Skalierung kleiner LLMs mit NVIDIA MPS
Kleine Modelle werden rapide leistungsfähiger und sind für eine Vielzahl von Anwendungsfällen in Unternehmen einsetzbar. Gleichzeitig bietet jede neue GPU-Generation dramatisch mehr compute und Speicherbandbreite. Das Ergebnis? Selbst bei Workloads mit high concurrency lassen kleine LLMs oft einen großen Teil der GPU-Compute und Speicherbandbreite inaktiv.
Mit Anwendungsfällen wie Code-Vervollständigung, Retrieval, Grammatikkorrektur oder spezialisierten Modellen betreiben unsere Unternehmenskunden viele solcher kleinen Sprachmodelle auf Databricks, und wir bringen die GPUs ständig an ihre Grenzen. Der Multi-Process Dienst (MPS) von NVIDIA sah wie ein vielversprechendes Tool aus: Er ermöglicht es mehreren Inferenzprozessen, einen einzigen GPU-Kontext gemeinsam zu nutzen, sodass sich deren Speicher- und Compute-Operationen überlappen können – wodurch aus derselben Hardware effektiv weitaus mehr Arbeit herausgeholt wird.
Wir haben rigoros getestet, ob MPS in unseren Produktionsumgebungen einen höheren Durchsatz pro GPU liefert. Wir haben festgestellt, dass MPS in diesen Bereichen signifikante Durchsatzsteigerungen liefert:
- Sehr kleine Sprachmodelle (≤3 Mrd. Parameter) mit kurzem bis mittlerem Kontext (<2k Tokens)
- Sehr kleine Sprachmodelle (<3B) in reinen Prefill-Workloads
- Engines mit signifikantem CPU-Overhead
Die Schlüsselerklärung, basierend auf unseren Ablationsstudien, ist zweigeteilt: Auf GPU-Ebene ermöglicht MPS eine signifikante Kernel-Überlappung, wenn einzelne Engines die compute- oder Speicherbandbreite nicht vollständig ausnutzen – insbesondere während aufmerksamkeitsdominanter Phasen in kleinen Modellen. Als nützlicher Nebeneffekt kann es auch CPU-Engpässe wie Scheduler-Overhead oder Bildverarbeitungs-Overhead bei multimodalen Workloads abmildern, indem der gesamte Batch auf die Engines aufgeteilt wird, was die CPU-Last pro Engine reduziert.
Was ist MPS?
Der Multi-Process Service (MPS) von NVIDIA ist ein Feature, das es mehreren Prozessen ermöglicht, eine einzelne GPU effizienter zu nutzen, indem ihre CUDA-Kernel auf die Hardware gemultiplext werden. Wie es in der offiziellen Dokumentation von NVIDIA heißt:
Der Multi-Process Dienst (MPS) ist eine alternative, binärkompatible Implementierung des CUDA Application Programming Interface (API). Die MPS-Laufzeitarchitektur ist darauf ausgelegt, kooperative Multi-Prozess-CUDA-Anwendungen transparent zu ermöglichen.
Einfach ausgedrückt, bietet MPS eine binärkompatible CUDA-Implementierung innerhalb des Treibers, die es mehreren Prozessen (wie Inferenz-Engines) ermöglicht, die GPU effizienter gemeinsam zu nutzen. Anstatt dass Prozesse den Zugriff serialisieren (und die GPU zwischen den Zugriffen im Leerlauf lassen), werden ihre Kernel und Speichervorgänge vom MPS-Server gemultiplext und überlappt, wenn Ressourcen verfügbar sind.
Die Skalierungslandschaft: Wann hilft MPS?
Bei einer bestimmten Hardware-Konfiguration hängt die effektive Auslastung stark von der Modellgröße, der Architektur und der Kontextlänge ab. Da neuere große Sprachmodelle tendenziell auf ähnlichen Architekturen konvergieren, verwenden wir die Qwen2.5-Modellfamilie als repräsentatives Beispiel, um die Auswirkungen von Modellgröße und Kontextlänge zu untersuchen.
In den folgenden Experimenten wurden zwei identische Inferenz-Engines, die auf derselben NVIDIA H100-GPU (mit aktiviertem MPS) liefen, mit einer Single-Instance-Baseline verglichen, wobei perfekt ausbalancierte, homogene Workloads verwendet wurden.
