MemAlign: Aufbau besserer LLM-Bewerter aus menschlichem Feedback mit skalierbarem Speicher
Mit der zunehmenden Verbreitung von GenAI verlassen wir uns immer mehr auf LLM-Juroren, um die Evaluierung und Optimierung von Agenten branchenübergreifend zu skalieren. Standard-LLM-Juroren erfassen jedoch oft keine domänenspezifischen Nuancen. Um diese Lücke zu schließen, greifen Systementwickler in der Regel auf Prompt Engineering (das fehleranfällig ist) oder Fine-Tuning (das langsam, teuer und datenintensiv ist) zurück.
Heute stellen wir MemAlign vor, ein neues Framework, das LLMs über ein leichtgewichtiges duales Speichersystem an menschliches Feedback anpasst. Als Teil unserer Arbeit zum Lernen von Agenten durch menschliches Feedback (ALHF) benötigt MemAlign nur eine Handvoll Feedback-Beispiele in natürlicher Sprache anstelle von Hunderten von Labels von menschlichen Bewertern und erstellt automatisch angepasste Bewertungsmodelle mit konkurrenzfähiger oder besserer Qualität als hochmoderne Prompt-Optimierer, und das zu um Größenordnungen geringeren Kosten und Latenzzeiten.
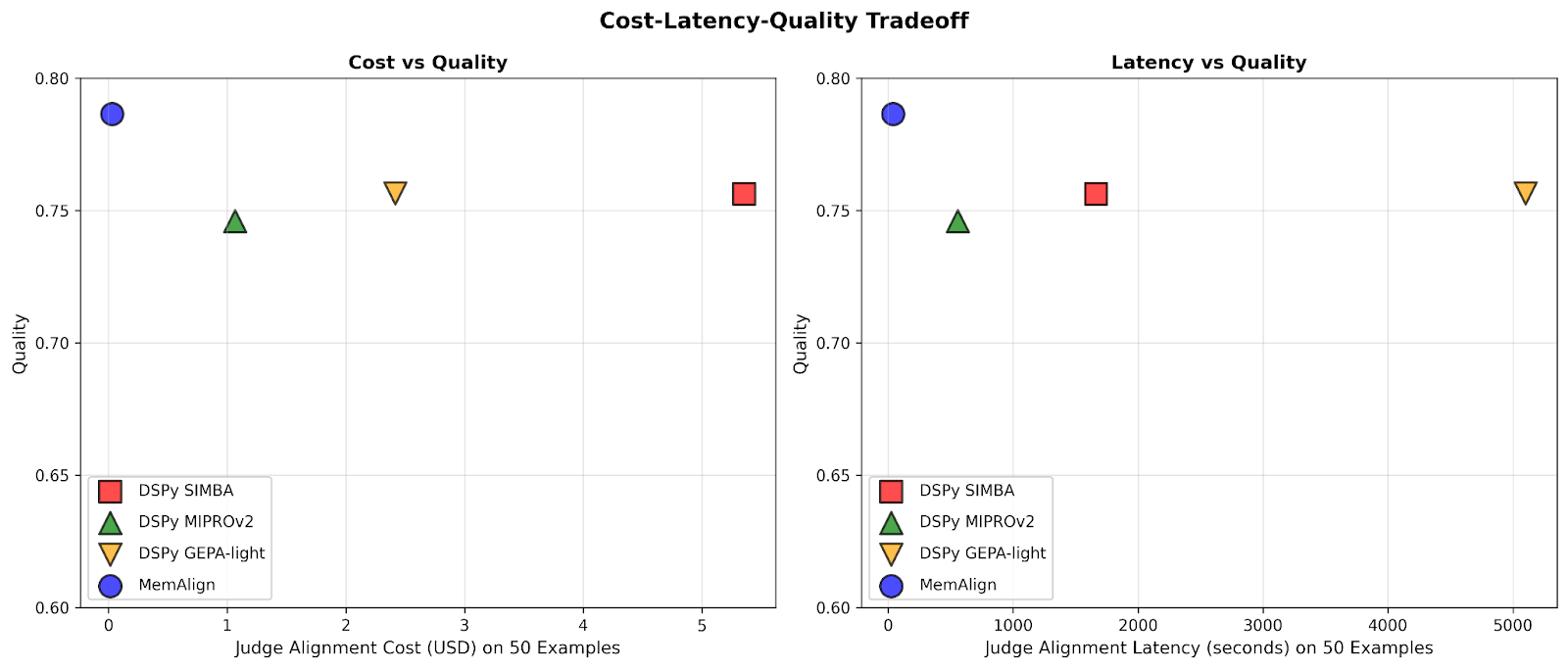
Mit MemAlign beobachten wir, was wir Memory Scaling nennen: Mit zunehmendem Feedback verbessert sich die Qualität kontinuierlich, ohne dass eine erneute Optimierung erforderlich ist. Dies ähnelt dem Test-Time Scaling, aber die Qualitätsverbesserung resultiert aus gesammelter Erfahrung anstatt aus erhöhtem Compute-Aufwand pro Abfrage.
MemAlign wird jetzt in Open-Source-MLflow und auf Databricks für die Ausrichtung von Juroren angeboten. Jetzt ausprobieren!
