Was sind Modelle des maschinellen Lernens?
Algorithmen, die aus Trainingsdaten Muster lernen, um Vorhersagen zu treffen, von linearer Regression und Entscheidungsbäumen bis hin zu tiefen neuronalen Netzen
- Der Trainingsprozess beinhaltet das Training von gelabelten Daten mit Algorithmen, die interne Parameter (Gewichte, Koeffizienten) anpassen, um den Vorhersagefehler auf Validierungsdatensätzen zu minimieren. Dabei kommen Techniken wie Gradientenabstieg, Backpropagation und Regularisierung zum Einsatz.
- Die Modelltypen umfassen überwachtes Lernen (Klassifizierung, Regression), unüberwachtes Lernen (Clustering, Dimensionsreduktion), bestärkendes Lernen und semi-überwachte Ansätze. Jeder Ansatz eignet sich für unterschiedliche Problemstrukturen und Datenverfügbarkeiten.
- Zu den Bewertungsmetriken gehören Genauigkeit, Präzision, Trefferquote, F1-Score und AUC-ROC für die Klassifizierung; MSE, MAE und R² für die Regression; sowie Silhouette-Score und Davies-Bouldin-Index für das Clustering. Diese Metriken dienen der Modellauswahl und der Hyperparameteroptimierung.
Was ist ein Machine-Learning-Modell?
Ein Machine-Learning-Modell ist ein Programm, das Muster findet oder auf Basis eines zuvor ungesehenen Datasets Entscheidungen trifft. Bei der Verarbeitung natürlicher Sprache beispielsweise können Machine-Learning-Modelle die Absicht hinter zuvor ungehörten Sätzen oder Wortkombinationen analysieren und korrekt erkennen. Bei der Bilderkennung kann einem Machine-Learning-Modell beigebracht werden, Objekte wie beispielsweise Autos oder Hunde zu erkennen. Ein Machine-Learning-Modell kann solche Aufgaben erfüllen, wenn es mit einem großen Dataset trainiert wird. Beim Training wird der Machine-Learning-Algorithmus optimiert, um je nach Aufgabe bestimmte Muster oder Ausgaben des Datasets zu ermitteln. Das Ergebnis dieses Prozesses – oft ein Computerprogramm mit konkreten Regeln und Datenstrukturen – bezeichnet man als Machine-Learning-Modell.
Was ist ein Machine-Learning-Algorithmus?
Ein Machine-Learning-Algorithmus ist ein mathematisches Verfahren, mit dem man Muster in einer Datenmenge erkennt. Machine-Learning-Algorithmen werden häufig aus der Statistik, der Infinitesimalrechnung und der linearen Algebra übernommen. Einige bekannte Beispiele für Machine-Learning-Algorithmen sind die lineare Regression, Entscheidungsbäume, Random Forest und XGBoost.
Was ist das Modelltraining beim Machine Learning?
Als Modelltraining bezeichnet man den Vorgang, bei dem ein Machine-Learning-Algorithmus für ein Dataset (die so genannten Trainingsdaten) ausgeführt wird, um den Algorithmus zu optimieren und auf bestimmte Muster oder Ausgaben zuzuschneiden. Die resultierende Funktion mit ihren Regeln und Datenstrukturen wird trainiertes Machine-Learning-Modell genannt.
Welche verschiedenen Formen des maschinellen Lernens gibt es?
Grundsätzlich lassen sich Machine-Learning-Verfahren in beaufsichtigtes Lernen, unbeaufsichtigtes, und verstärkendes Lernen einteilen.
Was ist beaufsichtigtes Machine Learning?
Beim beaufsichtigten Machine Learning erhält der Algorithmus ein Eingabe-Dataset und wird darauf ausgerichtet, bestimmte Ergebnisse zu erzielen. Beaufsichtigtes Machine Learning wird beispielsweise häufig in der Bilderkennung eingesetzt. Dabei kommt eine Technik namens Klassifizierung zum Einsatz. Das beaufsichtigte maschinelle Lernen wird auch bei der Vorhersage von demografischen Daten wie Bevölkerungswachstum oder Gesundheitsmetriken verwendet,, wobei eine Technik namens Regression genutzt wird.
Was ist unbeaufsichtigtes Machine Learning?
