Lakeflow Connect: Effiziente und einfache Datenaufnahme mit dem SQL Server-Connector
Entdecken Sie den vollständig verwalteten SQL Server Connector von Databricks Lakeflow Connect, um die Aufnahme und nahtlose Integration von Daten mit Databricks-Tools für Datenverarbeitung und Analysen zu vereinfachen.
von Andrea Tardif, Prasanna Selvaraj, Hector Bustamante und Phanitha Kommareddi
- Führende Technologieunternehmen stehen vor komplexen Herausforderungen, wenn es darum geht, aus ihren SQL Server-Daten Wert für KI und Analysen zu schöpfen.
- Lakeflow Connect für SQL Server bietet eine effiziente, inkrementelle Aufnahme für On-Premises- und Cloud-Datenbanken.
- Dieser Blogbeitrag behandelt architektonische Überlegungen, Voraussetzungen und Schritt-für-Schritt-Anleitungen für die Aufnahme von SQL Server-Daten in Ihr Lakehouse.
Komplexität der Extraktion von SQL Server-Daten
Während digital aufgestellte Unternehmen die entscheidende Rolle von KI für Innovationen erkennen, stehen viele immer noch vor Herausforderungen, ihre Daten für nachgelagerte Zwecke wie die Entwicklung von maschinellem Lernen und erweiterte Analysen leicht verfügbar zu machen. Für diese Organisationen bedeutet die Unterstützung von Geschäftsteams, die auf SQL Server angewiesen sind, dass sie über Data Engineering-Ressourcen verfügen und benutzerdefinierte Konnektoren pflegen müssen, um Daten für Analysen vorzubereiten und sicherzustellen, dass sie für Datenteams zur Modellentwicklung verfügbar sind. Oft müssen diese Daten mit zusätzlichen Quellen angereichert und transformiert werden, bevor sie datengesteuerte Entscheidungen informieren können.
Die Pflege dieser Prozesse wird schnell komplex und fehleranfällig, was Innovationen verlangsamt. Deshalb hat Databricks Lakeflow Connect entwickelt, das integrierte Datenkonnektoren für gängige Datenbanken, Unternehmensanwendungen und Dateiquellen enthält. Diese Konnektoren bieten eine effiziente End-to-End-Inkrementalinjektion, sind flexibel und einfach einzurichten und vollständig in die Databricks Data Intelligence Platform integriert für vereinheitlichte Governance, Beobachtbarkeit und Orchestrierung. Der neue Lakeflow SQL Server-Konnektor ist der erste Datenbankkonnektor mit robuster Integration für On-Premises- und Cloud-Datenbanken, um Erkenntnisse aus Daten innerhalb von Databricks zu gewinnen.
In diesem Blogbeitrag werden wir die wichtigsten Überlegungen prüfen, wann Lakeflow Connect für SQL Server verwendet werden sollte, und erklären, wie der Konnektor konfiguriert wird, um Daten aus einer Azure SQL Server-Instanz zu replizieren. Anschließend werden wir einen spezifischen Anwendungsfall, Best Practices und die ersten Schritte untersuchen.
Wichtige architektonische Überlegungen
Nachfolgend finden Sie die wichtigsten Überlegungen, die Ihnen bei der Entscheidung helfen, wann der SQL Server-Konnektor verwendet werden soll.
Region & Feature-Kompatibilität
Lakeflow Connect unterstützt eine breite Palette von SQL Server-Datenbankvarianten, einschließlich Microsoft Azure SQL Database, Amazon RDS für SQL Server, Microsoft SQL Server auf Azure VMs und Amazon EC2 sowie On-Premises SQL Server, auf die über Azure ExpressRoute oder AWS Direct Connect zugegriffen wird.
Da Lakeflow Connect im Hintergrund auf Serverless-Pipelines läuft, können integrierte Funktionen wie Pipeline-Beobachtbarkeit, Event-Log-Alarmierung und Lakehouse-Überwachung genutzt werden. Wenn Serverless in Ihrer Region nicht unterstützt wird, wenden Sie sich an Ihr Databricks Account Team, um eine Anfrage einzureichen und die Entwicklung oder Bereitstellung in dieser Region zu priorisieren.
Lakeflow Connect basiert auf der Data Intelligence Platform, die eine nahtlose Integration mit Unity Catalog (UC) bietet, um etablierte Berechtigungen und Zugriffskontrollen über neue SQL Server-Quellen für eine vereinheitlichte Governance wiederzuverwenden. Wenn Ihre Databricks-Tabellen und -Ansichten auf Hive liegen, empfehlen wir, sie auf UC zu aktualisieren, um von diesen Funktionen zu profitieren (AWS | Azure | GCP)!
Änderungsdaten-Anforderungen
Lakeflow Connect kann mit einer SQL Server-Instanz integriert werden, bei der Microsoft Change Tracking (CT) oder Microsoft Change Data Capture (CDC) aktiviert ist, um eine effiziente, inkrementelle Injektion zu unterstützen.
CDC liefert historische Änderungsdaten zu Insert-, Update- und Delete-Operationen und wann die tatsächlichen Daten geändert wurden. Change Tracking identifiziert, welche Zeilen in einer Tabelle geändert wurden, ohne die tatsächlichen Datenänderungen selbst zu erfassen. Erfahren Sie mehr über CDC und die Vorteile der Verwendung von CDC mit SQL Server.
Databricks empfiehlt die Verwendung von Change Tracking für jede Tabelle mit einem Primärschlüssel, um die Belastung der Quelldatenbank zu minimieren. Für Quelltabellen ohne Primärschlüssel verwenden Sie CDC. Erfahren Sie mehr darüber, wann Sie es verwenden sollten hier.
Der SQL Server-Konnektor erfasst eine anfängliche Ladung historischer Daten beim ersten Ausführen Ihrer Injektionspipeline. Anschließend verfolgt und injiziert der Konnektor nur die seit der letzten Ausführung vorgenommenen Änderungen an den Daten und nutzt die CT/CDC-Funktionen von SQL Server, um Betriebsabläufe und Effizienz zu optimieren.
Governance & Private Networking Sicherheit
Wenn eine Verbindung mit einem SQL Server über Lakeflow Connect hergestellt wird:
- Der Datenverkehr zwischen der Client-Schnittstelle und der Steuerungsebene wird während der Übertragung mit TLS 1.2 oder höher verschlüsselt.
- Das Staging-Volume, in dem Rohdateien während der Injektion gespeichert werden, wird vom zugrunde liegenden Cloud-Speicheranbieter verschlüsselt.
- Daten im Ruhezustand werden gemäß Best Practices und Compliance-Standards geschützt.
- Wenn mit privaten Endpunkten konfiguriert, bleibt der gesamte Datenverkehr im privaten Netzwerk des Cloud-Anbieters und vermeidet das öffentliche Internet.
Sobald die Daten in Databricks injiziert sind, werden sie wie andere Datensätze innerhalb von UC verschlüsselt. Das Injektions-Gateway, das Snapshots, Änderungsprotokolle und Metadaten aus der Quelldatenbank extrahiert, landet in einem UC Volume, einer Speicherabstraktion, die sich am besten für die Registrierung nicht-tabellarischer Datensätze wie JSON-Dateien eignet. Dieses UC Volume befindet sich im Cloud-Speicherkonto des Kunden innerhalb seiner virtuellen Netzwerke oder Virtual Private Clouds.
Darüber hinaus erzwingt UC feingranulare Zugriffskontrollen und pflegt Audit-Protokolle zur Steuerung des Zugriffs auf diese neu injizierten Daten. UC Service-Anmeldeinformationen und Speicheranmeldeinformationen werden als sicherbare Objekte innerhalb von UC gespeichert und gewährleisten eine sichere und zentralisierte Verwaltung der Authentifizierung. Diese Anmeldeinformationen werden niemals in Protokollen angezeigt oder in SQL-Injektionspipelines fest codiert, was robusten Schutz und Zugriffskontrolle bietet.
Wenn Ihre Organisation die oben genannten Kriterien erfüllt, sollten Sie Lakeflow Connect für SQL Server in Betracht ziehen, um die Dateninjektion in Databricks zu vereinfachen.
Aufschlüsselung der technischen Lösung
Überprüfen Sie als Nächstes die Schritte zur Konfiguration von Lakeflow Connect für SQL Server und zur Replikation von Daten aus einer Azure SQL Server-Instanz.
Unity Catalog-Berechtigungen konfigurieren
Stellen Sie innerhalb von Databricks sicher, dass Serverless Compute für Notebooks, Workflows und Pipelines aktiviert ist (AWS | Azure | GCP). Validieren Sie dann, dass der Benutzer oder das Dienstprinzipal, das die Injektionspipeline erstellt, über die folgenden UC-Berechtigungen verfügt:
| Berechtigungstyp | Grund | Dokumentation |
| CREATE CONNECTION für den Metastore | Lakeflow Connect muss eine sichere Verbindung zum SQL Server herstellen. | CREATE CONNECTION |
| USE CATALOG für den Zielkatalog | Erforderlich, da er Zugriff auf den Katalog gewährt, in dem Lakeflow Connect die SQL Server-Datentabellen in UC landen wird. | USE CATALOG |
| USE SCHEMA, CREATE TABLE, and CREATE VOLUME auf einem vorhandenen Schema oder CREATE SCHEMA im Zielkatalog | Bietet die notwendigen Rechte für den Zugriff auf Schemata und die Erstellung von Speicherorten für aufgenommene Datentabellen. | GRANT PRIVILEGES |
| Uneingeschränkte Berechtigungen zum Erstellen von Clustern oder eine benutzerdefinierte Clusterrichtlinie | Erforderlich, um die für den Gateway-Ingestion-Prozess benötigten Compute-Ressourcen zu starten | MANAGE COMPUTE POLICIES |
Azure SQL Server einrichten
Um den SQL Server-Connector zu verwenden, stellen Sie sicher, dass die folgenden Anforderungen erfüllt sind:
- SQL-Version bestätigen
- SQL Server 2012 oder eine neuere Version muss für die Verwendung von Change Tracking aktiviert sein. 2016+ wird jedoch empfohlen*. Überprüfen Sie die Anforderungen an die SQL-Version hier.
- Konfigurieren Sie das dedizierte Datenbankdienstkonto für die Databricks-Ingestion.
- Change Tracking oder integrierte CDC aktivieren
- Sie müssen SQL Server 2012 oder eine neuere Version verwenden, um CDC nutzen zu können. Versionen vor SQL Server 2016 erfordern zusätzlich die Enterprise Edition.
* Anforderungen ab Mai 2025. Änderungen vorbehalten.
