Ein Echtzeit-Open-Lakehouse mit Redpanda und Databricks
Die Investitionen von Redpanda in die grundlegende Integration mit Iceberg und Unity Catalog schaffen eine nachhaltige Architektur für die Bereitstellung von Echtzeit-Agilität von Streams zu Tabellen und die Unterstützung eines Echtzeit-Open-Lakehouse.
von Matt Schumpert und Jason Reid
- Verwandeln Sie Ihre Kafka-Streams mit einem Schritt in vollständig verwaltete, von Unity Catalog verwaltete Iceberg-Tabellen. Dies ermöglicht Echtzeit-Lakehouse-Analysen ohne aufwendige Konnektoren oder benutzerdefinierte ETL-Jobs.
- Führen Sie Streaming mit Latenzen unter 10 ms und hochdurchsatzfähige Apache Iceberg™-Ingestion auf demselben Redpanda-Cluster mit Iceberg Topics aus, die Parquet-Batching, Exactly-Once-Commits und die prädiktiven Optimierungen von Unity handhaben, wodurch Kosten und Betriebsaufwand drastisch reduziert werden.
- Stellen Sie überall bereit (SaaS, BYOC oder selbstverwaltet) und bauen Sie auf offenen Standards mit Kafka-, Iceberg V2- und REST Catalog-APIs auf. Einfache deklarative Konfigurationen bieten Ihnen benutzerdefinierte Partitionierung, Schema-Evolution und integrierte DLQs out of the box.
Jeder Lakehouse sollte „stream-gesteuert“ sein
Das von Databricks vor Jahren entwickelte „Open Lakehouse“-Konzept wurde durch den jüngsten Aufstieg von Apache Iceberg™ breiter realisiert. Dies wird durch die Investitionen großer Anbieter in Framework-Integration, Tooling, Katalogunterstützung und Dateninteroperabilität vorangetrieben, die sich zu Iceberg als gemeinsamer Grundlage für ein offenes Lakehouse bekennen. Fortschritte wie die Möglichkeit, Delta Lake-Tabellen über UniForm dem wachsenden Iceberg-Ökosystem zugänglich zu machen, die Unterstützung von Unity Catalog für erweiterte Funktionen wie Predictive Optimization und Iceberg REST mit Managed Iceberg Tables und die jüngste Vereinheitlichung der Delta/Iceberg-Datenschicht in Iceberg V3 bedeuten, dass Unternehmen jetzt eine „Iceberg-orientierte“ Datenstrategie mit Zuversicht verfolgen können, ohne die Nutzung der reichhaltigen Funktionssätze etablierter Lakehouse-Produkte wie Databricks zu beeinträchtigen.
Einer der wichtigsten fehlenden Bausteine in dieser Geschichte des allgegenwärtigen Zugriffs auf Cloud-Daten über die Lingua Franca von Iceberg waren Streams, insbesondere Kafka-Topics. Heute können alle strukturierten Daten im Ruhezustand nativ als Iceberg gespeichert oder „dekoriert“ werden. Im Gegensatz dazu müssen hochwertige Daten, die über eine Streaming-Plattform fließen und Echtzeitanwendungen antreiben, immer noch über einen Point-to-Point-Datenintegrationsjob pro Stream in das Ziel-Lakehouse „ETLed“ werden, oder durch den Betrieb einer kostspieligen Connector-Infrastruktur auf einem eigenen Cluster. Beide Ansätze nutzen einen schwerfälligen Kafka Consumer, was Ihre Echtzeit-Datenliefer-Pipelines belastet, und erstellen eine Middleman-Infrastrukturkomponente, die mit spezialisierten Kafka-Kenntnissen skaliert, verwaltet und beobachtet werden muss. Beide Ansätze laufen darauf hinaus, eine sehr teure Gebühr zwischen Ihren Echtzeit- und Analyse-Datenbeständen einzuführen, die wirklich nicht notwendig ist.
