Verwendung von MemAlign zur Verbesserung der Evaluierung traditioneller maschineller Lernmodelle in Genie Code
Schließen der Lücke zwischen LLM-Richtern und menschlichen Experten mit MemAlign und MLflow.
von Stepan Nosov, Pavle Martinović, Tejas Sundaresan, Alkis Polyzotis und Nemanja Petrovic
- Genie Code generiert vollständige ML-Notebooks aus natürlichsprachlichen Eingabeaufforderungen – wir haben neun LLM-Richter entwickelt, um deren Qualität in Dimensionen wie Modelltraining, Datenimputation und Feature Engineering zu bewerten.
- Menschliche Annotationen zeigten, dass die Richter mit Experten um bis zu 0,68 MAE auf einer 3-Punkte-Skala nicht übereinstimmten. MemAlign, ein Open-Source-Alignment-Framework in MLflow, schloss diese Lücke mit nur etwa 50 gekennzeichneten Beispielen.
- In den drei am schlechtesten ausgerichteten Dimensionen reduzierte MemAlign die Fehlerrate der Richter um 74-89 %, und eine Folgestudie zeigte, dass sowohl das semantische als auch das episodische Gedächtnis für das Ergebnis unerlässlich sind.
Das kürzlich angekündigte Genie Code ist der autonome KI-Partner von Databricks, der speziell für Datenarbeit entwickelt wurde. Es ersetzte den Databricks Assistant, während es mehrere Agenten integrierte und neue Integrationspunkte und Funktionen bot. Genie Code ist tief in Unity Catalog integriert, was bedeutet, dass es Ihre Tabellen, Spalten, Abstammung, Metrikansichten und Geschäftsdefinitionen (Semantik) versteht. Dieses kontextbezogene Bewusstsein macht Genie Code für Datenpraktiker weitaus nützlicher als generische Chatbots.
Wenn Genie Code ein Notebook für traditionelle ML-Aufgaben generiert, wie z. B. „Erstellen eines Churn-Vorhersagemodells“, erwarten wir, dass es einen produktionsreifen Workflow liefert, der die Installation der entsprechenden Python-Bibliotheken, die Exploration und Vorverarbeitung der Daten, das Training, die Abstimmung, die Registrierung und Bereitstellung des Modells sowie die Bewertung seiner Leistung umfasst. Wir erwarten auch, dass jeder Schritt wirklich durch die Daten informiert ist: Genie Code soll beispielsweise verstehen, dass unausgeglichene Klassen bei einem binären Klassifizierungsproblem zu dramatisch unterschiedlichen Workflows und Erfolgsmetriken führen.
Um sicherzustellen, dass Genie Code durchweg native Databricks-Best Practices befolgt und beispielsweise das Überspringen von Kreuzvalidierung, das Übersehen von Datenlecks oder unsachgemäße Datenimputation vermeidet, mussten wir eine rigorose Methode finden, um eine Frage zu beantworten: Woher wissen wir, ob der generierte Code tatsächlich gut ist? Das generierte Notebook hängt stark vom Problem ab, das der Kunde zu lösen versucht, und dies kann zwischen verschiedenen Kunden stark variieren, sodass dies eine sehr nicht triviale Frage ist.
In diesem Beitrag werden wir untersuchen, wie wir eine Bewertungs-Pipeline für die traditionellen ML-Fähigkeiten von Genie Code aufgebaut haben und wie wir MemAlign (ein neues Open-Source-Framework zur Ausrichtung in MLflow) verwendet haben, um die massive Lücke zu schließen, die wir zwischen LLM-Richtern und menschlichen Experten festgestellt haben. Die verbesserten Richter halfen uns, Lücken in der ML-Anleitung von Genie Code zu identifizieren und zu beheben, die wir sonst übersehen hätten.
Aufbau des Bewertungsframeworks
Ein robustes Bewertungsframework wird benötigt für:
- Hillclimbing: Quantifizieren, wie sich Prompts, Tools, Fähigkeiten und Architekturänderungen auf die Ausgabe auswirken.