Beispiel: Ingestion von Azure SQL Server nach Databricks
Als Nächstes nehmen wir eine Tabelle von einer Azure SQL Server-Datenbank nach Databricks mit Lakeflow Connect auf. In diesem Beispiel geben CDC und CT einen Überblick über alle verfügbaren Optionen. Da die Tabelle in diesem Beispiel einen Primärschlüssel hat, hätte CT die primäre Wahl sein können. Da es jedoch nur eine kleine Tabelle in diesem Beispiel gibt, gibt es keine Bedenken hinsichtlich des Last-Overheads, daher wurde auch CDC einbezogen. Es wird empfohlen zu überprüfen, wann CDC, CT oder beides verwendet werden sollte, um zu bestimmen, welche Option für Ihre Daten und Aktualisierungsanforderungen am besten geeignet ist.
1. [Azure SQL Server] Azure SQL Server für CDC und CT überprüfen und konfigurieren
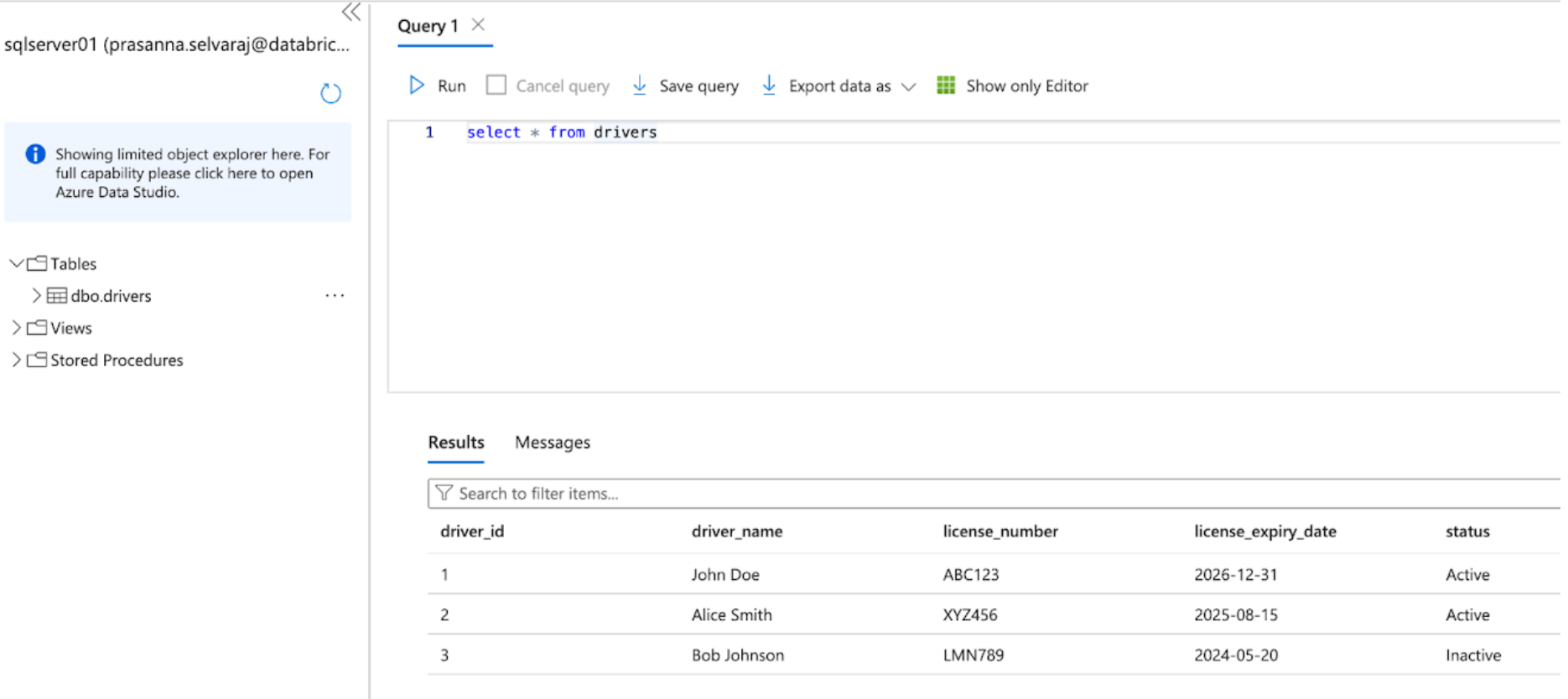
Greifen Sie zunächst auf das Azure-Portal zu und melden Sie sich mit Ihren Azure-Kontodaten an. Klicken Sie auf der linken Seite auf Alle Dienste und suchen Sie nach SQL Servers. Suchen und klicken Sie auf Ihren Server und dann auf den „Query Editor“; in diesem Beispiel wurde sqlserver01 ausgewählt.
Der folgende Screenshot zeigt, dass die SQL Server-Datenbank eine Tabelle namens „drivers“ hat.
Bevor die Daten nach Databricks repliziert werden, muss entweder Change Data Capture, Change Tracking oder beides aktiviert sein.
Für dieses Beispiel wird das folgende Skript auf der Datenbank ausgeführt, um CT zu aktivieren:
Dieser Befehl aktiviert das Change Tracking für die Datenbank mit den folgenden Parametern:
- CHANGE_RETENTION = 3 DAYS: Dieser Wert verfolgt Änderungen für 3 Tage (72 Stunden). Eine vollständige Aktualisierung ist erforderlich, wenn Ihr Gateway länger als die eingestellte Zeit offline ist. Es wird empfohlen, diesen Wert zu erhöhen, wenn längere Ausfallzeiten erwartet werden.
- AUTO_CLEANUP = ON: Dies ist die Standardeinstellung. Um die Leistung aufrechtzuerhalten, werden automatisch Change Tracking-Daten entfernt, die älter als der Aufbewahrungszeitraum sind.
Dann wird das folgende Skript auf der Datenbank ausgeführt, um CDC zu aktivieren:
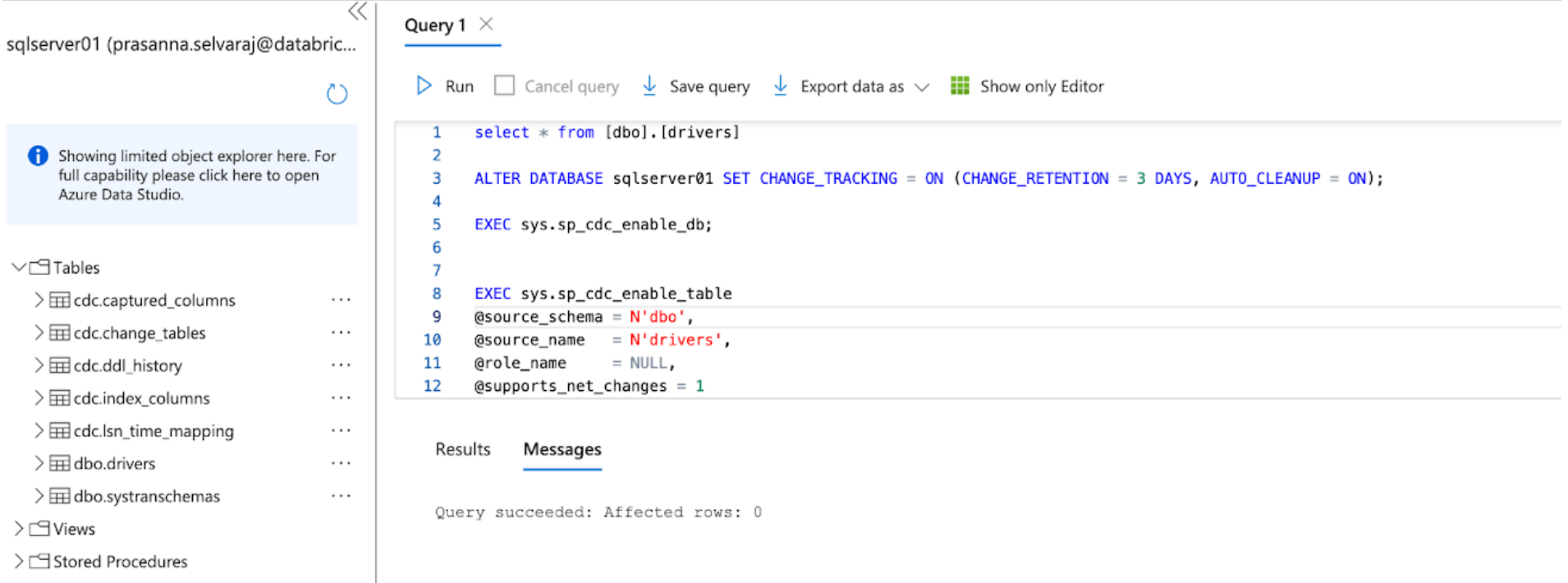
Wenn beide Skripte ausgeführt wurden, überprüfen Sie den Tabellenbereich unter der SQL Server-Instanz in Azure und stellen Sie sicher, dass alle CDC- und CT-Tabellen erstellt wurden.
2. [Databricks] SQL Server-Connector in Lakeflow Connect konfigurieren
Im nächsten Schritt wird die Databricks-Benutzeroberfläche zur Konfiguration des SQL Server-Connectors angezeigt. Alternativ können auch Databricks Asset Bundles (DABs), eine programmatische Möglichkeit zur Verwaltung von Lakeflow Connect-Pipelines als Code, genutzt werden. Ein Beispiel für das vollständige DABs-Skript finden Sie im Anhang unten.