Da die Nutzung von Cloud-Objektspeichern für die Sicherung von Streams ausgereift ist (Redpanda führte diese Entwicklung vor einigen Jahren an) und da offene Tabellenformate im Mittelpunkt von Lakehouses stehen, ist diese Verbindung von Stream zu Tabelle sowohl praktisch als auch „bestimmt“. Databricks und Redpanda liefern zwei erstklassige Datenplattformen, die diesen Ansatz glänzen lassen und Aufmerksamkeit erregen. Gemeinsam schaffen sie ein Daten-Substrat, das Echtzeit-Entscheidungsfindung, Analysen und KI umfasst und schwer zu schlagen ist. Praktisch verschmilzt dieser Ansatz Streams mit Tabellen mit der Leichtigkeit eines Konfigurationsflags. Er fungiert wie ein mehrkammeriger Damm, der wählbare Streams bei Bedarf in einen einheitlichen Data Lake leitet, tagesaktuelle Einblicke liefert und die gleiche beliebige Einbeziehung von Daten in neue Analyse-Pipelines ermöglicht, die uns die Lakehouse-Architektur für Tabellen bot, und das jetzt durch die erweiterte Öffnung, die das Iceberg-Ökosystem bietet.
Die nahtlose Verschmelzung von Echtzeit- und Analyse-Dateninfrastrukturen, um ein „stream-gesteuertes Lakehouse“ zu einem Knopfdruck-Ereignis zu machen, erschließt nicht nur massiven Wert, sondern löst auch ein schwieriges technisches Problem, das einen durchdachten Ansatz erfordert, um es im Allgemeinen richtig zu lösen. Wie wir unten zu veranschaulichen hoffen, haben wir keine Kompromisse gemacht, um diese Funktion überstürzt auf den Markt zu bringen. In Zusammenarbeit mit Dutzenden von Designpartnern (und Databricks) seit über einem Jahr haben wir den Code von Redpanda so erweitert, dass die bevorzugten Bereitstellungsoptionen unserer Kunden (einschließlich BYOC in mehreren Clouds) erhalten bleiben, die vollständige Kafka-Kompatibilität (keine Workloads zurücklassen) gewahrt bleibt und Duplizitäten von Artefakten und Schritten für Benutzer, wo immer möglich, vermieden werden. Wir hoffen, dass diese Vollständigkeit der Vision durchscheint, wenn wir die Leitprinzipien für den Aufbau von Redpanda Iceberg Topics darlegen, die jetzt mit Databricks Unity Catalog auf AWS und GCP verfügbar sind!
Betreiben Sie Ihre Stream-to-Lakehouse-Plattform überall
Unser erstes Prinzip war es, die Wahl zu erhalten und die Benutzer dort zu treffen, wo sie sind. Redpanda verfügt bereits über ausgereifte Multi-Cloud-SaaS-, BYOC- und selbstverwaltete-Angebote, private souveräne Netzwerkoptionen wie BYOVPC und zwingt seine Kunden generell nie, Clouds, Netzwerke, Objektspeicher, IdPs oder irgendetwas anderes zu wechseln, was die Einführung behindern oder es Plattformbesitzern verhindern würde, ihre Streaming-Plattform-Bereitstellung (einschließlich sowohl Daten- als auch Steuerebenen) dort zu positionieren, wo es für sie am sinnvollsten ist. Unabhängig von dieser Wahl erhalten Benutzer alle Funktionen der Plattform und eine konsistente Benutzererfahrung für Entwickler und Administratoren. Diese Single-Platform-Produktstrategie ermöglicht es uns, bekannt zu geben, dass Iceberg Topics für Databricks heute in AWS, GCP und Azure Clouds allgemein verfügbar sind und dass Unternehmen mit der Gewissheit bereitstellen können, dass sie, wenn und wann sie die Cloud wechseln oder zu neuen Formfaktoren wechseln, dasselbe Produkt mit derselben zugrunde liegenden Engine, Kafka-Kompatibilität, Sicherheitsmodell, Leistungseigenschaften und Verwaltungstools bereitstellen. Diese Bandbreite an Flexibilität und Konsistenz steht im scharfen Kontrast zu anderen Optionen auf dem Markt.
Unity Catalog trifft die vereinheitlichteste Streaming-Plattform
Zweitens waren wir entschlossen, dies als ein einziges System zu bauen, und eines, das sich auch so anfühlt. Man kann zwei Konzepte nicht gut miteinander verschmelzen, indem man zwei völlig unterschiedliche Softwarearchitekturen zusammenfügt. Man kann einige Dinge mit einer SaaS-Oberfläche überdecken, aber aufgeblähte Architekturen lecken mindestens in Preismodellen, Leistung und TCO durch und im schlimmsten Fall in die Benutzererfahrung. Wir haben unser Bestes getan, um das zu vermeiden.