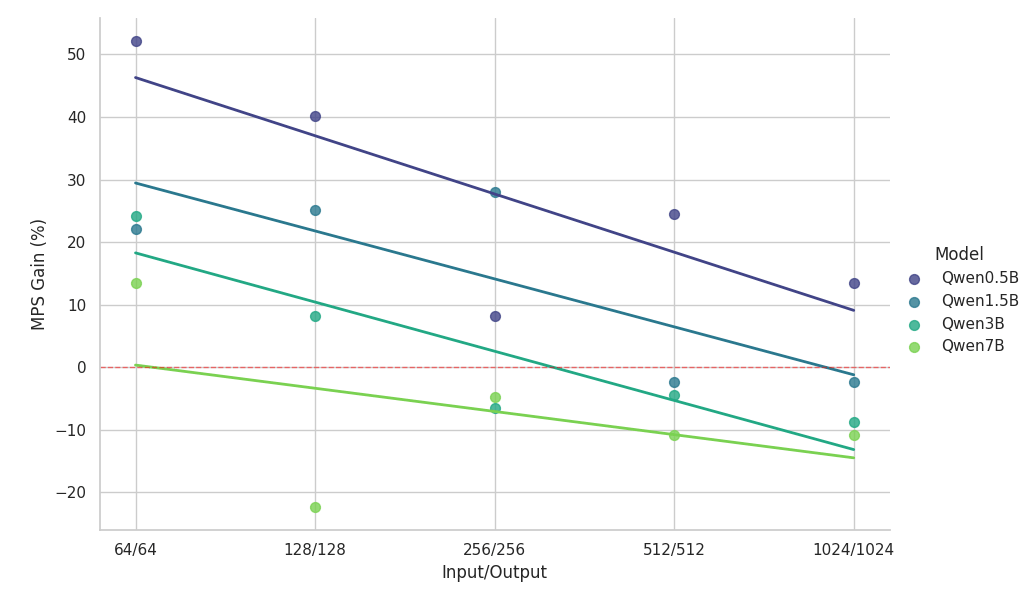
{kind=link}
Wichtige Beobachtungen aus der Skalierungsstudie:
- MPS liefert eine Durchsatzsteigerung von >50 % für kleine Modelle mit kurzen Kontexten.
- Die Zuwächse fallen mit zunehmender Kontextlänge log-linear ab – bei gleicher Modellgröße.
- Die Verbesserungen nehmen mit zunehmender Modellgröße schnell ab – selbst in kurzen Kontexten.
- Beim 7B-Modell oder 2k-Kontext fällt der Vorteil unter 10 % und führt schließlich zu einer Verlangsamung.
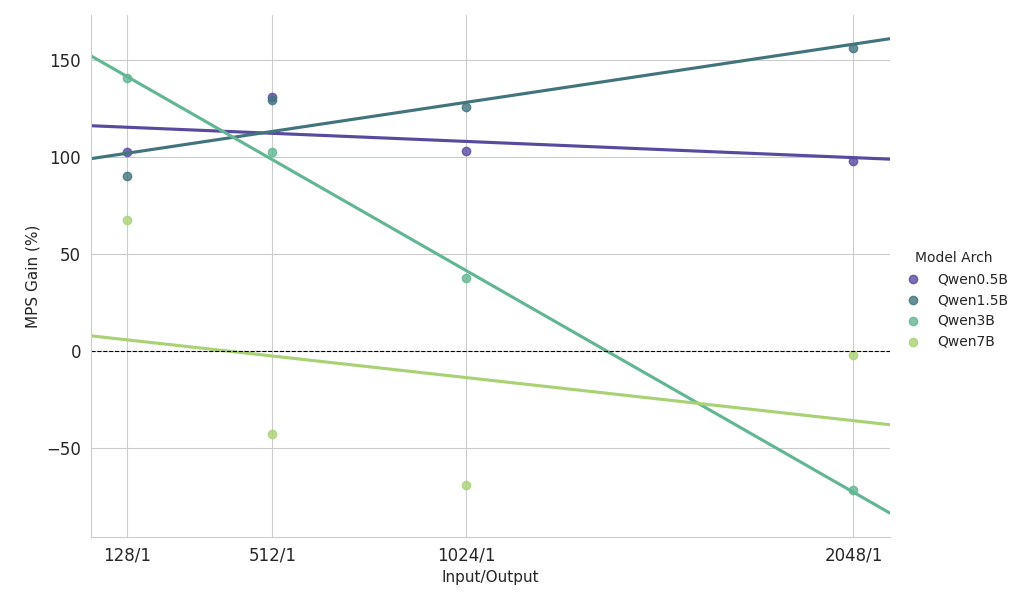
{kind=link}
Wesentliche Erkenntnisse aus der Skalierungsstudie zu prefill-lastigen Workloads
- Kleine Modelle (<3B): MPS liefert durchgängig eine Durchsatzsteigerung von über 100 %.
