Open Sourcing Unity Catalog
Der branchenweit einzige universelle Katalog für Daten und KI
von Matei Zaharia, Ali Ghodsi, Reynold Xin, Arsalan Tavakoli-Shiraji und Patrick Wendell
Wir freuen uns, die Open-Source-Veröffentlichung von Unity Catalog bekannt zu geben, dem branchenweit ersten Open-Source-Katalog für Data- und KI-Governance über Clouds, Datenformate und Datenplattformen hinweg. Hier sind die wichtigsten Säulen der Unity Catalog-Vision:
- Open-Source-API und -Implementierung: Es basiert auf der OpenAPI-Spezifikation und einer Open-Source-Serverimplementierung unter der Apache 2.0-Lizenz. Es ist außerdem kompatibel mit der Metastore-API von Apache Hive und der REST-Katalog-API von Apache Iceberg.
- Unterstützung mehrerer Formate: Es ist erweiterbar und unterstützt Delta Lake, Apache Iceberg über UniForm, Apache Parquet, CSV und alle gängigen Formate.
- Unterstützung mehrerer Engines: Mit seinen offenen APIs kann Unity katalogisierte Daten von praktisch allen Compute-Engines gelesen werden.
- Multimodal: Es unterstützt alle Ihre Daten- und KI-Assets, einschließlich Tabellen, Dateien, Funktionen und KI-Modelle.
- Lebendiges Ökosystem: Dies ist eine Gemeinschaftsinitiative, und wir freuen uns außerordentlich über die Unterstützung von Amazon Web Services, Microsoft Azure, Google Cloud, Nvidia, Salesforce, DuckDB, LangChain, dbt Labs, Fivetran, Confluent, Unstructured, Onehouse, Immuta, Informatica und vielen anderen.
Das Projekt ist heute auf GitHub verfügbar, als erster Schritt auf unserem Weg, die Unity-Vision in Open Source zu überführen. Unity Catalog wird bei LF AI & Data gehostet, einer Dachorganisation der Linux Foundation, die Open-Source-Innovationen in den Bereichen künstliche Intelligenz (KI) und Daten unterstützt. Wir freuen uns darauf, in den kommenden Jahren mit den Open-Source-Communities zusammenzuarbeiten, um diese Vision zu verwirklichen.
Warum Open Source?
Angesichts der weit verbreiteten Akzeptanz von Unity Catalog fragen Sie sich vielleicht, warum wir es als Open Source veröffentlichen und warum gerade jetzt. Das liegt daran, dass wir von Organisationen immer wieder gehört haben, dass sie eine offene Grundlage für ihre Daten- und KI-Anwendungen benötigen, nicht nur für heute, sondern auch für die Innovationen der kommenden Jahrzehnte.
Leider sind die meisten heutigen Datenplattformen abgeschottete Systeme. Viele Cloud-Data-Warehouses verwenden "native Tabellen", die nicht in offenen Formaten vorliegen. Andere Plattformen verlangen von Kunden, dass sie für Always-on-Compute bezahlen, selbst wenn sie Daten von externen Engines lesen. Und viele Plattformen schränken die unterstützten Datenformate und Clients ein.
Dies führt zu Datensilos und fragmentierter Governance über Assets hinweg. Und ohne eine multimodale Schnittstelle über tabellarische Daten hinaus, ganz zu schweigen von KI-Assets, müssen Organisationen mehrere getrennte Lösungen miteinander verbinden. Databricks hat bereits eine starke Haltung in der Branche eingenommen, indem es als einzige große Plattform standardmäßig alle Tabellen in offenen Formaten anbietet und im letzten Jahr durch UniForm Delta-Tabellen für Iceberg-Clients geöffnet hat. Durch die Open-Source-Veröffentlichung von Unity Catalog geben wir Organisationen eine offene Grundlage für ihre aktuellen und zukünftigen Workloads.
Warum ein multimodaler Daten- und KI-Katalog?
