Zero-Downtime Patching in Lakebase Teil 1: Prewarming
Das erste von mehreren Features, die Compute-Neustarts unsichtbar machen
von Hans Norheim
- Geplante Wartungsarbeiten verursachen bei den meisten Datenbanken mehr Störungen als ungeplante Ausfälle, da Patches häufiger auftreten als Hardwarefehler. Ziel ist es, Versionsupdates und Sicherheitspatches vollständig unbemerkt zu machen.
- Das Kernproblem bei Datenbankneustarts ist, dass In-Memory-Caches gelöscht werden, was zu einer Durchsatzverschlechterung von bis zu 70 % führt, während Daten aus dem Speicher neu geladen werden. Unter hoher Arbeitslast kann dies von einem Leistungsproblem zu einem Verfügbarkeitsproblem eskalieren.
- Lakebase löst dieses Problem, indem vor einem geplanten Neustart im Hintergrund ein neuer Compute-Knoten gestartet wird, dessen Cache mithilfe der Seitenliste und des WAL-Streams des aktuellen Primärknotens vorab aufgewärmt wird, und dieser dann ohne zusätzliche Kosten oder Replikationsaufwand zum Primärknoten befördert wird.
Die Gewährleistung der ständigen Verfügbarkeit von Kundendatenbanken ist eine der wichtigsten Aufgaben, die wir in Lakebase erledigen. Wir haben das System auf jeder Ebene mit Redundanz konzipiert und schalten Ihre Datenbank bei Hardware- oder Softwarefehlern automatisch um und stellen sie wieder her.
In einem großen System sind solche ungeplanten Ausfälle statistisch zu erwarten, aber für eine einzelne Datenbank treten sie nicht so häufig auf. Für eine einzelne Datenbank verursacht geplante Wartung tendenziell mehr Arbeitsunterbrechungen. Schließlich wird eine typische Datenbank häufiger gepatcht, als dass Hardwareausfälle auftreten.
Heute arbeitet fast jeder Datenbankanbieter mit Wartungsfenstern: Zeiträume, in denen Ihre Datenbank alle aktiven Verbindungen trennt und in einem Prozess aktualisiert und neu gestartet wird, der einige Sekunden bis Minuten dauern kann. Während Lakebase es Ihnen ermöglicht,Updates zu planen, zu einer für Sie optimalen Zeit, ist es dennoch eine kurze Unterbrechung, wenn sie auftritt.
Wir denken, wir können das besser machen. Dieser Blogbeitrag ist der erste einer Reihe darüber, wie wir die Lakebase-Architektur nutzen, um die Auswirkungen geplanter Wartungsarbeiten vollständig zu eliminieren. Unser Ziel: Versionsupdates und Sicherheitspatches vollständig unbemerkt machen.
In diesem Beitrag behandeln wir Prewarming: eine Technik, die Leistungseinbußen nach einem Datenbankneustart verhindert. In zukünftigen Beiträgen werden wir Verbesserungen am Failover-Prozess selbst und zusätzliche Optimierungen diskutieren, die uns näher an ein echtes Zero-Downtime-Patching bringen.
Das Problem mit Kaltstarts
Die Herausforderung beim Neustart von PostgreSQL besteht darin, dass In-Memory-Caches (insbesondere der Buffer Cache und der lokale Dateicache) verloren gehen. Obwohl die Datenbank sehr schnell wieder online ist (1 Sekunde @ P99), kann die Arbeitslast in den ersten Minuten nach dem Neustart eine Verlangsamung erfahren – wir sahen eine Reduzierung des pgbench TPS um ca. 70 %. Dies liegt an einer niedrigen Cache-Trefferquote, während Daten vom Speicher gelesen und der Cache aufgewärmt werden. Dies mag zwar nur ein Leistungsproblem sein, kann aber ein Verfügbarkeitsproblem darstellen, wenn die Verlangsamung so stark ist, dass die Datenbank die Arbeitslast nicht bewältigen kann und Timeouts auftreten.
Techniken zur Bewältigung dieses Problems existieren in Postgres: pg_prewarm kann zum Aufwärmen von Buffer-Caches verwendet werden. Dies geschieht jedoch nach einem Neustart, wenn die Arbeitslast bereits beeinträchtigt ist. Streaming-Replikation kann zum Einrichten einer Replik verwendet werden, die vor dem Failover (Beförderung zum primären Server) vorab aufgewärmt werden kann. Dies erfordert jedoch die Erstellung einer vollständigen Replik und die sorgfältige Orchestrierung des Prewarmings vor dem Failover.
Prewarming auf der Lakebase-Architektur
In der Lakebase-Architektur kombinieren wir zustandslose, elastische Compute-Knoten mit disaggregiertem, gemeinsam genutztem Speicher. Die Compute-Knoten verwenden lokale Caches, um maximale Leistung zu erzielen, ohne Serverless-Eigenschaften zu opfern. Während der Cache mit denselben Kaltstartproblemen konfrontiert ist, wie oben beschrieben, haben wir mit der Lakebase-Architektur mehr Optionen.
