LLMs im Lakehouse: Ein Quantensprung nach vorne für den öffentlichen Sektor
von Tim Lortz, Parth Vakil und Lisa Sion

In den letzten Monaten ist das Interesse von Behörden des öffentlichen Sektors an Large Language Models (LLMs) sprunghaft angestiegen, da LLMs die Erwartungen, die Menschen an ihre Interaktionen mit Computern und Daten haben, grundlegend verändern. Aus Sicht von Databricks verspürt praktisch jeder Kunde und Interessent aus dem öffentlichen Sektor, mit dem wir interagieren, den Auftrag, LLMs in seine Mission zu integrieren. Uns werden immer wieder Fragen darüber gestellt, was LLMs (wie Databricks' Dolly) sind, wofür sie verwendet werden können und wie die Databricks Lakehouse LLM-bezogene Anwendungen unterstützen wird. In diesem Beitrag gehen wir auf diese Fragen im Kontext der besonderen Bedürfnisse, Chancen und Beschränkungen von Organisationen des öffentlichen Sektors ein. Wir werden uns auch auf die Vorteile der Erstellung, des Besitzes und der Kuratierung eines eigenen LLM konzentrieren, im Gegensatz zur Einführung einer Technologie wie ChatGPT, die Data Sharing erfordert.
Was sind LLMs?
Die heutigen LLMs stellen die neueste Version in einer Reihe von Innovationen im Bereich Natural Language Processing dar, die etwa 2017 mit dem Aufkommen der Transformer -Modellarchitektur begann. Diese auf Transformern basierenden Modelle verfügen seit Langem über erstaunliche Fähigkeiten, die menschliche Sprache so gut zu verstehen, dass sie Tasks wie das Erkennen von Stimmungen, das Extrahieren von genannten Personen, Orten und Dingen und das Übersetzen von Dokumenten von einer Sprache in eine andere ausführen können. Sie können auch anhand eines Prompts interessanten Text in unterschiedlicher Qualität und Genauigkeit generieren. In jüngerer Zeit haben Forscher und Entwickler entdeckt, dass sehr große Sprachmodelle, die auf sehr großen und vielfältigen Textquellen "vortrainiert" wurden, "feinabgestimmt" werden können, um eine Vielzahl von Anweisungen eines Menschen zu befolgen und nützliche Informationen zu generieren.
Früher war es die bewährte Methode, für jede sprachbezogene Task separate Modelle zu trainieren. Der Prozess des Modelltrainings erforderte Ressourcen: kuratierte Daten, compute (in der Regel eine oder mehrere GPUs) und fortgeschrittene Kenntnisse in den Bereichen Data Science und Softwareentwicklung. Obwohl solche Modelle sehr genau sein können, gibt es bei der Skalierung ihrer Nutzung eindeutig Ressourcenbeschränkungen – sowohl in Bezug auf die Rechenleistung als auch auf den menschlichen Aufwand. Mit dem rasanten Aufstieg von ChatGPT sehen wir nun, dass ein einziges LLM – mit dem entsprechenden Kontext und dem richtigen Prompt – für viele verschiedene Aufgaben verwendet werden kann, manchmal sogar mit höherer Genauigkeit als ein spezialisierteres Modell. Und die Fähigkeit von LLMs, neuen Text zu generieren – „Generative KI“ – ist sowohl faszinierend als auch äußerst nützlich.
Wofür können LLMs im öffentlichen Sektor verwendet werden?
