Was ist Feature Engineering?
Umwandlung von Rohdaten in informative Merkmale für ML-Modelle durch Auswahl-, Extraktions-, Konstruktions- und Transformationstechniken
- Die Selektion identifiziert die relevantesten Variablen aus den verfügbaren Daten mithilfe von Korrelationsanalysen, gegenseitiger Information, rekursiver Merkmalseliminierung oder Domänenexpertise und entfernt redundante, irrelevante oder verrauschte Merkmale.
- Die Extraktion leitet neue Merkmale aus bestehenden ab, indem sie Dimensionsreduktion (PCA, t-SNE), Textvektorisierung (TF-IDF, Wortvektorisierungen) oder automatisches Merkmalslernen (Deep-Learning-Repräsentationen) nutzt.
- Die Konstruktion erzeugt strukturierte Merkmale, indem sie Variablen mithilfe von Domänenwissen kombiniert, z. B. durch Verhältnisse, Aggregationen, Interaktionen, Binning, Polynommerkmale und temporale Merkmale (gleitende Fenster, Verzögerungen), um komplexe Zusammenhänge zu erfassen.
Feature Engineering für Machine Learning
Feature Engineering – auch „Daten-Preprocessing“ genannt – bezeichnet die Abläufe bei der Umwandlung von Rohdaten in Features, die zur Entwicklung von Machine-Learning-Modellen verwendet werden können. Hier beschreiben wir die wichtigsten Konzepte des Feature Engineering und die Rolle, die es bei der Verwaltung des ML-Lebenszyklus spielt.
Features sind im Kontext des Machine Learning die Eingabedaten, die zum Trainieren eines Modells verwendet werden. Es handelt sich um die Attribute einer Entität, über die das Modell etwas erlernen soll. Rohdaten müssen normalerweise erst verarbeitet werden, um als Eingabedaten für ein ML-Modell genutzt werden zu können. Gutes Feature Engineering gestaltet den Prozess der Modellentwicklung effizienter und sorgt dafür, dass die Modelle einfacher, flexibler und zuverlässiger sind.
Was ist Feature Engineering?
Unter Feature Engineering versteht man die Umwandlung und Anreicherung von Daten mit dem Ziel, die Leistung von Machine-Learning-Algorithmen zu verbessern, die zum Trainieren von Modellen mit diesen Daten verwendet werden.
Das Feature Engineering umfasst Schritte wie die Skalierung oder Normalisierung von Daten, die Kodierung nichtnumerischer Daten (z. B. Text oder Bilder), die Aggregation von Daten nach Zeit oder Entität, die Verknüpfung von Daten aus verschiedenen Quellen und sogar die Übernahme von Wissen aus anderen Modellen. Das Ziel solcher Transformationen besteht darin, die Lernfähigkeit von Machine-Learning-Algorithmen zu verbessern, um aus dem Dataset genauere Vorhersagen treffen zu können.
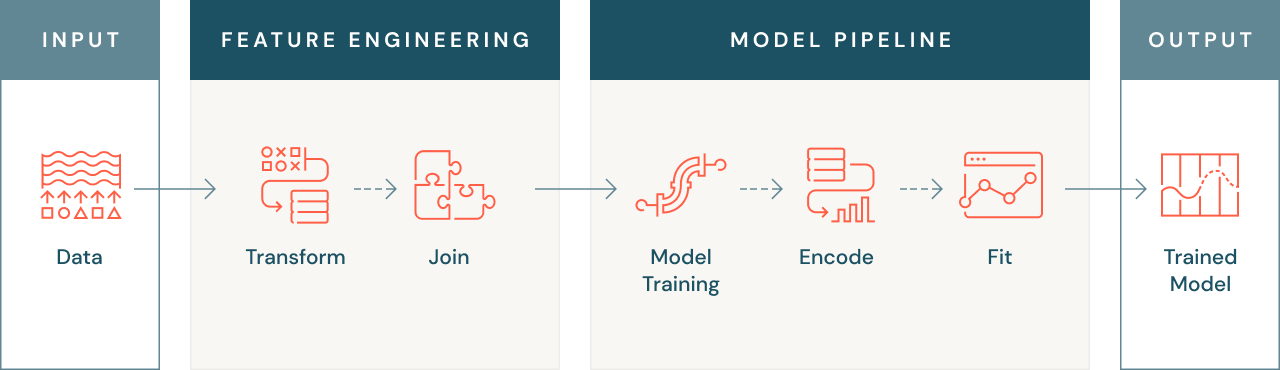
Warum ist Feature Engineering wichtig?