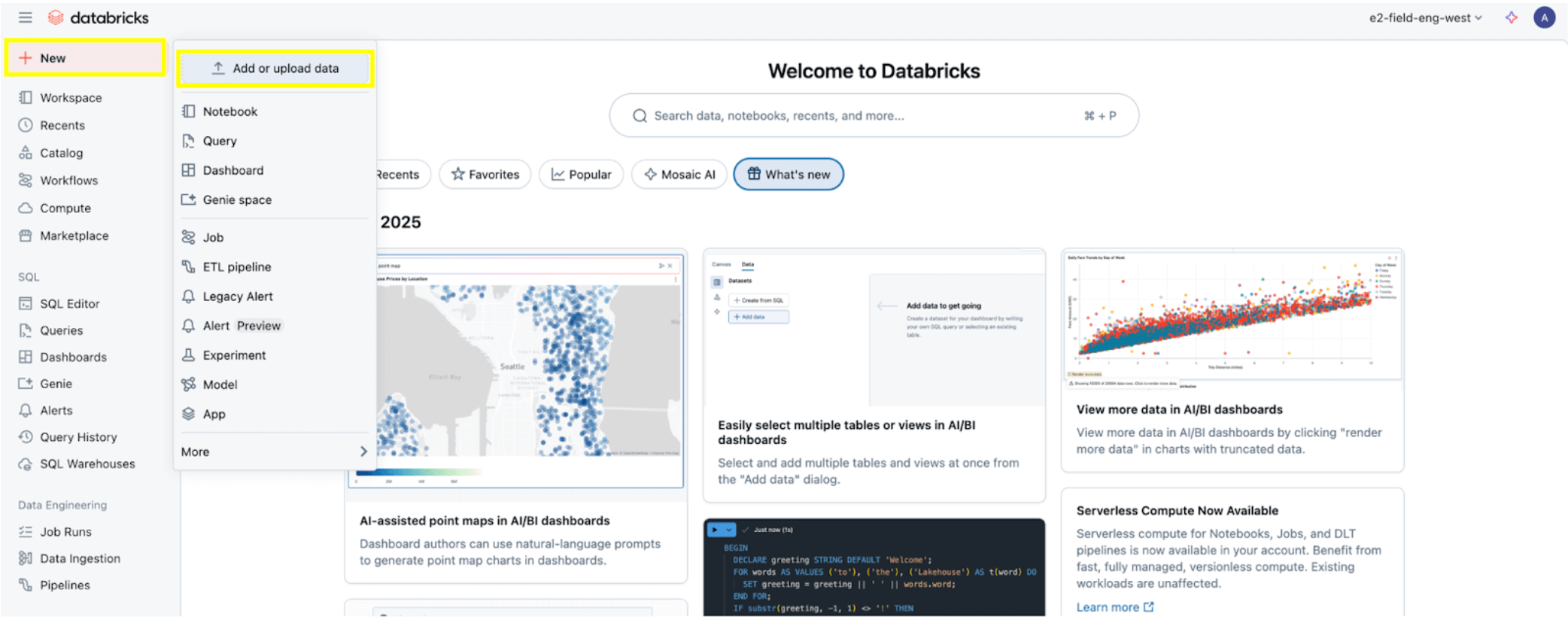
Sobald alle Berechtigungen wie in den Berechtigungs-Voraussetzungen beschrieben festgelegt sind, können Sie Daten aufnehmen. Klicken Sie oben links auf die Schaltfläche + Neu und wählen Sie dann Daten hinzufügen oder hochladen.
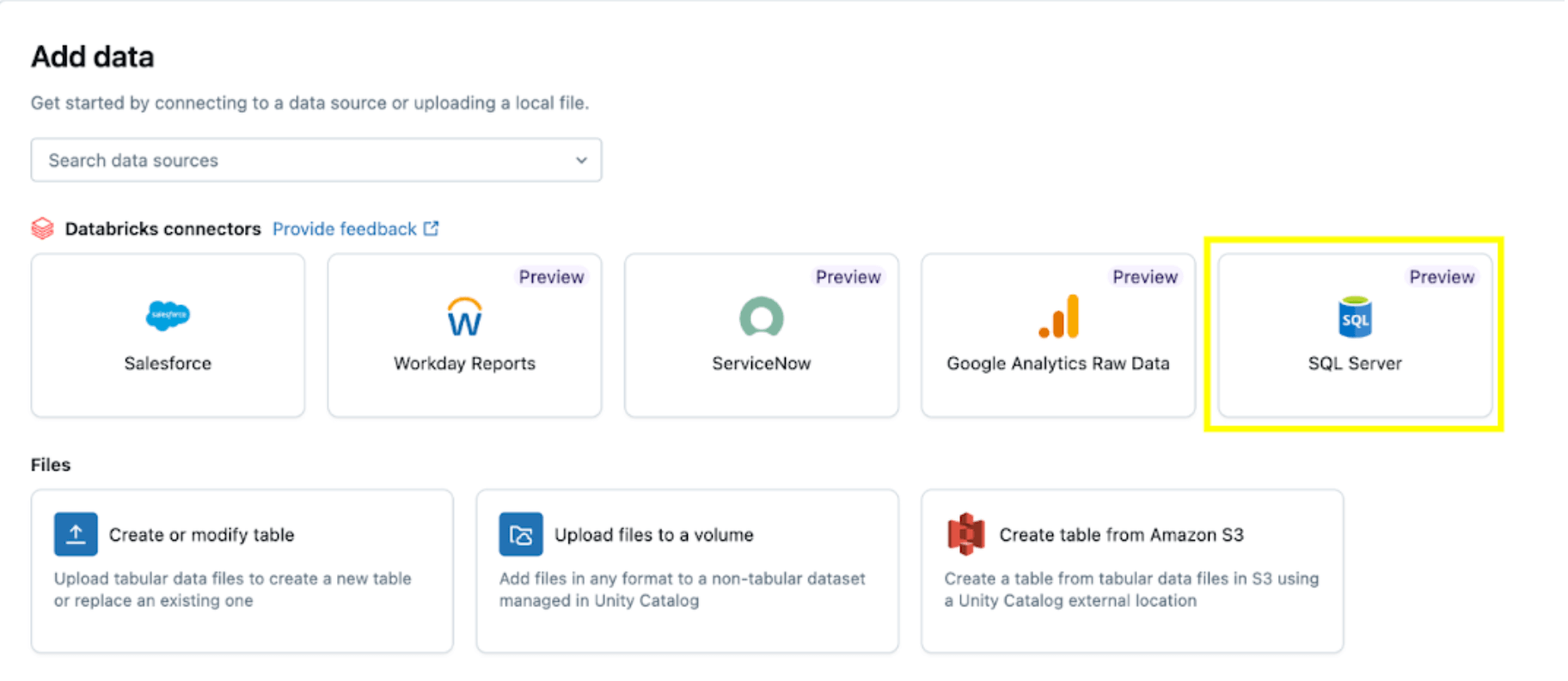
Wählen Sie dann die Option SQL Server.
Der SQL Server-Connector wird in mehreren Schritten konfiguriert.
1. Richten Sie das Ingestion-Gateway ein (AWS | Azure | GCP). In diesem Schritt geben Sie einen Namen für die Ingestion-Gateway-Pipeline sowie einen Katalog und ein Schema für den UC Volume-Speicherort an, um Snapshots und kontinuierlich geänderte Daten aus der Quelldatenbank zu extrahieren.
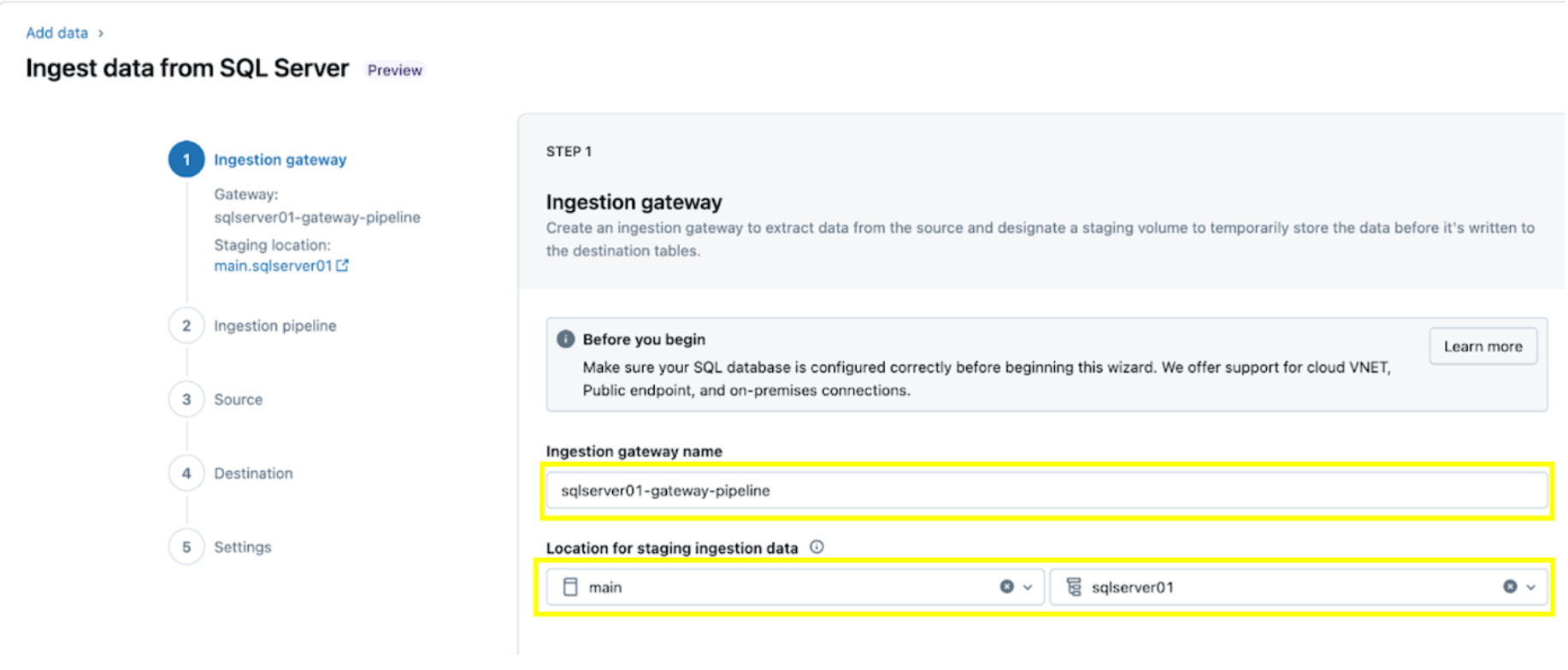
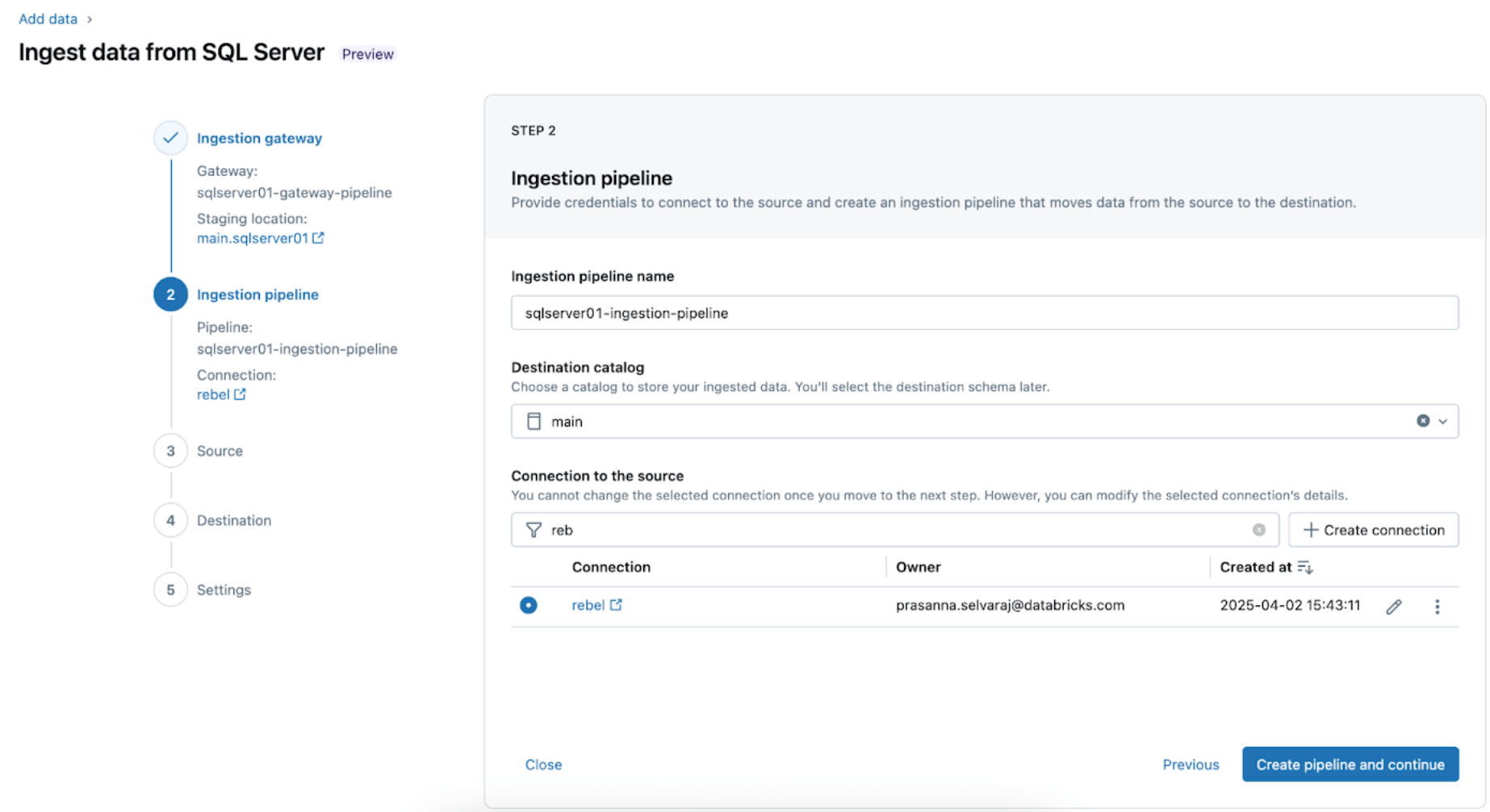
2. Konfigurieren Sie die Ingestion-Pipeline. Diese repliziert die CDC/CT-Datenquelle und die Schemaentwicklungsereignisse. Eine SQL Server-Verbindung ist erforderlich, die über die Benutzeroberfläche nach diesen Schritten oder mit dem folgenden SQL-Code unten erstellt wird:
Benennen Sie für dieses Beispiel die SQL Server-Verbindung rebel wie gezeigt.