Organisationen des Privatsektors haben über erstaunliche Vorteile von LLMs berichtet, wie z. B. Codegenerierung und -migration, automatische Kategorisierung von Kundenfeedback und entsprechende Antworten, Callcenter-Chatbots, Berichtserstellung und vieles mehr. Als Mikrokosmos vieler verschiedener Branchen haben Behörden des öffentlichen Sektors die gleichen LLM-Möglichkeiten und darüber hinaus weitere einzigartige Anforderungen. Häufige Anwendungsfälle im öffentlichen Sektor sind:
- Unterstützung bei der Einhaltung gesetzlicher Vorschriften. Mit seiner Fähigkeit, Text zu interpretieren und zu verarbeiten, kann ein LLM bei der Ermittlung von Compliance-Anforderungen helfen, indem es regulatorische Dokumente, Rechtstexte und relevante Rechtsprechung analysiert. Es kann Behörden und Unternehmen dabei helfen, die Auswirkungen von Vorschriften zu verstehen und die Einhaltung der Gesetze sicherzustellen.
- Trainings- und Bildungsassistent. Skalieren und beschleunigen Sie das Lernen für Studierende, indem Sie als virtueller Dozent fungieren, Fragen beantworten, komplexe Konzepte erklären, relevante Teile von Vorlesungsaufzeichnungen abrufen oder Angebote aus dem Kurskatalog empfehlen.
- Zusammenfassen und Beantworten von Fragen aus technischen Dokumenten. Der vielleicht am weitesten verbreitete LLM-bezogene Anwendungsfall im öffentlichen Sektor besteht darin, Wissen aus Tausenden oder Millionen von Dokumenten, einschließlich PDFs und E-Mails, in ein Format zu extrahieren, das das schnelle Auffinden relevanter Inhalte anhand von Suchkriterien ermöglicht, um dann aus den relevanten Inhalten Zusammenfassungen oder Berichte zu generieren.
- Open-Source-Intelligence. LLMs können die Analyse von Open-Source-Intelligence (OSINT) durch die Intelligence Community erheblich verbessern, indem sie riesige Mengen an öffentlich verfügbaren, mehrsprachigen Informationen verarbeiten und analysieren. LLMs können Key-Entitäten, Beziehungen, Stimmungen und kontextbezogenes Verständnis aus unterschiedlichen Quellen wie Social Media, Nachrichtenartikeln und Berichten extrahieren, diese Informationen dann effizient zusammenfassen und organisieren und so Analysten dabei helfen, große Mengen an OSINT-Daten schnell zu verstehen und daraus Erkenntnisse zu gewinnen.
- Modernisierung von Legacy-Codebasen. Behörden verlagern weiterhin Daten-Workloads von Mainframes, on-premises Data Warehouses und proprietärer Analytics-Software. Indem Entwicklern und Analysten Programmierassistenten zur Verfügung gestellt werden, die während der Arbeit Code vorschlagen, oder durch das Training benutzerdefinierter LLMs zur Abwicklung von Massenkonvertierungen von Code, kann das Migrationstempo beschleunigt werden, während sich Wissens-Worker mühelos relevante Softwarekenntnisse aneignen.
- Personalwesen. Als größter Arbeitgeber des Landes steht die Bundesregierung vor einzigartigen Herausforderungen bei der Personalbeschaffung und der Gewährleistung der Mitarbeiterzufriedenheit. Der Einsatz von LLMs im Personalwesen kann zur Bewältigung dieser Herausforderungen beitragen, indem sie das Screening von Lebensläufen automatisieren, Kandidaten mit Stellenbeschreibungen abgleichen und Mitarbeiterfeedback analysieren, um die Einstellungsprozesse zu verbessern und das Engagement der Belegschaft zu erhöhen. Darüber hinaus können LLMs bei der Compliance mit HR-Richtlinien helfen, Initiativen für Vielfalt und Inklusion unterstützen und personalisierte Empfehlungen für das Onboarding und die Karriereentwicklung geben.
Wie wird Databricks die Bedürfnisse von Organisationen des öffentlichen Sektors in einer von LLMs angetriebenen Welt unterstützen?
