LogSentinel: Wie Databricks Databricks für die LLM-gestützte PII-Erkennung und Governance nutzt
Ein tiefer Einblick in LogSentinel: Wie wir intern LLMs zur Automatisierung der PII-Erkennung und -Governance nutzen
- Wir verwenden LLMs auf Databricks, um sensible Daten in logs und Datenbanken automatisch zu erkennen und zu klassifizieren.
- Unser LogSentinel-System wendet eine hierarchische, residenzbewusste und multimodale Klassifizierung für ein präzises Label an – Techniken, die direkt in das Produkt zur Datenklassifizierung integriert werden.
- Durch die Vor-Labeling von Spalten und die kontinuierliche Erkennung von Labeling-Drift ermöglicht LogSentinel eine zuverlässige PII-Erkennung, eine automatisierte Durchsetzung von Richtlinien und wesentlich schnellere Compliance-Workflows im großen Scale.
Databricks arbeitet in einer Scale, in der sich unsere internen Logs und Datensätze ständig ändern – Schemata entwickeln sich weiter, neue Spalten kommen hinzu und die Datensemantik verschiebt sich. Dieser Blogbeitrag beschreibt, wie wir Databricks intern bei Databricks einsetzen, um sicherzustellen, dass PII und andere sensible Daten bei Änderungen unserer Plattform korrekt mit Label versehen bleiben.
Dafür haben wir LogSentinel entwickelt, ein LLM-gestütztes Datenklassifizierungssystem auf Databricks, das die Schemaentwicklung verfolgt, Kennzeichnungsabweichungen erkennt und hochwertige Kennzeichnungen in unsere Governance- und Sicherheitskontrollen einspeist. Wir verwenden MLflow, um Experimente zu verfolgen und die Leistung im Zeitverlauf zu überwachen. Zudem integrieren wir die besten Ideen aus LogSentinel wieder in das Produkt Databricks Data Classification, damit Kunden vom selben Ansatz profitieren können.
Warum dieses System wichtig ist
Dieses System wurde entwickelt, um drei konkrete Geschäftshebel für Plattform-, Daten- und Sicherheitsteams zu bewegen:
- Kürzere Compliance-Zyklen: Wiederkehrende Überprüfungs-Tasks, die zuvor wochenlange Analystenarbeit erforderten, werden jetzt in Stunden abgeschlossen, da die Spalten vorab mit Label versehen und vorsortiert werden, bevor sie von Menschen überprüft werden.
- Geringeres Betriebsrisiko: Das System erkennt kontinuierlich Label-Drift und Schemaänderungen, sodass sensible Felder seltener unbemerkt mit falschen oder fehlenden Tags durchrutschen.
- Stärkere Durchsetzung von Richtlinien: Zuverlässige Labels steuern jetzt direkt Maskierungs-, Zugriffskontroll-, Aufbewahrungs- und Residenzregeln und verwandeln das, was früher „Best-Effort-Governance“ war, in eine ausführbare Richtlinie.
In der Praxis können Teams neue Tabellen in eine Standard-Pipeline einbinden, Drift-Metriken und Ausnahmen überwachen und sich darauf verlassen, dass das System PII- und Residenzbeschränkungen durchsetzt, ohne für jede Domain einen maßgeschneiderten Klassifikator erstellen zu müssen.
