Der neue Weg zum Erstellen von Pipelines auf Databricks: Vorstellung der IDE für Data Engineering
Eine neue Entwicklererfahrung, die speziell für die Erstellung von Lakeflow Spark Declarative Pipelines entwickelt wurde
von Adriana Ispas, Lennart Kats, Camiel Steenstra und Monica Alvarez Vicente
- Spark Declarative Pipelines haben jetzt eine dedizierte IDE-Entwicklererfahrung im Databricks Workspace.
- Die neue IDE verbessert die Produktivität und das Debugging mit Funktionen wie Abhängigkeitsgraphen, Vorschauen und Ausführungseinblicken.
- Die IDE unterstützt sowohl schnelles Onboarding als auch fortgeschrittene Anwendungsfälle wie Git-Integration, CI/CD und Observability.
Auf der diesjährigen Data + AI Summit haben wir die IDE für Data Engineering vorgestellt: eine neue Entwicklungsumgebung, die speziell für die Erstellung von Datenpipelines direkt in der Databricks Workspace entwickelt wurde. Als neue Standard-Entwicklungsumgebung spiegelt die IDE unseren zielgerichteten Ansatz für Data Engineering wider: standardmäßig deklarativ, modular im Aufbau, Git-integriert und KI-gestützt.
Kurz gesagt, die IDE für Data Engineering ist alles, was Sie brauchen, um Datenpipelines zu erstellen und zu testen – alles an einem Ort.
