Einführung in AI Runtime: Skalierbare, serverlose NVIDIA GPUs auf Databricks für Training und Finetuning
Trainieren Sie die neuesten LLMs mit sofort verfügbaren NVIDIA H100 GPUs, die mit Ihrem Lakehouse verbunden sind
von Tejas Sundaresan, Jianwei Xie, Bandish Shah und Hanlin Tang
- Mit der AI Runtime unterstützt Databricks jetzt NVIDIA GPUs in Serverless Compute. Dies ermöglicht den bedarfsgesteuerten Zugriff auf skalierbare NVIDIA A10 und H100 ohne Infrastruktur-Overhead.
- Trainieren Sie Computer-Vision-Modelle, LLMs, Deep-Learning-basierte Empfehlungssysteme und andere Modelle mit unserer dedizierten Runtime für verteiltes Training – alles inklusive.
- Die AI Runtime ist integriert mit schnellem Datentransfer aus Lakehouse-Daten, Workflow-Orchestrierung mit Lakeflow und Governance mit Unity Catalog.
GPUs sind die treibende Kraft hinter den fortschrittlichsten KI-Workloads von heute – von Prognosen und Empfehlungen bis hin zu multimodalen Foundation Models. Allerdings haben Teams Schwierigkeiten bei der Beschaffung und Verwaltung von GPU-Infrastruktur, der Konfiguration von verteilten Trainingsumgebungen und dem Debugging von Engpässen bei der Datenladung. Forscher im Bereich Deep Learning möchten sich lieber auf die Modellierung konzentrieren, nicht auf die Fehlersuche in der Infrastruktur.
Wir freuen uns, die Public Preview von AI Runtime (AIR) anzukündigen, einem neuen Trainings-Stack, der bedarfsgesteuertes verteiltes GPU-Training auf A10 und H100 ermöglicht. AI Runtime enthält die gesamte Technologie, die für das Training von LLMs im großen Maßstab wie MPT und DBRX verwendet wird. Bereits in der