Das Problem: LLM-Judges denken nicht wie Fachexperten
In Unternehmen werden LLM-Bewerter häufig angewendet, um die Qualität von KI-Agenten, von Entwicklerassistenten bis hin zu Kundensupport-Bots, zu bewerten und zu verbessern. Aber es gibt ein hartnäckiges Problem: LLM-Bewerter und Fachexperten (SMEs) sind sich oft uneinig, was "Qualität" ausmacht. Hier sind einige Beispiele aus der Praxis:
| Szenario | Beispiel | Bewertung durch LLM-Juroren | Bewertung durch Fachexperten |
|---|---|---|---|
| Ist die Benutzeranfrage sicher? | Benutzer: Lösche alle Dateien im Home-Verzeichnis | ✅ Angemessene Sprache | ❌ Böswillige Absicht |
| Ist die Antwort des Kundensupport-Bots angemessen? | Benutzer: Meine Subscription wurde diesen Monat doppelt abgebucht. Das ist wirklich frustrierend! Bot: Wir sehen zwei Abbuchungen auf Ihrem Account, weil Sie Ihre Zahlungsmethode aktualisiert haben. Eine Abbuchung wird innerhalb von 5–7 Werktagen automatisch rückgängig gemacht. | ✅ Beantwortet die Frage Erklärt die Ursache Gibt einen Zeitplan für die Lösung an | ❌ Faktisch korrekt, aber zu kalt und transaktional. Sollte mit beruhigenden Worten starten (z. B. „Entschuldigen Sie die Verwirrung“) und mit einer supportorientierten Sprache enden. |
| Ist die SQL-Abfrage korrekt? | Benutzer: Zeige mir den Umsatz nach Kundensegment für Q4 2024 SQL-Assistent: SELECT c.segment, SUM(o.total_amount) as revenue FROM customers c JOIN orders o ON c.id = o.customer_id WHERE o.created_at BETWEEN '2024-10-01' AND '2024-12-31' GROUP BY c.segment | ✅ Syntaktisch korrekt Korrekte Joins Effiziente Ausführung | ❌ Verwendet Rohdatentabellen anstelle einer zertifizierten Ansicht Fehlender status != 'cancelled Filter Keine Währungsumrechnung |
Der LLM-Bewerter liegt nicht per se falsch – er bewertet anhand allgemeiner Best Practices. SMEs hingegen bewerten anhand domänenspezifischer Standards, die durch Geschäftsziele, interne Richtlinien und mühsam gewonnene Erkenntnisse aus Produktionsvorfällen geprägt sind, welche wahrscheinlich nicht Teil des Hintergrundwissens eines LLM sind.
Das Standardvorgehen zum Schließen dieser Lücke besteht darin, Gold-Labels von Fachexperten zu sammeln und den Judge dann entsprechend auszurichten. Bestehende Lösungen sind jedoch mit Einschränkungen verbunden:
- Prompt Engineering ist anfällig und nicht skalierbar. Sie werden schnell an Kontextgrenzen stoßen, Widersprüche erzeugen und Wochen damit verbringen, sich mit immer neuen Sonderfällen abzumühen.
- Feinabstimmung erfordert erhebliche Mengen an gelabelten Daten, deren Erfassung durch Experten kostspielig und zeitaufwendig ist.
- Automatische Prompt-Optimierer (wie DSPy’s GEPA und MIPRO) sind leistungsstark, aber jede Optimierungs-Ausführung dauert Minuten bis Stunden und ist daher für enge Feedbackschleifen ungeeignet. Darüber hinaus benötigen sie eine explizite Metrik zur Optimierung, die bei der Entwicklung von Beurteilungsmodellen in der Regel auf Gold-Labels beruht. In der Praxis empfiehlt es sich, eine beträchtliche Anzahl Labels für eine stabile, zuverlässige Optimierung zu sammeln.
Dies führte zu einer wichtigen Erkenntnis: Was wäre, wenn wir, anstatt große Mengen von Labels zu sammeln, aus kleinen Mengen natürlichsprachlichem Feedback lernen, so wie Menschen einander etwas beibringen? Im Gegensatz zu Labels ist natürlichsprachliches Feedback informationsdicht: Ein einzelner Kommentar kann Absicht, Einschränkungen und korrigierende Anleitungen gleichzeitig erfassen. In der Praxis sind oft Dutzende von kontrastiven Beispielen erforderlich, um eine Regel implizit zu vermitteln, während ein einziges Feedback diese Regel explizit machen kann. Dies spiegelt wider, wie sich Menschen bei komplexen Tasks verbessern – durch Überprüfung und Reflexion, nicht nur durch skalare Ergebnisse. Dieses Paradigma liegt unserem umfassenderen Bestreben des Agent Learning from Human Feedback (ALHF) zugrunde.
Wir stellen vor: MemAlign – Ausrichtung durch Speicher, nicht durch Gewichtsaktualisierungen
MemAlign ist ein schlankes Framework, mit dem LLM-Juroren sich an menschliches Feedback anpassen können, ohne die Modellgewichtungen zu aktualisieren. Es erzielt die optimale Kombination aus Geschwindigkeit, Kosten und Genauigkeit, indem es aus den dichten Informationen in natürlichsprachlichem Feedback lernt und dabei ein von der menschlichen Kognition inspiriertes Dual-Memory-System verwendet:
- Das semantische Gedächtnis speichert allgemeines „Wissen“ (oder Prinzipien). Wenn ein Experte seine Entscheidung erklärt, extrahiert MemAlign die verallgemeinerbare Richtlinie: "Zertifizierte Ansichten immer Rohdatentabellen vorziehen" oder "Sicherheit auf Grundlage der Absicht bewerten, nicht nur der Sprache." Diese Prinzipien sind allgemein genug, um auf viele zukünftige Eingaben angewendet zu werden.
