Direkt zum Hauptinhalt
Was sind kontinuierliche Anwendungen?
Wie kontinuierliche Anwendungen Streaming, Serving, Batch-Verarbeitung und maschinelles Lernen hinter einer einzigen Schnittstelle vereinen, damit Systeme in Echtzeit auf Daten reagieren können
- Erfahren Sie, was Continuous Applications sind und wie Sie damit durchgängige Systeme entwickeln, die in Echtzeit auf Daten reagieren – mit einer einzigen Programmierschnittstelle.
- Sehen Sie, wie Anwendungsfälle wie Echtzeit-Serving, ETL, das Erstellen von Streaming-Versionen von Batch-Jobs und Online-Machine-Learning in einer einzigen Continuous Application abgebildet werden können.
- Verstehen Sie, warum die Vereinheitlichung von Streaming, Storage, Serving und Batch hinter einer API die Komplexität im Vergleich zur Integration mehrerer separater Systeme reduziert.
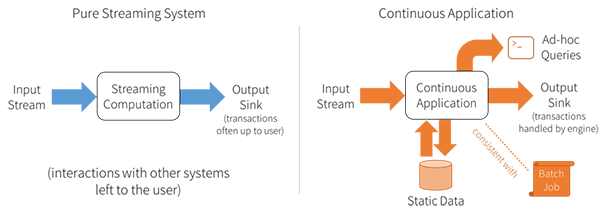
Kontinuierliche Anwendungen sind End-to-End-Anwendungen, die in Echtzeit auf Daten reagieren. Entwickler möchten eine einzige Programmierschnittstelle verwenden, um die Facetten kontinuierlicher Anwendungen zu unterstützen, die derzeit in separaten Systemen abgewickelt werden, z. B. Abfragebereitstellung oder die Interaktion mit Batchjobs. Unten finden Sie ein Beispiel für kontinuierliche Anwendungen, die die folgenden Anwendungsfälle verarbeiten können.
- Aktualisierung der Daten, die in Echtzeit bereitgestellt werden. Der Entwickler würde eine einzelne Spark-Anwendung schreiben, die sowohl Aktualisierungen als auch Bereitstellung abwickelt (z. B. über den JDBC-Server von Spark), oder er würde eine API verwenden, die automatisch Transaktionsaktualisierungen auf einem Bereitstellungssystem wie MySQL, Redis oder Apache Cassandra durchführt.
- Extract, Transform, Load (ETL; Extrahieren, Transformieren, Laden). Der Entwickler würde einfach die erforderlichen Transformationen wie bei einem Batchjob auflisten und das Streaming-System würde die Koordination mit beiden Speichersystemen übernehmen, um eine genau einmalige Verarbeitung sicherzustellen.
- Erstellen einer Echtzeit-Version eines vorhandenen Batchjobs. Das Streaming-System würde garantieren, dass die Ergebnisse immer mit einem Batchjob auf denselben Daten konsistent sind.
- Online Machine Learning. Eine Machine Learning Library (MLlib) ist so konzipiert, dass sie Echtzeit-Training, periodisches Batch-Training und Vorhersagebereitstellung hinter derselben API kombiniert.
Bericht
Das Playbook für agentenbasierte KI für Unternehmen

Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.