In dieser Ära rasanter KI-Fortschritte hat jedes Unternehmen erkannt, dass es Daten- und KI-Assets gemeinsam verwalten muss – sei es die Verwaltung unstrukturierter Daten für komplexe KI-Systeme oder der Aufbau eines Katalogs von Tools für agentenbasierte LLM-Anwendungen. Bei Databricks erkannten wir diesen Bedarf an integrierter Daten- und KI-Infrastruktur frühzeitig und haben Unity Catalog vor drei Jahren eingeführt, um diese beiden Welten in einem konsistenten Governance-Modell zusammenzuführen. Heute sehen wir, wie Tausende von Kunden von der einheitlichen Governance profitieren, darunter:
- Ein einziger Namespace für die Organisation und gemeinsame Nutzung von Tabellen, unstrukturierten Daten und KI-Assets
- Zentralisierte Audit-Logs aller Daten- und KI-Aktivitäten
- Einheitliche Datenherkunft (Lineage) über Daten- und KI-Workloads hinweg
- Organisationsübergreifende Zusammenarbeit über das Open-Source-Delta-Sharing-Protokoll.
Unsere neuesten KI-Einführungen, wie das Konzept der Tool-Kataloge für generative KI-Agenten, sind ebenfalls darauf ausgelegt, in dieses einheitliche Governance-Modell zu passen.
Unity Catalog 0.1 Release
Heute veröffentlichen wir Version 0.1 des Open-Source-Unity-Catalog. Obwohl einige unserer APIs und Funktionen noch weiterentwickelt werden, zeigt diese Version mehrere wichtige Fähigkeiten von Unity Catalog:
- Tabellen, Volumes (unstrukturierte Daten) und KI-Tools/Funktionen können gemeinsam verwaltet werden.
- Tabellen können in mehreren Formaten vorliegen, einschließlich Delta Lake, Iceberg über UniForm, Parquet, CSV und JSON.
- Unity Catalog implementiert die Iceberg REST Catalog API für den Zugriff aus dem Iceberg-Engine-Ökosystem und nutzt dabei die Expertise von Tabular.
- Die API unterstützt das Vending von Anmeldeinformationen, um den Zugriff von Clients auf den zugrunde liegenden Cloud-Speicher für Tabellen und Volumes zu steuern und die Governance im Katalogserver zu zentralisieren.