Beta-Phase haben Hunderte von Kunden, darunter Rivian, Factset und YipitData, AIR genutzt, um Deep-Learning-Modelle zu trainieren und in die Produktion zu überführen. Die Anwendungsfälle reichen von Computer-Vision-Modellen über Empfehlungssysteme bis hin zu feinabgestimmten LLMs für agentenbasierte Aufgaben. Unser eigenes Databricks AI Research Team nutzte AIR für das Reinforcement Learning von Modellen, wie in unserem kürzlich veröffentlichten Paper über KARL.
Mit AI Runtime haben Databricks-Benutzer jetzt:
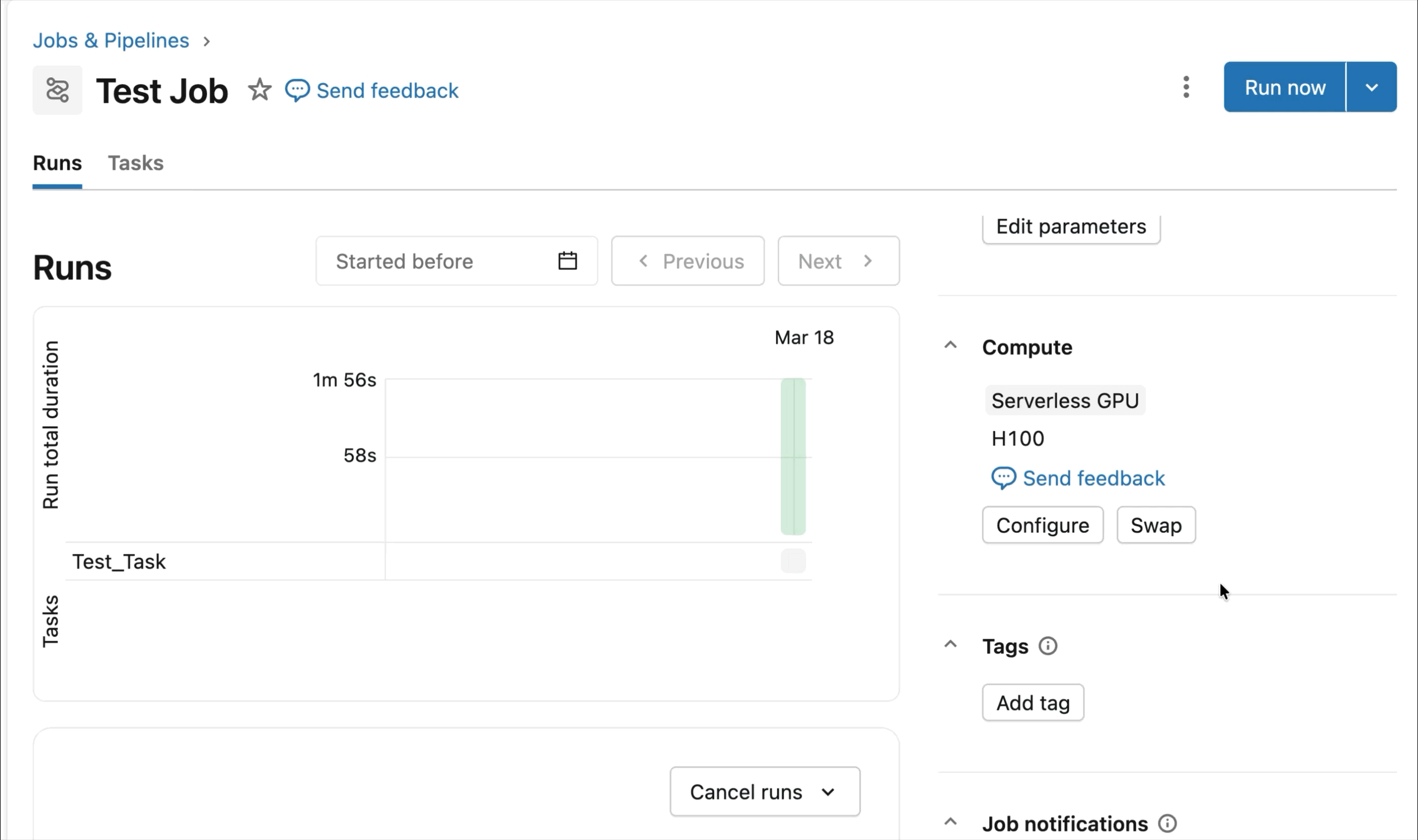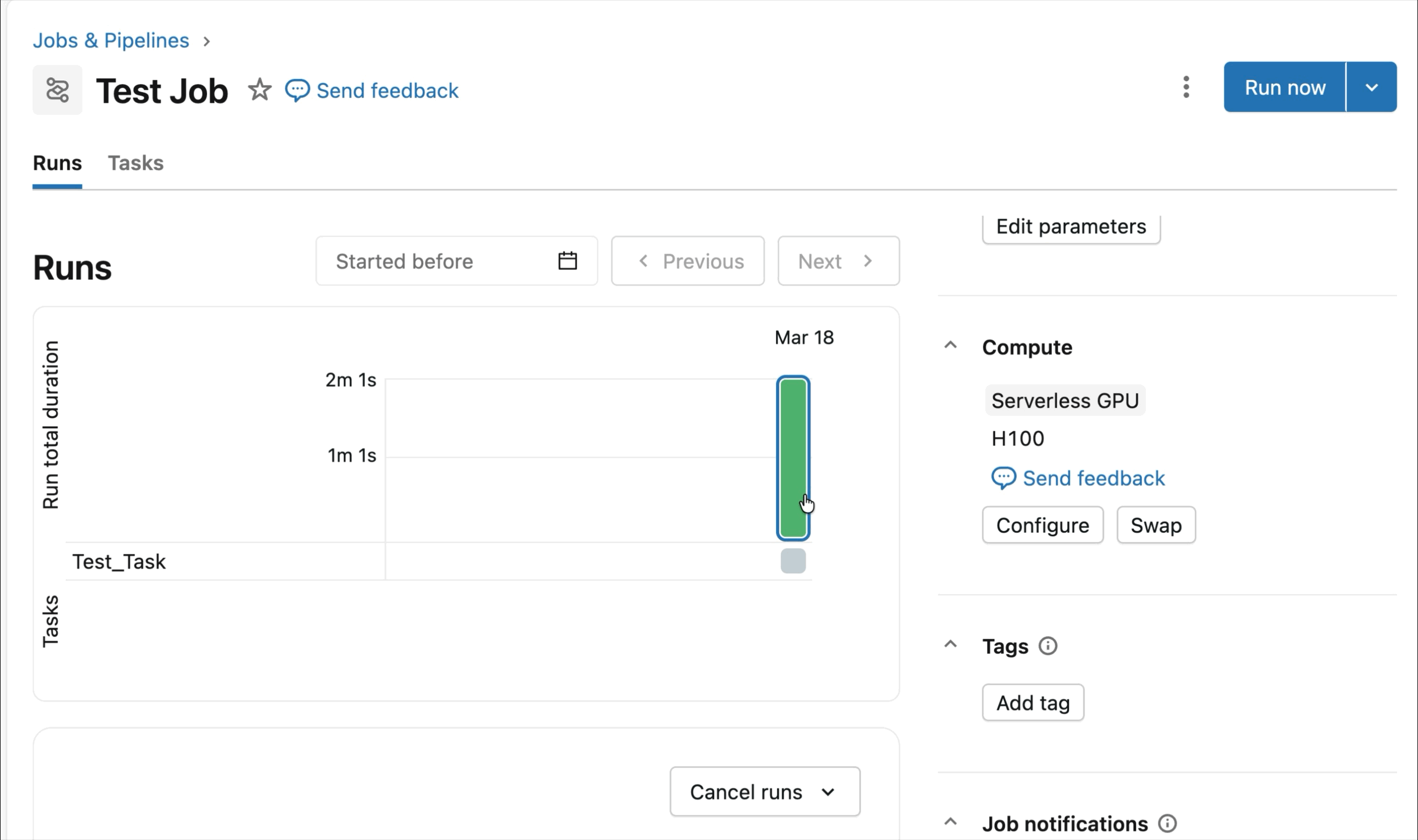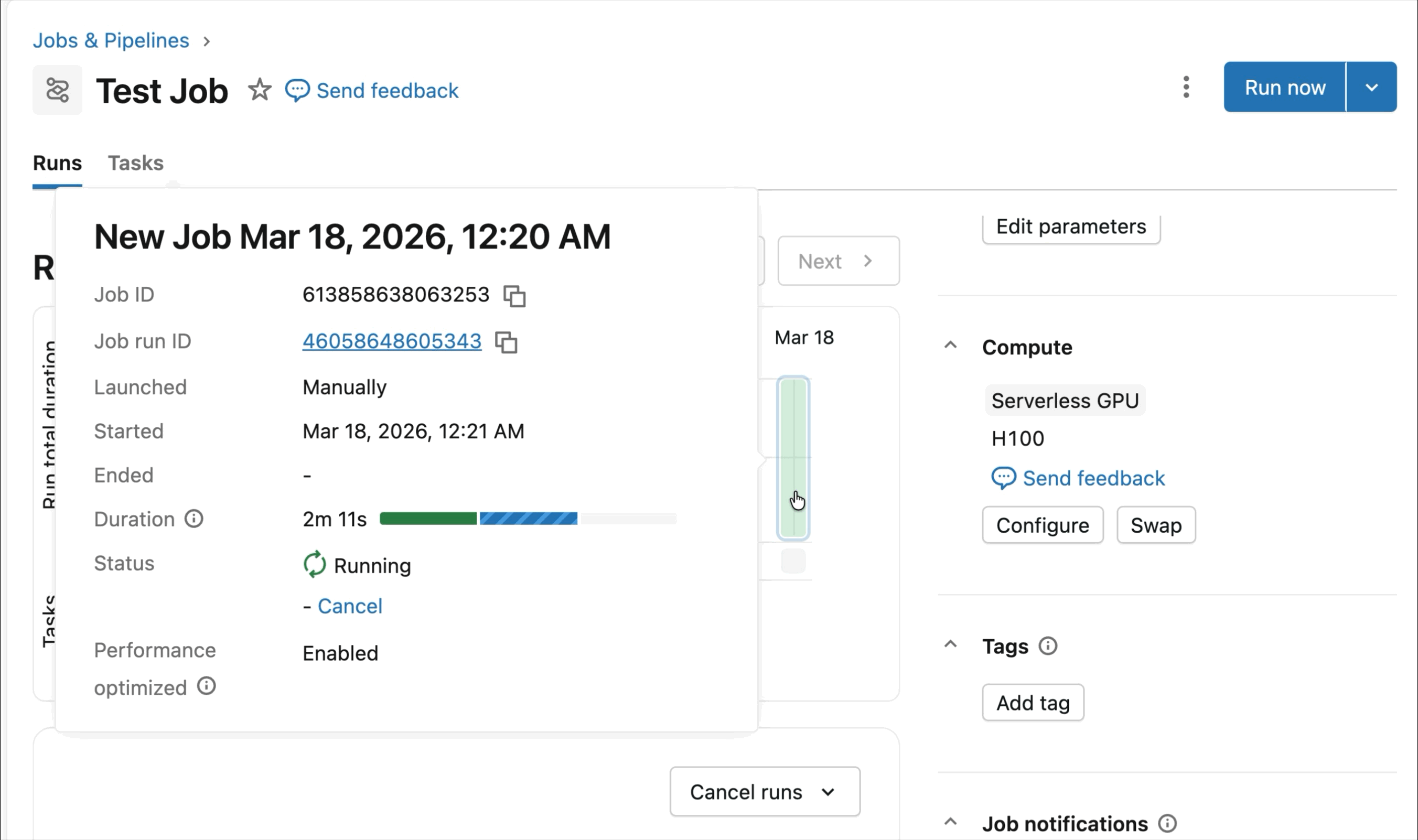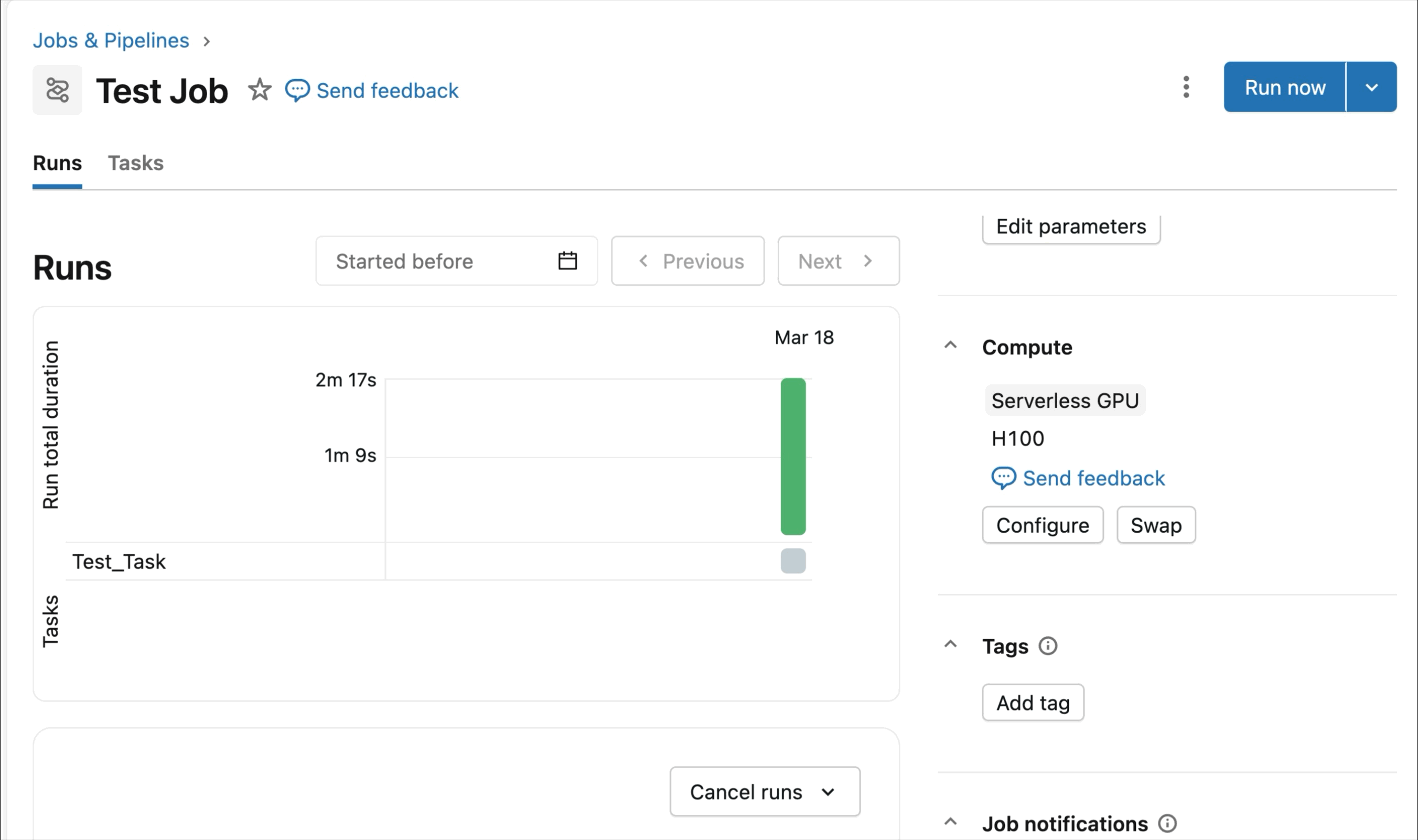
- Serverless, bedarfsgesteuerte NVIDIA GPUs: Konfigurieren Sie Ihr Notebook einfach mit 2-3 Klicks und erhalten Sie eine schnelle Verbindung