Stoppen Sie die manuelle Erstellung von Change Data Capture Pipelines
Wie AutoCDC CDC und Slowly Changing Dimensions automatisiert
von Matt Jones, Zoé Durand, Phoebe Weiser, Bilal Aslam und Ray Zhu
- Warum handcodierte CDC- und SCD-Pipelines fehleranfällig, komplex und teuer im Betrieb bei Skalierung sind
- Wie AutoCDC SCD-Typ-1-, SCD-Typ-2- und Snapshot-basierte CDC-Muster deklarativ automatisiert
- Reale Gewinne bei Korrektheit, Leistung und Kosten durch AutoCDC-Workloads in der Produktion
Ich habe AutoCDC von Snapshots in Python ausprobiert und war erstaunt, wie 4 Codezeilen das ersetzen konnten, was ich vorher in 1.500 Codezeilen gemacht habe. —Senior Data Engineer, Fortune 500 Aerospace & Defense Company
Change Data Capture (CDC) und Slowly Changing Dimensions (SCD) sind grundlegend für moderne Analyse- und KI-Workloads. Teams verlassen sich darauf, um nachgelagerte Tabellen korrekt zu halten, wenn sich operative Daten ändern – sei es, um eine aktuelle Sicht auf das Geschäft zu erhalten oder um den vollständigen historischen Kontext zu bewahren.
Doch in der Praxis gehören CDC-Pipelines oft zu den mühsamsten Pipelines, die man erstellen und betreiben kann. Teams erstellen routinemäßig komplexe MERGE-Logik von Hand, um Updates, Löschungen und spät ankommende Daten zu verarbeiten: Sie schichten Staging-Tabellen, Fensterfunktionen und Sequenzierungsannahmen übereinander, die schwer zu durchschauen und noch schwerer zu warten sind, wenn sich Pipelines weiterentwickeln.
In diesem Beitrag gehen wir die CDC- und SCD-Muster durch, denen Datenentwickler und SQL-Praktiker täglich begegnen, warum diese Muster mühsam von Hand zu implementieren sind und wie AutoCDC in Lakeflow Spark Declarative Pipelines diese deklarativ automatisiert – und gleichzeitig sinnvolle Verbesserungen bei Preis und Leistung erzielt.
CDC und SCD sind für Datenentwickler immer noch schwierig
Selbst für Teams, die diese Muster gut verstehen, liegt die Schwierigkeit darin, sie korrekt umzusetzen und über die Zeit korrekt zu halten. Wenn die Datenmengen wachsen und die Anwendungsfälle sich erweitern, werden Pipelines fragil; Korrektheitsprobleme treten spät auf; und selbst kleine Änderungen erfordern sorgfältige Überarbeitungen, um die Beschädigung nachgelagerter Tabellen zu vermeiden.
Pflege von SCD Typ 1-Tabellen
SCD Typ 1-Tabellen überschreiben vorhandene Zeilen, um den neuesten Zustand widerzuspiegeln. Selbst dieser „einfache“ Fall führt schnell zu Herausforderungen:
- Updates kommen außer der Reihe an
- Duplizierte Ereignisse müssen konsistent dedupliziert werden
- Löschungen müssen korrekt angewendet werden
- Die Logik muss über Wiederholungsversuche und Neubearbeitungen hinweg idempotent bleiben
Was oft als einfaches MERGE INTO beginnt, entwickelt sich zu tief verschachtelter Logik mit Staging-Tabellen, Fensterfunktionen und Sequenzierungsannahmen, die schwer zu durchschauen (oder sicher zu ändern) sind. Mit der Zeit werden Teams zögerlich, diese Pipelines überhaupt anzufassen.
Pflege des SCD Typ 2-Verlaufs
SCD Typ 2 führt zusätzliche Komplexität ein:
- Verfolgung von Zeilenversionen und Gültigkeitszeitfenstern
- Verarbeitung von spät ankommenden Updates, ohne den Verlauf zu beschädigen
- Sicherstellung, dass zu jeder Zeit genau eine „aktuelle“ Version existiert
Fehler hier schlagen nicht immer laut aus. Sie treten oft Wochen später als subtile Metrik-Drift auf oder erfordern die vollständige Neuerstellung historischer Tabellen.