- Schutz vor Regressionen: Sicherstellen, dass die Verbesserung des „Modelltrainings“ nicht versehentlich die „Datenexploration“ verschlechtert.
- Benchmarking: Messen, wie verschiedene Foundation-Modelle (LLM-Backends) die Notebook-Qualität beeinflussen.
- CI: Überwachen, wie sich Änderungen in der zugrunde liegenden Agentenschleife auf die endgültigen ML-Aufgaben auswirken.
Die Bewertung traditioneller ML-Notebooks ist eine der komplexesten Bewertungsaufgaben, da sie die Bewertung der Codequalität, der besten ML-Praktiken und datengesteuerter Anpassungen/Maßschneiderungen umfasst. Um eine so breite und unübersichtliche Aufgabe wie die Bewertung von ML-Notebooks zu bewältigen, verwenden wir LLM-as-a-judge – einen LLM-„Experten“, der von Menschen darin geschult wurde, wie genau ein gutes Notebook aussieht. Wir haben neun Richter erstellt, die aufgefordert werden, die ML-Notebooks anhand von neun Dimensionen zu bewerten, die in den meisten ML-Workflows vorkommen:
| Dimensionen | Was wir bewerten |
|---|---|
| Bibliotheksinstallation | Korrekte Abhängigkeiten |
| Explorative Datenanalyse | Umfassende EDA und |
| Datenimputation | Mean Time to Contain |
| Umgang mit fehlenden Werten ohne Leckage. | Feature Engineering |
| Feature-Auswahl/-Transformation. | Modelltraining |
| Modellauswahl, Kreuzvalidierung, Hyperparameter-Tuning | Wiederverwendung des trainierten Modells für Inferenz. |
| Metrikbewertung | Inferenzlogik und aufgabenspezifische Metriken (z. B. MAPE für Prognosen, MAE für Regression, Genauigkeit für Klassifizierung). |
| MLflow-Protokollierung | Einrichtung der Experimentverfolgung. |
| Zellenorganisation | Aufteilung des Codes in Zellen, Code-Sauberkeit, Lesbarkeit, Markdown-Header, entsprechende Protokollierung. |
Für jede Dimension haben wir Bewertungsrubriken (wiederverwendet zwischen menschlichen Bewertern und LLM-Richtern) geschrieben, die eine Punktzahl von 1 bis 3 und 0 für „nicht anwendbar“ zuweisen:
- 3 (Gut): Das Notebook erfüllt einen hohen Standard für eine Dimension. Es demonstriert Best Practices, deckt den erwarteten Umfang ab und behandelt Randfälle angemessen.
- 2 (Durchschnittlich): Akzeptabel, aber mit Lücken. Die Grundlagen sind vorhanden, aber dem Notebook fehlen Verfeinerungen, die ein erfahrener Praktiker erwarten würde.
- 1 (Schlecht): Grundlegende Probleme. Wichtige Schritte fehlen, sind falsch oder werden auf eine Weise angewendet, die zu falschen Schlussfolgerungen führen würde.
- N/A (Nicht anwendbar): Diese Dimension ist für diesen Prompt nicht anwendbar (z. B. kann die Dimension Datenimputation nicht angewendet werden, wenn der Datensatz keine fehlenden Werte aufweist).
Um eine Vorstellung von der Granularität zu geben, hier ist die spezifische Rubrik, die wir für die Dimension „Datenimputation“ verwenden:
Zusammen mit den Richtern pflegen wir eine Reihe von Evaluierungstestfällen, die eine Reihe von ML-Aufgaben (Klassifizierung, Regression, Prognose) über verschiedene Datensatzgrößen, Domänen und Komplexitätsstufen hinweg abdecken. Jeder Testfall enthält einen Benutzer-Prompt, der Genie Code die ML-Aufgabe mitteilt, die er auf dem angegebenen Datensatz lösen soll („Ich habe Passagierdaten in den Tabellen titanic_train_table und titanic_test_table. Können Sie herausfinden, wer überlebt hat?“). Die Evaluationsschleife besteht darin, Genie Code zu verwenden, um ein Notebook (oder mehrere) für jeden Testfall zu generieren, und dann jedes Notebook anhand aller anwendbaren Dimensionen zu bewerten.
