jobs und Compute-Ressourcen (Cluster, SQL Warehouse) taggen, was ihnen helfen kann, die Nutzung und Kosten zu verfolgen und sie bestimmten Teams oder Einheiten zuzuordnen.
Tags anwenden
Tags können auf die folgenden Databricks-Ressourcen angewendet werden, um Nutzung und Kosten zu verfolgen:
- Databricks Compute
- Databricks Jobs
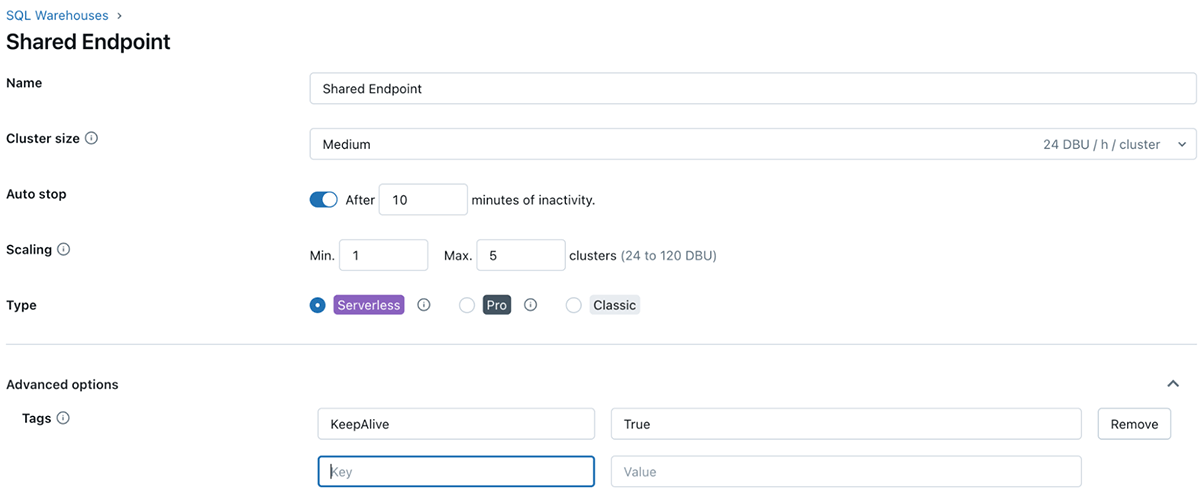
Sobald diese Tags angewendet wurden, kann eine detaillierte Kostenanalyse mithilfe der Systemtabellen für abrechenbare Nutzung durchgeführt werden.
Kosten mit Cloud-nativen Tools identifizieren
Um die Kosten zu überwachen und die Databricks-Nutzung korrekt den Geschäftsbereichen und Teams Ihrer Organisation zuzuordnen (z. B. für Verrechnungszwecke), können Sie Workspaces (und die zugehörigen verwalteten Ressourcengruppen) sowie Rechenressourcen taggen.
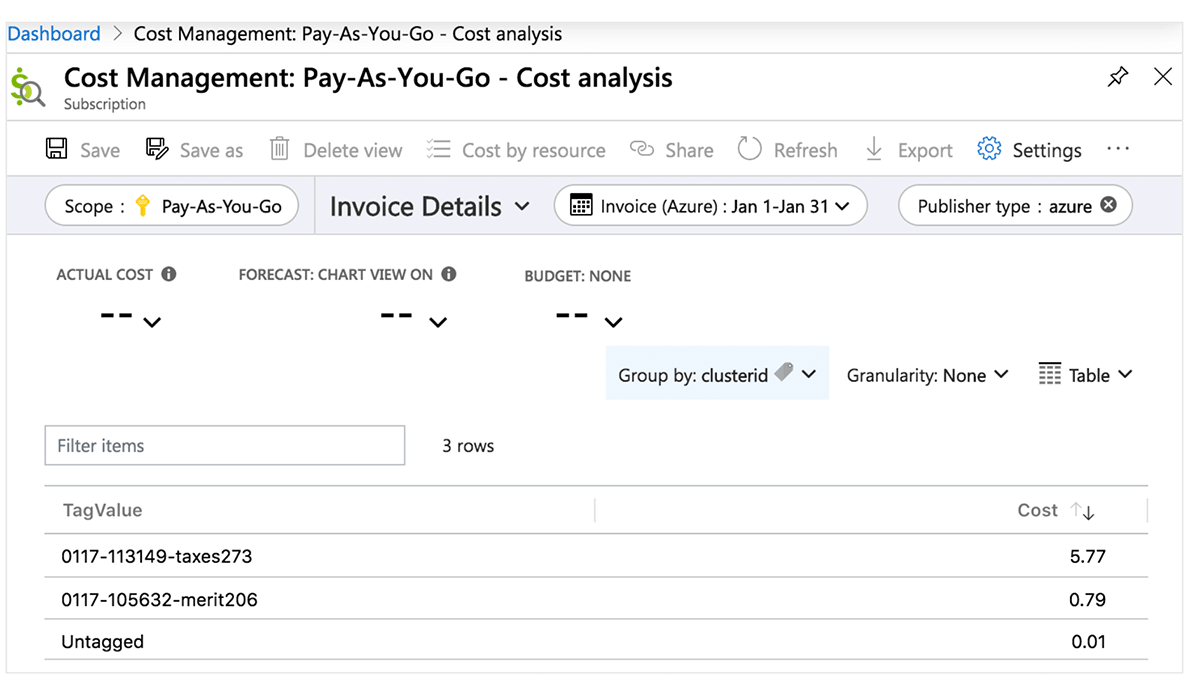
Azure Cost Center
Die folgende Tabelle beschreibt Azure Databricks-Objekte, auf die Tags angewendet werden können. Diese Tags können in detaillierte Kostenanalyseberichte übernommen