Vereinfachen Sie PySpark-Tests mit DataFrame-Gleichheitsfunktionen
Einführung in PySpark DataFrame-Gleichheitstestfunktionen, warum sie wichtig sind und wie sie verwendet werden.
von Haejoon Lee, Allison Wang und Amanda Liu
Die DataFrame-Gleichheitstestfunktionen wurden in Apache Spark™ 3.5 und Databricks Runtime 14.2 eingeführt, um PySpark-Unit-Tests zu vereinfachen. Der vollständige Funktionsumfang, der in diesem Blog-Post beschrieben wird, wird ab Apache Spark 4.0 und Databricks Runtime 14.3 verfügbar sein.
Schreiben Sie zuverlässigere DataFrame-Transformationen mit DataFrame-Gleichheitstestfunktionen
Die Arbeit mit Daten in PySpark umfasst das Anwenden von Transformationen, Aggregationen und Manipulationen auf DataFrames. Wie können Sie sicher sein, dass Ihr Code wie erwartet funktioniert, wenn sich Transformationen ansammeln? Die PySpark-Hilfsfunktionen für Gleichheitstests bieten eine effiziente und effektive Möglichkeit, Ihre Daten mit den erwarteten Ergebnissen zu vergleichen. So können Sie unerwartete Unterschiede erkennen und Fehler frühzeitig im Analyseprozess abfangen. Darüber hinaus geben sie intuitive Informationen zurück, die genau auf die Unterschiede hinweisen, sodass Sie sofort Maßnahmen ergreifen können, ohne viel Zeit mit dem Debuggen zu verbringen.
Verwenden von DataFrame-Gleichheitstestfunktionen
Zwei Gleichheitstestfunktionen für PySpark DataFrames wurden in Apache Spark 3.5 eingeführt: assertDataFrameEqual und assertSchemaEqual. Sehen wir uns an, wie man sie jeweils verwendet.
assertDataFrameEqual: Mit dieser Funktion können Sie zwei PySpark DataFrames mit einer einzigen Codezeile auf Gleichheit vergleichen und prüfen, ob die Daten und Schemas übereinstimmen. Sie gibt aussagekräftige Informationen zurück, wenn es Unterschiede gibt.
Gehen wir ein Beispiel durch. Zuerst erstellen wir zwei DataFrames, wobei wir absichtlich einen Unterschied in der ersten Zeile einführen:
Dann rufen wir assertDataFrameEqual mit den beiden DataFrames auf:
Die Funktion gibt eine aussagekräftige Meldung zurück, die angibt, dass sich die erste Zeile in den beiden DataFrames unterscheidet. In diesem Beispiel sind die ersten für Alfred aufgeführten Beträge in dieser Zeile nicht gleich (erwartet: 1500, tatsächlich: 1200):
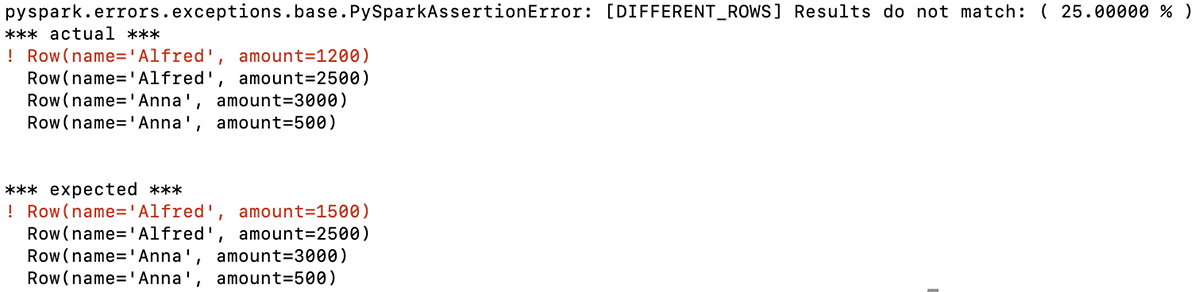
Mit diesen Informationen kennen Sie sofort das Problem mit dem DataFrame, das Ihr Code generiert hat, und können Ihr Debugging darauf ausrichten.
Die Funktion bietet auch verschiedene Optionen, um die Strenge des DataFrame-Vergleichs zu steuern, sodass Sie ihn an Ihre spezifischen Anwendungsfälle anpassen können.
assertSchemaEqual: Diese Funktion vergleicht nur die Schemas von zwei DataFrames; sie vergleicht keine Zeilendaten. Sie können damit überprüfen, ob die Spaltennamen, Datentypen und die Nullable-Eigenschaft für zwei verschiedene DataFrames gleich sind.
Sehen wir uns ein Beispiel an. Zuerst erstellen wir zwei DataFrames mit unterschiedlichen Schemas:
Rufen wir nun assertSchemaEqual mit diesen beiden DataFrame-Schemas auf:
Die Funktion stellt fest, dass sich die Schemas der beiden DataFrames unterscheiden, und die Ausgabe gibt an, wo sie abweichen:

In diesem Beispiel gibt es zwei Unterschiede: Der Datentyp der Spalte amount ist LONG im tatsächlichen DataFrame, aber DOUBLE im erwarteten DataFrame, und da wir das erwartete DataFrame erstellt haben, ohne ein Schema anzugeben, sind auch die Spaltennamen unterschiedlich.
Beide Unterschiede werden in der Funktionsausgabe hervorgehoben, wie hier dargestellt.
assertPandasOnSparkEqual wird in diesem Blog-Post nicht behandelt, da es ab Apache Spark 3.5.1 als veraltet gilt und in der kommenden Apache Spark 4.0.0 entfernt werden soll. Informationen zum Testen der Pandas API on Spark finden Sie unter Pandas API on Spark-Gleichheitstestfunktionen.
Strukturierte Ausgabe zum Debuggen von Unterschieden in PySpark DataFrames
Während die Funktionen assertDataFrameEqual und assertSchemaEqual in erster Linie für Unit-Tests gedacht sind, bei denen Sie typischerweise kleinere Datensätze verwenden, um Ihre PySpark-Funktionen zu testen, können Sie sie auch mit DataFrames mit mehr als nur wenigen Zeilen und Spalten verwenden. In solchen Szenarien können Sie die Zeilendaten für Zeilen, die sich unterscheiden, einfach abrufen, um das Debuggen zu erleichtern.
Sehen wir uns an, wie das geht. Wir verwenden die gleichen Daten, die wir zuvor zum Erstellen von zwei DataFrames verwendet haben:
Und jetzt holen wir uns die Daten, die sich zwischen den beiden DataFrames unterscheiden, aus den Assertion-Fehlerobjekten, nachdem wir assertDataFrameEqual aufgerufen haben:
Das Erstellen eines DataFrames basierend auf den Zeilen, die sich unterscheiden, und das Anzeigen, wie wir es in diesem Beispiel getan haben, veranschaulicht, wie einfach es ist, auf diese Informationen zuzugreifen:

Wie Sie sehen, sind Informationen zu den Zeilen, die sich unterscheiden, sofort für weitere Analysen verfügbar. Sie müssen keinen Code mehr schreiben, um diese Informationen zu Debugging-Zwecken aus den tatsächlichen und erwarteten DataFrames zu extrahieren.
Diese Funktion wird ab Apache Spark 4.0 und DBR 14.3 verfügbar sein.
Pandas API on Spark-Gleichheitstestfunktionen
Zusätzlich zu den Funktionen zum Testen der Gleichheit von PySpark DataFrames haben Pandas API on Spark-Benutzer Zugriff auf die folgenden DataFrame-Gleichheitstestfunktionen:
assert_frame_equalassert_series_equalassert_index_equal
Die Funktionen bieten Optionen zur Steuerung der Strenge von Vergleichen und eignen sich hervorragend für Unit-Tests Ihrer Pandas API on Spark DataFrames. Sie bieten die exakt gleiche API wie die Pandas-Test-Utility-Funktionen, sodass Sie sie verwenden können, ohne vorhandenen Pandas-Testcode zu ändern, den Sie mit Pandas API on Spark ausführen möchten.
Hier sind ein paar Beispiele, die die Verwendung von assert_frame_equal mit verschiedenen Parametern demonstrieren und Pandas API on Spark DataFrames vergleichen:
In diesem Beispiel unterscheiden sich die Schemas der beiden DataFrames. Die Funktionsausgabe listet die Unterschiede auf, wie hier gezeigt:

Wir können angeben, dass die Funktion Spaltendaten auch dann vergleichen soll, wenn die Spalten nicht denselben Datentyp haben, indem wir das Argument check_dtype verwenden, wie in diesem Beispiel:
Da wir angegeben haben, dass assert_frame_equal Spaltendatentypen ignorieren soll, betrachtet es die beiden DataFrames nun als gleich.
Diese Funktionen ermöglichen auch Vergleiche zwischen Pandas API on Spark-Objekten und Pandas-Objekten, was die Kompatibilitätsprüfung zwischen verschiedenen DataFrame-Bibliotheken erleichtert, wie in diesem Beispiel veranschaulicht:
Die Verwendung der neuen PySpark DataFrame- und Pandas API on Spark-Gleichheitstestfunktionen ist eine großartige Möglichkeit, um sicherzustellen, dass Ihr PySpark-Code wie erwartet funktioniert. Diese Funktionen helfen Ihnen nicht nur, Fehler abzufangen, sondern auch genau zu verstehen, was schiefgelaufen ist, sodass Sie schnell und einfach erkennen können, wo das Problem liegt. Weitere Informationen finden Sie auf der Seite Testing PySpark.
Diese Funktionen werden ab Apache Spark 4.0 verfügbar sein. DBR 14.2 unterstützt sie bereits.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.