Feature Engineering ist aus mehreren Gründen wichtig. Zunächst einmal können Machine-Learning-Modelle, wie bereits erwähnt, manchmal keine Rohdaten verarbeiten. Daher müssen die Daten in eine numerische Form umgewandelt werden, die das Modell versteht. Das kann etwa die Konvertierung von Text- oder Bilddaten in eine numerische Form oder die Erstellung aggregierter Features wie etwa durchschnittliche Transaktionswerte für einen Kunden umfassen.
Ein im Zusammenhang mit dem Machine Learning gelegentlich auftretendes Problem sind relevante Features, die sich auf mehrere Datenquellen verteilen. In solchen Fällen umfasst ein effektives Feature Engineering auch das Verknüpfen dieser Datenquellen mit dem Ziel, ein zentrales nutzbares Dataset zu erstellen. Auf diese Weise können Sie alle vorhandenen Daten zum Trainieren Ihres Modells verwenden, was dessen Treffgenauigkeit und Leistung verbessern kann.
Ein weiteres gängiges Szenario besteht darin, dass die Ergebnisse und Erkenntnisse anderer Modelle in Form von Features für ein anderes Problem wiederverwendet werden können. Diesen Prozess bezeichnet man als Transfer Learning. Er gestattet es Ihnen, die Leistung eines neuen Modells ausgehend von Erkenntnissen aus früheren Modellen zu verbessern. Das Transfer Learning kann besonders dann nützlich sein, wenn Sie mit umfangreichen und komplexen Datasets arbeiten, bei denen es nicht praktikabel ist, ein Modell von Grund auf neu zu trainieren.
Ein effektives Feature Engineering ermöglicht auch die Nutzung belastbarer Features zum Zeitpunkt der Inferenz, d. h. wenn das Modell verwendet wird, um Prognosen anhand neuer Daten zu erstellen. Das ist wichtig, denn die Features, die bei der Inferenz eingesetzt werden, müssen mit jenen identisch sein, die für das Training verwendet wurden, um eine Online-Offline-Verzerrung („Skew“) zu vermeiden, bei der die zum Vorhersagezeitpunkt verwendeten Features anders berechnet werden als die für das Training genutzten.
Wie unterscheidet sich das Feature Engineering von anderen Datentransformationen?
Das Ziel des Feature Engineering ist die Erstellung eines Datasets, mit dem ein Training zum Aufbau eines Machine-Learning-Modells durchgeführt werden kann. Viele der Tools und Verfahren, die für Datentransformationen verwendet werden, werden auch für das Feature Engineering eingesetzt.
Da der Schwerpunkt des Feature Engineering auf der Entwicklung eines Modells liegt, gibt es mehrere Anforderungen, die nicht bei allen Feature-Transformationen gegeben sind. So müssen Sie vielleicht modellübergreifend oder auch für mehrere Teams in Ihrem Unternehmen Features wiederverwenden. Das erfordert eine robuste Methode zum Auffinden von Features.
Wenn Features wiederverwendet werden, benötigen Sie jedoch zusätzlich eine Möglichkeit, nachzuvollziehen, wo und wie diese Features berechnet werden. Das wird als „Herkunft“ (oder „Lineage“) der Features bezeichnet. Reproduzierbare Feature-Berechnungen sind für das Machine Learning von besonderer Bedeutung, da das Feature nicht nur für das Modelltraining, sondern in exakt gleicher Weise neu berechnet werden muss, wenn das Modell für die Inferenz verwendet wird.
Das Playbook für agentenbasierte KI für Unternehmen

Was sind die Vorteile eines effektiven Feature Engineering?
Eine effiziente Pipeline für das Feature Engineering führt zu robusteren Modellierungspipelines und damit letztlich auch zu zuverlässigeren und leistungsfähigeren Modellen. Die Verbesserung der Features, die gleichermaßen für Training und Inferenz verwendet werden, kann einen enormen Einfluss auf die Modellqualität haben, d. h., bessere Features generieren auch bessere Modelle.
Aus einem anderen Blickwinkel betrachtet, begünstigt ein effektives Feature Engineering auch die Wiederverwendung, wodurch in der Praxis nicht nur Zeit gespart, sondern auch die Qualität der Modelle verbessert wird. Diese Wiederverwendung von Features ist aus zwei Gründen wichtig: Sie spart Zeit, und robust definierte Features verhindern, dass Ihre Modelle bei Training und Inferenz unterschiedliche Feature-Daten nutzen, wodurch in der Regel eine Online-Offline-Verzerrung entsteht.