Bewertung des Bewertungssystems
Durch die Verwendung von LLM-Richtern anstelle von Menschen zur Bewertung von Genie Code-Artefakten haben wir im Wesentlichen ein schwieriges Problem durch ein anderes ersetzt: Der Out-of-the-Box-Richter ist in der anstehenden Aufgabe unerfahren und nicht mit menschlichen Bewertungen abgestimmt. Unser Problem ist es, die Bewertungen der LLM-Richter mit denen menschlicher Gutachter abzugleichen.
Der Bewertungsdatensatz für die LLM-Richterbewertung enthält 50 von Genie Code generierte Notebooks („Testfälle“), bei denen menschliche Experten jede anwendbare Dimension bewertet und sowohl eine Punktzahl als auch eine kurze Begründung als Ground Truth geliefert haben. In den Grauzonen zwischen zwei Punktzahlen durften die Bewerter ihr eigenes Urteil äußern, aber die Schemata waren so geschrieben, dass dies selten der Fall war.
Das Maß für die Mensch-Maschine-Abstimmung ist der mittlere absolute Fehler (MAE) zwischen den Punktzahlen in jeder Dimension. Die Ergebnisse waren gemischt, einige Dimensionen zeigten eine starke Abstimmung (4 Dimensionen hatten einen MAE von <= 0,10), während andere erhebliche Meinungsverschiedenheiten zeigten:
- Modelltraining: MAE von 0,680
- Modellnutzung: MAE von 0,562
- Datenimputation: MAE von 0,474
- Datenexploration: MAE von 0,407
Diese Lücke besteht, weil Menschen und LLMs dieselbe Rubrik nicht auf die gleiche Weise interpretieren. Während ein menschlicher Bewerter eine subtil fehlerhafte Imputationsstrategie oder eine Trainingsschleife erkennen kann, die „funktioniert“, aber logisch fehlerhaft ist, übersieht ein LLM-Richter oft diese technische Nuance. Wir stellten auch fest, dass der Richter ein klassisches Positivitäts-Bias aufwies – er war einfach zu „höflich“, und das hinderte uns daran, objektive Ergebnisse zu erzielen.
Es wurde völlig klar, dass LLM-Richter und Menschen bei gleicher Rubrik nicht zu denselben Ergebnissen kommen würden – eine Fehlausrichtung. Dies ist genau das Szenario, für das MemAlign entwickelt wurde, um es zu beheben.