werden, auf die Sie im Portal zugreifen können, sowie in die Systemtabelle für abrechenbare Nutzung. Weitere Details zur Tag-Propagation und zu Einschränkungen in Azure finden Sie hier.
| Azure Databricks-Objekt | Tagging-Oberfläche (UI) | Tagging-Oberfläche (API) |
|---|---|---|
| Workspace | Azure Portal | Azure Resources API |
| Pool | Pools UI im Azure Databricks Workspace | Instance Pool API |
| All-purpose & Job Compute | Compute UI im Azure Databricks Workspace | Clusters API |
| SQL Warehouse | SQL Warehouse UI im Azure Databricks Workspace | Warehouse API |
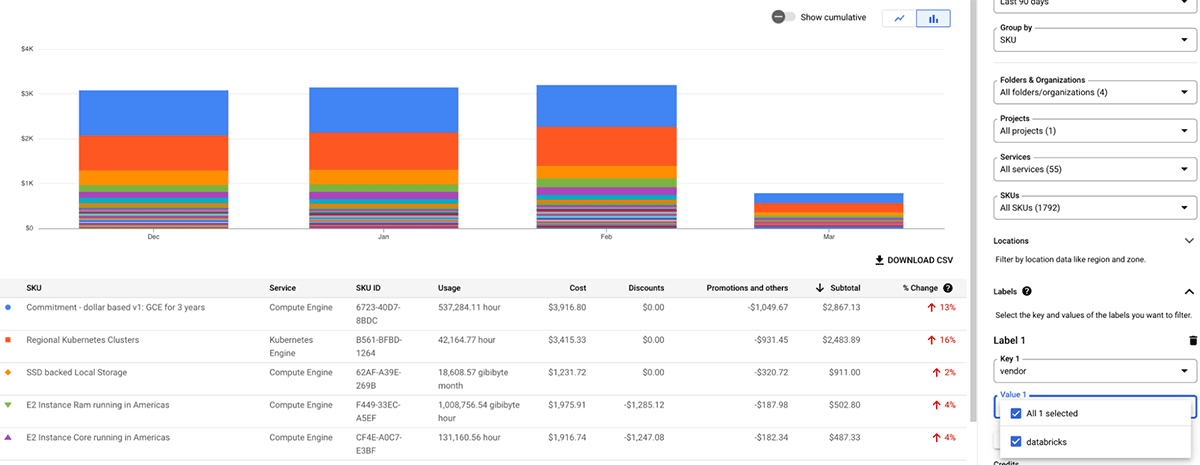
AWS Cost Explorer
Die folgende Tabelle beschreibt AWS Databricks-Objekte, auf die Tags angewendet werden können. Diese Tags können sowohl in Nutzungsprotokolle als auch in AWS EC2- und AWS EBS-Instanzen für die Kostenanalyse übernommen werden. Databricks empfiehlt die Verwendung von Systemtabellen (Public Preview), um abrechenbare Nutzungsdaten anzuzeigen. Weitere Details zur Tag-Propagation und zu Einschränkungen in AWS finden Sie hier.
