PDFs in Produktion: Ankündigung von hochmoderner Dokumentenintelligenz auf Databricks
Mit ai_parse_document PDFs direkt in SQL mit führender Qualität zu 3-5x niedrigeren Kosten parsen und verstehen
- Heute stellen wir die neueste Ergänzung zu Agent Bricks vor: ai_parse_document (öffentliche Vorschau): Angetrieben von unserem agentenbasierten System für multimodales Verständnis in großem Maßstab.
- Erschließen Sie 80 % Ihrer Unternehmensdaten mit modernster intelligenter Dokumentenverarbeitung: Verarbeiten Sie Millionen komplexer Dokumente – Tabellen, Abbildungen, Diagramme – mit der Kraft bahnbrechender KI-Forschung in einer einzigen SQL-Funktion.
- Führende Qualität und Kosten: Wir haben ein System zur Dokumentenintelligenz entwickelt, das in der Qualität mit den besten Angeboten der Konkurrenz bei 3-5x niedrigeren Kosten konkurrenzfähig ist.
- Vollständige Plattformintegration: Automatische inkrementelle Verarbeitung mit Spark Declarative Pipelines, Governance mit Unity Catalog und nahtlose Nutzung über Agent Bricks, AI Search und AIBI.
Während der Week of Agents erweitern wir Agent Bricks, die Databricks-Plattform für den Aufbau von gesteuerten, produktionsreifen KI-Agenten, die präzise auf Ihren Daten schlussfolgern. Eine der