LLM-Inferenz-Performance-Engineering: Best Practices
von Megha Agarwal, Asfandyar Qureshi, Nikhil Sardana, Linden Li, Julian Quevedo und Daya Khudia
In diesem Blogbeitrag teilt das MosaicML Engineering Team Best Practices, wie beliebte Open-Source Large Language Models (LLMs) für den Produktionseinsatz optimal genutzt werden können. Wir geben auch Richtlinien für die Bereitstellung von Inferenzdiensten, die auf diesen Modellen basieren, um Benutzer bei der Auswahl von Modellen und der Bereitstellung von Hardware zu unterstützen. Wir haben mit mehreren PyTorch-basierten Backends in der Produktion gearbeitet; diese Richtlinien stammen aus unserer Erfahrung mit FasterTransformers, vLLM, NVIDIAs bald erscheinendem TensorRT-LLM und anderen.
LLM-Textgenerierung verstehen
Large Language Models (LLMs) generieren Text in einem zweistufigen Prozess: "Prefill", bei dem die Tokens im Eingabe-Prompt parallel verarbeitet werden, und "Decoding", bei dem Text nacheinander ('Token' für 'Token') autoregressiv generiert wird. Jedes generierte Token wird an die Eingabe angehängt und zurück in das Modell eingespeist, um das nächste Token zu generieren. Die Generierung stoppt, wenn das LLM ein spezielles Stopp-Token ausgibt oder wenn eine benutzerdefinierte Bedingung erfüllt ist (z. B. eine maximale Anzahl von Tokens wurde generiert). Wenn Sie mehr Hintergrundinformationen darüber wünschen, wie LLMs Decoder-Blöcke verwenden, lesen Sie diesen Blogbeitrag.
Tokens können Wörter oder Wortteile sein; die genauen Regeln für die Aufteilung von Text in Tokens variieren von Modell zu Modell. Sie können zum Beispiel vergleichen, wie Llama-Modelle Text tokenisieren und wie OpenAI-Modelle Text tokenisieren. Obwohl LLM-Inferenzanbieter oft über Leistung in Token-basierten Metriken (z. B. Tokens/Sekunde) sprechen, sind diese Zahlen aufgrund dieser Unterschiede nicht immer vergleichbar zwischen verschiedenen Modelltypen. Als konkretes Beispiel stellte das Team von Anyscale fest, dass die Tokenisierung von Llama 2 19 % länger dauert als die von ChatGPT (aber immer noch deutlich niedrigere Gesamtkosten verursacht). Forscher von HuggingFace fanden außerdem heraus, dass Llama 2 etwa 20 % mehr Tokens benötigte, um über die gleiche Textmenge wie GPT-4 zu trainieren.
Wichtige Metriken für LLM Serving
Wie genau sollten wir also über Inferenzgeschwindigkeit nachdenken?
Unser Team verwendet vier Schlüsselmetriken für LLM Serving:
- Time To First Token (TTFT): Wie schnell Benutzer die Ausgabe des Modells sehen, nachdem sie ihre Anfrage eingegeben haben. Kurze Wartezeiten für eine Antwort sind für Echtzeitinteraktionen unerlässlich, aber für Offline-Workloads weniger wichtig. Diese Metrik wird durch die Zeit bestimmt, die für die Verarbeitung des Prompts und die Generierung des ersten Ausgabetokens benötigt wird.
- Time Per Output Token (TPOT): Zeit, die benötigt wird, um ein Ausgabetoken für jeden Benutzer zu generieren, der unser System abfragt. Diese Metrik entspricht der Wahrnehmung der Modellgeschwindigkeit durch jeden Benutzer. Zum Beispiel wären 100 Millisekunden/Token TPOT 10 Tokens pro Sekunde pro Benutzer oder ca. 450 Wörter pro Minute, was schneller ist, als eine durchschnittliche Person lesen kann.
- Latenz: Die Gesamtzeit, die das Modell benötigt, um die vollständige Antwort für einen Benutzer zu generieren. Die Gesamtlatenz der Antwort kann mit den beiden vorherigen Metriken berechnet werden: Latenz = (TTFT) + (TPOT) * (Anzahl der zu generierenden Tokens).
- Durchsatz: Die Anzahl der Ausgabetokens pro Sekunde, die ein Inferenzserver für alle Benutzer und Anfragen generieren kann.
Unser Ziel? Die schnellste Time To First Token, der höchste Durchsatz und die schnellste Time Per Output Token. Mit anderen Worten, wir möchten, dass unsere Modelle so schnell wie möglich Text für so viele Benutzer wie möglich generieren.
Es gibt einen bemerkenswerten Kompromiss zwischen Durchsatz und Zeit pro Ausgabetoken: Wenn wir 16 Benutzeranfragen gleichzeitig verarbeiten, haben wir einen höheren Durchsatz im Vergleich zur sequenziellen Verarbeitung der Anfragen, aber es dauert länger, Ausgabetokens für jeden Benutzer zu generieren.
Wenn Sie allgemeine Inferenzlatenzziele haben, finden Sie hier einige nützliche Heuristiken zur Bewertung von Modellen:
- Ausgabelänge dominiert die gesamte Antwortlatenz: Für die durchschnittliche Latenz können Sie normalerweise einfach Ihre erwartete/maximale Ausgabetokenlänge nehmen und diese mit einer durchschnittlichen Zeit pro Ausgabetoken für das Modell multiplizieren.
- Eingabelänge ist für die Leistung nicht signifikant, aber wichtig für Hardwareanforderungen: Die Hinzufügung von 512 Eingabe-Tokens erhöht die Latenz weniger als die Produktion von 8 zusätzlichen Ausgabe-Tokens in den MPT-Modellen. Die Notwendigkeit, lange Eingaben zu unterstützen, kann die Bereitstellung von Modellen jedoch erschweren. Wir empfehlen beispielsweise die Verwendung des A100-80GB (oder neuer), um MPT-7B mit seiner maximalen Kontextlänge von 2048 Tokens bereitzustellen.
- Gesamtlatenz skaliert sublinear mit der Modellgröße: Auf derselben Hardware sind größere Modelle langsamer, aber das Geschwindigkeitsverhältnis entspricht nicht unbedingt dem Verhältnis der Parameteranzahl. Die Latenz von MPT-30B ist etwa 2,5-mal so hoch wie die von MPT-7B. Die Latenz von Llama2-70B ist etwa 2-mal so hoch wie die von Llama2-13B.
