Zuverlässige LLM-Inferenz im großen Maßstab
Erkenntnisse aus dem Aufbau einer zuverlässigen LLM-Inferenzinfrastruktur
von Ying Chen, Wendy Hu, Ankit Mathur, Mike Eastham, Pei-Lun Liao, Wai Wu und Arjun DCunha
- Multi-tenant LLM-Serving erfordert Überlegungen zur Kapazität über Workloads hinweg. „Model Units“ bieten eine VM-ähnliche Abstraktion, die es ermöglicht, GPU-Ressourcen pro Kunde zuzuweisen, zu routen und zu skalieren.
- Kostenbewusstes Load Balancing und Autoscaling, basierend auf Model Units, sparten über 80 % der GPU-Kosten im Vergleich zur statischen Bereitstellung bei gleichzeitiger Einhaltung der Latenzziele.
- Laufzeit-Zuverlässigkeitsmechanismen wie Black-Box-Health-Checks erkennen und beheben stille Fehler automatisch, während die Profilerstellung multimodaler Engpässe zu 3-fachen Durchsatzsteigerungen führte.
Bei Databricks haben wir eine einzigartige Inferenzplattform entwickelt, die jedes Frontier-Modell bedient, von Open-Source-Modellen wie Kimi und Qwen bis hin zu proprietären Modellen wie OpenAI, Gemini und Claude. Wir ermöglichen die Inferenz für einige der größten agentenbasierten Anwendungen der Welt, darunter Superhuman, Yipit Data, Fox Sports und andere. Heute bedienen wir mehr als 120 Billionen Tokens pro Monat.
Was das LLM-Serving im großen Maßstab schwierig macht, ist die Zuverlässigkeit. Da Agenten zur Schnittstelle werden, wie wir arbeiten und leben, wächst die Inferenznachfrage exponentiell. Wir sehen extrem sprunghafte Nachfragekurven, die während der Arbeitszeit ihren Höhepunkt erreichen.
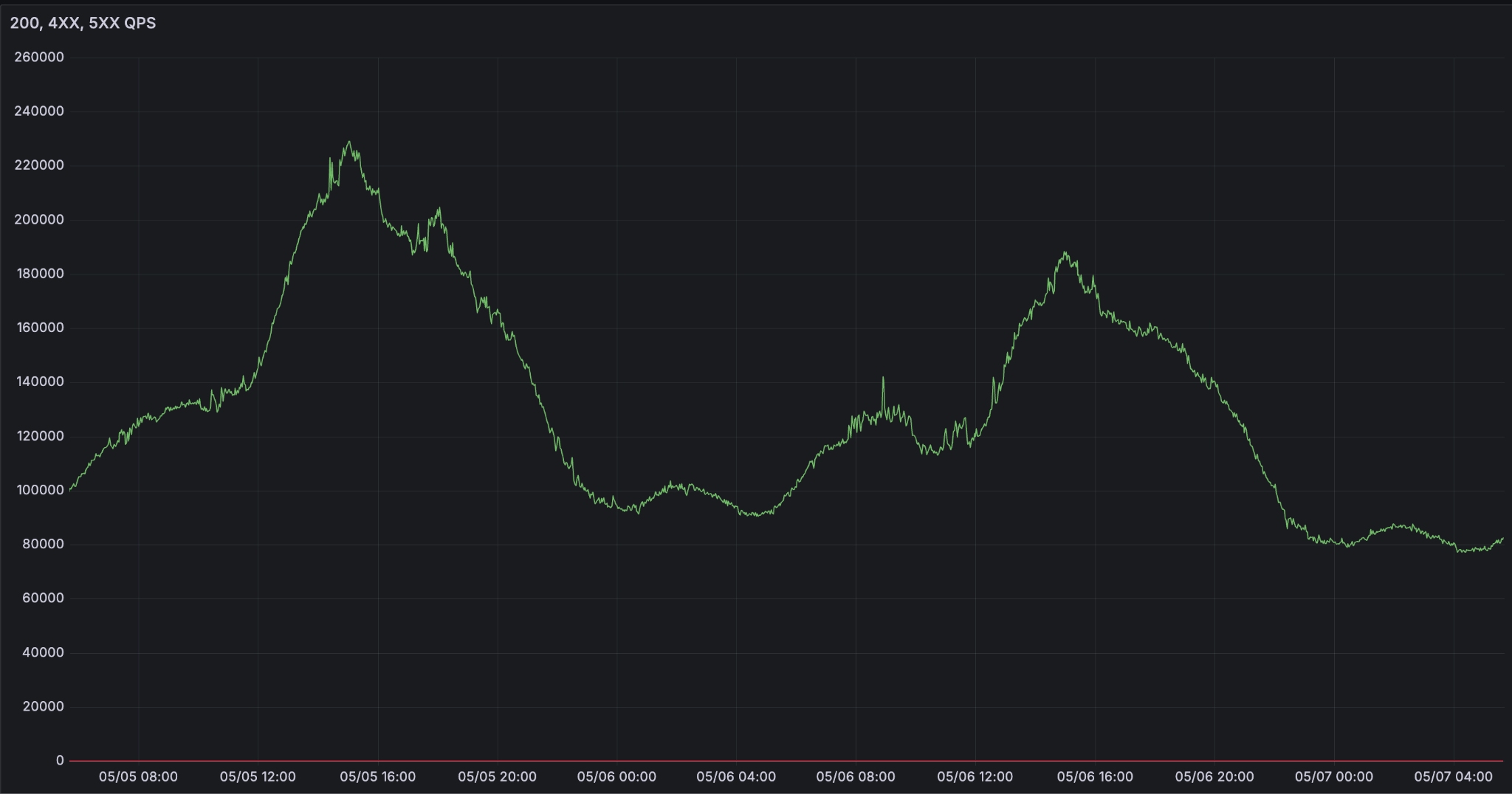
Herausforderungen beim Betrieb von LLM-Inferenz im großen Maßstab
Was bedeutet es, eine zuverlässige Inferenzplattform zu sein? Der Vertrag erscheint einfach. Verfügbarkeit bedeutet, ob die Anfrage bearbeitet werden kann. Aber in der Praxis haben verschiedene Anwendungsfälle erheblich unterschiedliche Latenzanforderungen, und dies wirkt sich auf die Verfügbarkeit aus. Die fortschrittlichsten Agenten können es sich nicht leisten, dass die p95 Zeit bis zum ersten Token (TTFT) und die Ausgabe-Tokens pro Sekunde (OPTS) schlechter werden.
