Lernen Sie KARL kennen: Ein schnellerer Agent für Unternehmenswissen, gestützt auf benutzerdefiniertes RL
Reinforcement Learning für Unternehmens-Agents
Den vollständigen technischen Bericht finden Sie hier. Sind Sie daran interessiert, Databricks Custom RL für Ihren Unternehmens-Agenten auszuprobieren? Klicken Sie hier.
Die verbesserten Reasoning-Fähigkeiten aktueller Modelle haben zu einer explosionsartigen Zunahme von Agents geführt, die für Wissensarbeit angewendet werden, z. B. zum Schreiben von Code, zum Stellen von Fragen zu Unternehmensdaten und zur Automatisierung gängiger Workflows. Obwohl die für Unternehmensaufgaben verwendeten Modelle sehr leistungsstark sind, sind sie auch extrem teuer, und die Inferenzkosten sind für viele Anwendungsfälle untragbar geworden. In diesem Beitrag und dem zugehörigen technischen Bericht beschreiben wir unsere Erfahrungen mit dem Einsatz von Reinforcement Learning (RL) zur Erstellung benutzerdefinierter Modelle für Anwendungsfälle, die ein wichtiger Key-Bestandteil unseres Produkts Agent Bricks sind. Dieses Beispiel zeigt, dass es bei relativ geringen Kosten möglich ist, benutzerdefinierte Modelle zu erstellen, die Frontier-Modelle in allen drei kritischen Dimensionen – Inferenzkosten, Latenz und Qualität – deutlich übertreffen. Unsere Ergebnisse decken sich mit anderen Beobachtungen in der Branche, wie z. B. dem Composer-Modell von Cursor, bei dem eine RL-basierte Anpassung sowohl die Geschwindigkeit als auch die Qualität im Vergleich zu Alternativen drastisch verbessern konnte.
KARL: Ein schnellerer, stärkerer und günstigerer Wissensagent für Databricks-Nutzer
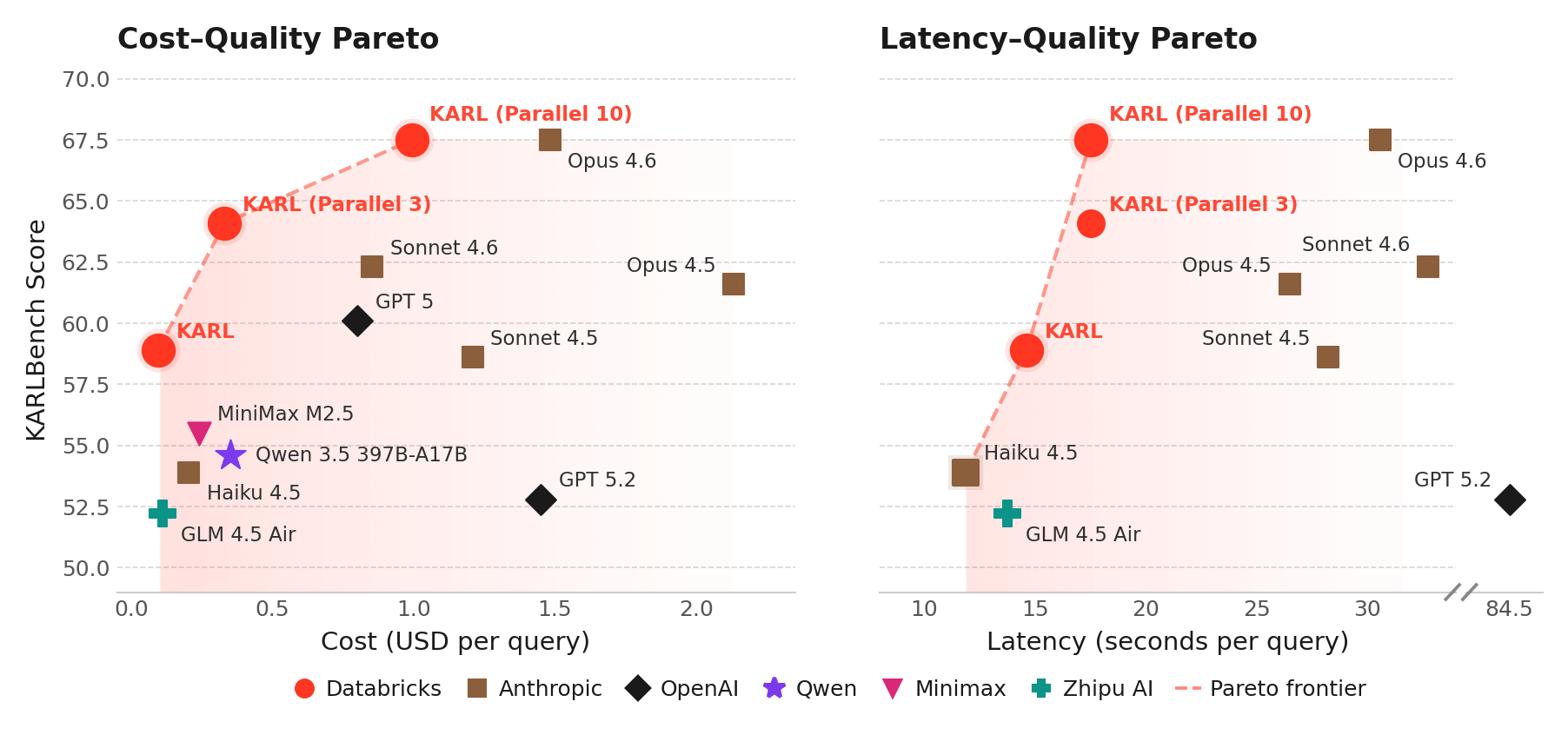
Das von uns trainierte Modell, das wir KARL nennen, adressiert eine kritische Unternehmensfähigkeit, das fundierte Reasoning: die Beantwortung von Fragen durch die Suche nach Dokumenten, die Faktenermittlung, den Abgleich von Informationen und das Ziehen von Schlussfolgerungen über Dutzende oder Hunderte von Schritten hinweg. Fundiertes Reasoning wird für mehrere Databricks-Produkte benötigt, wie z. B. den Agent Bricks Knowledge Assistant. Im Gegensatz zu Mathematik und Programmierung sind der fundierten Reasoning- Tasks schwer zu überprüfen – oft gibt es keine einzig richtige Antwort. In solchen Situationen ist es besonders schwierig, Reinforcement Learning zu einer guten Lösung zu führen.