zu Serverless A10 und H100 GPUs, um mit dem Training zu beginnen – kein Cluster erforderlich. Bezahlen Sie nur für die GPUs, die Sie nutzen, ohne sich Gedanken über die Auslastung im Leerlauf machen zu müssen.
- Robuste Orchestrierungstools: Nutzen Sie die volle Leistung der Orchestrierungs-Suite von Databricks mit Lakeflow Jobs und DABs-Unterstützung für langlaufende GPU-Workloads.
- Optimiertes verteiltes Training: AIR bündelt Leistungsverbesserungen für verteiltes GPU-Training, wie RDMA und Hochleistungs-Datenladung.
- Zentralisierte Governance und Observability: Führen Sie GPU-Workloads aus, beobachten Sie sie und steuern Sie sie genau dort, wo sich Ihre Daten befinden, mit integriertem Experiment-Management über MLflow, Zugriffsmanagement mit Unity Catalog und agentengestütztem Debugging.
Bedarfsgesteuerte NVIDIA H100 und A10 GPUs in Notebooks
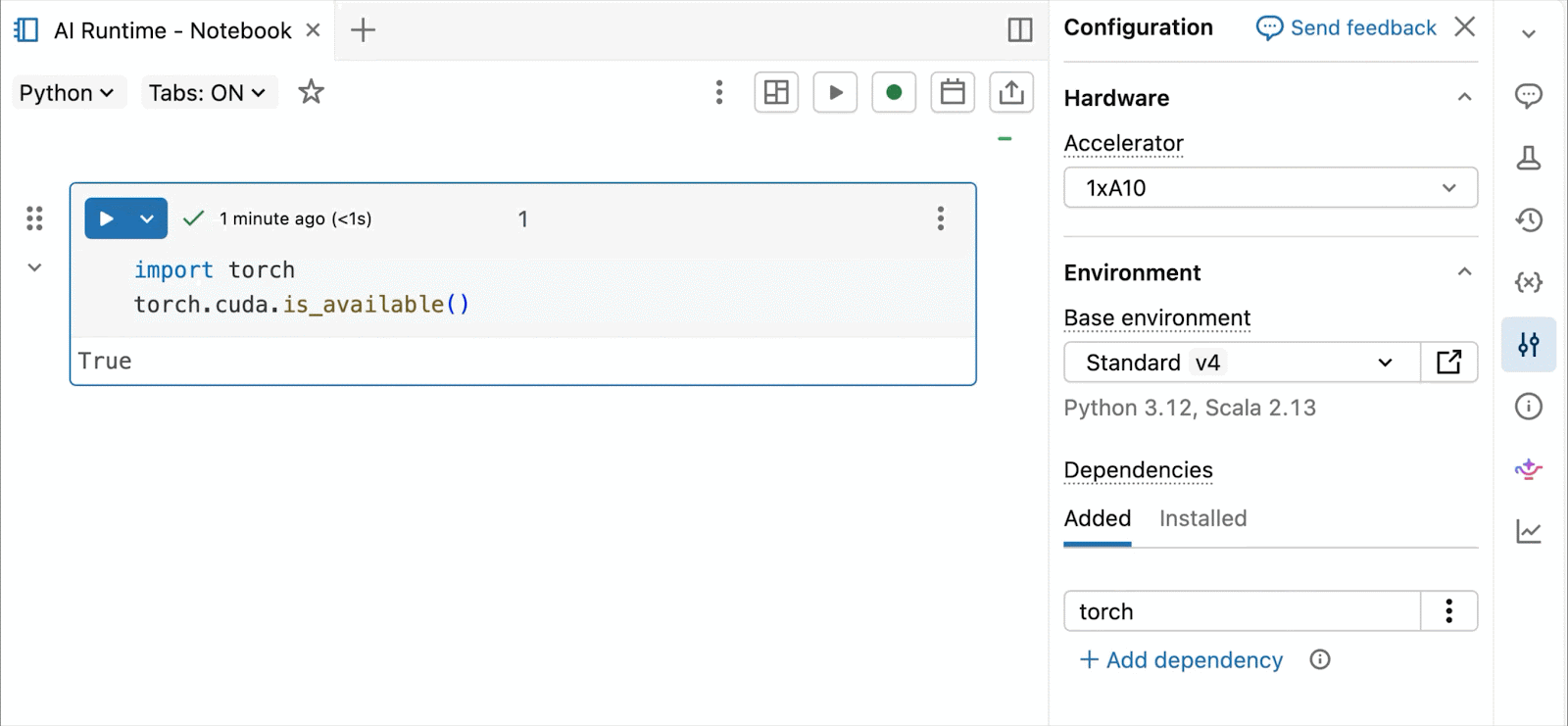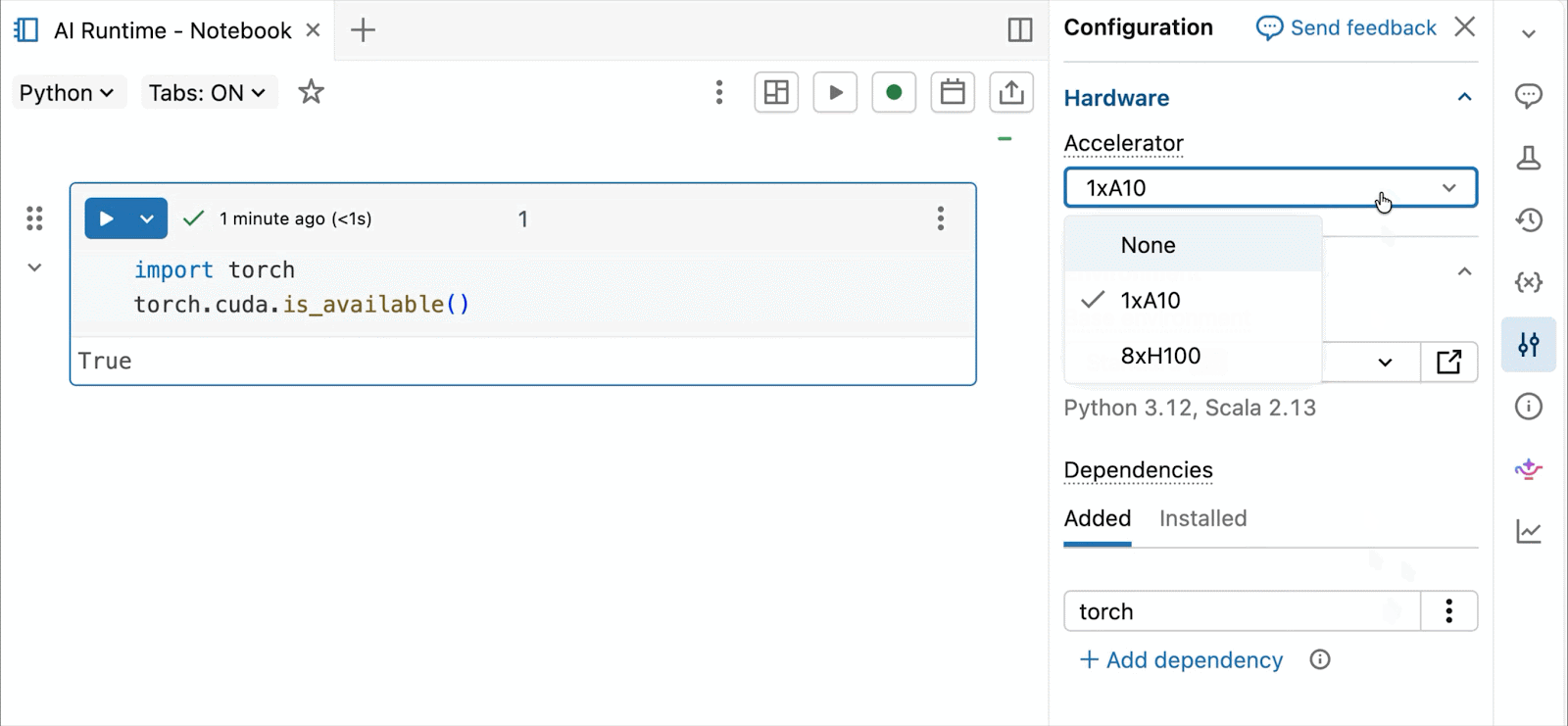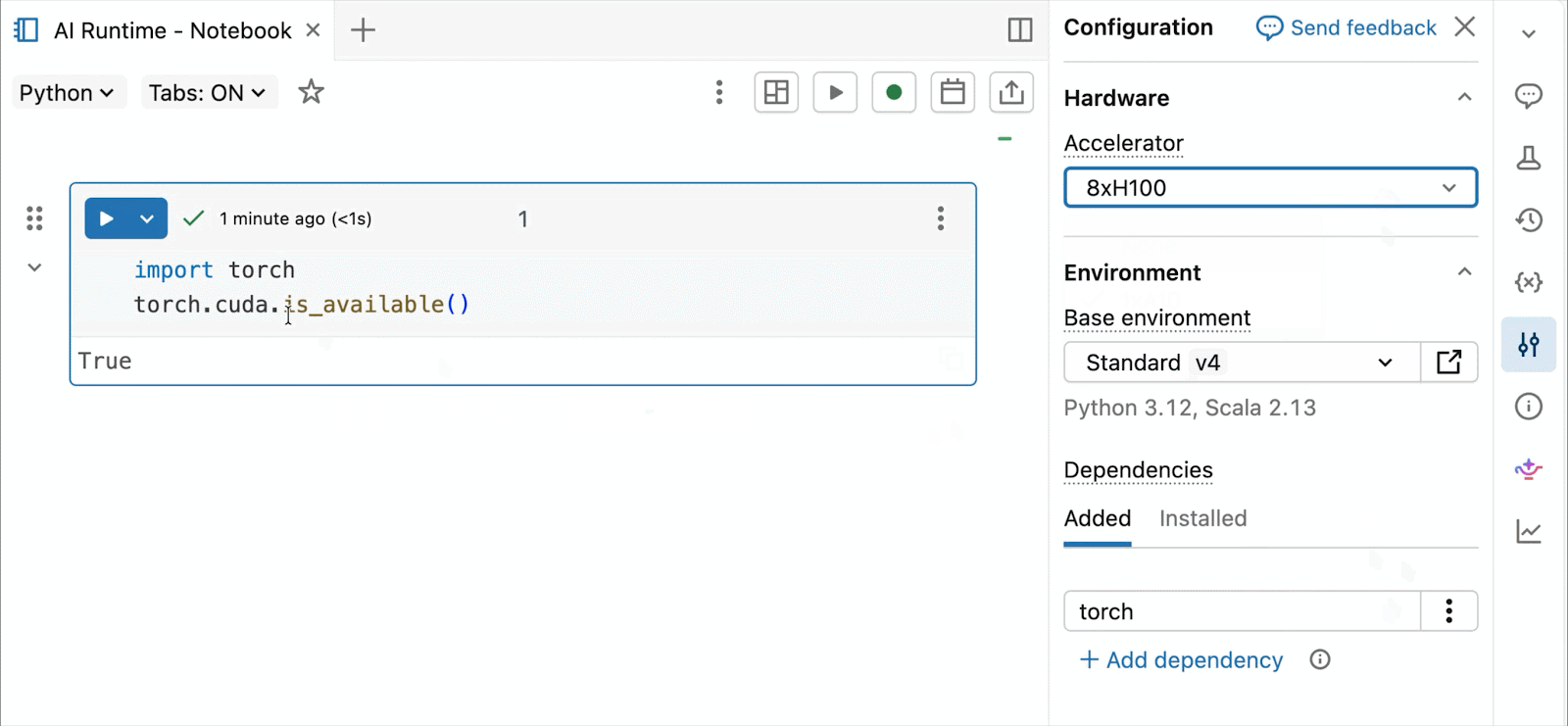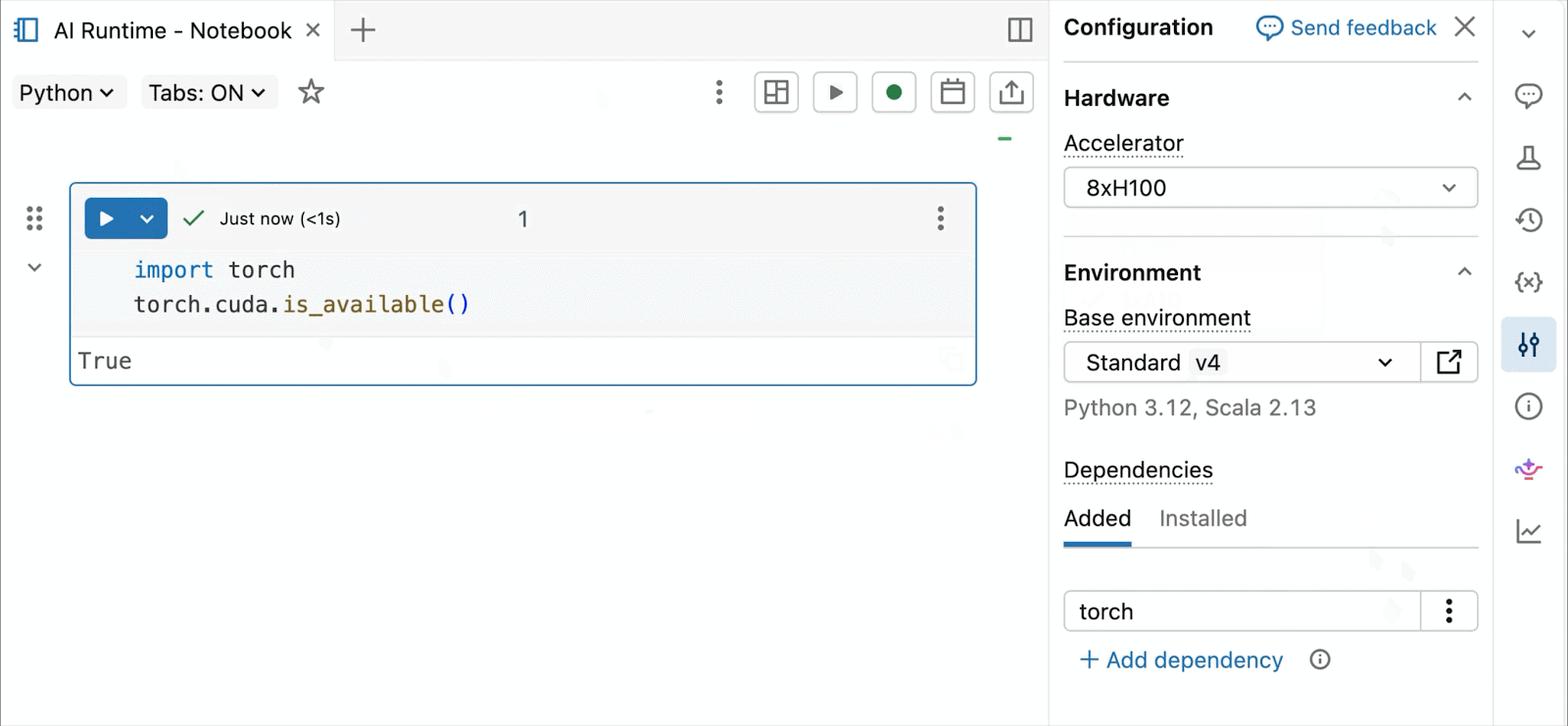
Für interaktive Entwicklung und Debugging verbinden Sie sich mit wenigen Klicks mit bedarfsgesteuerten A10 und H100 in Databricks Notebooks. Von dort aus nutzen Sie die gesamte Entwicklerergonomie, für die Databricks bekannt ist, von der Umgebungsverwaltung für gängige Python-Pakete bis hin zur agentengesteuerten Erstellung und Fehlersuche mit Genie Code. Hängen Sie einfach Daten aus dem Lakehouse ein, um Deep-Learning-Modelle zu trainieren, oder rufen Sie sogar eine Flotte von Remote-CPUs für Spark-Datenverarbeitungs-Workloads von Ihrem GPU-gestützten Notebook aus auf, um Ihre Daten vorzubereiten.