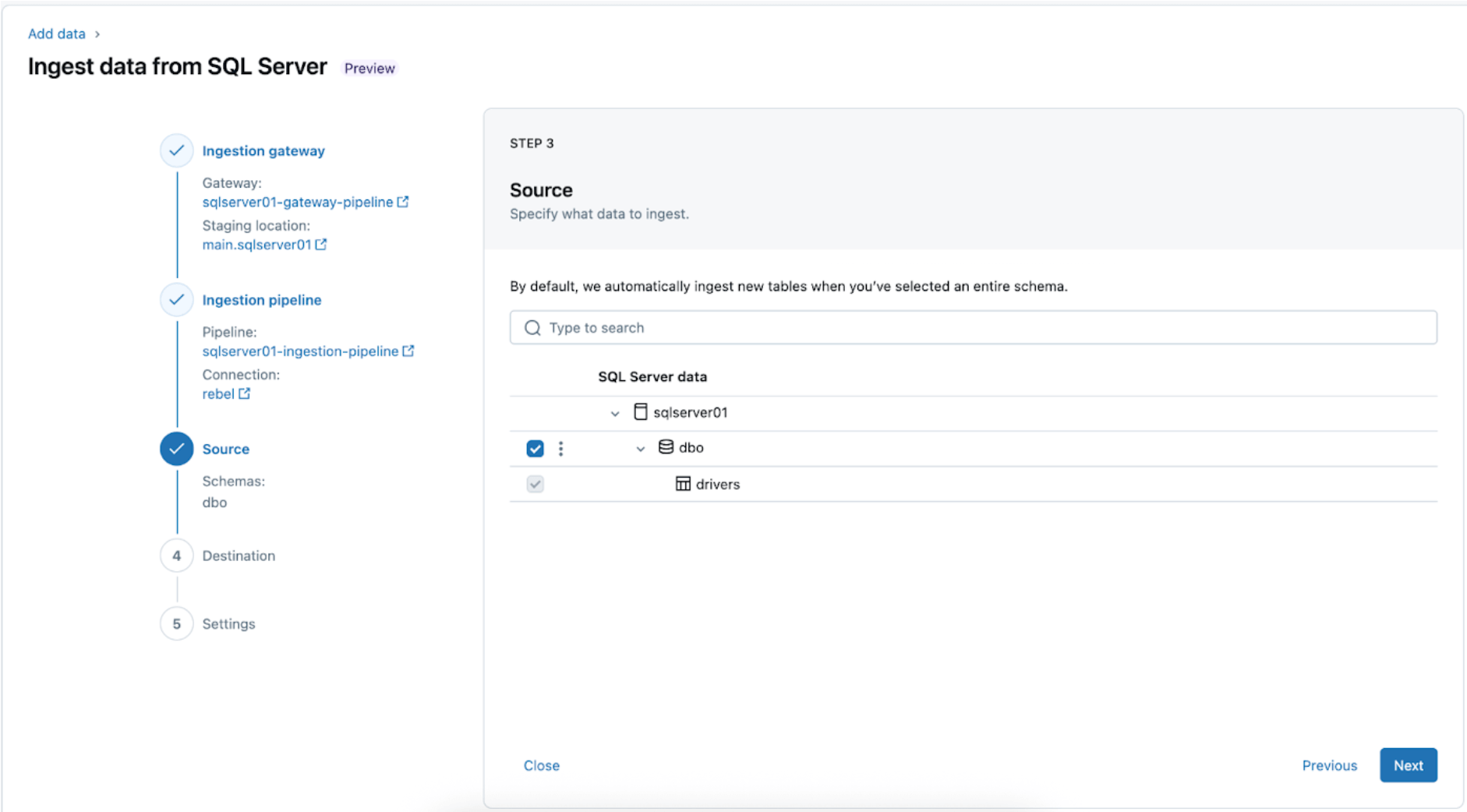
3. Auswählen der SQL Server-Tabellen für die Replikation. Wählen Sie das gesamte Schema aus, das in Databricks aufgenommen werden soll, anstatt einzelne Tabellen auszuwählen.
Das gesamte Schema kann während der anfänglichen Erkundung oder Migrationen in Databricks aufgenommen werden. Wenn das Schema groß ist oder die zulässige Anzahl von Tabellen pro Pipeline überschreitet (siehe Connector-Limits), empfiehlt Databricks, die Aufnahme auf mehrere Pipelines aufzuteilen, um eine optimale Leistung aufrechtzuerhalten. Für anwendungsfallspezifische Workflows wie ein einzelnes ML-Modell, Dashboard oder einen Bericht ist es im Allgemeinen effizienter, einzelne Tabellen aufzunehmen, die auf diesen spezifischen Bedarf zugeschnitten sind, anstatt das gesamte Schema.
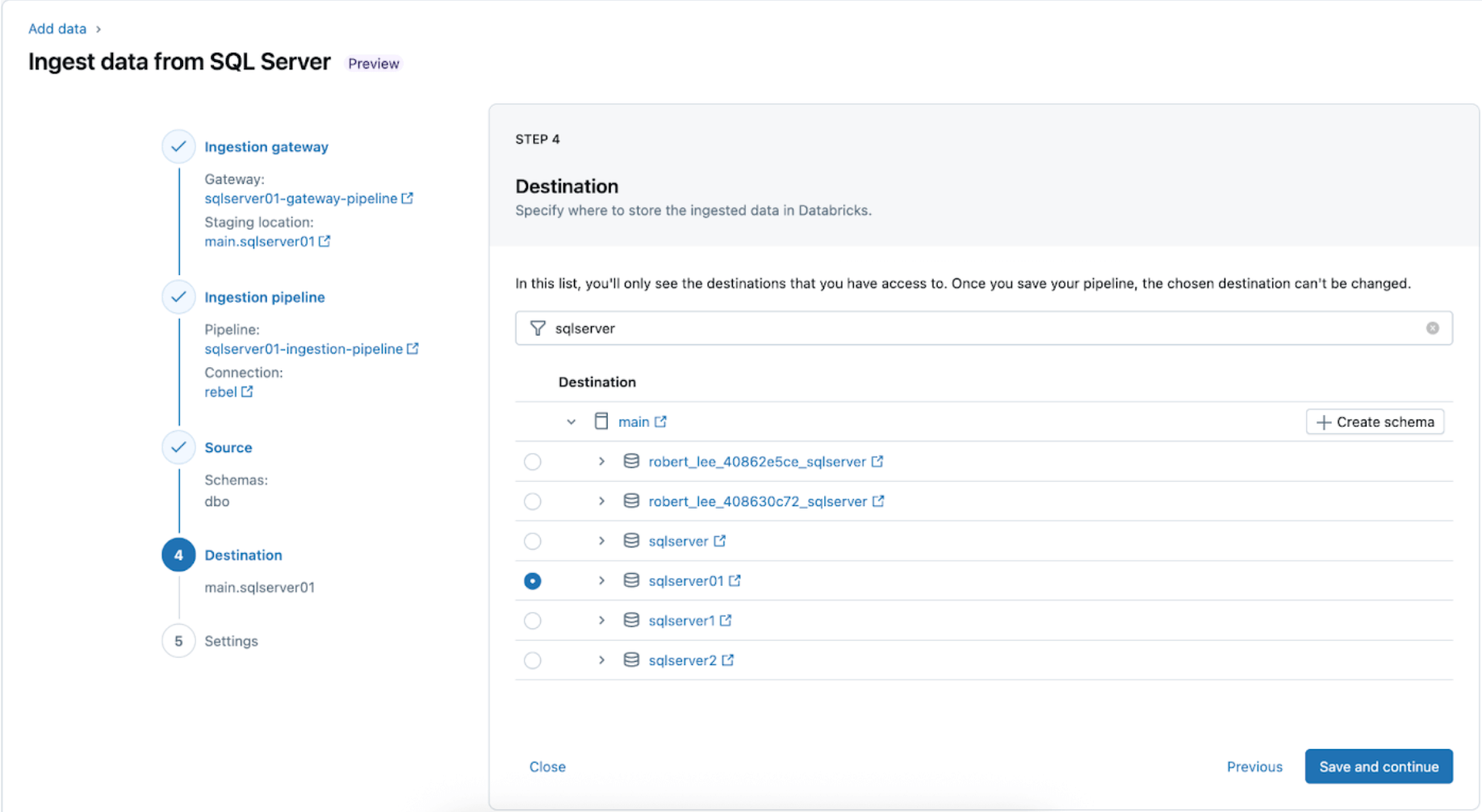
4. Konfigurieren Sie das Ziel, in dem die SQL Server-Tabellen innerhalb von UC repliziert werden. Wählen Sie den main Katalog und das Schema sqlserver01 aus, um die Daten in UC zu landen.