Für Entwickler bedeutet das „Gefühl“ eines einzigen Systems einen einzigen CRUD-Lebenszyklus und eine konsistente Benutzererfahrung für Topics-as-Tables und die Dinge, die sie zum Arbeiten benötigen (nämlich Schemas). Mit Iceberg Topics kopieren Sie niemals Einträge oder Konfigurationen, noch erstellen Sie sie zweimal über eine separate Benutzeroberfläche. Sie verwalten eine einzige Entität als Quelle der Wahrheit für Daten und Schema und verwenden dabei immer dieselben Tools. Für uns bedeutet das, dass Sie über die Tools, die Sie bereits verwenden, CRUD-Operationen durchführen: jedes Kafka-Ökosystem-Tool, unser rpk CLI, Cloud REST APIs oder jedes Redpanda-Bereitstellungsautomatisierungstool wie unsere K8s CRs oder Terraform provider. Für Schemas ist es unsere integrierte Schema Registry mit ihrer weithin akzeptierten Standard-API, die das Iceberg-Tabellenschema implizit oder explizit definiert, wie Sie es bevorzugen. Alles ist konfigurationsgesteuert und DevOps-freundlich. Und mit den neuen Managed Iceberg Tables von Unity Catalog sind alle Ihre Streams standardmäßig über Databricks-Tools als Iceberg- und Delta Lake-Tabellen auffindbar.
