Was ist Datenvirtualisierung?
Zugriff auf und Abfrage von Daten aus mehreren Quellen ohne physische Verschiebung oder Replikation, wodurch eine einheitliche virtuelle Ebene geschaffen wird.
- Verstehen Sie, was Datenvirtualisierung ist und wie sie den Datenzugriff über heterogene Systeme hinweg durch eine einheitliche Schnittstelle abstrahiert.
- Erfahren Sie, wie Virtualisierung den Datenverkehr reduziert, die Architektur vereinfacht und Echtzeitzugriff auf verteilte Datenquellen ermöglicht.
- Entdecken Sie Anwendungsfälle wie föderierte Abfragen, die Integration von Altsystemen und agile Analysen ohne komplexe ETL-Prozesse.
Was ist Datenvirtualisierung?
Datenvirtualisierung ist eine Methode der Datenintegration, mit der Unternehmen einheitliche Sichten auf Informationen aus mehreren Datenquellen erstellen können, ohne die Daten physisch zu verschieben oder zu kopieren. Als zentrale Technologie der Datenvirtualisierung ermöglicht dieser Ansatz im Datenmanagement Datenkonsumenten den Zugriff auf Daten aus heterogenen Systemen über eine einzige virtuelle Schicht. Statt Daten in ein zentrales Repository zu extrahieren, legt die Datenvirtualisierung eine Abstraktionsschicht zwischen Datenkonsumenten und Quellsysteme. Nutzer stellen ihre Abfragen über eine einheitliche Schnittstelle, während die zugrunde liegenden Daten an ihrem ursprünglichen Speicherort verbleiben.
Datenvirtualisierung adressiert damit eine grundlegende Herausforderung moderner Datenlandschaften: Unternehmensdaten sind über zahlreiche Quellen verteilt – darunter Datenbanken, Data Lakes, Cloud-Anwendungen und Legacy-Systeme. Klassische Integrationsansätze erfordern den Aufbau komplexer Pipelines, um Daten in ein zentrales Warehouse zu verschieben, wo die Informationen liegen. Datenvirtualisierung beseitigt diese Verzögerung, indem sie Echtzeitzugriff auf Informationen bietet, wo auch immer sie sich befinden.
Das Interesse an Datenvirtualisierung hat zugenommen, da Unternehmen verstärkt auf Multi-Cloud-Umgebungen, Lakehouse-Architekturen und organisationsübergreifenden Datenaustausch setzen. Diese Trends vervielfachen die Anzahl der Quellen, auf die Teams zugreifen müssen, wodurch eine physische Konsolidierung zunehmend unpraktisch wird. Die Datenvirtualisierung bietet eine Möglichkeit, den Zugriff zu vereinheitlichen, ohne den Speicher zu vereinheitlichen.
Die Datenvirtualisierungstechnologie erstellt eine Virtualisierungsschicht, die sich zwischen Datenkonsumenten und Quellsystemen befindet. Diese virtuelle Schicht ermöglicht es Geschäftsanwendern, Daten über Data Lakes, Data Warehouses und Cloud-Speicherdienste abzufragen, ohne die technischen Komplexitäten jeder Quelle zu verstehen. Durch die Implementierung der Datenvirtualisierung ermöglichen Unternehmen ihren Teams, Daten aus mehreren Quellen in Echtzeit zu kombinieren und gleichzeitig eine zentralisierte Governance aufrechtzuerhalten.
Ein häufiger Irrtum, den man ausräumen sollte: Datenvirtualisierung und Datenvisualisierung klingen ähnlich, lösen aber völlig unterschiedliche Probleme. Datenvirtualisierung ist eine Integrationstechnologie, die Zugriffsebenen über verteilte Quellen hinweg erstellt. Datenvisualisierung ist eine Präsentationstechnologie, die Informationen als Diagramme, Graphen und Dashboards für Business Intelligence darstellt. Beide ergänzen sich; die Datenvirtualisierung bietet einen einheitlichen Zugriff, den Visualisierungstools dann in für Menschen lesbaren Formaten anzeigen.
Für Organisationen, die eine agile Datenverwaltung verfolgen, bietet die Datenvirtualisierung einen Weg zu schnelleren Erkenntnissen ohne den Infrastruktur-Overhead traditioneller Ansätze.