Potenzielle Kunden fragen uns oft, ob wir eine durchschnittliche Inferenzlatenz angeben können. Wir empfehlen, dass Sie, bevor Sie sich auf bestimmte Latenzziele festlegen ("wir brauchen weniger als 20 ms pro Token"), einige Zeit damit verbringen, Ihre erwarteten Eingabe- und gewünschten Ausgabelängen zu charakterisieren.
Herausforderungen bei der LLM-Inferenz
Die Optimierung der LLM-Inferenz profitiert von allgemeinen Techniken wie:
- Operator Fusion: Das Zusammenfassen verschiedener benachbarter Operatoren führt oft zu einer besseren Latenz.
- Quantisierung: Aktivierungen und Gewichte werden komprimiert, um eine geringere Anzahl von Bits zu verwenden.
- Kompression: Sparsity oder Distillation.
- Parallelisierung: Tensor-Parallelität über mehrere Geräte oder Pipeline-Parallelität für größere Modelle.
Über diese Methoden hinaus gibt es viele wichtige Transformer-spezifische Optimierungen. Ein Hauptbeispiel hierfür ist das KV (Key-Value) Caching. Der Attention-Mechanismus in Decoder-Only-Transformer-basierten Modellen ist rechnerisch ineffizient. Jedes Token beachtet alle zuvor gesehenen Tokens und berechnet somit viele der gleichen Werte neu, wenn jedes neue Token generiert wird. Zum Beispiel beachtet beim Generieren des N-ten Tokens das (N-1)-te Token die (N-2)-ten, (N-3)-ten ... 1-ten Tokens. Ebenso muss beim Generieren des (N+1)-ten Tokens die Attention für das N-te Token erneut die (N-1)-ten, (N-2)-ten, (N-3)-ten ... 1-ten Tokens betrachten. KV-Caching, d. h. das Speichern von Zwischenschlüsseln/-werten für die Attention-Layer, wird verwendet, um diese Ergebnisse für die spätere Wiederverwendung zu erhalten und wiederholte Berechnungen zu vermeiden.
Speicherbandbreite ist entscheidend
Berechnungen in LLMs werden hauptsächlich von Matrix-Matrix-Multiplikationsoperationen dominiert; diese Operationen mit kleinen Dimensionen sind auf den meisten Hardware-Systemen typischerweise speicherbandbreitengebunden. Bei der autoregressiven Token-Generierung ist eine der Aktivierungsmatrixdimensionen (definiert durch Batch-Größe und Anzahl der Tokens in der Sequenz) bei kleinen Batch-Größen klein. Daher hängt die Geschwindigkeit davon ab, wie schnell wir Modellparameter vom GPU-Speicher in lokale Caches/Register laden können, und nicht davon, wie schnell wir mit geladenen Daten rechnen können. Die verfügbare und erreichte Speicherbandbreite in der Inferenz-Hardware ist ein besserer Prädiktor für die Geschwindigkeit der Token-Generierung als ihre Spitzen-Rechenleistung.
Die Auslastung der Inferenz-Hardware ist in Bezug auf die Serving-Kosten sehr wichtig. GPUs sind teuer und wir müssen sie so viel Arbeit wie möglich erledigen lassen. Gemeinsame Inferenzdienste versprechen, die Kosten niedrig zu halten, indem sie Workloads von vielen Benutzern kombinieren, einzelne Lücken füllen und überlappende Anfragen zusammenfassen. Für große Modelle wie Llama2-70B erreichen wir nur bei großen Batch-Größen eine gute Kosten/Leistung. Ein Inferenz-Serving-System, das bei großen Batch-Größen betrieben werden kann, ist entscheidend für die Kosteneffizienz. Ein großer Batch bedeutet jedoch eine größere KV-Cache-Größe, und das erhöht wiederum die Anzahl der benötigten GPUs, um das Modell bereitzustellen. Hier gibt es ein Tauziehen, und Betreiber von Shared Services müssen einige Kostenkompromisse eingehen und Systemoptimierungen implementieren.
Model Bandwidth Utilization (MBU)
Wie optimiert ist ein LLM-Inferenzserver?
Wie bereits kurz erläutert, wird die Inferenz für LLMs bei kleineren Batch-Größen – insbesondere zur Decodierungszeit – durch die Geschwindigkeit des Ladens von Modellparametern vom Gerätespeicher zu den Recheneinheiten limitiert. Die Speicherbandbreite bestimmt, wie schnell die Datenbewegung erfolgt. Um die Auslastung der zugrunde liegenden Hardware zu messen, führen wir eine neue Metrik namens Model Bandwidth Utilization (MBU) ein. MBU ist definiert als (erreichte Speicherbandbreite) / (Spitzen-Speicherbandbreite), wobei die erreichte Speicherbandbreite ((Gesamtgröße der Modellparameter + KV-Cache-Größe) / TPOT) ist.
Zum Beispiel, wenn ein 7B-Parameter, der mit 16-Bit-Präzision läuft, eine TPOT von 14ms hat, dann werden 14 GB Parameter in 14ms bewegt, was einer Bandbreitennutzung von 1 TB/Sekunde entspricht. Wenn die Spitzenbandbreite der Maschine 2 TB/Sekunde beträgt, laufen wir mit einer MBU von 50%. Der Einfachheit halber ignoriert dieses Beispiel die KV-Cache-Größe, die bei kleineren Batch-Größen und kürzeren Sequenzlängen gering ist. MBU-Werte nahe 100% deuten darauf hin, dass das Inferenzsystem die verfügbare Speicherbandbreite effektiv nutzt. MBU ist auch nützlich, um verschiedene Inferenzsysteme (Hardware + Software) auf normierte Weise zu vergleichen. MBU ist eine Ergänzung zur Metrik Model Flops Utilization (MFU; eingeführt im PaLM-Paper), die in rechenintensiven Szenarien wichtig ist.
Abbildung 1 zeigt eine bildliche Darstellung von MBU in einem Diagramm ähnlich einem Roofline-Diagramm. Die durchgezogene, geneigte Linie des orange schattierten Bereichs zeigt den maximal möglichen Durchsatz, wenn die Speicherbandbreite zu 100% ausgelastet ist. In der Realität ist die beobachtete Leistung bei kleinen Batch-Größen (weißer Punkt) jedoch geringer als das Maximum – wie viel geringer ist ein Maß für die MBU. Bei großen Batch-Größen (gelber Bereich) ist das System rechenintensiv, und der erreichte Durchsatz als Bruchteil des maximal möglichen Durchsatzes wird als Model Flops Utilization (MFU) gemessen.