Mithilfe von RL -basierten Techniken und einer beiDatabricks entwickelten Infrastruktur erreicht KARL die Performance der weltweit leistungsstärksten proprietären Modelle zu einem Bruchteil der Bereitstellungskosten und Latenz, auch bei neuen Tasks des fundierten Reasonings, die es noch nie zuvor gesehen hatte. ( Siehe den technischen Bericht für alle Details.) Wir haben dies mit nur wenigen tausend GPU-Stunden Training und ausschließlich synthetischen Daten erreicht.
In internen Tests mit menschlichen Nutzern lieferte KARL bessere und umfassendere Antworten als unsere bestehenden Produkte und die neuesten Frontier-Modelle. Diese Forschung fließt in die Databricks-Agents ein, die Sie heute verwenden, wie Agent Bricks, wobei die Antworten in Ihren unstrukturierten und strukturierten Daten im Databricks Lakehouse verankert werden.
Eine wiederverwendbare RL-Pipeline für Databricks-Kunden
Wir freuen uns, Ihnen mitteilen zu können, dass dieselben RL-Pipelines und die Infrastruktur, die wir zur Erstellung von KARL (und anderen Agents, über die wir bald sprechen werden) verwendet haben, jetzt für Databricks-Kunden verfügbar sind, die die Modell-Performance verbessern und die Kosten für ihre agentenbasierten Workloads mit hohem Volumen reduzieren möchten. Nahezu alle realen Unternehmens-Tasks sind schwer zu überprüfen. KARL ebnet daher den Weg – nicht nur für eine bessere Erfahrung für Databricks-Nutzer –, sondern auch für unsere Kunden, damit sie ihre eigenen benutzerdefinierten RL-Modelle für ihre populären Agenten erstellen können. Unsere Private Preview von Custom RL, die auf Serverless GPU compute basiert, ermöglicht es Ihnen, die KARL-Infrastruktur zu nutzen, um eine effizientere, domänenspezifische Version Ihres Agenten zu erstellen. Wenn Sie einen KI-Agenten haben, der schnell skaliert, und daran interessiert sind, ihn mit RL zu optimieren, melden Sie sich hier an, um Ihr Interesse an dieser Preview zu bekunden.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.