Da diese neue Entwicklungsumgebung in der Public Preview verfügbar ist, möchten wir diesen Blogbeitrag nutzen, um zu erklären, warum deklarative Pipelines von einer dedizierten IDE-Erfahrung profitieren, und die wichtigsten Funktionen hervorzuheben, die die Pipeline-Entwicklung schneller, organisierter und einfacher zu debuggen machen.
Deklaratives Data Engineering erhält eine dedizierte Entwicklungsumgebung
Deklarative Pipelines vereinfachen Data Engineering, indem sie es Ihnen ermöglichen, zu deklarieren, was Sie erreichen möchten, anstatt detaillierte Schritt-für-Schritt-Anweisungen zu schreiben, wie Sie es aufbauen. Obwohl deklaratives Programmieren ein äußerst leistungsfähiger Ansatz für den Aufbau von Datenpipelines ist, kann die Arbeit mit mehreren Datensätzen und die Verwaltung des gesamten Entwicklungslebenszyklus ohne dedizierte Tools schwierig werden.
Deshalb haben wir eine vollständige IDE-Erfahrung für deklarative Pipelines direkt in der Databricks Workspace entwickelt. Verfügbar als neuer Editor für Lakeflow Spark Declarative Pipelines, ermöglicht er Ihnen, Datensätze und Qualitätsbeschränkungen in Dateien zu deklarieren, sie in Ordnern zu organisieren und die Verbindungen über einen automatisch generierten Abhängigkeitsgraphen anzuzeigen, der neben Ihrem Code