Was ist ein MMM und warum ist es für Marketer wichtig?
von Dan Morris, Corey Abshire, Tristan Nixon und Layla Yang

MMM (Marketing- oder Media-Mix-Modellierung) ist eine datengestützte Methodik, die es Unternehmen ermöglicht, die Wirkung ihrer Marketingkampagnen über mehrere Kanäle hinweg zu identifizieren und zu messen. Das Ziel von MMM ist es, Unternehmen dabei zu helfen, fundierte Entscheidungen über ihre Werbe- und Marketingstrategien zu treffen. Durch die Analyse von Daten aus verschiedenen Kanälen wie TV, Social Media, E-Mail-Marketing und mehr kann MMM ermitteln, welche Kanäle am meisten zu Umsätzen und anderen Geschäftsergebnissen beitragen. Durch die Einbeziehung externer Ereignisse und Indikatoren können Entscheidungsträger die Auswirkungen externer Faktoren (wie Feiertage, wirtschaftliche Bedingungen oder das Wetter) besser verstehen und vermeiden, den Einfluss von Werbeausgaben allein versehentlich überzubewerten.
Mithilfe von MMM können Unternehmen ermitteln, welche Marketingkanäle das meiste Engagement, die meisten Verkäufe oder den höchsten Umsatz generieren. Diese Informationen können genutzt werden, um Marketingbudgets zu optimieren und Ressourcen den effektivsten Kanälen zuzuweisen. Nehmen wir beispielsweise an, ein Unternehmen führt Marketingkampagnen über verschiedene Kanäle wie Social Media, E-Mail-Marketing, TV-Werbung usw. durch. Das Marketingteam ist sich jedoch nicht sicher, welcher Kanal den höchsten ROI liefert. Hier kommt MMM ins Spiel. Durch die Analyse der aggregierten Daten aus all diesen Kanälen kann ein leistungsstarkes Modell das Unternehmen dabei unterstützen, die umsatzstärksten Kampagnen sowie die Kanäle mit dem effizientesten Return on Ad Spend zu identifizieren, sodass sie ihre Werbestrategien effektiv optimieren können. Dies ermöglicht es dem Unternehmen, seine Marketingaktivitäten zu optimieren und sein Budget in die richtige Richtung zu lenken.
Seit Jahren ist MMM ein sehr leistungsstarkes Tool und gilt als Game-Changer, der klugen Unternehmen den nötigen Vorsprung verschafft, um der Konkurrenz einen Schritt voraus zu sein. Durch die Nutzung datengestützter Entscheidungsfindung ermöglicht MMM es Unternehmen, kluge Investitionen in ihre Marketingstrategien zu tätigen und sicherzustellen, dass jeder Cent an der richtigen Stelle, zur richtigen Zeit und auf die richtige Weise ausgegeben wird. Dies führt zu überzeugenden Ergebnissen, von höherem Kundenengagement und steigenden Umsätzen bis hin zu einem hohen Return on Investment.
Die Evolution von MMM
MMM gibt es bereits seit Jahrzehnten, und es war schon immer ein leistungsstarkes Tool zur Messung der Effektivität von Marketingkampagnen. Das Modell kann verschiedene Faktoren wie Saisonalität, Wettbewerbsaktivitäten und makroökonomische Trends berücksichtigen, um ein ganzheitliches Bild der Gesamtwirkung von Marketingaktivitäten zu vermitteln. In den letzten Jahren wurde MMM jedoch etwas von MTA (Multi-Touch-Attribution) in den Schatten gestellt, das einen granulareren Attributionsansatz bietet, indem es einzelne Nutzer über mehrere Touchpoints hinweg verfolgt. Mit MTA können Marketer sehen, welche spezifischen Touchpoints Conversions bei einzelnen Nutzern auslösen, und ihr Budget entsprechend zuweisen. Dieser Grad an Granularität hat MTA zu einer beliebten Wahl für viele Marketer gemacht, insbesondere im digitalen Marketing.
Doch mit den neuen Datenschutzbestimmungen wie der GDPR (General Data Protection Regulation) und dem CCPA (California Consumer Privacy Act) wird das Cookie-basierte Tracking, auf das MTA angewiesen ist, immer schwieriger. Das bedeutet, dass MMM, das aggregierte Daten anstelle von Daten auf Nutzerebene verwendet, nun neuen Aufwind erhält.