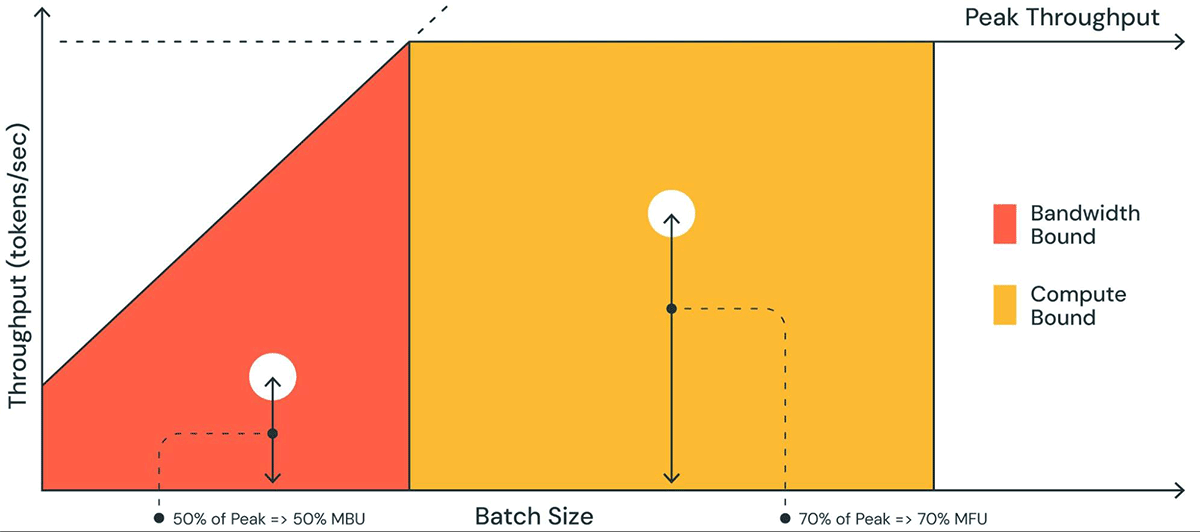
MBU und MFU bestimmen, wie viel mehr Spielraum für die Beschleunigung der Inferenzgeschwindigkeit auf einem gegebenen Hardware-Setup vorhanden ist. Abbildung 2 zeigt die gemessene MBU für verschiedene Grade der Tensorparallelität mit unserem TensorRT-LLM-basierten Inferenzserver. Die Spitzen-Speicherbandbreitennutzung wird beim Übertragen großer zusammenhängender Speicherblöcke erreicht. Wenn kleinere Modelle wie MPT-7B über mehrere GPUs verteilt werden, beobachten wir eine geringere MBU, da wir kleinere Speicherblöcke auf jeder GPU bewegen.
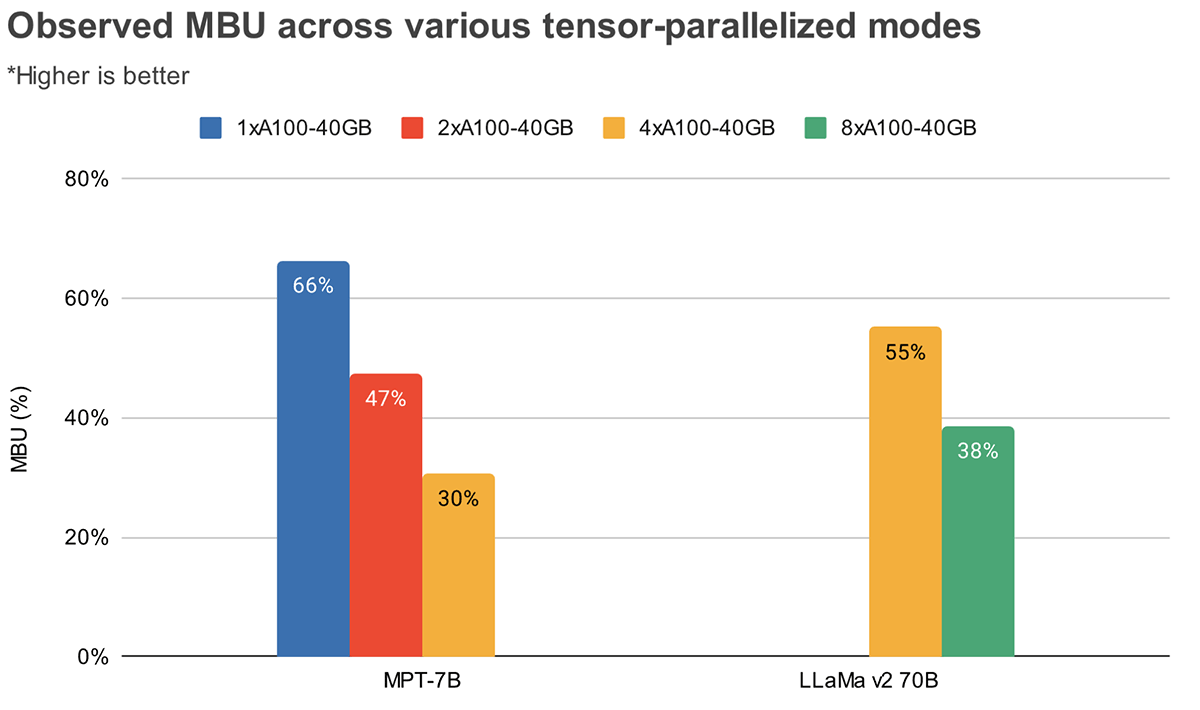
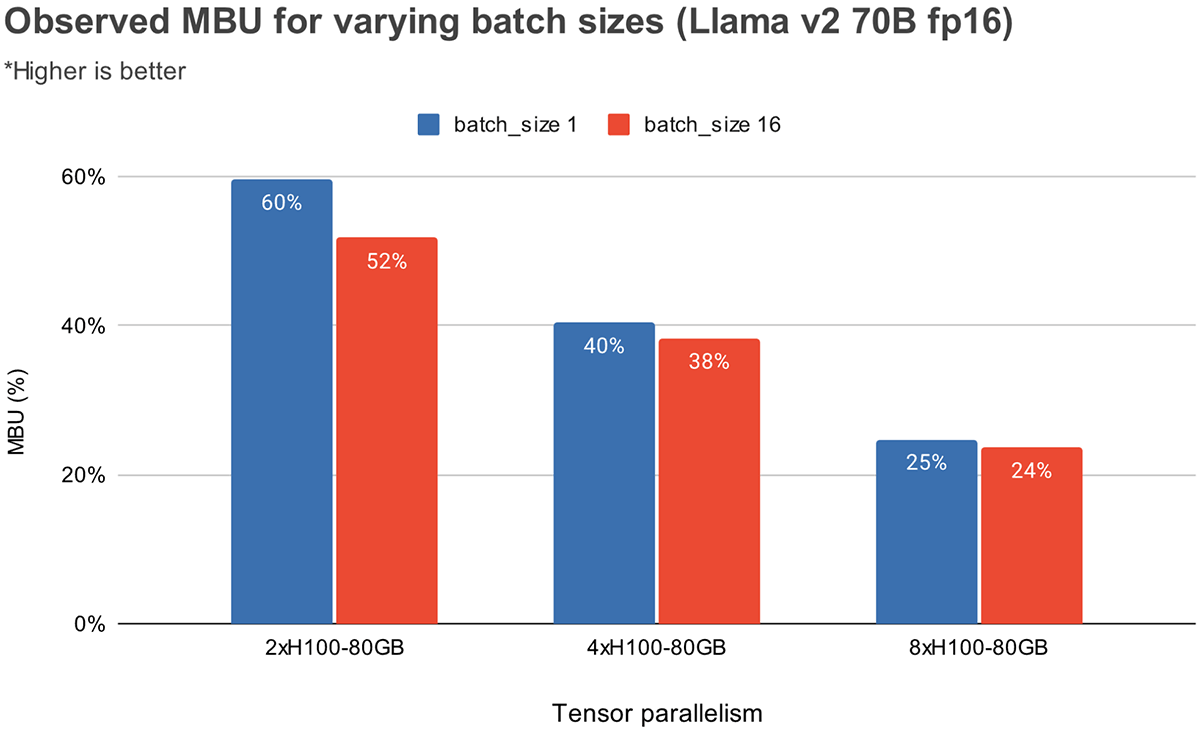
Abbildung 3 zeigt empirisch beobachtete MBU für verschiedene Grade der Tensorparallelität und Batch-Größen auf den NVIDIA H100 GPUs. Die MBU nimmt mit zunehmender Batch-Größe ab. Wenn wir jedoch GPUs skalieren, ist die relative Abnahme der MBU weniger signifikant. Es ist auch erwähnenswert, dass die Auswahl von Hardware mit größerer Speicherbandbreite die Leistung mit weniger GPUs steigern kann. Bei einer Batch-Größe von 1 können wir eine höhere MBU von 60% auf 2xH100-80GB erreichen, verglichen mit 55% auf 4xA100-40GB GPUs (Abbildung 2).
Benchmark-Ergebnisse
Latenz
Wir haben die Zeit bis zum ersten Token (TTFT) und die Zeit pro Ausgabetoken (TPOT) über verschiedene Grade der Tensorparallelität für die Modelle MPT-7B und Llama2-70B gemessen. Wenn die Eingabe-Prompts länger werden, beginnt die Zeit für die Generierung des ersten Tokens einen erheblichen Teil der Gesamtlatenz auszumachen. Die Tensorparallelisierung über mehrere GPUs hinweg hilft, diese Latenz zu reduzieren.