| AWS Databricks-Objekt | Tagging-Oberfläche (UI) | Tagging-Oberfläche (API) |
|---|---|---|
| Workspace | N/A | Account API |
| Pool | Pools UI im Databricks Workspace | Instance Pool API |
| All-purpose & Job Compute | Compute UI im Databricks Workspace | Clusters API |
| SQL Warehouse | SQL Warehouse UI im Databricks Workspace | Warehouse API |
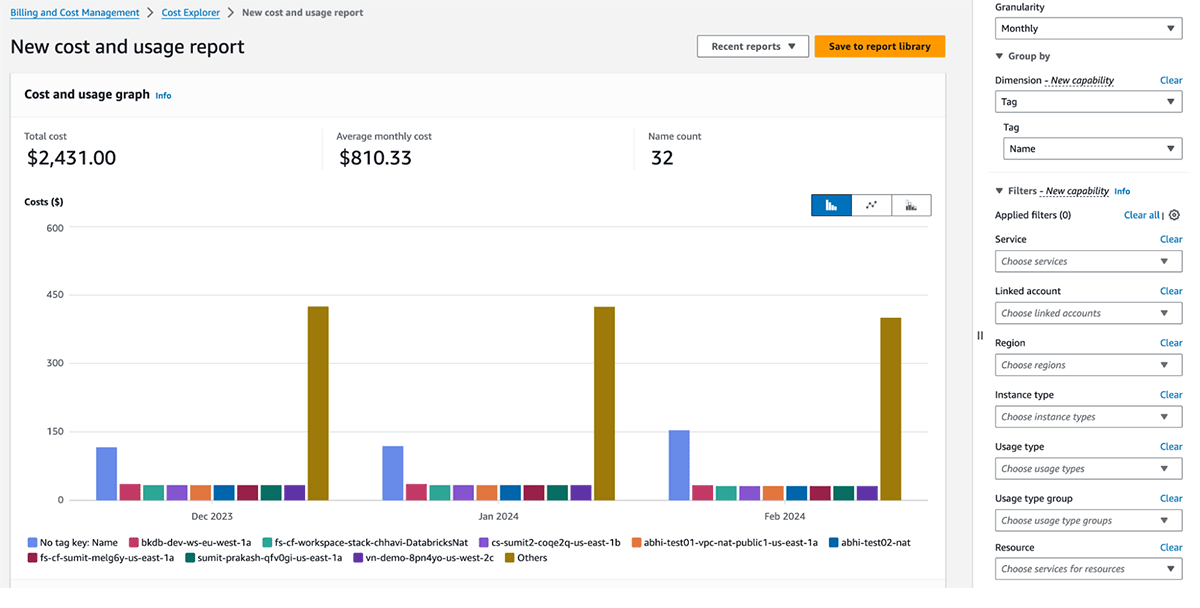
GCP Kostenmanagement und Abrechnung
Die folgende Tabelle beschreibt GCP Databricks-Objekte, auf die Tags angewendet werden können. Diese Tags/Labels können auf Rechenressourcen angewendet werden. Weitere Details zur Tag/Label-Propagation und zu Einschränkungen in GCP finden Sie hier.
Die Nutzungsgraphen für die Abrechnung von Databricks in der Account-Konsole können die Nutzung nach einzelnen Tags aggregieren. Die von derselben Seite heruntergeladenen CSV-Berichte für abrechenbare Nutzung enthalten auch Standard- und benutzerdefinierte Tags. Tags werden auch auf GKE- und GCE-Labels übertragen.