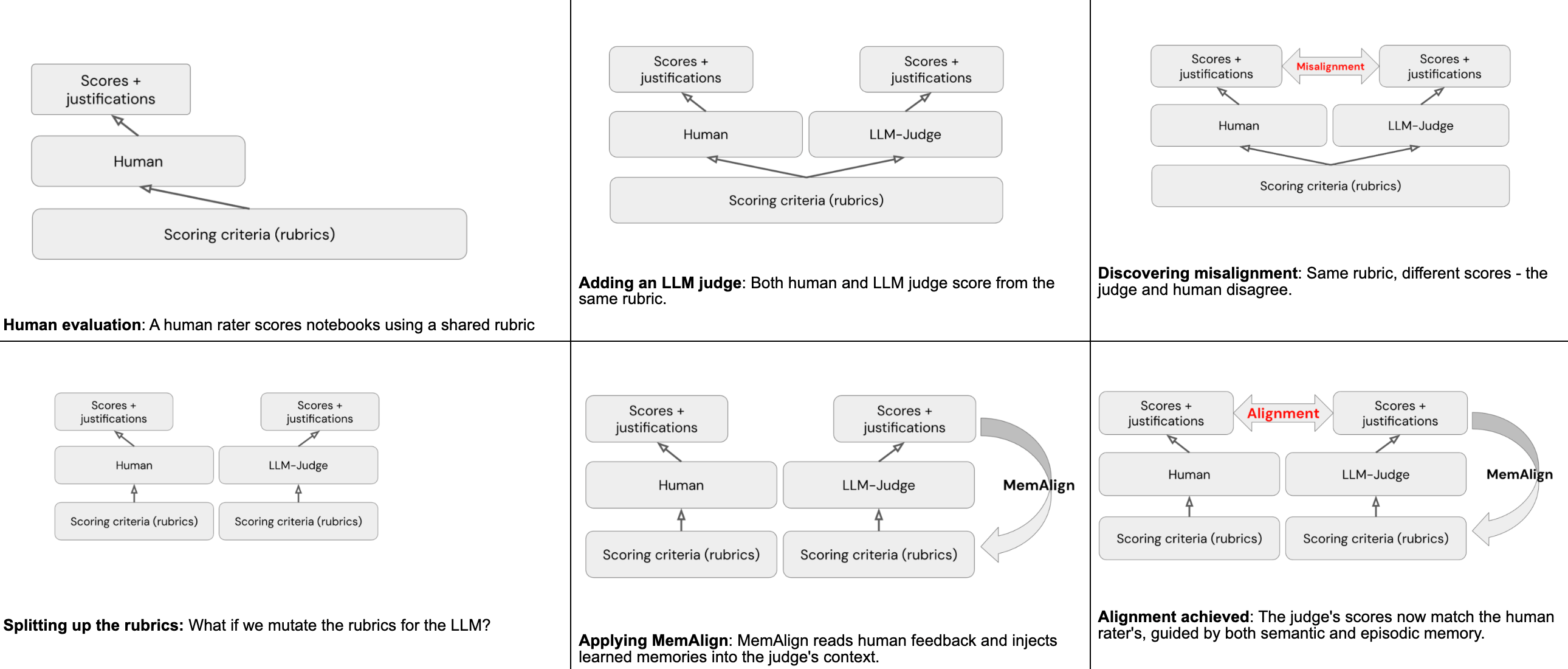
Verwendung von MemAlign zur Ausrichtung
MemAlign ist ein Framework innerhalb von MLflow, das mit einer sehr geringen Menge an menschlichem Feedback in natürlicher Sprache die Ausrichtung zwischen menschlichen Bewertern und LLM-Richtern durchführen kann. Dies wird durch zwei Arten von „Speichern“ erreicht, die durch das Lesen des menschlichen Feedbacks gebildet werden:
- Semantischer Speicher speichert verallgemeinerte Richtlinien - Regeln, die aus Feedback destilliert wurden und breit anwendbar sind
- Episodischer Speicher speichert spezifische Beispiele - Fälle, in denen der Richter falsch lag, aufbewahrt als Anker für zukünftige Entscheidungen
Zur Inferenzzeit erstellt MemAlign einen Arbeitskontext, indem es alle semantischen Richtlinien abruft und die relevantesten episodischen Beispiele für die aktuelle Eingabe abruft. Der Richter lädt all diese zusammen mit der ursprünglichen Bewertungsmatrix in seinen Kontext und verwendet das gesammelte Wissen, um eine genauere Bewertung für alle zukünftigen Notebooks zu geben.
Die Schlüsseleigenschaft, die MemAlign herausstechen ließ, war die hohe Leistung bei nur einer kleinen Anzahl von Beispielen. Dies liegt daran, dass MemAlign effektiv aus reichhaltigen Lernsignalen in natürlichem Sprachfeedback lernt und diese in das Dual-Memory-System integriert.
Hier ist ein Beispiel für einige der Ausschnitte aus dem semantischen Speicher, die für die Dimension „Datenimputation“ generiert wurden und die Lücken in der zuvor definierten Bewertungsmatrix füllen, indem sie im Allgemeinen Ankerpunkte, Beispiele und Gegenbeispiele liefern:
Darüber hinaus wird, wie bereits erwähnt, der im Prompt dargestellte semantische Speicher zur Bewertungszeit mit relevanten Beispielen aus dem episodischen Speicher des Richters ergänzt, wodurch der Richter noch mehr Kontext erhält, um die optimierten Anweisungen zu interpretieren.