dargestellt wird. Der Editor wertet Ihre Dateien aus, um den effizientesten Ausführungsplan zu ermitteln, und ermöglicht es Ihnen, schnell zu iterieren, indem Sie einzelne Dateien, eine Reihe von geänderten Datensätzen oder die gesamte Pipeline erneut ausführen.
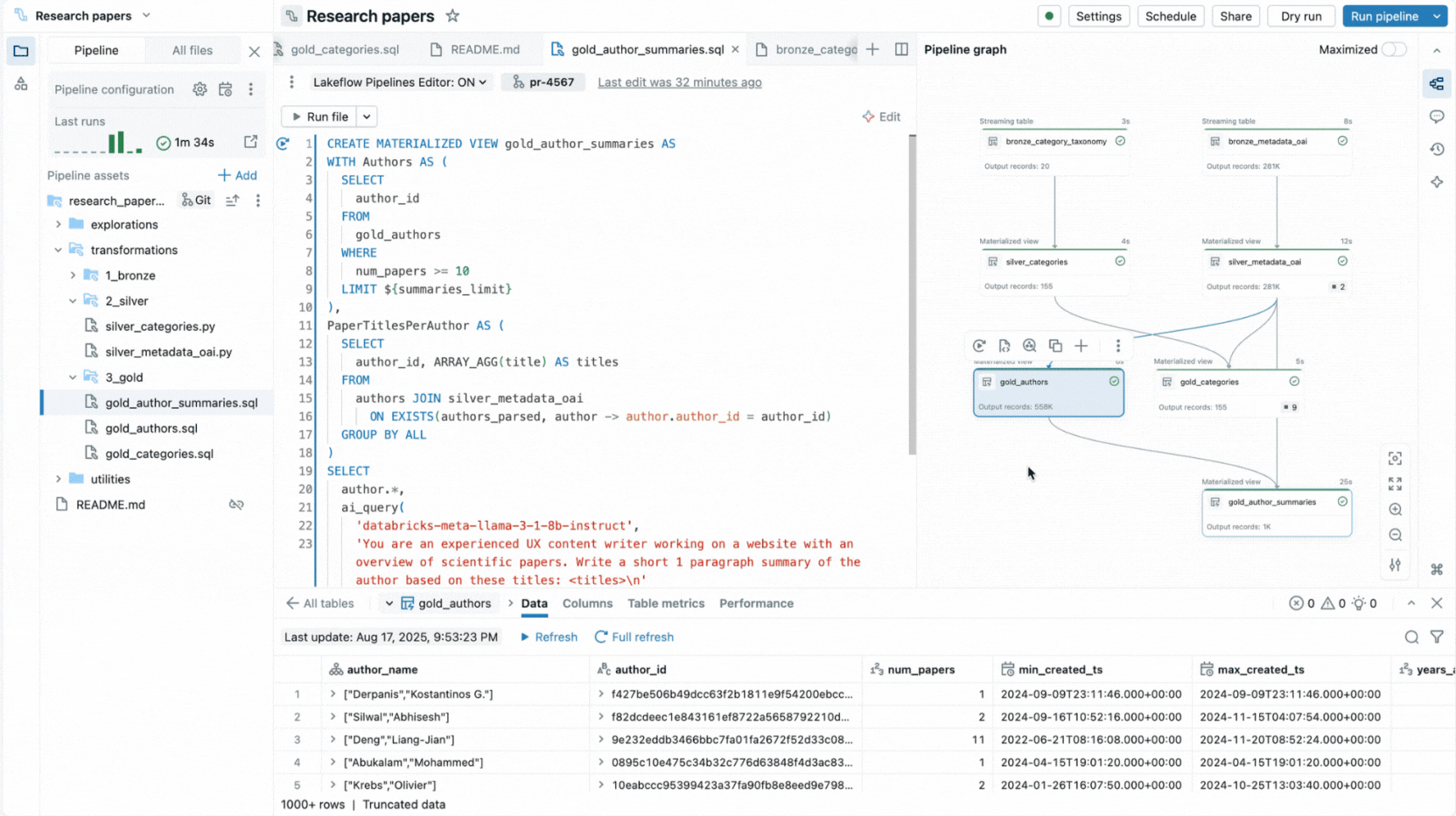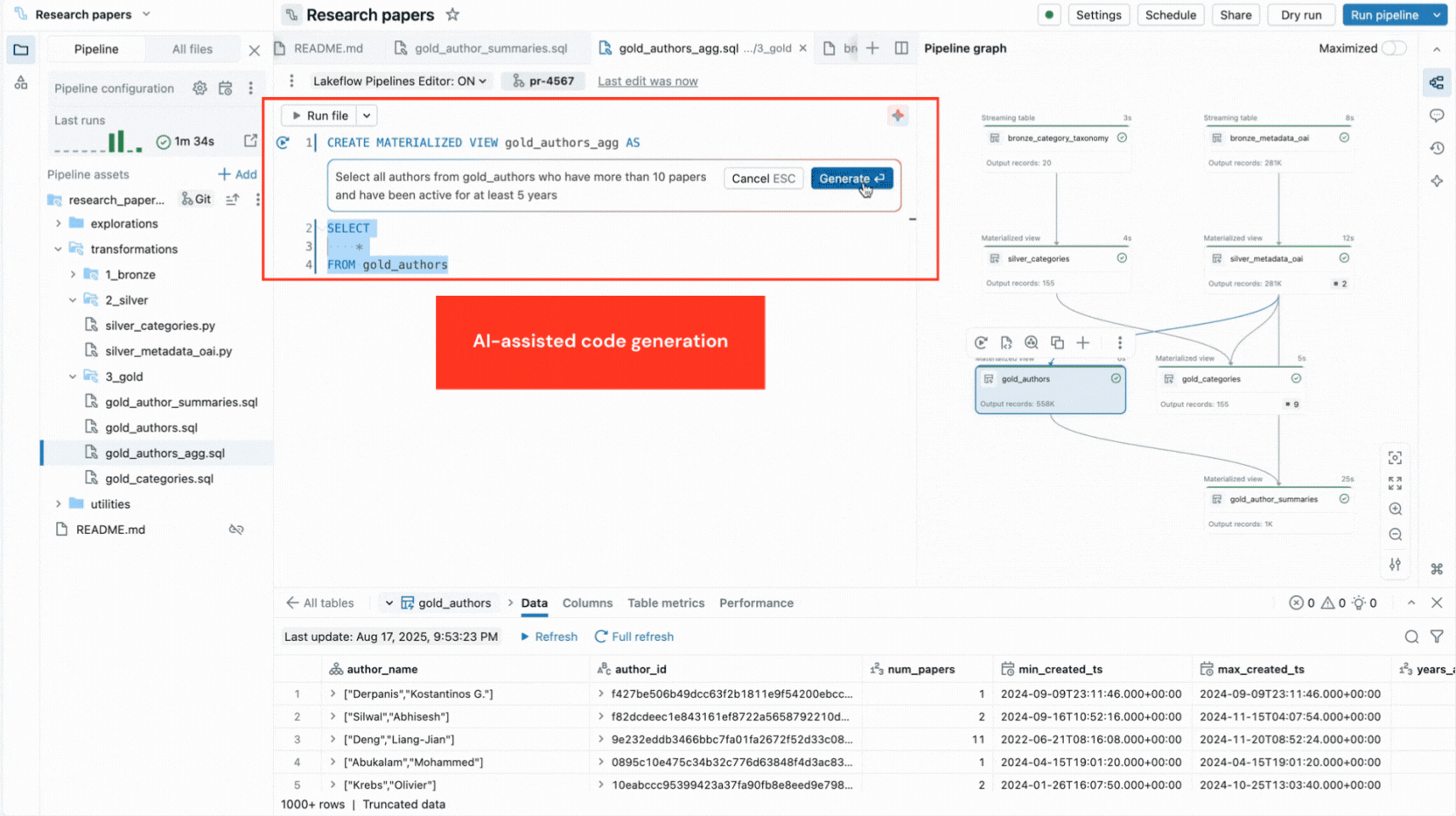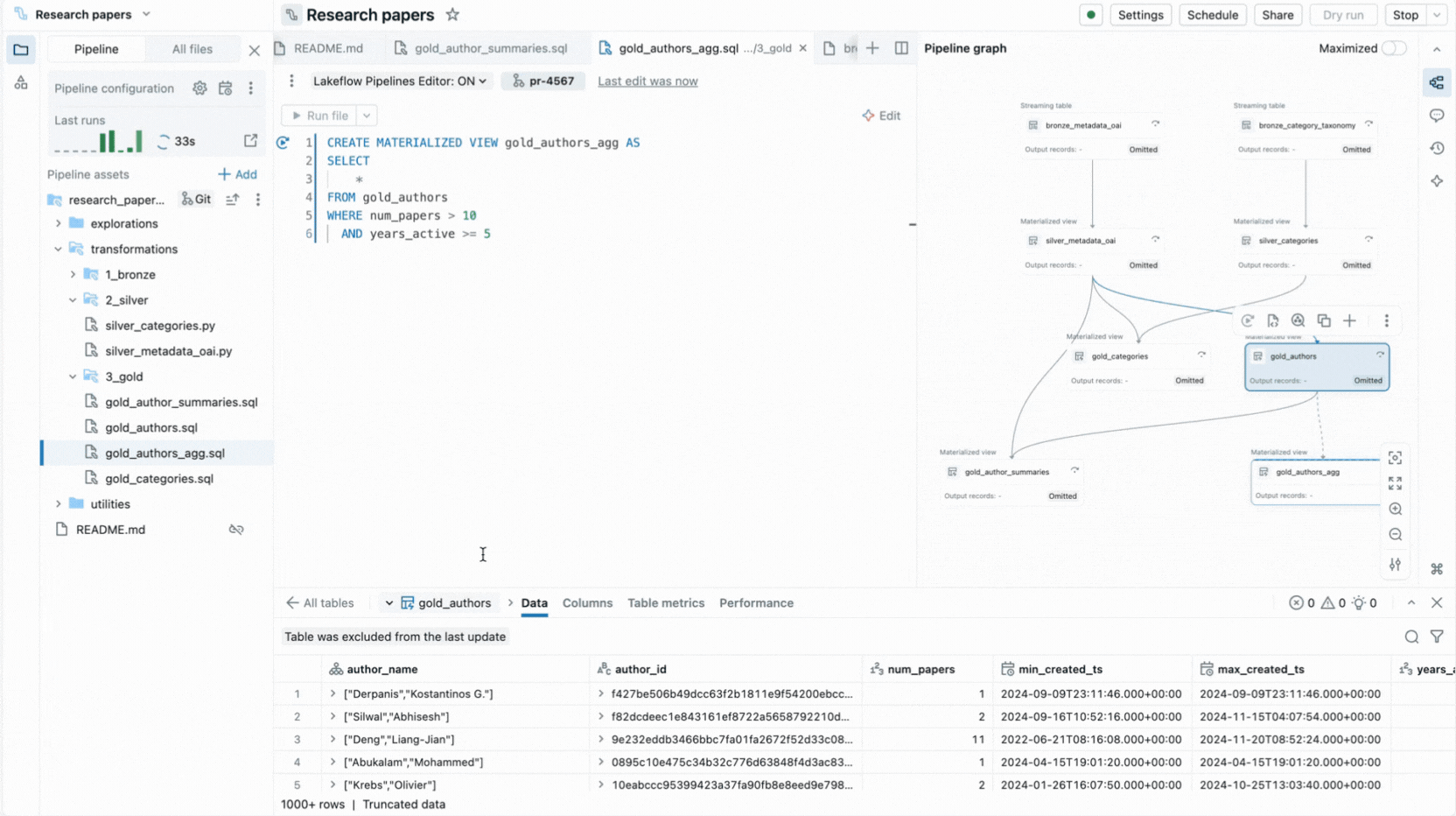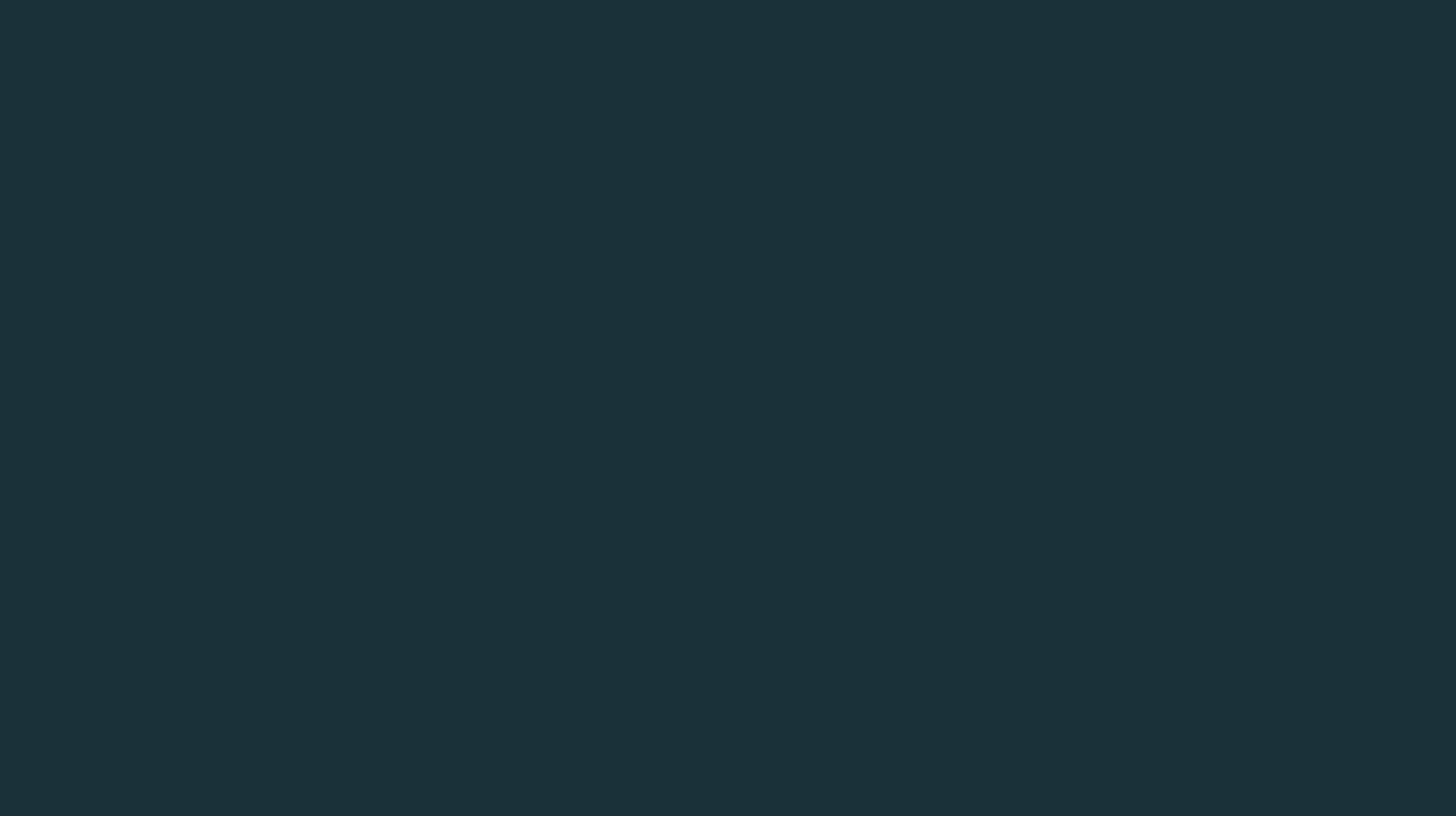
Der Editor zeigt auch Ausführungseinblicke, bietet integrierte Datenvorschau und enthält Debugging-Tools, die Ihnen helfen, Ihren Code zu optimieren. Er integriert sich auch mit Versionskontrolle und geplanter Ausführung mit Lakeflow Jobs. So können Sie alle Aufgaben im Zusammenhang mit Ihrer Pipeline von einer einzigen Oberfläche aus erledigen.
Durch die Konsolidierung all dieser Funktionen in einer einzigen IDE-ähnlichen Oberfläche ermöglicht der Editor die Praktiken und die Produktivität, die Data Engineers von einer modernen IDE erwarten, und bleibt dabei dem deklarativen Paradigma treu.
Das unten eingebettete Video zeigt diese Funktionen in Aktion, weitere Details werden in den folgenden Abschnitten behandelt.