| GCP Databricks-Objekt | Tagging-Oberfläche (UI) | Tagging-Oberfläche (API) |
|---|---|---|
| Pool | Pools UI im Databricks Workspace | Instance Pool API |
| All-purpose & Job-Compute | Compute-Benutzeroberfläche im Databricks-Workspace | Clusters API |
| SQL Warehouse | SQL Warehouse-Benutzeroberfläche im Databricks-Workspace | Warehouse API |
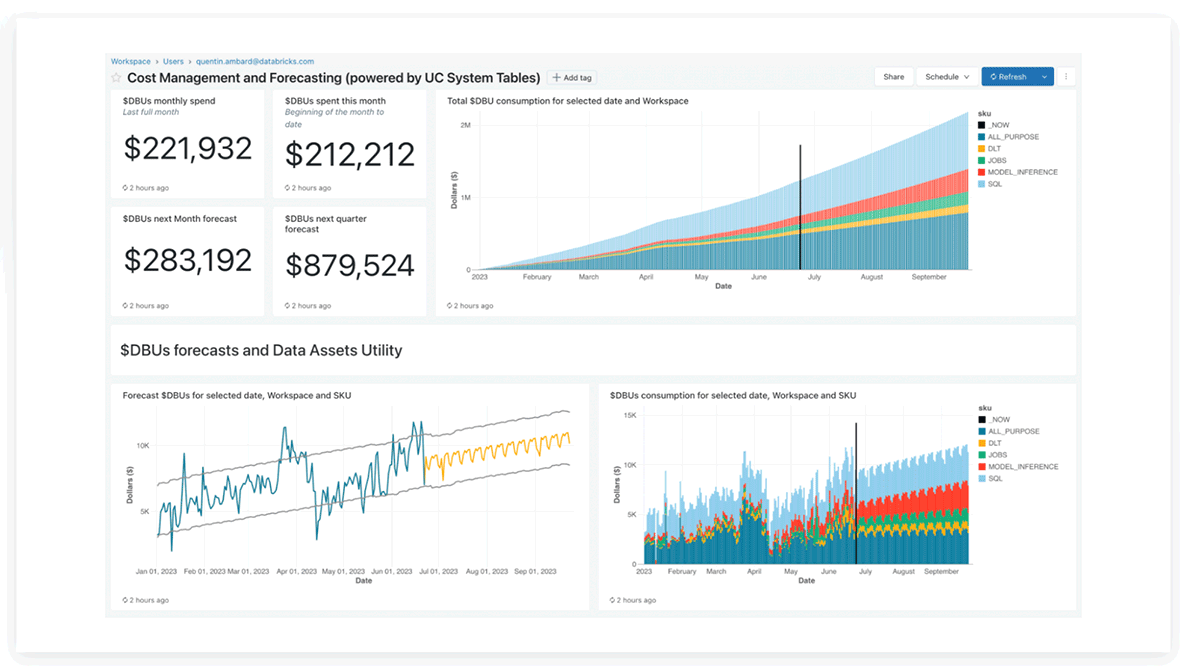
Databricks Systemtabellen Lakeview Dashboard
Das Databricks-Produktteam hat vorkonfigurierte Lakeview Dashboards für Kostenanalysen und Prognosen mithilfe von Systemtabellen bereitgestellt, die Kunden auch anpassen können.
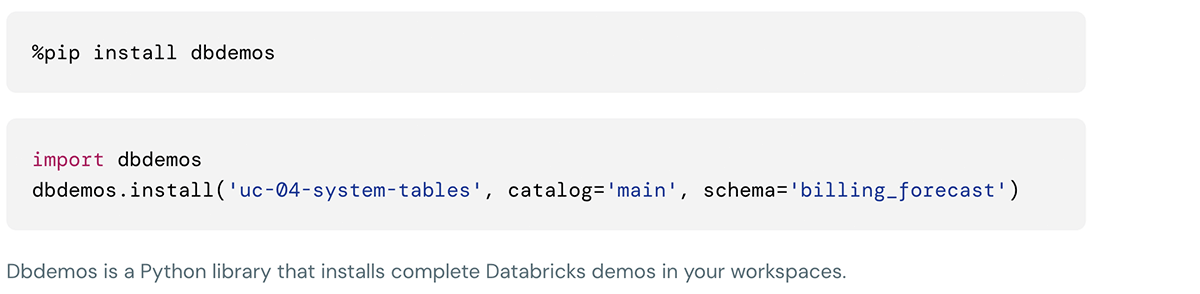
Diese Demo kann mit den folgenden Befehlen in der Databricks Notebook-Zelle installiert werden:
Best Practices zur Maximierung des Werts
Beim Ausführen von Workloads auf Databricks verbessert die Wahl der richtigen Compute-Konfiguration die Kosten-/Leistungsmetriken erheblich. Nachfolgend finden Sie einige praktische Kostenoptimierungstechniken:
Verwendung des richtigen Compute-Typs für den richtigen Job
Für interaktive SQL-Workloads ist SQL Warehouse die kostengünstigste Engine. Noch effizienter kann Serverless Compute sein, das eine sehr schnelle Startzeit für SQL Warehouses bietet und eine kürzere automatische Beendigungszeit ermöglicht.