größten Herausforderungen für Unternehmen bei der Skalierung von Agenten ist der Zugriff auf unstrukturierte Daten. Fast 80 % des Wissens von Unternehmen sind in PDFs, Berichten und Diagrammen gefangen, die Agenten nicht lesen, verstehen oder verarbeiten können. Diese Dokumente enthalten kritische Kontexte, aber die meisten KI-Agenten konnten sie nicht lesen – bis jetzt.
Bestehende Parsing-Tools stoppen bei der Textextraktion. Sie übersehen die Layouts, visuellen Elemente und Beziehungen, die in echten Dokumenten Bedeutung tragen. Teams verbringen Monate damit, brüchigen benutzerdefinierten Code zu schreiben, der bei realen Daten immer noch versagt. ai_parse_document eliminiert diese Komplexität. Es bringt vollständiges Dokumentenverständnis direkt in die Databricks Data Intelligence Platform und gibt jedem Agenten Zugriff auf die volle Treue Ihres Geschäftskontexts – präzise, sicher und in großem Maßstab.
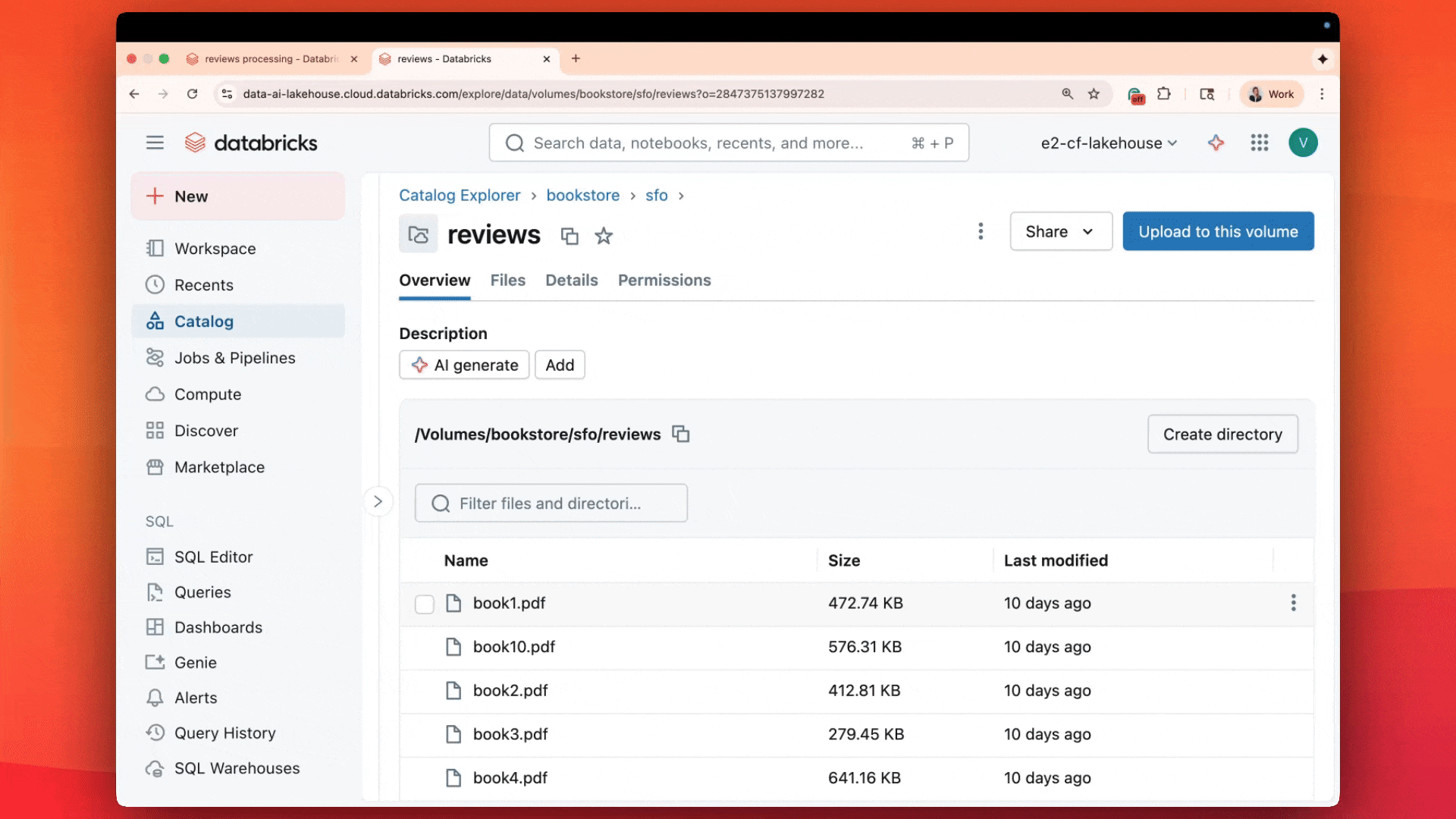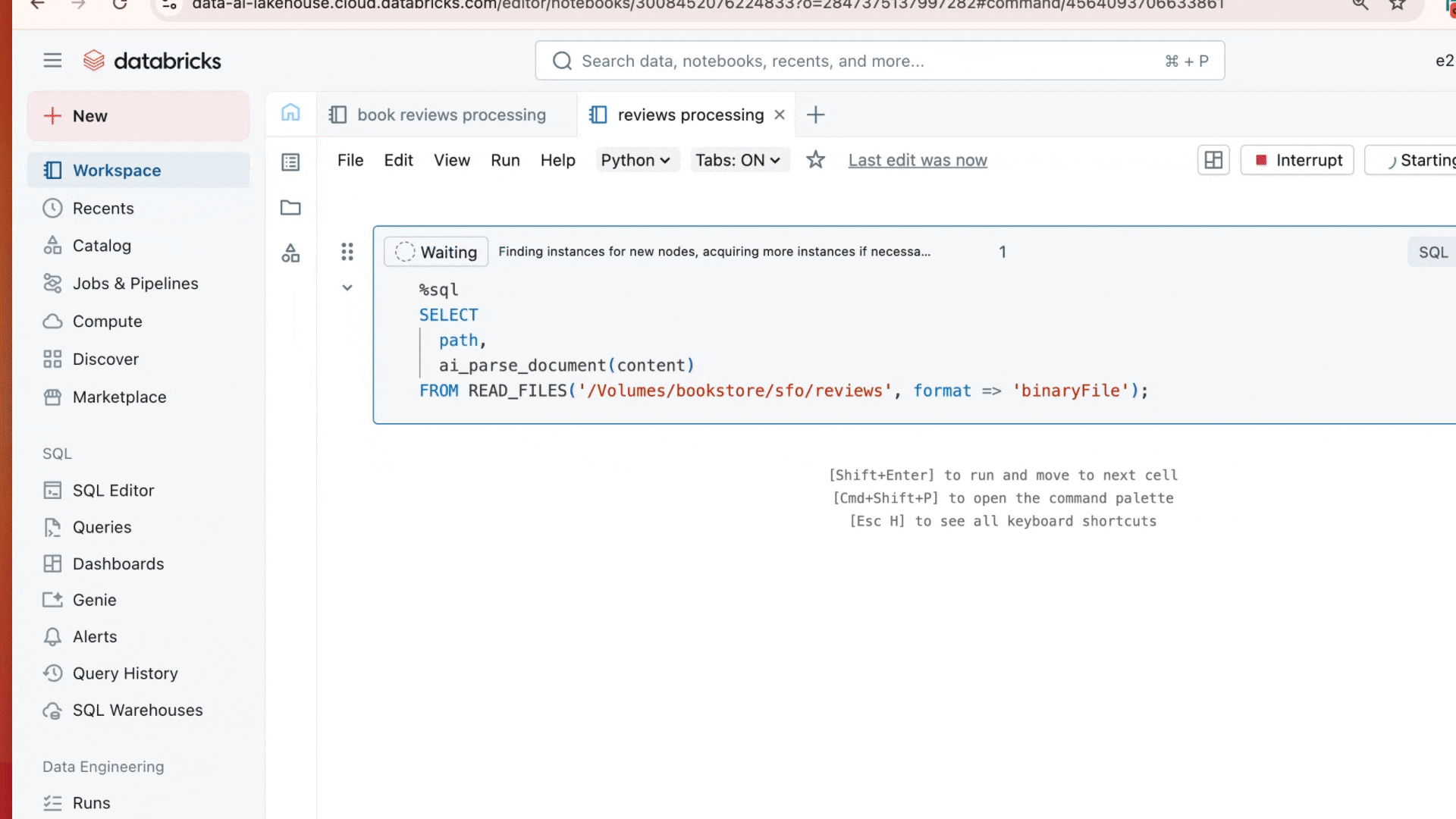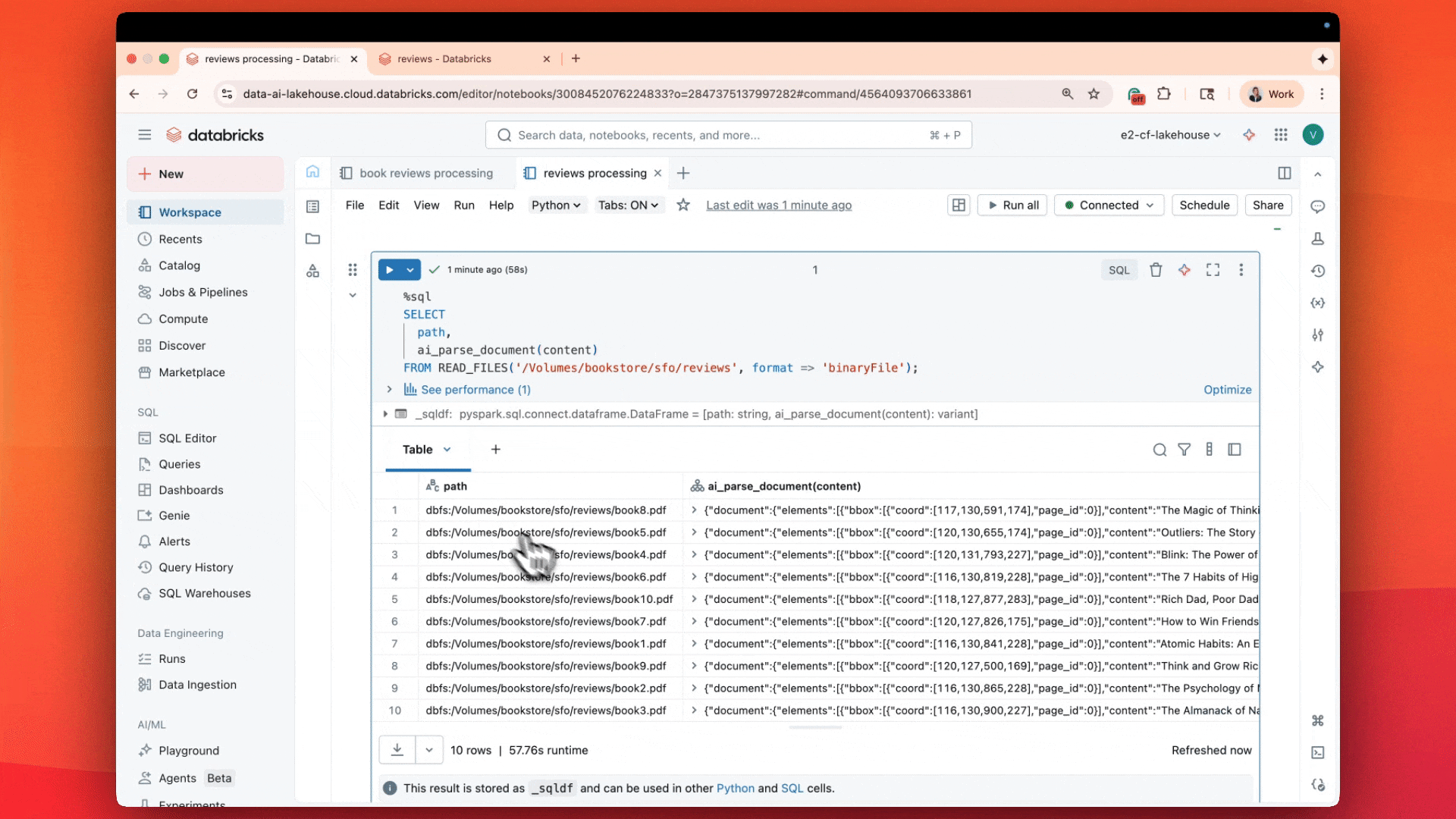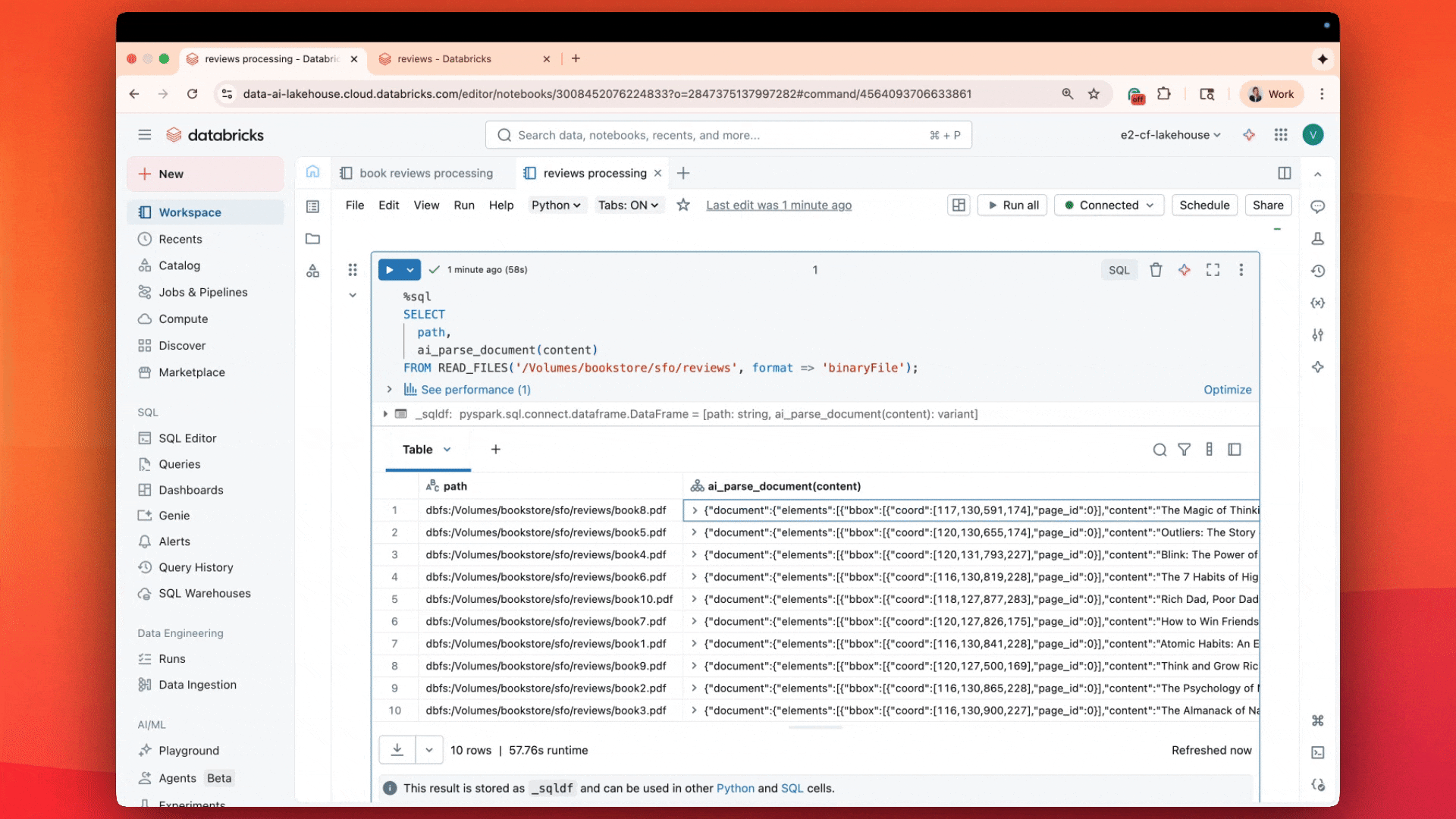
Mit einem einzigen SQL-Befehl können Organisationen Dokumente in strukturierte, gesteuerte und abfragbare Daten umwandeln:
