Einführung des Open Variant Datentyps in Delta Lake und Apache Spark
Schnellere Verarbeitung und mehr Flexibilität bei der Arbeit mit semi-strukturierten Daten
von Kent Marten, Gene Pang, Chenhao Li und Han Xiao
Wir freuen uns, einen neuen Datentyp namens Variant für semi-strukturierte Daten anzukündigen. Variant bietet eine um Größenordnungen bessere Leistung im Vergleich zur Speicherung dieser Daten als JSON-Strings, während die Flexibilität für die Unterstützung von stark verschachtelten und sich entwickelnden Schemata erhalten bleibt.
Die Arbeit mit semi-strukturierten Daten ist seit langem eine grundlegende Fähigkeit des Lakehouse. Endpoint Detection & Response (EDR), Ad-Click-Analysen und IoT-Telemetrie sind nur einige der beliebten Anwendungsfälle, die auf semi-strukturierten Daten basieren. Da wir immer mehr Kunden von proprietären Data Warehouses migrieren, haben wir gehört, dass diese auf den Variant-Datentyp angewiesen sind, den diese proprietären Warehouses anbieten, und sich einen Open-Source-Standard dafür wünschen, um jegliche Lock-ins zu vermeiden.
Der offene Variant-Typ ist das Ergebnis unserer Zusammenarbeit sowohl mit der Apache Spark Open-Source-Community als auch mit der Linux Foundation Delta Lake-Community:
- Der Variant-Datentyp, Variant-Binärausdrücke und das Variant-Binärkodierungsformat wurden bereits in Open-Source-Spark integriert. Details zur Binärkodierung finden Sie hier.
- Das Binärkodierungsformat ermöglicht einen schnelleren Zugriff und eine schnellere Navigation der Daten im Vergleich zu Strings. Die Implementierung des Variant-Binärkodierungsformats ist in einer Open-Source-Bibliothek verpackt, sodass sie auch in anderen Projekten verwendet werden kann.
- Die Unterstützung für den Variant-Datentyp ist auch für Delta Open Source, und das Protokoll-RFC finden Sie hier. Die Variant-Unterstützung wird in Spark 4.0 und Delta 4.0 enthalten sein.
„Wir unterstützen die Open-Source-Community mit Fokus auf Daten durch unsere Open-Source-Datenplattform Legend“, sagte Neema Raphael, Chief Data Officer und Head of Data Engineering bei Goldman Sachs. „Die Einführung von Open Source Variant in Spark ist ein weiterer großer Schritt für ein offenes Datenökosystem.“
Und ab DBR 15.3 stehen alle genannten Funktionen unseren Kunden zur Verfügung.
Was ist Variant?
Variant ist ein neuer Datentyp zur Speicherung semi-strukturierter Daten. In der Public Preview der kommenden Databricks Runtime 15.3-Version wird der Ein- und Ausstieg hierarchischer Daten über JSON unterstützt. Ohne Variant mussten Kunden zwischen Flexibilität und Leistung wählen. Um die Flexibilität zu erhalten, speicherten Kunden JSON in einzelnen Spalten als Strings. Um eine bessere Leistung zu erzielen, wendeten Kunden strenge Schematisierungsansätze mit Structs an, die separate Prozesse zur Wartung und Aktualisierung bei Schemaänderungen erfordern. Mit Variant können Kunden Flexibilität beibehalten (es ist keine explizite Schema-Definition erforderlich) und eine erheblich verbesserte Leistung im Vergleich zur Abfrage von JSON als String erzielen.
Variant ist besonders nützlich, wenn die JSON-Quellen unbekannte, sich ändernde und sich häufig entwickelnde Schemata aufweisen. Kunden haben beispielsweise Anwendungsfälle für Endpoint Detection & Response (EDR) mit der Notwendigkeit, Protokolle mit unterschiedlichen JSON-Schemata zu lesen und zu kombinieren. Ebenso ist Variant gut geeignet für Anwendungsfälle mit Ad-Click- und Anwendungs-Telemetrie, bei denen das Schema unbekannt und ständig im Wandel ist. In beiden Fällen ermöglicht die Flexibilität des Variant-Datentyps die Aufnahme von Daten und eine performante Verarbeitung, ohne dass ein explizites Schema erforderlich ist.