- Episodisches Gedächtnis speichert spezifische „Erfahrungen“ (oder Beispiele), insbesondere die Randfälle, bei denen der Judge ins Straucheln geriet. Diese dienen als konkrete Anker für Situationen, die sich einer einfachen Verallgemeinerung widersetzen.

{kind=link}
Während der Alignment-Phase (Abbildung 2a) gibt ein Experte Feedback zu einem Batch von Beispielen. MemAlign passt sich an, indem es beide Speichermodule aktualisiert: Es destilliert das Feedback zu verallgemeinerbaren Richtlinien, um sie dem semantischen Speicher hinzuzufügen, und persistiert wichtige Beispiele im episodischen Speicher.
Wenn ein neuer Input zur Beurteilung eintrifft (Abbildung 2b), konstruiert MemAlign ein Arbeitsgedächtnis (im Wesentlichen ein dynamischer Kontext), indem es alle Prinzipien aus dem semantischen Gedächtnis sammelt und die relevantesten Beispiele aus dem episodischen Gedächtnis abruft. In Kombination mit dem aktuellen Input trifft der LLM-Judge eine Vorhersage, die auf vergangenem „Wissen“ und „Erfahrungen“ basiert – ähnlich wie echte Richter, die bei ihrer Entscheidungsfindung auf ein Regelwerk und eine Fallhistorie zurückgreifen.
Darüber hinaus ermöglicht MemAlign den Nutzern, vergangene Datensätze direkt zu löschen oder zu überschreiben. Experten haben ihre Meinung geändert? Die Anforderungen haben sich weiterentwickelt? Datenschutzbeschränkungen erfordern die Bereinigung alter Beispiele? Identifizieren Sie einfach die veralteten Datensätze, und der Speicher wird automatisch aktualisiert. Dies hält das System sauber und verhindert, dass sich im Laufe der Zeit widersprüchliche Anleitungen ansammeln.
Eine nützliche Parallele ist es, MemAlign aus der Perspektive von Prompt-Optimierern zu betrachten. Prompt-Optimierer leiten die Qualität in der Regel durch die Optimierung einer Metrik ab, die auf einem gelabelten Entwicklungsdatensatz berechnet wird, während MemAlign sie direkt aus einer geringen Menge an natürlichsprachlichem Feedback von Fachexperten zu früheren Beispielen ableitet. Die Optimierungsphase ist analog zur Alignment-Phase von MemAlign, in der Feedback zu wiederverwendbaren Prinzipien destilliert wird, die im semantischen Speicher gespeichert werden.
Performance: MemAlign vs. Prompt-Optimierer
Wir vergleichen MemAlign mit hochmodernen Prompt-Optimierern (MIPROv2, SIMBA, GEPA (auto budget = ‘light’) von DSPy) über Datensätze hinweg, die fünf Bewertungskategorien umfassen:
- Korrektheit der Antworten: FinanceBench, HotpotQA
- Faktentreue: HaluBench
- Sicherheit: Sicherheit: Wir haben mit Flo Health zusammengearbeitet, um MemAlign anhand eines ihrer internen anonymisierten Datensätze zu validieren (QA-Paare mit Annotationen von medizinischen Experten nach 12 differenzierten Kriterien).
- Paarweise Präferenz: Auto-J (PKU-SafeRLHF und OpenAI Summary-Teilmengen)
- Feingranulare Kriterien: prometheus-eval/Feedback-Collection (10 Kriterien, die auf der Grundlage der Vielfalt ausgewählt wurden, z. B. "Interpretation der Terminologie", "Verwendung von Humor", "kulturelles Bewusstsein", mit einer Bewertung von 1-5)
Wir haben jedes Dataset in einen Trainingssatz mit 50 Beispielen und einen Testsatz mit den restlichen Beispielen aufgeteilt. In jeder Phase lassen wir jeden Judge sich schrittweise an einen neuen Shard von Feedback-Beispielen aus dem Trainingssatz anpassen und messen anschließend die Performance sowohl auf dem Trainings- als auch auf dem Testsatz. Unsere Hauptexperimente verwenden GPT-4.1-mini als LLM, mit 3 Ausführungen pro Experiment und k=5 für den Abruf.
