Archive erschließen: Unstrukturierte Dokumente in eine durchsuchbare Datenbank für die Grundwassererkundung verwandeln
Wie Databricks for Good MapAid dabei geholfen hat, AI zu nutzen, um statische Archive in eine nutzbare Suchmaschine für die Wasserkrise im Sudan zu verwandeln
- MapAid hat sich mit Databricks for Good zusammengetan, um fast 700 gescannte hydrogeologische Dokumente zu klassifizieren und zu katalogisieren und so eine unstrukturierte Sammlung in eine durchsuchbare Datenbank zu verwandeln.
- Mithilfe von multimodaler AI hat das Team eine serverlose Pipeline aufgebaut, die Dokumente klassifiziert und wasserbezogene Informationen direkt aus gescannten Seitenbildern extrahiert.
- Forschende können nun relevante historische Studien in Sekundenschnelle finden und auf Brunnenaufzeichnungen zugreifen, die direkt in die Grundwasservorhersagemodelle von MapAid einfließen, was zu besseren Bohrergebnissen beiträgt.
Einführung
Im gesamten Sudan sind Gemeinden für Trinkwasser, Bewässerung und das Überleben auf Grundwasser angewiesen, aber das Bohren eines ertragreichen Brunnens ist alles andere als garantiert. Die Geologie ist komplex, Aquifere variieren stark und eine Fehlbohrung kann Tausende von Dollar kosten. Jahrzehnte an geologischen Vermessungen und Feldberichten enthalten die Daten, die zur Verbesserung der Ergebnisse benötigt werden. Diese Informationen waren jedoch über verschiedene Archive verstreut und wurden nie systematisch organisiert, sodass sie für die Menschen, die sie am dringendsten benötigen, unsichtbar blieben.
MapAid ist eine an der Stanford University gegründete gemeinnützige Organisation, deren Mission es ist, humanitäre Akteure und Entwicklungshelfer, primär in Afrika, in die Lage zu versetzen, datengestützte Entscheidungen durch AI-gestützte Kartierung zu treffen. Ihr Flaggschiff-Tool, die kostenlos nutzbare App WellMapr, nutzt AI und Geodaten, um flache Grundwasserzonen zu identifizieren. Dies dient als Orientierungshilfe für kostengünstige Bohrungen zur Trinkwasserversorgung und Bewässerung für Kleinbauern. Eine entscheidende Eingabe für diese Modelle sind historische Daten über Brunnen, Bohrlöcher und die Geologie von Aquiferen.
Die Sudan Association for Archiving Knowledge (SUDAAK) pflegt eine der umfangreichsten Sammlungen dieser Daten: fast 700 gescannte PDFs, TIFFs und JPGs mit insgesamt über 5.000 Seiten an geologischen Vermessungen, Brunnenbohrberichten und Feldstudien, die unter wossac.com öffentlich zugänglich sind. Verfügbarkeit ist jedoch nicht gleichbedeutend mit Barrierefreiheit. Forschende, die nach Bohrlochdaten in einem bestimmten Teil des Sudans suchen, müssten Hunderte von Dokumenten manuell durchforsten. Die Daten wurden zwar digitalisiert, blieben aber ohne ein Abrufsystem ungenutzt.