Sie fragen sich vielleicht, welches Tool Sie zur Messung der Marketingeffektivität wählen sollten. Bei der Entscheidung zwischen beiden gibt es einige Faktoren zu berücksichtigen, wenn es um die Wahl von MMM geht. Eine Option ist die Wahl von MMM, wenn Ihre Daten teilweise oder vollständig voraggregiert sind. Ein weiterer Faktor ist, ob Ihre Marketingaktivitäten sowohl Online- als auch Offline-Kanäle umfassen. Dies wird im heutigen digitalen Zeitalter, in dem die Grenzen zwischen Online- und Offline-Marketing oft verschwimmen, immer wichtiger. Schließlich kann MMM Ihnen helfen, diese Daten in Ihr Modell zu integrieren, wenn Sie über zusätzliche Informationen verfügen, die für Ihre Marketingaktivitäten relevant sind, wie z. B. Geo-Testergebnisse.
Vorteile von MMM
Erstens kann eine MMM-basierte Analyse die Auswirkungen von Offline-Kanälen wie TV-, Print-, Radio- oder OOH-Werbung (Out-Of-Home) einbeziehen, die mit Cookies nicht nachverfolgt werden können. Einige fortgeschrittenere Modellierungstechniken können sogar den Funnel-Effekt einbeziehen, der beschreibt, wie verschiedene Kanäle zusammenwirken, sowie multiplikative Effekte, die die synergistische Wirkung dieser Kanäle berücksichtigen. Darüber hinaus kann es Einblicke in die längerfristigen Auswirkungen von Marketingaktivitäten liefern, die MTA möglicherweise entgehen. MMM gilt als skalierbarer und kann zur Messung der Auswirkungen von Marketingaktivitäten in großen geografischen Regionen oder sogar ganzen Ländern eingesetzt werden.
Zudem kann MMM Unternehmen dabei helfen, Datenschutzbestimmungen einzuhalten, da aggregierte Daten anstelle von individuellen Nutzerdaten verwendet werden. Das bedeutet, dass Unternehmen die Effektivität ihrer Marketingaktivitäten weiterhin messen können, ohne die Privatsphäre der Nutzer zu gefährden.
In diesem Blogbeitrag werden wir die wichtigsten Funktionen von MMM untersuchen und zeigen, wie die Databricks Lakehouse-Plattform Unternehmen dabei unterstützen kann, eine robuste und skalierbare moderne MMM-Lösung aufzubauen.
Häufige Herausforderungen meistern
MMM wird von einer Vielzahl von Unternehmen entwickelt, von Beratungsfirmen über Werbetreibende bis hin zu Softwareanbietern. Da Unternehmen weiterhin nach Möglichkeiten suchen, ihre Marketingausgaben zu optimieren, ist MMM zu einer immer beliebteren Methode zur Messung des ROI geworden. Der Aufbau einer skalierbaren und robusten MMM-Lösung kann jedoch eine anspruchsvolle Aufgabe sein. In diesem Abschnitt erörtern wir einige der häufigsten Herausforderungen, mit denen Unternehmen beim Aufbau einer skalierbaren Lösung konfrontiert sind. In diesem Abschnitt gehen wir auf einige der häufigsten Herausforderungen ein.
Eine der größten Herausforderungen beim Aufbau einer MMM-Lösung sind die vorgelagerten Datenquellen. Das Data-Science- und Machine-Learning-Team muss Datenströme aus verschiedenen Quellen für MMM-Daten zusammenführen, einschließlich Drittanbieterdaten wie ökonometrischen Daten, für die es keine standardisierten Erfassungsmethoden gibt. Zudem sind die Datenquellen oft über verschiedene Orte wie Altsystem-Datenbanken, Hive, SFTP-Flat-Files und andere Quellen verstreut, was die Beschaffung der erforderlichen Daten erschwert. Darüber hinaus müssen die Daten jeden Monat manuell aktualisiert werden, was eine mühsame und zeitaufwendige Aufgabe sein kann.