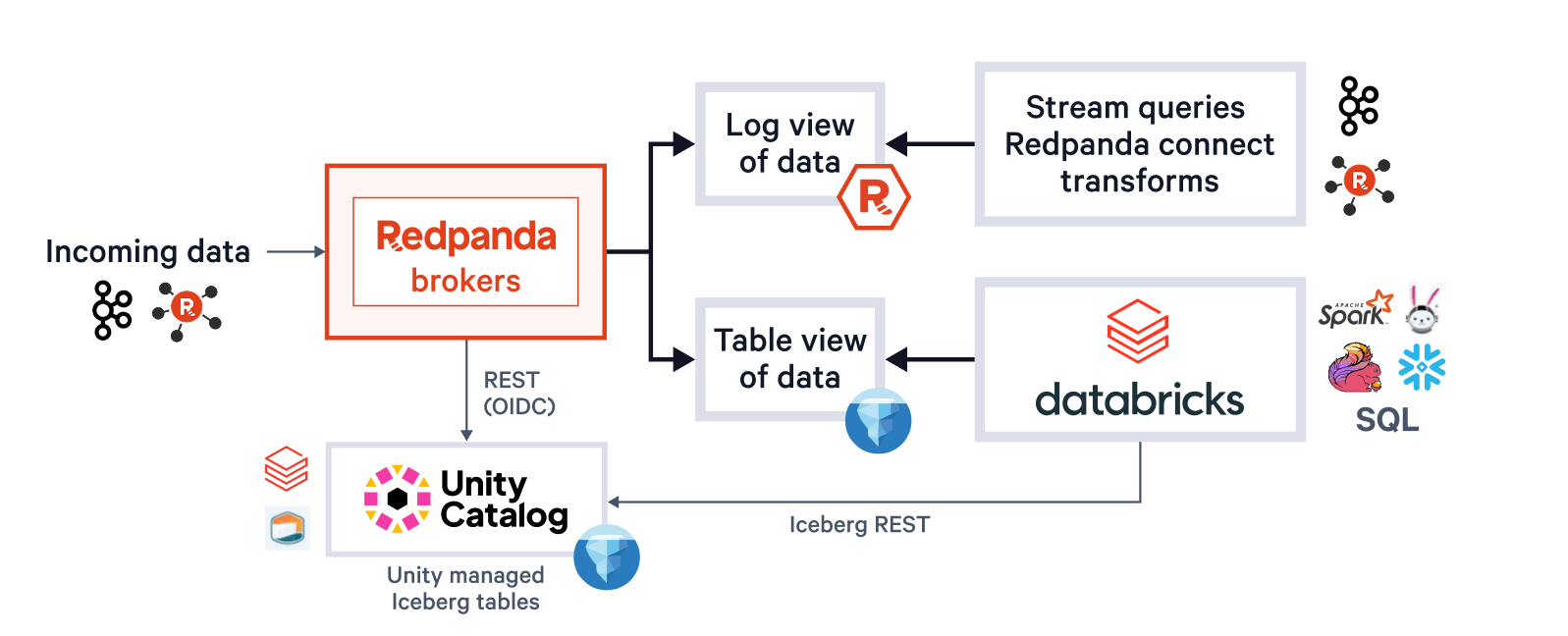
Ein einziges System betrifft auch den Plattformbetreiber, der sich nicht um die Verwaltung mehrerer Buckets oder Kataloge, die Optimierung von Parquet-Dateigrößen, verzögerte Tabellen gegenüber Streams, wenn Cluster ressourcenbeschränkt sind, oder um Knotenausfälle, die eine Exactly-Once-Zustellung beeinträchtigen, kümmern muss. Mit Redpanda Iceberg Topics ist all dies selbstreifend. Betreiber profitieren von dynamisch gebündelten Parquet-Schreibvorgängen und transaktionalen Iceberg-Commits, die sich an Ihre Datenankunfts-SLAs anpassen, automatischer Lag-Überwachung, die bei Bedarf Kafka Producer Backpressure generiert, und Exactly-Once-Zustellung über Iceberg-Snapshot-Tagging (Vermeidung von Lücken oder Duplikaten nach Infrastrukturausfällen).
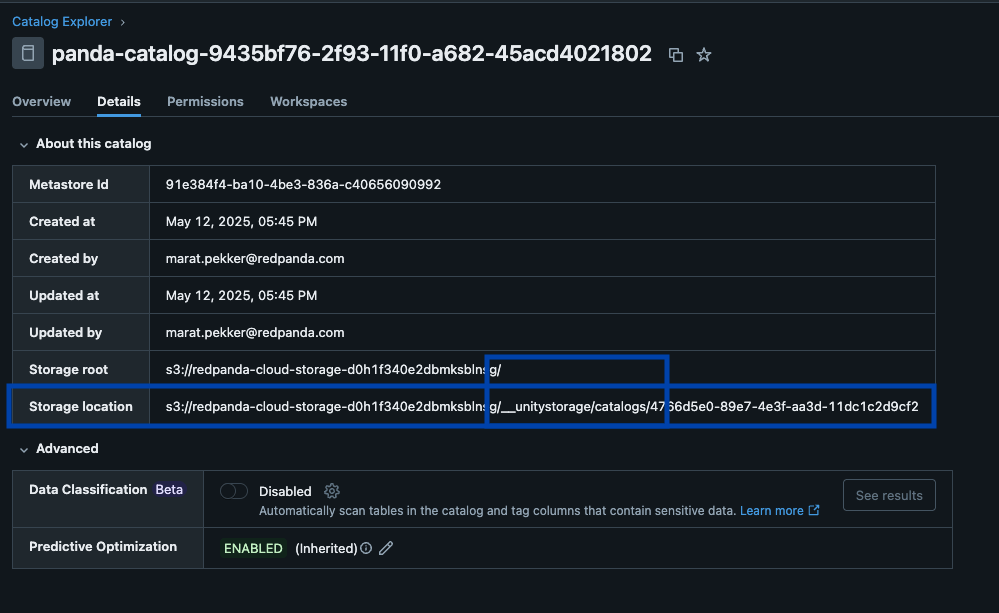
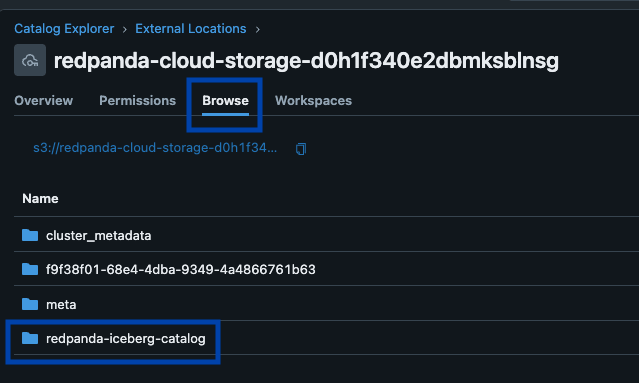
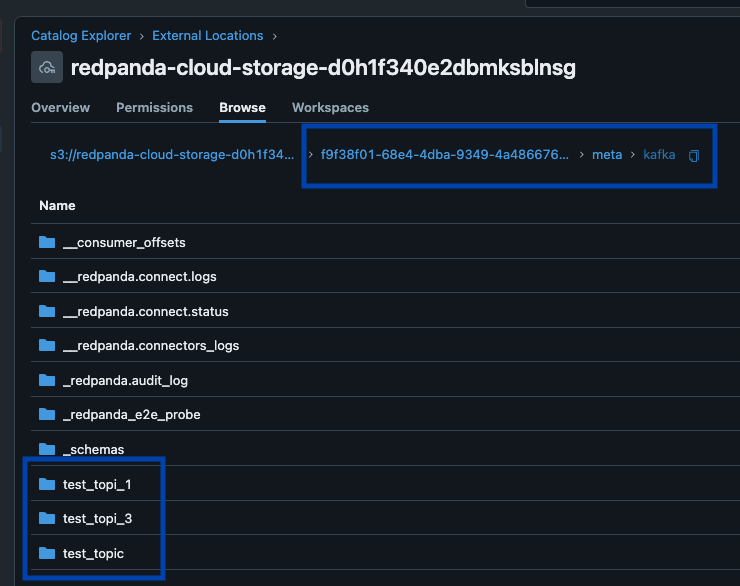
