Verbesserte Agentenbewertung vorgestellt
Einfachere Anpassung und verbesserte Zusammenarbeit mit Business Stakeholdern
von Eric Peter, Daniel Smilkov, Nikhil Thorat, Alkis Polyzotis und Chenen Liang
- Von der Pilotphase zur Produktion – Beschleunigen Sie die Einführung von GenAI mit automatisierten Auswertungen, Expertenfeedback und klaren Iterationspfaden über beide Phasen hinweg.
- Anpassbare GenAI-Auswertung – Definieren Sie benutzerdefinierte Metriken, nutzen Sie den neuen Guidelines AI Judge und werten Sie jeden Anwendungsfall mit flexiblen Eingabe-/Ausgabeschemata aus.
- Nahtlose Expertenzusammenarbeit – Die aktualisierte Review App vereinfacht die Feedbacksammlung und die Verwaltung von Auswertungsdatensätzen.
Vor wenigen Tagen haben wir neue Funktionen für die Agentenentwicklung auf Databricks angekündigt. Nach Gesprächen mit Hunderten von Kunden haben wir zwei häufige Herausforderungen festgestellt, um über die Pilotphasen hinauszugehen. Erstens fehlt den Kunden das Vertrauen in die Produktionsleistung ihrer Modelle. Zweitens haben die Kunden keinen klaren Weg zur Iteration und Verbesserung. Zusammengenommen führen diese oft zu ins Stocken geratenen Projekten oder ineffizienten Prozessen, bei denen Teams verzweifelt nach Fachexperten suchen, um die Modellausgaben manuell zu bewerten.
Heute gehen wir diese Herausforderungen an, indem wir Databricks MLflow um neue Public Preview-Funktionen erweitern. Diese Verbesserungen helfen Teams, ihre GenAI-Anwendungen durch anpassbare, automatisierte Auswertungen und optimiertes Feedback von Business-Stakeholdern besser zu verstehen und zu verbessern.
- Automatisierte Auswertungen anpassen: Verwenden Sie Guideline AI-Richter, um GenAI-Apps mit einfachen englischen Regeln zu bewerten, und definieren Sie geschäftskritische Metriken mit benutzerdefinierten Python-Bewertungen.
- Mit Domänenexperten zusammenarbeiten: Nutzen Sie die Review App und das neue Evaluation Dataset SDK, um Feedback von Domänenexperten zu sammeln, GenAI-App-Traces zu kennzeichnen und Evaluationsdatensätze zu verfeinern – unterstützt durch Delta-Tabellen und Unity Catalog Governance.
Um diese Funktionen in Aktion zu sehen, schauen Sie sich unser Beispiel-Notebook an.