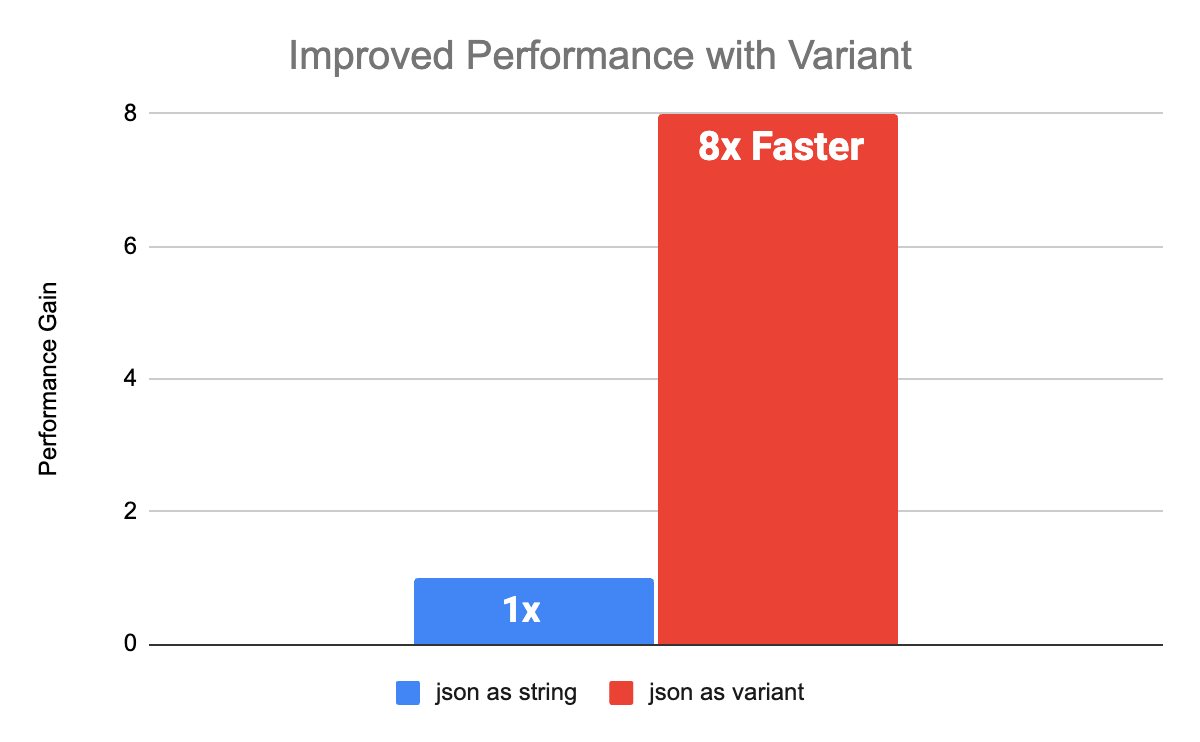
Performance-Benchmarks
Variant bietet eine verbesserte Leistung gegenüber bestehenden Workloads, die JSON als String speichern. Wir haben mehrere Benchmarks mit von Kundendaten inspirierten Schemata durchgeführt, um die Leistung von String vs. Variant zu vergleichen. Sowohl für verschachtelte als auch für flache Schemata verbesserte sich die Leistung mit Variant um das 8-fache gegenüber String-Spalten. Die Benchmarks wurden mit Databricks Runtime 15.0 mit aktiviertem Photon durchgeführt.
Wie kann ich Variant verwenden?
Es gibt eine Reihe neuer Funktionen zur Unterstützung von Variant-Typen, mit denen Sie das Schema eines Variant inspizieren, eine Variant-Spalte aufbrechen und sie in JSON konvertieren können. Die Funktion PARSE_JSON() wird häufig verwendet, um einen Variant-Wert zurückzugeben, der die eingegebene JSON-String-Eingabe darstellt.
Um Variant-Daten zu laden, können Sie eine Tabellenspalte mit dem Variant-Typ erstellen. Sie können jeden JSON-formatierten String mit der Funktion PARSE_JSON() in Variant konvertieren und in eine Variant-Spalte einfügen.
Sie können CTAS verwenden, um eine Tabelle mit Variant-Spalten zu erstellen. Das Schema der zu erstellenden Tabelle wird aus dem Abfrageergebnis abgeleitet. Daher muss das Abfrageergebnis Variant-Spalten im Ausgabeschema enthalten, um eine Tabelle mit Variant-Spalten erstellen zu können.
Sie können auch COPY INTO verwenden, um JSON-Daten in eine Tabelle mit einer oder mehreren Variant-Spalten zu kopieren.
Die Pfadnavigation folgt einer intuitiven Punkt-Notation.
Vollständig Open Source, kein proprietärer Daten-Lock-in
Lassen Sie uns zusammenfassen:
- Der Variant-Datentyp, Binärausdrücke und das Binärkodierungsformat wurden bereits in Apache Spark integriert. Das Binärkodierungsformat kann im Detail hier eingesehen werden.
- Das Binärkodierungsformat ermöglicht einen schnelleren Zugriff und eine schnellere Navigation der Daten im Vergleich zu Strings. Die Implementierung des Binärkodierungsformats ist in einer Open-Source-Bibliothek verpackt, sodass sie auch in anderen Projekten verwendet werden kann.
- Die Unterstützung für den Variant-Datentyp ist auch für Delta Open Source, und das Protokoll-RFC finden Sie hier. Die Variant-Unterstützung wird in Spark 4.0 und Delta 4.0 enthalten sein.
Darüber hinaus planen wir die Implementierung von Shredding/Sub-Columnarization für den Variant-Typ. Shredding ist eine Technik zur Verbesserung der Leistung beim Abfragen bestimmter Pfade innerhalb der Variant-Daten. Mit Shredding können Pfade in ihrer eigenen Spalte gespeichert werden, was den IO- und Rechenaufwand für die Abfrage dieses Pfades reduzieren kann. Shredding ermöglicht auch das Pruning von Daten, um zusätzlichen unnötigen Aufwand zu vermeiden. Shredding wird auch in Apache Spark und Delta Lake verfügbar sein.
Besuchen Sie dieses Jahr den DATA + AI Summit vom 10. bis 13. Juni in San Francisco?
Besuchen Sie den Vortrag „Variant Data Type - Making Semi-Structured Data Fast and Simple“.
Variant wird in Databricks Runtime 15.3 in der Public Preview und im DBSQL Preview Channel bald standardmäßig aktiviert. Testen Sie Ihre Anwendungsfälle für semi-strukturierte Daten und starten Sie eine Unterhaltung in den Databricks Community Foren, wenn Sie Gedanken oder Fragen haben. Wir würden uns freuen zu hören, was die Community denkt!
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.