Beim unbeaufsichtigten Machine Learning erhält der Algorithmus ein Dataset als Eingabe, wird aber nicht für bestimmte Ausgaben, sondern darauf optimiert, Objekte anhand gemeinsamer Eigenschaften zu Gruppen zusammenzufassen. Empfehlungssysteme für Online-Shops beispielsweise nutzen unbeaufsichtigtes Machine Learning und ganz konkret eine Technik namens Clustering.
Was ist verstärkendes Lernen?
Beim verstärkenden Lernen wird der Algorithmus dazu veranlasst, sich selbst zu trainieren, indem er nach dem Prinzip von Versuch und Irrtum viele Experimente durchführt. Verstärkendes Lernen findet statt, wenn der Algorithmus fortlaufend mit der Umgebung interagiert, statt auf Trainingsdaten zurückzugreifen. Eines der bekanntesten Beispiele für das verstärkendes Lernen ist das autonome Fahren.
Welche verschiedenen Machine-Learning-Modelle gibt es?
Es gibt eine ganze Reihe von Machine-Learning-Modellen, die fast alle auf bestimmten Machine-Learning-Algorithmen beruhen. Gängige Klassifizierungs- und Regressionsalgorithmen fallen unter das beaufsichtigte Machine Learning, während Clustering-Algorithmen im Allgemeinen in Szenarien mit unbeaufsichtigtem Machine Learning eingesetzt werden.
Beaufsichtigtes Machine Learning
- Logistische Regression: Wird verwendet, um festzustellen, ob eine Eingabe zu einer bestimmten Gruppe gehört oder nicht.
- SVM (Support Vector Machines): SVMs erstellen Koordinaten für jedes Objekt in einem n-dimensionalen Raum und verwenden eine Hyperebene, um Objekte nach gemeinsamen Merkmalen zu gruppieren.
- Naive Bayes: Naive Bayes ist ein Algorithmus, der ausgehend von der These der Unabhängigkeit von Variablen die Wahrscheinlichkeit zur Klassifizierung von Objekten anhand von Merkmalen verwendet.
- Entscheidungsbäume: Entscheidungsbäume sind ebenfalls Klassifizierer, mit denen bestimmt werden kann, in welche Kategorie eine Eingabe fällt. Hierzu werden die Blätter und Knoten eines Baums durchlaufen.
- Lineare Regression: Mit der linearen Regression werden Beziehungen zwischen der interessanten Variable und den Eingaben ermittelt und Werte auf der Grundlage der Werte der Eingabevariablen vorhergesagt.
- kNN (k Nearest Neighbors): Bei der kNN-Technik werden die jeweils nächstgelegenen Objekte in einem Dataset zusammengefasst und die häufigsten oder durchschnittlichen Merkmale der Objekte ermittelt.
- Random Forest (deutsch auch „Zufallswald“): Ein Random Forest ist eine Sammlung mehrerer Entscheidungsbäume aus zufälligen Teilmengen der Daten. Das Ergebnis ist eine Kombination von Bäumen, die in der Vorhersage genauer sein kann als ein einzelner Entscheidungsbaum.
- Boosting-Algorithmen: Boosting-Algorithmen, wie z. B. Gradient Boosting Machine, XGBoost und LightGBM, verwenden das so genannte Ensemble Learning. Sie kombinieren die Voraussagen mehrerer Algorithmen (wie z. B. Entscheidungsbäume) und berücksichtigen dabei den Fehler des vorangegangenen Algorithmus.
Unbeaufsichtigtes Machine Learning
- K-Means: Der K-Means-Algorithmus findet Ähnlichkeiten zwischen Objekten und gruppiert sie in K verschiedenen Clustern.
- Hierarchisches Clustering: Beim hierarchischen Clustering wird ein Baum mit verschachtelten Clustern erstellt, ohne die Anzahl der Cluster angeben zu müssen.
Was ist beim Machine Learning ein Entscheidungsbaum?