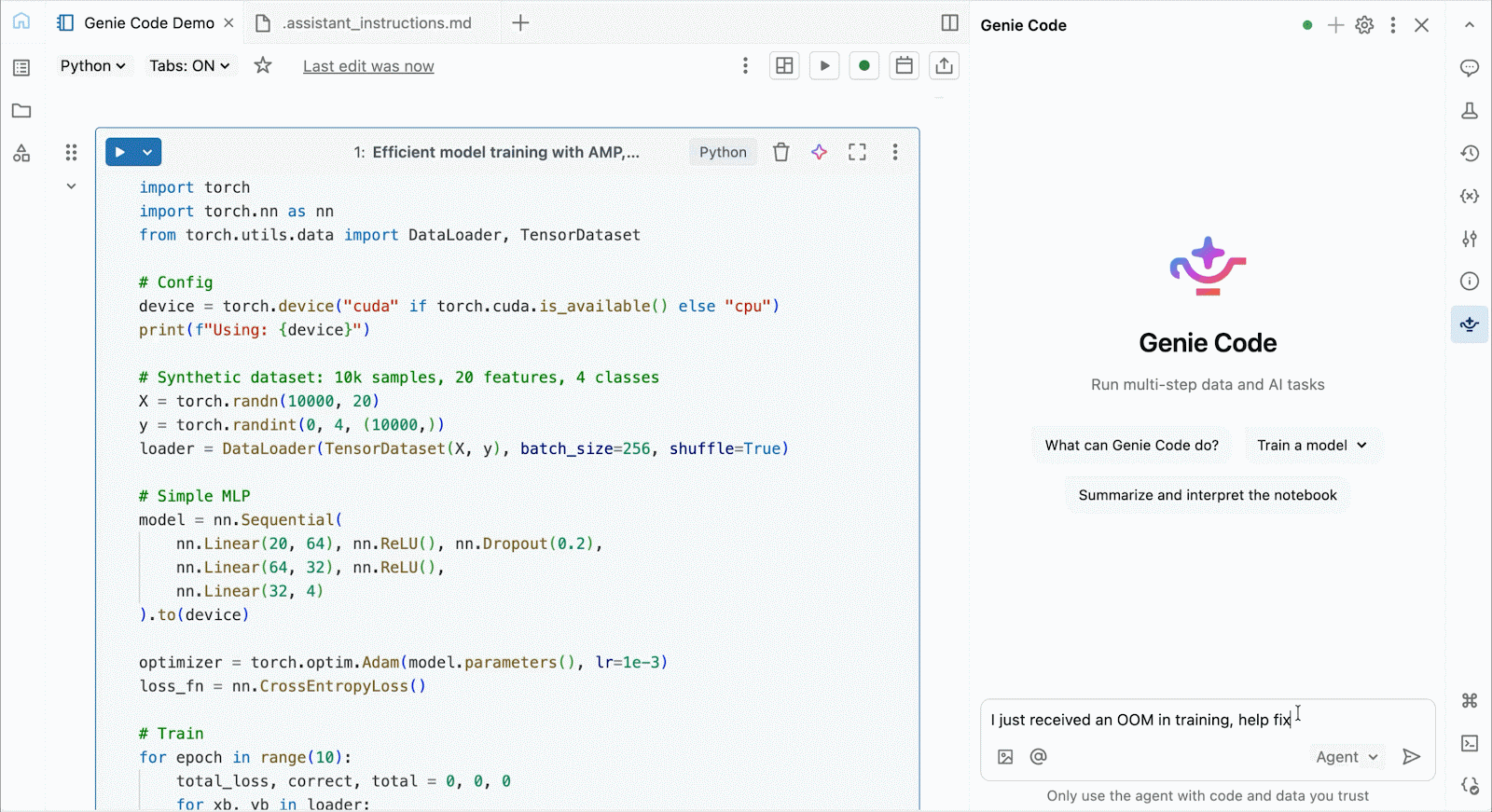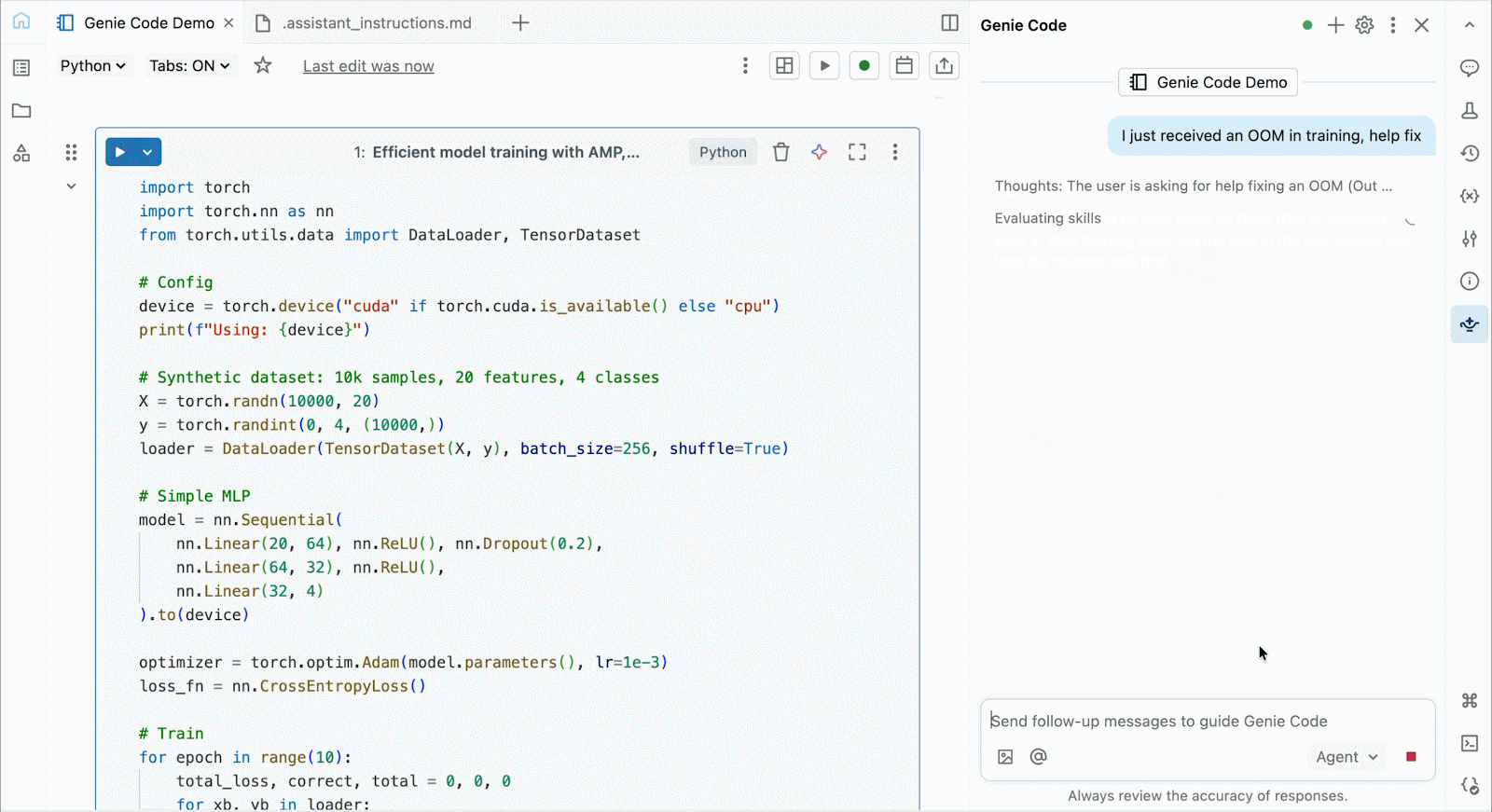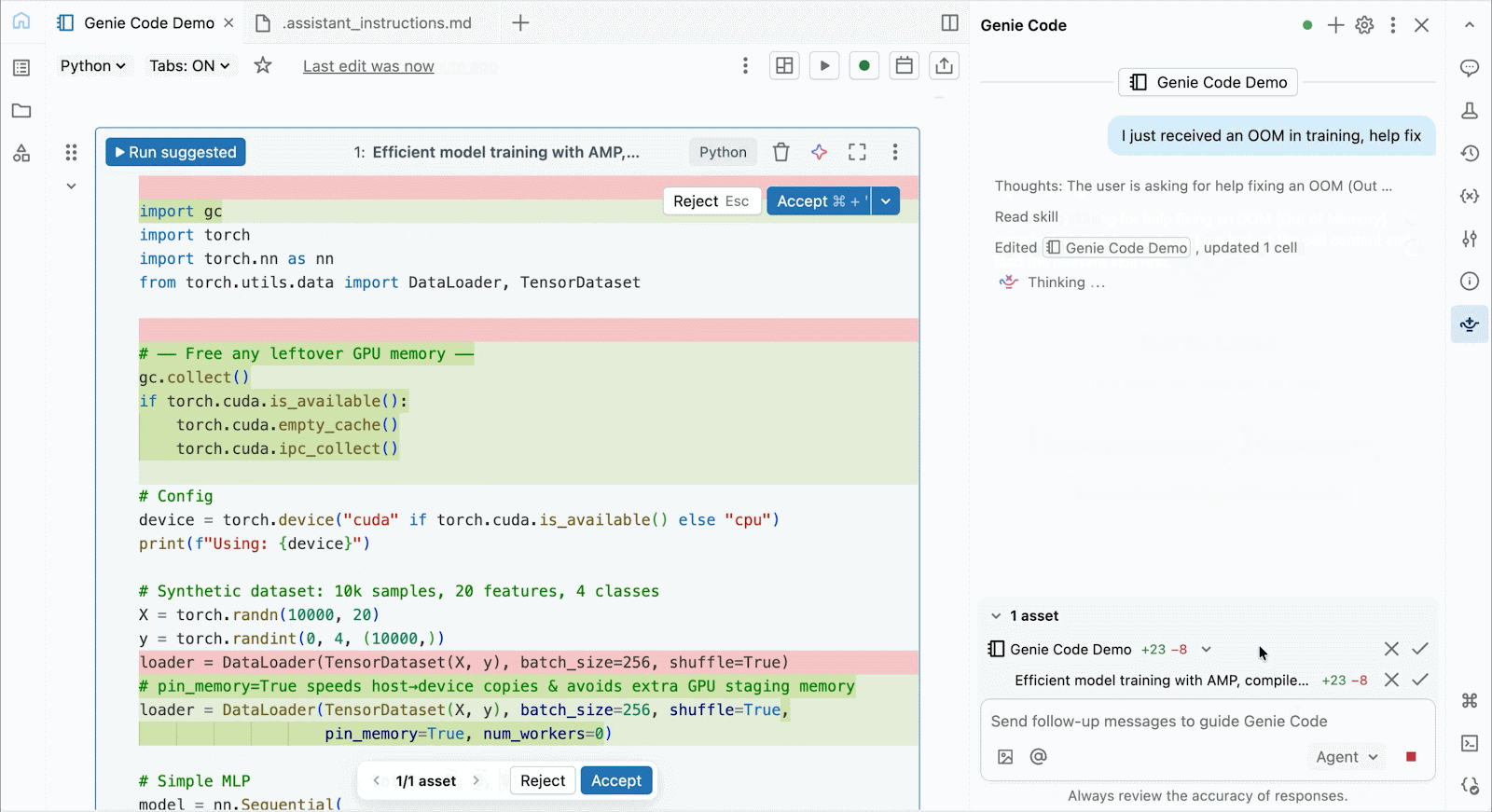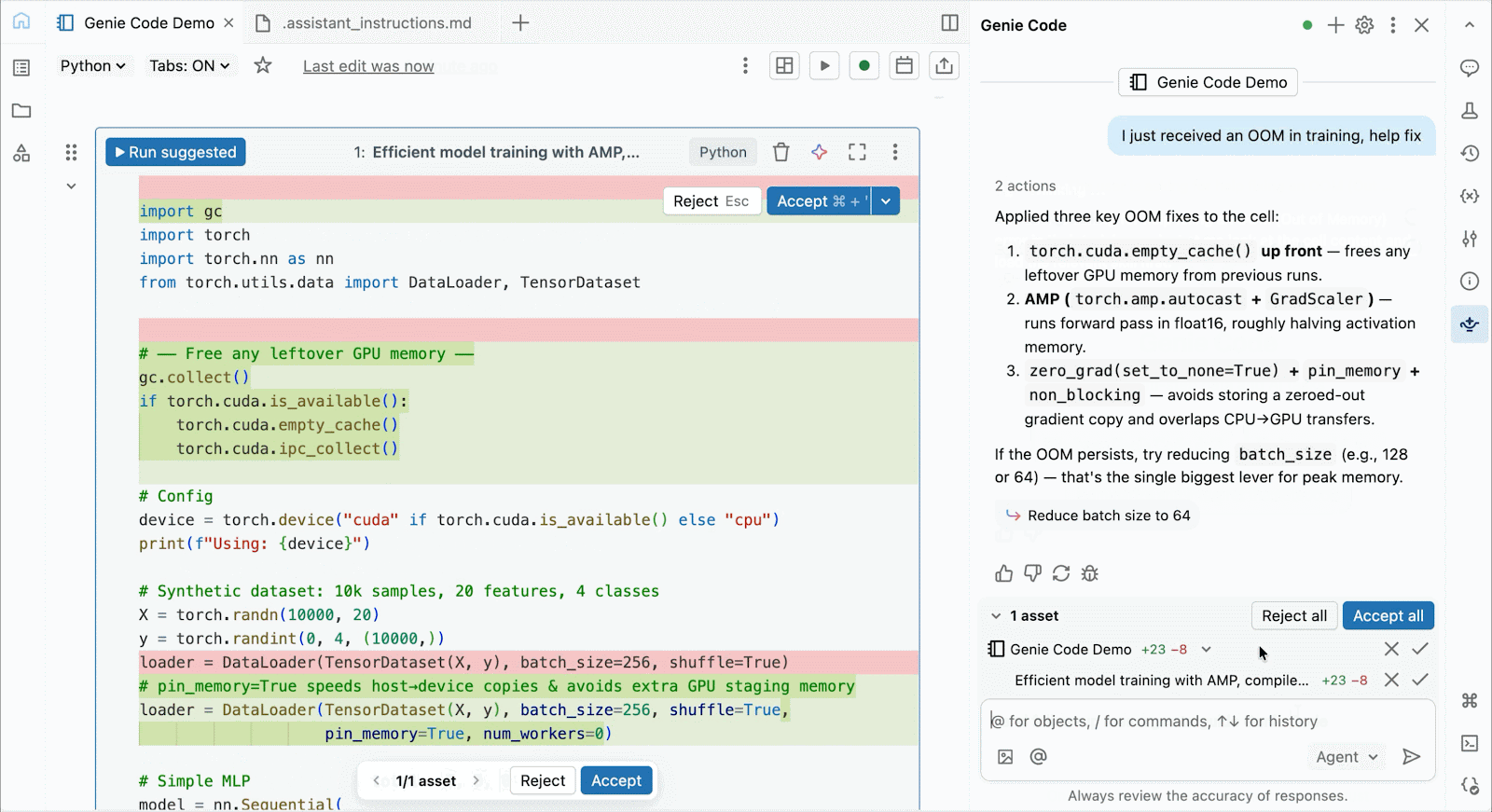
Nutzen Sie Genie Code, um Leistungsprobleme zu beheben, mit neuen Architekturen zu experimentieren oder knifflige Fehler bei der Modellkonvergenz oder kryptische Framework-Fehler zu beheben.