- Mittelgroße Modelle (~3B): Die Vorteile nehmen mit zunehmender Kontextlänge ab, was schließlich zu einer Performanceregression führt.
- Große Modelle (>3B): MPS bietet für diese Modellgrößen keinen Performancevorteil.
Die obigen Skalierungsergebnisse zeigen, dass die Vorteile von MPS bei Setups mit geringer GPU-Auslastung, kleinen Modellen und kurzem Kontext am ausgeprägtesten sind, da diese eine effektive Überlappung ermöglichen.
Analyse der Vorteile: Woher kommen die MPS-Vorteile wirklich?
Um den genauen Grund zu ermitteln, haben wir das Problem in seine beiden Kernbausteine moderner Transformer zerlegt: die MLP-Schichten (Multi-Layer Perceptron) und den Attention-Mechanismus. Durch die Isolierung jeder Komponente (und die Beseitigung anderer Störfaktoren wie dem CPU-Overhead) konnten wir die Zuwächse genauer zuordnen.
Benötigte GPU-Ressourcen | |||
| N = Kontextlänge | Prefill (compute) | Dekodieren (Speicherbandbreite) | Dekodieren (Berechnung) |
| MLP | O(N) | O(1) | O(1) |
| Attn | O(N^2) | O(N) | O(N) |
Transformer bestehen aus Attention- und MLP-Layern mit unterschiedlichem Skalierungsverhalten:
- MLP: Lädt Gewichte einmal; verarbeitet jeden Token unabhängig -> Konstante Speicherbandbreite und compute pro Token.