Ein Entscheidungsbaum ist ein prädiktiver ML-Ansatz, um zu ermitteln, zu welcher Klasse ein Objekt gehört. Wie der Name bereits andeutet, ist ein Entscheidungsbaum ein baumartiges Ablaufdiagramm, in dem die Klasse eines Objekts schrittweise anhand bestimmter bekannter Bedingungen ermittelt wird. 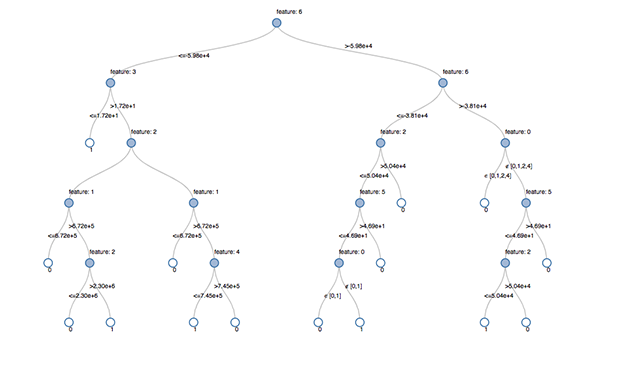 Darstellung eines Entscheidungsbaums im Databricks Lakehouse. Quelle: https://www.databricks.com/blog/2019/05/02/detecting-financial-fraud-at-scale-with-decision-trees-and-mlflow-on-databricks.html
Darstellung eines Entscheidungsbaums im Databricks Lakehouse. Quelle: https://www.databricks.com/blog/2019/05/02/detecting-financial-fraud-at-scale-with-decision-trees-and-mlflow-on-databricks.html
Das Playbook für agentenbasierte KI für Unternehmen

Was versteht man im Kontext von Machine Learning unter Regression?
In der Data Science und im Machine Learning bezeichnet der Begriff „Regression“ eine statistische Methode, die eine Vorhersage von Ergebnissen auf der Grundlage einer Reihe von Eingabevariablen ermöglicht. Das Ergebnis ist häufig eine Variable, die von einer Kombination der Eingabevariablen abhängt. 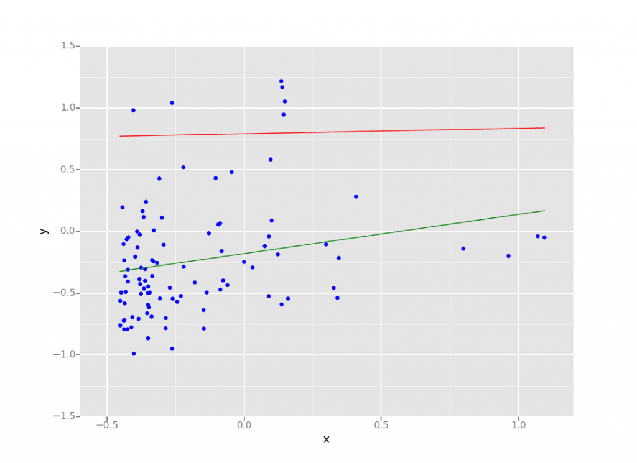 Auf das Databricks Lakehouse angewandtes lineares Regressionsmodell. Quelle: https://www.databricks.com/blog/2015/06/04/simplify-machine-learning-on-spark-with-databricks.html
Auf das Databricks Lakehouse angewandtes lineares Regressionsmodell. Quelle: https://www.databricks.com/blog/2015/06/04/simplify-machine-learning-on-spark-with-databricks.html
Was ist beim Machine Learning ein Klassifikator?
Ein Klassifikator ist ein Machine-Learning-Algorithmus, der ein Objekt als Mitglied einer Kategorie oder Gruppe zuordnet. Klassifikatoren werden zum Beispiel verwendet, um zu erkennen, ob es sich bei einer E-Mail um Spam oder bei einer Transaktion um Betrug handelt.
Wie viele Modelle gibt es beim Machine Learning?
Sehr viele! Machine Learning entwickelt sich fortlaufend weiter und es werden immer mehr Machine-Learning-Modelle entwickelt.
Welches ist das beste Machine-Learning-Modell?
Welches Machine-Learning-Modell sich in einer bestimmten Situation am besten eignet, hängt vom gewünschten Ergebnis ab. Wenn Sie etwa die Anzahl der Fahrzeugkäufe in einer Stadt anhand historischer Daten vorhersagen möchten, könnte eine beaufsichtigte Methode wie die lineare Regression am sinnvollsten sein. Um jedoch herauszufinden, ob ein potenzieller Kunde in dieser Stadt unter Berücksichtigung seines Einkommens und seiner Pendlervorgeschichte ein Fahrzeug kaufen würde, könnte ein Entscheidungsbaum die bessere Wahl sein.