Im Gegensatz zum Modelltraining bietet die Skalierung auf mehr GPUs nur geringe Ertragssteigerungen für die Inferenzlatenz. Z.B. verringert sich bei Llama2-70B der Wechsel von 4x auf 8x GPUs nur um das 0,7-fache bei kleinen Batch-Größen. Ein Grund dafür ist, dass höhere Parallelität eine niedrigere MBU aufweist (wie oben diskutiert). Ein weiterer Grund ist, dass die Tensorparallelität Kommunikations-Overhead über einen GPU-Knoten hinweg verursacht.
| Zeit bis zum ersten Token (ms) | ||||
|---|---|---|---|---|
| Modell | 1xA100-40GB | 2xA100-40GB | 4xA100-40GB | 8xA100-40GB |
| MPT-7B | 46 (1x) | 34 (0,73x) | 26 (0,56x) | - |
| Llama2-70B | Passt nicht | 154 (1x) | 114 (0,74x) | |
Tabelle 1: Zeit bis zum ersten Token bei Eingabeanfragen mit 512 Token Länge und einer Batch-Größe von 1. Größere Modelle wie Llama2 70B benötigen mindestens 4xA100-40B GPUs, um in den Speicher zu passen.
Bei größeren Batch-Größen führt eine höhere Tensorparallelität zu einer signifikanteren relativen Abnahme der Token-Latenz. Abbildung 4 zeigt, wie sich die Zeit pro Ausgabetoken für MPT-7B ändert. Bei einer Batch-Größe von 1 reduziert der Wechsel von 2x auf 4x die Token-Latenz nur um etwa 12%. Bei einer Batch-Größe von 16 ist die Latenz mit 4x um 33% niedriger als mit 2x. Dies steht im Einklang mit unserer früheren Beobachtung, dass die relative Abnahme der MBU bei höheren Graden der Tensorparallelität für eine Batch-Größe von 16 im Vergleich zu einer Batch-Größe von 1 geringer ist.