Obwohl LLMs zweifellos leistungsstark sind, bringen sie auch eine Reihe neuer Herausforderungen mit sich, die durch einige der betrieblichen Einschränkungen, die für Organisationen des öffentlichen Sektors typisch sind, noch verstärkt werden. Lassen Sie uns einige davon genauer betrachten und sie auf die Funktionen des Databricks Lakehouse abstimmen:
Herausforderung Nr. 1: Datensouveränität und Governance
Die Herausforderung dabei?
Die meisten Organisationen des öffentlichen Sektors haben strenge regulatorische Kontrollen für ihre Daten. Diese Kontrollen dienen dem Datenschutz, der Sicherheit und in manchen Fällen der Notwendigkeit, die Geheimhaltung zu wahren. Schon die einfache Task, einem LLM eine oder mehrere Fragen zu stellen, könnte geschützte Information preisgeben. Darüber hinaus werden die meisten Bundesbehörden LLMs für ihre speziellen Anforderungen feintunen müssen. Aus diesen Gründen ist davon auszugehen, dass Behörden des öffentlichen Sektors bei der Nutzung öffentlicher Modelle eingeschränkt sein werden. Wahrscheinlich werden sie fordern, dass die Modelle in einer Umgebung einer Feinabstimmung unterzogen werden, die deren Vertraulichkeit und Sicherheit gewährleistet, und dass auch die Interaktionen mit den Modellen über verschiedene Prompting-Methoden vertraulich sind.
Databricks-Lösungen
Die Lakehouse-Plattform von Databricks bietet die notwendigen Tools, um End-to-End-LLM-Anwendungen zu entwickeln und bereitzustellen. (Mehr dazu später.) Darüber hinaus verfügt Databricks über die erforderlichen Zertifizierungen, um Daten für die große Mehrheit der Organisationen des öffentlichen Sektors in den USA zu verarbeiten. Databricks ist ein vertrauenswürdiger und kompetenter Partner für Organisationen, die das volle Potenzial von LLMs ausschöpfen möchten, ohne die Risiken, die durch die Nutzung proprietärer LLMs-as-a-Dienst wie ChatGPT oder Bard entstehen.
Über Databricks hinaus gibt es in der Branche zunehmend Belege dafür, dass Open-Source-LLMs – bei richtiger Anwendung – Ergebnisse liefern können, die nahezu an die der führenden proprietären LLMs heranreichen. Dies zeigt sich am deutlichsten in Anwendungsfällen, in denen proprietäre LLMs nuancierte Kontexte oder Anweisungen verstehen müssen, für die sie bisher nicht trainiert wurden. In diesen Fällen können Open-Source-LLMs durch Prompts oder Feinabstimmung auf organisationsspezifische Daten erstaunliche Ergebnisse liefern. Mit dieser Lösungsarchitektur können Unternehmen mit geringem compute- und Entwicklungsaufwand erstklassige Ergebnisse erzielen, ohne dass die Daten die genehmigten Grenzen verlassen. Für Organisationen des öffentlichen Sektors stellt dies einen erheblichen Vorteil dar, der nicht übersehen werden darf.