"Der neue Editor bringt alles an einen Ort – Code, Pipeline-Graph, Ergebnisse, Konfiguration und Fehlerbehebung. Kein Jonglieren mehr mit Browser-Tabs oder Verlust des Kontexts. Die Entwicklung fühlt sich fokussierter und effizienter an. Ich kann die Auswirkungen jeder Codeänderung direkt sehen. Ein Klick bringt mich zur genauen Fehlerzeile, was das Debugging beschleunigt. Alles ist verbunden – Code zu Daten; Code zu Tabellen; Tabellen zum Code. Der Wechsel zwischen Pipelines ist einfach, und Funktionen wie automatisch konfigurierte Utility-Ordner reduzieren die Komplexität. Dies fühlt sich an, als ob die Pipeline-Entwicklung funktionieren sollte."—Chris Sharratt, Data Engineer, Rolls-Royce
"Meiner Meinung nach ist der neue Pipelines Editor eine enorme Verbesserung. Ich finde es viel einfacher, komplexe Ordnerstrukturen zu verwalten und dank der Multi-Soft-Tab-Erfahrung zwischen Dateien zu wechseln. Die integrierte DAG-Ansicht hilft mir wirklich, komplexe Pipelines im Griff zu behalten, und die verbesserte Fehlerbehandlung ist ein Gamechanger – sie hilft mir, Probleme schnell zu identifizieren und optimiert meinen Entwicklungs-Workflow."—Matt Adams, Senior Data Platforms Developer, PacificSource Health Plans
Einfacher Einstieg
Wir haben den Editor so gestaltet, dass auch Benutzer, die neu im deklarativen Paradigma sind, schnell ihre erste Pipeline erstellen können.