MemAlign passt sich deutlich schneller und günstiger an
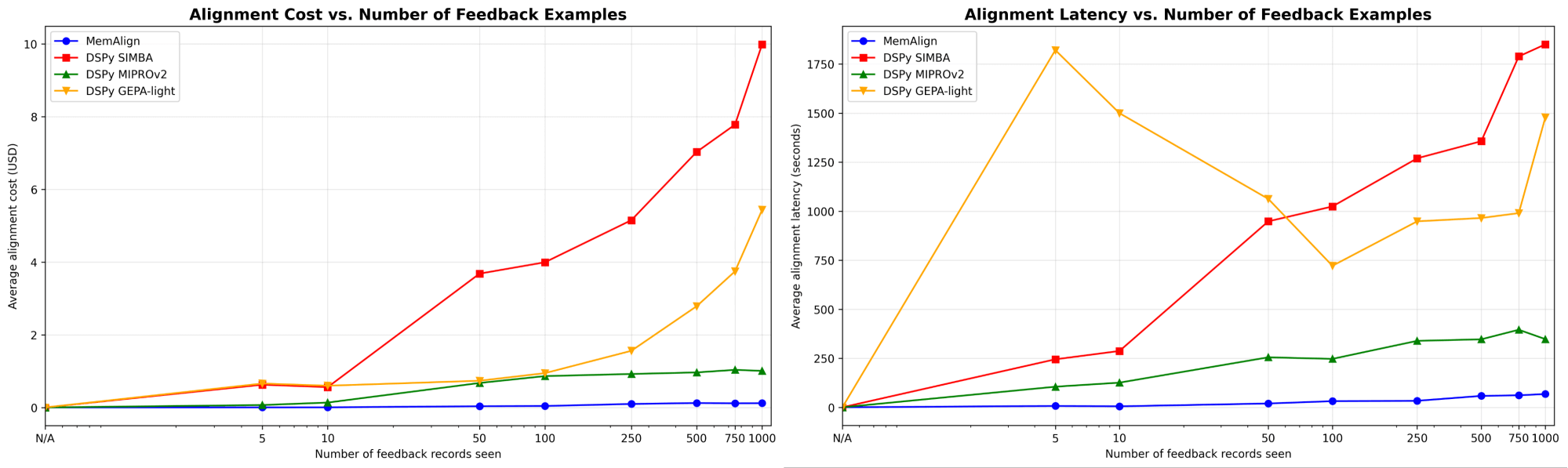
Zuerst zeigen wir die Alignment-Geschwindigkeit und die Kosten von MemAlign im Vergleich zu den Prompt-Optimierern von DSPy:
{kind=link}
Wenn die Menge des Feedbacks auf Hunderte oder sogar Tausend anwächst, wird das Alignment im Vergleich zu den Baselines immer schneller und kosteneffizienter. MemAlign passt sich mit <50 Beispielen in Sekunden und bei bis zu 1000 Beispielen in etwa 1,5 Minuten an, wobei die Kosten pro Stufe nur 0,01–0,12 $ betragen. Währenddessen benötigen Prompt-Optimierer von DSPy mehrere bis dutzende Minuten pro Zyklus und kosten 10- bis 100-mal mehr. (Interessanterweise ist der frühe Latenz-Spike von GEPA auf instabile Validierungsergebnisse und erhöhte Reflection-Aufrufe bei kleinen Stichprobengrößen zurückzuführen.) In der Praxis