Einführung in Data Lakes
Data Lake bieten einen vollständigen und autoritativen Datenspeicher, der Data Analytics, Business Intelligence und Machine Learning antreibt.

Einführung in Data Lake
Was ist ein Data Lake?
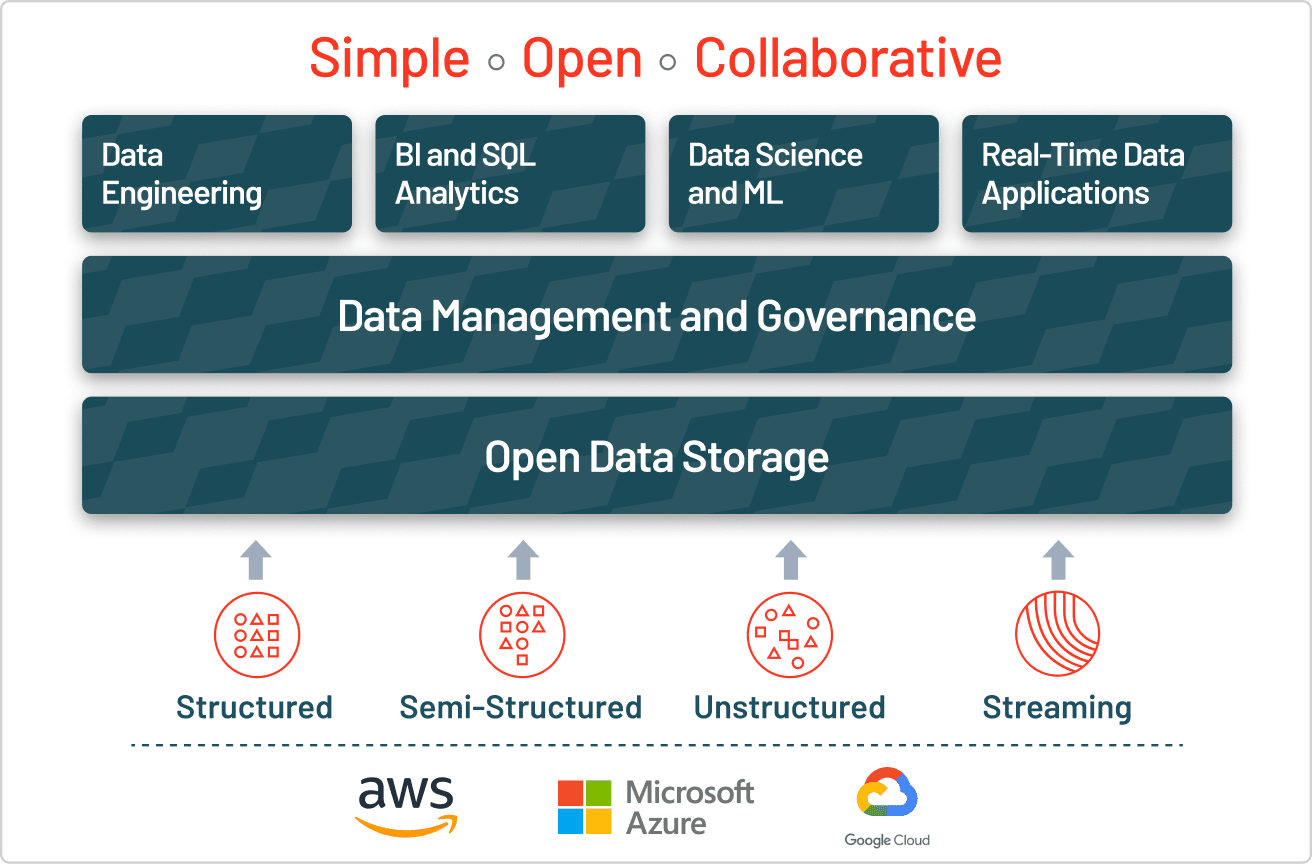
Ein Data Lake ist ein zentraler Speicherort, der eine große Menge an Daten in ihrem nativen Rohformat speichert. Im Unterschied zu einem hierarchischen Data Warehouse, das Daten in Dateien oder Ordnern ablegt, nutzt ein Data Lake eine flache Architektur und Objektspeicher zur Datenspeicherung. Beim Objektspeicher werden Daten gemeinsam mit Metadaten-Tags und einer eindeutigen Kennung abgelegt. Dadurch lassen sich Daten über Regionen hinweg leichter auffinden und abrufen, und die Performance verbessert sich. Durch die Nutzung von kostengünstigem Objektspeicher und offenen Formaten ermöglichen Data Lakes vielen Anwendungen, die Daten zu nutzen.