- Geführte Einrichtung ermöglicht es neuen Benutzern, mit Beispielcode zu beginnen, während bestehende Benutzer fortgeschrittene Setups konfigurieren können, wie z. B. Pipelines mit integriertem CI/CD über Databricks Asset Bundles.
- Vorgeschlagene Ordnerstrukturen bieten einen Ausgangspunkt für die Organisation von Assets, ohne starre Konventionen zu erzwingen, sodass Teams auch ihre eigenen etablierten Organisationsmuster implementieren können. Sie können beispielsweise Transformationen in Ordnern für jede Medallion-Stufe gruppieren, mit einem Datensatz pro Datei.
- Standardeinstellungen ermöglichen es Benutzern, ihren ersten Code ohne hohen anfänglichen Konfigurationsaufwand zu schreiben und auszuführen, und die Einstellungen später anzupassen, sobald ihre End-to-End-Workload definiert ist.
Diese Funktionen helfen Benutzern, schnell produktiv zu werden und ihre Arbeit in produktionsreife Pipelines zu überführen.
Effizienz in der inneren Entwicklungsschleife
Der Aufbau von Pipelines ist ein iterativer Prozess. Der Editor optimiert diesen Prozess mit Funktionen, die die Erstellung vereinfachen und das Testen und Verfeinern von Logik beschleunigen:
- KI-gestützte Code-Generierung und Code-Vorlagen beschleunigen die Definition von Code-Datensätzen und Datenqualitätsbeschränkungen und eliminieren repetitive Schritte.