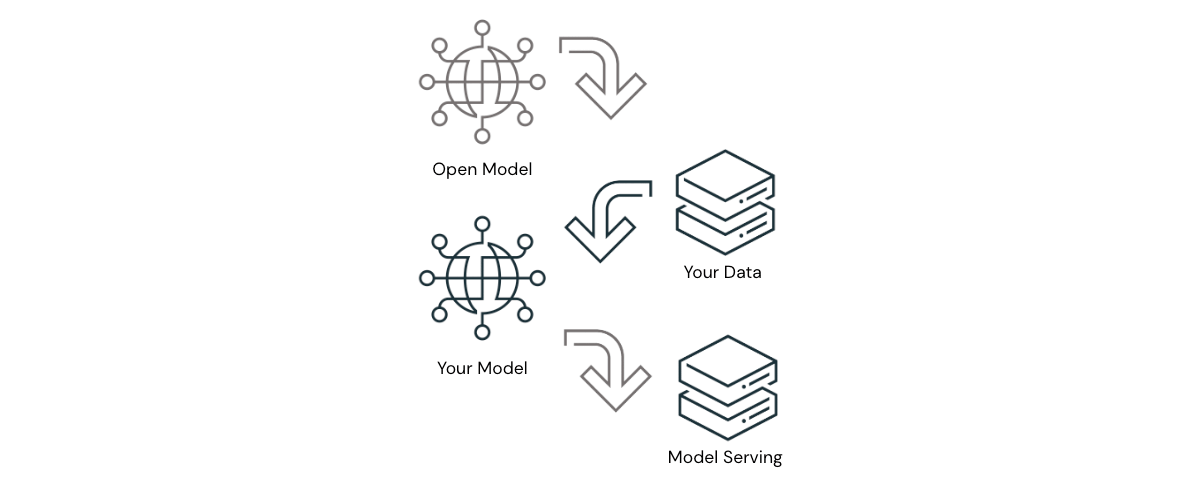
Die Überzeugung von Databricks von der Leistungsfähigkeit von Open Source LLMs wird durch die Veröffentlichung von Dolly 2.0 bekräftigt, dem ersten quelloffenen, anweisungsbefolgenden LLM, das auf einem von Menschen erstellten, für Forschung und kommerzielle Nutzung lizenzierten Anweisungs-Dataset feinabgestimmt wurde. Auf die Veröffentlichung von Dolly folgte eine Welle anderer leistungsfähiger Open Source-LLMs, von denen einige eine sehr beeindruckende Performance aufweisen. Databricks ist bestrebt, Organisationen des öffentlichen Sektors eine Plattform zum Erstellen von Anwendungen mit dem LLM ihrer Wahl – Open-Source oder kommerziell – bereitzustellen, und wir freuen uns auf die Zukunft.

Herausforderung Nr. 2: Architektonische Komplexität
Die Herausforderung dabei?
Die Modernisierung der Datenlandschaft hat für die meisten technischen Führungskräfte im öffentlichen Sektor weiterhin höchste Priorität. Die Zeiten von on-premises Data Warehouses sind größtenteils vorbei; sie werden typischerweise durch ein Data Warehouse oder Lakehouse in der Cloud ersetzt. Organisationen, die noch nicht in die Cloud migriert sind – oder die sich für ein Data Warehouse in der Cloud entschieden haben – stehen jetzt vor einem weiteren Wendepunkt: Wie können LLMs in einer Architektur eingeführt werden, die nicht dafür ausgelegt ist? Angesichts des immensen Potenzials von LLMs, die Missionen von Behörden und die sie erfüllenden Beamten zu beeinflussen, ist es entscheidend, eine zukunftssichere Architektur zu etablieren. Hier kommt das Lakehouse ins Spiel.
Databricks-Lösungen
Databricks ist seit langem eine leistungsstarke Plattform für Workloads des machine learning (ML) und der künstlichen Intelligenz (KI). Kunden nutzen seit Jahren produktionsreife LLMs und deren Vorgänger auf Databricks und profitieren dabei von Features wie:
- Skalierbare compute für die Vorverarbeitung von unstrukturierten Daten wie Text, Bildern und Audio
- Zugriff auf die gesamte Suite von Open-Source-Bibliotheken für ML/KI
- Eine native, erstklassige Notebook-Entwicklungsumgebung, die ebenfalls eine hervorragende Unterstützung für die IDE-Integration bietet
- Data-Governance-Funktionen über den Unity Catalog, die eine ordnungsgemäße Zugriffskontrolle gewährleisten
- Strukturierte Daten (Datenbanken und Tabellen)
- Unstrukturierte Daten (Dateien, Bilder, Dokumente)
- Modelle (LLMs oder andere)
- GPU-compute-Optionen für das Training von und die Vorhersagen aus ML-Modellen – jetzt eine Voraussetzung für die Arbeit mit transformatorbasierten LLMs
- End-to-End-Modelllebenszyklus-Management mit MLflow und Unity Catalog. Modelle werden als erstklassige Elemente behandelt, mit Herkunftsverfolgung zu ihren Quelldaten und Trainingsereignissen, und können entweder im Batch- oder Echtzeitmodus angewendet werden.