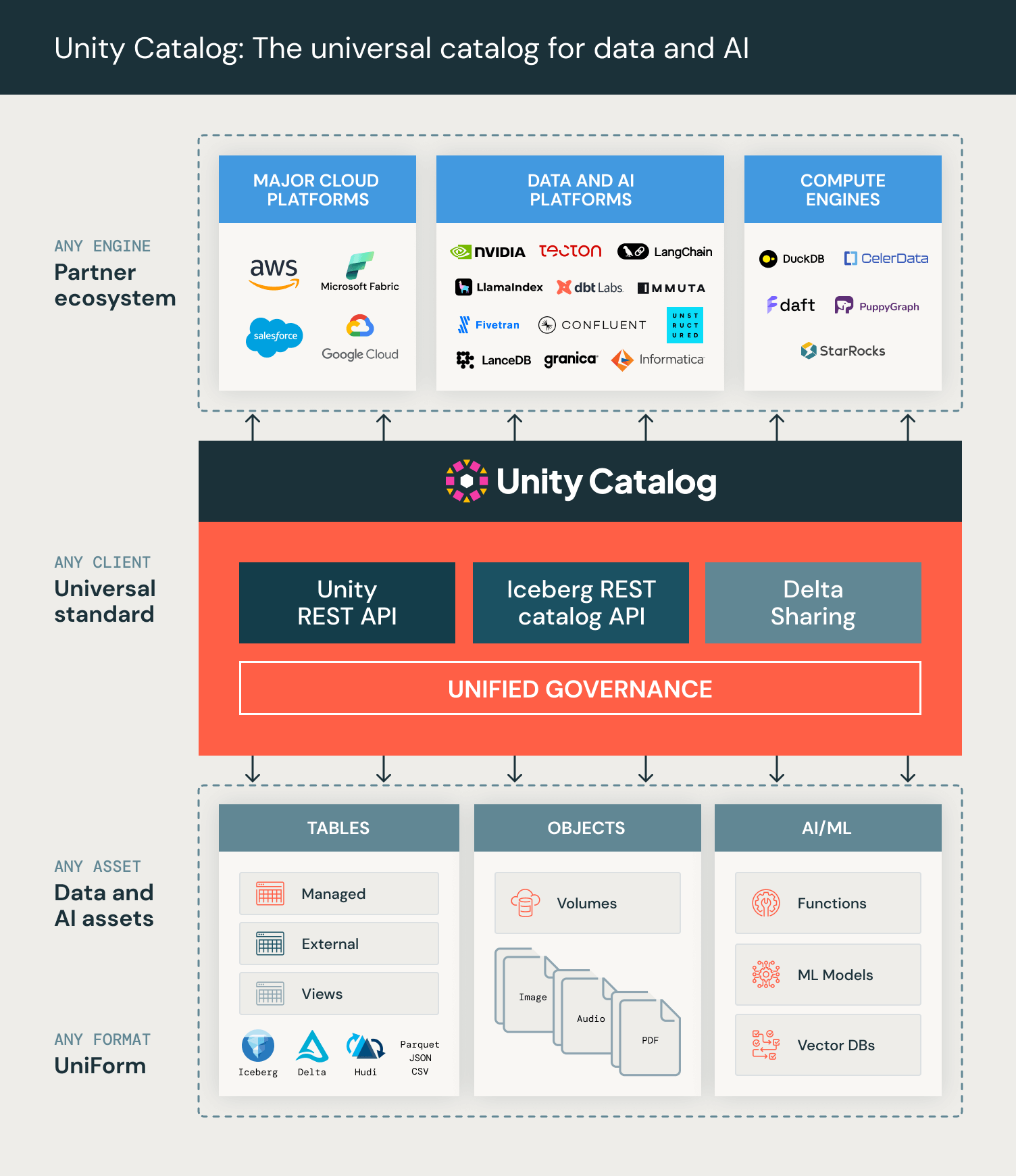
Was das für Databricks-Kunden bedeutet
Wenn Sie bereits Databricks-Kunde sind, müssen Sie nichts ändern. Die bestehenden Unity Catalog-Bereitstellungen der Kunden implementieren dieselben offenen APIs – und ermöglichen es externen Clients, ab dem ersten Tag von allen Tabellen (einschließlich verwalteter und externer Tabellen), Volumes und Funktionen im gehosteten Unity Catalog mit Ihren bestehenden Zugriffskontrollen zu lesen. Diese Änderung bedeutet einfach, dass ein größeres Ökosystem von Clients mit Ihrem bestehenden Katalog funktioniert.
Unity REST APIs ermöglichen es unseren Partnern und der Open-Source-Community, leistungsstarke Integrationen zu entwickeln, die es Kunden ermöglichen, mit ihren Tabellen, unstrukturierten Daten und KI-Tools/-Funktionen aus verschiedenen Anwendungen zu arbeiten, ohne externe Zugriffsgebühren.
"AT&T verpflichtet sich, unsere Daten mit unseren Plattformen interoperabel zu machen. Mit der Ankündigung der Open-Source-Veröffentlichung von Unity Catalog sind wir durch den Schritt von Databricks ermutigt, Lakehouse-Governance und Metadatenmanagement durch offene Standards zu ermöglichen. Die Flexibilität, interoperable Tools mit unseren Daten- und KI-Assets zu nutzen, mit konsistenter Governance, ist Kernstück der Datenplattformstrategie von AT&T."
— Matt Dugan, Vice President Data Platforms, AT&T
![]()
"Nasdaq ist stolz darauf, den Unity Catalog von Databricks als Teil unserer ganzheitlichen Datenmanagementstrategie zu nutzen. Die Entscheidung von Databricks, Unity Catalog als Open Source zu veröffentlichen, bietet eine Lösung, die dazu beiträgt, Datensilos zu beseitigen, und wir freuen uns darauf, unsere Plattform weiter zu skalieren, unsere Governance zu verbessern und unsere Datenanwendungen zu modernisieren, während wir weiterhin für unsere Kunden liefern."