Experimentdesign
K-fache Kreuzvalidierung
Nach dem ML-Trainings-Test-Paradigma haben wir eine K-fache Kreuzvalidierung (K=4) auf 50 Testfällen (Notebooks) angewendet, um Datenlecks und die Notwendigkeit, einen separaten Testdatensatz zu kennzeichnen, zu vermeiden. Für jede Faltung haben wir Folgendes getan:
- Trainingsphase: MemAlign hat den Richter anhand von Spuren aus den anderen Faltungen ausgerichtet, um den Richter zu erhalten.
- Evaluierungsphase: Die Notebooks in Faltung i wurden mit dem Richter bewertet.
Bootstrapping-Konfidenzintervalle
Um die Konfidenzintervalle ohne zusätzliche gekennzeichnete Daten zu berechnen, haben wir 100 Bootstrap-Stichproben mit Zurücklegen aus den ursprünglichen 50 generiert. Indem wir dies 10.000 Mal wiederholten und die MAE zwischen menschlichen und maschinellen Bewertungen verfolgten, berechneten wir die Konfidenzintervalle für die menschlich-maschinelle Ausrichtung mit einem 95% CI, das eine statistisch signifikante Änderung definiert.
Implementierung
Die Evaluierungspipeline ist als ein einzelner MLflow-Snippet implementiert, der den gesamten Prozess orchestriert:
Der MemAlign-Optimierer kann LLM-Richter anhand der Spuren der Testfälle in nur wenigen Codezeilen ausrichten. Wir haben diesen neuen „ausgerichteten“ Richter verwendet, um die neue MAE zu berechnen. Die Ausrichtung eines Richters auf eine einzelne Dimension dauert etwa 25 Sekunden pro Faltung, sodass die Ausrichtung selbst kein Engpass ist.
Ergebnisse
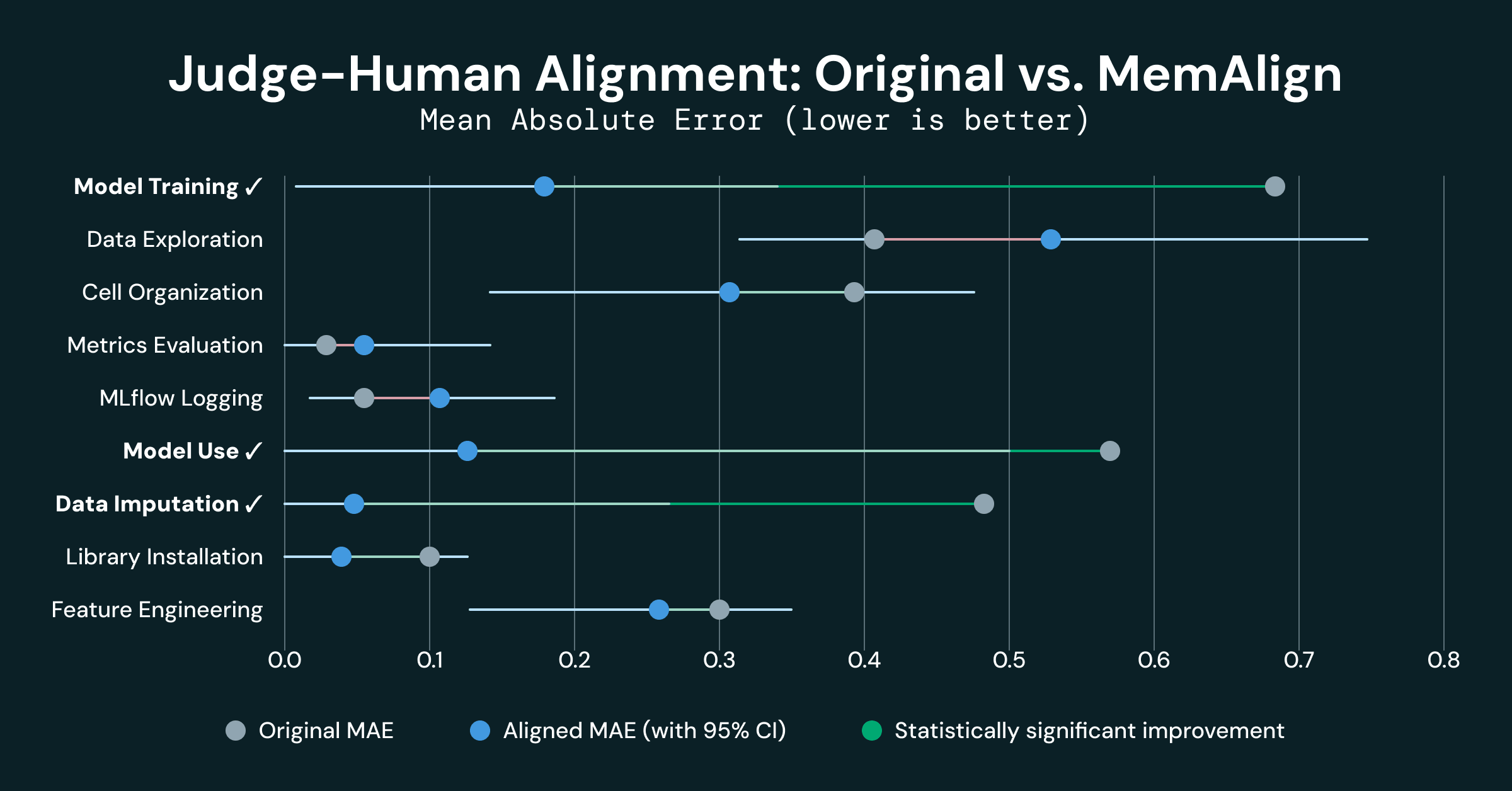
Drei von 9 Dimensionen zeigten statistisch signifikante Verbesserungen:
- Modelltraining verbessert um 0,500 MAE (0,680 → 0,180), eine Reduzierung um 74 %
- Modellnutzung verbessert um 0,438 MAE (0,562 → 0,125), eine Reduzierung um 78 %