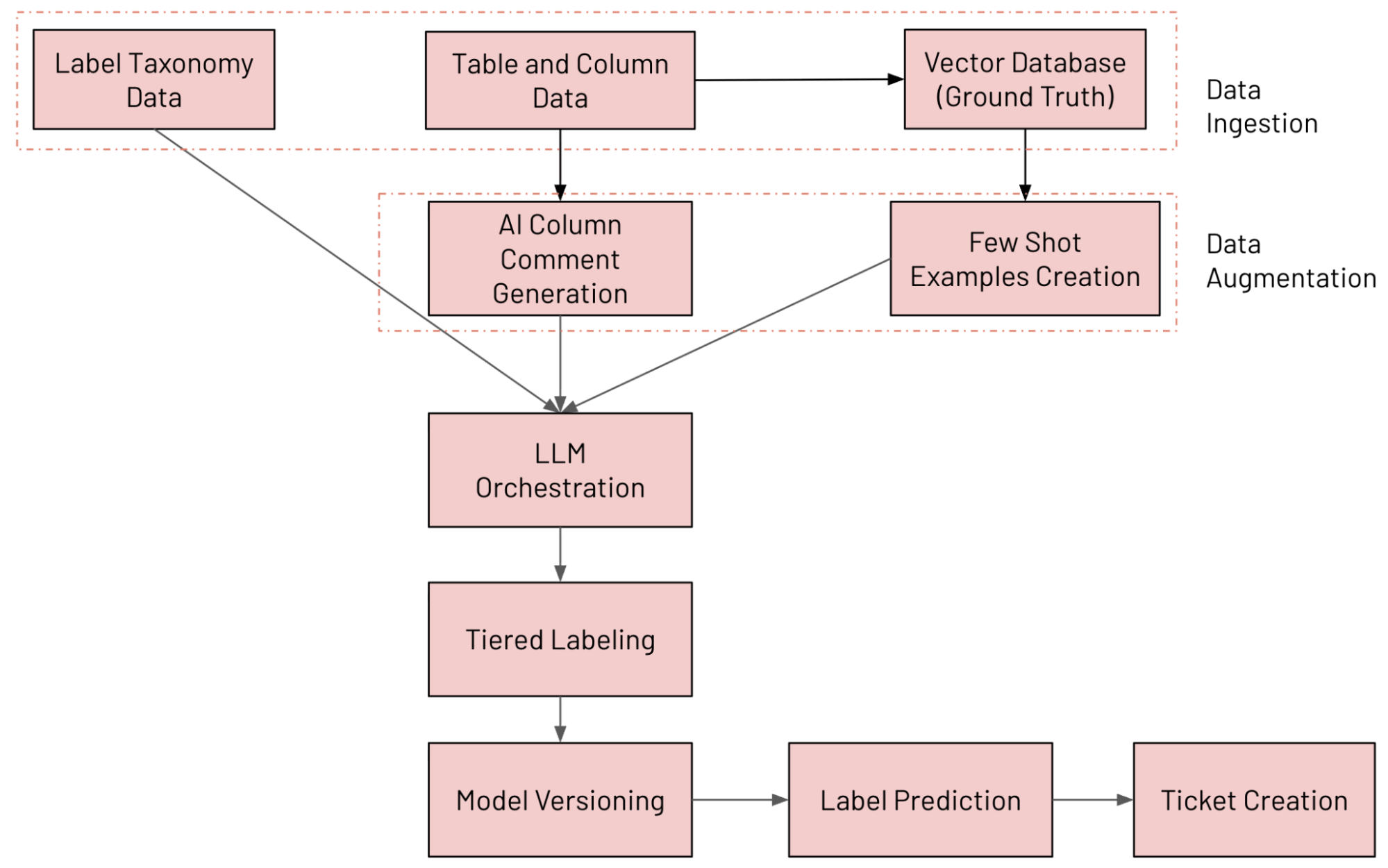
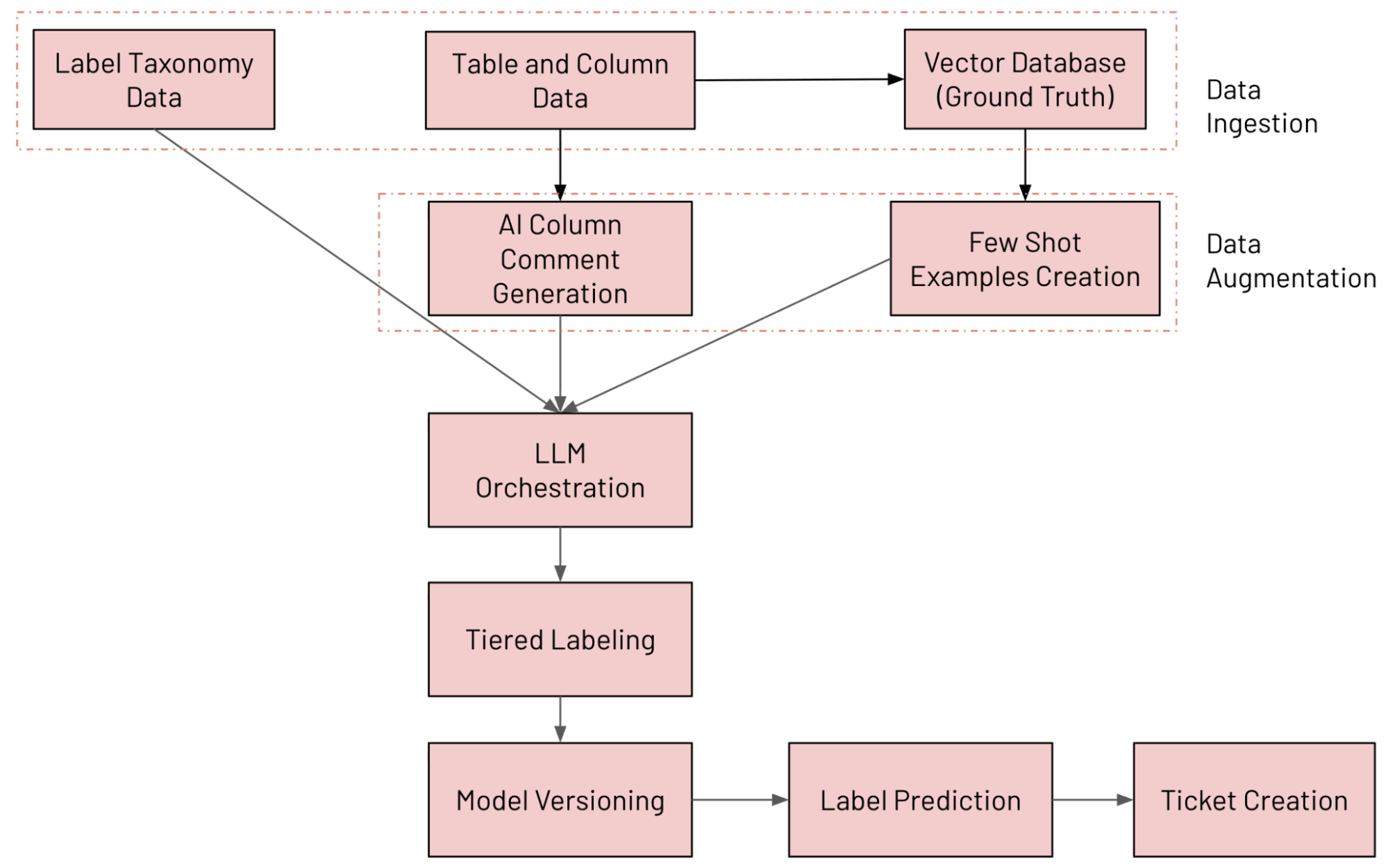
Systemarchitektur auf einen Blick
Wir haben auf Databricks ein LLM-gestütztes System zur Spaltenklassifizierung entwickelt, das Tabellen unter Verwendung unserer internen Datentaxonomie kontinuierlich annotiert, Labeling Drift erkennt und Behebungstickets eröffnet, wenn etwas nicht in Ordnung zu sein scheint. Die verschiedenen Komponenten des Systems sind nachfolgend aufgeführt (mit MLFlow verfolgt und evaluiert):
- Datenaufnahme: Erfassung verschiedener Datenquellen (einschließlich Spaltendaten aus dem Unity Catalog, Daten zur Kennzeichnungstaxonomie und Ground-Truth-Daten)
- Datenerweiterung: Erweiterung von Daten mit Databricks AI Search und der KI-Kommentargenerierung
- LLM-Orchestrierung
- Gestaffeltes Labeling-System
- Modellversionierung: Paralleles Ausführen mehrerer Modelle
- Label-Vorhersage: Vorhersage des endgültigen Labels mittels des Mixture-of-Experts-Ansatzes (MoE)
- Ticketerstellung: Erkennen von Verstößen und Erstellen von JIRA-Tickets
Der End-to-End-Workflow ist in der folgenden Abbildung dargestellt
{kind=link}
Datenaufnahme
Für jeden zu annotierenden Protokolltyp oder Dataset werden nach dem Zufallsprinzip Werte aus jeder Spalte als Stichprobe entnommen und die folgenden Metadaten an das System gesendet: Tabellenname, Spaltenname, Typ, vorhandener Kommentar und eine kleine Stichprobe von Werten. Um die LLM-Kosten zu senken und den Durchsatz zu verbessern, werden mehrere Spalten aus derselben Tabelle in einer einzigen Anfrage gebündelt.
Unsere Taxonomie wird mithilfe von Protocol Buffers definiert und umfasst derzeit mehr als 100 hierarchische Datenlabels, mit Raum für benutzerdefinierte Erweiterungen, wenn Teams zusätzliche Kategorien benötigen. Dies bietet Governance- und Plattform-Stakeholdern einen gemeinsamen Vertrag darüber, was „PII“ und „sensibel“ über eine Handvoll Regexes hinaus bedeuten.
