Einführung der Verbundfunktionen von Lakehouse in Unity Catalog
Daten entdecken, abfragen und verwalten – ganz gleich, wo sie gespeichert sind
von Matei Zaharia, Andrew Li, Can Efeoglu, Cyrielle Simeone, Sachin Thakur und Daniel Tenedorio
Lakehouse Federation ist jetzt in der Public Preview verfügbar!
Datenteams stehen vor vielen Herausforderungen beim schnellen Zugriff auf die richtigen Daten, hauptsächlich aufgrund von Datenfragmentierung, dem Zeit- und Kostenaufwand für die Datenkonsolidierung und Schwierigkeiten bei der Verwaltung der Data Governance über viele Systeme hinweg.
Deshalb freuen wir uns, heute auf dem Data+AI Summit die Lakehouse Federation-Funktionen in Unity Catalog anzukündigen, die es Unternehmen ermöglichen, eine hochskalierbare und leistungsstarke Data-Mesh-Architektur mit einheitlicher Governance zu erstellen.
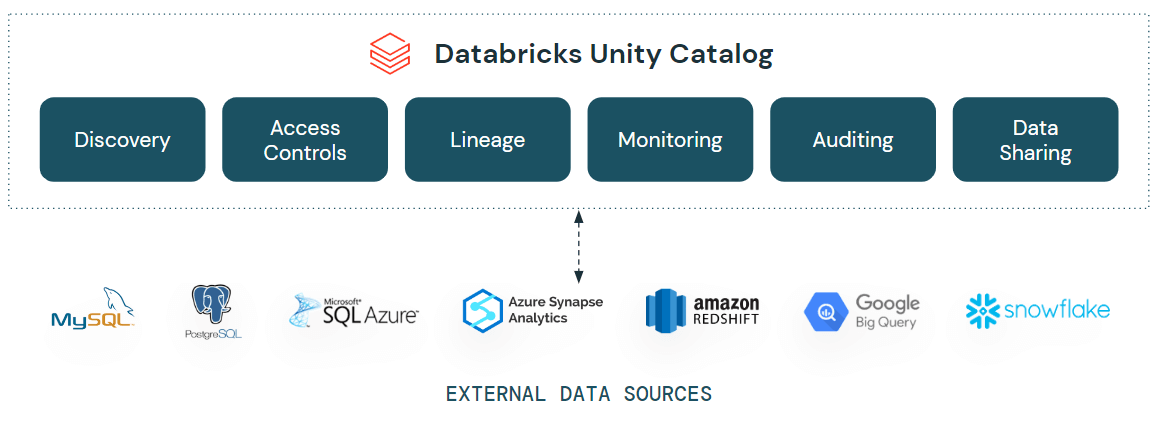
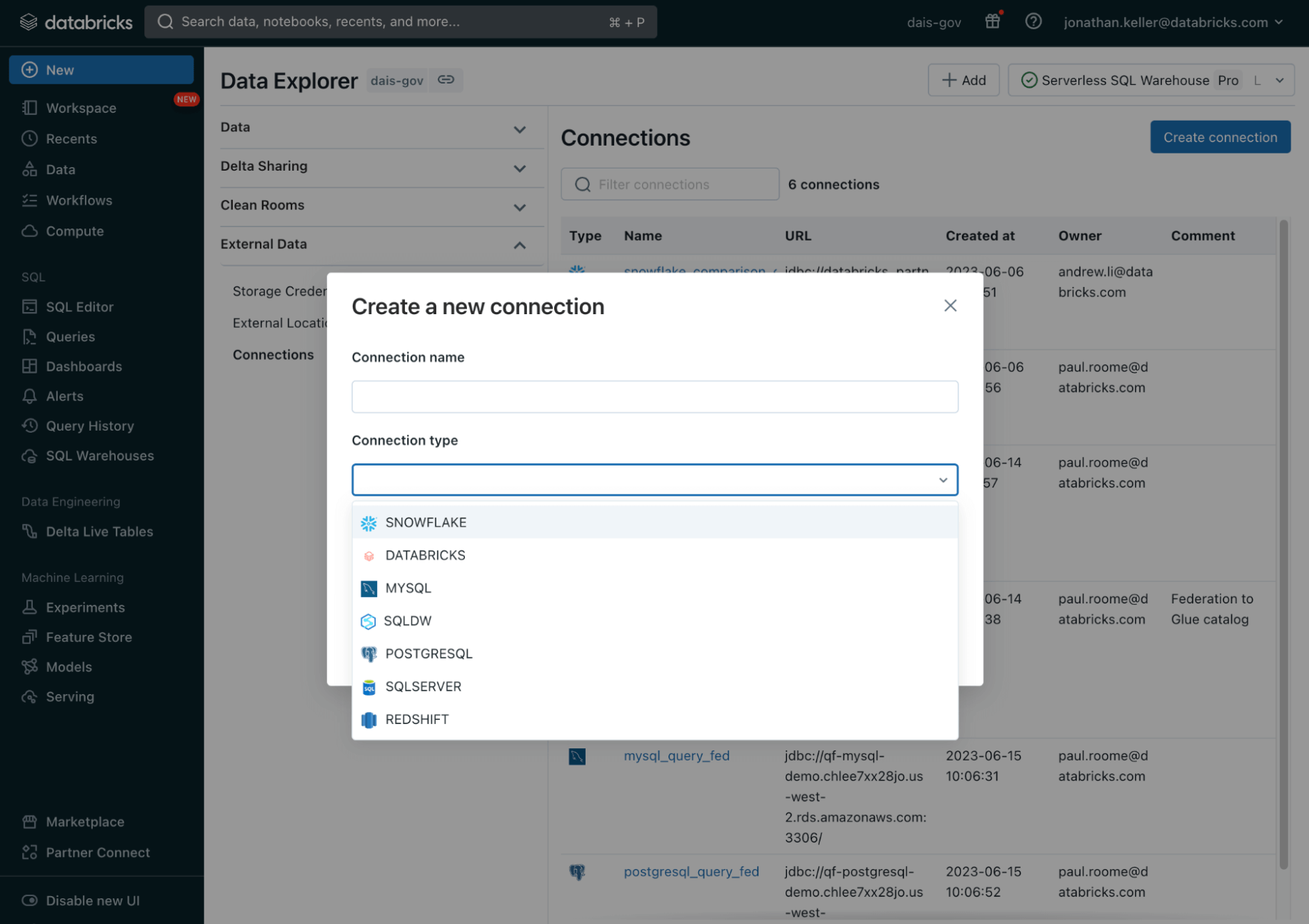
Unity Catalog bietet eine einheitliche Governance -Lösung für Daten und KI. Die Lakehouse Federation-Funktionen in Unity Catalog ermöglichen es Ihnen, Daten über Datenplattformen wie MySQL, PostgreSQL, Amazon Redshift, Snowflake, Azure SQL Database, Azure Synapse, Google BigQuery und weitere hinweg von Databricks aus zu entdecken, abzufragen und zu steuern, ohne die Daten verschieben oder kopieren zu müssen – alles in einer vereinfachten und einheitlichen Umgebung. Das bedeutet, dass die erweiterten Sicherheitsfunktionen von Unity Catalog wie Zugriffskontrollen auf Zeilen- und Spaltenebene, Erkennungsfunktionen wie Tags und Datenherkunft für diese externen Datenquellen verfügbar sein werden, was eine konsistente Governance gewährleistet.