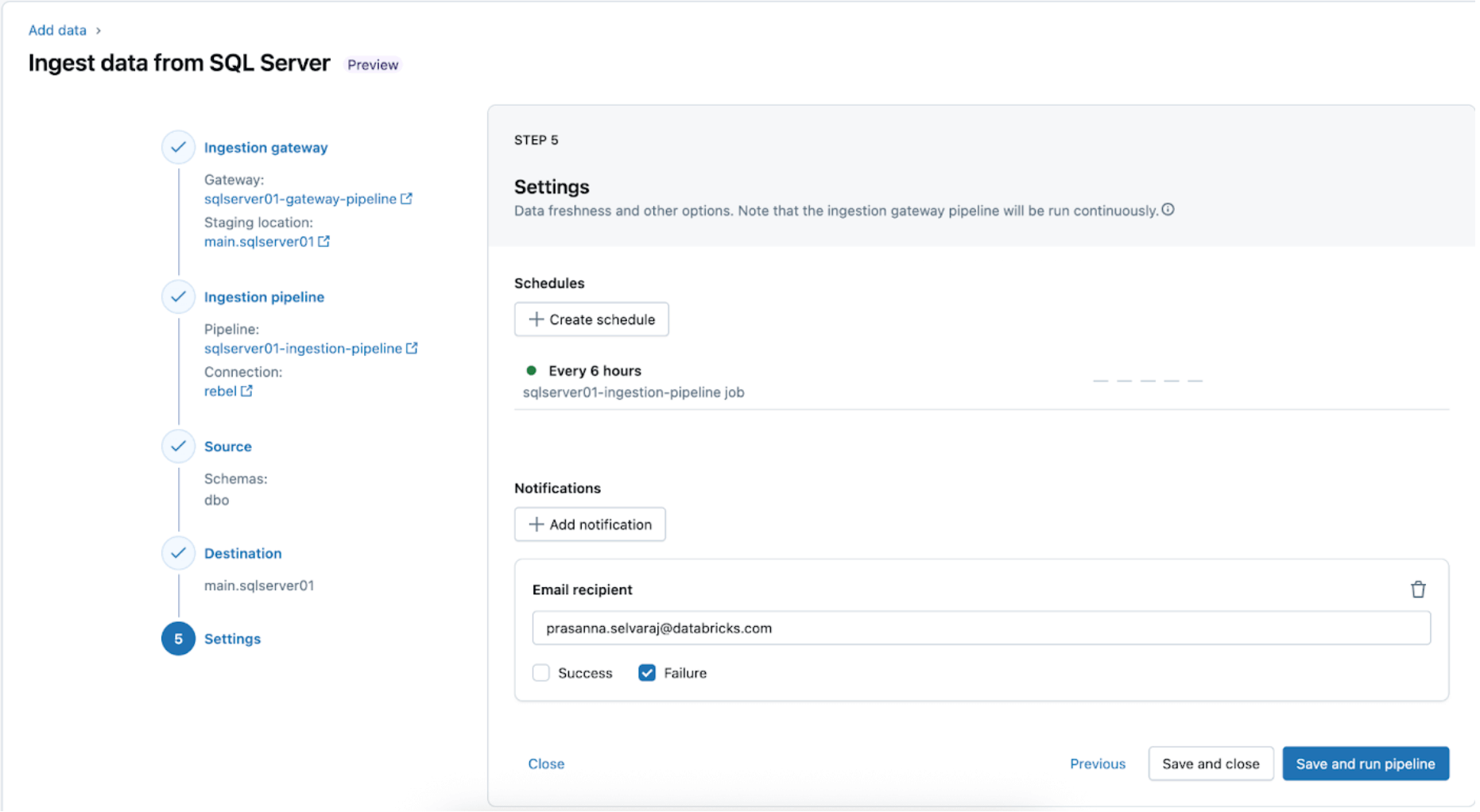
5. Konfigurieren Sie Zeitpläne und Benachrichtigungen (AWS | Azure | GCP). Dieser letzte Schritt hilft zu bestimmen, wie oft die Pipeline ausgeführt werden soll und wohin Erfolgs- oder Fehlermeldungen gesendet werden sollen. Stellen Sie die Pipeline so ein, dass sie alle 6 Stunden ausgeführt wird und der Benutzer nur über Pipeline-Fehler benachrichtigt wird. Dieses Intervall kann an die Bedürfnisse Ihrer Workload angepasst werden.
Die Aufnahmepipeline kann nach einem benutzerdefinierten Zeitplan ausgelöst werden. Lakeflow Connect erstellt automatisch einen dedizierten Job für jeden geplanten Pipeline-Trigger. Die Aufnahmepipeline ist eine Aufgabe innerhalb des Jobs. Optional können weitere Aufgaben vor oder nach der Aufnahmestelle für nachgelagerte Verarbeitungen hinzugefügt werden.
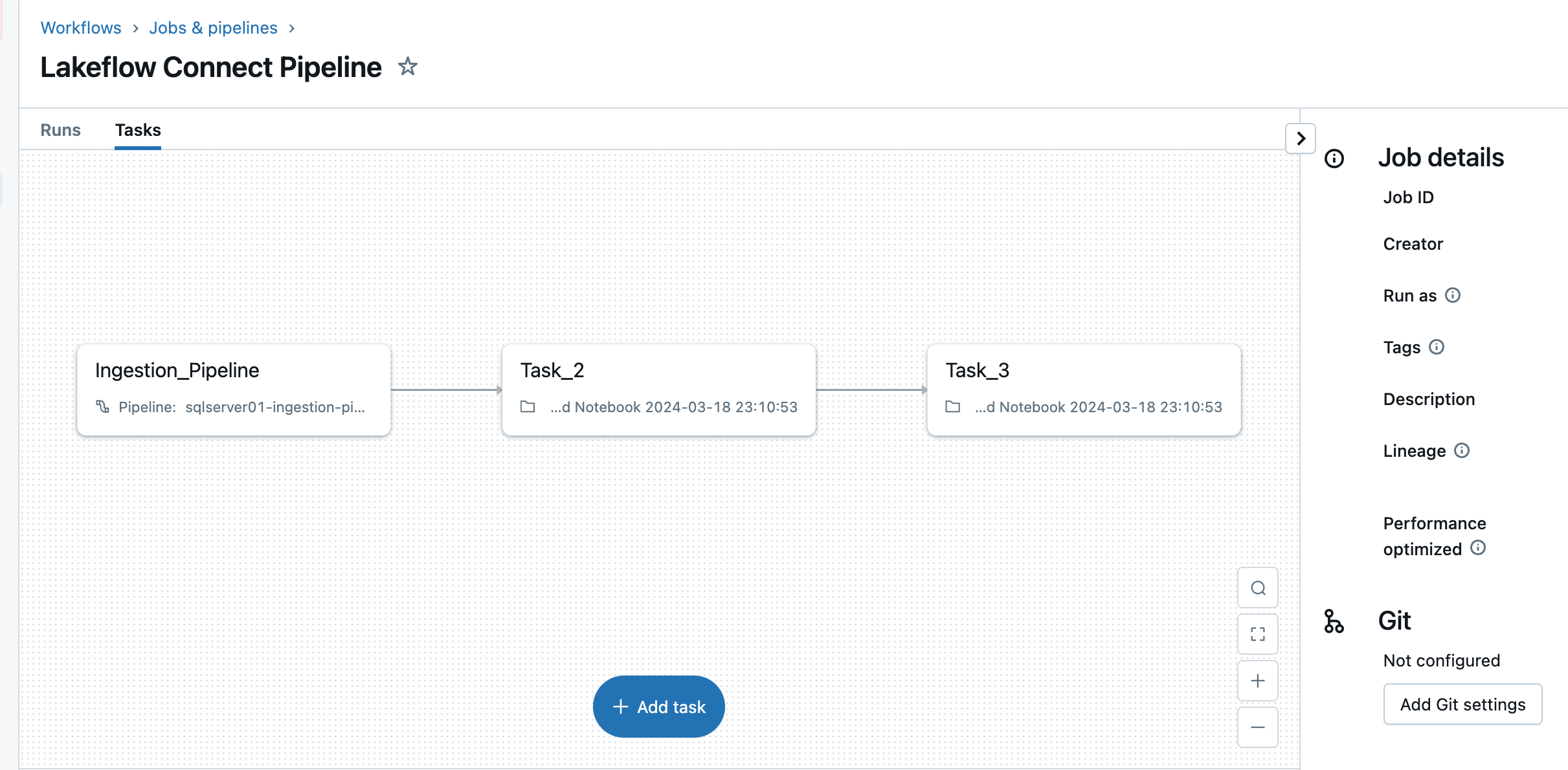
Nach diesem Schritt wird die Aufnahmepipeline gespeichert und ausgelöst, wodurch eine vollständige Datenladung vom SQL Server in Databricks beginnt.