Datenerweiterung
Zwei Augmentierungsstrategien verbessern die Klassifizierungsqualität erheblich:
- KI-gestützte Generierung von Spaltenkommentaren: Wenn Kommentare fehlen, verwenden wir KI-generierte Kommentare von Databricks, um prägnante, für Menschen lesbare Beschreibungen zu erstellen, die sowohl dem LLM als auch zukünftigen Tabellennutzern helfen.
- Few-Shot-Beispielgenerierung: Wir pflegen einen Ground-Truth-Datensatz und verwenden sowohl statische als auch dynamische Beispiele, die über die Vektorsuche abgerufen werden. Für jede Spalte erstellen wir eine Einbettung aus Name, Typ, Kommentar und Kontext und rufen dann die Top-K ähnlichsten gekennzeichneten Spalten ab, um sie in den Prompt aufzunehmen.
Statisches Prompting eignet sich am besten in frühen Phasen oder wenn nur begrenzt mit Label versehene Daten verfügbar sind, da es für Konsistenz und Reproduzierbarkeit sorgt. Dynamisches Prompting ist in ausgereiften Systemen effektiver und nutzt die Vektorsuche, um ähnliche Beispiele heranzuziehen und sich an neue Schemata und Datendomänen in großen, vielfältigen Datasets anzupassen.
LLM-Orchestrierung
Im Kern des Systems befindet sich eine schlanke Orchestrierungsschicht, die LLM-Aufrufe im Produktionsmaßstab verwaltet.
Zu den wichtigsten Funktionen gehören:
- Multi-Modell-Routing über intern gehostete LLMs (zum Beispiel Llama-, Claude- und GPT-basierte Modelle) mit automatischem Fallback, wenn ein Modell nicht verfügbar ist.
- Wiederholungslogik für vorübergehende Fehler und Ratenbegrenzungen mit exponentiellem Backoff.
- Validierungs-Hooks, die leere, ungültige oder halluzinierte Labels erkennen und diese Fälle mit Backup-Modellen erneut ausführen.
- Batch-Verarbeitung, die mehrere Spalten gleichzeitig annotiert, um die Token-Nutzung ohne Kontextverlust zu optimieren.
Gestaffeltes Labeling-System
Wir prognostizieren drei Arten von Labels pro Spalte:
- Granulare Labels, die aus einem Satz von über 100 feingranularen Optionen stammen, die Maskierung, Schwärzung und strikte Zugriffskontrollen ermöglichen.
- Hierarchische Labels, die verwandte granulare Labels in breitere Kategorien zusammenfassen, die sich für Monitoring und Reporting eignen.
- Residenzlabels, die angeben, ob Daten in der Region verbleiben müssen oder regionsübergreifend verschoben werden können, fließen direkt in die Richtlinien zur Datenverschiebung ein.
Um konsistente Vorhersagen zu gewährleisten und Halluzinationen zu reduzieren, verwenden wir einen zweistufigen Flow: Ein grober Klassifizierungsschritt weist eine übergeordnete Kategorie zu, woraufhin ein Verfeinerungsschritt das genaue Label innerhalb dieser Kategorie auswählt. Dies spiegelt wider, wie ein menschlicher Prüfer zuerst entscheiden würde: „Das sind Workspace-Daten“, und dann das spezifische Label für die Workspace-Kennung auswählen würde.
Modellversionierung und Labelvorhersage
Anstatt sich auf eine einzige „beste“ Konfiguration zu verlassen, wird jede Modellkonfiguration als Experte behandelt, der darum konkurriert, eine Spalte mit einem Label zu versehen.
Mehrere Modellversionen laufen parallel mit Unterschieden in:
- Primäre und Fallback-LLM-Auswahlmöglichkeiten.
- Verwendung von generierten Kommentaren im Vergleich zu rohen Metadaten.
- Prompting-Strategie (statisches vs. dynamisches Few-Shot).
- Label-Granularität und Taxonomie-Untermengen.
Jeder Experte erzeugt ein Label und einen Konfidenzwert zwischen 0 und 100. Das System wählt dann das Label von dem Experten mit der höchsten Konfidenz aus, ein Ansatz im Stil von Mixture-of-Experts, der die Genauigkeit verbessert und die Auswirkungen gelegentlicher schlechter Vorhersagen einer einzelnen Konfiguration reduziert.
Dieses Design ermöglicht sicheres Experimentieren: Neue Modelle oder Prompting-Strategien können eingeführt, parallel zu bestehenden in Ausführung gebracht und sowohl anhand von Metriken als auch am nachgelagerten Ticketaufkommen bewertet werden, bevor sie zum default werden.