Klassifizierung gescannter Dokumente mit multimodaler AI
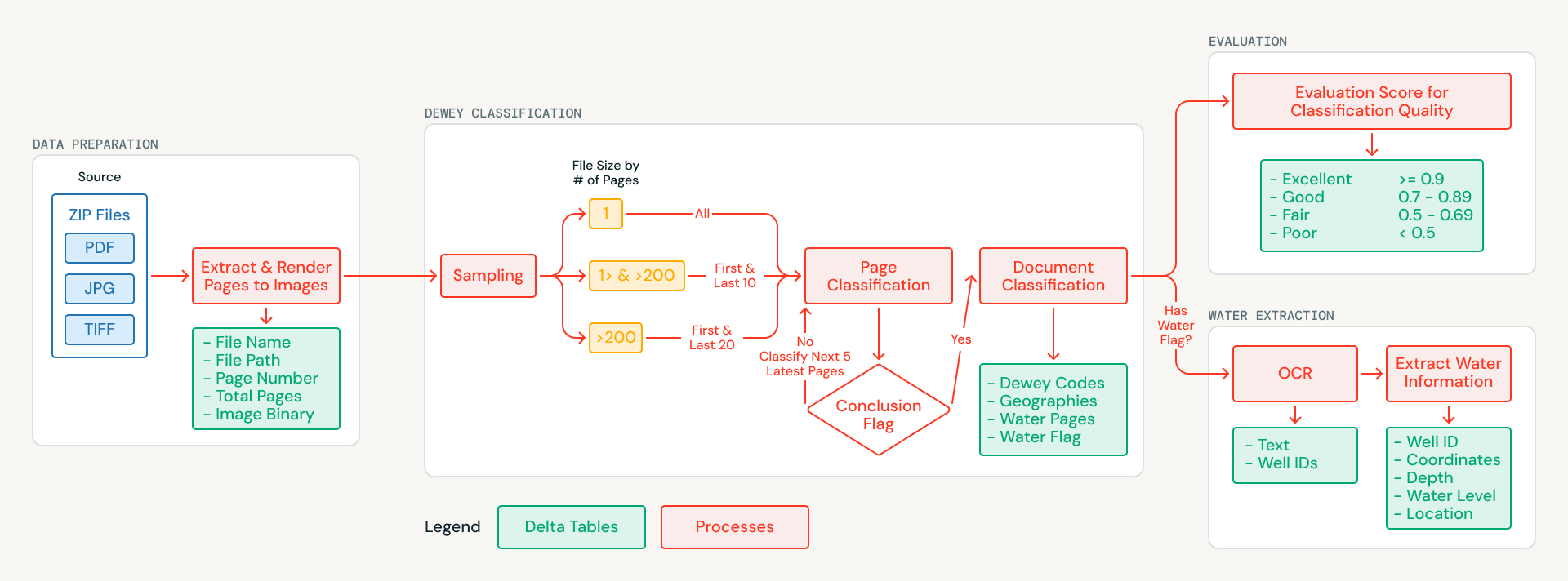
Databricks hat sich mit MapAid zusammengetan, um eine AI-gestützte Pipeline zu entwickeln, die jedes Dokument im Archiv klassifiziert, es mit geografischen und thematischen Metadaten versieht und strukturierte Brunnen- und Bohrlochdaten aus wasserbezogenen Dokumenten extrahiert. Das System läuft vollständig auf Databricks und ist für die Bereitstellung mit einem einzigen Befehl vorkonfiguriert. Dieser Artikel beschreibt den technischen Ansatz und zeigt, wie er sich auf jede Organisation übertragen lässt, die strukturiertes Wissen aus großen Sammlungen unstrukturierter, gescannter Dokumente extrahieren möchte.
Das Archiv stellte Herausforderungen dar, die eine traditionelle Textextraktion ausschlossen. Bei den Dokumenten handelt es sich um Scans physischer Berichte, die viele Jahrzehnte alt sind und keine eingebettete Textebene besitzen. Einige Seiten sind schief, andere kombinieren Englisch und Arabisch, und viele enthalten handschriftliche Feldnotizen. Anstatt OCR als ersten Schritt zu versuchen, definierte das Team das Problem als eine Frage des visuellen Verständnisses neu: Die gescannten Seitenbilder werden direkt an multimodale AI-Modelle gesendet, die den Inhalt visuell interpretieren können.
Die Seiten jedes Dokuments werden als Bilder gerendert und in Unity Catalog Volumes gespeichert, wodurch ein sauberer, versionierter Basisdatensatz entsteht. Von dort aus reduziert eine intelligente Sampling-Strategie die Verarbeitungskosten: Kürzere Dokumente werden vollständig analysiert, während bei längeren Dokumenten Stichproben aus den informativsten Abschnitten (Titelseiten, Einleitungen und Schlussfolgerungen) gezogen werden. Dies reduzierte das AI-Verarbeitungsvolumen um mehr als 70 % bei gleichbleibender Klassifizierungsqualität.
Jede als Stichprobe ausgewählte Seite wird mithilfe von Databricks AI Functions (ai_query) analysiert, die nativ multimodale Eingaben und strukturierte JSON-Ausgaben unterstützen. Das Modell untersucht jedes Seitenbild und gibt Folgendes zurück:
- Dewey-Dezimal-Klassifikationscodes, das universelle Bibliotheksklassifizierungssystem
- im Inhalt referenzierte sudanesische Regionen
- eine Kennzeichnung für Wasserrelevanz, die angibt, ob die Seite Brunnen-, Bohrloch- oder Aquiferdaten enthält
Da AI Functions direkt in SQL ausgeführt werden, konnte das Team Prompts und Ausgabeschemata iterieren, ohne eine separate Model-Serving-Infrastruktur aufbauen zu müssen. Die Ergebnisse auf Seitenebene werden zu Klassifizierungen auf Dokumentenebene aggregiert. So entsteht ein strukturierter, durchsuchbarer Katalog, in dem jedes Dokument mit seinem Inhalt und seinem räumlichen Bezug getaggt ist.