Ein weiteres Hindernis für präzise MMM-Ergebnisse ist das Fehlen von Daten. Beispielsweise kommt es häufig vor, dass die Erfassung von Wirtschaftsdaten und traditionellen/Offline-Mediendaten fehlt, was die Genauigkeit der Ergebnisse erheblich beeinträchtigen kann. Diese Herausforderung kann besonders für Unternehmen ausgeprägt sein, die in mehreren Ländern vertreten sind, in denen Vorschriften die Datenerfassung und -weitergabe einschränken können. Im modernen AI-Zeitalter ist die MMM-Lösung als eine Form von Machine-Learning-Modell nicht von den Herausforderungen und Risiken ausgenommen, die mit dem aufstrebenden Feld der AI verbunden sind. Die Nachverfolgung der Lineage von den Datenquellen bis zu den Modellen von der Erfassung bis hin zum Insight-Dashboard kann bei herkömmlichen Ansätzen eine erhebliche Hürde darstellen, was es schwierig macht, Transparenz und Verantwortlichkeit zu gewährleisten.
Zudem kann das Bestehen von Teamsilos die Erstellung einer skalierbaren MMM-Lösung behindern. Die Modellentwicklung findet oft in isolierten Umgebungen statt, was zu Barrieren zwischen Teams führt – sowohl horizontal über technische und geschäftliche Funktionsbereiche hinweg als auch vertikal über Organisationsebenen, Marken, Kategorien und Geschäftsbereiche hinweg. Das Fehlen von Versionskontrollmethoden für Modelle, Code und Daten kann zu Inkonsistenzen und Ungenauigkeiten innerhalb der MMM-Lösung führen. Darüber hinaus kann unhandlicher Legacy-Code die Wartung und Aktualisierung der Lösung erschweren, was umfangreiche Refactoring-Maßnahmen erforderlich macht. Zudem laufen Prozesse oft manuell ab, und Analysen werden in der Regel als einmalige Aktivitäten alle paar Monate durchgeführt, die von Einzelpersonen oder kleinen Teams wiederholt werden müssen, anstatt Teil einer automatisierteren, wiederholbaren und zuverlässigen DSML-Pipeline zu sein.
Schließlich verzögern sich die Datenveröffentlichung und das Teilen von Erkenntnissen oft und erfordern eine separate Integration. Dies kann es für Stakeholder erschweren, schnell fundierte Entscheidungen zu treffen, was zu weiteren Verzögerungen bei der Entscheidungsfindung, verpassten Chancen und mangelnder Agilität führt, um in einem zunehmend schnelllebigen und dynamischen wirtschaftlichen Umfeld zu reagieren – insbesondere wenn sich die Konkurrenz in Lichtgeschwindigkeit bewegt. Vielen bestehenden MMM-Lösungen fehlt zudem die Flexibilität und der Datenschutz, die für eine effektive Zusammenarbeit mit Kunden und Partnern erforderlich sind.
Infolgedessen müssen Unternehmen bei der Implementierung von MMM im Zeitalter von AI einen umfassenden und sorgfältigen Ansatz wählen, der die einzigartigen Herausforderungen und Risiken im Zusammenhang mit der DSML-Technologie berücksichtigt.