Ticketerstellung
Die Pipeline vergleicht kontinuierlich aktuelle Schema-Annotationen mit LLM-Vorhersagen, um aussagekräftige Abweichungen aufzuzeigen.
Typische Fälle sind:
- Neu hinzugefügte Spalten ohne Annotationen.
- Bestehende Annotationen, die nicht mehr mit dem Inhalt der Spalte übereinstimmen.
- Spalten mit sensiblen Werten, die als für die regionenübergreifende Verschiebung geeignet mit Label versehenen wurden.
Wenn das System einen Verstoß erkennt, erstellt es einen Richtlinieneintrag und reicht ein JIRA-Ticket für das zuständige Team ein, das Kontext zur Tabelle, Spalte, zum vorgeschlagenen Label und zur Konfidenz enthält. Dadurch werden Probleme bei der Datenklassifizierung zu einem fortlaufenden Workflow, den Teams auf die gleiche Weise verfolgen und lösen können wie andere Produktionsvorfälle.
Auswirkungen und Evaluierung
Das System wurde an 2.258 mit Label versehenen Samples evaluiert, von denen 1.010 PII enthielten und 1.248 keine PII enthielten. Auf diesem Dataset erreichte es eine Präzision von bis zu 92 % und einen Recall von 95 % bei der PII-Erkennung.
Was für die Stakeholder noch wichtiger ist: Die Bereitstellung erbrachte die erforderlichen operativen Ergebnisse:
- Der manuelle Prüfaufwand für jeden großen Auditzyklus sank von Wochen auf Stunden, da die Prüfer von qualitativ hochwertigen Label-Vorschlägen statt von Rohschemata ausgehen.
- Labeling-Drift wird nun kontinuierlich erkannt, während sich Schemata weiterentwickeln, anstatt bei einer jährlichen Überprüfung entdeckt zu werden.
- Alerts zu sensiblen Daten, die fälschlicherweise als unbedenklich eingestuft wurden, sind zielgerichteter, sodass Sicherheitsteams schnell handeln können, anstatt die Ergebnisse rauschanfälliger regelbasierter Scanner sichten zu müssen.
- Maskierungs- und Residenzrichtlinien werden im großen Scale mithilfe derselben Label-Taxonomie durchgesetzt, die auch für Analytics und Berichte verwendet wird.
Precision und Recall dienen als Leitplanken, aber das System ist auf Ergebnisse wie Überprüfungszeit, Drifterkennung-Latenz und das Volumen der pro Woche erstellten, bearbeitbaren Tickets abgestimmt.
Fazit
Durch die Kombination von taxonomiegesteuertem Labeling und einem Evaluierungsframework im MoE-Stil haben wir bestehende Engineering- und Governance-Workflows bei Databricks ermöglicht, wobei Experimente und Deployments mit MLflow verwaltet werden. Es hält die Labels bei Schemaänderungen aktuell, macht Compliance-Prüfungen schneller und zielgerichteter und stellt die Enforcement-Hooks bereit, die benötigt werden, um Maskierungs- und Standortregeln plattformweit konsistent anzuwenden.
Der spannendste Teil dieser Arbeit ist die direkte Integration unserer internen Erkenntnisse in das Data Classification-Produkt. Während wir diese Techniken innerhalb von LogSentinel operationalisieren und validieren, integrieren wir unsere Techniken direkt in Databricks Data Classification.
Dasselbe Muster – Metadaten und Stichproben aufnehmen, Kontext erweitern, mehrere LLMs orchestrieren und Vorhersagen in Richtlinien- und Ticketsysteme einspeisen – kann überall dort wiederverwendet werden, wo ein zuverlässiges, sich entwickelndes Verständnis von Daten erforderlich ist. Indem wir diese Erkenntnisse in unser Kernproduktangebot integrieren, ermöglichen wir jeder Organisation, ihre Datenintelligenz für Compliance und Governance mit der gleichen Präzision und dem gleichen Scale zu nutzen, wie wir es bei Databricks tun.
Danksagung
Dieses Projekt wurde durch die Zusammenarbeit mehrerer Engineering-Teams ermöglicht. Dank an Anirudh Kondaveeti, Sittichai Jiampojamarn, Zefan Xu, Li Yang, Xiaohui Sun, Dibyendu Karmakar, Chenen Liang, Viswesh Periyasamy, Chengzu Ou, Evion Kim, Matthew Hayes, Benjamin Ebanks, Sudeep Srivastava für ihre Unterstützung und ihre Beiträge.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.