Was ist eine Feature-Plattform?
Infrastruktur für das Feature-Lifecycle-Management, einschließlich Entwicklung, Speicherung, Erkennung, Überwachung und Governance mit APIs zur Erstellung und Bereitstellung
- Die Komponenten umfassen Werkzeuge zur Feature-Erstellung für die Definition von Transformationen, Orchestrierungssysteme zur Planung von Berechnungspipelines, Speicherschichten für Offline- und Online-Features, APIs für den Echtzeitzugriff und Monitoring-Dashboards zur Qualitätsverfolgung.
- Unterstützt werden Batch-Feature-Berechnung für das Modelltraining, Streaming-Feature-Updates für Echtzeitsysteme, On-Demand-Feature-Berechnung während der Inferenz und Feature-Backfilling für historische Experimente.
- Zu den erweiterten Funktionen gehören Feature-Validierung zur Qualitätssicherung, automatisierte Tests für Feature-Pipelines, eine A/B-Testinfrastruktur für Feature-Experimente und die Integration mit ML-Plattformen für nahtlose Modellentwicklungs-Workflows.
Bis vor zwei Jahren hatten nur riesige Technologieunternehmen die Ressourcen und das Fachwissen, um Produkte zu entwickeln, die vollständig von Machine-Learning-Systemen abhingen. Denken Sie an Google, das Anzeigenauktionen steuert, TikTok, das Inhalte empfiehlt, und Uber, das die Preise dynamisch anpasst. Um ihre kritischsten Anwendungen mit Machine Learning zu betreiben, bauten diese Teams eine benutzerdefinierte Infrastruktur auf, die den speziellen Anforderungen der Bereitstellung von Machine-Learning-Systemen entsprach.
Ein paar Jahre später ist ein ganzes Ökosystem von MLOps-Tools entstanden, um Machine Learning in der Produktion zu demokratisieren. Aber bei Hunderten von verschiedenen Tools ist es mittlerweile ein Vollzeitjob, zu verstehen, was jedes einzelne davon tut. Feature-Plattformen und ihre nahen Verwandten, die Feature-Stores, sind ein beliebter Teil dieses Ökosystems. Kurz gesagt, eine Feature-Plattform macht Ihre bestehende Dateninfrastruktur (Data Warehouses, Streaming-Infrastrukturen wie Kafka, Datenprozessoren wie Spark/Flink usw.) für operationale ML -Anwendungen nutzbar. Dieser Beitrag erklärt genauer, was Feature-Plattformen sind und welche Probleme sie lösen.