Bauen Sie Ihr skalierbares und flexibles MMM mit dem Databricks Lakehouse auf
Referenzdiagramm
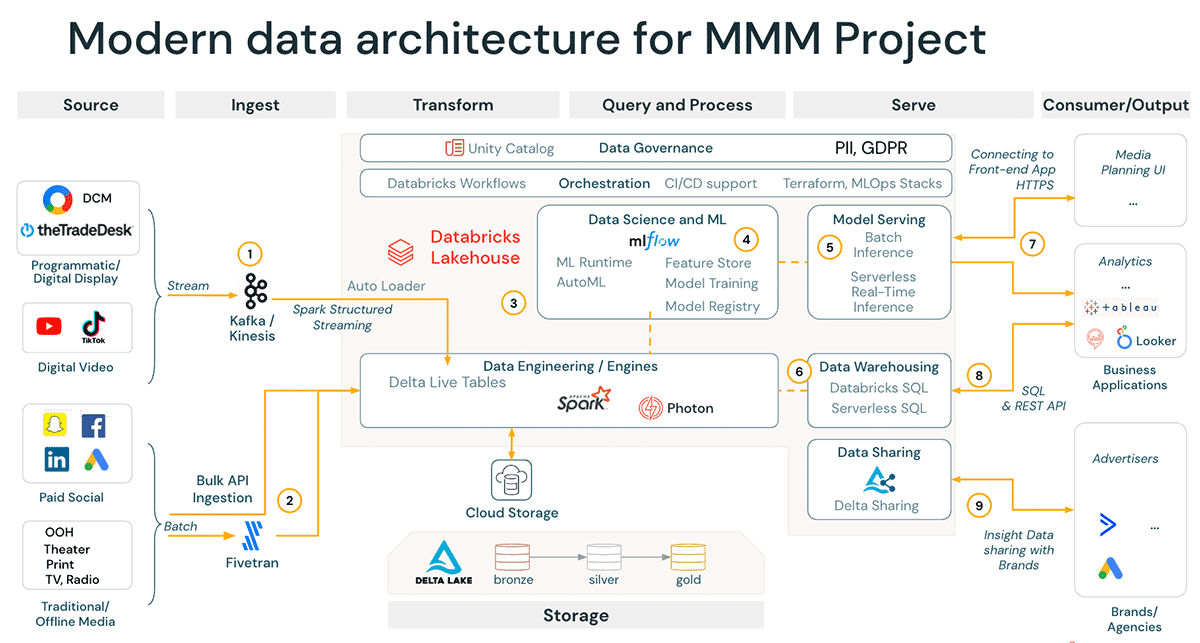
Das Databricks Lakehouse ist darauf ausgelegt, eine einheitliche Plattform für Unternehmen bereitzustellen, um modernisierte MMM-Lösungen aufzubauen, die sowohl skalierbar als auch flexibel sind.
Einer der bedeutendsten Vorteile des Databricks Lakehouse ist seine Fähigkeit, verschiedene vorgelagerte Datenquellen zusammenzuführen. Das bedeutet, dass die Plattform unterschiedliche Datenquellen, die für MMM unerlässlich sind – wie Offline-Ökonometriedaten, Medienkampagnendaten und CRM-Daten –, in einer einzigen zentralen Datenquelle (Single Source of Truth) vereinen kann. Dies ist in der heutigen datengesteuerten Welt, in der Unternehmen große Datenmengen aus verschiedenen Quellen verarbeiten müssen, besonders nützlich.
Ein weiterer entscheidender Vorteil des Databricks Lakehouse, der MMM erheblich zugutekommt, ist die Möglichkeit, Datenpipelines zu optimieren. Nach der Datenerfassung erfordert der MMM-Prozess die Transformation verschiedener Marketingkanäle und die Analyse ihrer Auswirkungen auf KPIs, was die Verarbeitung einer Vielzahl von Daten aus unterschiedlichen Quellen mit sich bringt. Das Lakehouse kann die Datenerfassung, -verarbeitung und -transformation automatisieren und so den Zeit- und Arbeitsaufwand für die manuelle Verwaltung von Datenpipelines reduzieren. Dies stellt sicher, dass Daten inkrementell und mit einer umfassenden Überwachung der Datenqualität bereitgestellt werden.
Darüber hinaus bietet das Lakehouse ein Lineage-Tracking-System, das die lückenlose Rückverfolgbarkeit (Lineage) für alle Ihre Daten-Assets sicherstellt – nicht nur für die Daten selbst, sondern auch für Code, Modellartefakte und Job-Iterationen. Dies ist ein wesentlicher Vorteil des Databricks Lakehouse. Es bietet volle Transparenz und Nachvollziehbarkeit der Datennutzung, sodass Unternehmen fundierte, datengesteuerte Entscheidungen treffen können. Dies ist im Kontext von MMM besonders wichtig, da die Genauigkeit und Zuverlässigkeit der Daten entscheidend sind, um den Einfluss von Marketingkanälen auf den Umsatz zu verstehen und die Budgetallokation im Marketing anzupassen.