„Sowohl Data Scientists als auch Geschäftsanwender können jetzt über eine einheitliche Benutzeroberfläche auf verschiedene Datenquellen zugreifen, wobei die Berechtigungen konsistent an einem Ort verwaltet werden“, so Jelle de Jong, Tech Lead bei Bayer. „Wir standardisieren unser Datenformat kontinuierlich auf Delta Lake, sind aber begeistert, dass Lakehouse Federation es uns ermöglicht hat, agil zu iterieren, bevor wir in die Datenextraktion investieren.“
Datenfragmentierung verlangsamt die Innovation.
Tausende von Organisationen jeder Größe treiben weltweit und in allen Branchen mit Daten und KI auf der Databricks Lakehouse Platform Innovationen voran. Doch aus historischen, organisatorischen oder technologischen Gründen sind die Daten über viele operative und Analytics-Systeme verstreut, was zu weiteren Herausforderungen führt:
- Daten sind schwer auffindbar und der Zugriff darauf ist schwierig: In den meisten Unternehmen sind wertvolle Daten auf mehrere Datenquellen verteilt. Diese können sich in mehreren Datenbanken, einem Data Warehouse, Objektspeichersystemen und mehr befinden. Dies führt zu unvollständigen Daten und Erkenntnissen, was Kunden daran hindert, fundierte Entscheidungen zu treffen und schneller zu innovieren.
- Langsame Ausführung aufgrund von Engpässen im Engineering: Um Daten über mehrere Datenquellen hinweg abzufragen, müssen Kunden ihre Daten in der Regel zuerst von externen Datenquellen auf die Plattform ihrer Wahl verschieben. Bei manchen Daten lohnt sich der Aufwand möglicherweise gar nicht. Bei manchen Daten dauert es zu lange, bis sie an einem einzigen, einheitlichen Ort landen, was die Innovation verlangsamt.