- Datenimputation verbessert um 0,421 MAE (0,474 → 0,053), eine Reduzierung um 89 %
Diese 3 Dimensionen gehören zu den anfänglich 4 Dimensionen, die stark fehlausgerichtet waren. Eine schwache anfängliche Ausrichtung deutet darauf hin, dass LLMs und Menschen ein grundlegend unterschiedliches Verständnis der gemeinsamen Bewertungsmatrizen haben, und die von MemAlign injizierte Erinnerung scheint genügend Kontext zu liefern, um sie „auf die gleiche Seite“ zu bringen.
- Metrikbewertung und MLflow-Protokollierung waren bereits gut ausgerichtet (MAE < 0,10 ursprünglich), und ihre Verschlechterung ist nicht statistisch signifikant (Experimentierrauschen)
- Datenexploration zeigte eine leichte Regression (-0,130), aber nicht statistisch signifikant angesichts ihres Konfidenzintervalls [-0,33, +0,09]. Diese Dimension wies die höchste Inter-Bewerter-Varianz auf, und dieses Rauschen verhinderte, dass MemAlign sich verbesserte (und hat es möglicherweise sogar behindert).
Nur semantischer Speicher-Experiment
Die Dual-Memory-Struktur von MemAlign veranlasste uns zu der Frage, ob beide tatsächlich zur Richteraustrichtung beitragen. Insbesondere soll der episodische Speicher dem Richter helfen, indem er eine Reihe der ähnlichsten annotierten Notebooks als Referenzpunkt gibt (unter Verwendung der Nearest-Neighbor-Suche). Aber was ist, wenn die abgerufenen Notebooks (nächste Nachbarn) nicht wirklich ähnlich zum aktuellen sind - nur die am wenigsten unähnlichen? Das Laden dieser in den Kontext des Richters könnte die Dinge eher verwirren als helfen. Der Problemraum, den wir bewerten (ML-Notebooks), ist sehr breit, und wir haben ursprünglich angenommen, dass eine Reihe von 50 Notebooks einfach nicht ausreichen würde, um eine ausreichend dichte Menge an Erinnerungen für den Richter zum Abrufen zu erhalten.