Siehe auch: ETL-Prozesse und Datenintegrationsstrategien
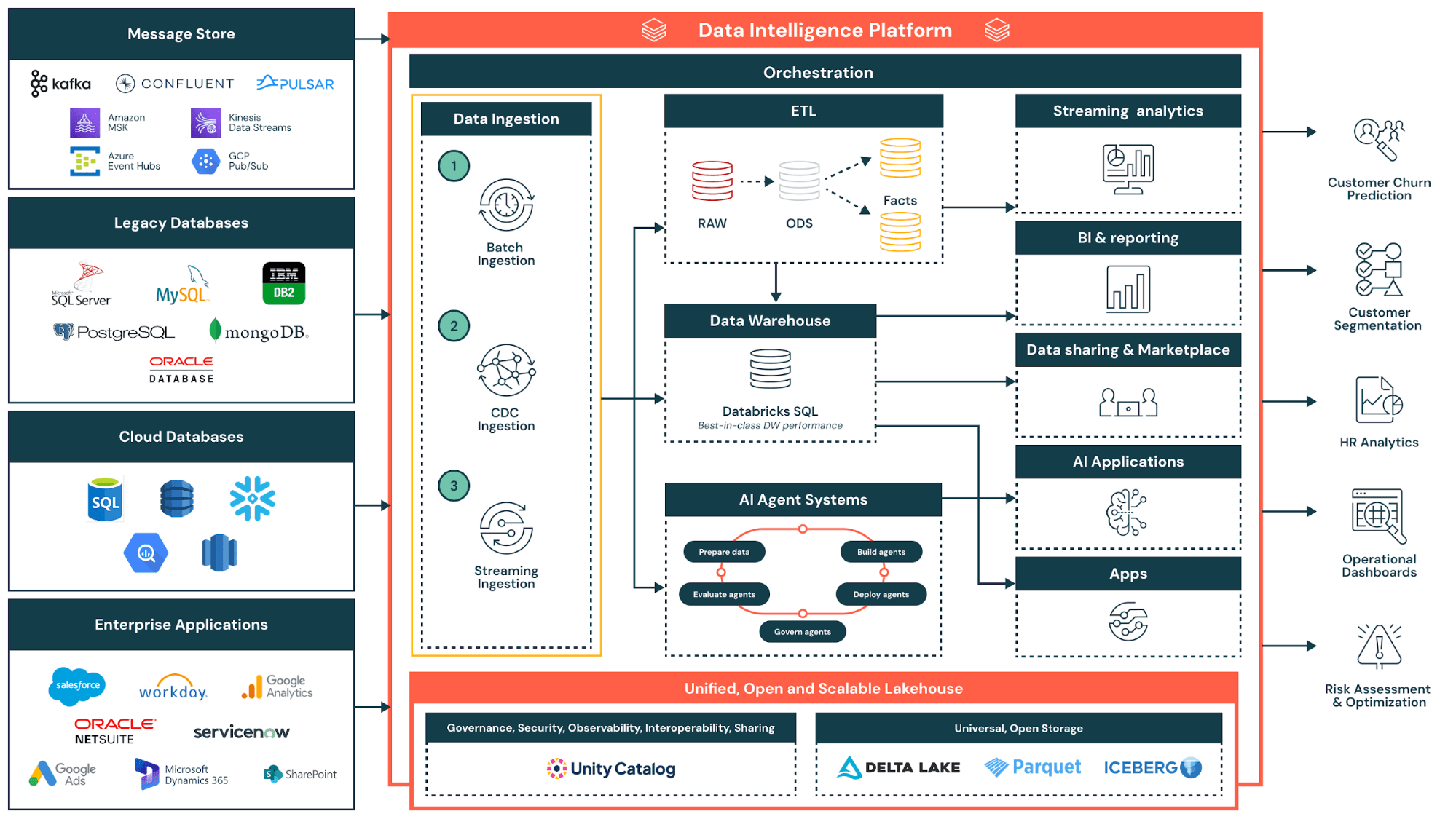
Wie Datenvirtualisierung funktioniert: Architektur & Komponenten
Die Architektur der Datenvirtualisierung basiert auf drei zentralen Komponenten der Datenmanagement-Infrastruktur: einer semantische Datenschicht für Geschäftsdefinitionen, einer Virtualisierungsschicht für die Abfrageföderation und einem Metadatenmanagement für Governance. Moderne Plattformen integrieren diese Komponenten zu vollständigen virtuellen Datenumgebungen. So können Data Scientists, Fachanwender und andere Datennutzer auf Datenquellen und Datenservices zugreifen, ohne wissen zu müssen, wo die Informationen gespeichert sind.
Die Virtualisierungsebene befindet sich zwischen den Datenkonsumenten (wie Analysten, Anwendungen und BI-Tools) und den zugrunde liegenden Datenquellen. Diese Ebene verwaltet Metadaten darüber, wo sich die Daten befinden, wie sie strukturiert sind und wie auf sie zugegriffen werden kann. Die Ebene selbst speichert keine Daten; sie fungiert als intelligente Routing- und Übersetzungs-Engine. Governance-Lösungen wie Unity Catalog können diese Metadaten zentral verwalten und bieten einen zentralen Kontrollpunkt für Discovery- und Zugriffsrichtlinien.
Wenn ein Benutzer eine Abfrage sendet, ermittelt die Datenvirtualisierungs-Engine, welche Datenquellen die relevanten Informationen enthalten. Sie übersetzt die Abfrage in die native Sprache des jeweiligen Systems, sei es SQL für relationale Datenbanken, API-Aufrufe für Cloud-Anwendungen oder Dateizugriffsprotokolle für Data Lakes. Anschließend föderiert die Engine die Anfrage über die verschiedenen Systeme hinweg und führt die Ergebnisse zu einer einheitlichen Antwort zusammen.
Datenvirtualisierung ermöglicht Abfrageföderation und beschreibt damit dieses verteilte Ausführungsmodell. Komplexe Abfragen werden in Teilabfragen aufgeteilt, die jeweils an die entsprechende Quelle weitergeleitet werden. Die Ergebnisse werden an die Virtualisierungsschicht zurückgegeben, die sie zusammenführt und transformiert, bevor sie eine einzige Antwort an den Benutzer liefert. Lakehouse Federation ermöglicht es Anwendern beispielsweise, direkt aus dem Lakehouse heraus Abfragen auf externe Datenbanken, Data Warehouses und Cloud-Anwendungen auszuführen – ganz ohne vorherige Datenmigration. Die Performance-Optimierung erfolgt durch Techniken wie Predicate Pushdown, bei denen die Filterlogik direkt an der Datenquelle statt zentral ausgeführt wird.