Redpanda verwaltet alle Ihre Daten in einem einzigen Bucket/Container, verwendet einen einzigen Iceberg-Katalog in Unity Catalog (den Redpanda überwacht für eine reibungslose Wiederherstellung) und macht Tabellen leicht auffindbar, indem der Iceberg REST-Endpunkt von Unity Catalog direkt in der Benutzeroberfläche von Redpanda Cloud angezeigt wird. Und jetzt, mit Unity Catalog Managed Iceberg Tables, sind Tabellenwartungsoperationen wie Kompaktierung, Datenablauf und Predictive Optimization integriert und werden automatisch von Unity Catalog im Hintergrund ausgeführt, während Redpanda die minimalen Wartungsoperationen übernimmt, die für seine Rolle angemessen sind (derzeit Iceberg-Snapshot-Bereinigung und Tabellenerstellung/-löschung). Databricks-Administratoren können diese Tabellen dann mit allen normalen Unity Catalog Berechtigungen sichern und verwalten.
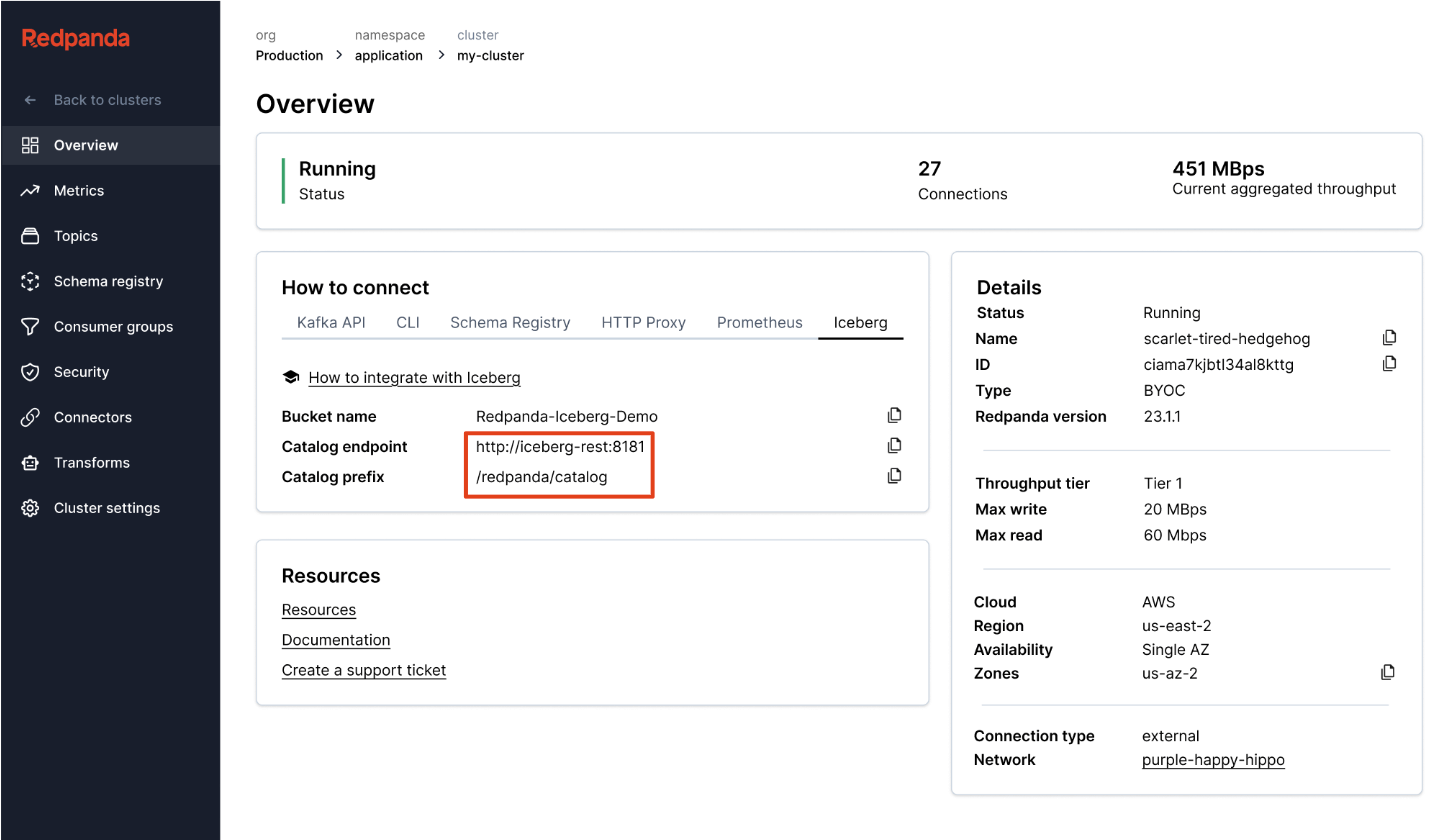
Ein Cluster für alle
Am wichtigsten ist, dass dank unserer R1 Multi-Modal Streaming Engine, die eine Thread-pro-Kern-Architektur verwendet und Funktionen wie Write Caching und Multi-Level Data and Workload Balancing nutzt, Administratoren diese Hochdurchsatz-Iceberg-Ingestion im selben Cluster und mit denselben Topics ausführen können, die bestehende Low-Latency-Kafka-Workloads mit Sub-10-ms-SLAs antreiben. Durch die Verwendung asynchroner, gepipelined Operationen, die an dieselben CPU-Kerne gebunden sind, die Produce/Consume-Anfragen bearbeiten, verarbeiten wir beide Workloads mit maximaler Effizienz in einem einzigen Prozess. Am wichtigsten ist, dass Iceberg Topics den vollen Umfang der Kafka-Semantik nutzen können, einschließlich Kafka-Transaktionen und komprimierter Topics, wobei die Iceberg-Schicht nur Datensätze aus abgeschlossenen Transaktionen empfängt. Diese Kombination aus einer grundlegend effizienten Architektur, die die schwierigen Probleme komplexer Semantiken löst, zahlt sich enorm bei der Senkung Ihrer Betriebskosten aus, denn nun ja, ein Cluster für alle. Keine zusätzlichen Produkte. Keine separaten Cluster. Keine Pipeline-Überwachung. Überall bereitstellen. Bleiben Sie ruhig und machen Sie weiter, Streaming-Plattform-Administratoren.