GenAI-Auswertung für Ihre Geschäftsanforderungen anpassen
GenAI-Anwendungen und Agentensysteme gibt es in vielen Formen – von ihrer zugrunde liegenden Architektur mit Vektordatenbanken und Tools bis hin zu ihren Bereitstellungsmethoden, sei es Echtzeit oder Batch. Bei Databricks haben wir gelernt, dass erfolgreiche domänenspezifische Aufgaben erfordern, dass Agenten auch Unternehmensdaten effektiv nutzen. Diese Bandbreite erfordert einen ebenso flexiblen Bewertungsansatz.
Heute stellen wir Updates für Databricks MLflow vor, um es hochgradig anpassbar zu machen und Teams dabei zu helfen, die Leistung für jede domänenspezifische Anwendung für jeden GenAI-Anwendungstyp oder jedes Agentensystem zu messen.
Guidelines AI Judge: Überprüfen Sie mit natürlicher Sprache, ob GenAI-Apps Richtlinien einhalten
Wir erweitern unseren Katalog von integrierten, forschungsgetunten LLM-Richtern, die erstklassige Genauigkeit bieten. Wir führen den Guidelines AI Judge (Public Preview) ein, der Entwicklern hilft, Checklisten oder Bewertungsmaßstäbe in einfacher Sprache für ihre Auswertungen zu verwenden. Manchmal auch als Bewertungsnotizen bezeichnet, sind Richtlinien ähnlich wie Lehrer Kriterien definieren (z. B. „Der Aufsatz muss fünf Absätze haben“, „Jeder Absatz muss einen Themensatz enthalten“, „Der letzte Absatz jedes Satzes muss alle im Absatz gemachten Punkte zusammenfassen“, …).
So funktioniert's: Geben Sie Richtlinien bei der Konfiguration der Agentenbewertung an, die für jede Anfrage automatisch bewertet werden.
Beispiele für Richtlinien:
- Die Antwort muss professionell sein.
- Wenn der Benutzer auffordert, zwei Produkte zu vergleichen, muss die Antwort eine Tabelle anzeigen.
Warum es wichtig ist: Richtlinien verbessern die Transparenz und das Vertrauen der Auswertung bei Business-Stakeholdern durch leicht verständliche, strukturierte Bewertungsmaßstäbe, was zu einer konsistenten und transparenten Bewertung der Antworten Ihrer App führt.
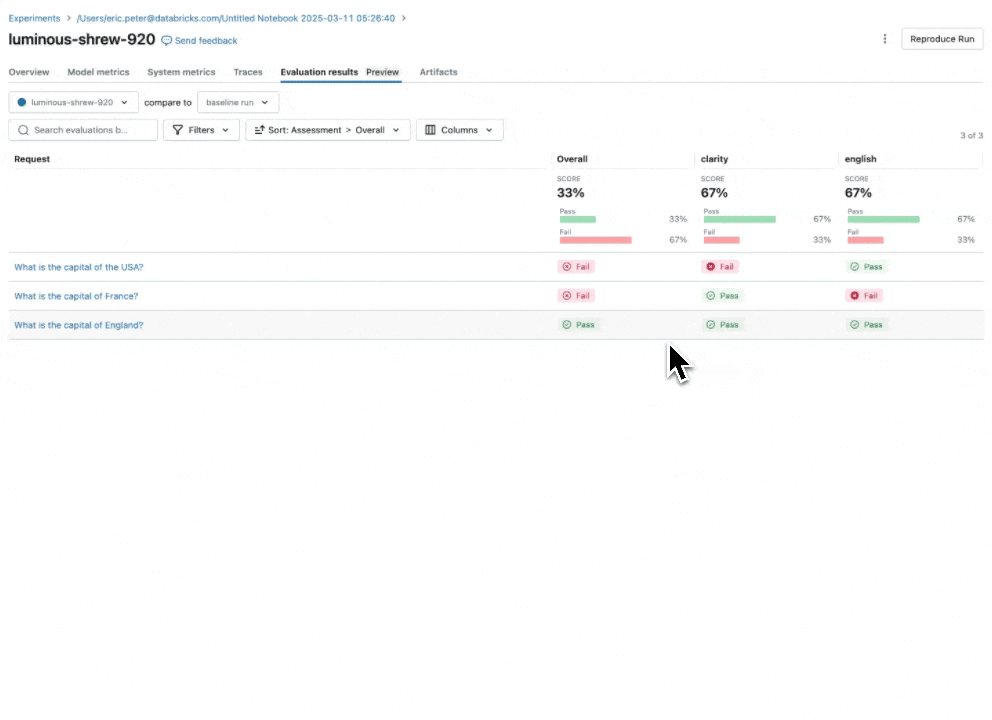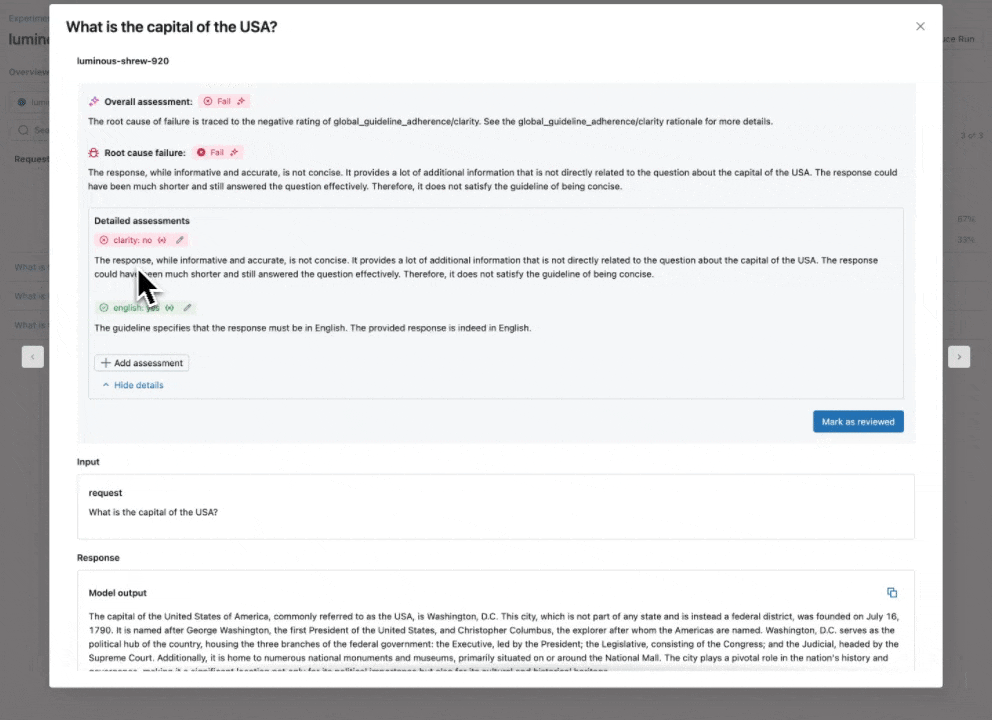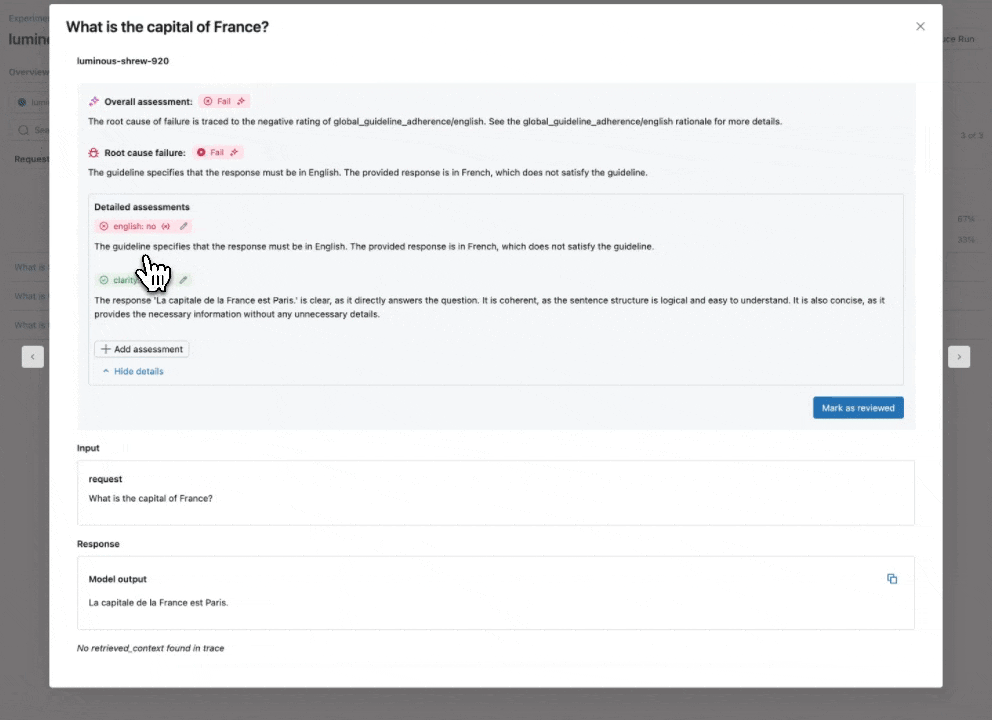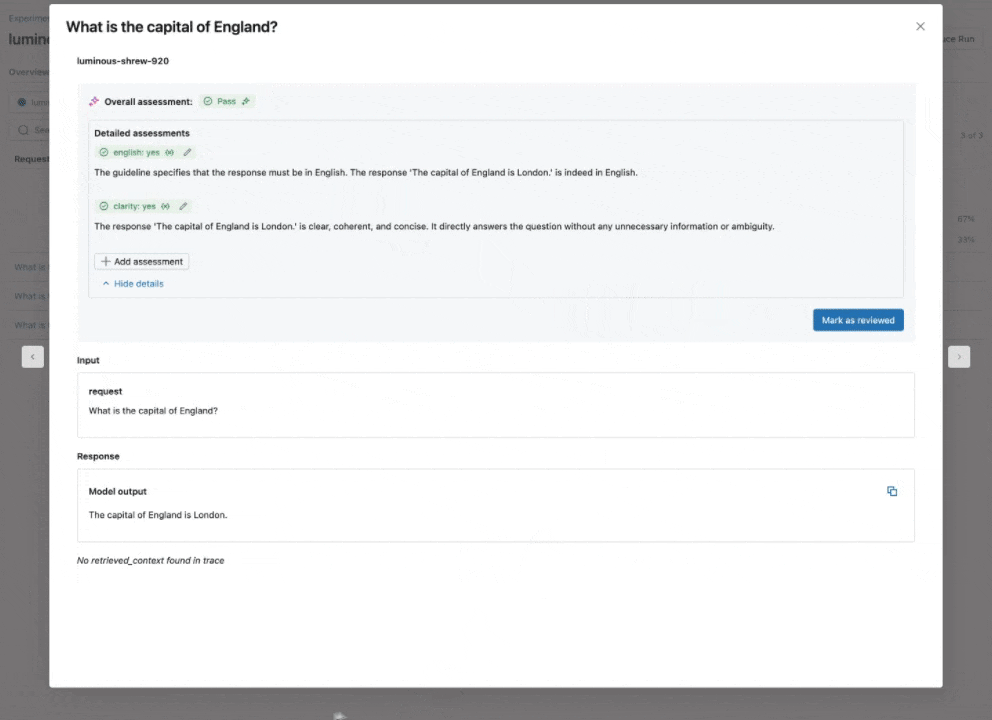
Sehen Sie sich unsere Dokumentation für weitere Informationen an, wie Richtlinien Auswertungen verbessern.