— Lenny Rosenfeld, Vice President, Capital Access Platforms, Nasdaq
![]()
"Bei Rivian hat die Einführung der Databricks-Plattform uns die Möglichkeit gegeben, Daten und KI beim Aufbau unserer EAVs der nächsten Generation zu nutzen. Wir freuen uns über die Open-Source-Veröffentlichung von Unity Catalog durch Databricks und die Bereitstellung von Open APIs, um Interoperabilität über unsere Datenlandschaft hinweg ohne Bedenken hinsichtlich Vendor Lock-ins zu ermöglichen. In Kombination mit der Unterstützung für alle unsere Daten-Assets – strukturierte und unstrukturierte Daten, ML-Modelle und Gen AI-Tools – war es eine einfache Entscheidung, uns auf Unity Catalog zu standardisieren."
— Jason Shiverick, Director of AI Platforms, Rivian
![]()
Open-Source-Ökosystem
Wir freuen uns auf die Partnerschaft mit führenden Cloud-Anbietern, Daten- und KI-Plattformen sowie Compute-Engines, um den Unity Catalog-Standard in den kommenden Monaten weiterzuentwickeln. Dazu gehören führende Softwareanbieter und Open-Source-Projekte in den Bereichen KI, Datenanalyse, unstrukturierte Daten und Governance, die sich problemlos mit Open-Source-Unity-Catalog-Servern und Databricks verbinden können.
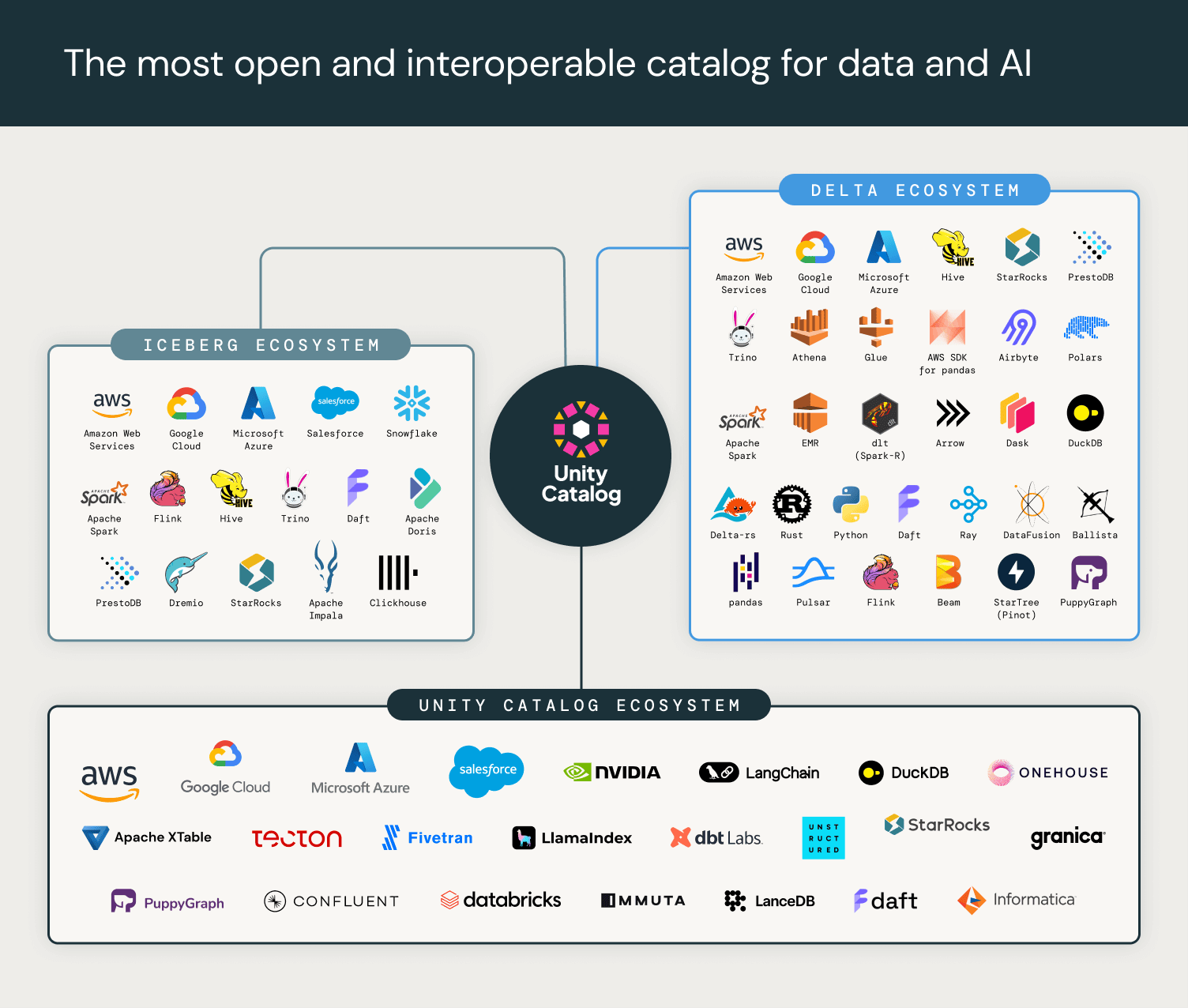
"AWS begrüßt den Schritt von Databricks, Unity Catalog als Open Source zu veröffentlichen. AWS ist bestrebt, mit der Branche an Open-Source-Lösungen zu arbeiten, die den Kunden Wahlmöglichkeiten und Interoperabilität ermöglichen."
— Chris Grusz, Managing Director of Technology Partnerships, AWS
![]()