Machen Sie es einfach
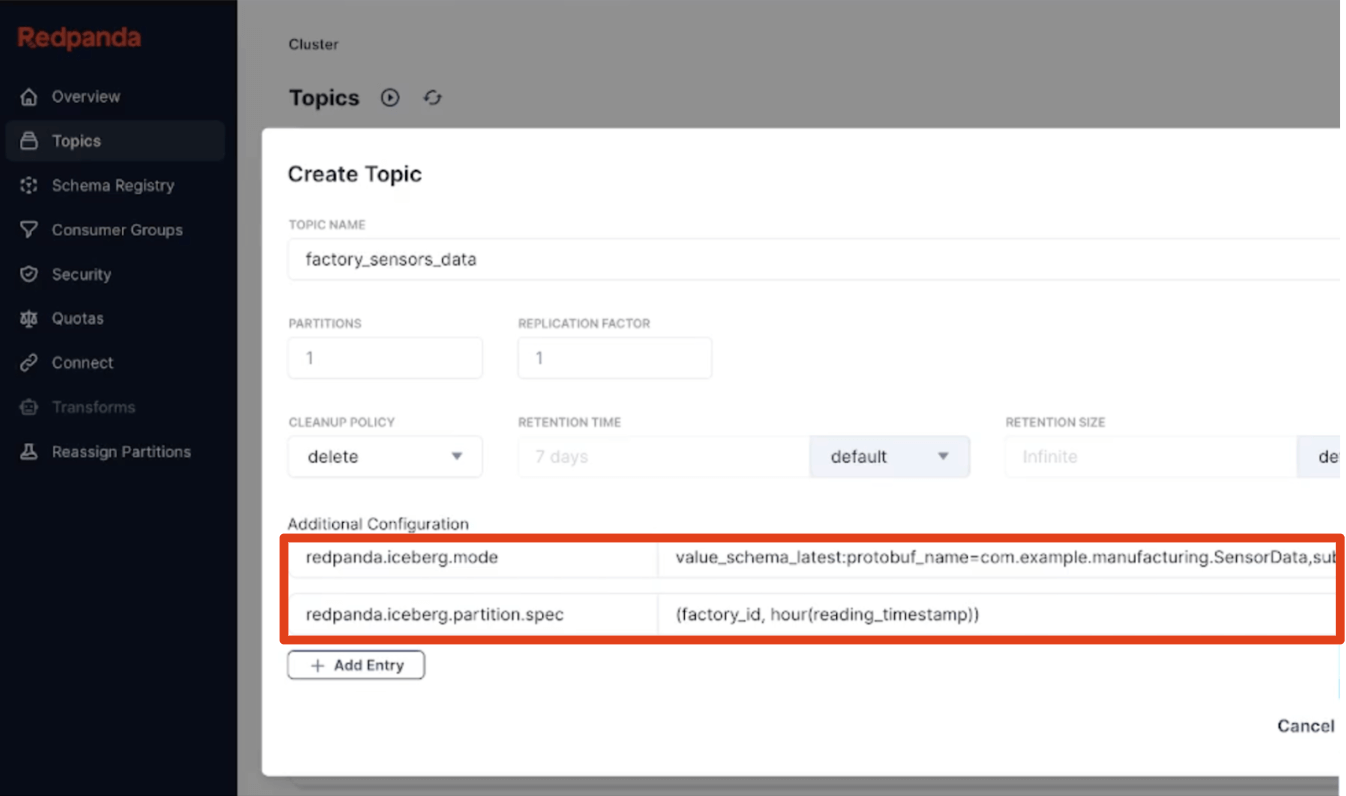
Unser drittes Prinzip war, einige meinungsbildende Entscheidungen über Standardverhalten zu treffen, damit Benutzer das System schrittweise mit der bestmöglichen automatischen Konfiguration erlernen können, die für die meisten Anwendungsfälle funktioniert. Dies bedeutet integrierte stündliche Tabellenpartitionierung (vollständig getrennt von Kafka-Topic-Partitions-Schemata), immer aktive Dead-Letter-Queues als Tabellen zur Erfassung ungültiger Daten und einfache, kanonische Konventionen wie „neueste Version“ oder „TopicNameStrategy“ für die Schema-Inferenz erleichtern die Einführung. Wir bringen auch Kafka-Metadaten wie Nachrichtenpartitionen, Offsets und Schlüssel als Iceberg Struct mit, sodass Entwickler über die gesamte Herkunft verfügen, um die Korrektheit ihrer Streaming-Pipelines in Iceberg SQL schnell zu validieren.