Moderne Plattformen implementieren auch Join Pushdown, Column Pruning und intelligentes Caching. Wenn Quellen unterschiedliche Antwortzeiten haben, führt die Engine Abfragen parallel aus und setzt Timeout-Mechanismen ein, damit langsame Quellen die Ergebnisse nicht blockieren. Diese Optimierungen sorgen dafür, dass virtualisierte Abfragen in ihrer Performance nahe an Abfragen auf physisch konsolidierte Daten herankommen.
Die Lakehouse-native Datenvirtualisierung bietet einen zusätzlichen Vorteil: eine einheitliche Governance für föderierte und interne Daten. Wenn Unity Catalog die Zugriffsrichtlinien verwaltet, wenden Unternehmen dieselben Sicherheitsregeln auf externe Datenbanken und Lakehouse-Tabellen an. Benutzer fragen virtualisierte und physische Daten in derselben SQL-Anweisung ab, ohne separate Systeme oder Berechtigungen verwalten zu müssen.
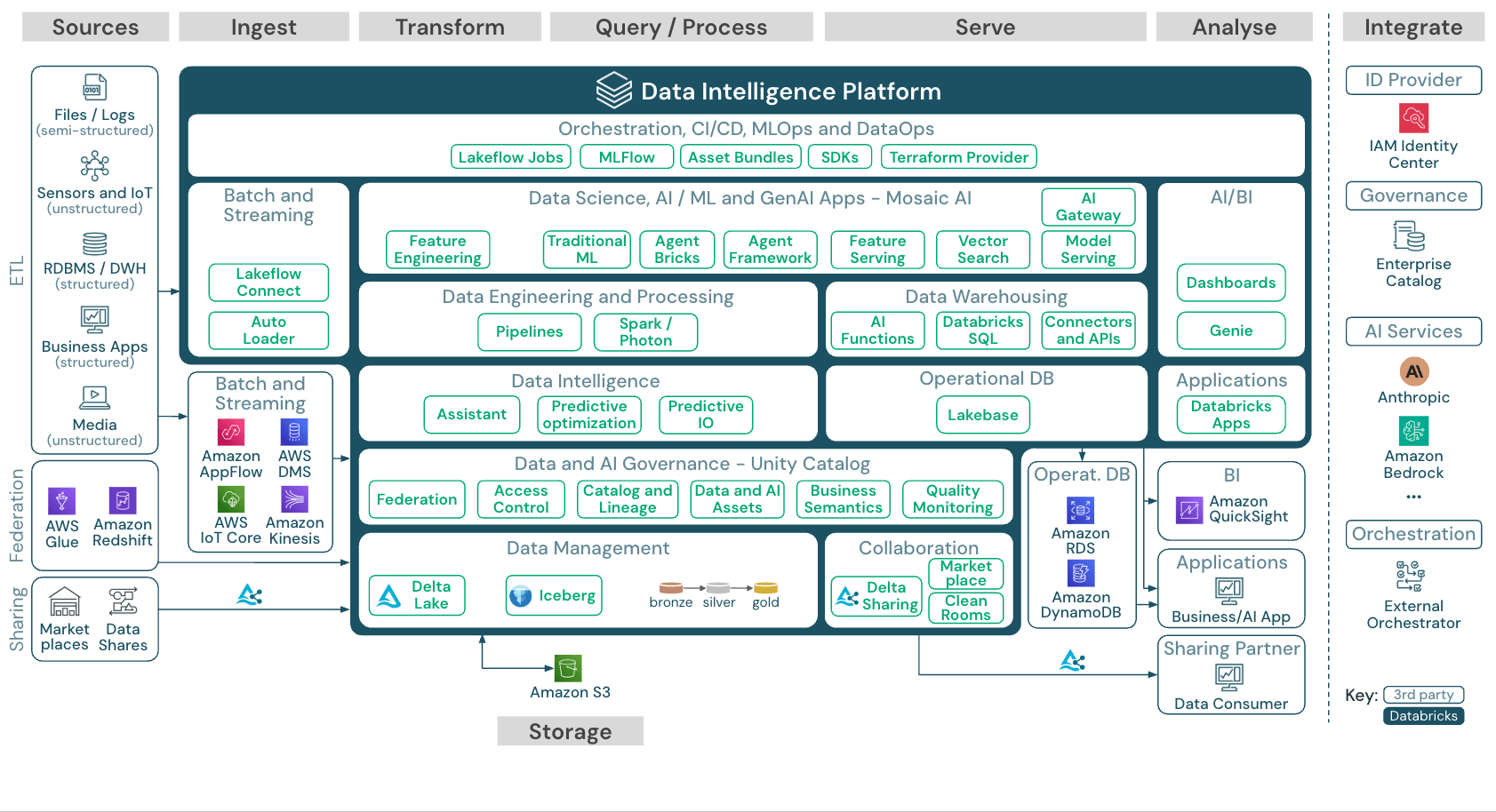
Datenvirtualisierung vs. ETL: Hauptunterschiede
Traditionelles ETL (Extract, Transform, Load) verschiebt Daten physisch von Quellsystemen in ein zentralisiertes Warehouse oder einen Lake. Das erzeugt Kopien, bringt Verzögerungen zwischen den Extraktionsläufen mit sich und erfordert kontinuierliche Pflege der Pipelines. Die Datenvirtualisierung verfolgt den entgegengesetzten Ansatz: Die Daten bleiben an Ort und Stelle und werden bei Bedarf abgerufen.
Die Ansätze sind für unterschiedliche Anwendungsfälle gedacht. Sehen Sie sich an, wie sie sich entlang zentraler Dimensionen unterscheiden:
Datenverschiebung: ETL kopiert Daten in ein zentrales Repository. Die Datenvirtualisierung fragt Daten vor Ort ab, ohne Duplikate zu erstellen.