In der Modellierungsphase zeigt sich einer der Hauptvorteile des Databricks Lakehouse: seine leistungsstarken DSML-Funktionen, die insbesondere in der erstklassigen ML Runtime und den MLOps-Tools zum Tragen kommen. Eine entscheidende Aufgabe bei der MMM-Modellierung ist die umfassende Festlegung von Prior-Einstellungen und die Variablentransformation, was eine Vielzahl von Iterationen erfordert. MLflow ermöglicht es Marketern, die Herleitung und Transformation ihrer unabhängigen Variablen (Features) sowie deren Verwendung in Modellen zu verfolgen. Darüber hinaus fördert der Databricks Feature Store Best Practices im Feature Engineering, indem er dem DSML-Team die erforderlichen Tools und die Infrastruktur zur Erstellung, Erkennung und Wiederverwendung von Features bereitstellt. Dies optimiert den Modellierungsprozess und erhöht die Genauigkeit von Vorhersagen für Geschäftsergebnisse. Diese Funktionen ermöglichen es Marketern, das volle Potenzial ihrer Daten nahtlos auszuschöpfen und fundiertere sowie effektivere Marketingentscheidungen zu treffen.
Inzwischen sollte klar sein, dass Databricks dem MMM-Team enorme Effizienzgewinne bringt! Mit Databricks können selbst Data Scientists auf einzelnen Nodes das Tuning und Training verteilen, mehrere Szenarien und Konfigurationen gleichzeitig auf dem Cluster ausführen und unabhängige Modelle für verschiedene Marken, Kategorien und Regionen parallel erstellen (siehe Demonstration unten):
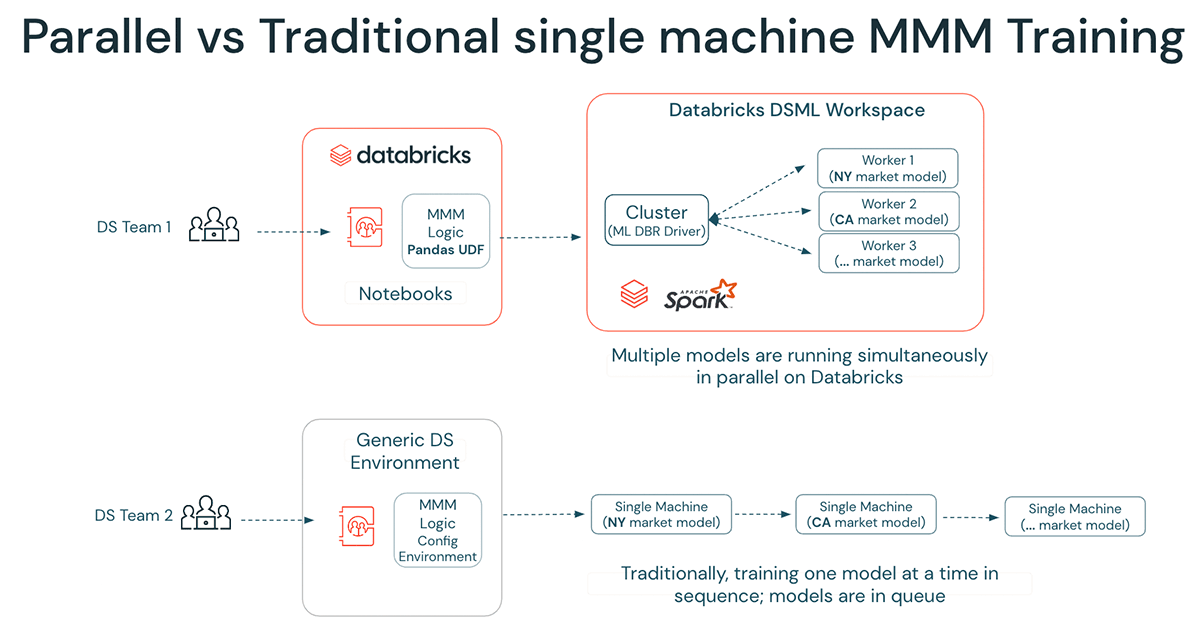
Die ML Runtime ist eine vollständig verwaltete, sichere und kollaborative ML-Umgebung, die die Produktivität des DS-Teams direkt steigert, ohne dass dieses eine eigene DS-Umgebung aufsetzen, erstellen oder warten muss. Darüber hinaus fördert sie einen kollaborativen Arbeitsablauf, indem sie das einfache Teilen von Ergebnissen erleichtert, was inkonsistente Ansätze verschiedener Teams verhindert. Eine Lösung besteht darin, Mechanismen zum Auffüllen fehlender Daten zu entwickeln, z. B. durch die Beschaffung über einen Marketplace oder die Speicherung von Daten aus Quellen wie Dun & Bradstreet, S&P, Edgar, Wetterdaten und Marktforschung an einem gut kuratierten Ort im Lakehouse. Dieser Ansatz kann verhindern, dass Teams das Rad bei Daten und Code neu erfinden müssen, was letztendlich Zeit und Ressourcen spart. Es ist jedoch wichtig anzuerkennen, dass dieser Mangel an Wiederverwendung und das Neuerfinden des Rads auch für den Code und den Rest der Pipeline gilt. Daher ist es notwendig, MMM in Teamsilos zu verlagern, um die Effizienz zu steigern und Diskrepanzen zu minimieren.