Extrahieren von Änderungsdaten aus verschiedenen Quellen
Nicht alle Systeme geben saubere CDC-Protokolle aus. Einige Systeme geben native Änderungsdaten-Feeds aus, andere nicht – oft, weil das Team, das die Daten konsumiert, die Upstream-Datenbank nicht kontrolliert – was Teams zwingt, Änderungen durch den Vergleich aufeinanderfolgender Snapshots einer Quelltabelle zu rekonstruieren.
Die Unterstützung beider erfordert in der Regel separate Erfassungs- und Verarbeitungslogik; unterschiedliche Korrektheitsannahmen; und mehr Code-Pfade, die gepflegt und debuggt werden müssen.
Betrieb von CDC-Pipelines über die Zeit
Selbst wenn eine CDC-Pipeline korrekt ist, muss sie noch Neubearbeitungen und Backfills, Schemaevolution, Ausfälle und Neustarts überstehen. Von Hand erstellte CDC-Logik wird im Laufe der Zeit immer fragiler, da diese Realitäten sich ansammeln, was das Betriebsrisiko und die Wartungskosten erhöht.
Automatisierung komplexer CDC-Muster mit deklarativer Datenentwicklung
AutoCDC wurde entwickelt, um diese gängigen CDC- und SCD-Muster hinter einer deklarativen Abstraktion zu standardisieren. Anstatt zu kodieren, wie Änderungen angewendet werden sollen, deklarieren Teams, welche Semantik sie wünschen, und die Plattform kümmert sich um Reihenfolge, Zustand und inkrementelle Verarbeitung.
| CDC-Workload | AutoCDC | Von Hand erstellte MERGE / Snapshot-Logik |
|---|---|---|
| Pflege von Current-State-Tabellen (SCD Typ 1) | Deklarative Pipeline-Definition kümmert sich automatisch um Sequenzierung, Deduplizierung und Löschungen | Benutzerdefinierte MERGE-Logik mit Fensterfunktionen und Sequenzierungsregeln |
| Pflege von historischen Tabellen (SCD Typ 2) | Automatische Versionsverwaltung mit integrierter Verlaufsverfolgung | Mehrstufige MERGE-Logik zum Schließen und Einfügen von Datensatzversionen |
| Ableiten von Änderungen aus Snapshot-Quellen | Integrierte Snapshot-CDC-Unterstützung | Manuelle Snapshot-Diff-Pipelines mit Joins und Vergleichen |
| Zuverlässiger Betrieb von Pipelines über die Zeit (späte Daten, Wiederholungsversuche, Neubearbeitung) | Automatische Reihenfolge und idempotente Ausführung | Erfordert benutzerdefinierte Schutzmaßnahmen und zusätzliche Logik |
| Code-Fußabdruck und betriebliche Komplexität | ~6–10 Zeilen deklarativer Pipeline-Definition | 40–200+ Zeilen benutzerdefinierter Pipeline-Logik |
Dies gibt Teams eine konsistente, wiederholbare Möglichkeit, CDC und SCD über Pipelines hinweg zu implementieren, anstatt das Muster jedes Mal neu zu erfinden (was eigentlich der Kernwert der deklarativen Programmierung im Allgemeinen und von Spark Declarative Pipelines im Besonderen ist).
Beim Verarbeiten von Änderungsdatensätzen aus einem Change Data Feed (CDF) kümmert sich AutoCDC automatisch um außer der Reihe liegende Datensätze und wendet Updates basierend auf einer deklarierten Sequenzspalte korrekt an. Um zu zeigen, wie das in der Praxis funktioniert, betrachten wir den folgenden Beispiel-CDC-Feed:
| userId | name | city | operation | sequenceNum |
|---|---|---|---|---|
| 124 | Raul | Oaxaca | INSERT | 1 |
| 123 | Isabel | Monterrey | INSERT | 1 |
| 125 | Mercedes | Tijuana | INSERT | 2 |
| 126 | Lily | Cancun | INSERT | 2 |
| 123 | null | null | DELETE | 6 |
| 125 | Mercedes | Guadalajara | UPDATE | 6 |
| 125 | Mercedes | Mexicali | UPDATE | 5 |
| 123 | Isabel | Chihuahua | UPDATE | 5 |
Denken Sie daran, dass Sie SCD Typ 1 wählen sollten, um nur die neuesten Daten zu behalten, oder SCD Typ 2, um historische Daten zu behalten. Beginnen wir mit Typ 1.