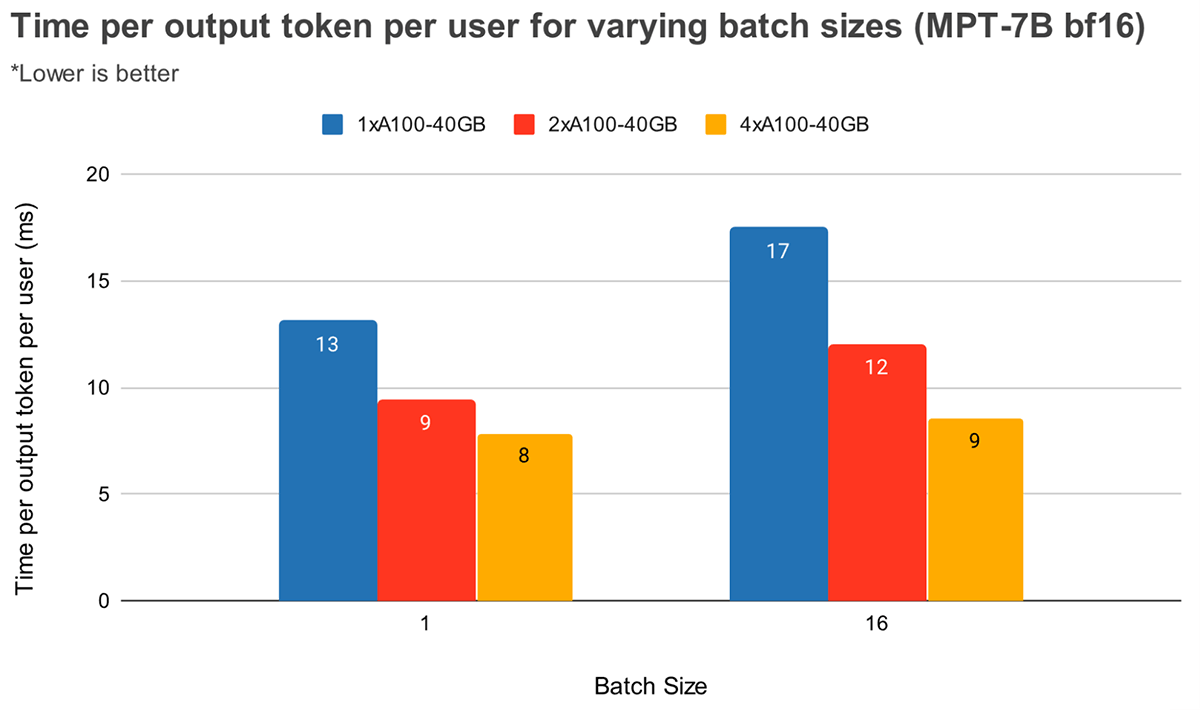
Abbildung 5 zeigt ähnliche Ergebnisse für Llama2-70B, außer dass die relative Verbesserung zwischen 4x und 8x weniger ausgeprägt ist. Wir vergleichen auch die GPU-Skalierung über zwei verschiedene Hardware-Konfigurationen. Da H100-80GB eine 2,15-mal höhere GPU-Speicherbandbreite als A100-40GB hat, sehen wir, dass die Latenz bei Batch-Größe 1 um 36% und bei Batch-Größe 16 um 52% niedriger ist für 4x-Systeme.
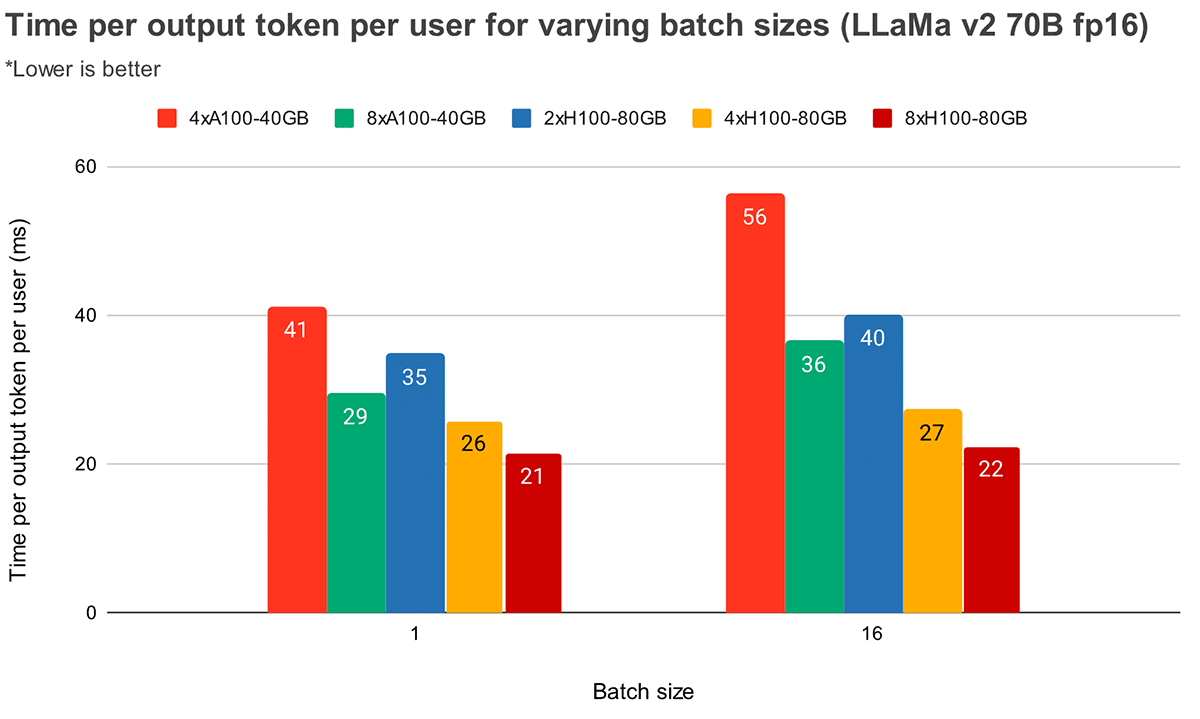
Durchsatz
Wir können Durchsatz und Zeit pro Token tauschen, indem wir Anfragen zusammenfassen. Das Gruppieren von Anfragen während der GPU-Auswertung erhöht den Durchsatz im Vergleich zur sequenziellen Verarbeitung von Anfragen, aber jede Anfrage wird länger dauern (Warteschlangeneffekte ignoriert).
Es gibt einige gängige Techniken für das Batching von Inferenzanfragen:
- Statisches Batching: Der Client packt mehrere Prompts in Anfragen und eine Antwort wird zurückgegeben, nachdem alle Sequenzen im Batch abgeschlossen sind. Unsere Inferenzserver unterstützen dies, verlangen es aber nicht.
- Dynamisches Batching: Prompts werden auf dem Server im laufenden Betrieb zusammengefasst. Typischerweise schneidet diese Methode schlechter ab als statisches Batching, kann aber nahe an das Optimum herankommen, wenn Antworten kurz oder von einheitlicher Länge sind. Funktioniert nicht gut, wenn Anfragen unterschiedliche Parameter haben.