- Selektive Ausführung ermöglicht es Ihnen, eine einzelne Tabelle, alle Tabellen in einer Datei oder die gesamte Pipeline auszuführen.
- Interaktiver Pipeline-Graph bietet einen Überblick über die Datensatzabhängigkeiten und bietet schnelle Aktionen wie Datenvorschau, erneute Ausführung, Navigation zum Code oder Hinzufügen neuer Datensätze mit automatisch generiertem Boilerplate-Code.
- Integrierte Datenvorschau ermöglicht es Ihnen, Tabellendaten zu inspizieren, ohne den Editor zu verlassen.
- Kontextbezogene Fehler erscheinen neben dem relevanten Code, mit vorgeschlagenen Korrekturen vom Databricks Assistant.
- Ausführungseinblick-Panels zeigen Datensatzmetriken, Erwartungen und Abfrageleistung an, mit Zugriff auf Query Profiles zur Leistungsoptimierung.
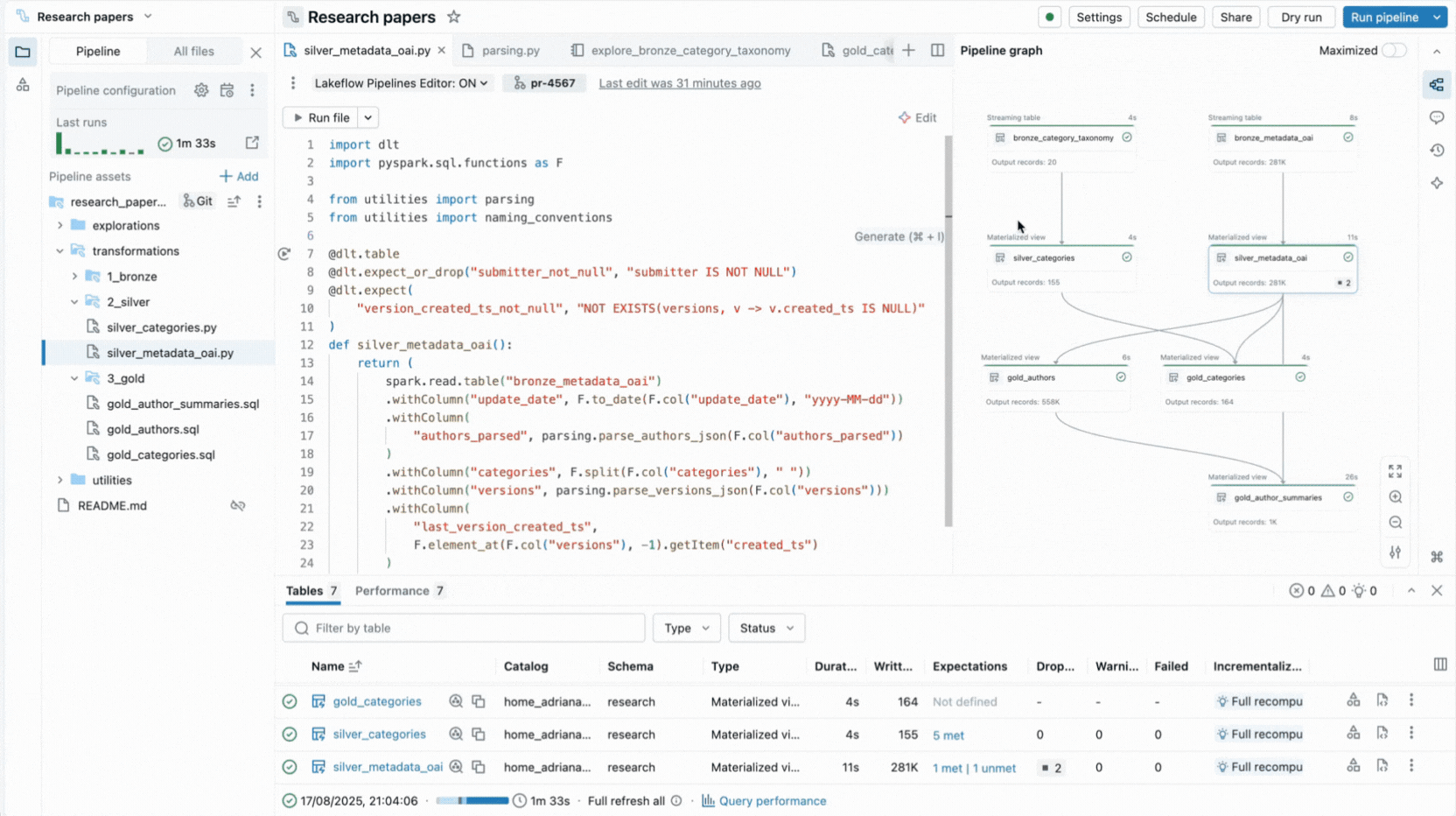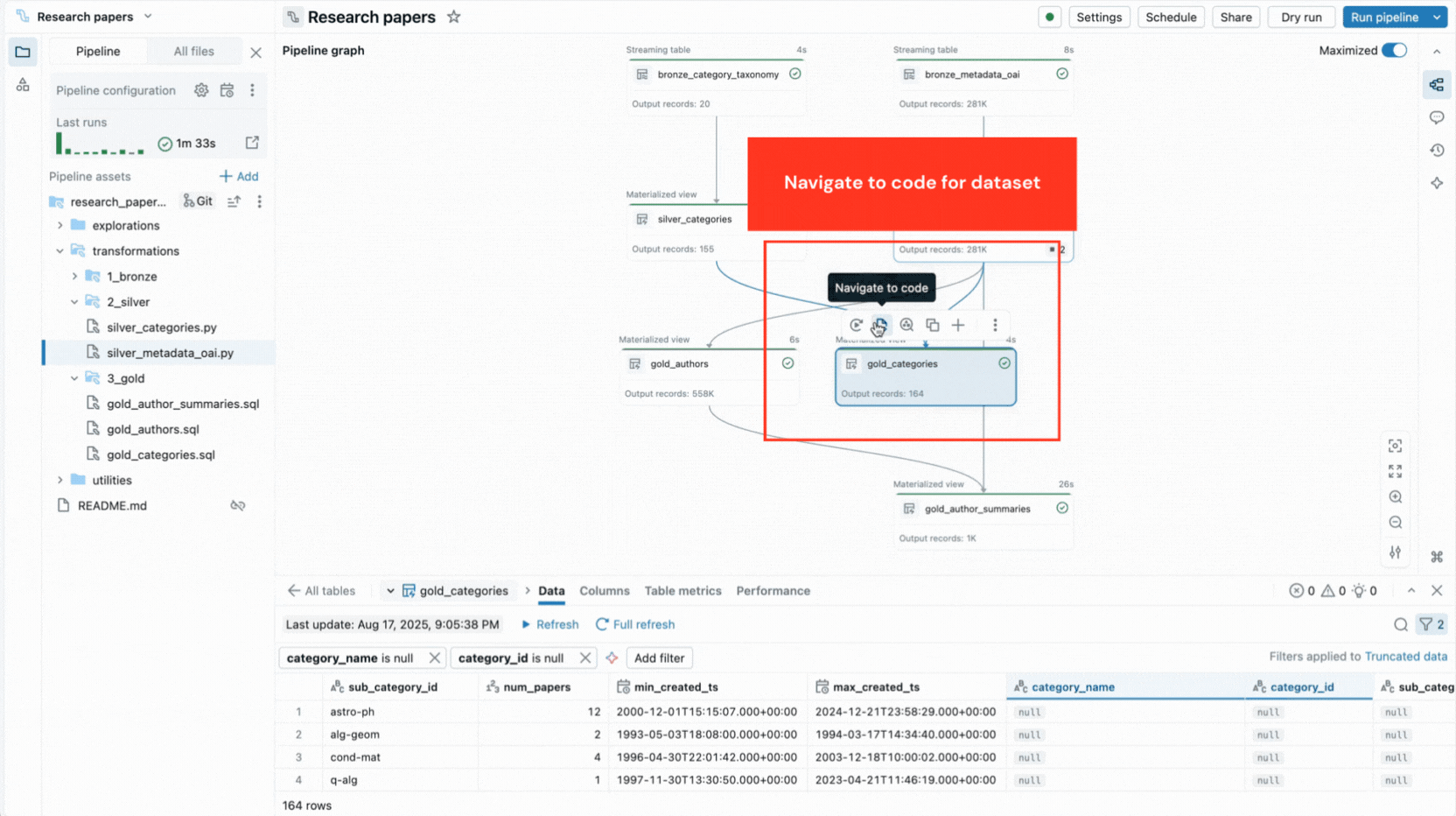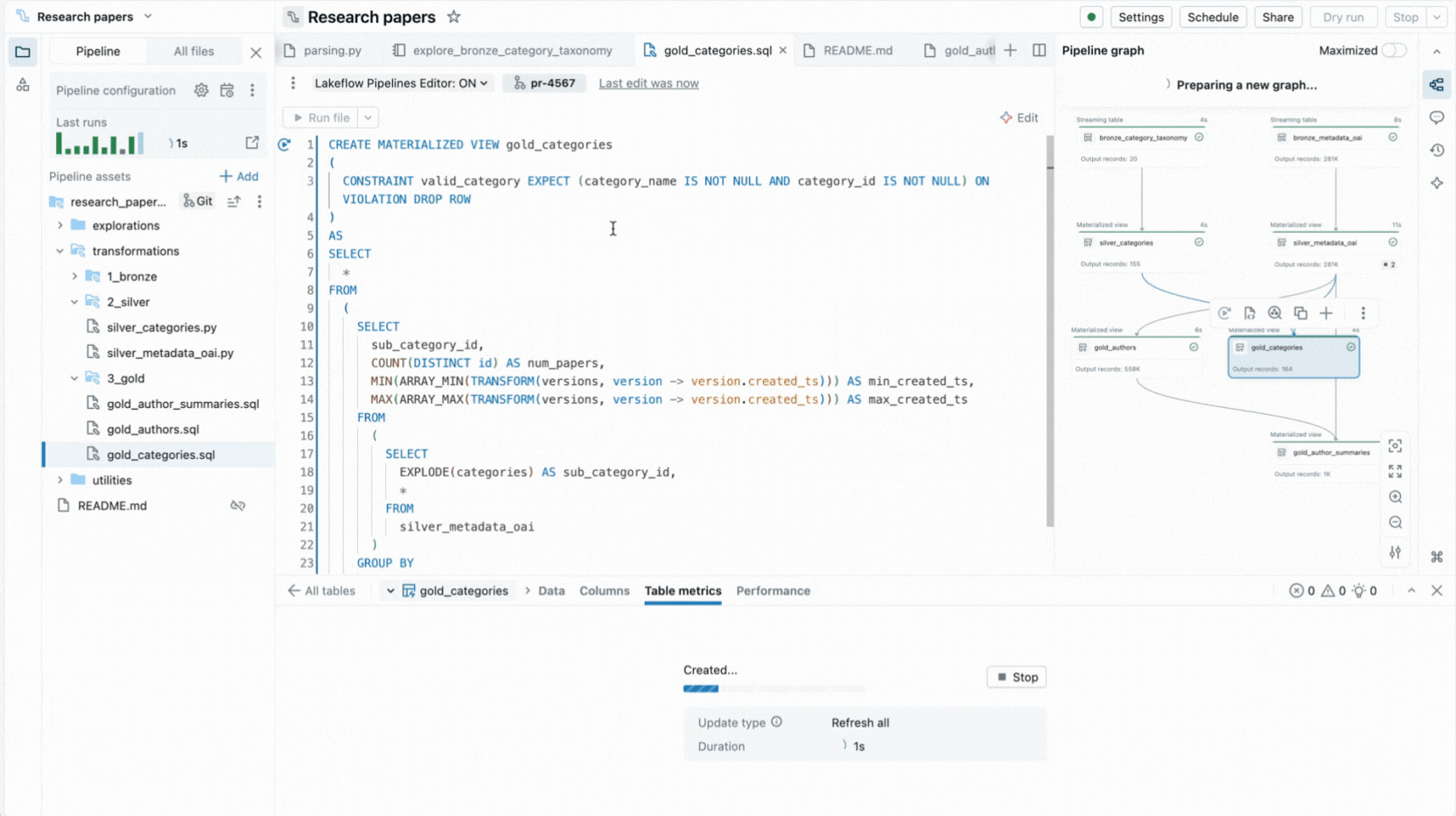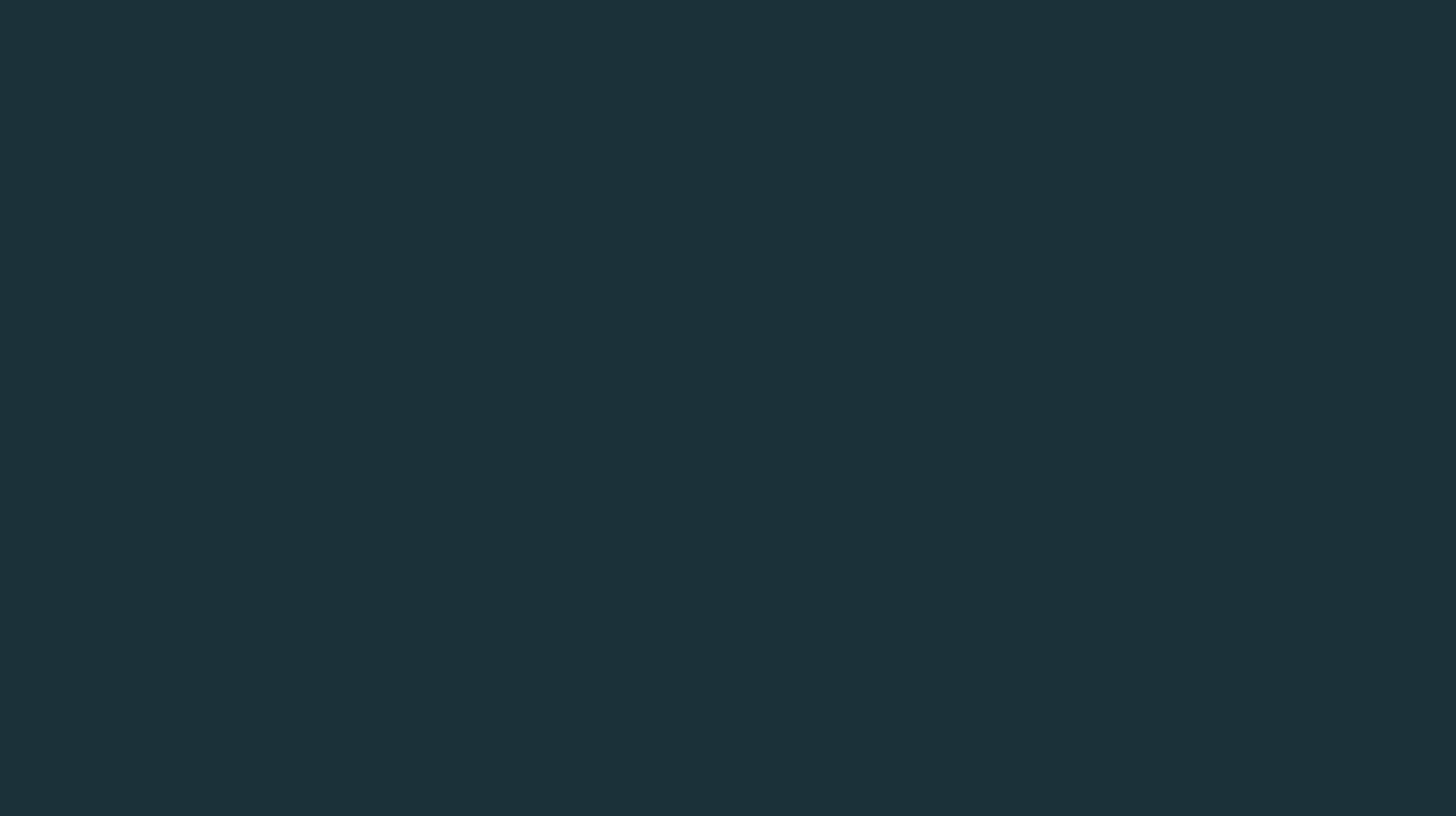
Diese Funktionen reduzieren den Kontextwechsel und halten Entwickler auf die Erstellung von Pipeline-Logik konzentriert.
Eine einzige Oberfläche für alle Aufgaben
Pipeline-Entwicklung ist mehr als nur Code schreiben. Die neue Entwicklungsumgebung bringt alle zugehörigen Aufgaben auf eine einzige Oberfläche, von der Modularisierung von Code für die Wartbarkeit bis hin zur Einrichtung von Automatisierung und Beobachtbarkeit:
- Organisieren Sie angrenzenden Code, wie explorative Notebooks oder wiederverwendbare Python-Module, in dedizierten Ordnern, bearbeiten Sie Dateien in mehreren Tabs und führen Sie sie separat von der Pipeline-Logik aus. Dies hält den zugehörigen Code auffindbar und Ihre Pipeline übersichtlich.
- Integrierte Versionskontrolle über Git-Ordner ermöglicht sicheres, isoliertes Arbeiten, Code-Reviews und Pull-Anfragen in gemeinsame Repositories.
- CI/CD mit Databricks Asset Bundles-Unterstützung für Pipelines verbindet die Entwicklung in der inneren Schleife mit der Bereitstellung. Datenadministratoren können Tests erzwingen und die Promotion zur Produktion mithilfe von Vorlagen und Konfigurationsdateien automatisieren, ohne die Arbeitsabläufe von Datenpraktikern zu verkomplizieren.
- Integrierte Automatisierung und Beobachtbarkeit ermöglichen die geplante Ausführung von Pipelines und bieten schnellen Zugriff auf vergangene Ausführungen zur Überwachung und Fehlerbehebung.
Durch die Vereinheitlichung dieser Funktionen optimiert der Editor sowohl die tägliche Entwicklung als auch den langfristigen Pipeline-Betrieb.