Welche Tools werden für das Feature Engineering benötigt?
Im Allgemeinen können die gleichen Tools, die für das Data Engineering verwendet werden, auch für das Feature Engineering eingesetzt werden, da die meisten Transformationen bei beiden Verfahren gleich sind. Hierzu gehören in der Regel ein System zur Datenspeicherung und -verwaltung, der Zugang zu offenen Standardtransformationssprachen (SQL, Python, Spark usw.) und die Möglichkeit der Nutzung von Rechenkapazitäten zur Ausführung der erforderlichen Transformationen.
Es gibt allerdings einige weitere Tools, die für das Feature Engineering in Form von bestimmten Python-Bibliotheken implementiert werden können, die bei den für das Machine Learning spezifischen Datentransformationen helfen können – wie z. B. das Einbetten von Text oder Bildern oder die One-Hot-Kodierung kategorischer Variablen. Es gibt auch verschiedene Open-Source-Projekte, die bei der Überwachung der Features helfen, die ein Modell verwendet.
Die Datenversionierung ist ein wichtiges Hilfsmittel für das Feature Engineering, da Modelle oft auf ein Dataset trainiert werden können, das in der Zwischenzeit verändert wurde. Eine ordnungsgemäße Datenversionierung ermöglicht das Reproduzieren eines bestimmten Modells, während sich Ihre Daten im Laufe der Zeit auf natürliche Weise weiterentwickeln.
Was ist ein Feature Store?
Ein Feature Store ist ein Tool, das speziell mit Blick auf die Anforderungen des Feature Engineering entwickelt wurde. Es handelt sich dabei um ein zentrales Repository für Features aus dem gesamten Unternehmen. Mithilfe von Feature Stores können Data Scientists Features ermitteln und austauschen und die Feature-Herkunft verfolgen. Ein Feature Store sorgt auch dafür, dass bei Training und Inferenz dieselben Feature-Werte verwendet werden. Diese reproduzierbare Feature-Berechnung ist für das Machine Learning von besonderer Bedeutung, da das Feature nicht nur für das Modelltraining, sondern in exakt gleicher Weise neu berechnet werden muss, wenn das Modell für die Inferenz verwendet wird.
Warum sich ein Databricks Feature Store anbietet
Der Databricks Feature Store ist vollständig mit anderen Komponenten von Databricks integriert. Sie können Databricks-Notebooks nutzen, um Code zur Erstellung von Features zu entwickeln und Modelle auf deren Grundlage zu erstellen. Wenn Sie Modelle mit Databricks bereitstellen, sucht das Modell zur Inferenz automatisch nach Feature-Werten aus dem Feature Store. Der Databricks Feature Store bietet außerdem die in diesem Artikel beschriebenen Vorteile von Feature Stores:
- Auffindbarkeit: Über die Benutzeroberfläche des Feature Store, auf die Sie vom Databricks-Arbeitsbereich aus zugreifen, können Sie nach vorhandenen Features suchen und diese durchsuchen.
- Herkunft: Wenn Sie mit dem Databricks Feature Store eine Feature-Tabelle erstellen, werden die zur Erstellung der Feature-Tabelle verwendeten Datenquellen gespeichert und sind zugänglich. Sie können auch auf alle Modelle, Notebooks, Jobs und Endpunkte der einzelnen Features in einer Feature-Tabelle zugreifen, die das Feature nutzen.
Weitere Eigenschaften des Databricks Feature Store
- Integration mit Modellbewertung und -bereitstellung: Wenn Sie Features aus dem Databricks Feature Store verwenden, um ein Modell zu trainieren, dann werden beim Packen des Modells Feature-Metadaten hinzugefügt. Nutzen Sie das Modell für Batch Scoring oder Online-Inferenz, dann ruft es automatisch Features aus dem Databricks Feature Store ab. Der Aufrufer muss diese nicht kennen und auch keine Logik zum Nachschlagen oder Verbinden von Features integrieren, um neue Daten zu bewerten. Dadurch werden Bereitstellung und Aktualisierung von Modellen wesentlich einfacher.
- Point-in-Time-Suchanfragen: Der Databricks Feature Store unterstützt Zeitreihen und ereignisbasierte Anwendungsfälle, die eine zeitpunktgenaue Richtigkeit erfordern.
Zusätzliche Ressourcen
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.