Automatisierung der SCD Typ 1-Pflege (Change Data Feed-Quellen)
In diesem Beispiel enthält ein Change Data Feed Einfügungen, Aktualisierungen und Löschungen für eine Benutzertabelle. Das Ziel ist es, eine aktuelle Sicht auf jeden Datensatz zu pflegen, bei der neue Aktualisierungen ältere Werte überschreiben.
Ausgabetabelle für SCD Typ 1
| id | name | city |
|---|---|---|
| 124 | Raul | Oaxaca |
| 125 | Mercedes | Guadalajara |
| 126 | Lily | Cancun |
Benutzer 123 (Isabel) wurde gelöscht, daher erscheint er nicht in der Ausgabe. Benutzer 125 (Mercedes) zeigt nur die neueste Stadt (Guadalajara), da SCD Typ 1 frühere Werte überschreibt.
Mit einem herkömmlichen Ansatz erfordert dies benutzerdefinierte MERGE-Logik, um Ereignisse zu deduplizieren, die Reihenfolge zu erzwingen, Löschungen anzuwenden und sicherzustellen, dass die Pipeline über Wiederholungsversuche oder spät ankommende Daten hinweg korrekt bleibt. AutoCDC ersetzt diese fragile Logik durch eine deklarative Pipeline-Definition, die automatisch Sequenzierung, Deduplizierung, spät ankommende Daten und inkrementelle Verarbeitung handhabt – und Dutzende von Zeilen benutzerdefinierter Merge-Logik eliminiert.
Vollständiges Codebeispiel siehe Anhang
Automatisierung des SCD Typ 2-Verlaufs (Change Data Feed-Quellen)
In vielen analytischen Systemen reicht es nicht aus, nur den neuesten Zustand zu speichern – Teams benötigen eine vollständige Historie, wie sich Datensätze im Laufe der Zeit ändern. Dies ist das SCD Typ 2-Muster, bei dem jede Version eines Datensatzes mit Gültigkeitszeitfenstern gespeichert wird, die angeben, wann er aktiv war.
Ausgabetabelle für SCD Typ 2:
| id | name | city | __START_AT | __END_AT |
|---|---|---|---|---|
| 123 | Isabel | Monterrey | 1 | 5 |
| 123 | Isabel | Chihuahua | 5 | 6 |
| 124 | Raul | Oaxaca | 1 | NULL |
| 125 | Mercedes | Tijuana | 2 | 5 |
| 125 | Mercedes | Mexicali | 5 | 6 |
| 125 | Mercedes | Guadalajara | 6 | NULL |
| 126 | Lily | Cancun | 2 | NULL |
Die Tabelle speichert die vollständige Historie. Benutzer 123 hat zwei Versionen (endete bei Sequenz 6, als er gelöscht wurde). Benutzer 125 hat drei Versionen, die Stadtänderungen zeigen. Datensätze mit __END_AT = NULL sind derzeit aktiv.
Die manuelle Implementierung erfordert mehrstufige MERGE-Logik, um frühere Datensätze abzuschließen, neue Versionen einzufügen und sicherzustellen, dass zu jedem Zeitpunkt nur eine Version aktiv ist. AutoCDC automatisiert diese Übergänge deklarativ, verwaltet Historien-Spalten und Versionierungslogik automatisch und stellt auch bei unsortierten Updates Korrektheit sicher.