Da die Postgres-Compute-Replikate von Lakebase zustandslos sind, können wir sie nach Bedarf hoch- und herunterfahren. Wir nutzen dies und kombinieren es mit automatischem Prewarming bei geplanten Neustarts, um die Leistungseinbußen für die Arbeitslast zu minimieren. So funktioniert es:
- Eine neue Version des Postgres-Compute-Images von Lakebase wird verfügbar. Sie erhalten eine Benachrichtigung und können den Neustart für eine für Sie passende Zeit planen.
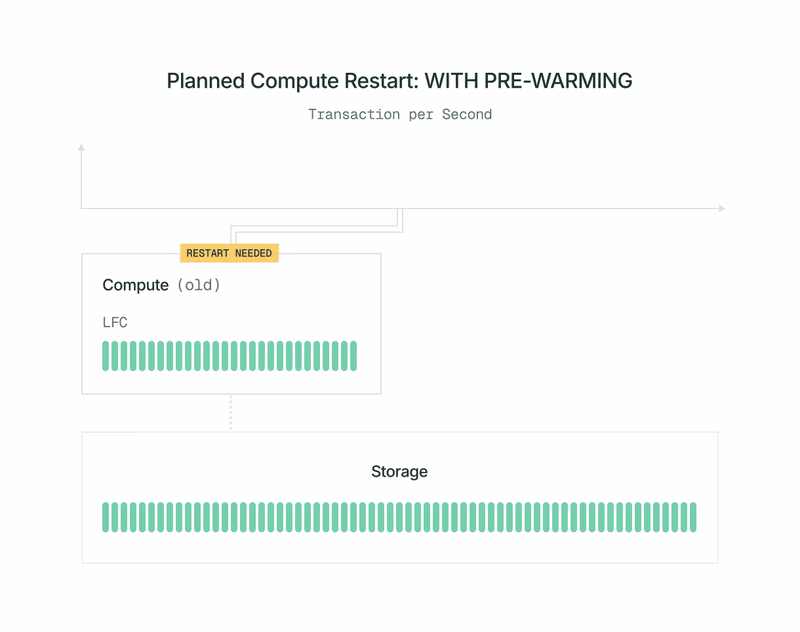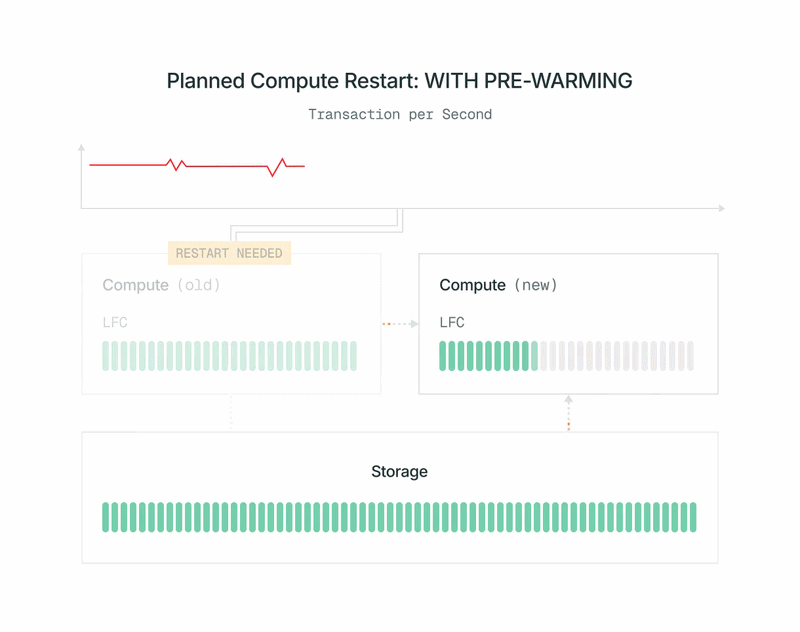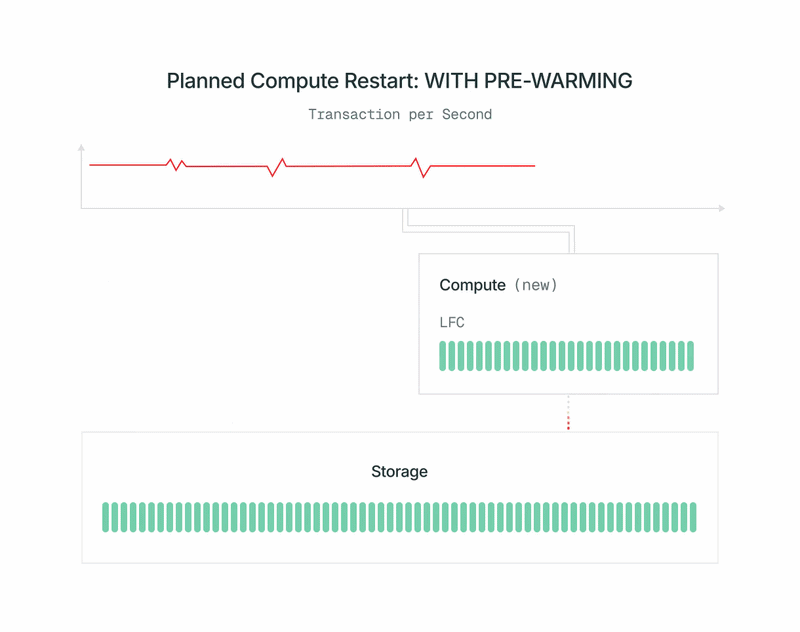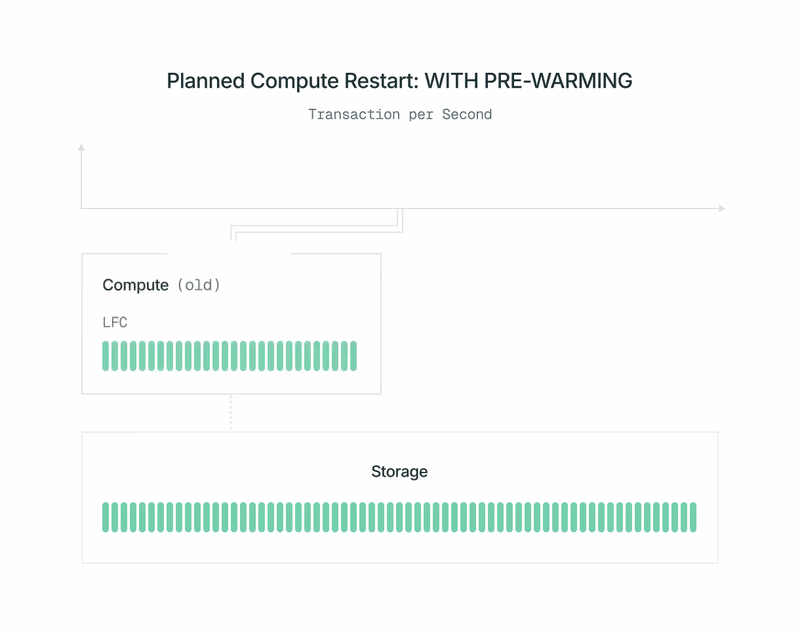
- Kurz vor der geplanten Zeit startet unsere Control Plane im Hintergrund eine neue Postgres-Compute-Instanz. Sie sehen sie nicht und zahlen nichts dafür. Die Arbeitslast des aktuellen Primärknotens bleibt unbeeinflusst.
- Eine Liste von Seiten im Cache des aktuellen Primärknotens wird an den neuen Compute gesendet. Der neue Compute lädt diese Seiten aus unserer Shared Storage-Schicht in den Cache, ohne den Primärknoten zu beeinträchtigen.
- Der neue Compute abonniert das WAL (Write-Ahead Log), um seinen Cache auf dem neuesten Stand zu halten. Aus Effizienzgründen kann er im Gegensatz zu einer normalen Postgres-Replik alle WAL-Datensätze ignorieren, die seinen Cache nicht beeinflussen. Er bezieht das WAL von unseren Safekeepers und belastet den primären Compute nicht zusätzlich.