In einem Mandantensystem für LLM-Serving ist es eine Herausforderung, sowohl Zuverlässigkeit als auch Latenz zu erreichen.
Zuverlässigkeit
Frontier-Leistung erfordert die neuesten GPUs mit Hochbandbreiten-Interconnects für die KV-Cache-Übertragung. Diese Compute-Setups sind grundsätzlich weniger zuverlässig als klassische CPU-Systeme und teuer. Da eine All-to-All-Kommunikation erforderlich ist, erfordert der Ausfall eines einzelnen Knotens eine Neukonfiguration für mehrere andere Knoten in disaggregierten Prefill/Decode-Setups. Die höchste Netzwerkbandbreite erfordert eine Single-Spine-Konnektivität in einem einzigen physischen Rack (z. B. NVL72-Systeme). Das bedeutet, dass Ausfälle in bestimmten Systemen innerhalb eines einzelnen Rechenzentrums-Racks zu einem Ausfall mit großer Reichweite führen können. Standardtricks in verteilten Systemen wie Multi-AZ oder die Nutzung von Backup-Instanztypen bedeuten, dass teure Backup-GPUs im Leerlauf gehalten werden, was eine kostenunerschwingliche Option ist. Überbereitstellung ist ein weiterer klassischer Trick, aber da das Compute-Angebot so begrenzt ist, ist es extrem teuer und unpraktisch. Daher müssen die Systeme unter starker Belastung betriebsbereit bleiben.
Die Liefergeschwindigkeit muss auch unter diesen Einschränkungen hoch bleiben – unsere Inferenznachfrage ist im Jahresvergleich um mehrere Größenordnungen gestiegen, und die Förderung dieses Wachstums bei gleichzeitiger Bereitstellung innovativer Funktionen war eine Herausforderung. Funktionen wie Bilder, Videos und Sicherheitsklassifizierung erfordern jeweils unterschiedliche Vorverarbeitungssysteme, die alle unabhängig voneinander skaliert werden müssen.