Vollständiges Codebeispiel in Anhang
CDC aus Snapshot-Quellen ableiten
Nicht alle Quellsysteme geben Änderungsprotokolle aus. In vielen Fällen erhalten Teams periodische Snapshots einer Quelltabelle und müssen ableiten, was sich zwischen den Läufen geändert hat.
Traditionell erfordert dies den manuellen Vergleich von Snapshots, um Einfügungen, Aktualisierungen und Löschungen zu erkennen, bevor diese Änderungen mit MERGE-Logik angewendet werden. AutoCDC behandelt Snapshot-basiertes CDC als erstklassiges Muster, erkennt automatisch Änderungen auf Zeilenebene zwischen Snapshots und wendet sie inkrementell an, ohne dass benutzerdefinierte Diff-Logik oder Zustandsverwaltung erforderlich sind.
Die manuelle Implementierung erfordert die Erkennung von Änderungen auf Zeilenebene zwischen Snapshots, den Abschluss zuvor aktiver Datensätze und das Einfügen neuer Versionen mit aktualisierten Gültigkeitszeitfenstern. AutoCDC leitet diese Änderungen automatisch ab und wendet SCD Typ 2-Semantik an, wobei die Versionshistorie ohne mehrstufige Merge-Logik oder benutzerdefinierte Snapshot-Zustandsverfolgung beibehalten wird.
Verwaltung von Reihenfolge, Zustand und Wiederverarbeitung
Lakeflow Spark Declarative Pipelines verfolgen automatisch den inkrementellen Fortschritt und verarbeiten unsortierte Daten. Pipelines können nach Fehlern wiederhergestellt, historische Daten neu verarbeitet und im Laufe der Zeit weiterentwickelt werden, ohne Änderungen doppelt anzuwenden oder zu verlieren.
Praktisch bedeutet dies, dass Teams keine Sequenzierungslogik, Watermark-Buchhaltung oder Sicherheit bei der Wiederverarbeitung mehr selbst verwalten müssen – die Plattform kümmert sich darum.
Neues: erhebliche Preis- und Leistungssteigerungen