Ohne episodischen Speicher verschlechtert sich das Bild erheblich:
- Modelltraining verbessert sich immer noch (+0,420), aber der Gewinn ist kleiner als die +0,500 mit vollständigem MemAlign, und die ausgerichtete MAE beträgt 0,260 gegenüber 0,180.
- Modellnutzung verliert vollständig die statistische Signifikanz - die Verbesserung sinkt von +0,438 auf +0,294, wobei das Konfidenzintervall nun Null kreuzt.
- Datenimputation geht von einer Reduzierung des Fehlers um 89 % auf keine Verbesserung über - die ausgerichtete MAE entspricht der ursprünglichen MAE (0,455).
- MLflow-Protokollierung und Metrikbewertung verschlechtern sich tatsächlich erheblich. Ohne episodische Beispiele, um den Richter zu verankern, führen die destillierten Richtlinien allein zu Rauschen in Dimensionen, die bereits gut kalibriert waren, und erhöhen die MAE der MLflow-Protokollierung von 0,062 auf 0,396.
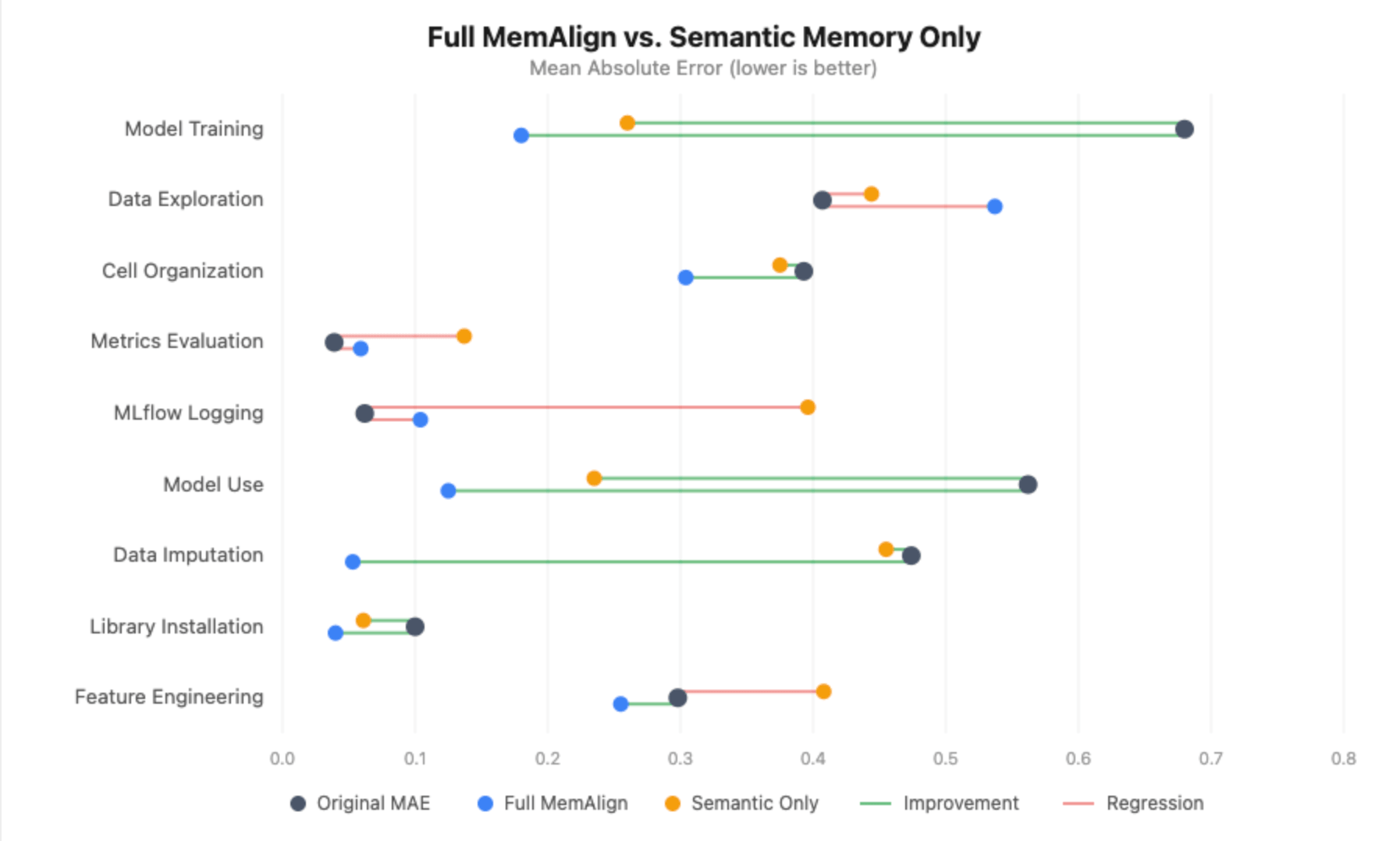
Dies war das Gegenteil von dem, was wir erwartet hatten. Wir hatten ursprünglich angenommen, dass unser spärlicher annotierter Datensatz den Richter verwirren würde, aber fast jede Dimension verschlechterte sich ohne episodische Erinnerung. Die einzige Ausnahme war die Datenexploration, bei der das Weglassen der episodischen Beispiele tatsächlich geholfen haben könnte - ohne die spezifischen Notebooks, bei denen sich unsere Annotatoren uneinig waren, hatte der Richter nur die destillierten Richtlinien und weniger verrauschte Signale zur Verfügung.
Die Quintessenz: Selbst wenn Ihre Eingaben groß und unordentlich sind, verbessert der episodische Speicher die Leistung des Richters drastisch. Sowohl semantische als auch episodische Erinnerungen sind für die Funktionsweise von MemAlign unerlässlich.
Fazit: Schließung der Expertenlücke