Was ist beim Machine Learning eine Modellimplementierung?
Als Modellimplementierung bezeichnet man einen Vorgang, bei dem ein Machine-Learning-Modell für den Einsatz in einer Zielumgebung bereitgestellt wird – sei es zum Testen oder für die Produktion. Das Modell wird in der Regel über APIs in andere Anwendungen in der Umgebung (wie Datenbanken und UI) integriert. Die Implementierung ist die Phase, nach deren Abschluss ein Unternehmen endlich eine Rendite für die hohen Investitionen in die Modellentwicklung erzielen kann. 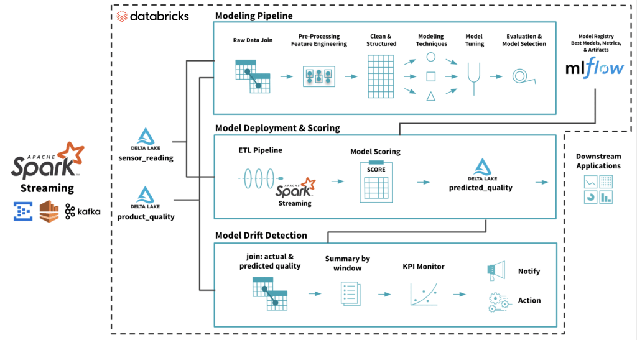 Ein vollständiger Machine-Learning-Modelllebenszyklus beim Databricks Lakehouse. Quelle: https://www.databricks.com/blog/2019/09/18/productionizing-machine-learning-from-deployment-to-drift-detection.html
Ein vollständiger Machine-Learning-Modelllebenszyklus beim Databricks Lakehouse. Quelle: https://www.databricks.com/blog/2019/09/18/productionizing-machine-learning-from-deployment-to-drift-detection.html
Was sind Deep-Learning-Modelle?
Als Deep-Learning-Modelle bezeichnet man eine Klasse von ML-Modellen, die die Verarbeitung von Informationen durch den Menschen nachahmen. Um aus den bereitgestellten Daten allgemeine Merkmale zu extrahieren, umfasst das Modell mehrere Verarbeitungsebenen (daher der Begriff „Deep“, der hier auf das Vorhandensein mehrerer Ebenen verweist). Jede Verarbeitungsebene übergibt eine abstraktere Darstellung der Daten an die nachfolgende Ebene, wobei die letzte Ebene einen Einblick gewährt, der dem eines Menschen ähnelt. Anders als herkömmliche ML-Modelle, die gelabelte Daten benötigen, können Deep-Learning-Modelle große Mengen auch unstrukturierter Daten einlesen. Mit ihnen lassen sich menschliche Handlungen wie das Erkennen von Gesichtern und die Verarbeitung natürlicher Sprache durchführen.  Eine vereinfachte Darstellung von Deep Learning. Quelle: https://www.databricks.com/discover/pages/the-democratization-of-artificial-intelligence-and-deep-learning
Eine vereinfachte Darstellung von Deep Learning. Quelle: https://www.databricks.com/discover/pages/the-democratization-of-artificial-intelligence-and-deep-learning
Was ist Machine Learning mit Zeitreihen?
Bei einem Machine-Learning-Modell mit Zeitreihen ist eine der unabhängigen Variablen eine Reihe aufeinanderfolgender Zeiteinheiten (Minuten, Tage, Jahre usw.), die die abhängige oder prognostizierte Variable beeinflussen. Solche Machine-Learning-Modelle werden verwendet, um zeitbezogene Ereignisse vorherzusagen, z. B. das Wetter in einer zukünftigen Woche, die erwartete Anzahl von Kunden in einem zukünftigen Monat, die Umsatzprognose für ein zukünftiges Jahr usw.
Wo kann ich mehr über Machine Learning erfahren?
- Lesen Sie dieses kostenlose E-Book und entdecken Sie viele faszinierende Machine-Learning-Anwendungsfälle von Unternehmen auf der ganzen Welt.
- Wenn Sie mehr Expertenwissen zum Thema Machine Learning wünschen, lesen Sie den Machine Learning Blog von Databricks.
Zusätzliche Ressourcen
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.