Neben der Vereinfachung der Pipeline-Logik haben die jüngsten Verbesserungen der Databricks Runtime erhebliche Leistungs- und Kosteneffizienzsteigerungen für AutoCDC-Workloads erzielt – allein seit November 2025:
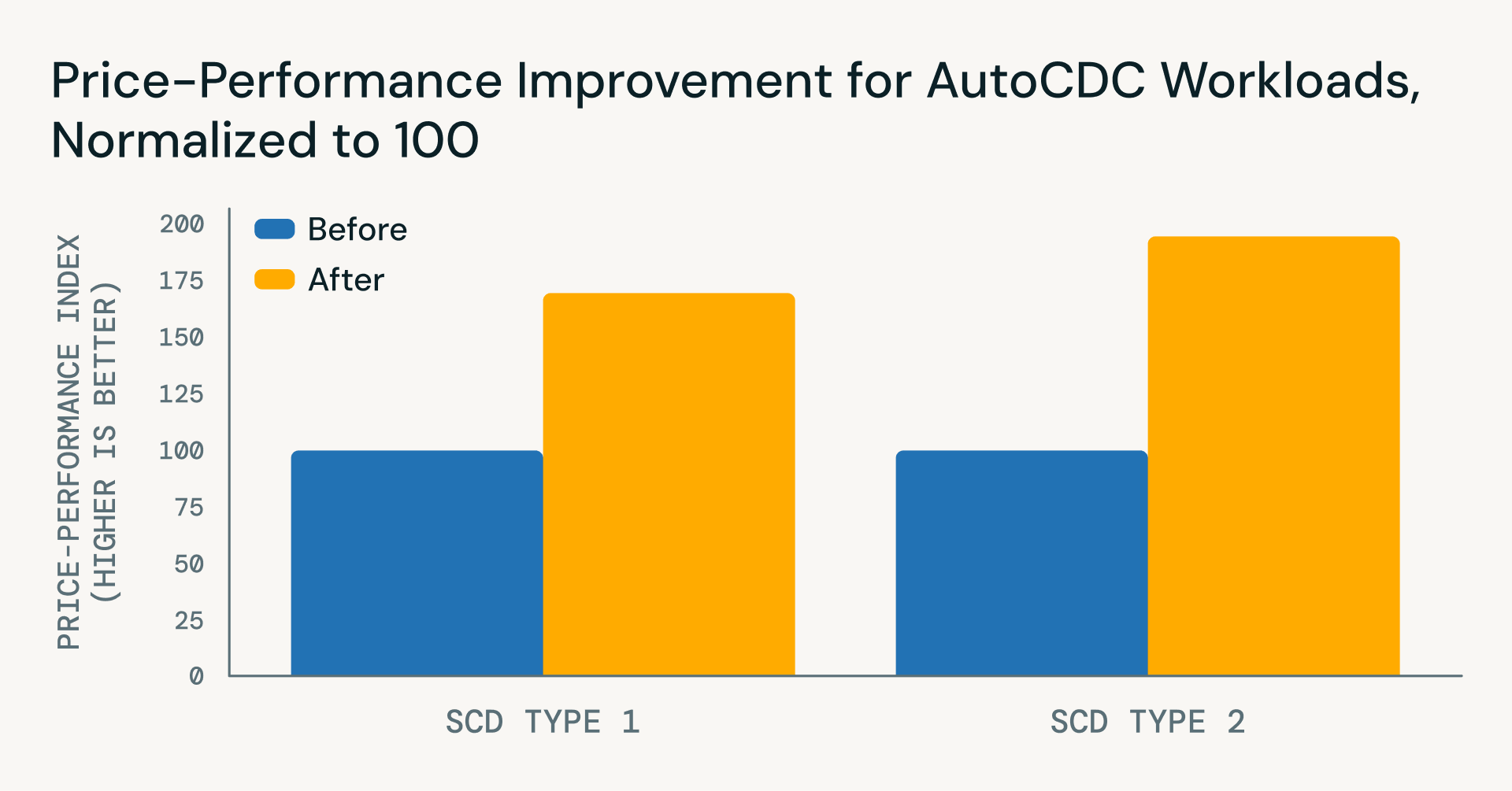
- SCD Typ 1
- ~22% Verbesserung der Latenz
- ~40% Kostenreduzierung
- ~71% Netto-Preis-Leistungs-Vorteil
- SCD Typ 2
- ~45% Latenzreduzierung
- ~35% Kostenreduzierung für inkrementelle Updates
- ~96% Netto-Preis-Leistungs-Vorteil
Diese Vorteile sind wichtig für reale Pipelines, die kontinuierlich im großen Maßstab laufen. Während MERGE INTO ein grundlegender Spark-Primitiv bleibt, baut AutoCDC darauf auf, um unsortierte Daten und inkrementelle Verarbeitung bei wachsenden Datenmengen effizienter zu handhaben.
Kundenerfolg mit AutoCDC
Teams, die CDC- und SCD-Pipelines in der Produktion betreiben, haben AutoCDC ausdrücklich als bedeutenden Wertträger genannt:
Navy Federal Credit Union nutzt AutoCDC in Lakeflow Spark Declarative Pipelines, um groß angelegte Echtzeit-Ereignisverarbeitung zu ermöglichen – Milliarden von Anwendungsereignissen werden kontinuierlich verarbeitet, während benutzerdefinierter CDC-Code und die laufende Pipeline-Wartung entfallen.
Die Einfachheit des Spark Declarative Pipelines Programmiermodells in Kombination mit seinen Servicefunktionen führte zu einer unglaublich schnellen Durchlaufzeit. —Jian (Miracle) Zhou, Senior Engineering Manager, Navy Federal Credit Union
Block nutzt AutoCDC in Lakeflow Spark Declarative Pipelines, um Change Data Capture und Echtzeit-Streaming-Pipelines auf Delta Lake zu vereinfachen und handgeschriebenen CDC- und Merge-Code durch einen deklarativen Ansatz zu ersetzen, der schnell zu implementieren und einfach zu bedienen ist.