Zu beurteilen, ob ein Codierungsagent seine Aufgabe erfüllt, ist schon schwierig genug, während die Bewertung eines autonomen KI-Partners beim Aufbau und der Ausführung traditioneller ML-Workflows eine andere Komplexitätsebene darstellt. Aufgrund der schnellen Iteration bei KI-Produkten gibt es einfach nicht genug Zeit, damit Experten die „kontinuierliche Integration“ des Agenten überwachen können. Die einzig praktikable skalierbare Lösung sind LLM-Richter - aber wir brauchen immer noch eine Jury von Menschen, um den LLM-Richter im Zaum zu halten.
Durch die Anwendung von MemAlign haben wir den Richterfehler in den Dimensionen, in denen es am wichtigsten war, um 74–89 % reduziert. Aber wie bei jeder ML/LLM-Arbeit ist das Ergebnis nur so gut wie die Informationen, die Sie hineinstecken. Stellen Sie also sicher, dass die Kennzeichnung kompetent ist.
Schlussfolgerungen:
- Messen Sie Ihr Messsystem: Ein verrauschtes System ist nicht gut für die Auswertung, und bis wir die Zeit und Ressourcen investiert hatten, um die Juroren tatsächlich zu validieren und zu verbessern, konnten wir unserem Auswertungssystem nicht vertrauen.
- Rubriken allein reichen nicht aus: Es gibt subtile Unterschiede zwischen der Art und Weise, wie ein Mensch Anweisungen wahrnimmt, und der Art und Weise, wie ein LLM Anweisungen wahrnimmt. Diese Unterschiede sollten berücksichtigt werden, und Alignment-Tools wie MemAlign sind ein effektiver Weg, um die Lücke zu schließen.
- Qualität der Beschriftung > Quantität: Wenn menschliche Annotatoren nicht übereinstimmen (wie wir in unserer Data Exploration-Regression gesehen haben), hat das Alignment kein kohärentes Signal zum Lernen.
MemAlign wird mit MLflow ausgeliefert und hat für uns mit nur ~50 beschrifteten Beispielen funktioniert. Wenn Ihre LLM-Juroren nicht mit Ihren Experten übereinstimmen, ist es eine Nachmittagsarbeit wert.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.