- Attention: Lädt KV-Cache und berechnet das Skalarprodukt mit allen vorherigen Tokens → Lineare Speicherbandbreite und Rechenleistung pro Token.
Vor diesem Hintergrund haben wir gezielte Ablationsstudien durchgeführt.
Reine MLP-Modelle (Attention entfernt)
Bei kleinen Modellen sättigt die MLP-Schicht die Compute möglicherweise nicht, selbst mit mehr Token pro Batch. Wir haben die Auswirkungen von MLP isoliert, indem wir den Attention-Block aus dem Modell entfernt haben.
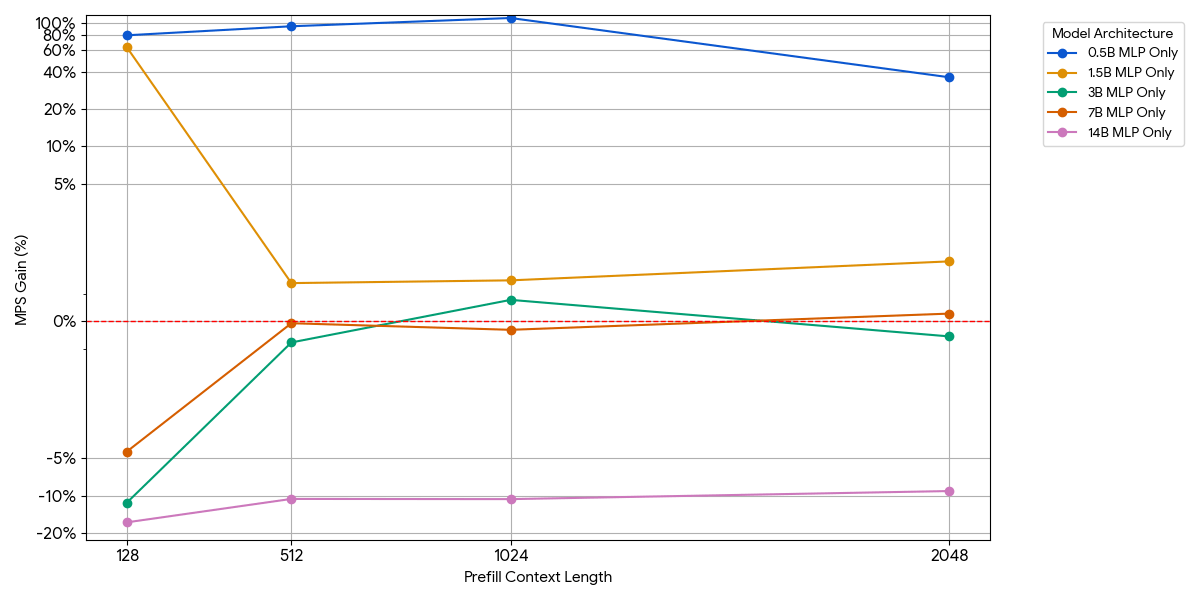
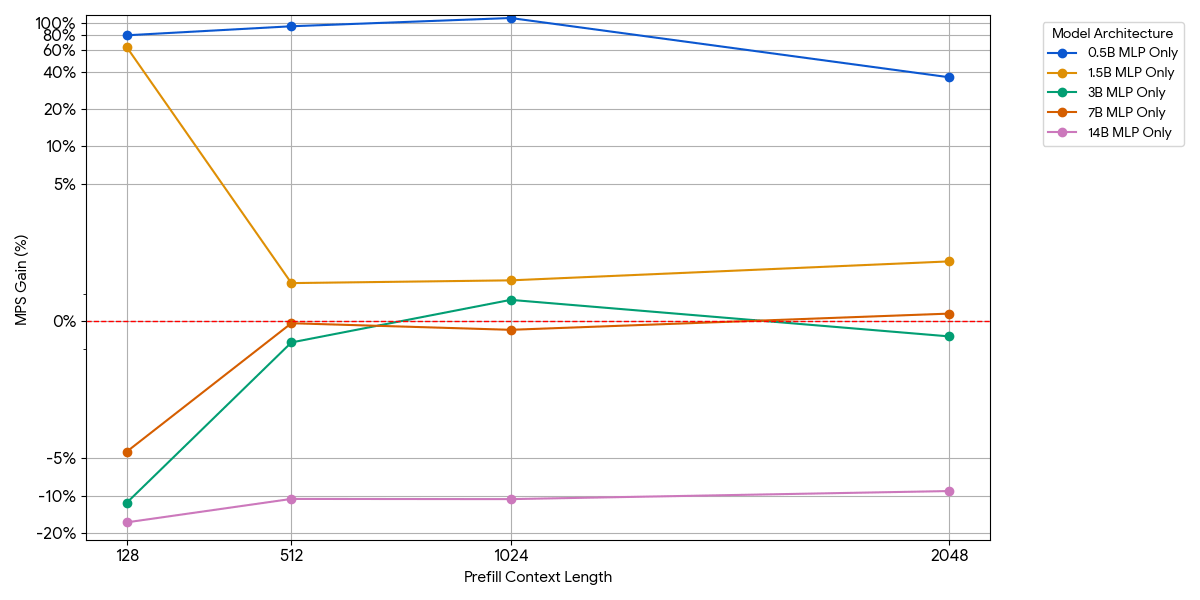{kind=link}
Wie in der obigen Abbildung gezeigt, sind die Zuwächse bescheiden und verschwinden schnell. Wenn die Modellgröße oder die Kontextlänge zunimmt, sättigt eine einzelne Engine bereits die compute (mehr FLOPs pro Token in größeren MLPs, mehr Tokens bei längeren Sequenzen). Sobald eine Engine rechengebunden ist, bringt der Betrieb von zwei gesättigten Engines fast keinen Vorteil – 1 + 1 <= 1.
Attention-Only-Modelle (MLP entfernt)
Nachdem wir nur begrenzte Verbesserungen durch das MLP sahen, haben wir Qwen2.5-3B und das reine Attention-Setup analog gemessen.