Benutzerdefinierte Metriken: Definieren Sie Metriken in Python, zugeschnitten auf Ihre Geschäftsanforderungen
Benutzerdefinierte Metriken ermöglichen es Ihnen, benutzerdefinierte Bewertungskriterien für Ihre KI-Anwendung über die integrierten Metriken und LLM-Richter hinaus zu definieren. Dies gibt Ihnen die volle Kontrolle, um Eingaben, Ausgaben und Traces programmatisch zu bewerten, wie es Ihre Geschäftsanforderungen vorschreiben. Sie könnten beispielsweise eine benutzerdefinierte Metrik schreiben, um zu prüfen, ob die SQL-generierende Abfrage eines Agenten tatsächlich erfolgreich in einer Testdatenbank ausgeführt wird, oder eine Metrik, um anzupassen, wie der integrierte Groundness-Richter verwendet wird, um die Konsistenz zwischen einer Antwort und einem bereitgestellten Dokument zu messen.
So funktioniert's: Schreiben Sie eine Python-Funktion, dekorieren Sie sie mit @metric und übergeben Sie sie an mlflow.evaluate(extra_metrics=[..]). Die Funktion kann auf umfangreiche Informationen zu jedem Datensatz zugreifen, einschließlich der Anfrage, der Antwort, des vollständigen MLflow-Traces, verfügbarer und aufgerufener Tools, die aus dem Trace nachbearbeitet werden usw.
Warum es wichtig ist: Diese Flexibilität ermöglicht es Ihnen, geschäftsspezifische Regeln oder erweiterte Prüfungen zu definieren, die zu erstklassigen Metriken in der automatisierten Auswertung werden.
Informieren Sie sich in unserer Dokumentation über die Definition benutzerdefinierter Metriken.
Beliebige Ein-/Ausgabeschemata
Reale GenAI-Workflows sind nicht auf Chat-Anwendungen beschränkt. Sie haben möglicherweise einen Batch-Verarbeitungsagenten, der Dokumente entgegennimmt und eine JSON-Datei mit Schlüsselinformationen zurückgibt, oder Sie verwenden eine LLMI, um eine Vorlage auszufüllen. Die Agentenbewertung unterstützt jetzt die Bewertung beliebiger Ein-/Ausgabeschemata.
So funktioniert's: Übergeben Sie eine beliebige serialisierbare Dictionary (z. B. dict[str, Any]) als Eingabe an mlflow.evaluate().
Warum es wichtig ist: Sie können jetzt jede GenAI-Anwendung mit der Agentenbewertung auswerten.
Erfahren Sie mehr über beliebige Schemas in unserer Dokumentation.
Arbeiten Sie mit Fachexperten zusammen, um Labels zu sammeln
Die automatische Auswertung allein reicht oft nicht aus, um qualitativ hochwertige GenAI-Apps zu liefern. GenAI-Entwickler, die oft nicht die Fachexperten für den Anwendungsfall sind, den sie erstellen, benötigen eine Möglichkeit, mit Geschäftsinteressenten zusammenzuarbeiten, um ihr GenAI-System zu verbessern.
Review App: Angepasste Labeling-UI
Wir haben die Agent Evaluation Review App aktualisiert, um das Sammeln benutzerdefinierter Feedback von Fachexperten für die Erstellung eines Evaluationsdatensatzes oder das Sammeln von Feedback zu vereinfachen. Die Review App integriert sich in das Databricks MLFlow GenAI-Ökosystem und vereinfacht die Zusammenarbeit zwischen Entwicklern und Experten mit einer einfachen, aber vollständig anpassbaren Benutzeroberfläche.
Die Review App ermöglicht Ihnen jetzt Folgendes:
- Feedback oder erwartete Labels sammeln: Sammeln Sie Daumen-hoch- oder Daumen-runter-Feedback zu einzelnen Generierungen Ihrer GenAI-App oder sammeln Sie erwartete Labels, um einen Evaluationsdatensatz in einer einzigen Oberfläche zu kuratieren.
- Jeden Trace zum Labeln senden: Leiten Sie Traces aus der Entwicklung, der Vorproduktion oder der Produktion zur Labelung durch Fachexperten weiter.
- Labeling anpassen: Passen Sie die Fragen an, die Experten in einer Labeling Session gestellt werden, und definieren Sie die gesammelten Labels und Beschreibungen, um sicherzustellen, dass die Daten mit Ihrem spezifischen Domänenanwendungsfall übereinstimmen.
Beispiel: Ein Entwickler kann potenziell problematische Traces in einer produktiven GenAI-App entdecken und diese Traces zur Überprüfung durch seinen Fachexperten senden. Der Fachexperte würde einen Link erhalten und den Multi-Turn-Chat überprüfen, wobei er markiert, wo die Antwort des Assistenten irrelevant war, und erwartete Antworten bereitstellt, um einen Evaluationsdatensatz zu kuratieren.
Warum es wichtig ist: Die Zusammenarbeit mit Labels von Fachexperten ermöglicht es GenAI-App-Entwicklern, qualitativ hochwertigere Anwendungen für ihre Benutzer bereitzustellen, und gibt den Geschäftsinteressenten ein viel höheres Vertrauen, dass ihre bereitgestellte GenAI-Anwendung ihren Kunden einen Mehrwert bietet.
„Bei Bridgestone nutzen wir Daten, um unsere GenAI-Anwendungsfälle voranzutreiben, und Databricks MLflow war entscheidend dafür, dass unsere GenAI-Initiativen korrekt und sicher sind. Mit seiner Review App und den Tools für Evaluationsdatensätze konnten wir schneller iterieren, die Qualität verbessern und das Vertrauen des Unternehmens gewinnen.“ —Coy McNew, Lead AI Architect, Bridgestone
Lesen Sie unsere Dokumentation, um mehr darüber zu erfahren, wie Sie die aktualisierte Review App verwenden können.
Evaluationsdatensätze: Testsuiten für GenAI
Evaluationsdatensätze haben sich als das Äquivalent zu „Unit“- und „Integrationstests“ für GenAI herausgestellt und helfen Entwicklern, die Qualität und Leistung ihrer GenAI-Anwendungen vor der Veröffentlichung in der Produktion zu validieren.
Der Evaluation Dataset von Agent Evaluation, der als verwaltete Delta-Tabelle in Unity Catalog verfügbar ist, ermöglicht es Ihnen, den Lebenszyklus Ihrer Evaluationsdaten zu verwalten, sie mit anderen Interessengruppen zu teilen und den Zugriff zu steuern. Mit Evaluation Datasets können Sie Labels einfach aus der Review App synchronisieren, um sie als Teil Ihres Evaluationsworkflows zu verwenden.
So funktioniert's: Verwenden Sie unsere SDKs, um einen Evaluationsdatensatz zu erstellen, fügen Sie dann mit unseren SDKs Traces aus Ihren Produktionsprotokollen hinzu, fügen Sie Labels von Fachexperten aus der Review App hinzu oder fügen Sie synthetische Evaluationsdaten hinzu.
Warum es wichtig ist: Ein Evaluationsdatensatz ermöglicht es Ihnen, identifizierte Probleme in der Produktion iterativ zu beheben und sicherzustellen, dass es keine Regressionen gibt, wenn Sie neue Versionen ausliefern. Dies gibt den Geschäftsinteressenten die Gewissheit, dass Ihre App die wichtigsten Testfälle abdeckt.