- Funktionen für das Model-Serving, die immer wichtiger werden, da Unternehmen ihre eigenen LLMs feinabstimmen, hosten und anwenden.
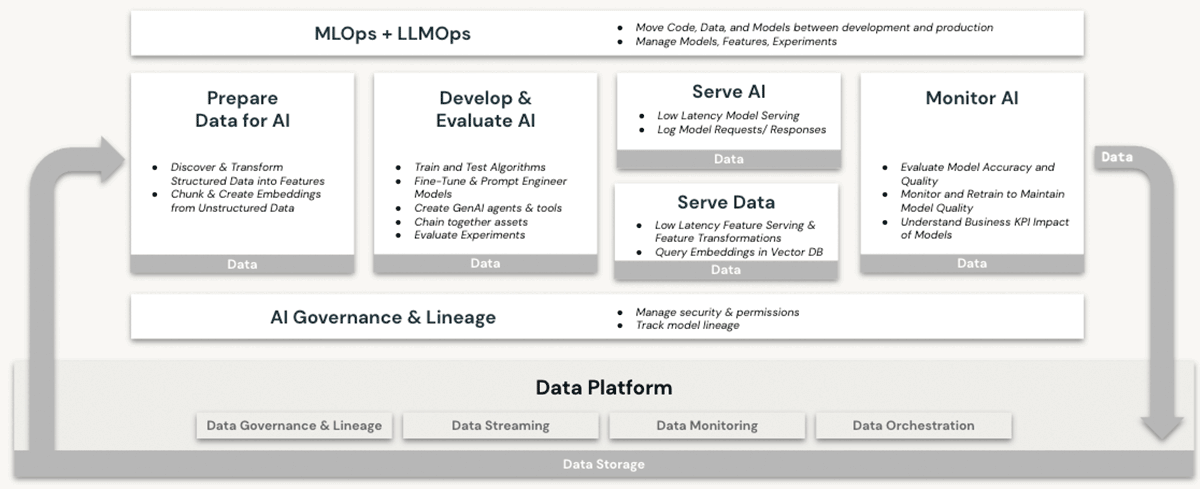
Keine dieser Funktionen wird in einem Data Warehouse angeboten, auch nicht in der Cloud. Um LLMs in Verbindung mit einem Data Warehouse zu verwenden, müsste ein Unternehmen andere Softwaredienste für alle Aspekte der Modelltrainings- und Bereitstellungsprozesse beschaffen und Daten zwischen diesen Diensten hin- und hersenden. Nur die Databricks Lakehouse-Architektur bietet die architektonische Einfachheit, alle LLM-Betriebe auf einer einzigen Plattform durchzuführen, und schöpft so die Vorteile, die in unserer obigen Diskussion zur Datensouveränität erläutert wurden, voll aus.