- Schwache Compliance in Silosystemen: Eine fragmentierte Governance führt zu doppeltem Aufwand und erhöht das Risiko, dass unangemessene Zugriffe oder Datenlecks nicht überwacht und abgewehrt werden können, was die Zusammenarbeit und die Demokratisierung von Daten behindert.
Vereinheitlichen Sie Ihre Datenlandschaft mit Lakehouse Federation in Unity Catalog
Lakehouse Federation geht diese kritischen Schwachstellen an und macht es für Organisationen einfach, isolierte Datensysteme als eine Erweiterung ihres Lakehouse bereitzustellen, abzufragen und zu verwalten. Mit diesen neuen Funktionen können Sie:
- Erstellen Sie eine einheitliche Ansicht Ihrer Datenlandschaft: Klassifizieren und entdecken Sie automatisch all Ihre strukturierten und unstrukturierten Daten an einem zentralen Ort und ermöglichen Sie allen in Ihrer Organisation, sicher auf alle verfügbaren Daten zuzugreifen und diese zu erkunden, ganz gleich, wo sie gespeichert sind.
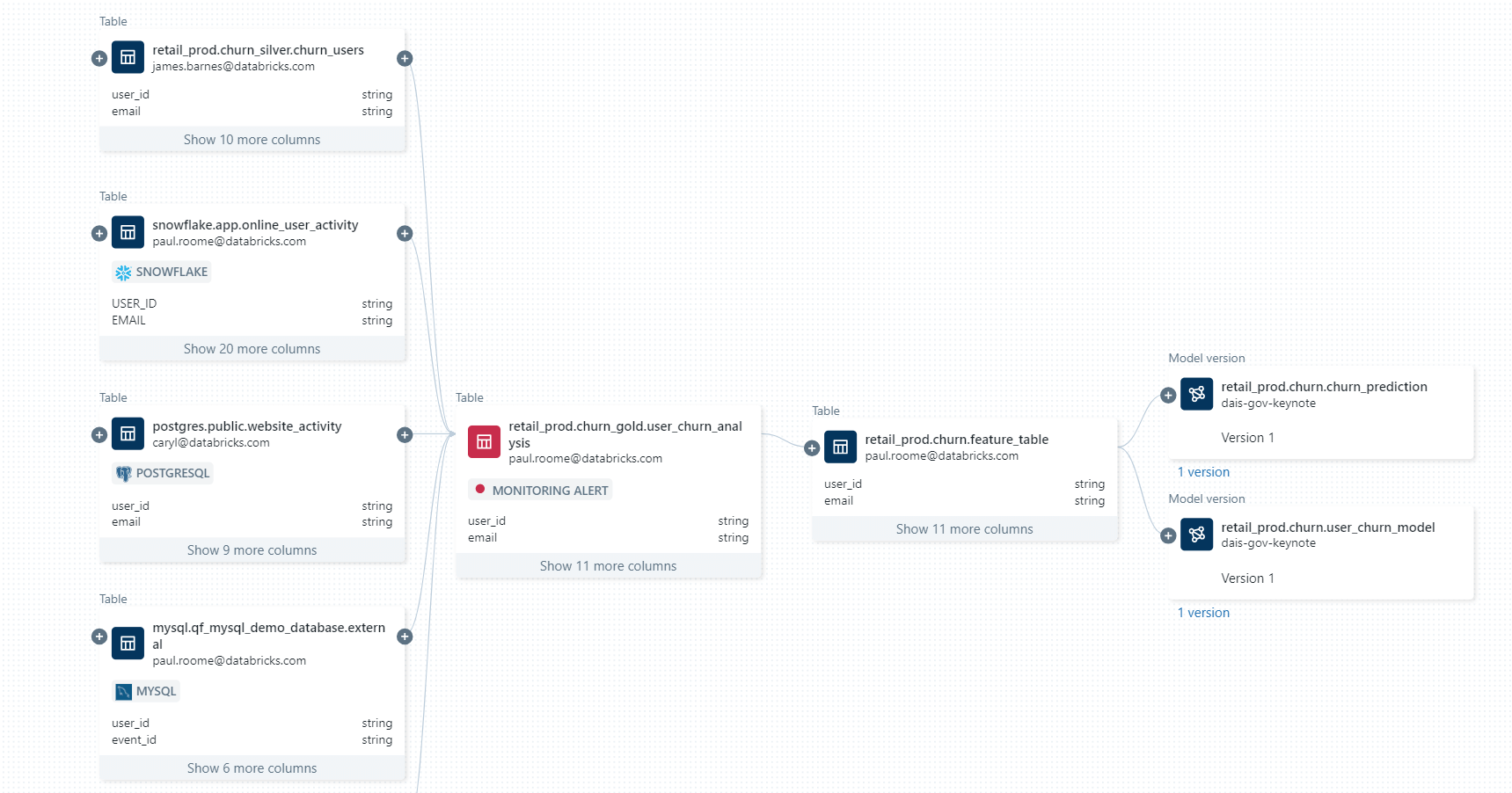
- Alle Daten effizient mit einer einzigen Engine abfragen und kombinieren: Beschleunigen Sie Ad-hoc-Analysen und Prototyping für all Ihre Daten-, Analysen- und KI-Anwendungsfälle mit den vollständigsten Daten – keine Erfassung erforderlich – mit einer einzigen Engine. Erweiterte, quellenübergreifende Abfrageplanung und Caching gewährleisten eine optimale Abfrage-Performance, auch beim Zugriff auf und der Kombination von Daten von mehreren Plattformen mit einer einzigen Abfrage.