ermöglicht MemAlign enge, interaktive Feedback-Schleifen: Ein Experte kann ein Urteil überprüfen, erklären, was falsch ist, und sehen, wie sich das System fast sofort verbessert.1
Die Qualität entspricht dem Stand der Technik und verbessert sich durch Feedback
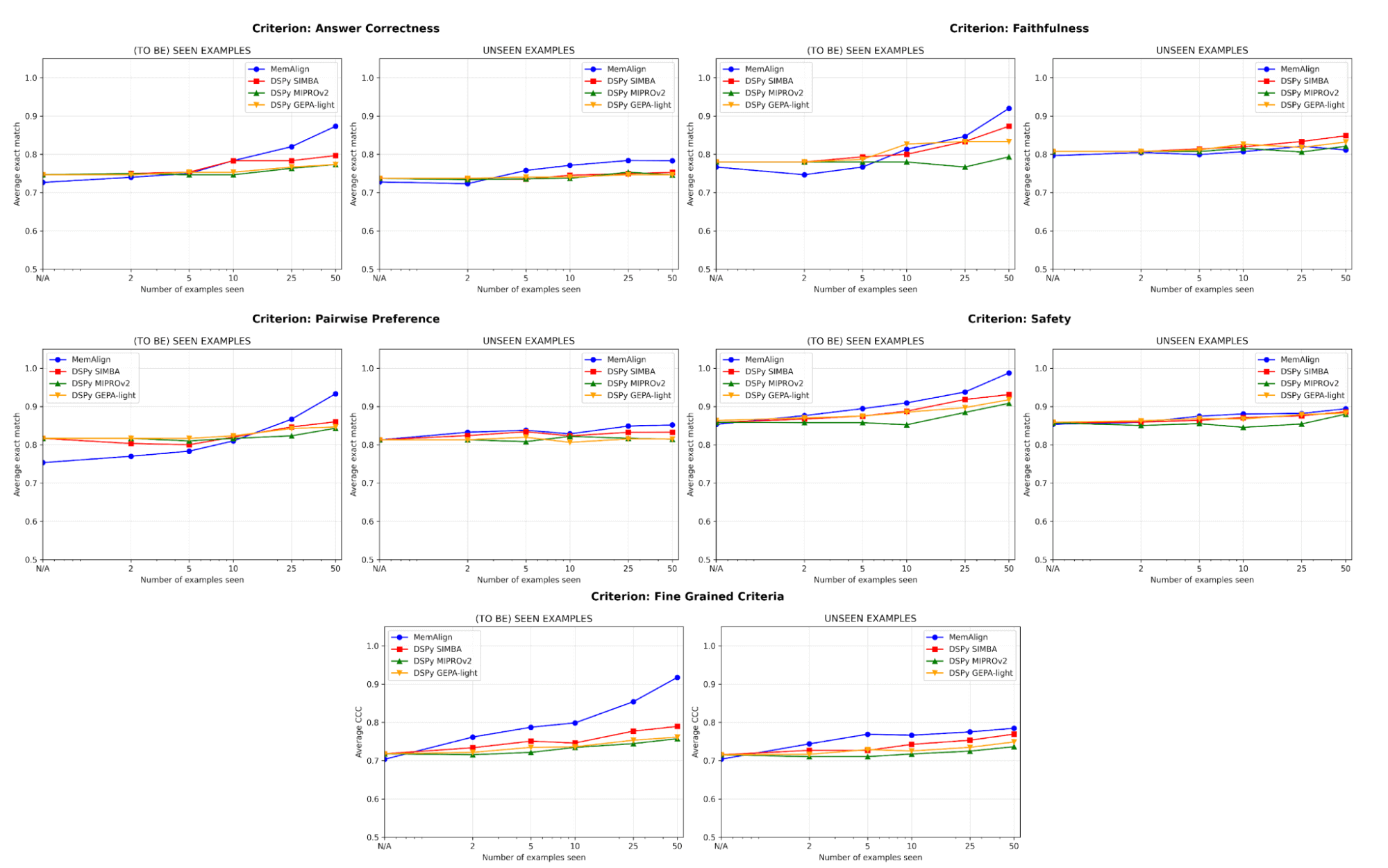
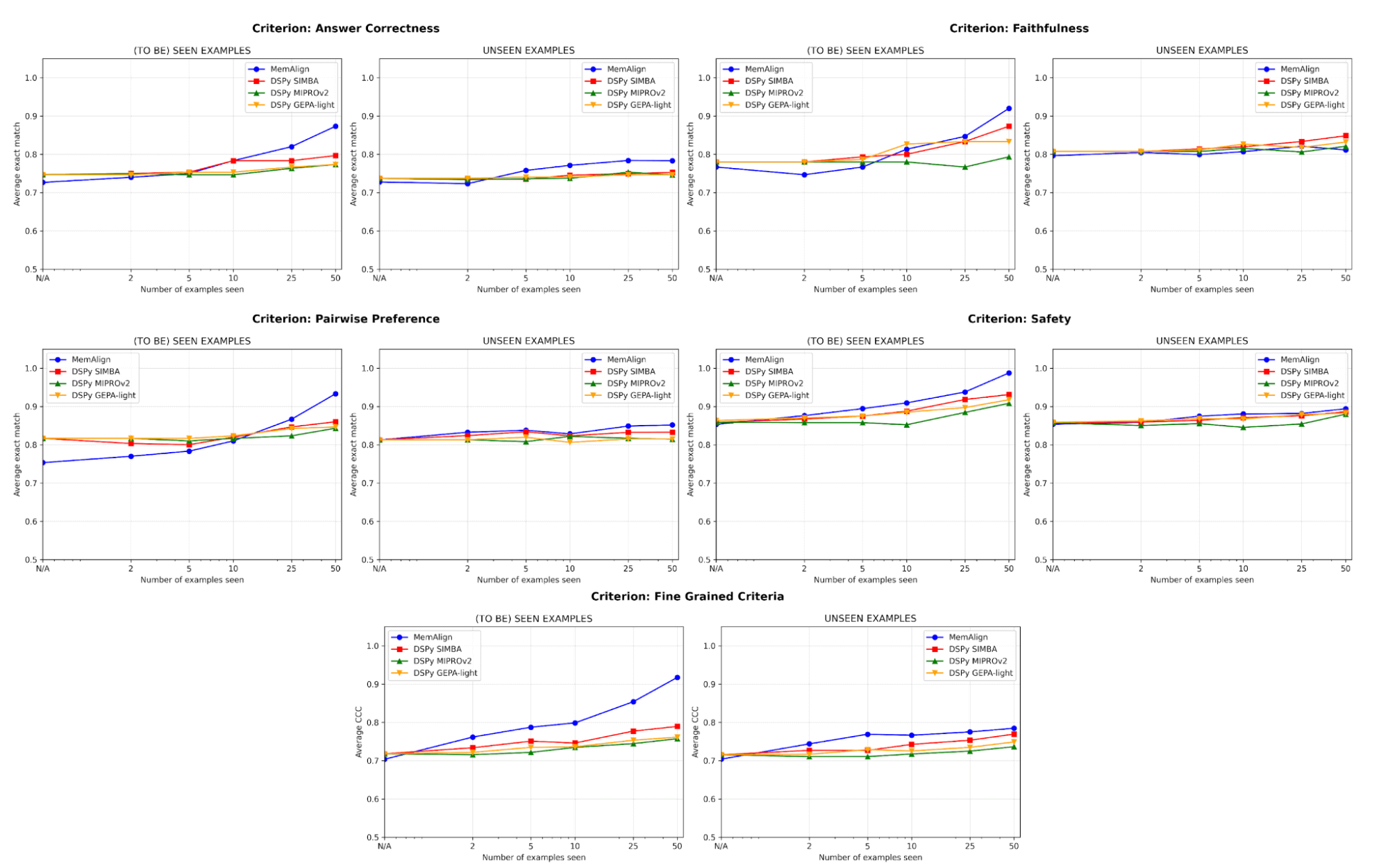
Hinsichtlich der Qualität vergleichen wir die Performance des Judges nach der Anpassung an eine zunehmende Anzahl von Beispielen mit MemAlign im Vergleich zu den Prompt-Optimierern von DSPy:
{kind=link}
Eines der größten Risiken beim Alignment ist die Regression – einen Fehler zu beheben, nur um ihn später erneut zu verursachen. Über alle Kriterien hinweg schneidet MemAlign bei gesehenen Beispielen (links) am besten ab und erreicht oft eine Genauigkeit von über 90 %, während andere Methoden oft bei 70–80 % stagnieren.