{kind=link}
Extraktion strukturierter Brunnen- und Bohrlochdaten
Viele der als wasserrelevant gekennzeichneten Dokumente enthalten genau die Art von strukturierten Informationen, auf die die WellMapr-Modelle von MapAid angewiesen sind: Brunnenstandorte, Bohrtiefen, Grundwasserstandsmessungen und Förderraten. Diese Informationen sind oft über das gesamte Dokument verteilt, wobei Koordinaten in einem Abschnitt, Tiefenmessungen in einem anderen und Ertragsdaten in einer Übersichtstabelle einige Seiten später erscheinen. Die Extraktion und Verknüpfung dieser Daten war ein zentrales Ziel der Partnerschaft.
Für jedes wasserrelevante Dokument verarbeitet die Pipeline jede Seite und nicht nur die für die Klassifizierung verwendete Stichprobe. Die OCR wird Seite für Seite mithilfe eines multimodalen Modells durchgeführt, das über die Foundation Model API bereitgestellt wird. Dieses Modell verarbeitet Englisch, Arabisch und komplexe Layouts, einschließlich handschriftlicher Feldnotizen, tabellarischer Daten und gemischt formatierter Seiten. Während der OCR wendet das System auch einen Ansatz zur Entitätserkennung an, bei dem Brunnen- und Bohrlochkennungen als Anker-Entitäten identifiziert werden, sodass sich über mehrere Seiten erstreckende Datensätze wieder mit einem einzigen Standort verknüpft werden können.
Der extrahierte Text aller Seiten wird in einer einheitlichen Dokumentendarstellung zusammengeführt. Diese wird in einem zweiten Durchlauf verarbeitet, um strukturierte Datensätze im JSON-Format zu extrahieren, die Standortnamen, GPS-Koordinaten, Bohrtiefen, statische Wasserstände und Pumptest-Erträge erfassen. Databricks AI Functions erzwingen schemakonforme Antworten und stellen so sicher, dass diese Attribute konsistent erfasst werden, selbst wenn sie in unterschiedlichen Formaten oder Abschnitten im Dokument erscheinen. Das Ergebnis ist ein Satz strukturierter Brunnen- und Bohrlochdaten, die direkt in die WellMapr-Vorhersagemodelle von MapAid integriert werden können.
Automatisierte Qualitätsbewertung im großen Stil
Die manuelle Validierung von Hunderten spezialisierter hydrogeologischer Klassifizierungen würde erhebliche Ressourcen und tiefes Fachwissen erfordern. Anstatt die Bewertung als separaten, nachträglichen Schritt zu behandeln, hat das Team eine automatisierte Qualitätsbewertung direkt als vollwertige Phase in die Pipeline integriert. Ein separates AI-Modell, das ebenfalls über AI Functions aufgerufen wird, fungiert als Bewerter: Es bewertet jede Klassifizierung anhand eines strukturierten Bewertungsschemas, das Genauigkeit, Vollständigkeit und Konsistenz abdeckt. Für jedes Dokument vergleicht der Bewerter die zugewiesenen Dewey-Dezimal-Codes und geografischen Tags mit dem Inhalt der Stichprobenseiten und prüft, ob die Klassifizierungen durch das gestützt werden, was das Modell tatsächlich beobachtet hat.
Jede Bewertung liefert sowohl eine kategorische Einstufung (hervorragend, gut, ausreichend oder mangelhaft) als auch eine schriftliche Begründung für die Punktzahl. Dadurch entsteht ein nachvollziehbarer Pfad für jede Entscheidung, die die Pipeline trifft. Dokumente, deren Bewertung unter einem Konfidenzschwellenwert liegt, werden für eine manuelle Überprüfung markiert, sodass der begrenzte menschliche Aufwand auf die Fälle gelenkt wird, in denen er am wichtigsten ist. Im ersten vollständigen Durchlauf erforderte nur ein kleiner Bruchteil der Klassifizierungen menschliche Aufmerksamkeit.