Datenaktualität: ETL liefert Daten, die so aktuell sind wie der letzte Aktualisierungszyklus, der Stunden oder Tage alt sein kann. Datenvirtualisierung bietet Echtzeitzugriff auf Live-Quelldaten.
Zeit bis zu Erkenntnissen: ETL erfordert den Aufbau von Pipelines, bevor die Analyse beginnen kann, was oft Wochen oder Monate dauert. Die Datenvirtualisierung bietet sofortigen Zugriff, sobald die Verbindungen konfiguriert sind.
Komplexe Transformationen: ETL ist stark bei mehrstufiger Verarbeitung und historischen Analysen. Datenvirtualisierung kann Joins und Filter gut abbilden, stößt bei komplexer Transformationslogik jedoch an Grenzen.
Die meisten Unternehmen kombinieren beide Ansätze. ETL und ELT bewältigen komplexe Transformationen, historische Trendanalysen und performancekritische Batch-Workloads. Datenvirtualisierung bietet agilen Echtzeitzugriff für Ad-hoc-Analysen und operative Dashboards. Die Wahl hängt von den Workload-Anforderungen ab – nicht von ideologischen Vorlieben.
Siehe auch: Unity Catalog für einheitliche Governance- und Datenarchitekturmuster
Wichtigste Vorteile: Echtzeitzugriff ohne Datenverschiebung
Der Business Case für Datenvirtualisierung konzentriert sich auf Geschwindigkeit, Kostensenkung und Vereinfachung der Governance. Datenvirtualisierung hilft Unternehmen, Speicherkosten zu senken, den Datenzugriff für Geschäftsanwender zu verbessern und die Infrastruktur über heterogene Datenquellen hinweg zu vereinfachen.
1. Geringere Speicher- und Infrastrukturkosten
Datenvirtualisierung schafft sofort messbaren Mehrwert, weil weniger Daten repliziert werden müssen und so die Kosten sinken. Wenn keine Duplikate entstehen, zahlen Unternehmen nicht länger dafür, dieselben Informationen mehrfach in Data Warehouses, Data Marts und Analytics-Umgebungen zu speichern. Die Speichereinsparungen potenzieren sich mit wachsendem Volumen und die Teams vermeiden die Infrastrukturkomplexität bei der Pflege synchronisierter Kopien.
2. Nahezu-Echtzeit-Erkenntnisse für Datenkonsumenten
Abfragen greifen auf Live-Systeme zu, statt auf veraltete Warehouse-Kopien. Finanzdienstleister nutzen das etwa für Betrugserkennung, Händler verfolgen Bestände kanalübergreifend während Transaktionen stattfinden, und Gesundheitssysteme können während der Behandlung auf aktuelle Patientendaten zugreifen. Echtzeitanalysen werden möglich, ohne dass Streaming-Pipelines erstellt werden müssen.
3. Vereinfachte Infrastruktur
Mit Datenvirtualisierung zentralisieren Unternehmen Zugriffsregeln, Sicherheitsrichtlinien und Metadaten in einer virtuellen Datenschicht, statt Governance über viele Systeme hinweg zu duplizieren. Administratoren definieren Richtlinien einmalig, statt sie in jeder Quelle separat zu pflegen. Wenn das in eine Lakehouse-Plattform integriert ist – und nicht als eigenständige Lösung betrieben wird – sinken Betriebsaufwand und Komplexität zusätzlich.
4. Schnellere Time-to-Value für Geschäftsinitiativen
Organisationen berichten von einer Verkürzung der Bereitstellungszeiten von Wochen auf Tage oder Stunden. Der Gewinn entsteht vor allem dadurch, dass die sonst oft monatelange Arbeit entfällt, für jeden neuen Analyse-Use-Case ETL-Pipelines zu konzipieren, zu bauen, zu testen und dauerhaft zu betreiben.
Diese Vorteile greifen besonders in Szenarien mit vielen unterschiedlichen Datenquellen, sich schnell ändernden Anforderungen und dann, wenn Datenaktualität wichtiger ist als historische Tiefe.