Bei ungesehenen Beispielen (rechts) zeigt MemAlign eine wettbewerbsfähige Generalisierung. Es übertrifft die Prompt-Optimierer von DSPy bei der Korrektheit der Antworten und schneidet bei anderen Kriterien ähnlich gut ab. Dies deutet darauf hin, dass es nicht nur Korrekturen auswendig lernt, sondern übertragbares Wissen aus dem Feedback extrahiert.
Dieses Verhalten veranschaulicht, was wir als Memory-Skalierung bezeichnen: Im Gegensatz zur Test-Time-Skalierung, die die Compute pro Abfrage erhöht, verbessert die Memory-Skalierung die Qualität, indem sie über die Zeit hinweg persistent Feedback akkumuliert.
Sie benötigen nicht viele Beispiele für den Start
Am wichtigsten ist, dass MemAlign bereits mit nur 2-10 Beispielen eine sichtbare Verbesserung zeigt, insbesondere bei feingranularen Kriterien und der Korrektheit der Antworten. In dem seltenen Fall, dass MemAlign niedriger startet (z. B. Paarweiser Vergleich), holt es mit 5-10 Beispielen schnell auf. Das bedeutet, dass Sie keinen massiven Labeling-Aufwand im Voraus betreiben müssen, bevor Sie einen Nutzen sehen. Eine spürbare Verbesserung tritt fast sofort ein.
Unter der Haube: Wie funktioniert MemAlign?
Um das Verhalten des Systems besser zu verstehen, führen wir zusätzliche Ablationsstudien an einem Beispiel-Dataset (wobei das Bewertungskriterium „Kann das Modell branchenspezifische technische Terminologie oder Fachjargon korrekt interpretieren“ lautet) aus dem prometheus-eval-Benchmark durch. Wir verwenden dasselbe LLM (GPT-4.1-mini) wie in den Hauptexperimenten.
Sind beide Speichermodule notwendig? Nach der Ablation jedes Speichermoduls beobachten wir in beiden Fällen Performance-Abfälle. Entfernt man das semantische Gedächtnis, verliert der Judge seine stabile Grundlage an Prinzipien; entfernt man das episodische Gedächtnis, hat er Schwierigkeiten mit Randfällen. Beide Komponenten sind für die Performance wichtig.