Schließlich erfordert das Erreichen von Best-in-Class-Leistung und die Unterstützung neuer Modellarchitekturen Optimierungen, die von benutzerdefinierten Kernels bis hin zu proprietären Inferenz-Engines reichen. Wenn sich Architekturen subtil ändern, wird oft neue Low-Level-Software eingeführt, die im großen Maßstab auf undurchsichtige Weise fehlschlagen kann und in schwierigen Debugging-Szenarien von Serverhängern bis zu GPU-Abstürzen auftritt.
Latenz
Die Latenz mit unterschiedlichen Lastmustern unter Kontrolle zu halten, ist eine Herausforderung. Dies liegt daran, dass die Kosten für die Bearbeitung einer Anfrage stark variieren und im Voraus schwer abzuschätzen sind. Selbst gesunde Server verarbeiten unter höherer Last alle Anfragen langsamer, was einen Kompromiss zwischen Durchsatz (und damit Kosteneffizienz) und der schnellsten Latenz, die Produkte zur Handhabung benötigen, aufzeigt. Dies kann sich auch als Zuverlässigkeitsproblem manifestieren, da Server sehr schnell unerwartet in einen ungesunden Zustand geraten können, basierend auf der Mischung der ihnen zugewiesenen Anfragen.
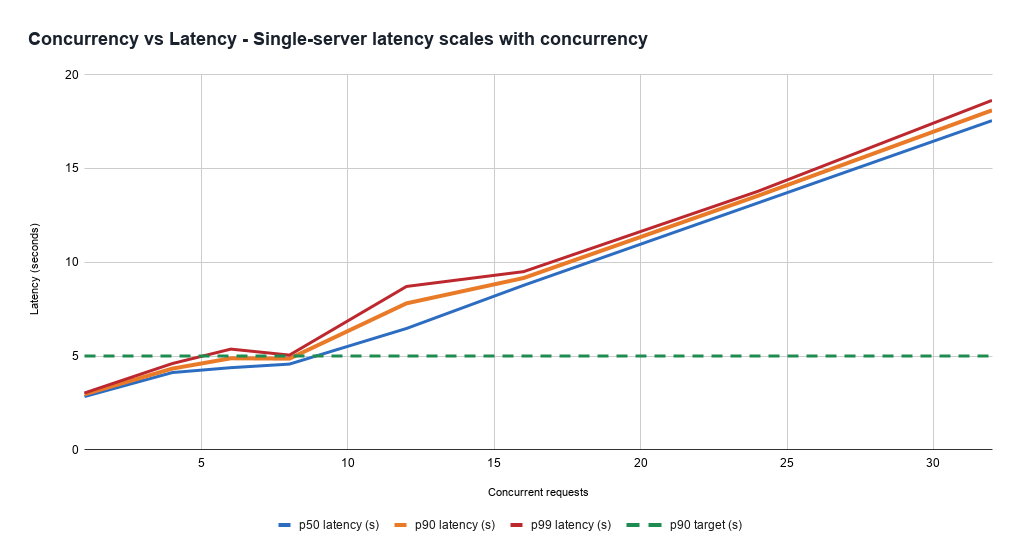
Darüber hinaus wird die Latenz durch die Ausgabe-Token-Generierung dominiert, aber die Vorkalkulation der Kosten ist schwierig, da schwer vorherzusagen ist, wie lange das Modell sprechen wird. Daher erfordert Low-Latency-Serving komplexe Kapazitätsmanagement-, Load-Balancing- und Anfragerangifizierungs-Systeme.
Gesamtarchitektur
Bevor wir uns den spezifischen Problemen widmen, werfen wir einen Blick auf einen Überblick über unsere Serving-Infrastruktur.