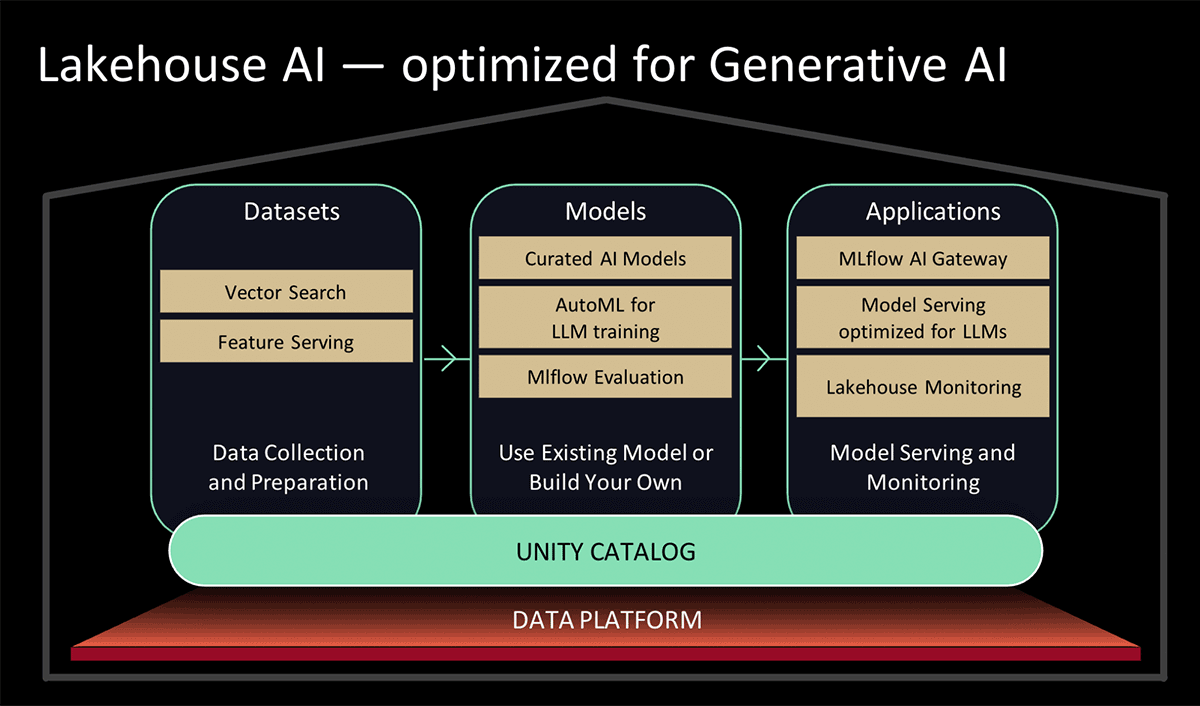
Auf dem Data and AI Summit 2023 hat Databricks Lakehouse AI vorgestellt, das mehrere wichtige neue LLM-bezogene Funktionen hinzufügt, die die Architektur für LLMOps erheblich vereinfachen, darunter:
- Vektorsuche zur Indizierung. Eine von Databricks gehostete Vektordatenbank hilft Teams dabei, die Daten ihrer Organisationen schnell als Embedding-Vektoren zu indizieren und Vektorähnlichkeitssuchen mit geringer Latenz in Echtzeit-Bereitstellungen durchzuführen.
- Lakehouse-Monitoring Der erste einheitliche Monitoring-Dienst für Daten und KI, mit dem Nutzer gleichzeitig die Qualität ihrer Daten und KI-Assets überwachen können.
- KI-Funktion. Datenanalysten und Dateningenieure können jetzt LLMs und andere Machine-Learning-Modelle innerhalb einer interaktiven SQL-Abfrage oder einer SQL/Spark-ETL-Pipeline verwenden.
- Einheitliche Daten- & KI-Governance. Verbesserungen am Unity Catalog, um eine umfassende Governance und Nachverfolgung der Datenherkunft (Lineage) von Daten- und KI-Assets in einer einzigen, einheitlichen Umgebung bereitzustellen.
- MLflow AI Gateway Das MLflow AI Gateway, Teil von MLflow 2.5, ist ein API-Gateway auf Workspace-Ebene, das Organisationen ermöglicht, Routen zu erstellen und zu teilen, die dann mit verschiedenen Ratenbegrenzungen, Caching, Kostenzuordnung usw. konfiguriert werden können, um Kosten und Nutzung zu verwalten.