Für nicht-interaktive Workloads sind Jobs-Cluster deutlich günstiger als Allzweck-Cluster. Multitask-Workflows können Compute-Ressourcen für alle Aufgaben wiederverwenden, was die Kosten noch weiter senkt.
Auswahl des richtigen Instanztyps
Die Verwendung der neuesten Generation von Cloud-Instanztypen bringt fast immer Leistungsvorteile, da sie die beste Leistung und die neuesten Funktionen bieten. Auf AWS können Graviton2-basierte Amazon EC2-Instanzen bis zu 3x bessere Preis-Leistungs-Verhältnisse als vergleichbare Amazon EC2-Instanzen bieten.
Basierend auf Ihren Workloads ist es auch wichtig, die richtige Instanzfamilie auszuwählen. Einige einfache Faustregeln sind:
- Speicheroptimiert für ML, intensive Shuffle- & Spill-Workloads
- Compute-optimiert für Structured Streaming-Workloads, Wartungsjobs (z. B. Optimize & Vacuum)
- Speicheroptimiert für Workloads, die von Caching profitieren, z. B. Ad-hoc- & interaktive Datenanalysen
- GPU-optimiert für spezifische ML- & DL-Workloads
- Allzweck bei Fehlen spezifischer Anforderungen
Auswahl des richtigen Runtimes
Die neueste Databricks Runtime (DBR) bietet normalerweise eine verbesserte Leistung und ist fast immer schneller als die vorherige Version.
Photon ist eine leistungsstarke, native Databricks-Vektorisierungs-Query-Engine, die Ihre SQL-Workloads und DataFrame-API-Aufrufe schneller ausführt, um Ihre Gesamtkosten pro Workload zu senken. Für diese Workloads kann die Aktivierung von Photon erhebliche Kosteneinsparungen bringen.
Nutzung von Autoscaling in Databricks Compute
Databricks bietet eine einzigartige Funktion für Cluster-Autoscaling, die es einfacher macht, eine hohe Cluster-Auslastung zu erreichen, da Sie den Cluster nicht für einen Workload bereitstellen müssen. Dies ist besonders nützlich für interaktive Workloads oder Batch-Workloads mit variabler Datenlast. Klassisches Autoscaling funktioniert jedoch nicht mit Structured Streaming-Workloads. Deshalb haben wir Enhanced Autoscaling in Delta Live Tables entwickelt, um Streaming-Workloads zu verarbeiten, die sprunghaft und unvorhersehbar sind.
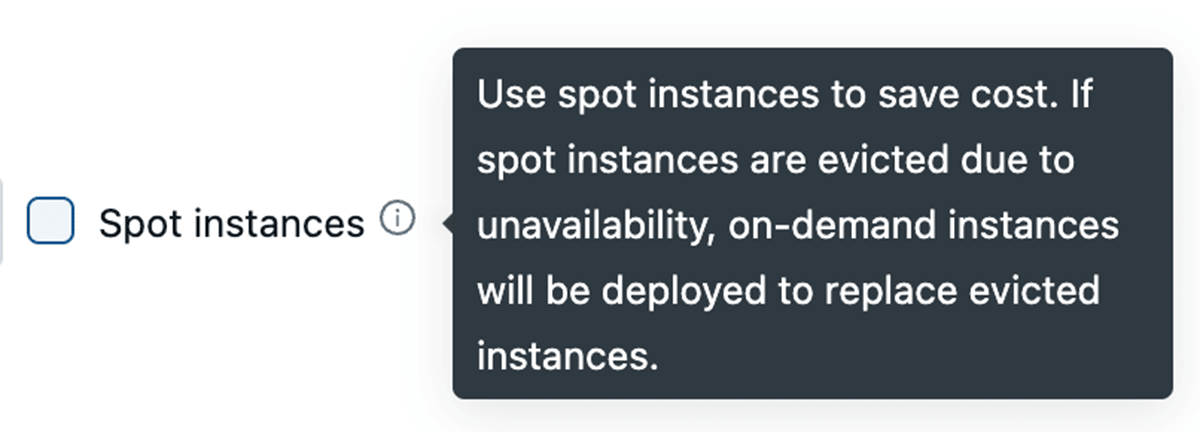
Nutzung von Spot-Instanzen
Alle großen Cloud-Anbieter bieten Spot-Instanzen an, mit denen Sie ungenutzte Kapazitäten in ihren Rechenzentren für bis zu 90 % weniger als reguläre On-Demand-Instanzen nutzen können. Databricks ermöglicht es Ihnen, diese Spot-Instanzen zu nutzen, mit der Möglichkeit, im Falle einer Beendigung automatisch auf On-Demand-Instanzen zurückzufallen, um Unterbrechungen zu minimieren. Für Cluster-Stabilität empfehlen wir die Verwendung von On-Demand-Treiberknoten.