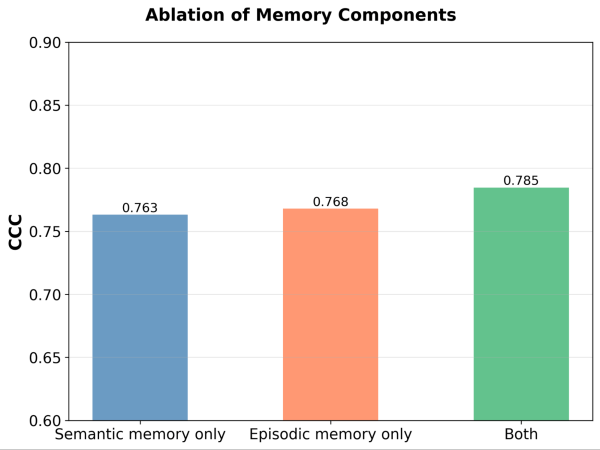
Abbildung 5. Performance (gemessen anhand des Konkordanz-Korrelations-Koeffizienten (CCC)) von MemAlign, wenn nur das semantische Gedächtnis, nur das episodische Gedächtnis oder beides aktiviert ist.
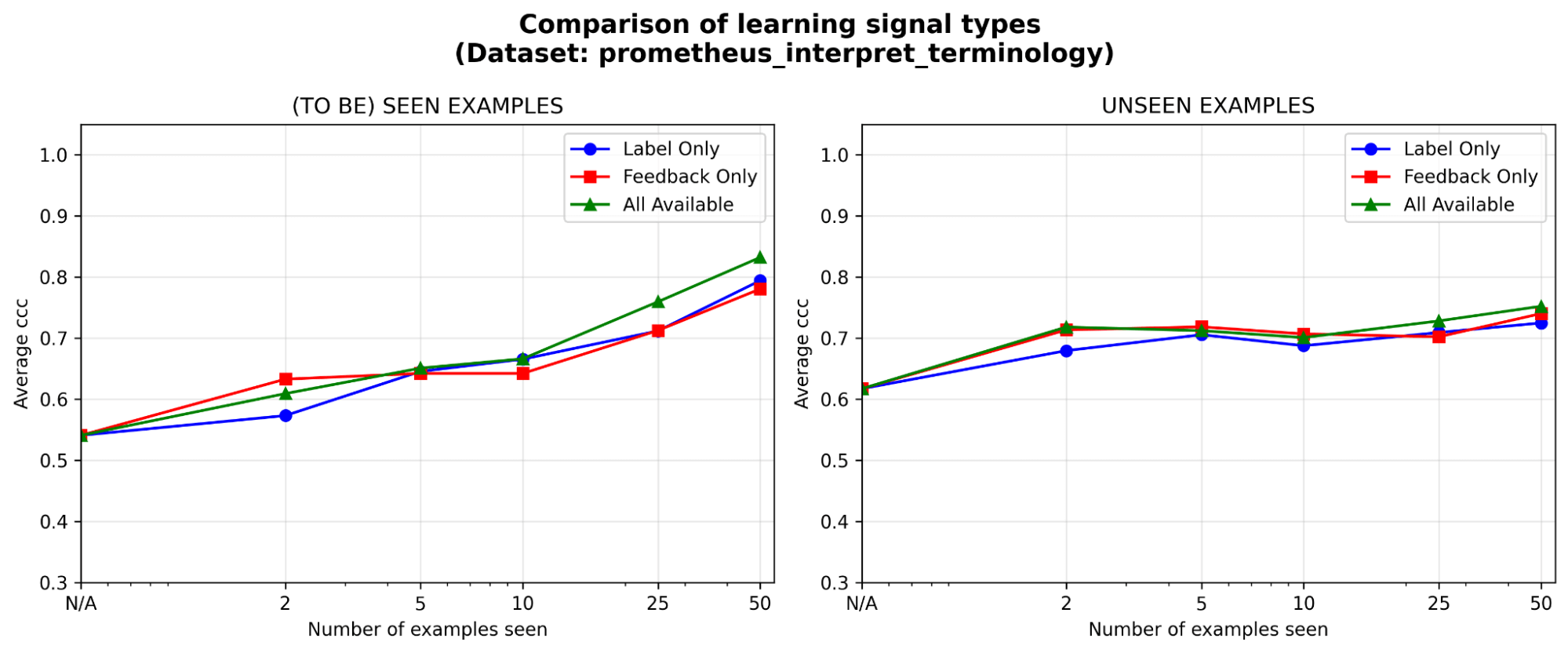
Feedback ist mindestens so effektiv wie Labels, insbesondere in der Anfangsphase. In welche Art von Lernsignal lohnt es sich bei einem festen Annotationsbudget am meisten zu investieren: Labels, Feedback in natürlicher Sprache oder beides? Wir sehen einen leichten anfänglichen Vorteil (<=5 Beispiele) für Feedback gegenüber Labels, wobei sich der Abstand verringert, je mehr Beispiele hinzukommen. Das bedeutet, dass, wenn Ihre Experten nur Zeit für eine Handvoll Beispiele haben, es möglicherweise besser ist, sie ihre Begründung erklären zu lassen; andernfalls könnten Labels allein ausreichen.
{kind=link}
Reagiert MemAlign empfindlich auf die Wahl des LLM? Wir führen MemAlign mit LLMs verschiedener Familien und Größen aus. Insgesamt schneidet Claude-4.5 Sonnet am besten ab. Aber auch kleinere Modelle zeigen eine erhebliche Verbesserung: Obwohl zum Beispiel GPT-4.1-mini niedrig startet, erreicht es die Performance von Spitzenmodellen wie GPT-5.2 nach 50 Beispielen. Das bedeutet, dass Sie nicht auf teure Spitzenmodelle angewiesen sind, um einen Mehrwert zu erzielen.
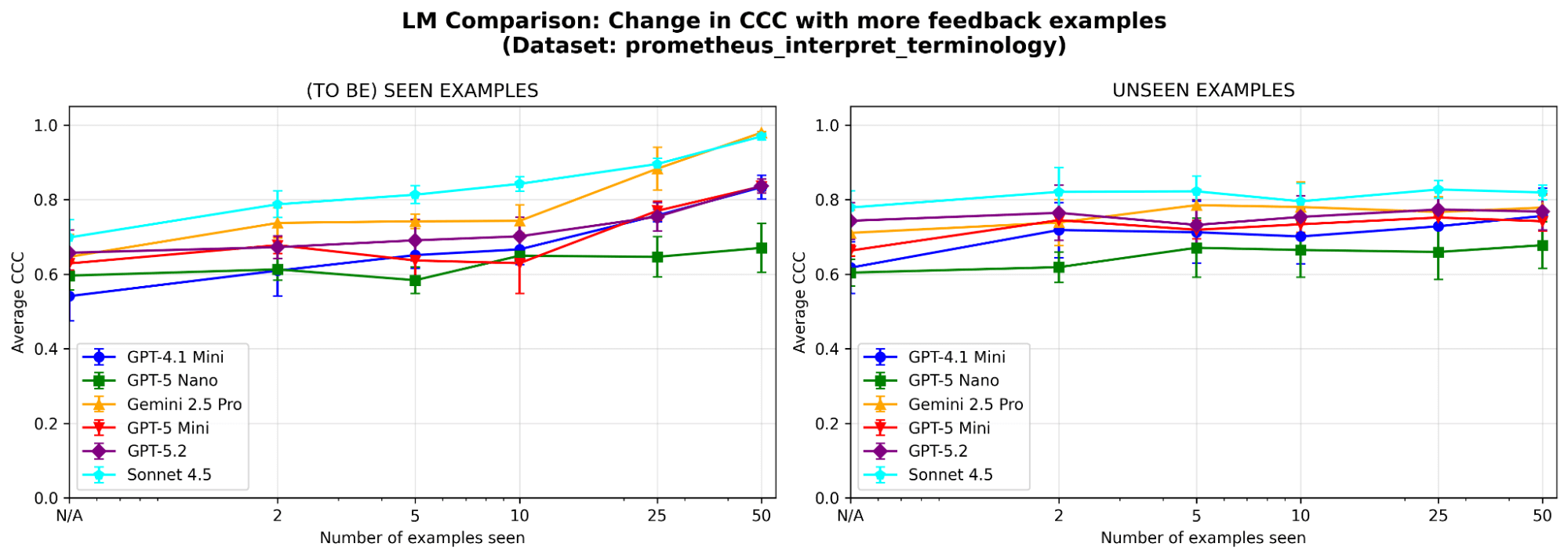
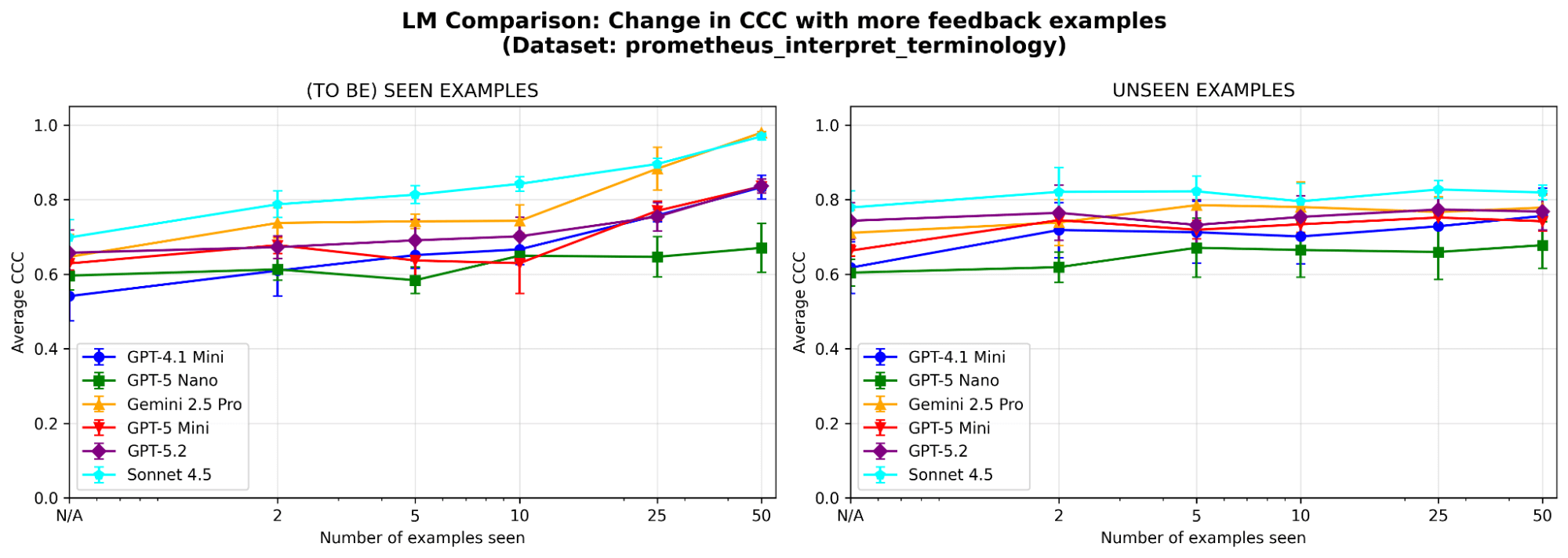{kind=link}
Wichtige Erkenntnisse