Der Aufbau von operativem maschinellem Lernen ist schwierig.
Merkmalsplattformen ermöglichen operatives maschinelles Lernen (ML), das stattfindet, wenn eine kundenorientierte Anwendung ML nutzt, um autonom und kontinuierlich Entscheidungen zu treffen, die sich in Echtzeit auf das Geschäft auswirken. Die von mir genannten Beispiele von Google, TikTok und Uber sind allesamt operative ML-Anwendungen. Jedes Machine-Learning-Projekt besteht immer aus vier Phasen:
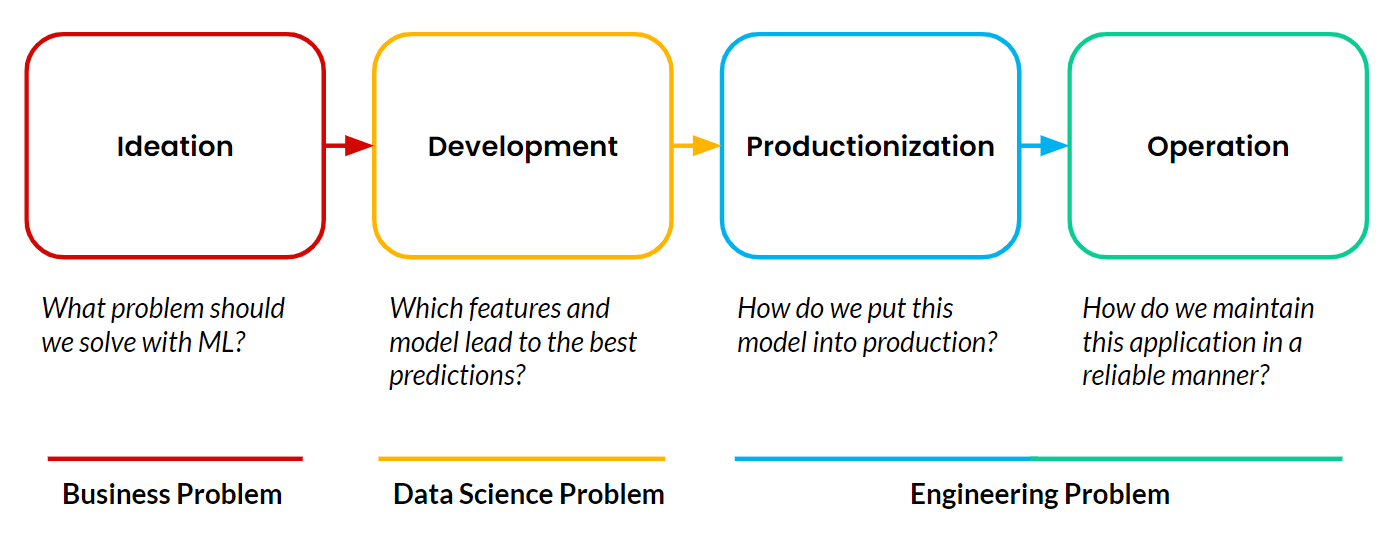
Die meisten Projekte kommen nie über die Entwicklungsphase hinaus. Die Produktivsetzung und der Betrieb von Machine-Learning-Anwendungen bleiben die größte Hürde für Teams. Und der schwierigste Teil bei der Produktivsetzung und dem Betrieb von ML ist die Verwaltung der Datenpipelines, die diese Anwendungen kontinuierlich versorgen müssen.
Eine Feature-Plattform löst die Datenherausforderungen, die mit der Produktivsetzung und dem Betrieb verbunden sind. Sie schafft einen Weg in die Produktion. Wir werden noch genauer darauf eingehen, was das bedeutet, aber lassen Sie uns zuerst beschreiben, was ein Feature ist.
Was ist ein Machine-Learning-Feature?
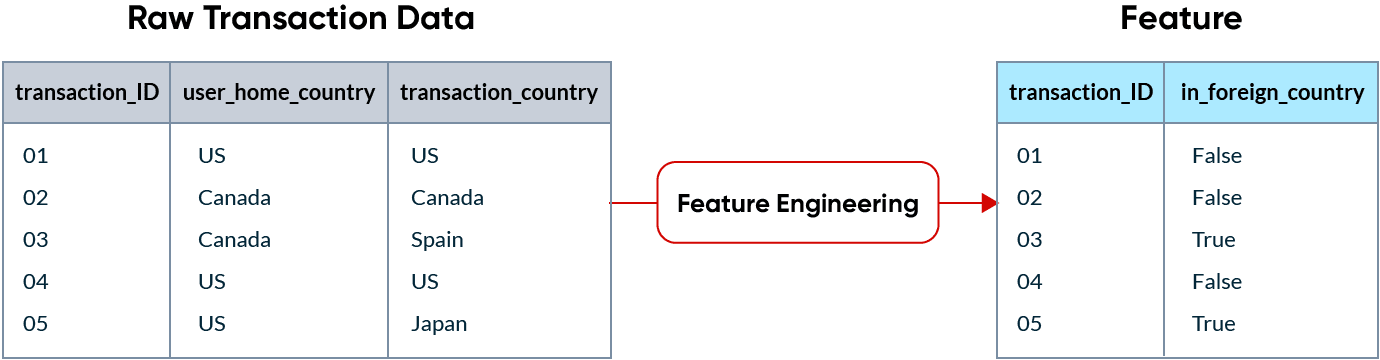
Beim maschinellen Lernen bezeichnet ein Feature Daten, die als Eingabe für ML-Modelle zur Erstellung von Vorhersagen verwendet werden. Rohdaten liegen selten in einem Format vor, das von einem ML-Modell verarbeitet werden kann, und müssen daher in Features umgewandelt werden. Dieser Prozess wird als Feature Engineering bezeichnet.
Wenn beispielsweise ein Kreditkartenunternehmen versucht, betrügerische Transaktionen aufzudecken, könnte eine im Ausland getätigte Transaktion ein guter Indikator für Betrug sein. Features sind letztendlich die Spalten in den Daten, die an ein Modell gesendet werden.
Das Besondere an ML ist, dass Features auf zwei verschiedene Weisen genutzt werden:
- Um ein Modell zu trainieren, benötigen wir große Mengen an Historische Daten.