- Kontinuierliches Batching: Die Idee, Anfragen zusammenzufassen, sobald sie eintreffen, wurde in diesem hervorragenden Paper vorgestellt und ist derzeit die SOTA-Methode. Anstatt darauf zu warten, dass alle Sequenzen in einem Batch abgeschlossen sind, gruppiert es Sequenzen auf Iterationsebene. Es kann einen 10- bis 20-mal höheren Durchsatz als dynamisches Batching erzielen.
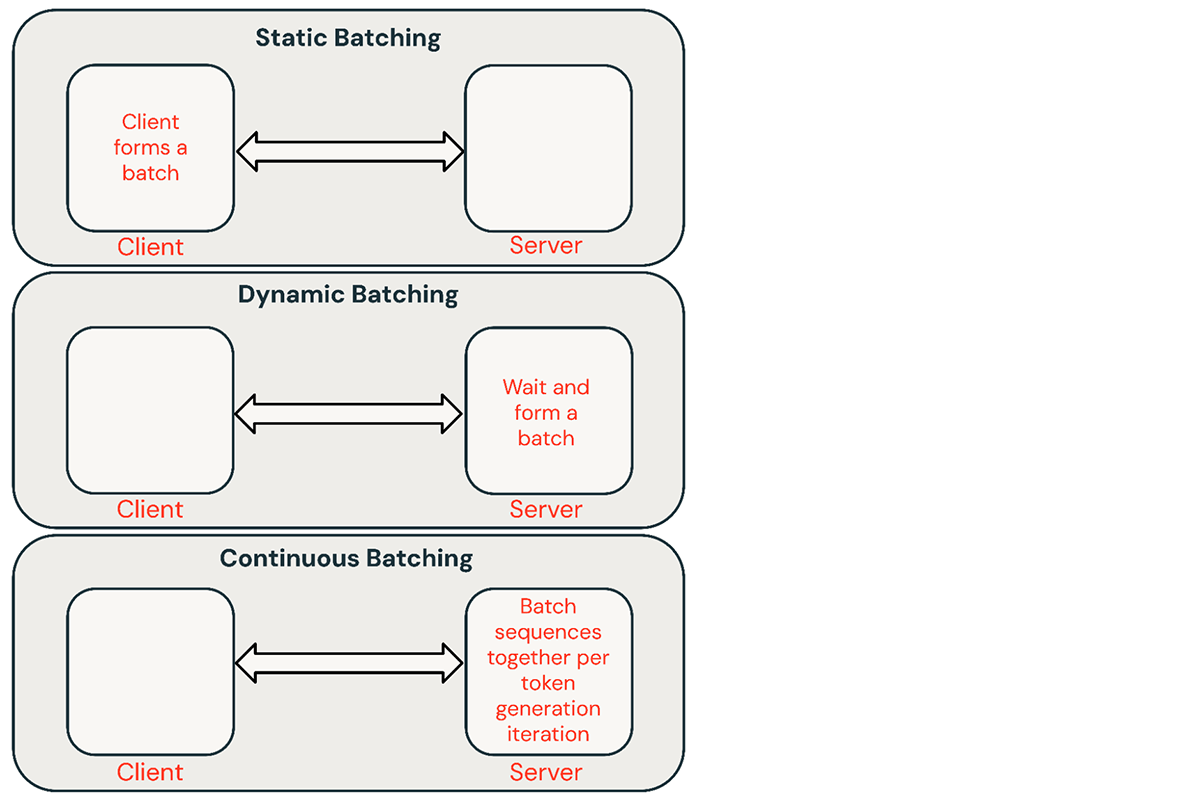
Kontinuierliches Batching ist normalerweise der beste Ansatz für gemeinsam genutzte Dienste, aber es gibt Situationen, in denen die anderen beiden besser sein könnten. In Umgebungen mit niedriger QPS kann dynamisches Batching kontinuierliches Batching übertreffen. Es ist manchmal einfacher, Low-Level-GPU-Optimierungen in einem einfacheren Batching-Framework zu implementieren. Für Offline-Batch-Inferenz-Workloads kann statisches Batching erhebliche Overheads vermeiden und einen besseren Durchsatz erzielen.
Batch-Größe
Wie gut das Batching funktioniert, hängt stark vom Anfrage-Stream ab. Wir können jedoch eine Obergrenze für die Leistung ermitteln, indem wir statisches Batching mit einheitlichen Anfragen benchmarken.
| Batch-Größe | |||||||
|---|---|---|---|---|---|---|---|
| Hardware | 1 | 4 | 8 | 16 | 32 | 64 | 128 |
| 1 x A10 | 0,4 (1x) | 1,4 (3,5x) | 2,3 (6x) | 3,5 (9x) | OOM (Out of Memory) Fehler | ||
| 2 x A10 | 0,8 | 2,5 | 4,0 | 7,0 | 8,0 | ||
| 1 x A100 | 0,9 (1x) | 3,2 (3,5x) | 5,3 (6x) | 8,0 (9x) | 10,5 (12x) | 12,5 (14x) | |
| 2 x A100 | 1,3 | 3,0 | 5,5 | 9,5 | 14,5 | 17,0 | 22,0 |
| 4 x A100 | 1,7 | 6,2 | 11,5 | 18,0 | 25,0 | 33,0 | 36,5 |
Tabelle 2: Spitzen-MPT-7B-Durchsatz (Anfragen/Sek.) mit statischem Batching und einem FasterTransformers-basierten Backend. Anfragen: 512 Eingabe- und 64 Ausgabe-Token. Bei größeren Eingaben liegt die OOM-Grenze bei kleineren Batch-Größen.
Latenz-Kompromiss
Die Latenz von Anfragen steigt mit der Batch-Größe. Mit einer NVIDIA A100 GPU beispielsweise steigt bei Maximierung des Durchsatzes mit einer Batch-Größe von 64 die Latenz um das 4-fache, während sich der Durchsatz um das 14-fache erhöht. Gemeinsam genutzte Inferenzdienste wählen typischerweise eine ausgewogene Batch-Größe. Benutzer, die ihre eigenen Modelle hosten, sollten den geeigneten Kompromiss zwischen Latenz und Durchsatz für ihre Anwendungen festlegen. Bei einigen Anwendungen, wie z. B. Chatbots, hat eine niedrige Latenz für schnelle Antworten oberste Priorität. Bei anderen Anwendungen, wie der Stapelverarbeitung unstrukturierter PDFs, möchten wir möglicherweise die Latenz für die Verarbeitung eines einzelnen Dokuments opfern, um alle schnell parallel zu verarbeiten.