Bereitstellung einer in sich geschlossenen Lösung auf Databricks
Ein Projekt wie dieses betrifft jede Ebene des Daten- und AI-Stacks: Dateispeicher, Data Engineering, AI-Inferenz, strukturiertes Parsen von Ausgaben, Qualitätsbewertung und Governance. Databricks stellte all dies in einem einzigen Workspace bereit. Die Roharchivdateien werden in Unity Catalog Volumes gespeichert, und alle Pipeline-Ausgaben werden in Delta Lake-Tabellen mit ACID-Zuverlässigkeit, Schema-Evolution und vollständiger Data Lineage geschrieben. Die Pipeline wird als Lakeflow-Job auf Serverless-Computing-Ressourcen orchestriert, sodass MapAid nur für das bezahlt, was bei jedem Durchlauf tatsächlich verbraucht wird.
Das gesamte System ist als Databricks Asset Bundle gepackt, was bedeutet, dass es mit einem einzigen Befehl bereitgestellt, aktualisiert und ausgeführt werden kann. MapAid erhielt eine in sich geschlossene Lösung, die ohne Fachwissen über mehrere Cloud-Dienste hinweg gewartet werden kann. Da die Pipeline-Logik von dem spezifischen Archiv, das sie verarbeitet, entkoppelt ist, könnte dasselbe System auch für andere Wasserarchive, andere Regionen oder andere Bereiche angepasst werden, in denen große Sammlungen gescannter Dokumente klassifiziert und durchsuchbar gemacht werden müssen.
Was das in der Praxis bedeutet
In ihrem ersten vollständigen Durchlauf lieferte die Pipeline:
- 654 Dokumente und 5.570 Seiten klassifiziert
- In weniger als drei Stunden abgeschlossen
- 95 % der Klassifizierungen wurden vom automatisierten Evaluator als „hervorragend“ oder „gut“ eingestuft
- Bei ca. 50 % des Archivs wurde festgestellt, dass es wasserbezogene Daten enthält
- 299 strukturierte Brunnen- und Bohrlochdatensätze mit Ortsnamen, Tiefen und Ertragsmessungen extrahiert
Die Pipeline verkürzte einen Prozess, der Fachexperten Wochen oder Monate gekostet hätte, auf wenige Stunden. Das Archiv kann nun nach Klassifizierung, Geografie oder dem Vorhandensein von Wasserdaten durchsucht werden. Jeder extrahierte Datensatz mit Koordinaten und Tiefendaten fließt direkt in die Grundwasservorhersagen von MapAid ein, was zu höheren Bohrerfolgsraten und einer schnelleren Wasserversorgung bedürftiger Gemeinden beiträgt.
Da SUDAAK weiterhin neue Dokumente digitalisiert, kann die Pipeline jeden neuen Batch mit einem einzigen Befehl verarbeiten. So wird sichergestellt, dass der Katalog mit dem Wachstum des Archivs aktuell bleibt. Die Arbeit von MapAid erstreckt sich über Ostafrika, einschließlich Äthiopien und Malawi, und ähnliche unklassifizierte Archive existieren auf dem gesamten Kontinent. Die Methodik und die Infrastruktur sind bereit für die Skalierung.
Rupert Douglas-Bate, Chief Executive Officer (CEO) von MapAid, teilte die folgende Perspektive auf die Partnerschaft: „Unser sich ständig weiterentwickelndes KI-System WellMapr soll die kostengünstige Suche und Lokalisierung nachhaltiger Grundwasserquellen revolutionieren, benötigt dafür jedoch Brunnenwasserdaten. Unsere Mission, dieses Ziel zu erreichen, wurde durch unsere Zusammenarbeit mit Databricks for Good, die über Rotary International den Kontakt zu uns herstellten, erheblich beschleunigt. Das Projekt Databricks for Good war grundlegend für die Entwicklung unserer Online Water Library (OWL) mit Unterstützung der Sudan Association for Archiving Knowledge (SUDAAK). Das Databricks-Team half dabei, ein großes, ungeordnetes Archiv historischer sudanesischer Wasser- und Bodendaten mithilfe der Dewey-Dezimalklassifikation in ein strukturiertes System zu verwandeln. Dies ermöglicht es uns, schnell und kostengünstig Daten über nachhaltige Grundwasserbrunnen zu identifizieren, die nun für die Entwicklung unseres WellMapr-Algorithmus genutzt werden können. MapAid freut sich, OWL als wichtiges Entwicklungsinstrument zur Linderung von Dürren einzusetzen. Dies beweist, dass wir, wenn die richtigen Partner zusammenarbeiten, das ‚Unmögliche‘ für diejenigen erreichen können, die es am dringendsten benötigen.“
Bitte lesen Sie unten mehr über einige unserer anderen Pro-Bono-Projekte:
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.