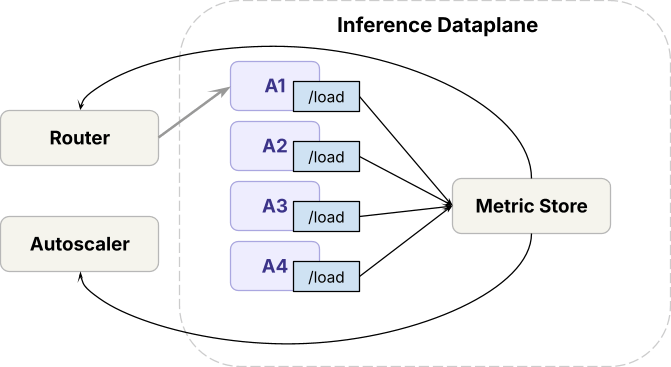
In der Datenebene,
- Die Inferenzlaufzeit (Open-Source- und proprietäre Inhouse-Engines) wird auf Frontier-GPUs bereitgestellt
- Zur Verarbeitung des Traffics über Modellbereitstellungen hinweg verfügt die Datenebene über einen Router, den wir Axon nennen und der die Last zwischen Replikaten desselben Modells ausgleicht, sowie einen Autoscaler, der die Replikatanzahl anpasst.
In der Steuerebene,
- Anfragen durchlaufen ein Ratenlimit, bevor sie die Datenebene erreichen.
- Basierend auf den Anfragemetriken bestimmt der Kapazitätsmanagement-Algorithmus, wie viel GPU-Kapazität jede Arbeitslast erhält, was der Autoscaler dann durchsetzt.
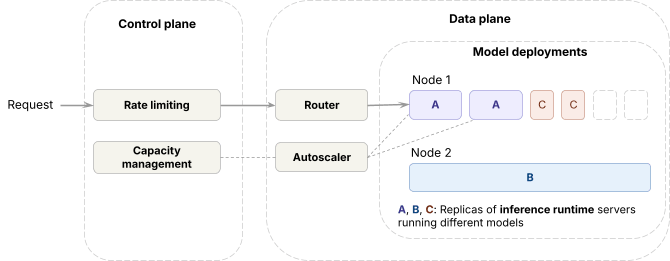
Kapazität im Griff behalten
Wir müssen in der Lage sein, die Kapazität ungefähr zu bewerten – wie viel wir haben, wie viel wir verkauft haben und wie viel Kunden nutzen. Dazu haben wir eine Abstraktion namens „Modelleinheiten“ eingeführt. Wenn wir davon ausgehen, dass eine Replikation eine feste Anzahl von Modelleinheiten pro Minute verarbeiten kann (z. B. 100), können wir folgende Annahmen treffen:
- Anfragen mit langem Eingabe- oder Ausgabefeld verbrauchen mehr Modelleinheiten, da in demselben Zeitfenster weniger abgeschlossen werden können.
- Prefill und Decode haben unterschiedliche Durchsatzeigenschaften, daher kosten Anfragen mit langer Ausgabe mehr als solche mit langer Eingabe.
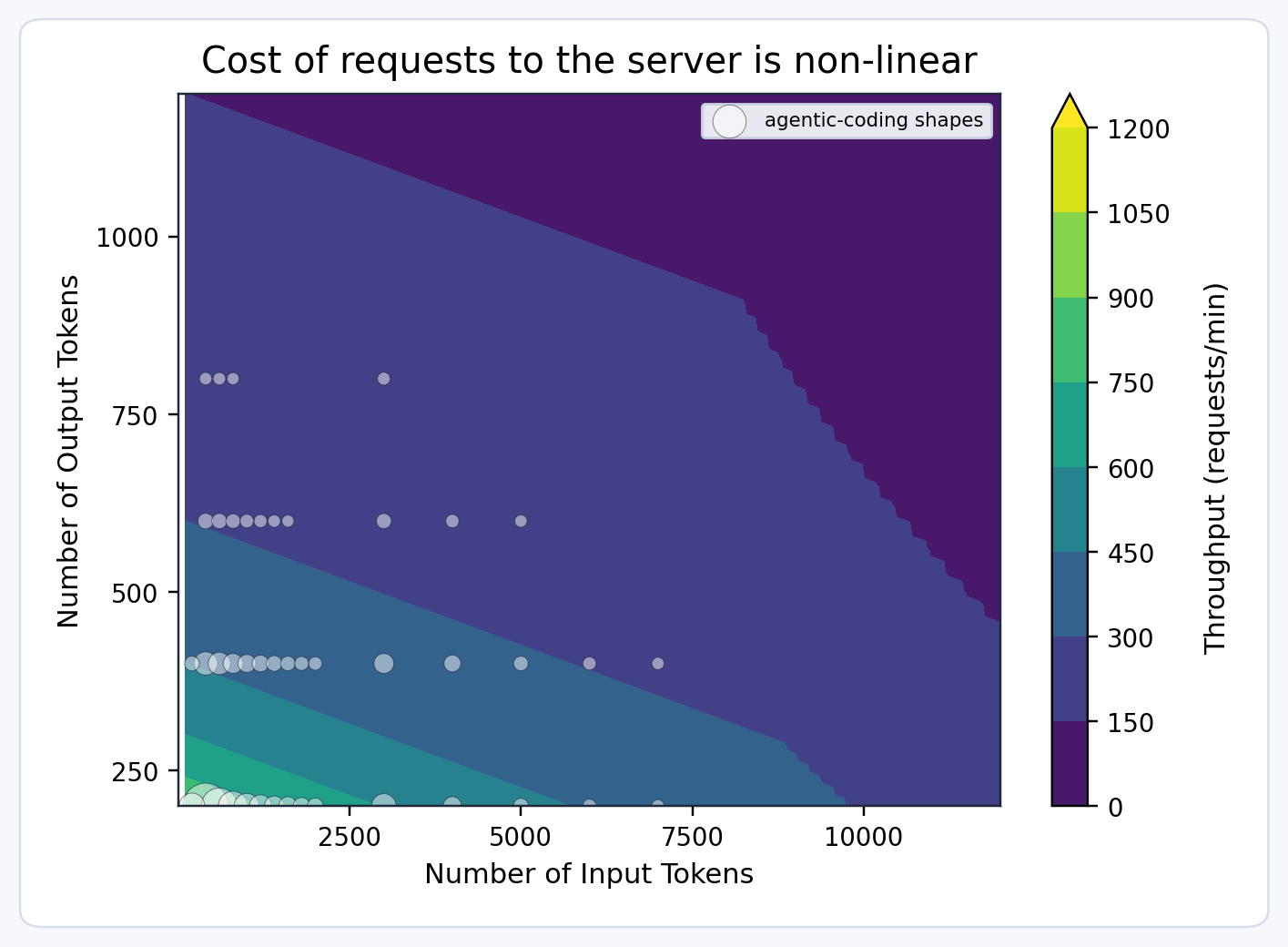
Daher modellieren wir die Anfragekosten mit einer multidimensionalen Funktion wie:
Die Koeffizienten α, β, γ werden durch automatisiertes Benchmarking für jedes Modell auf jedem Hardwaretyp bestimmt. Modelleinheiten können für Optimierungen wie Prefix-Caching weiter angepasst werden und müssen Funktionen wie Multimodalität berücksichtigen.
Solche Schätzungen sind strukturell unvollkommen, aber sie dienen uns als Möglichkeit, ein Mandantensystem in etwas Handhabbareres zu zerlegen, das Cloud-VMs ähnelt. VMs bieten die wünschenswerte Eigenschaft, eine vorhersagbare Leistung zu bieten, die bestimmten Kunden zugewiesen werden kann. Für produktive agentenbasierte Arbeitslasten ist es wichtig, Garantien für niedrige Latenz und Kapazität anzubieten, und ohne solche Zuweisungssysteme können wir höchstens eine „Best-Effort“-Kapazität anbieten, die zurückgefordert werden kann, wenn zu viele Kunden das System nutzen.
Kostenbasierte Lastverteilung und Autoskalierung
Da Anfragen einen stark variablen Einfluss auf die Server haben, ist es wichtig, nahezu optimale Routing-Entscheidungen zu treffen. Im Allgemeinen neigt die Lastverteilung dazu, sich auf statistische Ansätze wie P2C (Power of Two Choices) zu stützen, die die Last basierend auf der Warteschlangengröße schätzen und Stichproben nutzen, um den Speicher- und Latenzaufwand für das Verständnis aller möglichen Ziele zu reduzieren. LLM-Latenzen sind jedoch tendenziell hoch, die Serveranzahl ist geringer als bei skalierten CPU-Systemen, und die Kosten für Fehlrouten sind gravierend. Daher erfordert LLM-Serving einen anderen Ansatz.