Das Ergebnis ist nicht nur der Text der PDF, sondern auch Layoutinformationen, analysierte Tabellen, Begrenzungsrahmen, Abbildungen und Bilder mit Bildunterschriften – eine umfassende Beschreibung des Dokuments als strukturierte Information.
"Databricks’ ai_parse_document reduziert den Konfigurationsaufwand, sodass Data Scientists weniger Zeit für die Einrichtung aufwenden und mehr Zeit für die Weiterentwicklung komplexer, kundenorientierter Lösungen aufwenden können."—Meiling He, Sr. Data Science Manager, Rockwell Automation
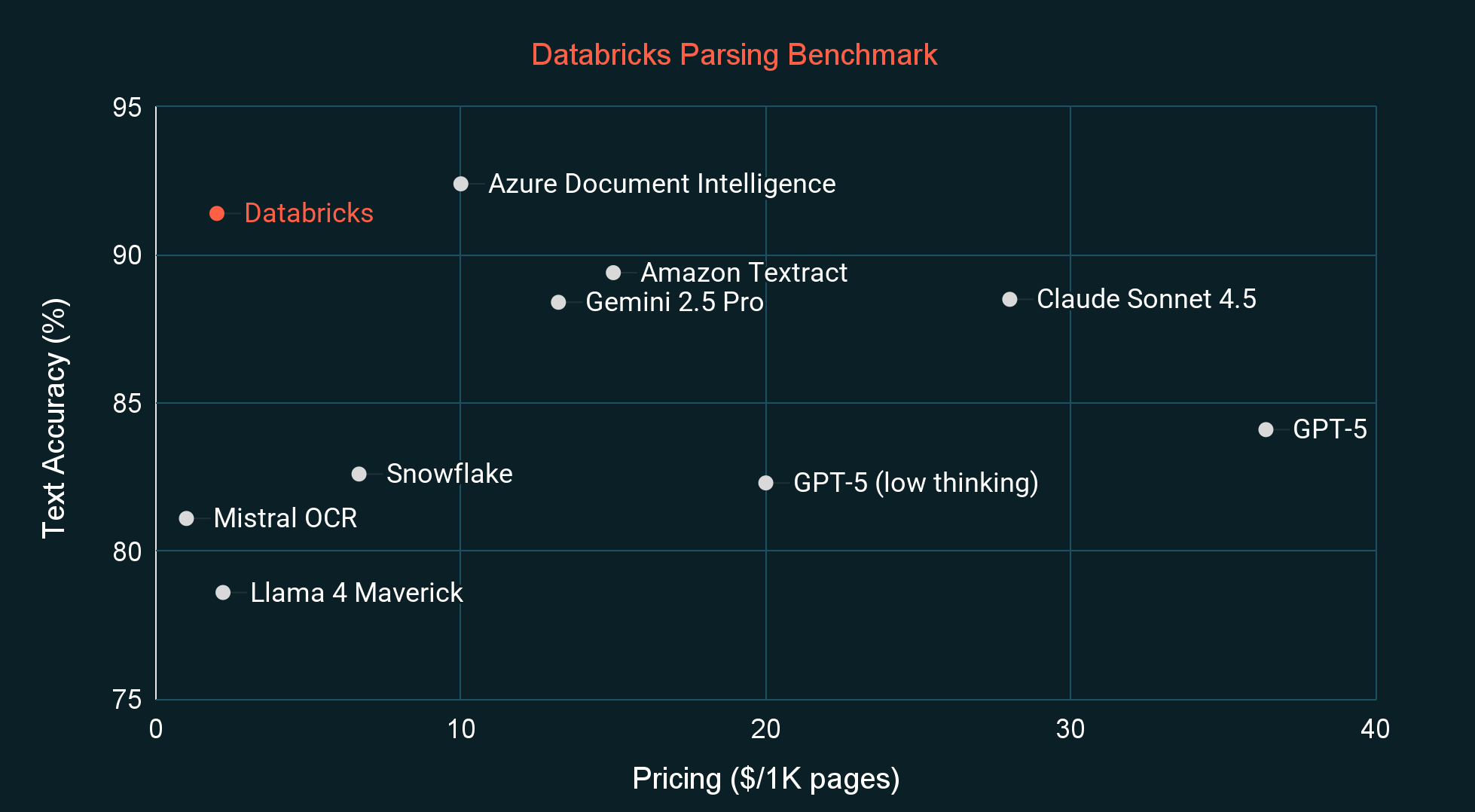
State-of-the-Art Preis-Leistung
Im Vergleich zu anderen State-of-the-Art-Parsing-Systemen und Vision-Language-Modellen (VLMs) weist ai_parse_document die höchste Qualität für seine Preisklasse auf, gemessen sowohl an einem gängigen externen Benchmark (OmniOCR) als auch an unserem privaten internen Benchmark (siehe Abbildungen unten). Der interne Benchmark ist besser auf die Verteilung der Dokumente abgestimmt, die wir von Kunden gesehen haben, und es ist auch unwahrscheinlich, dass er Teil der Trainingsdaten eines Modells ist. In den kommenden Wochen werden wir auch unsere neuen OmniOCR-Labels veröffentlichen, die einige Beschriftungsfehler beheben und Begrenzungsrahmen sowie Hierarchieinformationen einführen.