Abbildung 7 zeigt die Durchsatz- vs. Latenzkurve für das 7B-Modell. Jede Linie auf dieser Kurve wird durch Erhöhung der Batch-Größe von 1 auf 256 erzielt. Dies ist nützlich, um zu bestimmen, wie groß die Batch-Größe sein kann, abhängig von verschiedenen Latenzbeschränkungen. Wenn wir uns unsere obige Roofline-Grafik ansehen, stellen wir fest, dass diese Messungen mit dem übereinstimmen, was wir erwarten würden. Nach einer bestimmten Batch-Größe, d. h. wenn wir in den rechengebundenen Bereich wechseln, erhöht jede Verdopplung der Batch-Größe nur die Latenz, ohne den Durchsatz zu erhöhen.
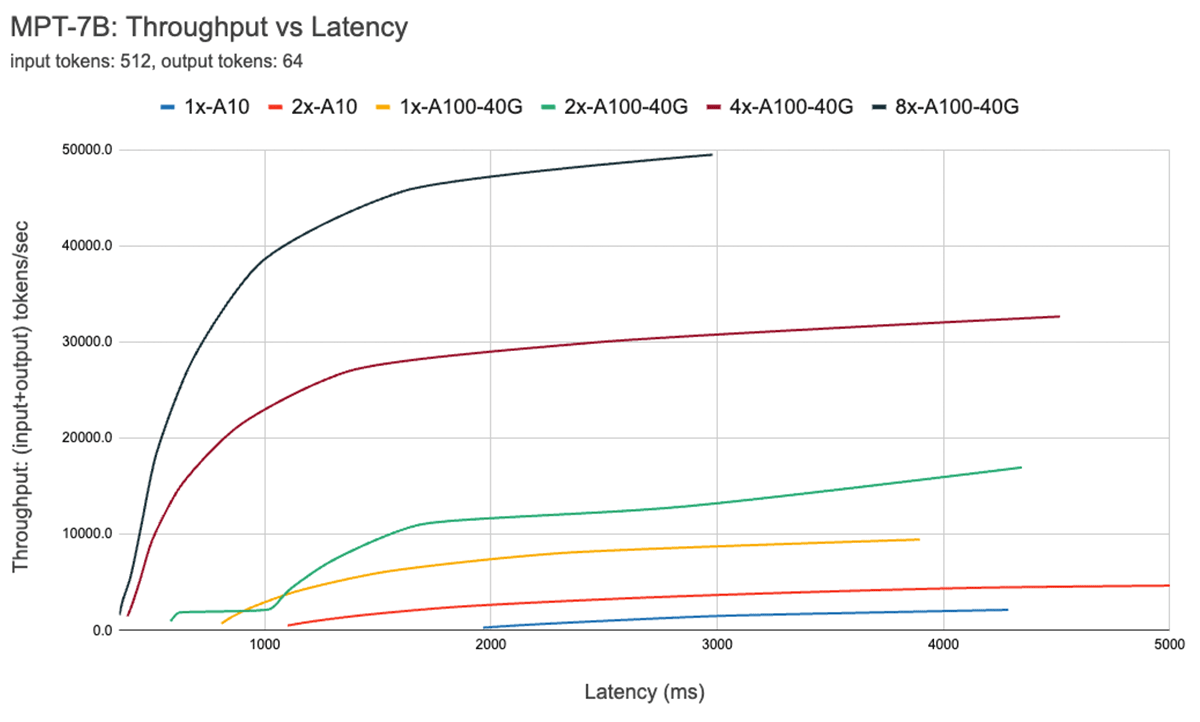
Bei der Verwendung von Parallelität ist es wichtig, Low-Level-Hardware-Details zu verstehen. Zum Beispiel sind nicht alle 8xA100-Instanzen in verschiedenen Clouds gleich. Einige Server verfügen über Hochgeschwindigkeitsverbindungen zwischen allen GPUs, andere koppeln GPUs und haben langsamere Verbindungen zwischen den Paaren. Dies kann zu Engpässen führen, wodurch die reale Leistung erheblich von den obigen Kurven abweicht.
Optimierungsfallstudie: Quantisierung
Quantisierung ist eine gängige Technik zur Reduzierung der Hardwareanforderungen für die LLM-Inferenz. Die Reduzierung der Präzision von Modellgewichten und Aktivierungen während der Inferenz kann die Hardwareanforderungen drastisch reduzieren. Beispielsweise kann der Wechsel von 16-Bit-Gewichten zu 8-Bit-Gewichten die Anzahl der benötigten GPUs in speicherbeschränkten Umgebungen (z. B. Llama2-70B auf A100s) halbieren. Die Reduzierung auf 4-Bit-Gewichte ermöglicht die Inferenz auf Consumer-Hardware (z. B. Llama2-70B auf Macbooks).
Nach unserer Erfahrung sollte die Quantisierung mit Vorsicht implementiert werden. Naive Quantisierungstechniken können zu einer erheblichen Verschlechterung der Modellqualität führen. Die Auswirkungen der Quantisierung variieren auch je nach Modellarchitektur (z. B. MPT vs. Llama) und Größe. Wir werden dies in einem zukünftigen Blogbeitrag genauer untersuchen.
Bei der Experimentation mit Techniken wie Quantisierung empfehlen wir die Verwendung eines LLM-Qualitäts-Benchmarks wie dem Mosaic Eval Gauntlet zur Bewertung der Qualität des Inferenzsystems, nicht nur der Qualität des Modells isoliert. Darüber hinaus ist es wichtig, tiefgreifendere Systemoptimierungen zu untersuchen. Insbesondere kann die Quantisierung KV-Caches viel effizienter machen.