Heute verwenden wir Dicer, Databricks' Auto-Sharder, um Arbeitslasten dynamisch über Server zu routen. Ohne lastabhängiges Routing verursachen Anfragen mit langem Kontext einzelne Server zu Hotspots, während andere unterausgelastet bleiben. Wir haben Modelleinheiten in Dicer integriert, sodass Routing-Entscheidungen auf der Serverlast in Modelleinheiten und nicht auf traditionellen anfragebasierten Heuristiken beruhen. Dicer bietet auch zustandsbehaftete Sitzungen, wodurch das Anfragerouting „sticky“ wird. Die Anfragen einer Arbeitslast gehen nur an eine Teilmenge von Servern, was die Cache-Trefferraten (entscheidend für latenzempfindliche Arbeitslasten wie Coding-Agenten) verbessert und den Wirkungsbereich begrenzt.
Wir können auch die Lastmetriken optimieren und zukünftig sogar optimalere Routing-Systeme basierend auf höherwertigen Kostenmetriken nutzen, wenn wir mehr lernen.
Ein ähnliches Problem besteht beim Autoscaling. Allein die Anzahl der ausstehenden Anfragen spiegelt nicht die tatsächliche Last wider. Eine Zunahme von Anfragen mit langem Kontext sieht genauso aus wie eine Zunahme von kurzen Anfragen, und CPU- und Speichermetriken korrelieren ebenfalls nicht mit der tatsächlichen GPU-Auslastung.
Mithilfe von Modelleinheiten kann unser Autoscaler entscheiden, ob er basierend auf dem Modelleinheiten-Auslastungsverhältnis hoch- oder runterskaliert. Wenn die Inferenz-Engine nahe einem bestimmten Prozentsatz ihrer maximalen Modelleinheiten läuft (bestimmt durch Hardwaretyp und Workload-Form), nähert sie sich dem maximalen Durchsatz, was ein Hochskalieren auslöst. Das Gegenteil löst ein Herunterskalieren aus. Anstatt die Autoscaling-Regeln für jedes Modell manuell anzupassen, ermöglicht dieser Ansatz eine modellunabhängige Skalierungsinfrastruktur.
Durch den Aufbau von Autoscaling auf LLM-Inferenzmustern konnten wir vermeiden, immer auf die maximale Anzahl von Replikaten zu skalieren. Bei Modellen mit burstartigem Datenverkehr hielt das Autoscaling die Anzahl der Replikate nahe der tatsächlichen Nachfrage, was zu über 80 % GPU-Einsparungen im Vergleich zur statischen Bereitstellung bei Spitzenlast führte.
Laufzeit-Zuverlässigkeit
Intelligentes Routing und Skalierung boten eine gute Grundlage, aber sie verhindern keine Fehler auf Engine-Ebene. Unabhängig davon, welche Inferenz-Engine wir einsetzen (unsere eigene Engine oder beliebte Open-Source-Optionen), treten Randfälle und Ressourcenkonflikte im Produktionsmaßstab auf. Wir benötigen Mechanismen, um Fehler automatisch zu erkennen und zu beheben.
Erkennung und Behebung von stillen Fehlern
Ein Fehlerfall, auf den wir stoßen, sind stille Hänger. Anfragen, die Randfälle betreffen (strukturierte Ausgabe, multimodale Eingaben), können unbehandelte Fehler in der Multi-Prozess-Architektur von Inferenz-Engines auslösen, wodurch Server aufhören zu antworten, ohne Fehler anzuzeigen.
Wir erkennen dies mit periodischen Black-Box-Health-Checks: minimale End-to-End-Anfragen, die gesendet werden, wenn keine echten Anfragen kürzlich abgeschlossen wurden. Wenn ein Health-Check fehlschlägt, startet die Kubernetes Liveness-Prüfung den Server neu. Dies funktioniert für alle Engines unabhängig von der internen Implementierung.