- Um eine Live-Vorhersage zu treffen, müssen wir dem Modell nur die neuesten Features zur Verfügung stellen, aber wir müssen diese Informationen innerhalb von Millisekunden bereitstellen. Dies wird auch als Online-Inferenz bezeichnet. In diesem Beispiel muss das Modell nur wissen, ob die aktuelle Transaktion im Ausland stattfindet oder nicht, und es muss diese Informationen verarbeiten, während die Transaktion ausgeführt wird.
Welche Probleme löst eine Feature-Plattform?
In der Entwicklungsphase eines Machine-Learning-Projekts führen Data Scientists umfangreiches Feature-Engineering durch, um die Features zu finden, die zur höchsten Vorhersagegenauigkeit führen. Sobald dieser Prozess abgeschlossen ist, übergeben sie das Projekt in der Regel an einen Engineering-Kollegen, der diese Feature-Engineering-Pipelines in Produktion nimmt.
Als Data Scientist möchten Sie sich nicht damit befassen, wie die Daten verfügbar gemacht oder wie sie berechnet werden. Sie wissen, welche Features Sie wollen, und Sie wollen, dass diese Features dem Modell für Live-Vorhersagen zur Verfügung stehen. Ingenieure hingegen müssen diese Datenpipelines in einer Produktionsumgebung neu implementieren, was schnell sehr komplex wird, sobald Echtzeitdaten oder Nahezu-Echtzeit-Daten im Spiel sind. Um operative ML-Anwendungen zu betreiben, müssen diese Pipelines kontinuierlich und ausfallsicher laufen, extrem schnell sein und mit dem Geschäft skalieren.
Die erneute Implementierung von Datenpipelines in einer Produktionsumgebung ist der Hauptblocker für operative ML-Projekte. Um auf das Beispiel der Betrugserkennung zurückzukommen: Realistische Features, die Unternehmen implementieren werden, sind:
- Entfernung zwischen dem Wohnort eines Nutzers und dem Transaktionsort, die während der Transaktion berechnet wird.
- Ob der aktuelle Transaktionsbetrag mehr als eine Standardabweichung über dem historischen Durchschnitt an diesem Händlerstandort liegt.
- Die Anzahl der Transaktionen eines Nutzers in den letzten 30 Minuten, jede Sekunde aktualisiert.
Diese Feature-Engineering-Pipelines sind schwierig zu implementieren. Sie können nicht direkt in einem Data Warehouse berechnet werden und erfordern die Einrichtung einer Streaming-Infrastruktur, um Daten in Echtzeit zu verarbeiten. Eine Feature-Plattform löst die technischen Herausforderungen bei der Inbetriebnahme dieser Features und schafft dadurch einen einfachen Weg in die Produktion. Konkret: eine Feature-Plattform:
- Orchestriert und führt kontinuierlich Datenpipelines aus, um Features zu compute und sie für Offline-Training und Online-Inferenz verfügbar zu machen.
- Verwaltet Features als Code, sodass Teams Code-Reviews und Versionskontrolle durchführen und Feature-Änderungen in CI/CD-Pipelines integrieren können.
- Erstellt eine Feature-Bibliothek, die Feature-Definitionen standardisiert und Data Scientists ermöglicht, Features teamübergreifend zu teilen und zu entdecken.
Lassen Sie uns einen genaueren Blick darauf werfen, wie Benutzer mit einer Feature-Plattform interagieren und was ihre Komponenten sind.
Das Playbook für agentenbasierte KI für Unternehmen

Was ist eine Feature-Plattform?
Eine Feature-Plattform ist ein System, das die vorhandene Dateninfrastruktur orchestriert, um Daten für operative Machine-Learning-Anwendungen kontinuierlich zu transformieren, zu speichern und bereitzustellen.
Es gibt zwei Hauptarten, auf die Nutzer mit einer Feature-Plattform interagieren:
- Feature-Erstellung und -Entdeckung
- Benutzer definieren neue Features als Code in Python-Dateien mithilfe eines deklarativen Frameworks. Feature-Definitionen werden in einem Git-Repository verwaltet.
- Benutzer entdecken vorhandene Features, die andere Teams definiert haben.