Wie bereits erwähnt, werden bei der autoregressiven Token-Generierung vergangene Schlüssel/Werte (KV) aus den Aufmerksamkeitslayern zwischengespeichert, anstatt sie bei jedem Schritt neu zu berechnen. Die Größe des KV-Caches variiert je nach Anzahl der gleichzeitig verarbeiteten Sequenzen und der Länge dieser Sequenzen. Darüber hinaus werden bei jeder Iteration der nächsten Token-Generierung neue KV-Elemente zum vorhandenen Cache hinzugefügt, wodurch er mit jeder neuen Token-Generierung größer wird. Daher ist ein effektives KV-Cache-Speichermanagement beim Hinzufügen dieser neuen Werte entscheidend für eine gute Inferenzleistung. Llama2-Modelle verwenden eine Variante der Aufmerksamkeit namens Grouped Query Attention (GQA). Bitte beachten Sie, dass GQA, wenn die Anzahl der KV-Köpfe 1 ist, mit Multi-Query-Attention (MQA) identisch ist. GQA hilft dabei, die KV-Cache-Größe durch Teilen von Schlüsseln/Werten zu reduzieren. Die Formel zur Berechnung der KV-Cache-Größe lautet
batch_size * seqlen * (d_model/n_heads) * n_layers * 2 (K und V) * 2 (Bytes pro Float16) * n_kv_heads
Tabelle 3 zeigt die GQA KV-Cache-Größe, berechnet bei verschiedenen Batch-Größen bei einer Sequenzlänge von 1024 Token. Die Parametergröße für Llama2-Modelle beträgt im Vergleich 140 GB (Float16) für das 70B-Modell. Die Quantisierung des KV-Caches ist eine weitere Technik (zusätzlich zu GQA/MQA), um die Größe des KV-Caches zu reduzieren, und wir bewerten derzeit deren Auswirkungen auf die Generierungsqualität.
| Batch-Größe | GQA KV-Cache-Speicher (FP16) | GQA KV-Cache-Speicher (Int8) |
|---|---|---|
| 1 | 0,312 GiB | 0,156 GiB |
| 16 | 5 GiB | 2,5 GiB |
| 32 | 10 GiB | 5 GiB |
| 64 | 20 GiB | 10 GiB |
Tabelle 3: KV-Cache-Größe für Llama-2-70B bei einer Sequenzlänge von 1024
Wie bereits erwähnt, ist die Token-Generierung mit LLMs bei kleinen Batch-Größen ein Problem, das durch die GPU-Speicherbandbreite begrenzt wird, d. h. die Geschwindigkeit der Generierung hängt davon ab, wie schnell Modellparameter vom GPU-Speicher in On-Chip-Caches verschoben werden können. Die Konvertierung von Modellgewichten von FP16 (2 Bytes) in INT8 (1 Byte) oder INT4 (0,5 Byte) erfordert die Übertragung von weniger Daten und beschleunigt daher die Token-Generierung. Die Quantisierung kann sich jedoch negativ auf die Modellgenerierungsqualität auswirken. Wir bewerten derzeit die Auswirkungen auf die Modellqualität mit Model Gauntlet und planen, bald einen Folgebeitrag dazu zu veröffentlichen.
Schlussfolgerungen und wichtigste Ergebnisse
Jeder der oben genannten Faktoren beeinflusst, wie wir Modelle erstellen und bereitstellen. Wir nutzen diese Ergebnisse, um datengesteuerte Entscheidungen zu treffen, die den Hardwaretyp, den Software-Stack, die Modellarchitektur und typische Nutzungsmuster berücksichtigen. Hier sind einige Empfehlungen aus unserer Erfahrung.
Identifizieren Sie Ihr Optimierungsziel: Geht es Ihnen um interaktive Leistung? Maximierung des Durchsatzes? Minimierung der Kosten? Hier gibt es vorhersehbare Kompromisse.
Achten Sie auf die Latenzkomponenten: Bei interaktiven Anwendungen bestimmt die Zeit bis zum ersten Token, wie reaktionsschnell Ihr Dienst ist, und die Zeit pro Ausgabetoken bestimmt, wie schnell er sich anfühlt.
Speicherbandbreite ist entscheidend: Die Generierung des ersten Tokens ist typischerweise rechengebunden, während die nachfolgende Dekodierung eine speichergebundene Operation ist. Da LLM-Inferenz häufig in speichergebundenen Szenarien durchgeführt wird, ist MBU eine nützliche Metrik zur Optimierung und kann zum Vergleich der Effizienz von Inferenzsystemen verwendet werden.
Batching ist entscheidend: Die Verarbeitung mehrerer Anfragen gleichzeitig ist entscheidend für hohen Durchsatz und die effektive Nutzung teurer GPUs. Für gemeinsam genutzte Online-Dienste ist kontinuierliches Batching unerlässlich, während Offline-Batch-Inferenz-Workloads mit einfacheren Batching-Techniken einen hohen Durchsatz erzielen können.
Tiefgreifende Optimierungen: Standard-Inferenzoptimierungstechniken sind für LLMs wichtig (z. B. Operator-Fusion, Gewichtsquantisierung), aber es ist wichtig, tiefere Systemoptimierungen zu erforschen, insbesondere solche, die die Speichernutzung verbessern. Ein Beispiel hierfür ist die KV-Cache-Quantisierung.
Hardwarekonfigurationen: Der Modelltyp und die erwartete Workload sollten zur Auswahl der Bereitstellungshardware herangezogen werden. Wenn beispielsweise die Skalierung auf mehrere GPUs erfolgt, fällt die MBU bei kleineren Modellen wie MPT-7B viel schneller ab als bei größeren Modellen wie Llama2-70B. Die Leistung skaliert tendenziell auch sublinear mit höheren Graden an Tensorparallelität. Dennoch kann ein hoher Grad an Tensorparallelität für kleinere Modelle sinnvoll sein, wenn der Traffic hoch ist oder wenn Benutzer bereit sind, einen Aufpreis für zusätzliche geringe Latenz zu zahlen.
Datengesteuerte Entscheidungen: Das Verständnis der Theorie ist wichtig, aber wir empfehlen, die End-to-End-Serverleistung immer zu messen. Es gibt viele Gründe, warum eine Inferenzbereitstellung schlechter als erwartet funktionieren kann. Die MBU könnte aufgrund von Softwareineffizienzen unerwartet niedrig sein. Oder Unterschiede in der Hardware zwischen Cloud-Anbietern könnten zu Überraschungen führen (wir haben einen 2-fachen Latenzunterschied zwischen 8xA100-Servern von zwei Cloud-Anbietern beobachtet).
Um mit der LLM-Inferenz zu beginnen, probieren Sie Databricks Model Serving aus. Schauen Sie sich die Dokumentation an, um mehr zu erfahren.
Alle vorherigen MosaicML-Blogs anzeigen
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.