Mit der Einführung von Spark Declarative Pipelines hat sich die Zeit für die Definition und Entwicklung einer Streaming-Pipeline von Tagen auf Stunden reduziert. —Yue Zhang, Staff Software Engineer, Data Foundations, Block
Valora Group, ein führender Schweizer Anbieter von „Foodvenience�“, nutzt AutoCDC in Lakeflow Spark Declarative Pipelines, um die Erfassung von Stammdatenänderungen und Echtzeit-Einzelhandelsanalysen zu optimieren und benutzerdefinierten CDC-Code durch einen deklarativen Ansatz zu ersetzen, der einfach zu implementieren, zu wiederholen und teamübergreifend zu skalieren ist.
Wir haben viel gewonnen, indem wir CDC in SDP gemacht haben, weil man keinen Code schreibt – alles ist im Hintergrund abstrahiert. AutoCDC minimiert die Anzahl der Zeilen… es ist so einfach zu machen. —Alexane Rose, Data and AI Architect, Valora Holding
Erste Schritte
AutoCDC ist als Teil von Lakeflow Spark Declarative Pipelines auf Databricks verfügbar.
Weitere Informationen:
- Überprüfen Sie die AutoCDC-Dokumentation (SQL und Python)
- Entdecken Sie Beispiele für SCD Typ 1, SCD Typ 2 und Snapshot-basiertes CDC
Probieren Sie AutoCDC in Ihren eigenen Pipelines aus und eliminieren Sie handgeschriebene CDC-Logik!
Anhang
SCD Typ 1 Beispiel
| MERGE | AutoCDC |
from delta.tables import DeltaTable
from pyspark.sql.functions import max_by, struct
# Deduplicate: keep latest record per userId
updates = (spark.read.table("cdc_data.users")
.groupBy("userId")
.agg(max_by(struct("*"), "sequenceNum").alias("row"))
.select("row.*"))
# Apply SCD Type 1: upsert updates, delete deletions
(DeltaTable.forName(spark, "target")
.alias("t")
.merge(updates.alias("s"), "s.userId = t.userId")
.whenMatchedDelete(condition="s.operation = 'DELETE'")
.whenMatchedUpdate(
condition="s.sequenceNum > t.sequenceNum",
set={"name": "s.name", "city": "s.city", "sequenceNum": "s.sequenceNum"}
)
.whenNotMatchedInsertAll(condition="s.operation != 'DELETE'")
.execute())
| from pyspark import pipelines as dp
from pyspark.sql.functions import col, expr
@dp.view
def users():
return spark.readStream.table("cdc_data.users")
dp.create_streaming_table("target")
dp.create_auto_cdc_flow(
target="target",
source="users",
keys=["userId"],
sequence_by=col("sequenceNum"),
apply_as_deletes=expr("operation = 'DELETE'"),
stored_as_scd_type=1
)
|
SCD Typ 2 Beispiel
| MERGE | AutoCDC |
from delta.tables import DeltaTable
from pyspark.sql.functions import col, lit, max_by, struct
# Deduplicate: keep latest record per userId
updates = (spark.read.table("cdc_data.users")
.groupBy("userId")
.agg(max_by(struct("*"), "sequenceNum").alias("row"))
.select("row.*"))
# Step 1: close out active rows for records being updated or deleted
(DeltaTable.forName(spark, "target")
.alias("t")
.merge(
updates.alias("s"),
"s.userId = t.userId AND t.__END_AT IS NULL AND s.sequenceNum > t.__START_AT"
)
.whenMatchedUpdate(set={"__END_AT": "s.sequenceNum"})
.execute())
# Step 2: insert new rows for inserts and updates (not deletes)
new_rows = (updates
.filter("operation != 'DELETE'")
.withColumn("__START_AT", col("sequenceNum"))
.withColumn("__END_AT", lit(None).cast("long"))
.drop("operation"))
new_rows.write.mode("append").saveAsTable("target")
| dp.create_auto_cdc_flow(
target="target",
source="users",
keys=["userId"],
sequence_by=col("sequenceNum"),
apply_as_deletes=expr("operation = 'DELETE'"),
stored_as_scd_type=2
)
|
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.