So funktioniert es
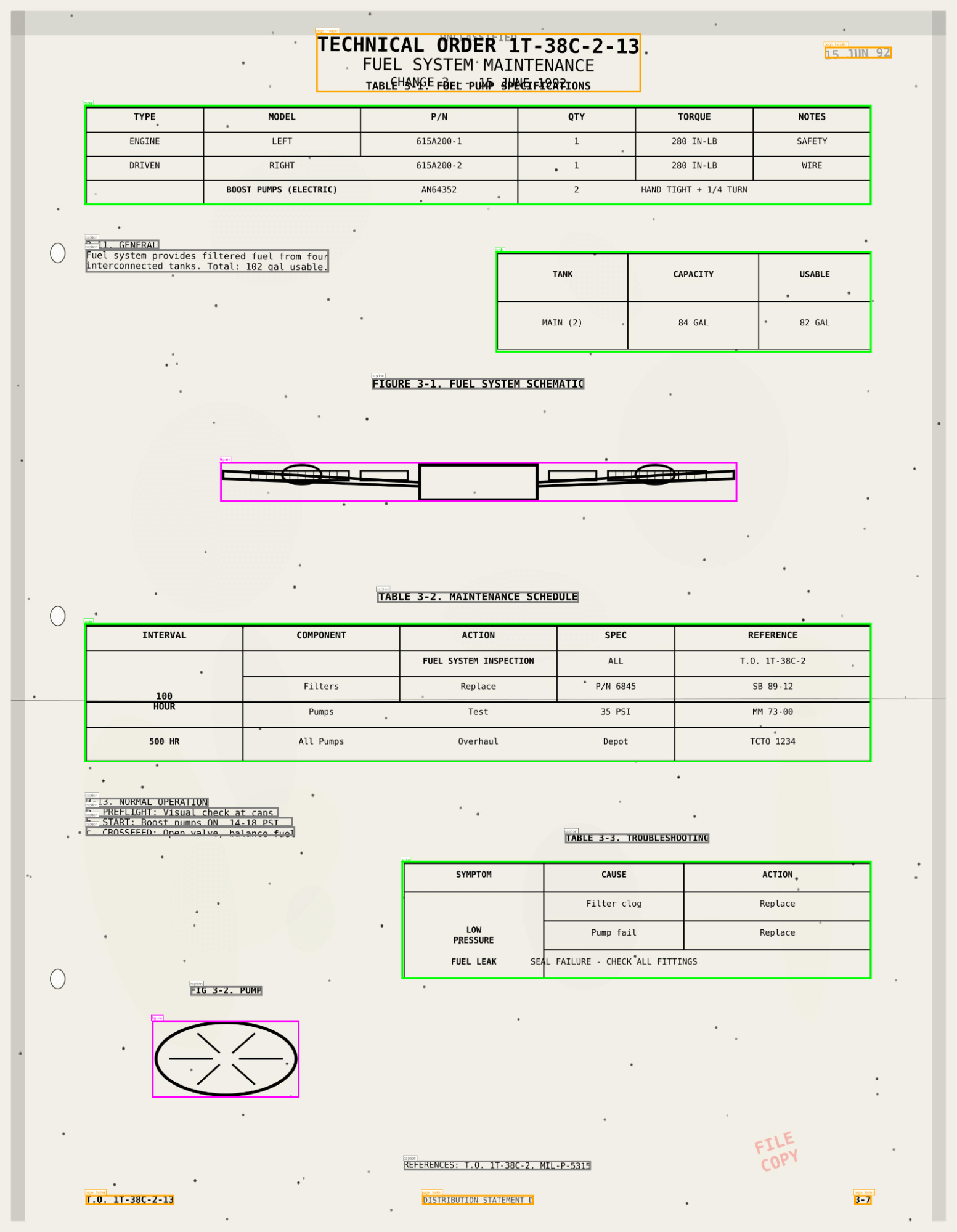
ai_parse_document erfasst Tabellen, Abbildungen und Diagramme mit KI-generierten Beschreibungen und räumlichen Metadaten und speichert die Ergebnisse in Unity Catalog. Ihre Dokumente verhalten sich jetzt wie Tabellen – durchsuchbar über AI Search und nutzbar in Agent Bricks Workflows.
„Das Extrahieren von Tabellen, Text und Metadaten aus PDFs oder Bildern war früher ein komplexer, codeintensiver Prozess. Databricks hat dies auf eine einzige SQL-Funktion, ai_parse_document, reduziert, wodurch die Verarbeitung unstrukturierter Daten in großem Maßstab radikal vereinfacht und in die Hände jedes Datenteams gelegt wird, nicht nur in die von Data Scientists.“—Rajesh Balakrishnan, Principal Data Scientist, TE Connectivity
Mit einer einzigen SQL-Anweisung verarbeiten Kunden bereits Millionen von Dokumenten parallel:
Jedes Ergebnis enthält:
- Tabellen, die exakt wie im Original erscheinen, einschließlich zusammengeführter Zellen und verschachtelter Strukturen.
- Abbildungen und Diagramme, die automatisch mit KI-generierten Bildunterschriften beschrieben werden.
- Räumliche Metadaten und Bounding Boxes für Zitate und Validierung.
- Optionale Bildausgaben, die in Unity Catalog Volumes für multimodale Suche oder Visualisierung gespeichert werden.