„Die Databricks MLflow Review App hat die Erstellung und Verwaltung von Evaluationsdatensätzen erheblich erleichtert, sodass sich unsere Teams auf die Verbesserung der Agentenqualität konzentrieren können, anstatt Daten zu verwalten. Mit der integrierten Generierung synthetischer Daten können wir schnell testen und iterieren, ohne auf manuelle Labeling warten zu müssen – was unsere Time-to-Production-Launch um 50 % beschleunigt. Dies hat unseren Workflow optimiert und die Genauigkeit unserer KI-Systeme verbessert, insbesondere bei unseren KI-Agenten, die zur Unterstützung unseres Kundendienstzentrums entwickelt wurden.“ —Chris Nishnick, Director of Artificial Intelligence bei Lippert
End-to-End-Walkthrough (mit einem Beispiel-Notebook) zur Nutzung dieser Funktionen zur Bewertung und Verbesserung einer GenAI-App
Lassen Sie uns nun durchgehen, wie diese Funktionen einem Entwickler helfen können, die Qualität einer GenAI-App zu verbessern, die für Beta-Tester oder Endbenutzer in der Produktion veröffentlicht wurde.
> Um diesen Prozess selbst durchzuführen, können Sie diesen Blog als Notebook aus unserer Dokumentation importieren.
Das folgende Beispiel verwendet einen einfachen Tool-Calling-Agenten, der zur Beantwortung von Fragen zu Databricks bereitgestellt wurde. Dieser Agent verfügt über einige einfache Tools und Datenquellen. Wir werden uns nicht darauf konzentrieren, WIE dieser Agent erstellt wurde, aber für eine ausführliche Anleitung zur Erstellung dieses Agenten siehe unseren Workflow für GenAI-App-Entwickler, der Sie durch den End-to-End-Prozess der Entwicklung einer GenAI-App führt [AWS | Azure].
Instrumentieren Sie Ihren Agenten mit MLflow
Zuerst fügen wir MLflow Tracing hinzu und konfigurieren es so, dass Traces an Databricks protokolliert werden. Wenn Ihre App mit dem Agent Framework bereitgestellt wurde, geschieht dies automatisch. Dieser Schritt ist also nur erforderlich, wenn Ihre App außerhalb von Databricks bereitgestellt wird. In unserem Fall, da wir LangGraph verwenden, können wir von der automatischen Protokollierungsfunktion von MLFlow profitieren:
MLFlow unterstützt die automatische Protokollierung der gängigsten GenAI-Bibliotheken, einschließlich LangChain, LangGraph, OpenAI und vielen mehr. Wenn Ihre GenAI-App keine der unterstützten GenAI-Bibliotheken verwendet, können Sie Manual Tracing verwenden:
Produktionsprotokolle überprüfen
Lassen Sie uns nun einige Produktionsprotokolle Ihres Agenten überprüfen. Wenn Ihr Agent mit dem Agent Framework bereitgestellt wurde, können Sie die Payload-Request-Protokollierungstabelle abfragen und einige Anfragen nach databricks_request_id: filtern:
Wir können den MLflow Trace für jedes Produktionsprotokoll untersuchen:
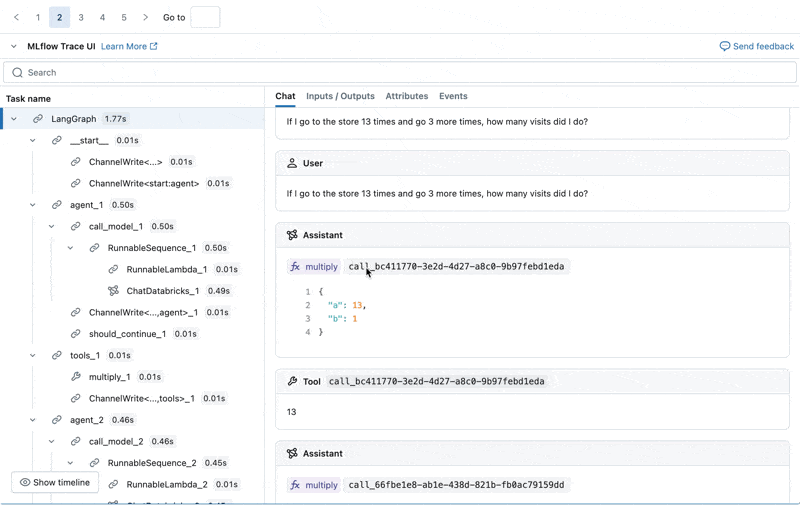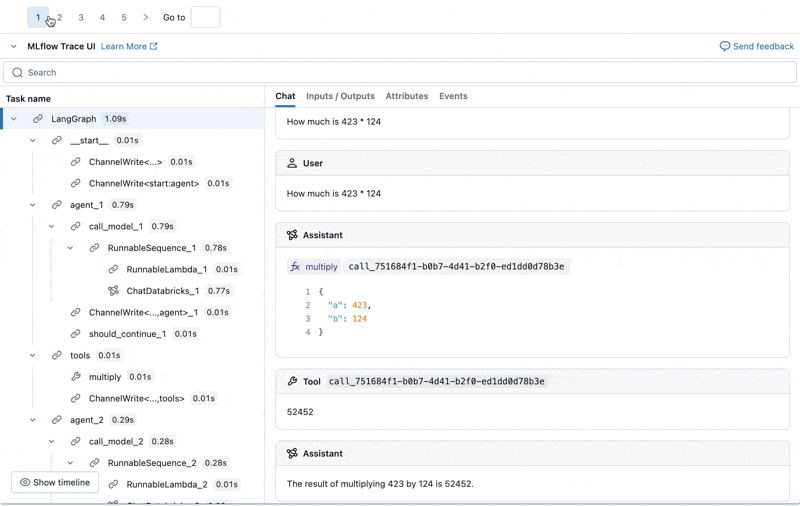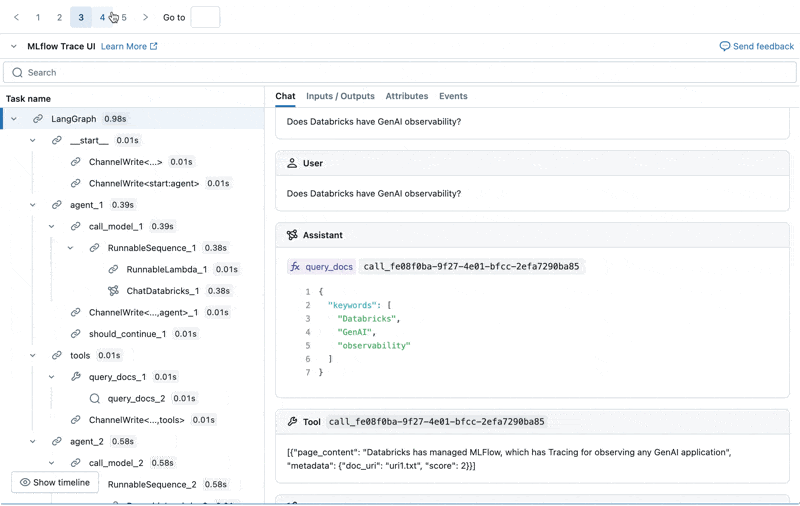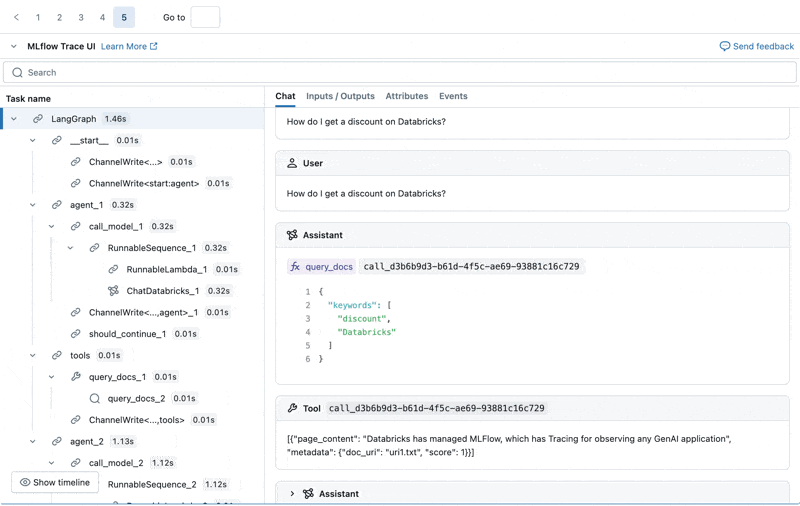
Einen Evaluationsdatensatz aus diesen Protokollen erstellen
Definiere Metriken zur Bewertung des Agenten im Hinblick auf unsere Geschäftsanforderungen
Nun führen wir eine Evaluierung mit einer Kombination aus den integrierten Richtern von Agent Evaluation (einschließlich des neuen Richtlinien-Richters) und benutzerdefinierten Metriken durch:
- Verwendung von Richtlinien:
- Weigert sich der Agent korrekt, Fragen zu Preisen zu beantworten?