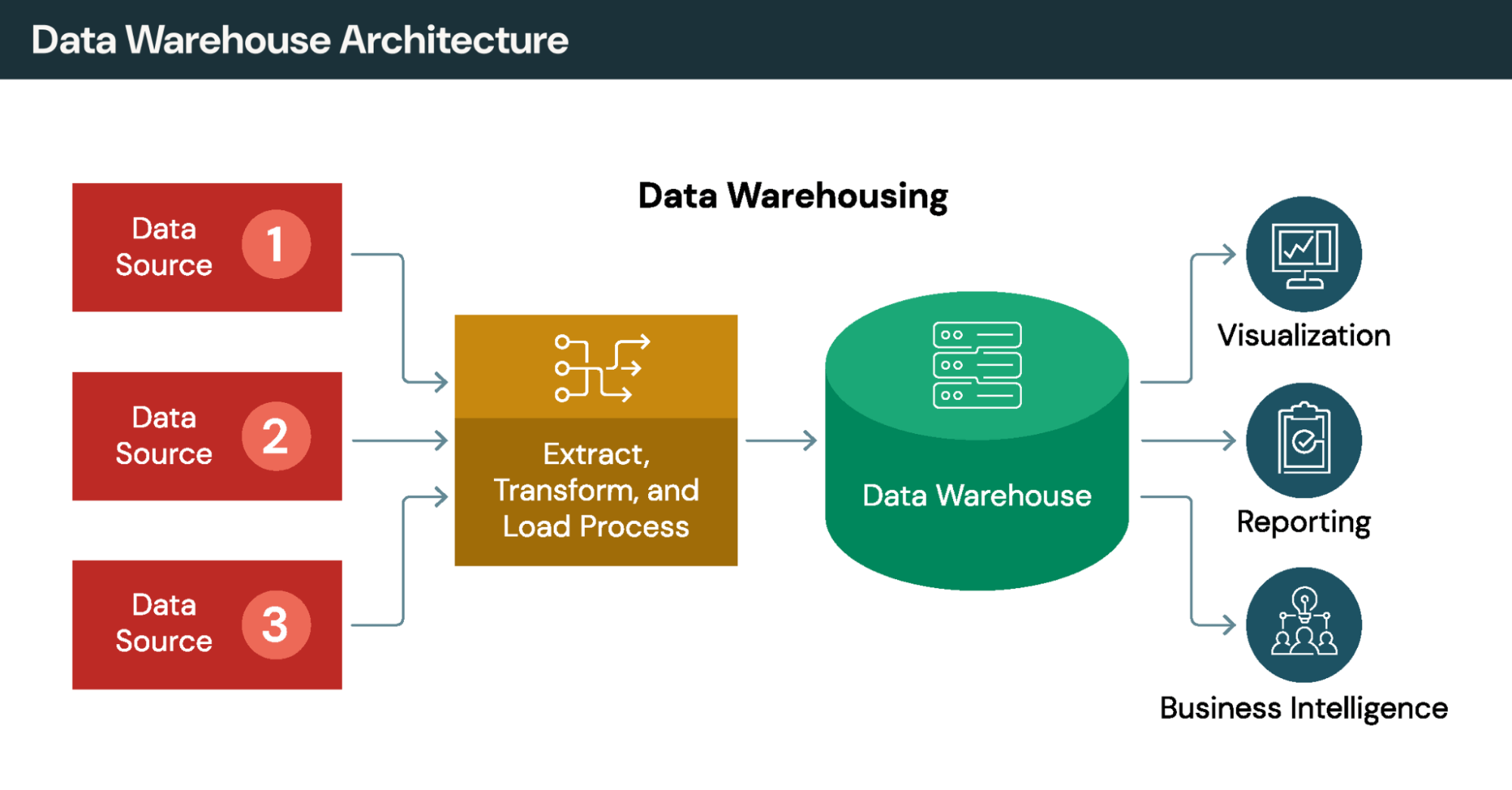
Vergleich der Integrationsansätze
Traditionelle Integrationsmethoden wie ETL verschieben Daten physisch in zentrale Repositories. Die Datenvirtualisierung verfolgt einen anderen Ansatz: Sie greift auf Daten am Ursprungsort zu, ohne sie zu replizieren. In der Praxis kombinieren viele Unternehmen beide Strategien: ETL für komplexe Transformationen, Datenvirtualisierung für agilen Zugriff.
Siehe auch: Echtzeit-Analysefunktionen und modernes Data Warehousing
Das Playbook für agentenbasierte KI für Unternehmen

Praktische Anwendungsfälle & Branchenanwendungen
Die Datenvirtualisierungstechnologie eignet sich hervorragend, wenn Unternehmen einen einheitlichen Zugriff auf operative Systeme, Data Lakes und Cloud-Anwendungen benötigen. Datenvirtualisierung ermöglicht den Echtzeitzugriff auf mehrere Datenquellen, ohne die langen Vorlaufzeiten klassischer Datenintegrationsprojekte. Die folgenden Beispiele veranschaulichen gängige Muster.
Einzelhandel
Einzelhändler agieren über E-Commerce Plattformen, physische Filialsysteme, Warehouse-Management-Anwendungen, Point-of-Sale-Terminals und Lieferantennetzwerke hinweg. Datenvirtualisierung schafft durchgängige Transparenz in der Supply Chain, weil sie Zugriff auf mehrere Systeme ermöglicht – ohne dafür Point-to-Point-Integrationen aufzubauen.
Gerade das Bestandsmanagement profitiert von Echtzeit-Datenvirtualisierung. Statt die Lagerbestände jede Nacht per Batch abzugleichen, fragen Händler Live-Daten aus allen Kanälen ab und erhalten so eine verlässliche Verfügbarkeitsanzeige. Das ist die Grundlage für Funktionen wie Click & Collect, bei denen Kunden vor der Bestellung aktuelle Bestandsinformationen brauchen. Unternehmen, die Datenvirtualisierung für den Supply-Chain-Zugriff einsetzen, berichten von erheblichen Kosteneinsparungen – etwa durch geringere Lagerhaltungskosten und präzisere Nachfrageprognosen.
Finanzdienstleistungen
Finanzdienstleister nutzen Datenvirtualisierung, um Kundendaten aus Kreditkartentransaktionen, Einlagen, Kreditsystemen, CRM-Plattformen und externen Anbietern zusammenzuführen und umfassende Kundenprofile zu erstellen. Diese Sichten werden bei Bedarf aufgebaut, statt vorab gepflegte Kundendatensätze vorzuhalten, die zwischen Updates schnell veralten.
Für Betrugserkennung in Echtzeit braucht es in Sekundenbruchteilen Zugriff auf Transaktionsmuster über Konten hinweg Batch-orientierte Warehouses können diese Latenzanforderung nicht erfüllen. Auch die regulatorische Compliance profitiert: Konsolidiertes Reporting über mehrere Systeme wird möglich, während Audit Trails für Prüfungen erhalten bleiben.