- MLflow 2.4. Dieses Release bietet ein umfassendes Set an LLMOps-Tools für die Modellevaluierung
Herausforderung Nr. 3: Kompetenzlücke
Die Herausforderung dabei?
Regierungsbehörden haben in den letzten Jahren mit einem anhaltenden "Brain Drain" zu kämpfen, insbesondere in Bereichen, die sich mit aktuellen technologischen Trends wie Cybersicherheit, Cloud-Computing und ML/KI überschneiden. Der aktuelle starke Fokus auf LLMs treibt die Nachfrage nach talentierten Fachkräften im Bereich ML/KI noch weiter an. Unweigerlich werden der Reiz und die Vorteile, die mit einer Anstellung bei großen Technologieunternehmen und in der Startup-Szene einhergehen, den Fachkräftemangel im öffentlichen Sektor verschärfen. Führungskräfte im öffentlichen Sektor benötigen Zugang zu Plattformen und Partnerschaften, die ihnen helfen, LLMs einfach einzuführen und ihre Mitarbeiter zu befähigen, eigenständig damit zu arbeiten.
Databricks-Lösungen
Databricks rollt derzeit Features aus, die die bestehenden Möglichkeiten zur Arbeit mit LLMs auf der Lakehouse-Plattform vereinfachen und erweitern. Dazu gehören:
- Vereinfachte Muster für die Verwendung vortrainierter LLMs von Hugging Face für Inferenz-Tasks in Datenpipelines oder deren Feinabstimmung für eine bessere Performance mit Ihren eigenen Daten in Databricks.
- Vereinfachung des Prozesses und Verbesserung der Leistung beim Laden von Daten aus Apache Spark in Hugging Face für Modelltrainings- oder Feinabstimmungs-Jobs.
- Branchenspezifische LLM-Lösungsbeschleuniger, die wiederholbare Implementierungsmuster für schnelle Erfolge aufzeigen, wie z. B. Kundenservice-Analysen und Produktentdeckung
- Das Release MLflow 2.3 mit nativer LLM-Unterstützung, insbesondere:
- Drei brandneue Modellvarianten: Hugging Face Transformers, OpenAI-Funktionen und LangChain.
- Deutlich verbesserte Geschwindigkeit beim Download und Upload von Modellen zu und von Cloud-Diensten durch mehrteiliges Download und Upload von Modelldateien.
- Eine integrierte Databricks SQL-Funktion, mit der Benutzer direkt von SQL aus auf LLMs zugreifen können. Dieses Feature kann langwierige und komplexe Entwicklungsprozesse für Sprachmodelle umgehen, indem sie es Analysten ermöglicht, einfach effektive LLM-Prompts zu erstellen.
- Wie auf dem Data & KI Summit 2023 angekündigt,
- Erweiterungen für den UI-basierten AutoML-Dienst von Databricks, die das Fine-Tuning von LLMs für die Textklassifizierung sowie von Einbettungsmodellen ermöglichen; und
- Kuratierte Modelle, unterstützt durch optimiertes Model Serving für hohe Leistung. Anstatt Zeit mit der Recherche nach den besten generativen Open-Source-KI-Modellen für Ihren Anwendungsfall zu verbringen, können Sie sich auf Modelle verlassen, die von Databricks-Experten für gängige Anwendungsfälle kuratiert wurden.