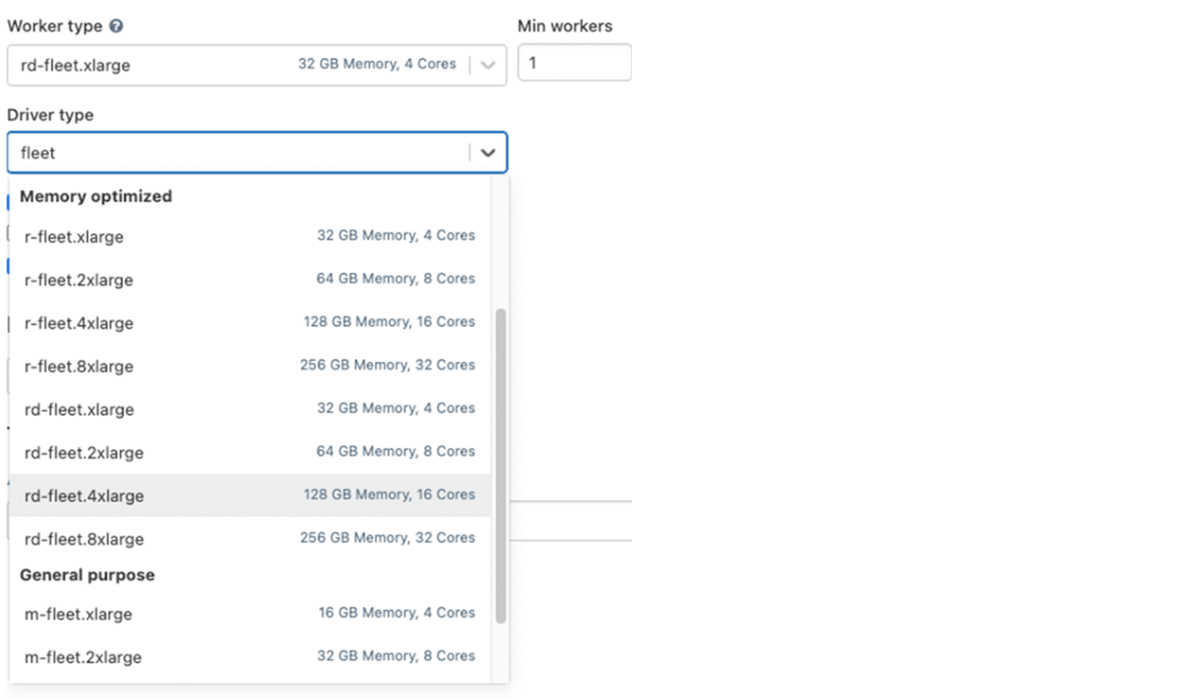
Nutzung von Fleet-Instanztypen (auf AWS)
Intern wählt Databricks die passenden physischen AWS-Instanztypen mit dem besten Preis und der besten Verfügbarkeit aus, wenn ein Cluster einen dieser Fleet-Instanztypen verwendet.
Cluster-Richtlinie
Die effektive Nutzung von Cluster-Richtlinien ermöglicht es Administratoren, kostenbezogene Einschränkungen für Endbenutzer durchzusetzen:
- Aktivieren Sie die automatische Cluster-Beendigung mit einem angemessenen Wert (z. B. 1 Stunde), um Zahlungen für Leerlaufzeiten zu vermeiden.
