Was sind ML-Pipelines?
Erfahren Sie, wie ML-Pipelines den Workflow des maschinellen Lernens von der Datenvorverarbeitung bis zur Modellvalidierung automatisieren und optimieren.
- Verstehen Sie, was ML-Pipelines sind und wie sie Vorverarbeitung, Merkmalsextraktion, Modellanpassung und Validierung in einem einheitlichen Workflow verbinden.
- Lernen Sie den Unterschied zwischen Transformatoren und Schätzern als den beiden zentralen Pipeline-Stufen kennen.
- Erfahren Sie, wie Spark ML-Pipelines skalierbares, verteiltes maschinelles Lernen durch die native Erstellung und Optimierung von Pipelines ermöglichen.
Die Ausführung von Machine-Learning-Algorithmen umfasst üblicherweise eine Reihe von Aufgaben wie die Phasen für Vorverarbeitung, Feature-Extraktion, Modellanpassung und Validierung. Wenn Sie beispielsweise Textdokumente klassifizieren, müssen der Text segmentiert und bereinigt, Features extrahiert und ein Klassifizierungsmodell mit Kreuzvalidierung trainiert werden. Zwar gibt es viele Bibliotheken, die wir für die einzelnen Phasen nutzen können, doch ist es nicht so einfach, die Verbindung zwischen ihnen herzustellen, wie es vielleicht aussieht – insbesondere bei umfangreichen Datasets. Die meisten ML-Bibliotheken sind nicht für verteilte Berechnungen konzipiert oder bieten keine native Unterstützung zum Erstellen und Optimieren von Pipelines.
Das Playbook für agentenbasierte KI für Unternehmen

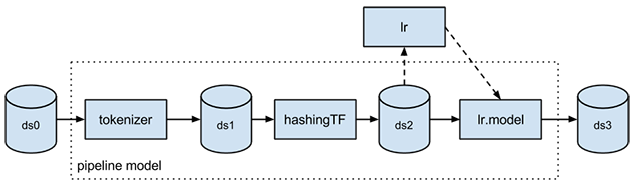
ML Pipelines sind eine High-Level-API für MLlib, die im Paket „spark.ml“ zu finden ist. Eine Pipeline umfasst eine Abfolge von Phasen. Es gibt zwei grundlegende Arten von Pipeline-Phasen: Transformer und Estimator. Ein Transformer nimmt ein Dataset als Eingabe entgegen und erzeugt als Ausgabe ein ergänztes Dataset. So ist etwa ein Tokenizer ein Transformer, der ein Dataset mit Text in eines mit tokenisierten Wörtern umwandelt. Ein Estimator muss zunächst an das Eingabe-Dataset angepasst werden, um ein Modell erstellen zu können, das seinerseits ein Transformer ist, der das Eingabe-Dataset umgestaltet. Die logistische Regression ist z. B. ein Estimator, der mit einem Dataset mit Labeln und Features trainiert und auf Grundlage der Ergebnisse ein logistisches Regressionsmodell erstellt.
Zusätzliche Ressourcen
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.