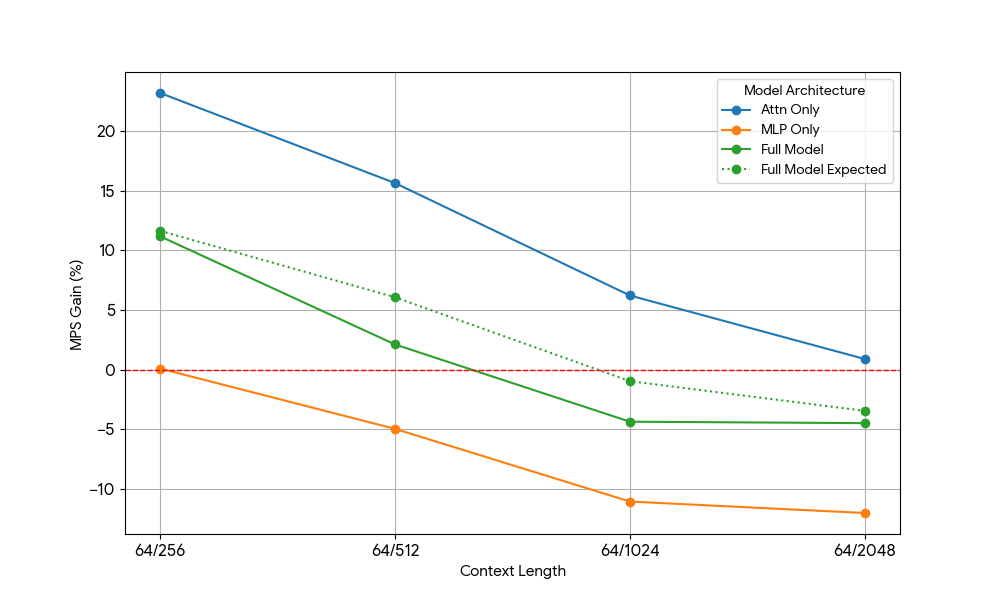
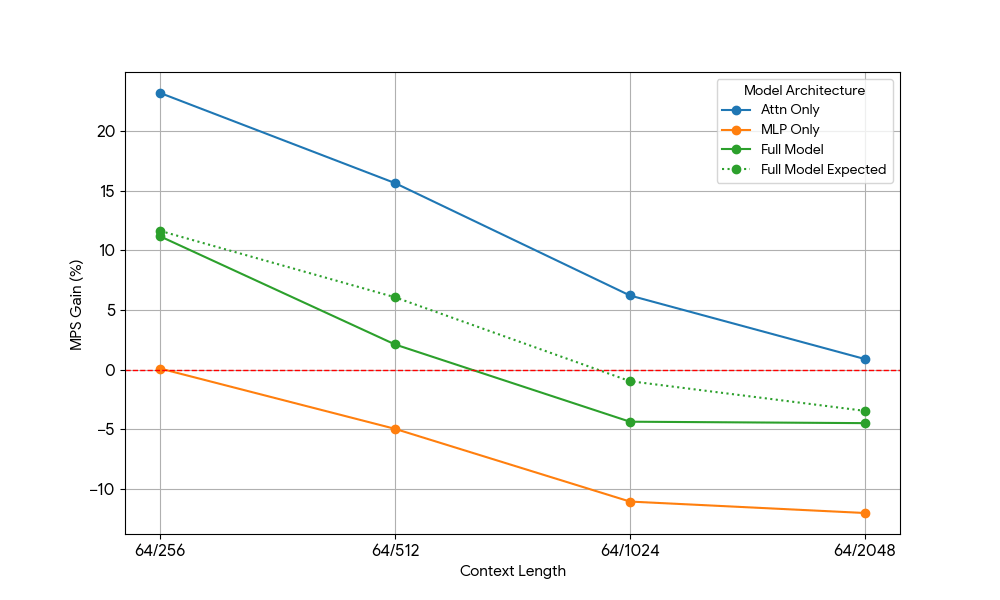{kind=link}
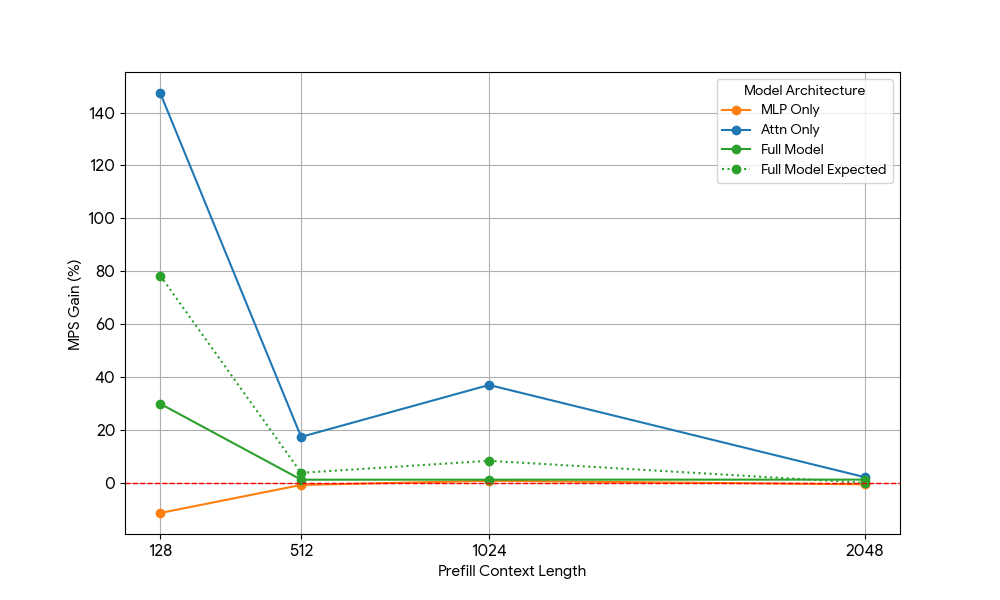
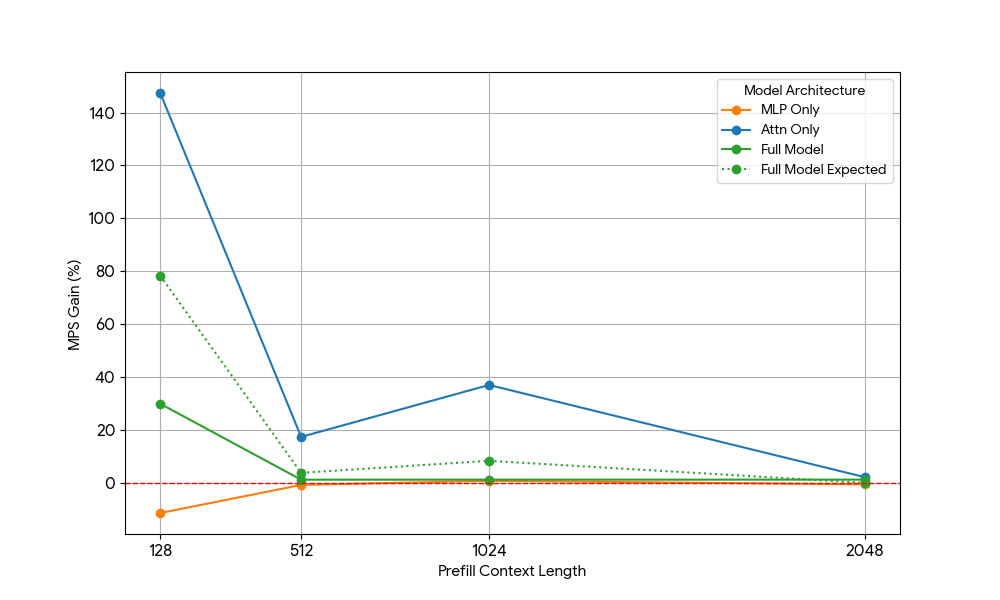{kind=link}
Die Ergebnisse waren beeindruckend:
- Reine Attention-Workloads zeigen signifikant größere MPS-Gewinne als das vollständige Modell, sowohl für Prefill als auch für Decode.
- Beim Decodieren nehmen die Verbesserungen linear mit der Kontextlänge ab, was unserer Erwartung entspricht, dass in der Decodierungsphase der Ressourcenbedarf für Attention mit der Kontextlänge wachsen.
- Beim Prefill sanken die Zuwächse schneller als beim Decode.
Stammt der MPS-Gewinn ausschließlich aus den Attention-Gewinnen, oder gibt es einen überlappenden Effekt zwischen Attention und MLP? Um dies zu untersuchen, haben wir den erwarteten Gesamtmodellgewinn als gewichteten Durchschnitt von „Nur Attention“ und „Nur MLP“ berechnet, wobei die Gewichtungen ihr Beitrag zur Wall Time sind. Dieser erwartete Gesamtmodellgewinn entspricht im Wesentlichen den Gewinnen aus reinen Attn-Attn- und MLP-MLP-Überlappungen, während die Attn-MLP-Überlappung nicht berücksichtigt wird.