Unter hoher Last können jedoch auch Health-Checks selbst zu Timeouts führen, wodurch die Liveness-Prüfung Server beendet, die tatsächlich fehlerfrei sind. Dies birgt die Gefahr von kaskadierenden Fehlern. Um dies zu lösen, weisen wir Health-Check-Anfragen die höchste Planungs-Priorität zu, um sicherzustellen, dass sie auch unter hoher Last abgeschlossen werden. Mit priorisierten Health-Checks dauert der gesamte Zyklus der Erkennung eines Hängers, der Beendigung des fehlerhaften Servers und der Wiederherstellung weniger als 5 Minuten. Die Anzahl der fehlerhaften Liveness-Prüfungen sank von mehreren pro Woche auf null.
Umgang mit unerwarteter Last durch multimodale Anfragen
Als große Stapel multimodaler Anfragen eintrafen, sahen wir Spitzen bei den Fehlerraten und Timeouts aus einer völlig anderen Quelle.
Untersuchungen ergaben, dass die Anfragen die Kernprozesse der Inferenz-Engine gar nicht erreichten. Die Bereitstellung von Bildanfragen ist ressourcenintensiver als reine Textanfragen, nicht nur wegen des zusätzlichen Vision Encoders, der auf GPUs läuft, sondern auch wegen der CPU-intensiven Bildverarbeitung. Bei bestimmten Modellen war die Bildverarbeitung extrem langsam und blockierte die Event-Schleife vollständig.
Das Verschieben blockierender Operationen in separate Threads und Prozesse löste das Problem nicht; die Anfragen stapelten sich weiterhin unter hoher Bildlast. Also haben wir die Python-Prozesse profiliert und mehrere Entdeckungen gemacht:
- Von allen CPU-Operationen für Bilder ist die Bildverarbeitung (Größenänderung und Normalisierung) 10-mal langsamer als andere Operationen wie die Base64-Dekodierung.
- Einige Hugging Face-Modelle verwenden standardmäßig den PIL-basierten Bildprozessor, während andere den schnelleren Torchvision-basierten Prozessor verwenden.
- In containerisierten Umgebungen ist OMP_NUM_THREADS (das die Anzahl der von Torch für CPU-Operationen verwendeten OpenMP-Threads steuert) standardmäßig auf die Anzahl der vCPUs auf dem Host-System eingestellt. In Mandantenumgebungen ist dies eine schlechte Standardeinstellung: Ein Host kann 192 vCPUs haben, aber ein Container hat nur Zugriff auf 12. Das Ergebnis sind weitaus mehr laufende Threads als verfügbare Kerne. Dies treibt die CPU-Auslastung über das Limit des Containers hinaus und löst Drosselung aus.
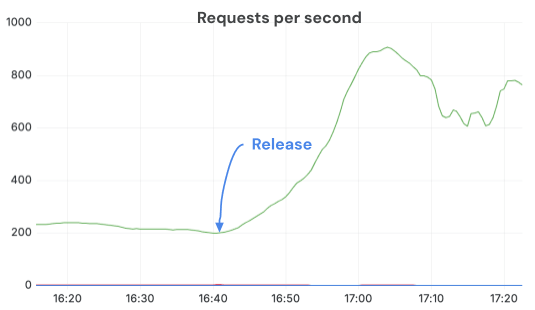
Durch den Wechsel zu Torchvision-basierten Bildprozessoren und die korrekte Konfiguration von OMP_NUM_THREADS konnten wir deutlich höhere QPS aufrechterhalten und die GPUs voll auslasten. Nach der Bereitstellung des Fixes sprang die Anzahl der abgeschlossenen Anfragen pro Sekunde um >3x bei gleicher Anzahl von Replikaten und Last. Die CPU-Drosselung verschwand, und die Server liefen in einem wesentlich gesünderen Zustand.
Fazit
Die zuverlässige Bereitstellung von LLMs im großen Maßstab erfordert Arbeit auf jeder Ebene des Inferenz-Stacks. Wir haben die Autoscaling- und Load-Balancing-Infrastruktur für LLM-Workloads sowie Laufzeitmechanismen behandelt, die unabhängig von der Engine oder dem Workload stabil bleiben. Es gibt noch viel mehr zu erzählen: schneller Containerstart, sichere Rollouts über GPU-Flotten hinweg, GPU-Kapazitätsmanagement über Clouds und Regionen hinweg. Wenn dies die Art von Problemen ist, an denen Sie arbeiten möchten, stellen wir ein!
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.