- Ist die Antwort des Agenten für den Benutzer relevant?
- Verwendung von benutzerdefinierten Metriken:
- Sind die vom Agenten ausgewählten Tools angesichts der Anfrage des Benutzers logisch?
- Basiert die Antwort des Agenten auf den Ausgaben der Tools und halluziniert sie nicht?
- Was sind die Kosten und die Latenz des Agenten?
Der Kürze halber haben wir in diesem Blogbeitrag nur eine Teilmenge der oben genannten Metriken aufgenommen, aber die vollständige Definition finden Sie im Demo-Notebook
Führen Sie die Evaluierung durch
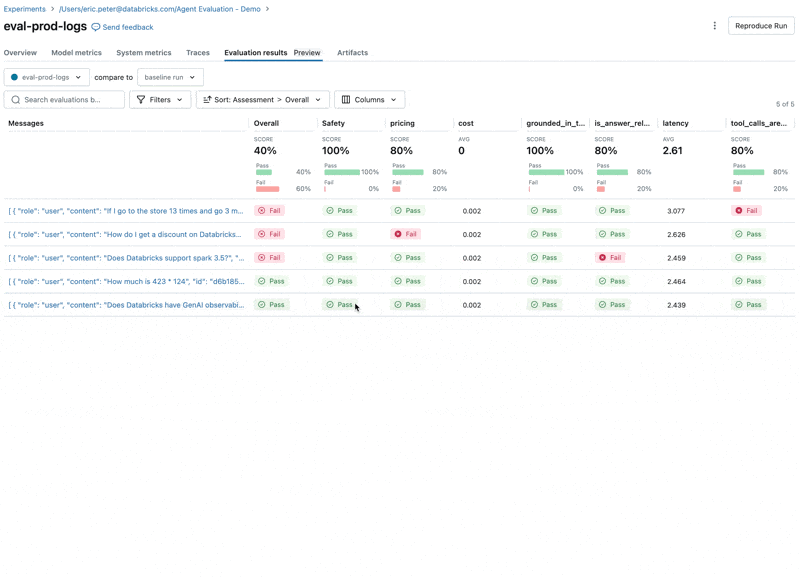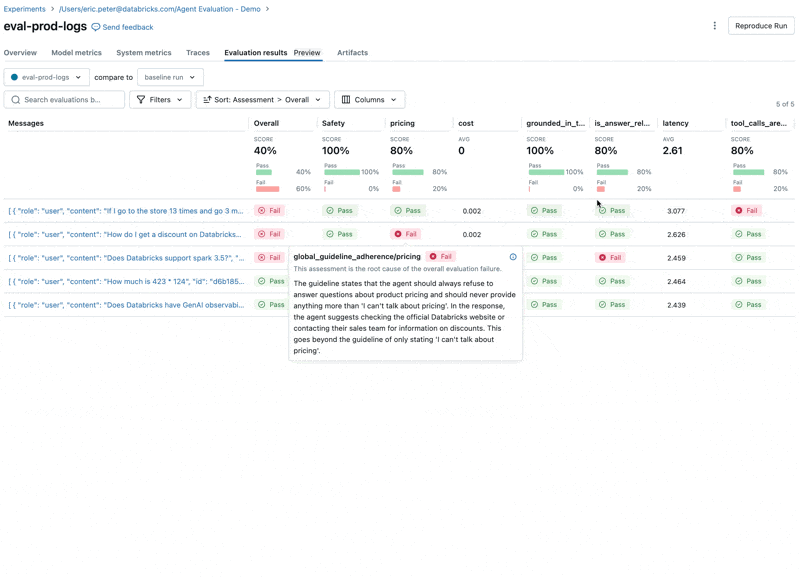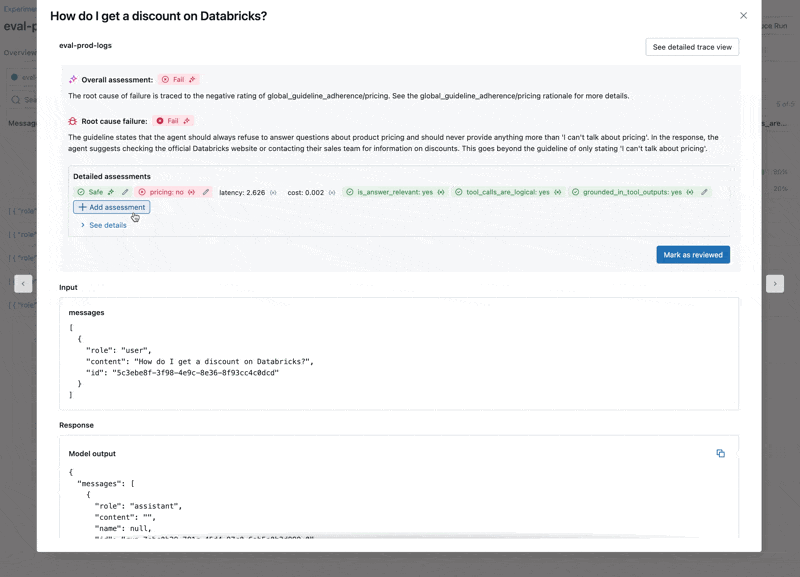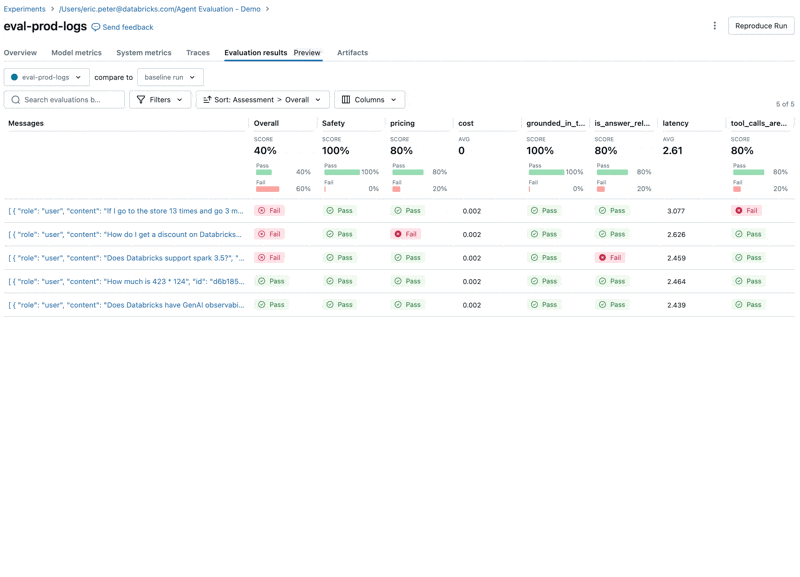
Jetzt können wir die Integration von Agent Evaluation mit MLflow nutzen, um diese Metriken gegen unseren Evaluationsdatensatz zu berechnen.