"Microsoft engagiert sich für die Open-Source-Community und befähigt Kunden mit Wahlmöglichkeiten. Databricks ist seit Jahren ein strategischer Partner, und es ist großartig zu sehen, dass sie Unity Catalog als Open Source veröffentlichen. Wir glauben, dass wirklich offene Standards mit breiter Branchenbeteiligung im besten Interesse der Kunden sind. Unsere Zusammenarbeit mit Databricks hebt Microsoft Azure weiterhin als die beste Wahl für Daten- und KI-Workloads hervor."
— Jessica Hawk, CVP Data, AI and Digital Applications, Microsoft
![]()
"Google engagiert sich für offene, flexible Lösungen, die es Kunden ermöglichen, den Wert ihrer Daten zu maximieren. Die Strategie von Databricks, den Unity Catalog-Standard für Daten und KI zu öffnen, passt sehr gut zu unserer Strategie."
— Ritika Suri, Director, Data and AI Technology Partnerships, Google Cloud
![]()
Roadmap für die Zukunft
Dies ist nur der Anfang für das Open-Source-Projekt Unity Catalog. Unity Catalog wird von Tausenden von Kunden im produktiven Einsatz genutzt und ist das Ergebnis jahrelanger Entwicklungsarbeit. Daher portieren wir diese Funktionalität schrittweise in das Open-Source-Projekt, wobei wir zunächst den Zugriff und die Client-Interoperabilität priorisieren.
In den kommenden Monaten werden wir die Unterstützung für die APIs, die für Ihre Daten- und KI-Workloads entscheidend sind, erweitern, darunter:
- Formatunabhängige Tabellen-Schreib-APIs
- Views
- Delta Sharing
- Modelle (mit MLflow-Integration)
- Remote-Funktionen
- Zugriffskontroll-APIs
- Und mehr
Starten Sie noch heute
Sie können der Unity Catalog Open-Source-Community unter unitycatalog.io beitreten. Databricks-Kunden sollten die Augen offen halten für das sich schnell entwickelnde Ökosystem von Daten- und KI-Tools, die sich in Unity Catalog integrieren.