Da alles innerhalb von Databricks bleibt, behalten Sie konsistente Governance, Lineage und Observability bei.
Ersetzen Sie Ihren Stapel externer Parser durch eine einzige SQL-Funktion, die wie jede andere Databricks-Operation funktioniert. Während Teams typischerweise Dokumente an OCR-Dienste, Layout-Erkennungs-APIs und Bildunterschriften-Tools exportieren, verarbeitet ai_parse_document sie, ohne Ihre Databricks-Umgebung zu verlassen:
„ai_parse_document macht RAG schnell und einfach auf Databricks, indem es die parallele Dokumentenverarbeitung direkt in den Delta-Tabellen ermöglicht, die Sie bereits verwenden.“—Hunter Johnson, Lead Data Scientist, Emerson Electric Co.
Von der Analyse zur Aktion mit Agent Bricks
Nach der Analyse fließen die Dokumentendaten natürlich durch den Rest des Agent Bricks Ökosystems:
- Vektorsuche indiziert jedes Element für multimodale RAG-Anwendungen, die sowohl Text als auch Bilder verstehen.
- Deklarative Agenten optimieren Extraktion, Klassifizierung und Zusammenfassung mit natürlicher Sprache für besseren Durchsatz und geringere Kosten
- KI-Funktionen extrahieren Entitäten, klassifizieren Inhalte und fassen Text zusammen – alles mit SQL.
- Supervisor-Agent koordiniert Dokumentenanalyse-Agenten mit anderen spezialisierten Agenten und ermöglicht komplexe, mehrstufige Workflows.
- KI/BI-Dashboards und Spark Declarative Pipelines verwenden dieselben analysierten Daten für Analysen und kontinuierliche Verarbeitung.
Zusammen machen diese Funktionen unstrukturierte Daten zu einem vollständig integrierten Bestandteil der Agent Bricks Plattform.
Für Produktionsskalierung und Zuverlässigkeit entwickelt
Viele Unternehmen haben Millionen von unstrukturierten Dokumenten zu verarbeiten, einige erhalten sogar Millionen pro Tag. Es ist entscheidend, eine Lösung zu haben, die zuverlässig skaliert, um diese Daten zu verarbeiten, ohne Tage zu benötigen. Databricks integriert ai_parse_document mit Spark Declarative Pipelines, was eine automatische, inkrementelle Dokumentenverarbeitung in großem Maßstab ermöglicht. Wenn neue Dokumente eintreffen – sei es von SharePoint, S3 oder ADLS –, werden sie automatisch verarbeitet. Lakeflow kümmert sich um Wiederholungsversuche, Checkpointing und Skalierung, sodass Sie niemals vorhandene Daten erneut verarbeiten oder benutzerdefinierten Orchestrierungscode schreiben müssen.
Alles wird über Unity Catalog gesteuert, sodass Sie Berechtigungen verwalten, den Zugriff überprüfen und die Abstammung für verarbeitete Inhalte nachverfolgen können, genau wie bei strukturierten Daten.
Unstrukturierte Daten mit Agent Bricks freischalten
ai_parse_document ist die neueste Ergänzung zu Agent Bricks AI Functions, neben Funktionen wie ai_extract, ai_classify, ai_summarize und ai_query. Gemeinsam geben diese Funktionen jedem Team die Möglichkeit, alle Unternehmensdaten direkt auf der Databricks-Plattform zu analysieren. Durch die Kombination von Dokumentenintelligenz mit integrierter Governance, Beobachtbarkeit und Orchestrierung ermöglicht Databricks Unternehmen, KI-Agenten zu erstellen, die ihren Geschäftskontext wirklich verstehen und mit Zuversicht darauf handeln.
Sind Sie bereit, den Wert in Ihren unstrukturierten Daten freizuschalten?
- Lesen Sie die Dokumentation, um noch heute mit der Verwendung von ai_parse_document zu beginnen
- Erstellen Sie inkrementelle Dokumenten-Pipelines mit unserer Referenzlösung
Forschende Autoren (gleiche Beteiligung): Ziyi Yang, Jasmine Collins, Adyasha Maharana, Cory Stephenson, Erich Elsen, Adam Gurary, Ethan Tang
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.