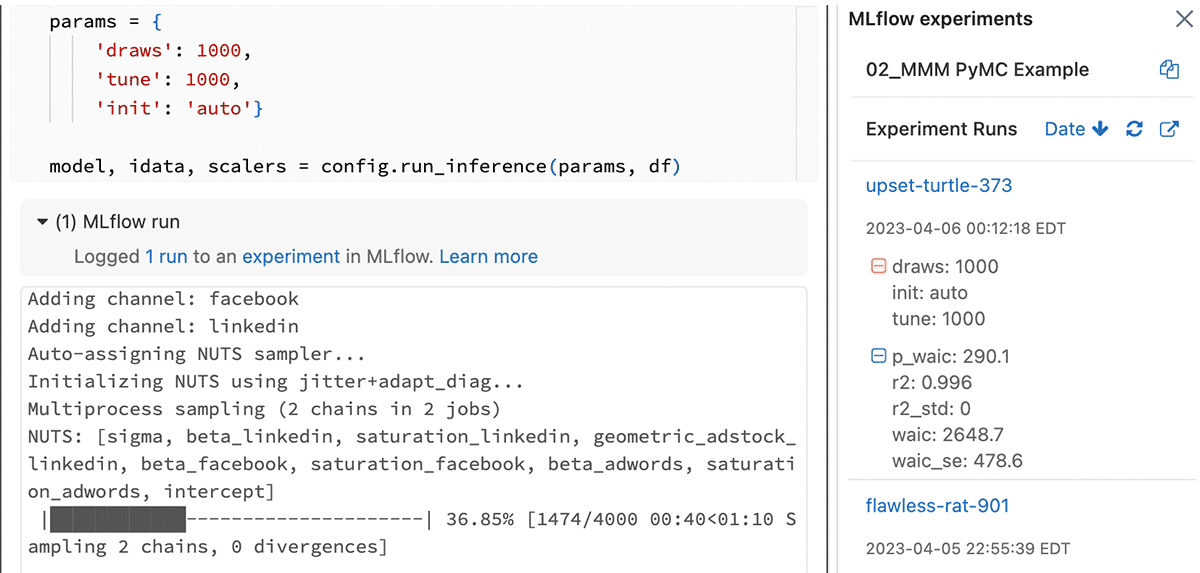
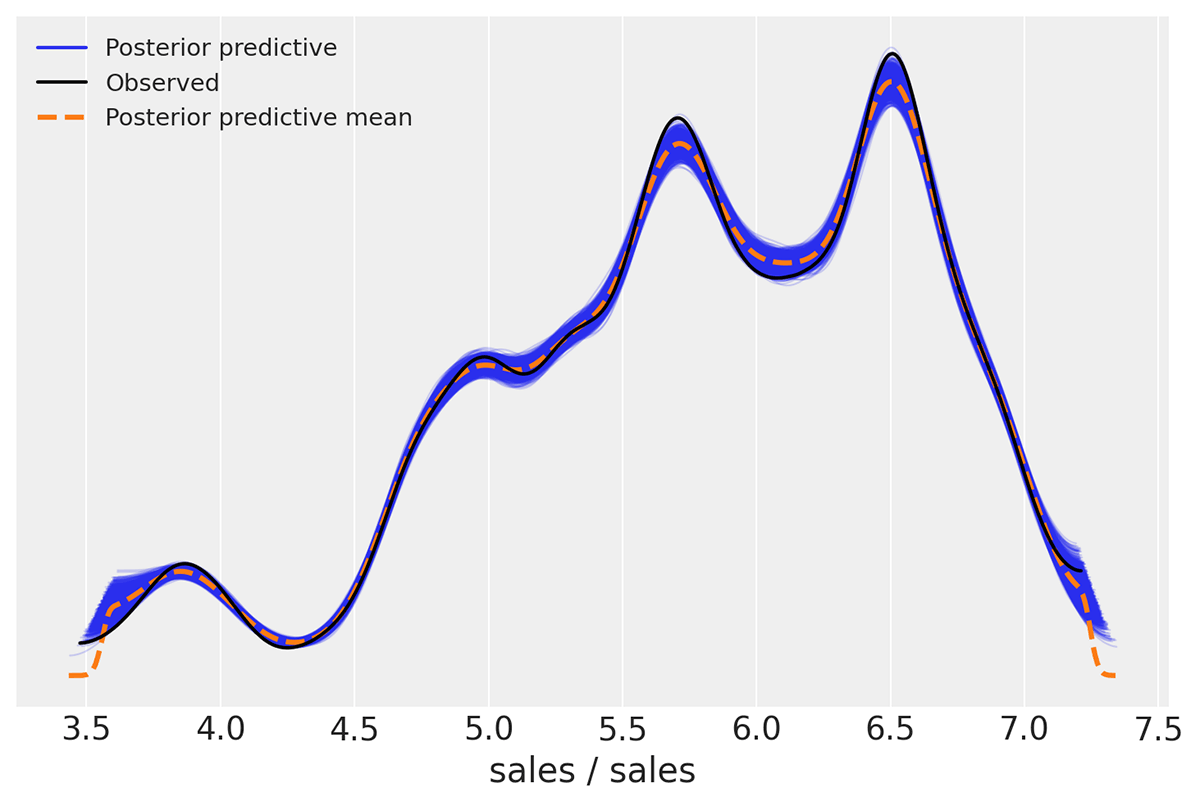
Der Open-Source-Charakter des Lakehouse bietet die ideale Umgebung für die Ausführung aller gängigen Open-Source-Bibliotheken für MMM, wie z. B. PyMC in Python und Robyn in R. Diese Funktion ermöglicht es Benutzern, Lösungen zu entwickeln, die auf ihre spezifischen Anforderungen zugeschnitten sind, und eine Anbieterabhängigkeit (Vendor-Lock-in) zu vermeiden.
Nicht zuletzt ermöglicht DBSQL mit BI-Integration und dem Databricks Marketplace dem MMM-Team, Modellerkenntnisse mühelos zu veröffentlichen. Dies verkürzt die Zeit, um neue Modellierungsprojekte von der Datenerfassung bis hin zu handlungsrelevanten Erkenntnissen für MMM-Entscheider zu bringen. Durch die Konsolidierung und Standardisierung aller Daten- und KI-Aktivitäten ist das Lakehouse der beste Ort, um nicht nur eine MMM-Lösung zu entwickeln, sondern auch jede andere Daten- und KI-Lösung, an der das Team heute und in Zukunft arbeiten wird.