- Feature-Abruf
- Zur Trainingszeit können Benutzer die Feature-Plattform in einem Notebook aufrufen, um alle Historische Daten zu erhalten, die sie zum Trainieren eines Modells benötigen. Dies kann mit einem Aufruf wie get_historical_features(fraud_model) erfolgen. Die Feature-Plattform übernimmt die Komplexität des Backfillings von Features und der Durchführung korrekter Point-in-Time-Joins, und der resultierende DataFrame kann von allen Modell-Trainings-Tools wie XGBoost, Scikit-learn usw. verarbeitet werden.
- Zur Inferenzzeit stellt die Feature-Plattform einen REST-Endpunkt bereit, der von einer Live-Anwendung aufgerufen werden kann. Dieser gibt in Millisekunden den neuesten Feature-Vektor für eine bestimmte Entitäts-ID zurück, den das Modell zur Erstellung einer Vorhersage verwendet.
Feature-Plattformen ersetzen keine bestehende Infrastruktur. Stattdessen ermöglichen sie den Einsatz der bestehenden Infrastruktur für operative Machine-Learning-Anwendungen –sie verbinden sich mit (1) Batch-Datenquellen wie Data Lakes und Data Warehouses und (2) Streaming-Quellen wie Kafka. Sie nutzen (3) bestehende Recheninfrastruktur, wie ein Data Warehouse oder Spark, und (4) bestehende Speicherinfrastruktur, wie S3, DynamoDB oder Redis. Eine moderne Feature-Plattform verbindet sich flexibel mit der bestehenden Dateninfrastruktur eines Unternehmens.
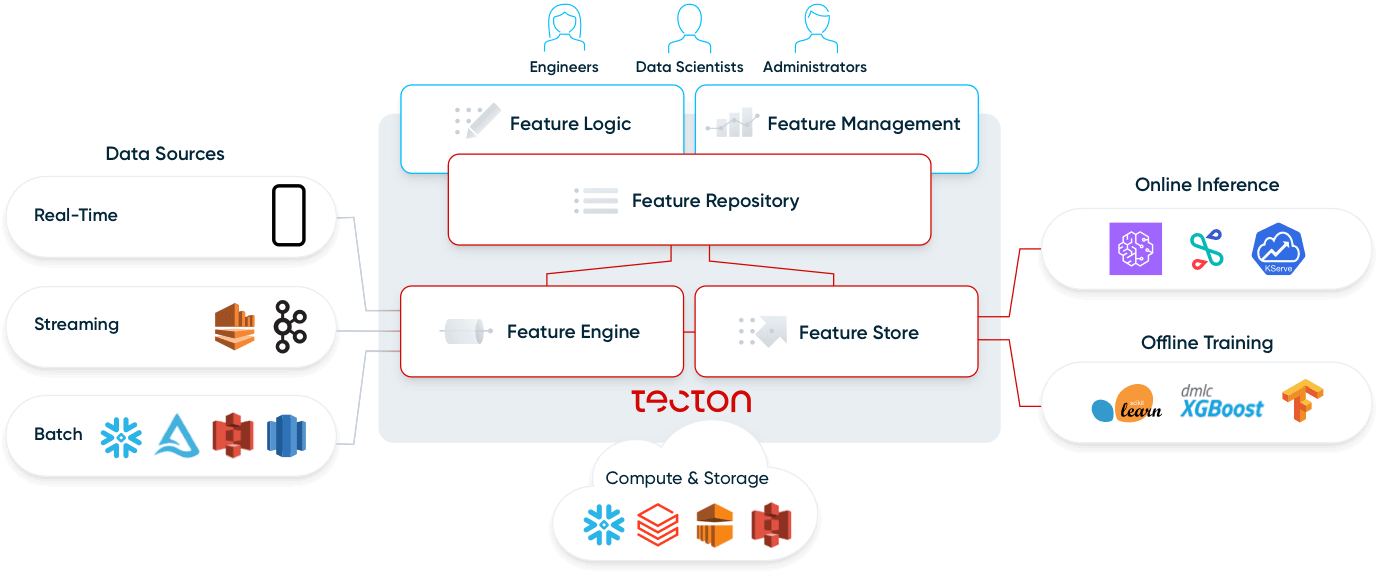
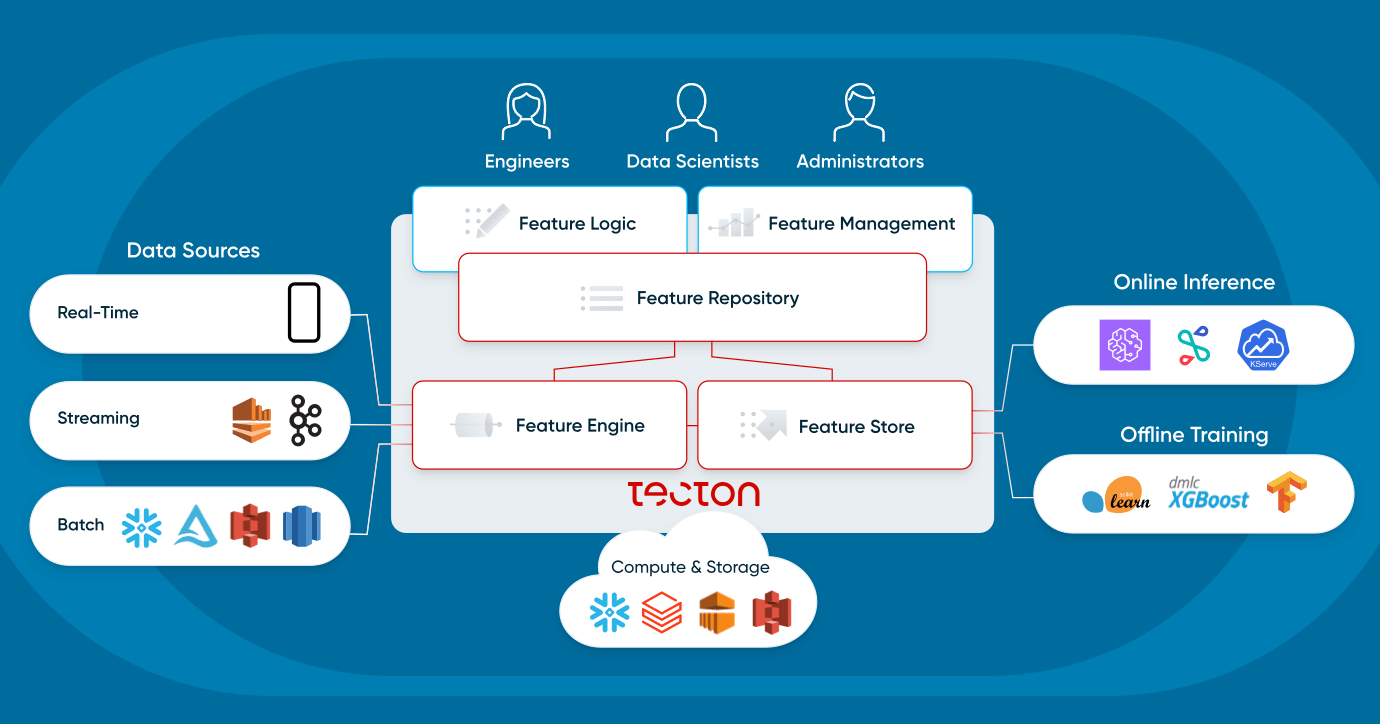