- Stellen Sie sicher, dass nur kostengünstige VM-Instanzen ausgewählt werden können
- Erzwingen Sie obligatorische Tags für die Kostenverrechnung
- Kontrollieren Sie das allgemeine Kostenprofil, indem Sie die maximalen Kosten pro Cluster begrenzen, z. B. maximale DBUs pro Stunde oder maximale Compute-Ressourcen pro Benutzer
KI-gestützte Kostenoptimierung
Die Databricks Data Intelligence Platform integriert fortschrittliche KI-Funktionen, die die Leistung optimieren, Kosten senken, die Governance verbessern und die Entwicklung von Enterprise-KI-Anwendungen vereinfachen. Predictive I/O und Liquid Clustering verbessern die Abfragegeschwindigkeit und Ressourcenauslastung, während intelligentes Workload-Management das Autoscaling für Kosteneffizienz optimiert. Insgesamt bietet die Plattform von Databricks eine umfassende Suite von KI-Tools, um die Produktivität und Kosteneinsparungen zu steigern und gleichzeitig innovative Lösungen für branchenspezifische Anwendungsfälle zu ermöglichen.
Liquid Clustering
Liquid Clustering von Delta Lake ersetzt Tabellenpartitionierung und ZORDER, um Entscheidungen über das Datenlayout zu vereinfachen und die Abfrageleistung zu optimieren. Liquid Clustering bietet Flexibilität, Clustering-Schlüssel neu zu definieren, ohne vorhandene Daten neu schreiben zu müssen, sodass sich das Datenlayout im Laufe der Zeit zusammen mit den analytischen Anforderungen weiterentwickeln kann.
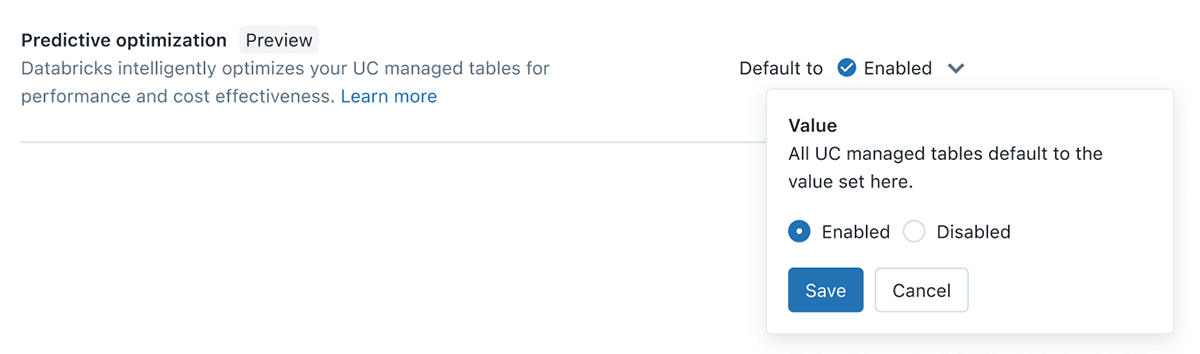
Predictive Optimization
Daten-Ingenieure auf dem Lakehouse kennen die Notwendigkeit, ihre Tabellen regelmäßig zu OPTIMIZE & VACUUM, aber dies schafft fortlaufende Herausforderungen bei der Ermittlung der richtigen Tabellen, des geeigneten Zeitplans und der richtigen Compute-Größe für diese Aufgaben. Mit Predictive Optimization nutzen wir Unity Catalog und Lakehouse AI, um die besten Optimierungen für Ihre Daten zu ermitteln und führen diese Operationen dann auf speziell dafür entwickelter Serverless-Infrastruktur aus. Dies geschieht alles automatisch und gewährleistet die beste Leistung ohne verschwendete Rechenleistung oder manuellen Abstimmungsaufwand.