Data Lakes wurden als Reaktion auf die Einschränkungen von Data Warehouses entwickelt. Data Warehouses bieten Unternehmen zwar hoch performante und skalierbare Analytics, sind aber teuer und proprietär und können die modernen Anwendungsfälle nicht bewältigen, die die meisten Unternehmen adressieren möchten. Data Lakes werden häufig genutzt, um alle Daten eines Unternehmens an einem einzigen, zentralen Ort zu konsolidieren, wo sie „as is“ gespeichert werden können, ohne dass vorab ein Schema (d. h. eine formale Struktur für die Organisation der Daten) wie bei einem Data Warehouse definiert werden muss. In einem Data Lake können Daten in allen Phasen des Aufbereitungsprozesses gespeichert werden: Rohdaten lassen sich direkt neben den strukturierten, tabellarischen Datenquellen eines Unternehmens (etwa Datenbanktabellen) ablegen – ebenso wie die intermediären Datentabellen, die bei der Aufbereitung der Rohdaten entstehen. Im Gegensatz zu den meisten Datenbanken und Data Warehouses können Data Lakes alle Datentypen verarbeiten – einschließlich unstrukturierter und halbstrukturierter Daten wie Bilder, Videos, Audio und Dokumente –, die für ML und fortgeschrittene Analysefälle von entscheidender Bedeutung sind.
Warum sollten Sie auf einen Data Lake setzen?
An erster Stelle steht das offene Format: Data Lakes basieren auf offenen Standards. So vermeiden Unternehmen den Lock-in in proprietäre Systeme wie klassische Data Warehouses – ein Aspekt, der in modernen Datenarchitekturen immer wichtiger wird. Zweitens sind Data Lakes besonders ausfallsicher und kostengünstig, da sie sehr gut skalieren und Objektspeicher nutzen können. Hinzu kommt: Advanced Analytics und Machine Learning auf unstrukturierten Daten gehören heute zu den strategisch wichtigsten Prioritäten vieler Unternehmen. Die einzigartige Fähigkeit, Rohdaten in verschiedensten Formaten (strukturiert, unstrukturiert, semistrukturiert) aufzunehmen, macht den Data Lake zusammen mit den anderen genannten Vorteilen zur klaren Wahl für die Datenspeicherung.
Bei richtiger Architektur ermöglichen Data Lakes Folgendes:

Data Science und Machine Learning antreiben
Mit Data Lakes können Sie Rohdaten in strukturierte Daten umwandeln, die mit geringer Latenz für SQL Analytics, Data Science und Machine Learning bereitstehen. Rohdaten lassen sich dabei zu sehr geringen Kosten langfristig aufbewahren und so für künftige Machine-Learning- und Analytics-Anwendungsfälle vorhalten.

Daten zentralisieren, konsolidieren und katalogisieren
Ein zentraler Data Lake löst typische Datensilo-Probleme wie doppelte Daten, uneinheitliche Sicherheitsrichtlinien und mangelnde Kollaboration und bietet nachgelagerten Nutzern einen zentralen Ort für alle Datenquellen.

Vielfältige Datenquellen und Formate schnell und nahtlos integrieren
Sämtliche Datentypen können in einem Data Lake zeitlich unbegrenzt gesammelt und gespeichert werden – darunter Batch- und Streaming-Daten, Videos, Bilder, Binärdateien und vieles mehr. Da der Data Lake als Landezone für neue Daten dient, bleibt er stets auf dem neuesten Stand.