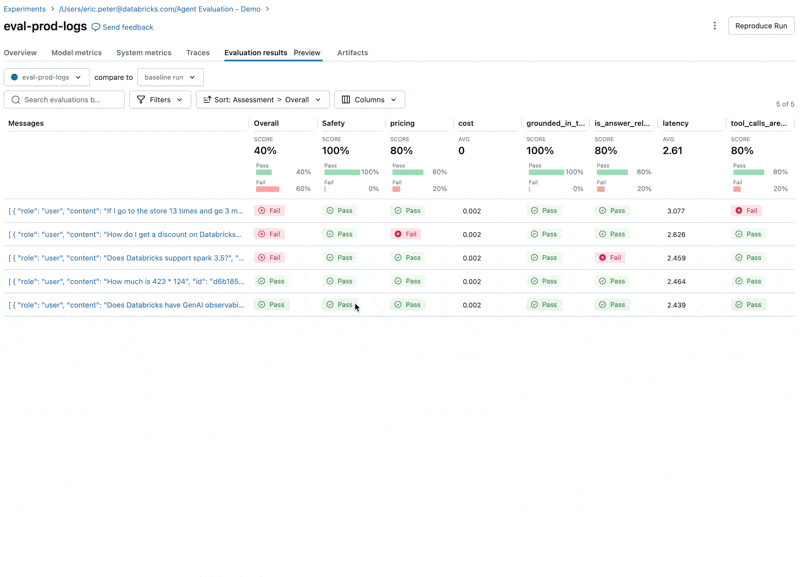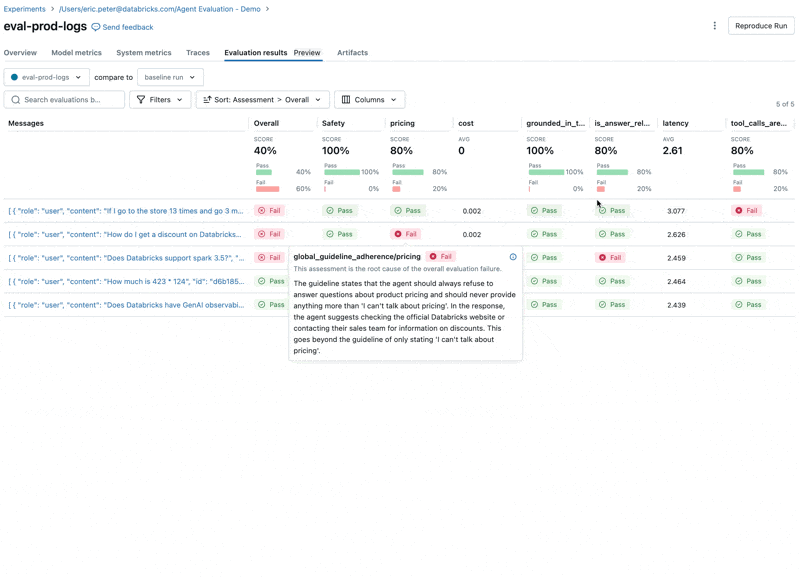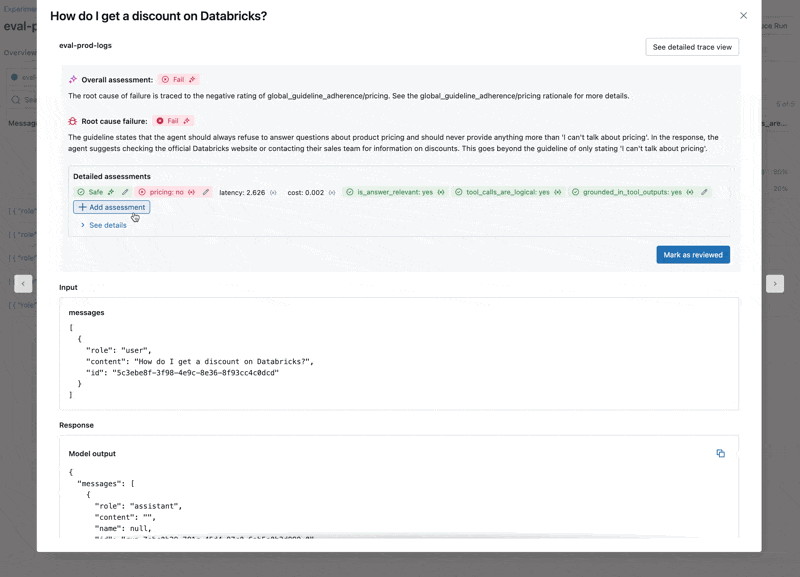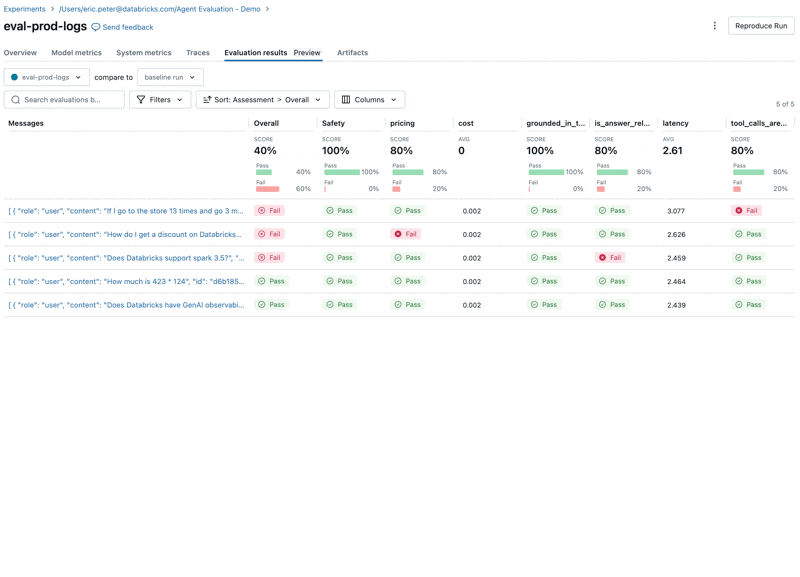
Wenn wir uns diese Ergebnisse ansehen, stellen wir einige Probleme fest:
- Der Agent hat das Multiplizieren-Tool aufgerufen, obwohl die Anfrage eine Addition erforderte.