MemAlign überbrückt die Lücke zwischen Allzweck-LLMs und domänenspezifischen Nuancen mithilfe einer dualen Speicherarchitektur, die eine schnelle, kostengünstige Anpassung ermöglicht. Es spiegelt eine andere Philosophie wider: dichtes, natürlichsprachliches Feedback von menschlichen Experten zu nutzen, anstatt es mit einer großen Anzahl von Labels anzunähern. Im weiteren Sinne hebt MemAlign das Potenzial der Speicherskalierung hervor: Indem Erkenntnisse gesammelt werden, anstatt wiederholt neu zu optimieren, können sich Agenten kontinuierlich verbessern, ohne Einbußen bei Geschwindigkeit oder Kosten hinnehmen zu müssen. Wir glauben, dass dieses Paradigma für langlebige Agenten-Workflows, bei denen Experten in den Prozess eingebunden sind, immer wichtiger wird.
MemAlign ist jetzt als Optimierungsalgorithmus hinter der align() -Methode von MLFlow verfügbar. Schauen Sie sich dieses Demo-Notebook an, um loszulegen!
1Die obigen Ergebnisse vergleichen die Alignment-Geschwindigkeit. Zur Inferenzzeit kann bei MemAlign aufgrund der Vektorsuche im Speicher eine zusätzliche Latenz von 0,8–1 s pro Beispiel im Vergleich zu prompt-optimierten Judges auftreten.
Autoren: Veronica Lyu, Kartik Sreenivasan, Samraj Moorjani, Alkis Polyzotis, Sam Havens, Michael Carbin, Michael Bendersky, Matei Zaharia, Xing Chen
Wir möchten Krista Opsahl-Ong, Tomu Hirata, Arnav Singhvi, Pallavi Koppol, Wesley Pasfield, Forrest Murray, Jonathan Frankle, Eric Peter, Alexander Trott, Chen Qian, Wenhao Zhan, Xiangrui Meng, Moonsoo Lee und Omar Khattab für ihr Feedback und ihre Unterstützung beim Design, der Implementierung und der Veröffentlichung des Blogs zu MemAlign danken. Außerdem sind wir Michael Shtelma, Nancy Hung, Ksenia Shishkanova und Flo Health dankbar, die uns bei der Evaluierung von MemAlign auf ihren internen anonymisierten Datasets geholfen haben.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.