Materialized View mit inkrementellem Refresh
In Databricks, Materialized Views (MVs) sind von Unity Catalog verwaltete Tabellen, die es Benutzern ermöglichen, Ergebnisse basierend auf der neuesten Version von Daten in Quelltabellen vorab zu berechnen. Basierend auf Delta Live Tables & Serverless reduzieren MVs die Abfragelatenz, indem sie ansonsten langsame Abfragen und häufig verwendete Berechnungen vorab berechnen. Wenn möglich, werden Ergebnisse inkrementell aktualisiert, aber die Ergebnisse sind identisch mit denen, die durch eine vollständige Neuberechnung erzielt würden. Dies reduziert die Rechenkosten und vermeidet die Notwendigkeit, separate Cluster zu verwalten.
Serverless-Funktionen für Model Serving & Gen AI-Anwendungsfälle
Um Model Serving und Gen AI-Anwendungsfälle besser zu unterstützen, hat Databricks mehrere Funktionen auf unserer Serverless-Infrastruktur eingeführt, die sich automatisch an Ihre Workflows anpassen, ohne dass Instanzen und Servertypen konfiguriert werden müssen.
- AI Search: Ein Vektorindex, der mit 1-Klick von jeder Delta-Tabelle synchronisiert werden kann – keine komplexen, benutzerdefinierten Data Ingestion/Sync-Pipelines erforderlich.
- Online Tables: Vollständig Serverless-Tabellen, die die Durchsatzkapazität automatisch an die Anfrage-Last anpassen und einen niedrigen Latenz- und hohen Durchsatzzugriff auf Daten jeder Größenordnung bieten.
- Model Serving: Ein hochverfügbarer und latenzarmer Dienst für die Bereitstellung von Modellen. Der Dienst skaliert automatisch nach oben oder unten, um Nachfrageänderungen zu erfüllen, spart Infrastrukturkosten und optimiert gleichzeitig die Latenzleistung.
Predictive I/O für Updates und Deletes
Mit diesen KI-gestützten Funktionen kann Databricks SQL jetzt historische Lese- und Schreibmuster analysieren, um Indizes intelligent zu erstellen und Workloads zu optimieren. Predictive I/O ist eine Sammlung von Databricks-Optimierungen, die die Leistung für Dateninteraktionen verbessern. Predictive I/O-Funktionen sind in die folgenden Kategorien unterteilt:
- Beschleunigte Lesevorgänge reduzieren die Zeit, die zum Scannen und Lesen von Daten benötigt wird. Dies geschieht mithilfe von Deep-Learning-Techniken. Weitere Details finden Sie in dieser Dokumentation
- Beschleunigte Updates reduzieren die Datenmenge, die bei Updates, Deletes und Merges neu geschrieben werden muss. Predictive I/O nutzt Deletion Vectors, um Updates zu beschleunigen, indem die Häufigkeit von vollständigen Dateineuschreibungen bei Datenänderungen an Delta-Tabellen reduziert wird. Predictive I/O optimiert
DELETE-,MERGE- undUPDATE-Operationen. Weitere Details finden Sie in dieser Dokumentation
Predictive I/O ist exklusiv für die Photon-Engine auf Databricks.
Intelligentes Workload-Management (IWM)
Einer der größten Schmerzpunkte für technische Plattform-Administratoren ist die Verwaltung verschiedener Warehouses für kleine und große Workloads und die Sicherstellung, dass der Code optimiert und fein abgestimmt ist, um optimal zu laufen und die volle Kapazität der Compute-Infrastruktur zu nutzen. IWM ist eine Suite von Funktionen, die bei den oben genannten Herausforderungen hilft und diese Workloads schneller ausführt, während die Kosten niedrig gehalten werden. Dies geschieht durch die Analyse von Echtzeitmustern und die Sicherstellung, dass die Workloads über die optimale Menge an Compute verfügen, um die eingehenden SQL-Anweisungen auszuführen, ohne bereits laufende Abfragen zu stören.
Die richtige FinOps-Grundlage – durch Tagging, Richtlinien und Berichterstattung – ist entscheidend für Transparenz und ROI Ihrer Data Intelligence Platform. Sie hilft Ihnen, schneller Geschäftswert zu realisieren und ein erfolgreicheres Unternehmen aufzubauen.
Nutzen Sie Serverless und DatabricksIQ für schnelle Einrichtung, Kosteneffizienz und automatische Optimierungen, die sich an Ihre Workload-Muster anpassen. Dies führt zu niedrigeren TCO, besserer Zuverlässigkeit und einfacheren, kostengünstigeren Betriebsabläufen.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.