Daten durch Bereitstellung von Self-Service-Tools demokratisieren
Data Lakes sind unglaublich flexibel und ermöglichen es Benutzern mit völlig unterschiedlichen Fähigkeiten, Tools und Sprachen, verschiedene Analytics Task gleichzeitig durchzuführen.
Herausforderungen von Data Lakes
Trotz ihrer Vorteile konnten viele der Versprechen von Data Lakes nicht eingelöst werden, da wichtige Features fehlten: Es gibt keine Unterstützung für Transaktionen, keine konsequente Sicherung von Datenqualität und Governance und nur unzureichende Performance-Optimierungen. Infolgedessen sind die meisten Data Lakes in Unternehmen zu Datensümpfen verkommen.
Probleme mit der Verlässlichkeit
Ohne die richtigen Tools können Data Lakes unter mangelnder Datenzuverlässigkeit leiden. Das erschwert es Data Scientists und Analysten, verlässliche Schlussfolgerungen aus den Daten zu ziehen. Diese Probleme können auf Schwierigkeiten bei der Kombination von Batch- und Streaming-Daten, aus Datenbeschädigungen oder anderen Faktoren resultieren.
Langsame Performance
Mit wachsendem Datenvolumen in einem Data Lake nimmt die Performance herkömmlicher Abfrage-Engines erfahrungsgemäß deutlich ab. Zu den typischen Engpässen zählen unter anderem das Metadaten-Management, eine ungünstige Datenpartitionierung und weitere Faktoren.
Fehlende Sicherheits-Features
Data Lakes lassen sich aufgrund mangelnder Transparenz und fehlender Möglichkeiten zum Löschen oder Aktualisieren von Daten nur schwer angemessen absichern und steuern. Diese Einschränkungen erschweren es erheblich, die Anforderungen von Aufsichts- und Regulierungsbehörden zu erfüllen.
Aus diesen Gründen reicht ein herkömmlicher Data Lake allein nicht aus, um die Anforderungen innovationsfreudiger Unternehmen gerecht zu werden. Viele Organisationen arbeiten daher mit komplexen Architekturen, in denen Daten in verschiedenen Speichersystemen im gesamten Unternehmen isoliert vorliegen: Data Warehouse, Datenbanken und andere Speichersysteme. Wer im nächsten Jahrzehnt mit Machine Learning und Data Analytics erfolgreich sein möchte, muss im ersten Schritt seine Architektur durch Zusammenführung aller Daten in einem Data Lake vereinfachen.
So lösen Lakehouses diese Herausforderungen
Die Antwort auf die Herausforderungen klassischer Data Lakes ist das Lakehouse, das sie um eine transaktionale Speicherschicht erweitert. Ein Lakehouse nutzt ähnliche Datenstrukturen und Funktionen für das Datenmanagement wie ein Data Warehouse, führt diese jedoch direkt auf Cloud Data Lakes aus. So ermöglicht ein Lakehouse dass klassische Analytik, Data Science und Machine Learning im selben System koexistieren �– und das alles in einem offenen Format.
Ein Lakehouse eröffnet eine breite Palette neuer Anwendungsfälle für funktionsübergreifende Analytics-, BI- und Machine-Learning-Projekte auf Unternehmensebene, die erheblichen Geschäftswert erschließen können. Datenanalysten können über SQL-Abfragen auf den Data Lake wertvolle Einblicke gewinnen, Data Scientists Datensätze verknüpfen und anreichern, um ML-Modelle mit stetig höherer Präzision zu entwickeln, Data Engineers automatisierte ETL-Pipelines aufbauen und Business-Intelligence-Analysten visuelle Dashboards und Reporting-Tools schneller und einfacher denn je erstellen. All diese Anwendungsfälle können gleichzeitig im Data Lake ausgeführt werden, ohne dass die Daten verschoben werden müssen – selbst dann, wenn neue Daten einströmen.