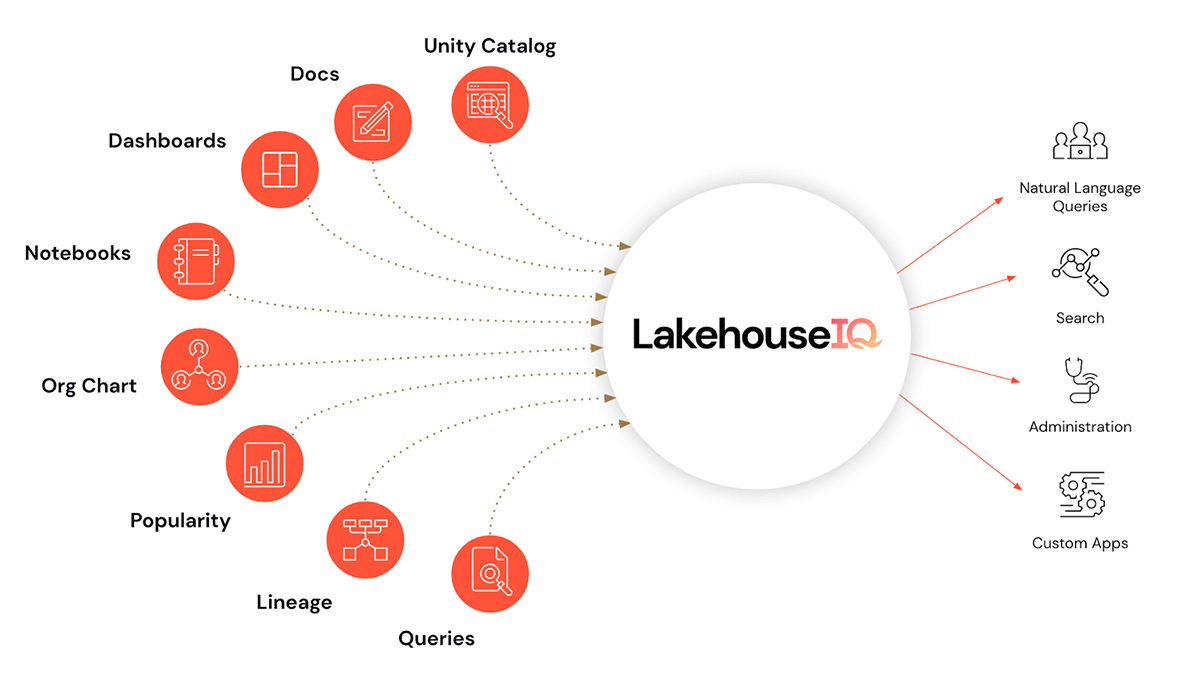
- Und als Sahnehäubchen gibt es LakehouseIQ, eine Wissens-Engine, die die einzigartigen Nuancen Ihres Unternehmens und Ihrer Daten erlernt, um für eine breite Palette von Anwendungsfällen den Zugriff darauf in natürlicher Sprache zu ermöglichen.
Zusätzlich dazu, dass wir die Nutzung von LLMs in Databricks vereinfachen, führen wir auch LLM-Schulungs- und Befähigungsprogramme ein, um Unternehmen bei der Skalierung ihrer LLM-Kompetenz zu unterstützen. Diese werden auf einem Niveau angeboten, das für Nutzer von Databricks aus dem öffentlichen Sektor verständlich ist.
- Partnerschaft mit EdX zur Bereitstellung von von Experten geleiteten Online-Kursen, die speziell auf die Entwicklung und Nutzung von Sprachmodellen in modernen Anwendungen ausgerichtet sind
Fazit und nächste Schritte
Es gibt zahlreiche Möglichkeiten, LLMs zu nutzen, um Anwendungsfälle im öffentlichen Sektor zu beschleunigen. In Altdaten ist ein enormer Wert vergraben, der nur darauf wartet, entdeckt und auf aktuelle Probleme angewendet zu werden. Erfahren Sie mehr darüber, wie Databricks Sie bei der Einführung von LLMs für Ihre Aufgaben unterstützen kann, indem Sie am 2. August um 12:00 Uhr (EDT) an unserem Webinar Large Language Models im öffentlichen Sektor teilnehmen. Sehen Sie sich auch die Anmeldungen für die Feature-Vorschau an, die in der Ankündigung zu Lakehouse AI aufgeführt sind, und prüfen Sie, für welche sich Ihre Organisation qualifiziert.
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.