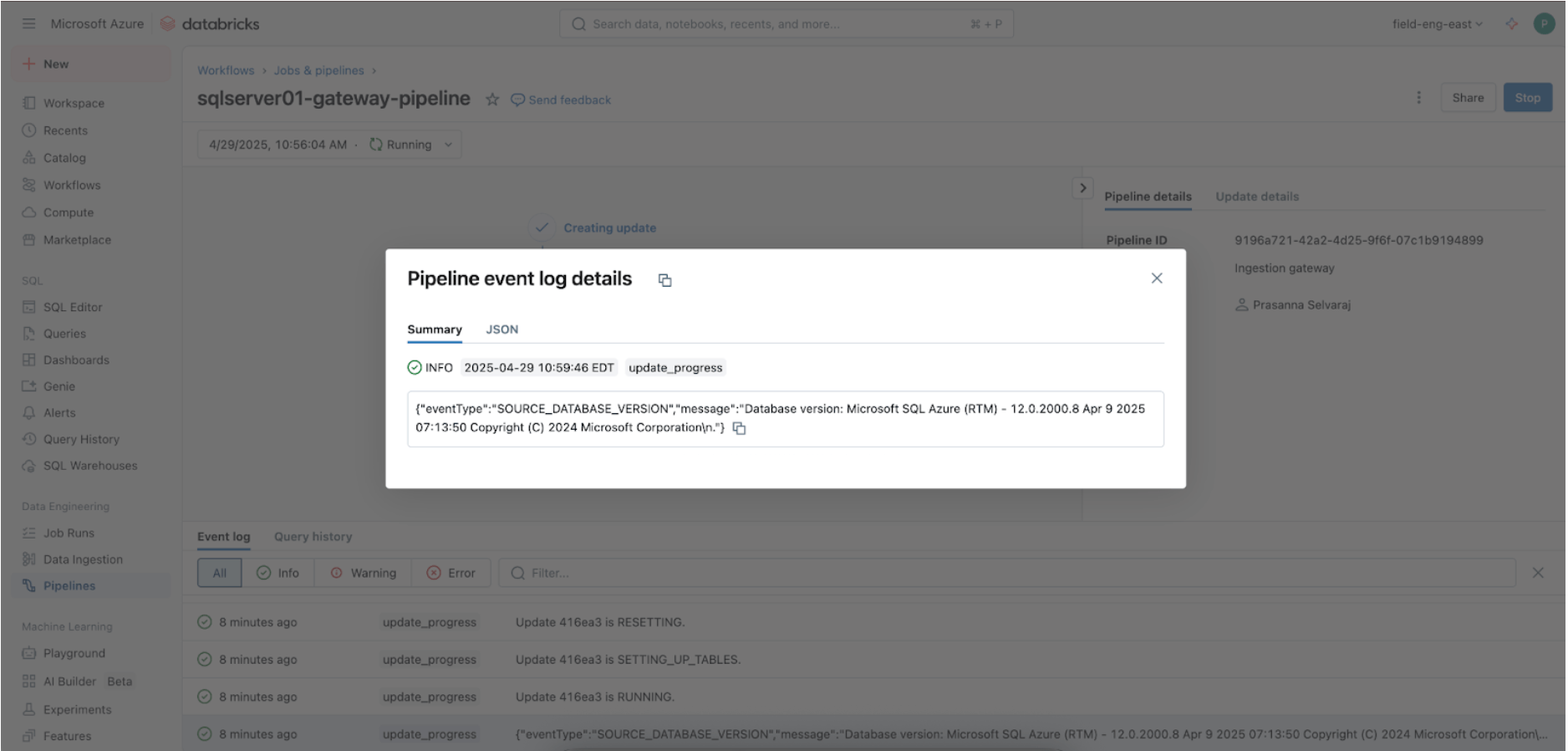
3. [Databricks] Erfolgreiche Ausführungen des Gateways und der Aufnahmepipelines validieren
Navigieren Sie zum Pipeline-Menü, um zu überprüfen, ob die Gateway-Aufnahmepipeline ausgeführt wird. Suchen Sie nach der Ausführung nach „update_progress“ in der Benutzeroberfläche des Pipeline-Ereignisprotokolls im unteren Bereich, um sicherzustellen, dass das Gateway die Quelldaten erfolgreich aufnimmt.
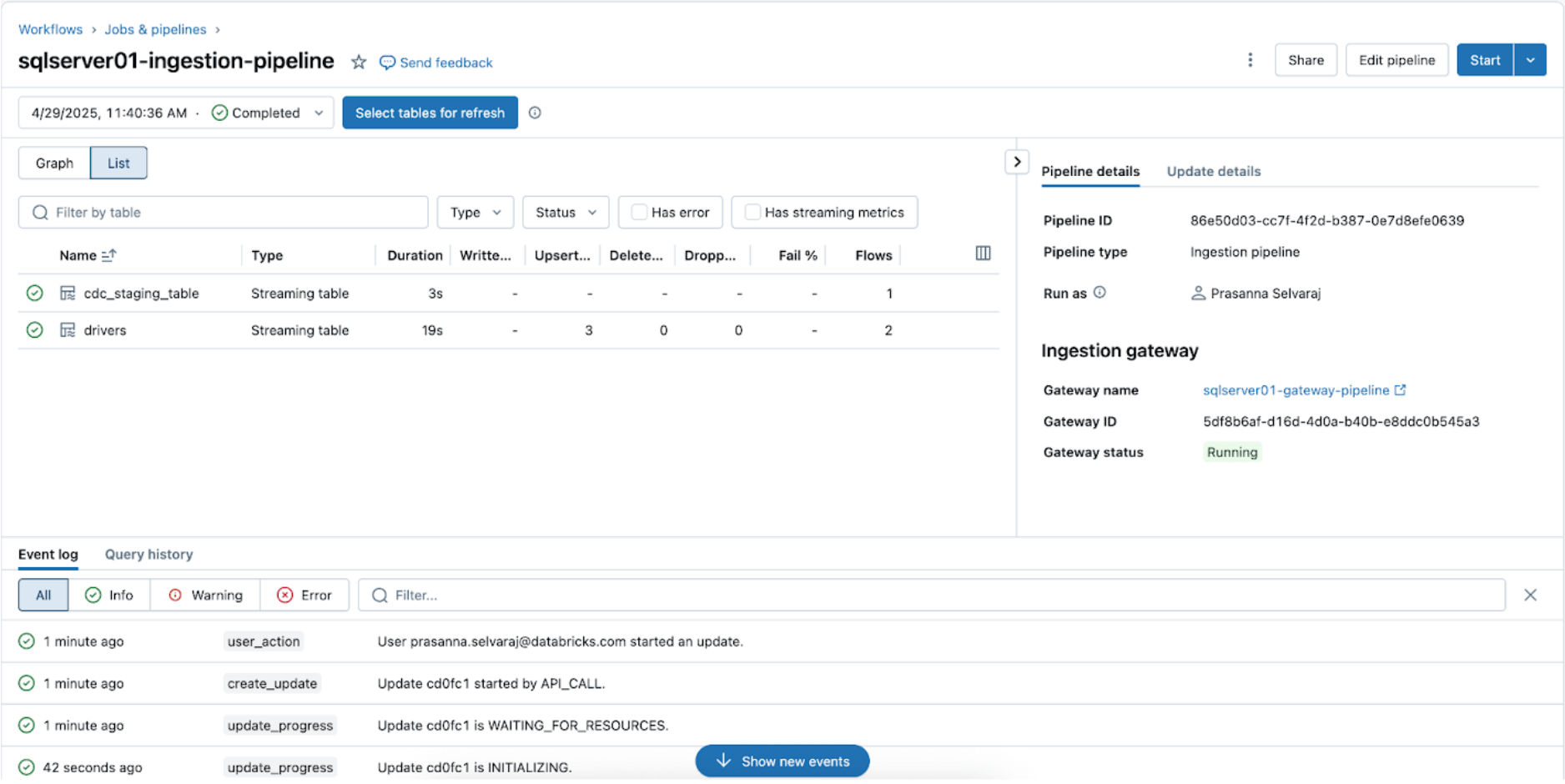
Um den Synchronisierungsstatus zu überprüfen, navigieren Sie zum Pipeline-Menü. Der folgende Screenshot zeigt, dass die Aufnahmepipeline drei Insert- und Update-Operationen (UPSERT) durchgeführt hat.
Navigieren Sie zum Zielkatalog main und zum Schema sqlserver01, um die replizierte Tabelle anzuzeigen, wie unten gezeigt.

4. [Databricks] CDC und Schema-Evolution testen
Überprüfen Sie als Nächstes ein CDC-Ereignis, indem Sie Einfüge-, Update- und Löschvorgänge in der Quelltabelle durchführen. Der Screenshot des Azure SQL Servers unten zeigt die drei Ereignisse.
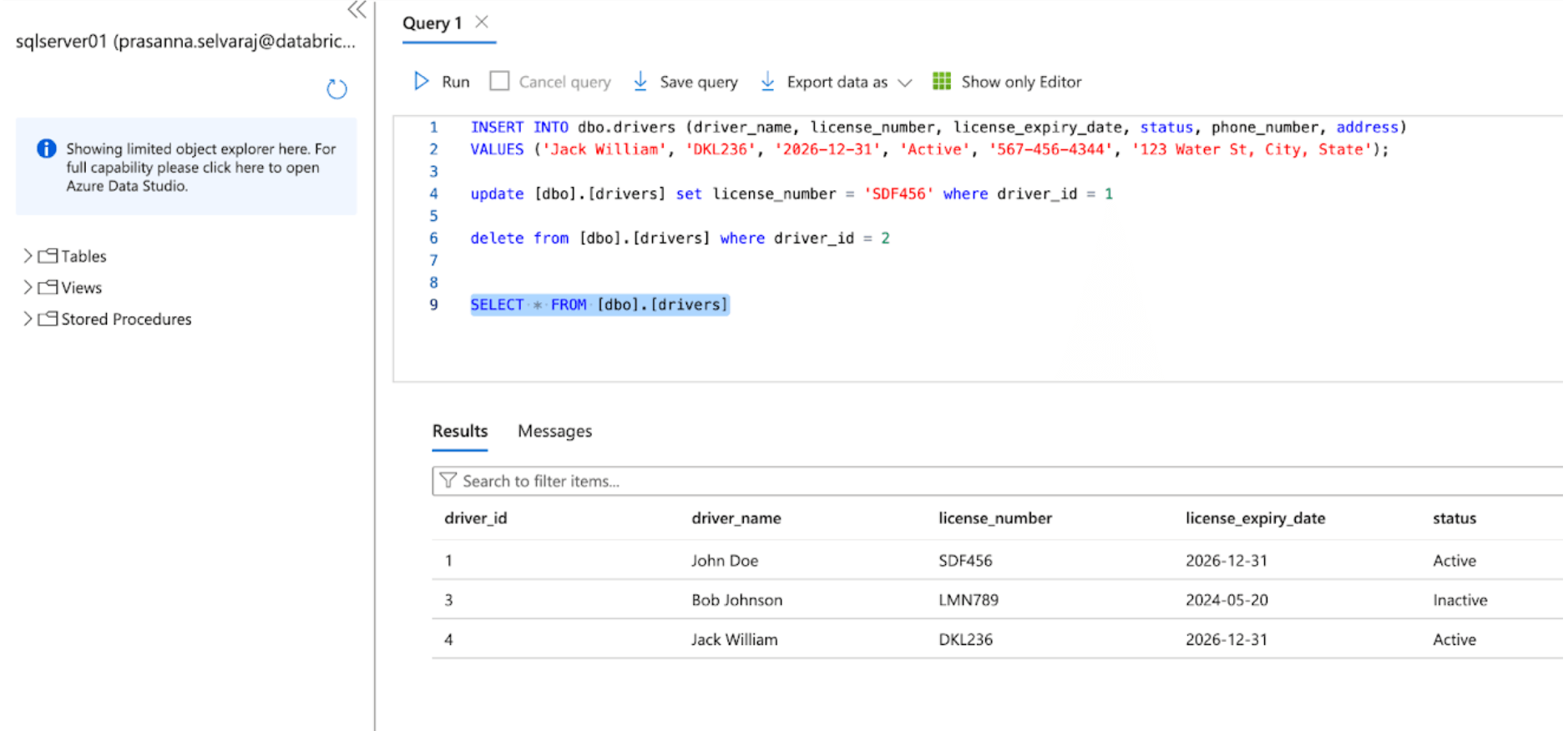
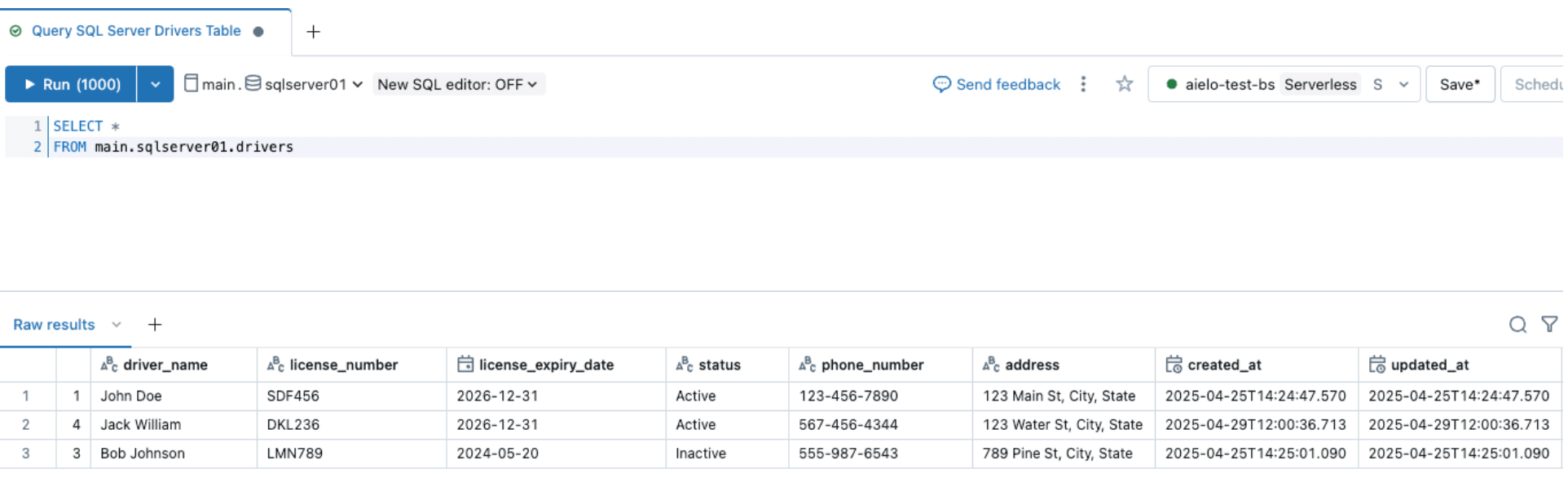
Sobald die Pipeline ausgelöst und abgeschlossen ist, fragen Sie die Delta-Tabelle im Zielschema ab und überprüfen Sie die Änderungen.