- Schutz von Daten über Datenquellen hinweg: Verwenden Sie ein einziges Berechtigungsmodell, um Zugriffsregeln festzulegen, anzuwenden und all Ihre Daten über verschiedene Datenquellen hinweg zu schützen. Wenden Sie Regeln wie Sicherheit auf Zeilen- und Spaltenebene, tagbasierte Richtlinien und ein zentralisiertes Auditing plattformübergreifend und konsistent an, verfolgen Sie die Datennutzung und erfüllen Sie die Compliance-Anforderungen mit integrierter Datenherkunft und Auditierbarkeit.
„Mit Lakehouse Federation können wir Daten – wie Nutzungs-, Verkaufs- und Spieletelemetriedaten – aus verschiedenen Quellen und über mehrere Clouds hinweg kombinieren und alles von einem Ort aus einsehen und abfragen. „Wir belassen die Daten jetzt in der ursprünglichen Datenquelle, können sie aber vom Databricks Lakehouse aus nutzen“, sagte Felix Baker, Head of Datendienste bei SEGA Europe. „Da wir unsere Finanzdaten, die häufig aktualisiert werden, nicht mehr verschieben müssen, sparen wir wertvolle Zeit, die wir darauf verwenden können, unseren Kunden das bestmögliche Spielerlebnis zu bieten.“
„Lakehouse Federation hat es uns ermöglicht, bei der Konsolidierung unserer bestehenden Datenlandschaft in Unity Catalog schneller voranzukommen. Das vereinfacht die Data Governance von Shell – mehr Datensätze werden an einem Ort auffindbar, die Authentifizierung wird standardisiert und die datensatzübergreifende Abfrage mit einer gemeinsamen Programmiersprache wird möglich", so Bryce Bartmann, Chief Digital Technology Advisor bei Shell. "Letztendlich macht uns das effektiver bei der Bewältigung der Transformation, die heute im Energiesektor stattfindet."
Diese neuen Funktionen in Verbindung mit der kürzlich angekündigten offenen Hive-Schnittstelle bedeuten, dass Unternehmen ihre Datenverwaltung, -ermittlung und -governance in Unity Catalog zentralisieren und sich von einer Vielzahl von Computing-Plattformen aus damit verbinden können, darunter Amazon EMR, Apache Spark, Amazon Athena, Presto, Trino und andere. Die neue Benutzeroberfläche macht die Pflege mehrerer Datenkataloge überflüssig und gewährleistet eine konsistente Data Governance über diese Plattformen hinweg.
Was kommt als Nächstes?
Diese Funktionen sind derzeit in der Public Preview verfügbar, sodass Sie sofort starten können!
Wir erweitern außerdem die Governance-Funktionen von Unity Catalog auf verschiedene offene Speicherformate, einschließlich Apache Iceberg und Hudi, mit der Public Preview des Delta Universal Format („UniForm“). Diese Integration ermöglicht es, Delta-Tabellen wie Iceberg-Tabellen (und bald auch Apache Hudi) zu lesen, was den Unity Catalog zum einzigen universellen Katalog macht, der alle drei wichtigen offenen Lakehouse-Speicherformate unterstützt.
Schließlich können Sie in Zukunft auch einen Push von Zugriffsrichtlinien, die in Unity Catalog definiert sind, an föderierte Datenquellen durchführen, um eine konsistente Durchsetzung zu gewährleisten, wo auch immer auf Daten zugegriffen wird. Dadurch entfällt die Notwendigkeit, redundante Richtliniendefinitionen über verschiedene Governance-Tools hinweg zu pflegen.
Sehen Sie sich die Keynote von Matei Zaharia, Mitbegründer und Chief Technologie Officer bei Databricks, auf dem Data+KI Summit 2023 an, um mehr zu erfahren.
Registrieren Sie sich hier für den Data + AI Summit, um persönlich oder virtuell teilzunehmen und die neuesten Entwicklungen in den Bereichen Daten, Analysen und KI zu entdecken!
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.