Gesundheitswesen
Patientendaten sind sensibel und häufig über elektronische Patientenakten, Abrechnungssysteme, Bildarchive und Laborinformationssysteme verteilt. Datenvirtualisierung ermöglicht es Klinikern während der Behandlung den Zugriff auf einheitliche Patientenansichten, ohne Daten aus den Quellsystemen herauszulösen. Ein Arzt kann die Historie eines Patienten in einer einzigen Abfrage einsehen – inklusive Hausarztakten, Facharztbesuchen und Laborergebnissen –, obwohl die Informationen in unterschiedlichen Systemen liegen.
Diese Architektur unterstützt Datenschutzanforderungen, da sensible Informationen niemals an einem einzigen Ort gebündelt werden, der für Sicherheitsverletzungen anfällig ist. Krankenhäuser und Gesundheitssysteme können den Zugriff teilen, ohne Daten physisch zwischen den Organisationen zu übertragen, was eine koordinierte Versorgung ermöglicht.
Wann Datenvirtualisierung nicht die richtige Wahl ist
Die Datenvirtualisierung hat klare Grenzen. Für großvolumige Batch-Verarbeitung ist weiterhin physische Datenbewegung nötig. Wenn Millionen von Zeilen verarbeitet werden, bringt Virtualisierung keinen Performance-Vorteil gegenüber dem einmaligen Verschieben der Daten. Ein Zahlungsdienstleister, der beispielsweise Millionen Transaktionen pro Stunde verarbeitet, gewinnt durch die Virtualisierung dieses Workloads nichts. Auch historische Analysen, die Point-in-Time-Snapshots erfordern, brauchen ein Data Warehouse, das Zustände über die Zeit hinweg versioniert speichert – denn Datenvirtualisierung greift nur auf den aktuellen Stand zu. Komplexe, mehrstufige Transformationen gehen über diese Möglichkeiten hinaus, da sie in der Regel auf datenbanktypische Joins, Filter und Aggregationen beschränkt sind.
Sehr große Warehouse-Implementierungen, Cross-Data-Center-Setups und Workloads mit garantiert niedriger Latenz sprechen in der Regel für physische Datenbewegung über Data-Engineering-Pipelines.
Siehe auch: Data Lakes und Business-Intelligence-Anwendungen
Überlegungen zu Governance, Sicherheit & Qualität
Die Datenvirtualisierung stärkt die Governance durch die Konsolidierung der Kontrolle in einer zentralisierten Virtualisierungsebene. Datenvirtualisierungstools ermöglichen es Administratoren, Sicherheitsrichtlinien einmal zu definieren, anstatt sie separat über unterschiedliche Quellen hinweg zu verwalten.
Die Sicherheitsfunktionen moderner Plattformen umfassen eine rollenbasierte Zugriffssteuerung, Sicherheit auf Zeilen- und Spaltenebene und Datenmaskierung für sensible Felder. Attributbasierte Zugriffskontrolle, die an Klassifizierungs-Tags gekoppelt ist, sorgt dafür, dass Richtlinien mit den Daten „mitwandern“ – unabhängig davon, auf welchem Weg Nutzer darauf zugreifen. Ob Analysten per SQL-Abfragen, REST APIs oder BI-Tools zugreifen: Es gelten überall dieselben Sicherheitsregeln.
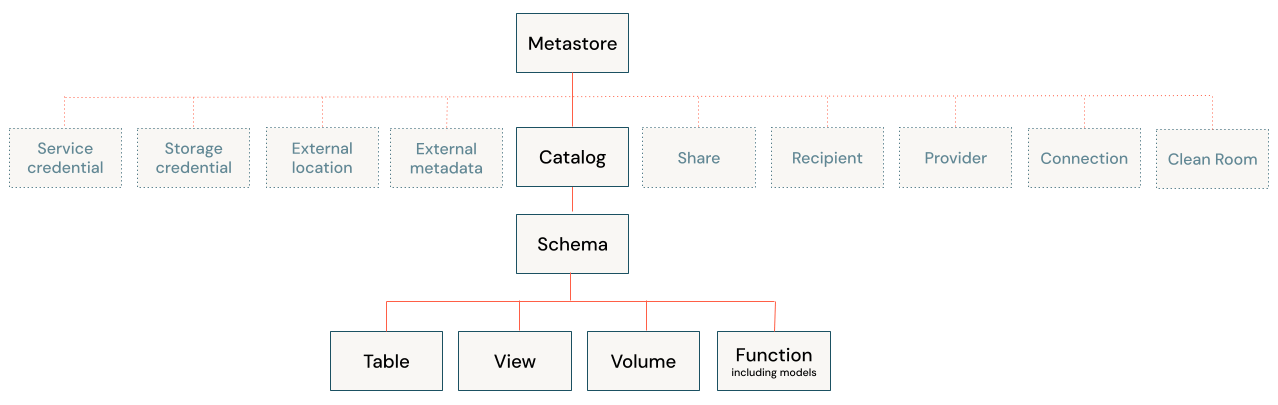
Audit- und Lineage-Tracking erfasst, wer wann auf welche Daten zugegriffen hat – und aus welcher Anwendung heraus. Unity Catalog bietet nutzerbezogene Audit-Logs und Datenherkunft über alle Sprachen hinweg für Compliance-Reporting. Diese Transparenz unterstützt GDPR, HIPAA, CCPA sowie Finanzvorgaben, die nachweisbare Governance verlangen.