Bei der Decode-Workload ist der erwartete Gewinn des vollständigen Modells geringfügig höher als der tatsächliche Gewinn, was auf einen begrenzten Einfluss der Attn-MLP-Überlappung hindeutet. Bei der Prefill-Workload ist der tatsächliche Gewinn des vollständigen Modells außerdem wesentlich geringer als die erwarteten Gewinne aus seq 128. Eine hypothetische Erklärung könnte sein, dass es weniger Gelegenheiten für die Überlappung des ungesättigten Attention-Kernels gibt, da die andere Engine einen erheblichen Teil der Zeit mit der Ausführung von gesättigtem MLP verbringt. Daher stammt der Großteil des MPS-Gewinns von 2 Engines mit ungesättigter Attention.
Zusätzlicher Vorteil: Rückgewinnung von GPU-Zeit, die durch CPU-Overhead verloren geht
Die obigen Ablationen konzentrierten sich auf GPU-gebundene Workloads, aber die schwerwiegendste Form der Unterauslastung tritt auf, wenn die GPU inaktiv auf CPU-Arbeit wartet – wie z. B. auf den Scheduler, die Tokenisierung oder die Bildvorverarbeitung in multimodalen Modellen.
In einer Konfiguration mit einer einzigen Engine verschwenden diese CPU-Stalls direkt GPU-Zyklen. Mit MPS kann eine zweite Engine die GPU übernehmen, sobald die erste von der CPU blockiert wird, wodurch Ausfallzeit in produktive compute umgewandelt wird.
Um diesen Effekt zu isolieren, wählten wir bewusst einen Bereich, in dem die früheren Zuwächse auf GPU-Ebene verschwunden waren: Gemma-4B (eine Größe und Kontextlänge, bei der Attention und MLP bereits gut ausgelastet sind, sodass die Vorteile der Kernel-Überlappung minimal sind).
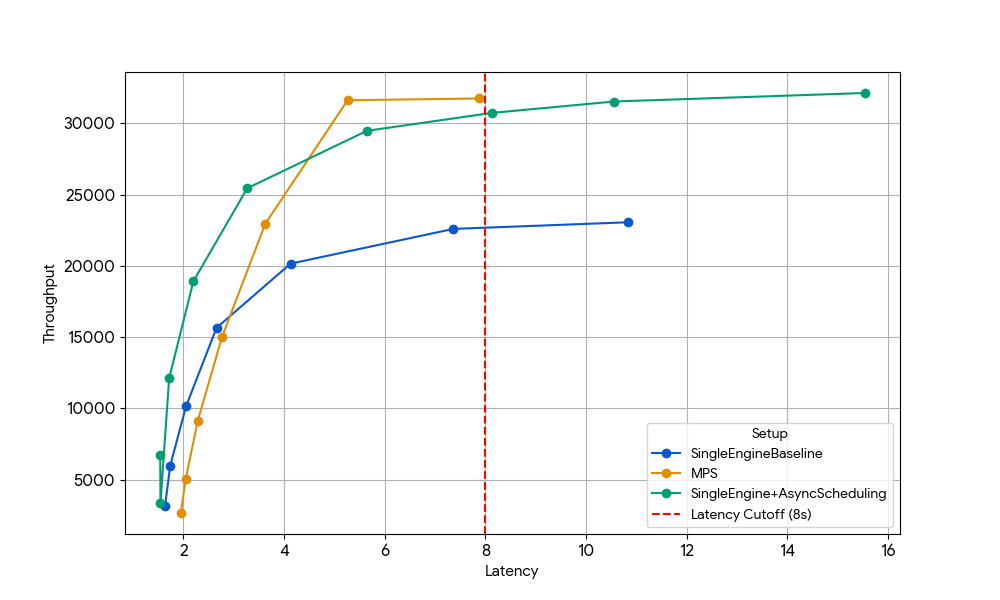
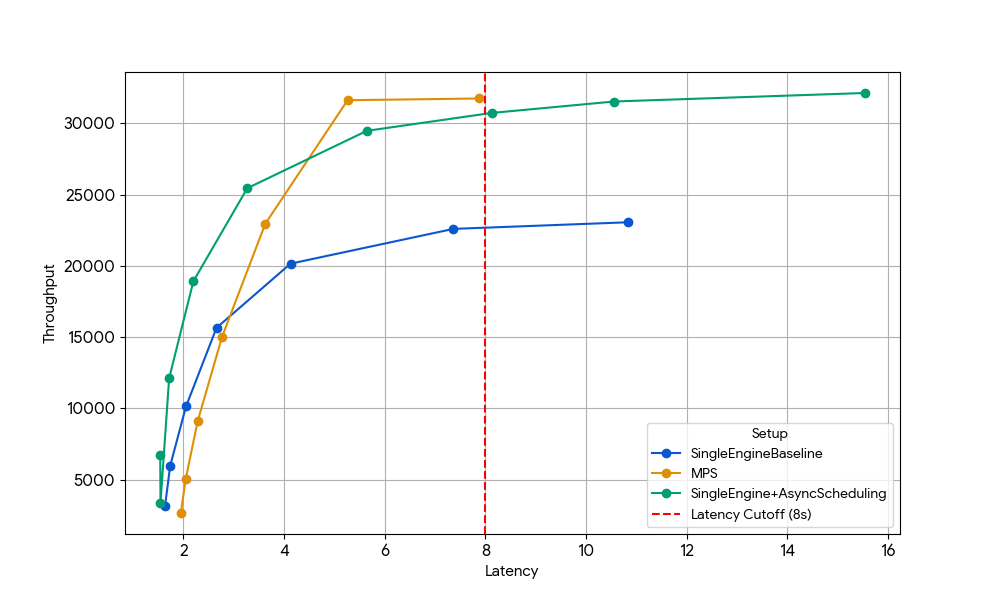{kind=link}
Bei einer Latenz von 8 s ist die einzelne Basis-Engine (blau) durch den CPU-Overhead des Schedulers begrenzt. Dieser kann entweder durch die Aktivierung des asynchronen Schedulings in vLLM (grüne Linie, +33 % Durchsatz) oder durch den Betrieb von zwei Engines mit MPS ohne asynchrones Scheduling (gelbe Linie, +35 % Durchsatz) aufgehoben werden. Dieser nahezu identische Zuwachs bestätigt, dass MPS in CPU-beschränkten Szenarien im Wesentlichen die gleiche inaktive GPU-Zeit zurückgewinnen kann, die durch asynchrones Scheduling eliminiert wird. MPS kann nützlich sein, da Vanilla vLLM v1.0 immer noch einen CPU-Overhead in der Scheduler-Schicht hat, in der Optimierungen wie asynchrones Scheduling nicht vollständig verfügbar sind.