"Salesforce Data Cloud basiert vollständig auf offenen Standards mit Apache Parquet und Apache Iceberg. Unsere Zero-Copy-Innovationen ermöglichen es Kunden, Daten zu erschließen, Erkenntnisse zu gewinnen und Aktionen über Customer 360 zu orchestrieren. Databricks' Übernahme von Apache Iceberg über UniForm und Unity Catalog adressiert wichtige Interoperabilitätsprobleme zwischen Delta Lake und Iceberg. Wir freuen uns, Databricks als Mitglied unseres Zero Copy Partner Network begrüßen zu dürfen und freuen uns auf gemeinsame Innovationen mit dem neuen offenen Unity Catalog, um überzeugenden Kundennutzen bei strukturierten Daten, unstrukturierten Daten und KI-Modellen zu liefern."
— Ravi Loganathan, Executive Vice President of Software Engineering, Salesforce
![]()
"Unternehmensdaten sind entscheidend für die Entwicklung genauer generativer KI-Anwendungen. NVIDIA arbeitet eng mit unserem Partner-Ökosystem zusammen, um Open-Source-Angebote wie Unity Catalog zu unterstützen, die Kunden helfen können, effiziente und leistungsstarke Entwicklungspipelines zu kuratieren."
— Pat Lee, VP of Strategic Enterprise Partnerships, NVIDIA
![]()
"Delta Kernel hat den Aufbau der DuckDB Delta Extension stark vereinfacht und ermöglicht den einfachen Zugriff auf Delta Lake von DuckDB aus. Wir freuen uns, mit Databricks an Delta Kernel und dem Unity Catalog Open Standard für Daten und KI zusammenzuarbeiten. Diese Zusammenarbeit stellt einen bedeutenden Schritt vorwärts in der Open-Source-Innovation und der Entwicklung von Open Data Lakehouses dar."
— Hannes Mühleisen, CEO, DuckDB Labs
![]()
"Databricks' Entscheidung, Unity Catalog als Open Source zu veröffentlichen, ist eine aufregende Entwicklung für die Daten- und KI-Community. Wir freuen uns, mit Databricks zusammenzuarbeiten, um Unity Catalog in LangChain zu integrieren, was es unseren gemeinsamen Nutzern ermöglicht, fortschrittliche Agenten zu erstellen, indem sie Unity Catalog-Funktionen als Werkzeuge nutzen."
— Harrison Chase, CEO & Founder, LangChain
![]()
"Unstructured ist die führende ETL-Lösung für unstrukturierte Daten für LLMs – sie hilft Organisationen, ihre Daten von Rohdaten in RAG-bereite Daten zu transformieren. Unsere Integration mit Unity Catalog ist sinnvoll, da wir Datensilos aufbrechen und die KI/ML-Entwicklung in Unternehmen beschleunigen. Wir freuen uns auf die Zusammenarbeit mit Databricks, um diesen offenen Standard für KI-Anwendungsfälle zu entwickeln und Metadaten für unstrukturierte Daten zu standardisieren – damit unsere Kunden an der Spitze der KI agieren können."
— Brian Raymond, CEO & Founder, UnstructuredIO
![]()
"Bei Eventual haben wir Daft entwickelt, die führende Open-Source-verteilte Abfragemaschine für multimodale Daten. Wir glauben, dass die Vereinheitlichung der Rechenleistung für tabellarische und unstrukturierte Daten nicht ausreicht und dass ein multimodaler Katalog entscheidend für den Aufbau von GenAI-Data-Lakehouses ist. Wir freuen uns auf die Zusammenarbeit mit Databricks und anderen KI-Innovatoren, um den Unity Catalog Open Standard für moderne Daten+KI-Workloads zu entwickeln."
— Sammy Sidhu, CEO & Founder, Eventual Computing
![]()
"Bei Granica setzen wir uns für Daten-Demokratisierung und die Freiheit von Vendor Lock-in ein. Unsere Safe Room-Technologie gewährleistet Datenschutz, Vertrauen und Sicherheit in generativen KI-Workflows und unterstützt gleichzeitig offene Standards wie Unity Catalog, Delta Lake und Apache Iceberg. Die herstellerneutrale Architektur von Unity Catalog und seine robusten Governance-Lösungen stimmen mit unserer Vision überein, Kunden Flexibilität und Kontrolle über ihre Daten zu bieten. Wir freuen uns darauf, zu diesem offenen Ökosystem beizutragen, Innovationen voranzutreiben und Kunden zu ermöglichen, nahtlos mit ihren Daten über Best-of-Breed-Plattformen hinweg zu arbeiten."