Führen Sie als Nächstes ein Schema-Evolution-Ereignis durch und fügen Sie eine Spalte zur SQL Server-Quelltabelle hinzu, wie unten gezeigt

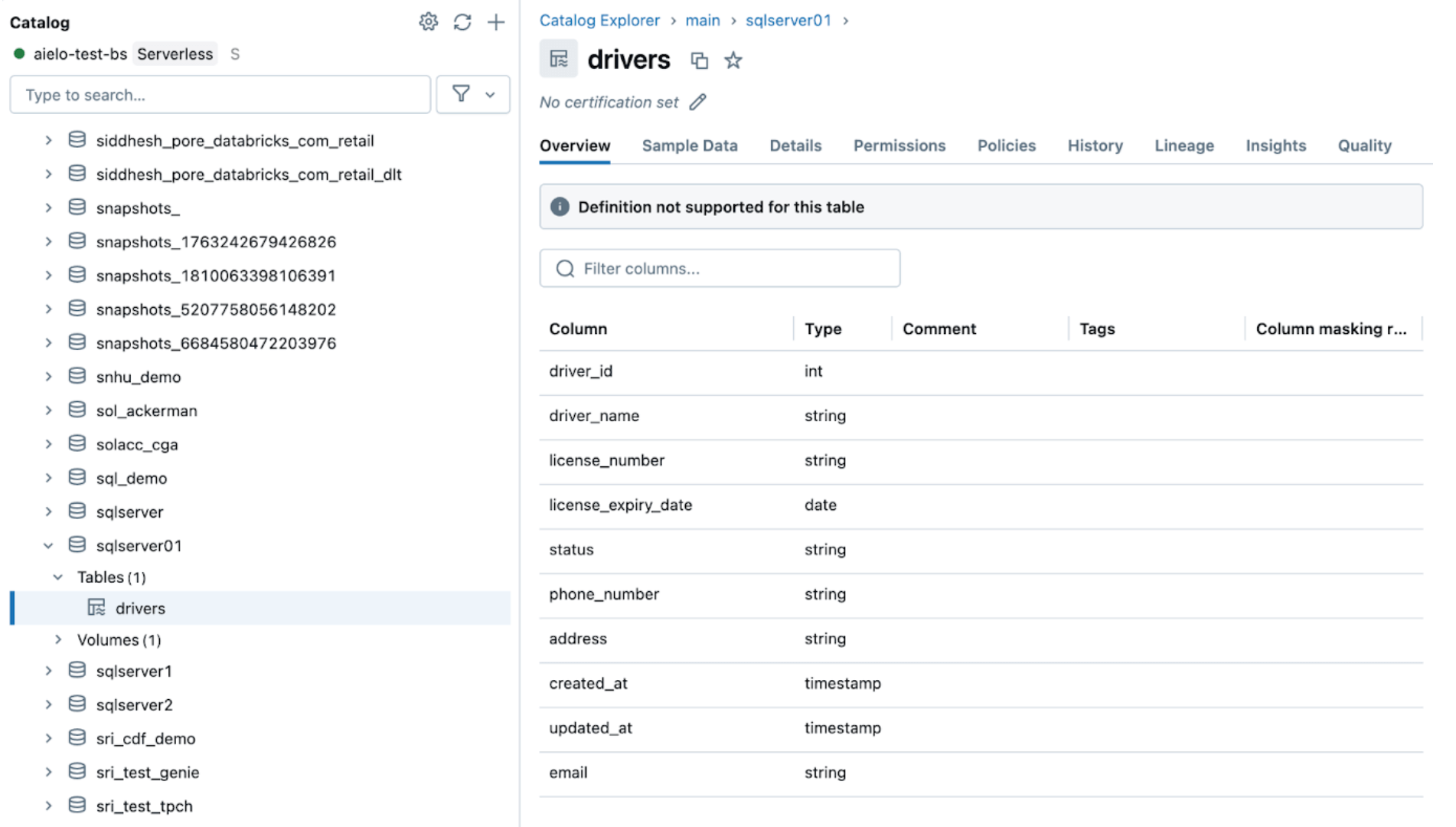
Nachdem die Quellen geändert wurden, lösen Sie die Aufnahmepipeline aus, indem Sie auf die Schaltfläche „Start“ in der Databricks DLT-Benutzeroberfläche klicken. Sobald die Pipeline abgeschlossen ist, überprüfen Sie die Änderungen, indem Sie die Zieltabelle durchsuchen, wie unten gezeigt. Die neue Spalte email wird am Ende der drivers-Tabelle angehängt.
5. [Databricks] Kontinuierliche Pipeline-Überwachung
Sobald die Ingestion- und Gateway-Pipelines erfolgreich laufen, ist die Überwachung ihrer Gesundheit und ihres Verhaltens entscheidend. Die Pipeline-Benutzeroberfläche bietet Datenqualitätsprüfungen, Pipeline-Fortschritt und Informationen zur Datenherkunft. Um die Ereignisprotokoll-Einträge in der Pipeline-Benutzeroberfläche anzuzeigen, suchen Sie den unteren Bereich unter dem Pipeline-DAG, wie unten gezeigt.

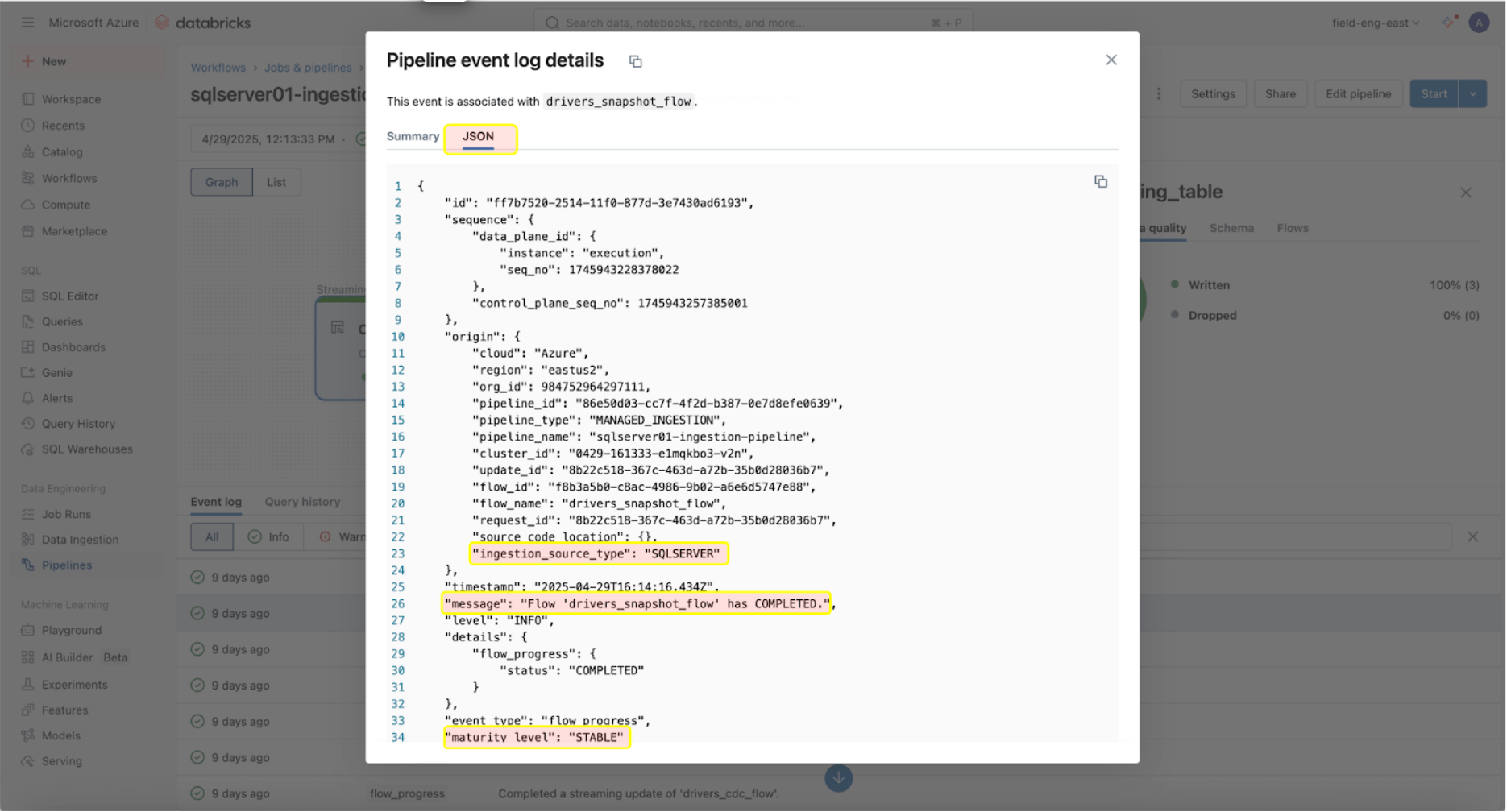
Der obige Eintrag im Ereignisprotokoll zeigt, dass der „drives_snapshot_flow“ aus SQL Server aufgenommen und abgeschlossen wurde. Die Reifegradstufe STABLE weist darauf hin, dass das Schema stabil ist und sich nicht geändert hat. Weitere Informationen zum Schema des Ereignisprotokolls finden Sie hier.