Ein scharfes Geschoss, aber keine Wunderwaffe
Basierend auf unseren Experimenten kann MPS bei der Inferenz kleiner Modelle in einigen Betriebsbereichen signifikante Vorteile bringen:
- Engines mit signifikantem CPU-Overhead
- Sehr kleine Sprachmodelle (≤3 Mrd. Parameter) mit kurzem bis mittlerem Kontext (<2k Tokens)
- Sehr kleine Sprachmodelle (<3B) bei Prefill-lastigen Workloads
Außerhalb dieser optimalen Bereiche (z. B. 7B+-Modelle, langer Kontext >8k oder bereits rechenintensive Workloads) können die Vorteile auf GPU-Ebene von MPS nicht einfach genutzt werden.
Andererseits führte MPS auch operative Komplexität ein:
- Zusätzliche Komponenten: MPS-Daemon, Einrichtung der Client-Umgebung und ein Router/Load-Balancer, um den Traffic auf die Engines aufzuteilen
- Erhöhte Komplexität beim Debugging: keine Isolierung zwischen den Engines → ein Speicherleck oder OOM in einer Engine kann alle anderen, die sich die GPU teilen, beschädigen oder beenden.
- Monitoring-Aufwand: Wir müssen jetzt den Zustand des Daemons, den Verbindungsstatus des Clients, den Lastausgleich zwischen den Engines usw. überwachen.
- Anfällige Fehlermodi: Da alle Engines einen einzigen CUDA-Kontext und MPS-Daemon gemeinsam nutzen, kann ein einzelner fehlerhafter Client die gesamte GPU beschädigen oder aushungern, was sich sofort auf jede kollokierte Engine auswirkt.
Kurz gesagt: MPS ist ein scharfes, spezialisiertes Werkzeug – extrem effektiv in den oben beschriebenen, eng begrenzten Bereichen, aber selten ein allgemeiner Gewinn. Es hat uns wirklich Spaß gemacht, die Grenzen des GPU-Teilens auszuloten und herauszufinden, wo die wirklichen Performance-Klippen liegen. Im gesamten Inferenz-Stack gibt es noch ein enormes ungenutztes Potenzial an Performance und Kosteneffizienz. Wenn du dich für verteilte Serving-Systeme begeisterst oder dafür, LLMs in der Produktion 10x günstiger auszuführen, wir stellen ein!
Autoren: Xiaotong Jiang
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.