- Wenn das Prewarming abgeschlossen ist, fahren wir den alten Primärknoten schnell herunter, befördern den neuen Compute zum Primärknoten und schalten ihn ein. Die Beförderung verwendet das Standard-pg_promote von OSS Postgres und startet den Datenbankserver nicht neu.
Vorher:

Nachher:
Mit der Lakebase-Architektur erhalten Sie dies ohne zusätzliche Kosten und ohne Bezahlung für zusätzliche Replikate. Ab heute werden alle geplanten Neustarts von Lese-/Schreib-Endpunkten auf diese Weise durchgeführt, ohne dass Sie etwas tun müssen. Bald werden wir dies auch auf Lese-Endpunkte ausweiten.
Ergebnisse
Um die Auswirkungen von kalten Caches zu messen, haben wir eine 10 GB pgbench (Skalierungsfaktor 670) auf einer Datenbank ausgeführt, während wir sie neu gestartet haben – zuerst mit aktiviertem Prewarming, dann ohne Prewarming. Das erste Diagramm zeigt eine reine Lese-Arbeitslast (pgbench „select only“), während das zweite eine Lese-/Schreib-Arbeitslast zeigt (pgbench „simple update“).


In beiden Fällen sehen wir, dass der Durchsatz mit Prewarming nahezu sofort wiederhergestellt wird. Ohne Prewarming ist die Wiederherstellung viel langsamer, während der kalte Cache aufgewärmt wird. Der Unterschied ist bei der reinen Lese-Arbeitslast am deutlichsten, da Prewarming die Cache-Trefferquote verbessert, was Lesezugriffe proportional stärker beeinflusst als Schreibzugriffe.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.