Beispiel aus der Praxis
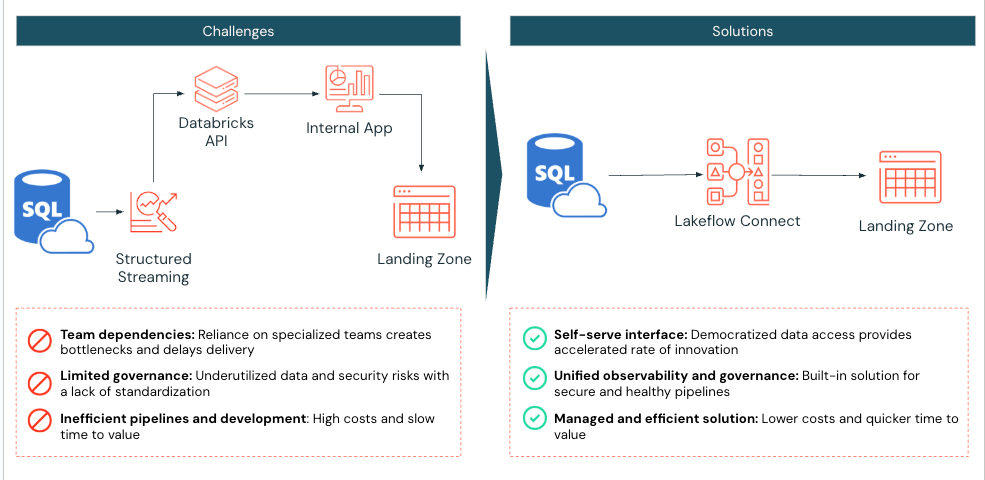
Ein großes medizinisch-diagnostisches Labor, das Databricks verwendet, stand vor der Herausforderung, SQL Server-Daten effizient in sein Lakehouse zu übertragen. Vor der Implementierung von Lakeflow Connect verwendete das Labor Databricks Spark-Notebooks, um zwei Tabellen aus Azure SQL Server in Databricks zu ziehen. Ihre Anwendung interagierte dann mit der Databricks API, um Compute und Jobausführung zu verwalten.
Das medizinisch-diagnostische Labor implementierte Lakeflow Connect für SQL Server und erkannte, dass dieser Prozess vereinfacht werden konnte. Nach der Aktivierung war die Implementierung in nur einem Tag abgeschlossen, was es dem medizinisch-diagnostischen Labor ermöglichte, die integrierten Tools von Databricks für die Beobachtbarkeit mit täglichen inkrementellen Ingestion-Aktualisierungen zu nutzen.
Betriebliche Überlegungen
Sobald der SQL Server-Konnektor erfolgreich eine Verbindung zu Ihrer Azure SQL-Datenbank hergestellt hat, besteht der nächste Schritt darin, Ihre Datenpipelines effizient zu planen, um Leistung und Ressourcenauslastung zu optimieren. Darüber hinaus ist es wichtig, die Best Practices für die programmatische Pipeline-Konfiguration zu befolgen, um Skalierbarkeit und Konsistenz über Umgebungen hinweg zu gewährleisten.
Pipeline-Orchestrierung
Es gibt keine Begrenzung, wie oft die Ingestion-Pipeline geplant werden kann. Um jedoch Kosten zu minimieren und Konsistenz bei Pipeline-Ausführungen ohne Überschneidungen zu gewährleisten, empfiehlt Databricks ein Intervall von mindestens 5 Minuten zwischen den Ingestion-Ausführungen. Dies ermöglicht die Aufnahme neuer Daten an der Quelle und berücksichtigt gleichzeitig die Rechenressourcen und die Startzeit.
Die Ingestion-Pipeline kann als Aufgabe innerhalb eines Jobs konfiguriert werden. Wenn nachgelagerte Workloads auf die Ankunft frischer Daten angewiesen sind, können Aufgabenabhängigkeiten festgelegt werden, um sicherzustellen, dass die Ausführung der Ingestion-Pipeline abgeschlossen ist, bevor nachgelagerte Aufgaben ausgeführt werden.
Wenn die Pipeline noch läuft, wenn die nächste Aktualisierung geplant ist, verhält sich die Ingestion-Pipeline ähnlich wie ein Job und überspringt die Aktualisierung bis zur nächsten geplanten, vorausgesetzt, die aktuell laufende Aktualisierung wird rechtzeitig abgeschlossen.
Beobachtbarkeit & Kostenverfolgung
Lakeflow Connect basiert auf einem Compute-basierten Preismodell, das Effizienz und Skalierbarkeit für verschiedene Datenintegrationsanforderungen gewährleistet. Die Ingestion-Pipeline läuft auf Serverless Compute, was Flexibilität bei der Skalierung je nach Bedarf ermöglicht und die Verwaltung vereinfacht, da Benutzer die zugrunde liegende Infrastruktur nicht konfigurieren und verwalten müssen.
Es ist jedoch wichtig zu beachten, dass die Ingestion-Pipeline zwar auf Serverless Compute laufen kann, das Ingestion-Gateway für Datenbankkonnektoren derzeit auf Classic Compute läuft, um die Verbindungen zur Datenbankquelle zu vereinfachen. Infolgedessen können Benutzer eine Kombination aus Classic- und Serverless DLT DBU-Gebühren in ihrer Abrechnung sehen.
Der einfachste Weg, die Nutzung von Lakeflow Connect zu verfolgen und zu überwachen, sind Systemtabellen. Unten sehen Sie ein Beispielabfrage, um die Nutzung einer bestimmten Lakeflow Connect-Pipeline anzuzeigen:

Die offizielle Preisdokumentation für Lakeflow Connect (AWS | Azure | GCP) enthält detaillierte Rateninformationen. Zusätzliche Kosten, wie z. B. Serverless Egress-Gebühren (Preise), können anfallen. Egress-Kosten vom Cloud-Anbieter für Classic Compute finden Sie hier (AWS | Azure | GCP).
Best Practices und wichtigste Erkenntnisse
Stand Mai 2025 sind hier einige der Best Practices und Überlegungen, die bei der Implementierung dieses SQL Server-Konnektors zu beachten sind:
- Konfigurieren Sie jedes Ingestion Gateway so, dass es mit einem Benutzer oder einer Entität authentifiziert wird, die nur Zugriff auf die replizierte Quelldatenbank hat.
- Stellen Sie sicher, dass der Benutzer die erforderlichen Berechtigungen zum Erstellen von Verbindungen in UC und zum Aufnehmen der Daten erhält.
- Verwenden Sie DABs, um Lakeflow Connect Ingestion-Pipelines zuverlässig zu konfigurieren und Wiederholbarkeit und Konsistenz in der Infrastrukturverwaltung zu gewährleisten.
- Für Quelltabellen mit Primärschlüsseln aktivieren Sie Change Tracking, um einen geringeren Overhead und eine verbesserte Leistung zu erzielen.
- Für Quelltabellen ohne Primärschlüssel aktivieren Sie CDC aufgrund seiner Fähigkeit, Änderungen auf Spaltenebene zu erfassen, auch ohne eindeutige Zeilenidentifikatoren.
Lakeflow Connect für SQL Server bietet eine vollständig verwaltete, integrierte Lösung für lokale und Cloud-Datenbanken zur effizienten, inkrementellen Ingestion in Databricks.
Nächste Schritte & Zusätzliche Ressourcen
Probieren Sie den SQL Server-Konnektor noch heute aus, um Ihre Herausforderungen bei der Datenaufnahme zu lösen. Befolgen Sie die Schritte in diesem Blog oder lesen Sie die Dokumentation. Erfahren Sie mehr über Lakeflow Connect auf der Produktseite, sehen Sie sich eine Produkttour an oder sehen Sie sich eine Demo des Salesforce-Konnektors zur Vorhersage von Kundenabwanderung an.
Databricks Delivery Solutions Architects (DSAs) beschleunigen Daten- und KI-Initiativen in Unternehmen. Sie bieten architektonische Führung, optimieren Plattformen hinsichtlich Kosten und Leistung, verbessern die Entwicklererfahrung und treiben die erfolgreiche Projektausführung voran. DSAs schließen die Lücke zwischen der anfänglichen Bereitstellung und produktionsreifen Lösungen. Sie arbeiten eng mit verschiedenen Teams zusammen, darunter Data Engineering, technische Leiter, Führungskräfte und andere Stakeholder, um maßgeschneiderte Lösungen und eine schnellere Wertschöpfung sicherzustellen. Um von einem benutzerdefinierten Ausführungsplan, strategischer Anleitung und Unterstützung während Ihrer Daten- und KI-Reise durch einen DSA zu profitieren, wenden Sie sich bitte an Ihr Databricks Account Team.
Appendix
In diesem optionalen Schritt, um die Lakeflow Connect Pipelines als Code mit DABs zu verwalten, müssen Sie lediglich zwei Dateien zu Ihrem bestehenden Bundle hinzufügen:
- Eine Workflow-Datei, die die Häufigkeit der Datenerfassung steuert (resources/sqlserver.yml).
- Eine Pipeline-Definitionsdatei (resources/sqlserver_pipeline.yml).
resources/sqlserver.yml:
resources/sqlserver_job.yml:
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.