Sehen Sie sich das Video unten an, um weitere Details zu all diesen Funktionen in Aktion zu erhalten.
Was kommt als Nächstes
Wir hören hier nicht auf. Hier ist ein Vorschau auf das, was wir derzeit erforschen:
- Native Unterstützung für Datentests in Lakeflow Spark Declarative Pipelines und Testläufer im Editor
- KI-gestützte Testerstellung zur Beschleunigung der Validierung
- Agenten-Erfahrung für Lakeflow Spark Declarative Pipelines.
Lassen Sie uns wissen, was Sie sich sonst noch wünschen – Ihr Feedback bestimmt, was wir entwickeln.
Starten Sie noch heute mit der neuen Entwicklungsumgebung
Die IDE für Data Engineering ist in allen Clouds verfügbar. Um sie zu aktivieren, öffnen Sie eine Datei, die mit einer vorhandenen Pipeline verknüpft ist, klicken Sie auf das Banner 'Lakeflow Pipelines Editor: AUS' und schalten Sie sie ein. Sie können sie auch während der Pipeline-Erstellung mit einem ähnlichen Schalter oder auf der Seite Benutzereinstellungen aktivieren.
Erfahren Sie mehr mit diesen Ressourcen:
- Sehen Sie sich die Dokumentation an.
- Sehen Sie sich den Vortrag Authoring Data Pipelines With the New Editor auf dem Data + AI Summit 2025 an.
- Sehen Sie sich Lakeflow in Production: CI/CD, Testing and Monitoring at Scale auf dem Data + AI Summit 2025 an.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.