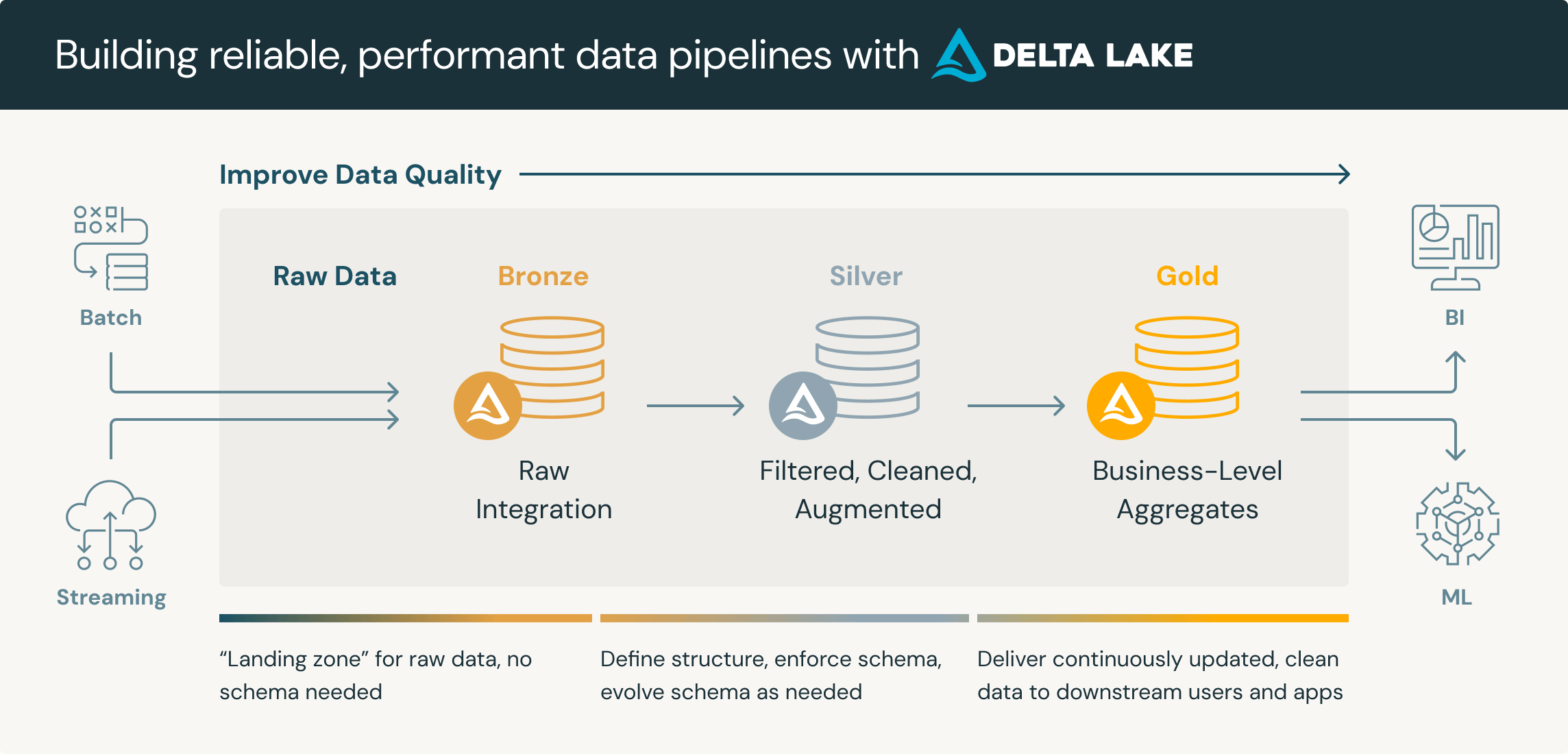
Datenaktualität ist bei Datenvirtualisierung grundsätzlich gegeben, weil Abfragen direkt auf Live-Quellen zugreifen. Das bringt jedoch Anforderungen an die Datenqualität mit sich: Wenn Systeme Fehler oder Inkonsistenzen enthalten, werden diese Probleme für Datenkonsumenten unmittelbar sichtbar. Effektive Implementierungen kombinieren Datenvirtualisierung deshalb mit Data-Quality-Monitoring, damit die einheitliche Sicht verlässlich bleibt.
Die semantische Konsistenz stellt eine weitere Herausforderung dar. Verschiedene Systeme können unterschiedliche Namen für dasselbe Konzept, unterschiedliche Datentypen für äquivalente Felder oder alternative Geschäftsdefinitionen für ähnliche Metriken verwenden. Die Virtualisierungsschicht muss konsistente Namenskonventionen durchsetzen, damit Kundendaten im CRM eindeutig demselben Kunden im Abrechnungssystem zugeordnet werden können. Das gilt auch dann, wenn die Systeme Daten unterschiedlich benennen und formatieren. Einige Unternehmen ergänzen eine semantische Datenschicht, um kanonische Geschäftsbegriffe und Berechnungen festzulegen, die über alle virtualisierten Quellen hinweg gelten. So sehen Analysten konsistente Definitionen – unabhängig davon, in welchem zugrunde liegenden System die Daten gespeichert sind.
Siehe auch: Data Governance mit Unity Catalog und Best Practices für die Datenverwaltung
Best Practices für die Implementierung und Tool-Auswahl
Unternehmen, die Datenvirtualisierung einführen, sollten bewährte Vorgehensweisen befolgen, um eine erfolgreiche Bereitstellung sicherzustellen. Starten Sie klein: Erfolgreiche Implementierungen beginnen oft mit einem kleinen Team, das klar abgegrenzte Projekte mit hohem geschäftlichem Mehrwert in Angriff nimmt. Expandieren Sie erst, wenn der des Werts für die Stakeholder belegt wurde. Definieren Sie zuerst die Governance, indem Sie Eigentumsverhältnisse, Sicherheitsmodelle und Entwicklungsstandards festlegen, bevor Sie die Technologie bereitstellen. Überwachen Sie die Performance regelmäßig, um langsam laufende Abfragen zu identifizieren, häufig aufgerufene virtuelle Ansichten zu optimieren und Verbindungen anzupassen, wenn sich die Nutzungsmuster ändern.