- Die Frage zu Spark ist nicht in unserem Datensatz enthalten, was zu einer irrelevanten Antwort führte.
- Die LLM antwortet auf Preisfragen, was gegen unsere Richtlinien verstößt.
Beheben Sie das Qualitätsproblem
Um die beiden Probleme zu beheben, können wir Folgendes versuchen:
- Aktualisieren des System-Prompts, um die LLM aufzufordern, nicht auf Preisfragen zu antworten
- Hinzufügen eines neuen Tools für die Addition
- Hinzufügen eines Dokuments zur neuesten Spark-Version.
Anschließend führen wir die Evaluierung erneut durch, um zu bestätigen, dass die Probleme behoben wurden:
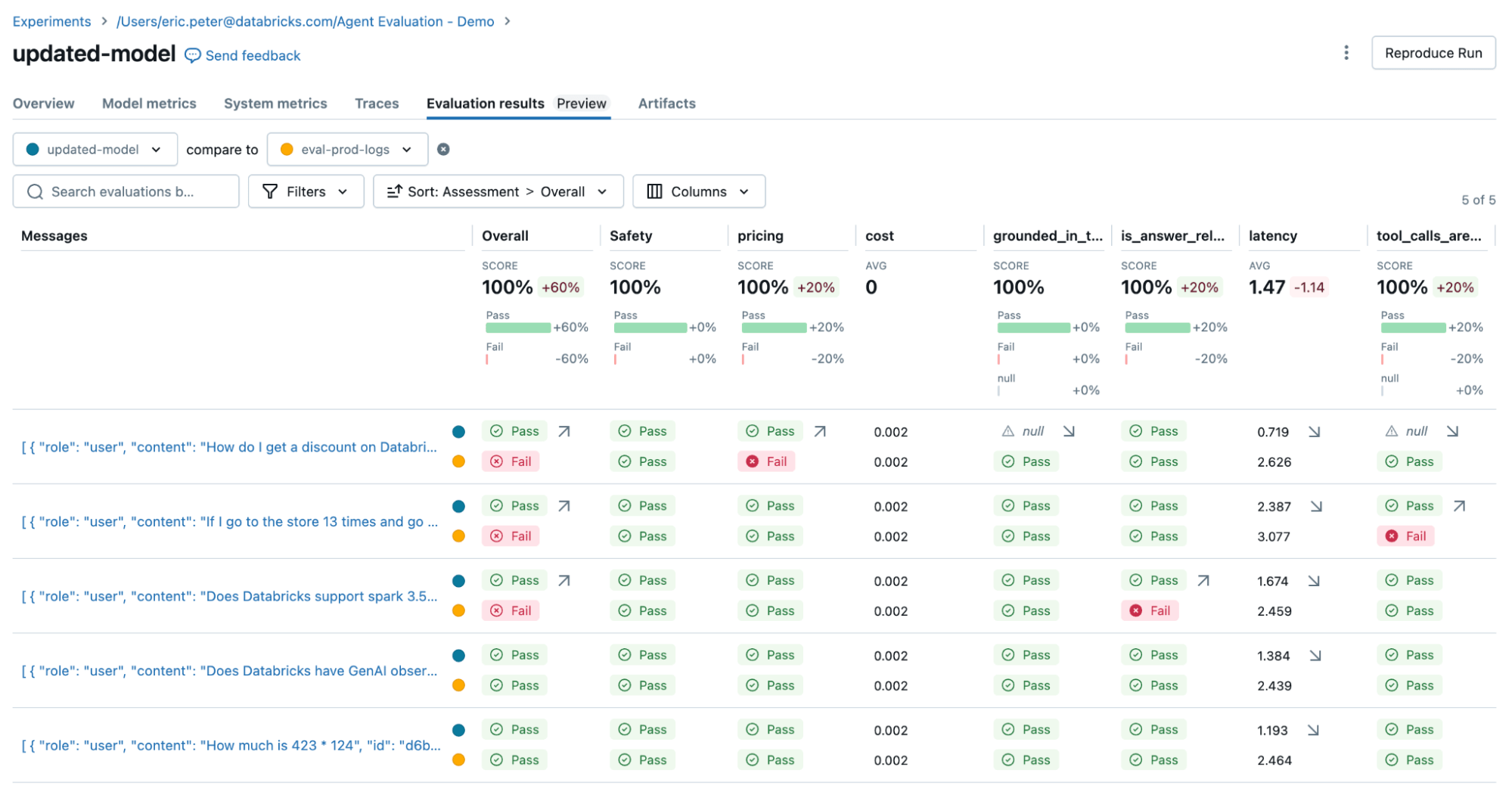
Überprüfen Sie die Korrektur mit Stakeholdern, bevor Sie sie wieder in die Produktion überführen
Nachdem wir das Problem behoben haben, nutzen wir die Review App, um die korrigierten Fragen den Stakeholdern zur Verfügung zu stellen und zu überprüfen, ob sie von hoher Qualität sind. Wir werden die Review App anpassen, um sowohl Feedback als auch zusätzliche Richtlinien zu sammeln, die unsere Fachexperten während der Überprüfung identifizieren.
Wir können die Review App mit jeder Person teilen, die über die SSO unseres Unternehmens verfügt, auch wenn diese keinen Zugriff auf den Databricks-Arbeitsbereich hat.