Lakeflow für produktionsreife Workloads
AI Runtime ist eine produktionsreife Plattform für beschleunigtes Computing. Entwickeln Sie Ihren Deep-Learning-Code in interaktiven Notebooks und nutzen Sie dann die volle Leistung von Lakeflow, um Jobs auf GPU-Compute zu übermitteln und zu orchestrieren. Sowohl Notebooks als auch benutzerdefinierte Code-Repositories können von Lakeflow für langlaufende oder geplante Jobs ausgeführt werden. Für Produktionsanforderungen wie CI/CD (Continuous Integration und Continuous Deployment) ist AI Runtime vollständig mit unseren Declarative Automation Bundles (DABs) kompatibel.
Mit unserer Lakeflow-Integration können Kunden das Modelltraining und die Feinabstimmung eng mit vorgelagerten Datenpipelines und nachgelagerten Produktionssystemen synchronisieren.
„Databricks' AI Runtime hat den Prozess des Trainings eines benutzerdefinierten Text-zu-Formel (TTF)-Modells stark vereinfacht. Ohne Infrastruktur-Setup oder Verzögerungen war es einfach, die richtige Rechenleistung basierend auf der Prompt-Größe und der Ausgabe-Token-Generierung auszuwählen. Dies ermöglichte es uns, schnell voranzukommen, unsere Lakehouse-Workflows beizubehalten und ein qualitativ hochwertiges Modell mit voller Governance zu liefern, wodurch die Zeit für Einrichtung, Training und Bereitstellung unseres Modells von Tagen auf Stunden reduziert wurde.“—Nikhil Sunderraj, Principal Machine Learning Engineer, FactSet Research Systems, Inc.
Runtime optimiert für verteiltes Deep Learning
Verteilte Trainings-Workloads können mühsam vorzubereiten, zu debuggen und zu beobachten sein. Von der Fehlersuche bei RDMA-Setups über die Verfolgung von Telemetriedaten von mehreren GPUs bis hin zur richtigen Softwarekonfiguration können Benutzer leicht kritische Details übersehen, die das Modelltraining drastisch verlangsamen.
Stattdessen ist AI Runtime für den gesamten Deep-Learning-Lebenszyklus optimiert – und wurde entwickelt, um Ihnen Zeit zu sparen. Wichtige Abhängigkeiten wie PyTorch und CUDA sind vorinstalliert, zusammen mit optimierter Unterstützung für verteilte Trainings-Frameworks wie Ray, Hugging Face Transformers, Composer und andere Bibliotheken, sodass Sie sofort mit dem Training beginnen können, ohne Umgebungen verwalten zu müssen. Kunden können auch ihre eigenen Bibliotheken mitbringen, von Unsloth bis TorchRec bis hin zu benutzerdefinierten Trainingsschleifen.

Integrierte SDKs und Observability-Tools vereinfachen die Verwaltung verteilter Trainings-Workloads. MLflow ermöglicht eine tiefe Observability von GPU-Workloads mit automatischer Verfolgung der GPU-Auslastung und Trainings-Experimente. Egal, ob Sie Foundation Models feinabstimmen oder Prognose- und Personalisierungsmodelle trainieren, die Runtime ist optimiert, um Trainings-Workflows mit minimalem Einrichtungsaufwand zu beschleunigen.
Die heutige Public Preview von AI Runtime unterstützt verteiltes Training über 8x H100s in einem einzelnen Knoten, wobei die Unterstützung für mehrere Knoten derzeit in der Private Preview ist.
„Databricks' AI Runtime ermöglicht es uns, LLM-Workloads (Fine-Tuning und Inferenz) ohne Infrastruktur-Overhead direkt in unserem Lakehouse auszuführen. Diese nahtlose Integration vereinfacht unsere Pipelines und ermöglicht eine effiziente Nutzung von GPUs, sodass wir unseren Kunden qualitativ hochwertige KI-Einblicke liefern und uns auf Innovation statt auf Infrastruktur konzentrieren können.“—Lucas Froguel, Senior AI Platform Engineer, YipitData
Zentralisierte Datengovernance und Observability
AI Runtime integriert sich nativ in das Databricks Lakehouse und ermöglicht es Ihnen, GPU-Workloads dort auszuführen und zu steuern, wo sich Ihre Daten befinden. Dies eliminiert fragmentierte Workflows und vereinfacht den Weg von der Experimentierung zur Produktion.
- Zentralisierte Governance mit Unity Catalog: Wenden Sie konsistente Zugriffskontrollen, Lineage und Governance-Richtlinien sowohl für Daten- als auch für KI-Workloads an, um eine sichere und konforme Nutzung von GPU-Ressourcen zu ermöglichen.
- Vereinheitlichte Observability: Verfolgen und überwachen Sie alle Workloads – CPU und GPU – an einem Ort mithilfe nativer Systemtabellen für einheitliches Auditing, Nutzungsverfolgung und operative Einblicke.
Ihre KI-Workloads laufen vollständig innerhalb Ihrer Unternehmensdatenperimeter und bieten starke Governance und Sicherheit, ohne die Flexibilität für Experimente und Skalierung zu beeinträchtigen.
„Die Nutzung der serverlosen GPU-Unterstützung von Databricks innerhalb unseres Lakehouse ermöglicht es uns, fortschrittliche Audio- und multimodale Modelle effizient und ohne Infrastruktur-Overhead zu trainieren. Diese nahtlose Integration vereinfacht Workflows und ermöglicht eine effiziente Nutzung von GPU-Ressourcen, sodass wir Hochleistungssysteme liefern und uns auf Innovation konzentrieren können.“—Arjuna Siva, VP of Infotainment & Connectivity, Rivian and Volkswagen Group Technologies
Integration von Next-Generation GPU-Innovation von NVIDIA
Die Nachfrage nach beschleunigter Rechenleistung wächst weiter für KI-Workloads und agentenbasierte Systeme. AI Runtime ermöglicht es mehr Databricks-Kunden, NVIDIA-Hardware zu nutzen, um ihre KI-Workloads zu beschleunigen und ihr Geschäft voranzutreiben. Wir freuen uns, weiterhin mit NVIDIA zusammenzuarbeiten, um unseren Kunden die neueste NVIDIA-Technologie, wie den RTX PRO 4500 Blackwell Server Edition, der auf der GTC 2026 angekündigt wurde, anzubieten.
"Da die KI-Adaption branchenübergreifend beschleunigt wird, benötigen Unternehmen skalierbare, hochleistungsfähige Infrastrukturen, um ihre Daten- und KI-Workloads zu betreiben. NVIDIA-Technologien bringen beschleunigte Leistung in das AI Runtime-Angebot für die Databricks Lakehouse Platform."—Pat Lee, Vice President, Strategic Partnerships bei NVIDIA.
Jetzt mit AI Runtime loslegen
Um Ihnen den Einstieg zu erleichtern, haben wir mehrere Beispiel-Notebooks und Starter-Guides zusammengestellt:
- Lesen Sie unsere Dokumentation für detaillierte Anweisungen zur Einrichtung und täglichen Nutzung.
- Starter-Vorlagen für das Training von Empfehlungssystemen, klassischen ML-Modellen, Fine-Tuning von LLMs und mehr!
- Migrationsleitfaden von Classic Compute GPU-Workloads zu Serverless.
Bitte wenden Sie sich an Ihr Account-Team, um mehr zu erfahren oder wenn Sie Fragen haben!
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.