Wie Datenvirtualisierung in der Praxis aussieht: Implementierung in der realen Welt
Betrachten wir ein konkretes Beispiel. Ein Einzelhandelsunternehmen möchte den Customer Lifetime Value analysieren, aber die Kundendaten befinden sich im Salesforce CRM, die Transaktionshistorie in einer PostgreSQL-Datenbank, das Website-Verhalten in Google Analytics und die Retourendaten in einem alten Oracle-System.
Bei klassischer Datenintegration müssten ETL-Pipelines aufgebaut werden, um all diese Daten zu extrahieren, zu transformieren und in ein Data Warehouse zu laden.. Ein solches Projekt dauert Monate. Mit Datenvirtualisierung richtet ein Administrator stattdessen Verbindungen zu den einzelnen Quellen ein und veröffentlicht eine virtuelle Sicht, die Daten systemübergreifend zusammenführt. Analysten fragen diese Ansicht über vertrautes SQL ab oder verbinden BI-Tools direkt. Sie sehen aktuelle Daten aus allen Quellen in einem einheitlichen Schema. Wird später eine Mobile App mit eigener Datenbank ergänzt, lässt sich diese Quelle innerhalb weniger Tage in die virtuelle Sicht integrieren, ohne dass dies eine Umgestaltung des Warehouses erfordert.
Dieses Muster unterstützt auch eine „Zuerst virtualisieren, später migrieren“-Strategie. Teams föderieren zunächst Abfragen auf externe Quellen und beobachten anschließend, welche Daten besonders häufig genutzt werden. Datasets mit hoher Auslastung werden zu Kandidaten für die physische Migration zu Delta Lake, wo sich die Abfrage-Performance verbessert und die Speicherkosten sinken können. Daten mit geringerer Nutzung bleiben virtualisiert, wodurch unnötiger Migrationsaufwand vermieden wird.
Bewertung von Software und Tools für die Datenvirtualisierung
Bei der Bewertung von Datenvirtualisierungstools sollten Sie drei Kriterien priorisieren.
Unterstützung von Quellvielfalt: Kann die Plattform alle aktuellen und absehbaren Datenquellen anbinden – darunter relationale Datenbanken, Cloud-Anwendungen, APIs und dateibasierte Speicher? Prüfen Sie, ob die von Ihnen benötigten Daten-Services unterstützt werden. Konnektivitätslücken erzwingen Workarounds, die den einheitlichen Zugriff untergraben, den die Datenvirtualisierung verspricht.
Sicherheits-Features: Achten Sie auf Sicherheit auf Zeilen- und Spaltenebene, Maskierung, Verschlüsselung und eine umfassende Audit-Protokollierung. Diese Mechanismen sollten konsistent greifen, unabhängig davon, wie Benutzer auf die virtualisierten Daten zugreifen.
Self-Service-Funktionen: Können Geschäftsanwender virtualisierte Daten eigenständig finden und nutzen, ohne für jede Anfrage IT-Unterstützung zu benötigen? Der Mehrwert von Datenvirtualisierung sinkt deutlich, wenn jede neue Abfrage administrativen Aufwand erfordert.
Berücksichtigen Sie über diese drei hinaus die Anforderungen an die Abfrage-Performance, die Präferenzen für das Bereitstellungsmodell und die Gesamtbetriebskosten.
Siehe auch: LakeFlow für Datenintegration und Funktionen der semantischen Schicht
Fazit: Wann Datenvirtualisierung die richtige Wahl ist
Die Datenvirtualisierung eignet sich hervorragend für operative Echtzeit-Analysen, die punktuelle Exploration heterogener Datenquellen, die Entwicklung von Proof-of-Concepts (PoCs) und Szenarien, in denen die Aktualität der Daten wichtiger ist als die Abfrage-Performance. Die Datenvirtualisierung ermöglicht Unternehmen den Zugriff auf Daten aus mehreren Quellen ohne komplexe Pipelines. Klassische Ansätze über Data Warehouses bleiben hingegen überlegen bei komplexen Transformationen, historischen Trendanalysen, großvolumiger Batch-Verarbeitung und latenzkritischen analytischen Workloads.
Die entscheidende Frage ist nicht, welchen Ansatz man exklusiv wählt, sondern wo welcher Baustein in eine ganzheitliche Architektur passt. Unternehmen wenden zunehmend beide Technologien an: Datenvirtualisierung für den agilen Zugriff und das Experimentieren, und physische Integration, wo die Workload-Eigenschaften es erfordern. Das Muster „Zuerst virtualisieren, später migrieren“ erlaubt es Teams, sofort Mehrwert über föderierte Abfragen zu liefern und anhand realer Nutzung zu entscheiden, welche Datenquellen eine physische Migration – etwa nach Delta Lake oder in andere Lakehouse-Speicher – rechtfertigen.
Beginnen Sie mit Use Cases, bei denen der Echtzeitzugriff auf verteilte Daten einen klaren geschäftlichen Nutzen stiftet. Führen Sie dort ein Pilotprojekt zur Datenvirtualisierung durch, messen Sie die Ergebnisse und skalieren Sie auf Basis nachgewiesener Erfolge.
Siehe auch: Entscheidungsrahmen für ETL vs. ELT
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.