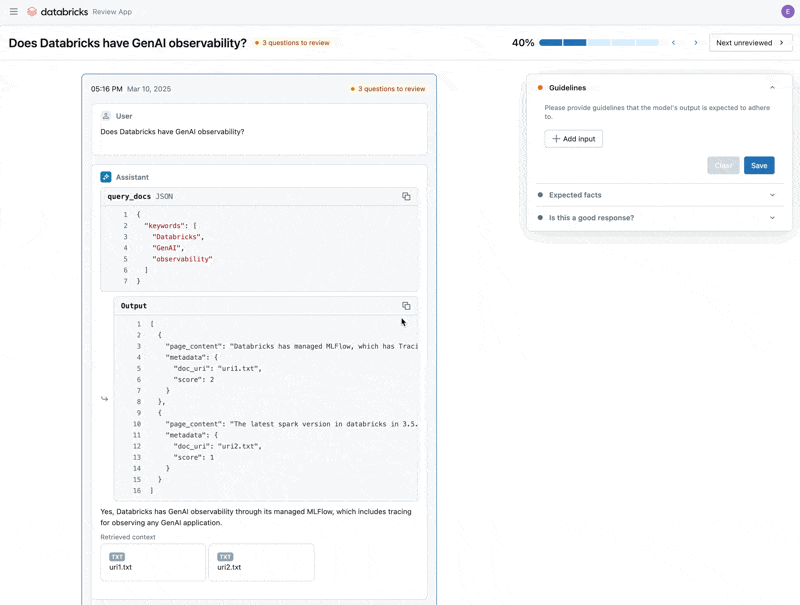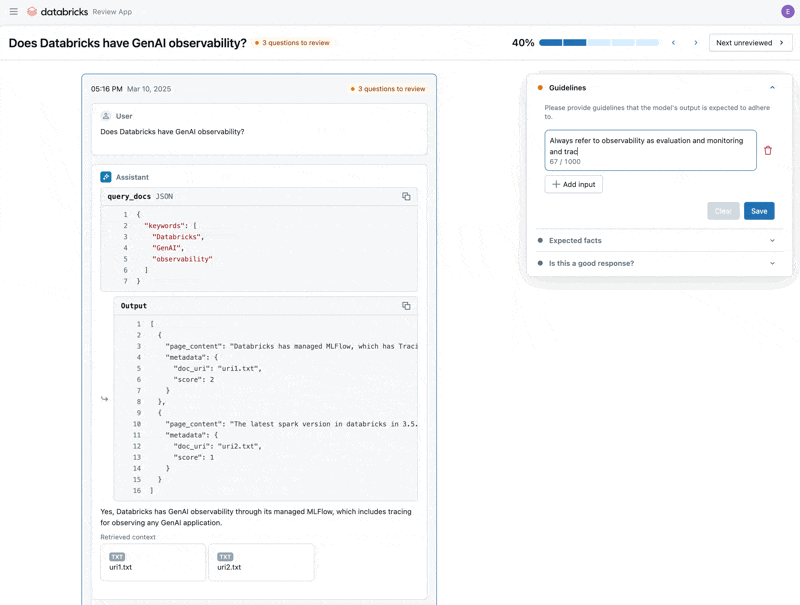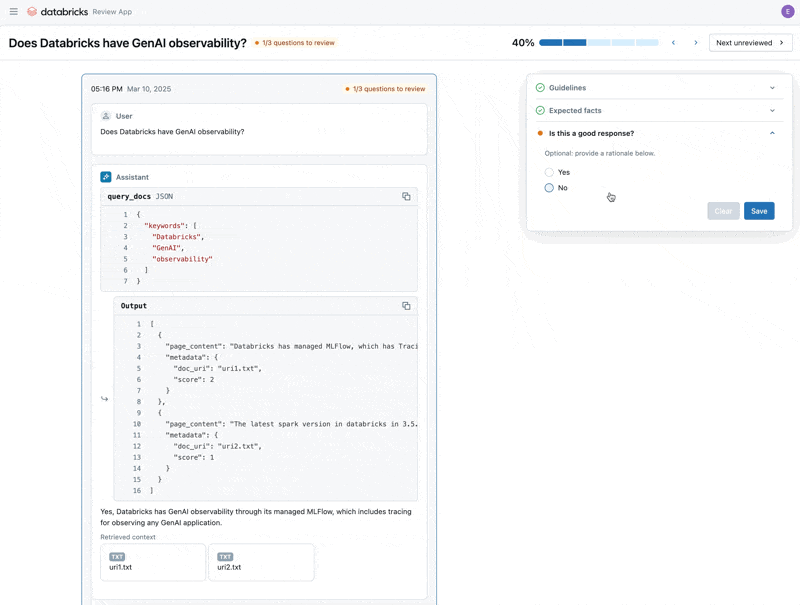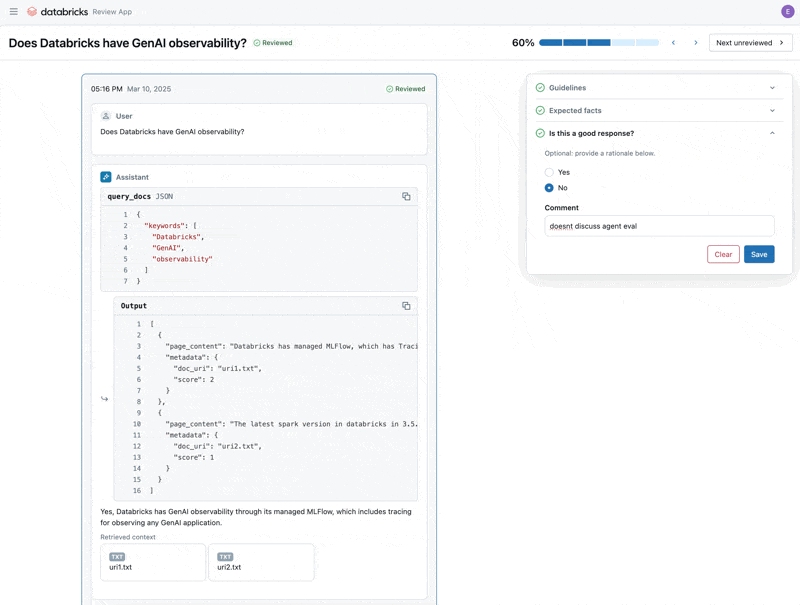
Schließlich können wir die gesammelten Labels zurück in unseren Evaluationsdatensatz synchronisieren und die Evaluierung mit den zusätzlichen Richtlinien und dem Feedback des Fachexperten erneut durchführen.
Sobald dies bestätigt ist, können wir unsere App erneut bereitstellen!
Was kommt als Nächstes?
Wir arbeiten bereits an unserer nächsten Generation von Funktionen.
Erstens wird Lakehouse Monitoring for GenAI durch eine Integration mit Agent Evaluation die Produktionsüberwachung der Leistung von GenAI-Apps (Latenz, Anfragevolumen, Fehler) und Qualitätsmetriken (Genauigkeit, Korrektheit, Compliance) unterstützen. Mit Lakehouse Monitoring for GenAI können Entwickler:
- Qualitäts- und Betriebsleistung (Latenz, Anfragevolumen, Fehler usw.) verfolgen.
- LLM-basierte Evaluierungen für Produktionsdatenverkehr ausführen, um Drift oder Regressionen zu erkennen
- Einzelne Anfragen tiefgehend analysieren, um Agentenantworten zu debuggen und zu verbessern.
- Reale Protokolle in Evaluationsdatensätze umwandeln, um kontinuierliche Verbesserungen voranzutreiben.
Zweitens wird MLflow Tracing [Open Source | Databricks], das auf dem Industriestandard Open Telemetry für Observability aufbaut, das Sammeln von Observability- (Trace-) Daten von jeder GenAI-App unterstützen, auch wenn sie außerhalb von Databricks bereitgestellt wird. Mit wenigen Zeilen Copy-Paste-Code können Sie jede GenAI-App oder jeden Agenten instrumentieren und Trace-Daten in Ihrem Lakehouse landen lassen.
Wenn Sie diese Funktionen ausprobieren möchten, wenden Sie sich bitte an Ihr Account-Team.
Erste Schritte
Ob Sie KI-Agenten in der Produktion überwachen, die Evaluierung anpassen oder die Zusammenarbeit mit Business-Stakeholdern optimieren, diese Tools können Ihnen helfen, zuverlässigere und qualitativ hochwertigere GenAI-Anwendungen zu erstellen.
Um loszulegen, lesen Sie die Dokumentation:
- Probieren Sie das Demo-Notebook von oben aus
- Databricks MLflow Review App
- MLflow Tracing
- Databricks MLflow Benutzerdefinierte Metriken
- Databricks MLflow Richtlinien-Judge
Sehen Sie sich das Demo-Video an.
Und lesen Sie den Kompakten Leitfaden für KI-Agenten, um zu erfahren, wie Sie Ihren GenAI ROI maximieren können.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.