— Rahul Ponnala, CEO & Co-Founder, Granica
![]()
"Das Open Sourcing von Unity Catalog ist ein entscheidender Schritt hin zu einem kollaborativeren und innovativeren Daten-Ökosystem. Indem Databricks diese Technologie zugänglich macht, fördert es ein Umfeld, in dem die gesamte Community zu verbesserten Daten-Governance- und Managementfähigkeiten beitragen und davon profitieren kann. Dieser Schritt steht im Einklang mit unserer Vision bei Onehouse und Apache XTable (Incubating), offene Format-Interoperabilität zu unterstützen, die Fortschritt und Innovation für alle vorantreibt."
— Vinoth Chandar, CEO & Co-Founder, Onehouse
![]()
"Confluents Mission ist es, Daten in Bewegung zu setzen und Organisationen zu ermöglichen, ihre Daten überall zu nutzen. Wir freuen uns, dass Databricks einen bedeutenden Beitrag zu einem offenen Daten-Ökosystem leistet, indem Unity Catalog Open Source wird. Tableflow auf Confluent Cloud ermöglicht die einfache Bereitstellung von Echtzeitdaten an Orte wie einen Data Lake, indem Datenströme mit einem einzigen Klick in Iceberg-Tabellen umgewandelt werden. Durch die Kombination unserer branchenführenden Streaming-Fähigkeiten mit den robusten Datenmanagementlösungen von Databricks können Kunden ihre Daten effektiver als je zuvor nutzen."
— Shaun Clowes, CPO, Confluent
![]()
"Gemeinsam helfen Databricks und dbt Cloud Nutzern, Datensilos aufzubrechen, um effektiv zusammenzuarbeiten, ETL zu vereinfachen, um die TCO mit Delta Lake zu senken, und die Governance mit Unity Catalog zu vereinheitlichen. Wir freuen uns, unsere Unterstützung für Unity Catalog und die offenen APIs bekannt zu geben. Diese Partnerschaft unterstreicht unser Engagement für ein einheitliches Datenerlebnis und befähigt unsere Community, größere Erkenntnisse zu gewinnen und Innovationen voranzutreiben."
— Mark Porter, CTO dbt Labs
![]()
"Wir freuen uns sehr, dass Databricks Unity Catalog als offenen Standard für Daten und KI Open Source macht. Dieser Schritt wird unseren Kunden mehr Auswahl und Flexibilität in ihrem Daten-Ökosystem bieten und eine nahtlose Integration und maximale Interoperabilität mit der Fivetran-Plattform gewährleisten, während sie kritische Daten in Databricks aufnehmen."
— Anjan Kundavaram, CPO, Fivetran
![]()
"Die Bereitstellung nativer Zugriffsmuster innerhalb von Unity Catalog hat die Art und Weise, wie unser Unternehmen den Datenzugriff optimiert und Governance-Regeln in großem Maßstab anwendet – ohne Leistungseinbußen – revolutioniert. Databricks' fortgesetzte Investitionen in eine Community zur Beschleunigung von Diensten, die die Erstellung von Datenkontrollen vereinfachen, ermöglichen es unseren Kunden, mit größerer Leichtigkeit zu steuern und das massive Volumen neuer Datennutzer zu verwalten, die im Zeitalter der KI onboarden."
— Matthew Carroll, CEO, Immuta
![]()
"Wir freuen uns über die Möglichkeiten für unsere gemeinsamen Kunden, da Databricks Unity Catalog als offenen Standard für Daten und KI Open Source macht. Mit Unity Catalog und der Informatica Intelligent Data Management Cloud können Kunden mehr Auswahl, Flexibilität und Interoperabilität in ihren Daten-Ökosystemen erzielen."
— Brett Roscoe, GM und SVP Cloud Data Governance und Cloud Operations, Informatica
![]()
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.