Ein Lakehouse mit Delta Lake erstellen
Unternehmen, die ein erfolgreiches Lakehouse aufbauen möchten, setzen auf Delta Lake. Dabei handelt es sich um eine Datenmanagement- und Governance-Schicht mit einem offenen Format, die das Beste aus Data Lakes und Data Warehouses kombiniert. Unternehmen in allen Branchen setzen Delta Lake ein, um die Zusammenarbeit zu stärken, indem sie eine zuverlässige, einheitliche Datenquelle (Single Source of Truth) bereitstellen. Indem Delta Lake Qualität, Zuverlässigkeit, Sicherheit und Performance für Ihren Data Lake gewährleistet – sowohl im Streaming- als auch im Batch-Betrieb –, eliminiert es Datensilos und macht Analytics im gesamten Unternehmen zugänglich. Mit Delta Lake können Kunden ein kosteneffizientes, hoch skalierbares Lakehouse aufbauen, das Datensilos eliminiert und Endanwendern Self-Service-Analytics ermöglicht.
Weitere Informationen zu Delta Lake
Data Lakes, Data Lakehouses und Data Warehouses im Vergleich
| Data Lake | Data Lakehouse | Data Warehouse | |
|---|---|---|---|
| Datentypen | Alle Typen: Strukturierte Daten, halbstrukturierte Daten, unstrukturierte (Roh-)Daten | Alle Typen: Strukturierte Daten, halbstrukturierte Daten, unstrukturierte (Roh-)Daten | Nur strukturierte Daten |
| Kosten | $ | $ | €€€ |
| Format | Offenes Format | Offenes Format | Geschlossenes, proprietäres Format |
| Skalierbarkeit | Skalierbar, um Datenmengen jeglicher Größenordnung zu geringen Kosten zu speichern, unabhängig vom Datentyp | Skalierbar, um Datenmengen jeglicher Größenordnung zu geringen Kosten zu speichern, unabhängig vom Datentyp | Eine Skalierung nach oben wird aufgrund der Anbieterkosten exponentiell teurer |
| Zielgruppe | Begrenzt: Data Scientists | Vereinheitlicht: Datenanalysten, Data Scientists, Machine Learning Engineers | Begrenzt: Datenanalysten |
| Zuverlässigkeit | Geringe Qualität, Datensumpf | Hochwertige und zuverlässige Daten | Hochwertige und zuverlässige Daten |
| Anwenderfreundlichkeit | Problematisch: Die Analyse großer Mengen von Rohdaten kann sich ohne Tools zur Organisation und Katalogisierung der Daten schwierig gestalten | Einfach: Bietet die Einfachheit und Struktur eines Data Warehouse mit den breiter angelegten Anwendungsfällen eines Data Lake | Einfach: Die Struktur eines Data Warehouse ermöglicht es Benutzern, schnell und problemlos auf Daten für Berichte und Analysen zuzugreifen |
| Performance | Mangelhaft | Hoch | Hoch |
Erfahren Sie mehr über häufige Herausforderungen im Data Lake
Best Practices für das Lakehouse
Den Data Lake als Landing-Zone für alle Ihre Daten nutzen
Speichern Sie alle Ihre Daten in Ihrem Data Lake, ohne sie zu transformieren oder aggregieren, um sie für Machine-Learning-Anwendungsfälle und eine lückenlose Datenherkunft vorzuhalten.
Daten mit privaten Informationen maskieren, bevor sie in Ihrem Data Lake gelangen
Personenbezogene Information (PII) muss pseudonymisiert werden, um die Vorgaben der DSGVO (GDPR) zu erfüllen und sicherzustellen, dass sie langfristig gespeichert werden können.
Ihren Data Lake mit rollen- und ansichtsbasierten Zugriffskontrollen absichern
Durch ansichtsbasierte ACLs (Access Control Lists) lässt sich die Sicherheit Ihres Data Lake deutlich präziser steuern als nur mit rollenbasierten Kontrollen.
Zuverlässigkeit und Performance in Ihren Data Lake integrieren – mit Delta Lake
Aufgrund der Eigenschaften von Big Data war es bisher schwierig, die gleiche Zuverlässigkeit und Performance wie bei klassischen Datenbanken zu erreichen. Delta Lake bringt diese wichtigen Features in Data Lakes.
Daten in Ihrem Data Lake katalogisieren
Verwenden Sie Tools zur Verwaltung von Datenkatalogen und Metadaten bereits am Punkt der Datenaufnahme, um Self-Service Data Science und Analytics zu ermöglichen.