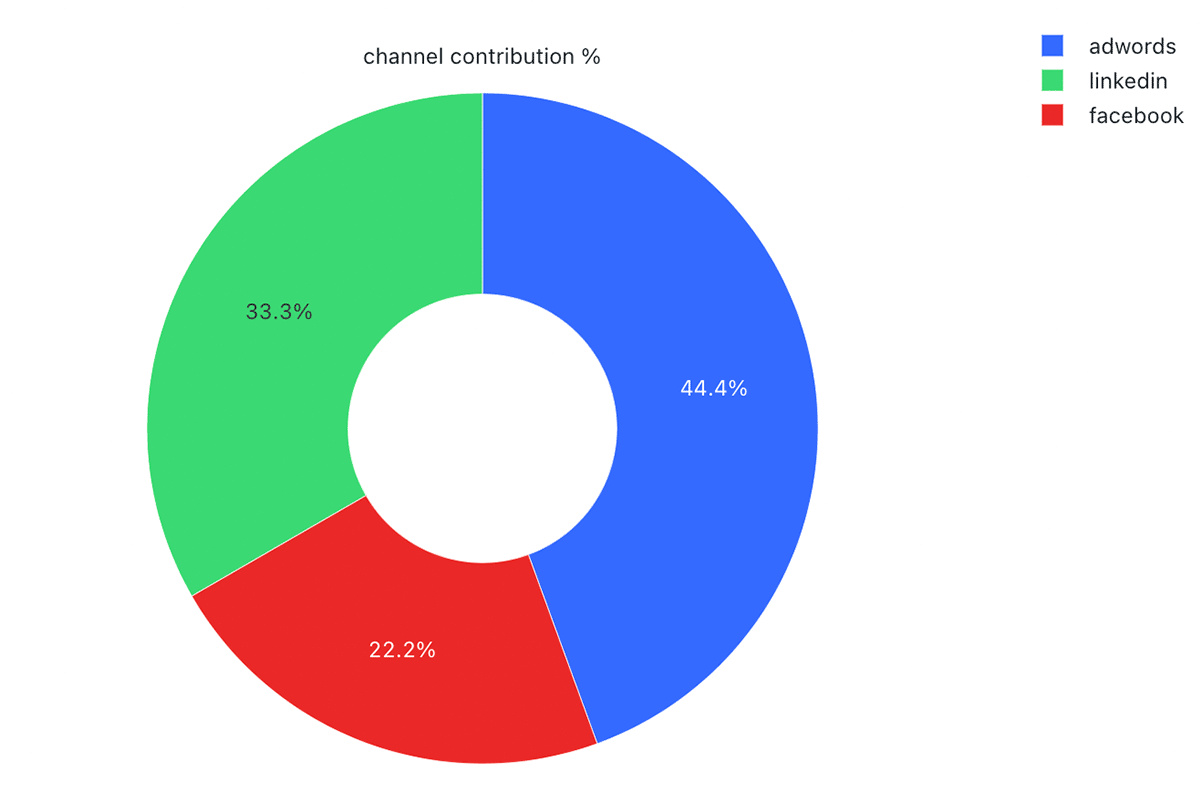
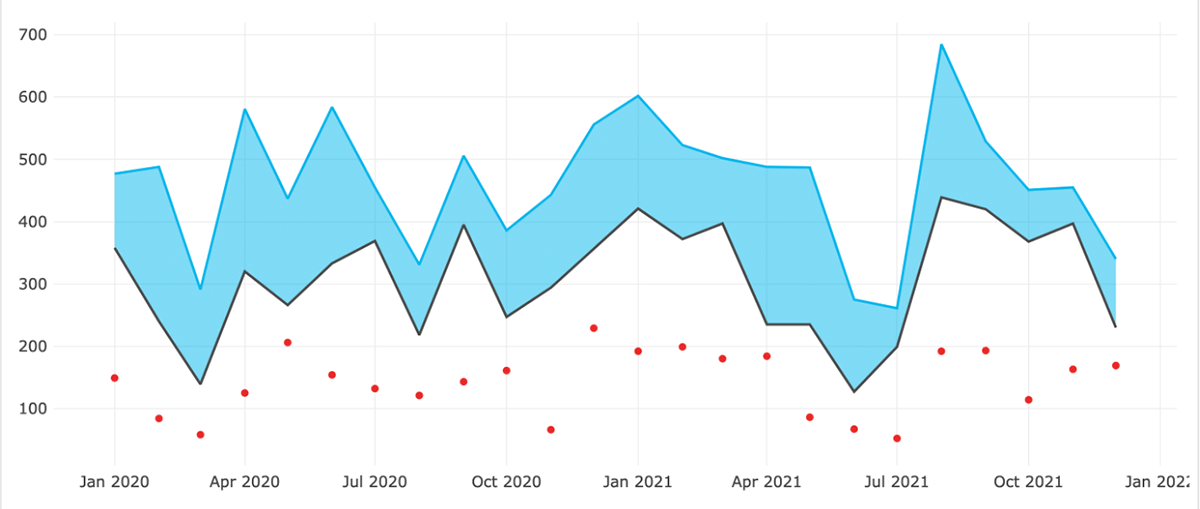
Erfahren Sie, wie Databricks für Lakehouse Ihnen helfen kann, Marketingkampagnen über mehrere Kanäle hinweg mit MMM zu optimieren. Greifen Sie auf den Solution Accelerator zu.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.