Das Einfache sollte natürlich einfach sein, aber auch das Anspruchsvolle sollte unkompliziert sein. Das Definieren hierarchischer benutzerdefinierter Partitionierung mit dem vollständigen Satz von Iceberg Partitionstransformationen oder das Ziehen eines bestimmten Protobuf-Nachrichtentyps aus einem Subject, um Ihr Iceberg-Tabellenschema zu werden, sind wieder nur deklarative einzeilige Topic-Eigenschaften. Schemas können sich anmutig entwickeln, da Redpanda In-Place-Tabellenentwicklung anwendet. Und wenn Sie müssen, führen Sie einen einfachen SMT in Ihrer bevorzugten Sprache aus, der komplexe Nachrichten von einem Roh-Topic in einfachere Iceberg-Fakten-Tabellen über integrierte Data Transforms, die von WebAssembly angetrieben werden, verteilt. Das ultimative Ziel ist die einstufige Landung von Analyse-bereiten Daten. Boom, hallo Bronze-Schicht.
Der Hintergrund für all diese Innovationen ist natürlich das sich schnell entwickelnde Apache Iceberg-Projekt und seine Spezifikationen sowie Redpandas allgemeines Engagement für offene Standards. Dieses Engagement begann mit der frühen Unterstützung des Kafka-Protokolls, des Schema-Registrierung und der HTTP-Proxy-APIs und sogar anderer Details wie der Standard-Topic-Konfiguration, die es Organisationen ermöglicht, einen gesamten Bestand an Kafka-Anwendungen unverändert zu migrieren. Im Iceberg-Bereich hat sich Redpanda als engagierter Pionier in der Community hervorgetan und einen vollständigen C++ Iceberg-Client von Grund auf neu implementiert (etwas, das nicht Open Source verfügbar ist). Dieser Client unterstützt die vollständige Iceberg V2-Tabellenspezifikation, alle Schema-Evolutionsregeln und Partitionstransformationen. Auf der Iceberg-Katalogseite liefert Redpanda sowohl einen dateibasierten Katalog als auch spricht Iceberg REST für Operationen wie Erstellen, Committen, Aktualisieren und Löschen in Remote-Katalogen wie Unity Catalog und unterstützt OIDC-Authentifizierung, wobei Ihre Unity Catalog-Anmeldeinformationen umsichtig als Geheimnis behandelt werden, das transparent in Ihrem Cloud-Anbieter-Secrets-Manager verschlüsselt ist. Redpanda hat auch eng mit Databricks und anderen Iceberg-Führern zusammengearbeitet, um zu untersuchen, wie die Spezifikation erweitert werden kann, um semi-strukturierte Stream-Daten über den Variant-Typ zu unterstützen und die Verwaltung von Tabellen-RBAC nahtloser zu gestalten, indem Richtlinien zwischen den beiden Plattformen synchronisiert werden. Diese Standardisierung und die ständige Implementierung nach der Spezifikation bedeuten auch minimale Anbieterbindung. Organisationen sind immer frei, jedes Teil des Systems auszutauschen, wenn sie eine bessere Option finden: die Streaming-Plattform, den Iceberg-Katalog oder das Lakehouse, das die Tabellen abfragt/verarbeitet.
Wenn Sie bis hierher gekommen sind, hoffen wir aufrichtig, dass Sie ein Gefühl für die durchdachte Strenge in Redpandas Ansatz für diese heiß umkämpfte Marktchance bekommen haben, die aus einer starken Ingenieurskultur und der Leidenschaft für den Aufbau robuster Produkte resultiert. Als Technologen im Herzen mit soliden Erfolgsbilanzen und mit unserem Fokus insbesondere auf den BYOC-Formfaktor sind Redpanda und Databricks perfekt aufeinander abgestimmt, um zwei erstklassige Plattformen zu liefern, die sich wie eine anfühlen und verhalten, und die für Sie das Problem der Datenübertragung zur Analyse löst.
Probieren Sie Iceberg Topics mit Unity Catalog mit Redpandas einzigartigem Bring-Your-Own-Cloud Angebot noch heute aus. Oder starten Sie mit einer kostenlosen Testversion unserer selbstverwalteten Variante, Redpanda Enterprise!: https://cloud.redpanda.com/try-enterprise.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.