Werfen wir einen genaueren Blick auf die vier Komponenten einer Feature-Plattform: Feature Repository, Feature Pipelines, Feature Store und Monitoring.
Feature-Repository
Viele Data Scientists führen ihr Feature-Engineering in Notebooks durch. Sie sind interaktiv, einfach zu bedienen und führen zu schnellen Entwicklungszyklen. Die Schwierigkeiten beginnen, wenn diese Features in die Produktion überführt werden müssen; es ist unmöglich, sie in CI/CD-Pipelines zu integrieren und die Kontrollen zu haben, die wir bei traditioneller Software einsetzen.
Teams, die operative ML-Anwendungen erfolgreich bereitstellen, verwalten ihre Features als Code-Assets. Dies bringt alle Vorteile von DevOps mit sich – es ermöglicht Teams, Code-Reviews durchzuführen, die Herkunft nachzuverfolgen und sich in CI/CD-Pipelines zu integrieren, wodurch Teams Änderungen schneller und zuverlässiger bereitstellen können. Ein häufiges Anzeichen bei Teams, die Features nicht als Code verwalten, ist, dass sie oft nicht in der Lage sind, über die erste Version eines Modells hinaus zu iterieren.
In einer Feature-Plattform definieren Nutzer Features als Code über eine deklarative Schnittstelle, die drei Elemente enthält:
- Konfiguration, wie oft das Feature berechnet werden sollte.
- Metadaten, wie der Feature-Name und die Beschreibung, um das Teilen und die Auffindbarkeit zu ermöglichen.
- Transformationslogik, definiert in SQL oder Python.
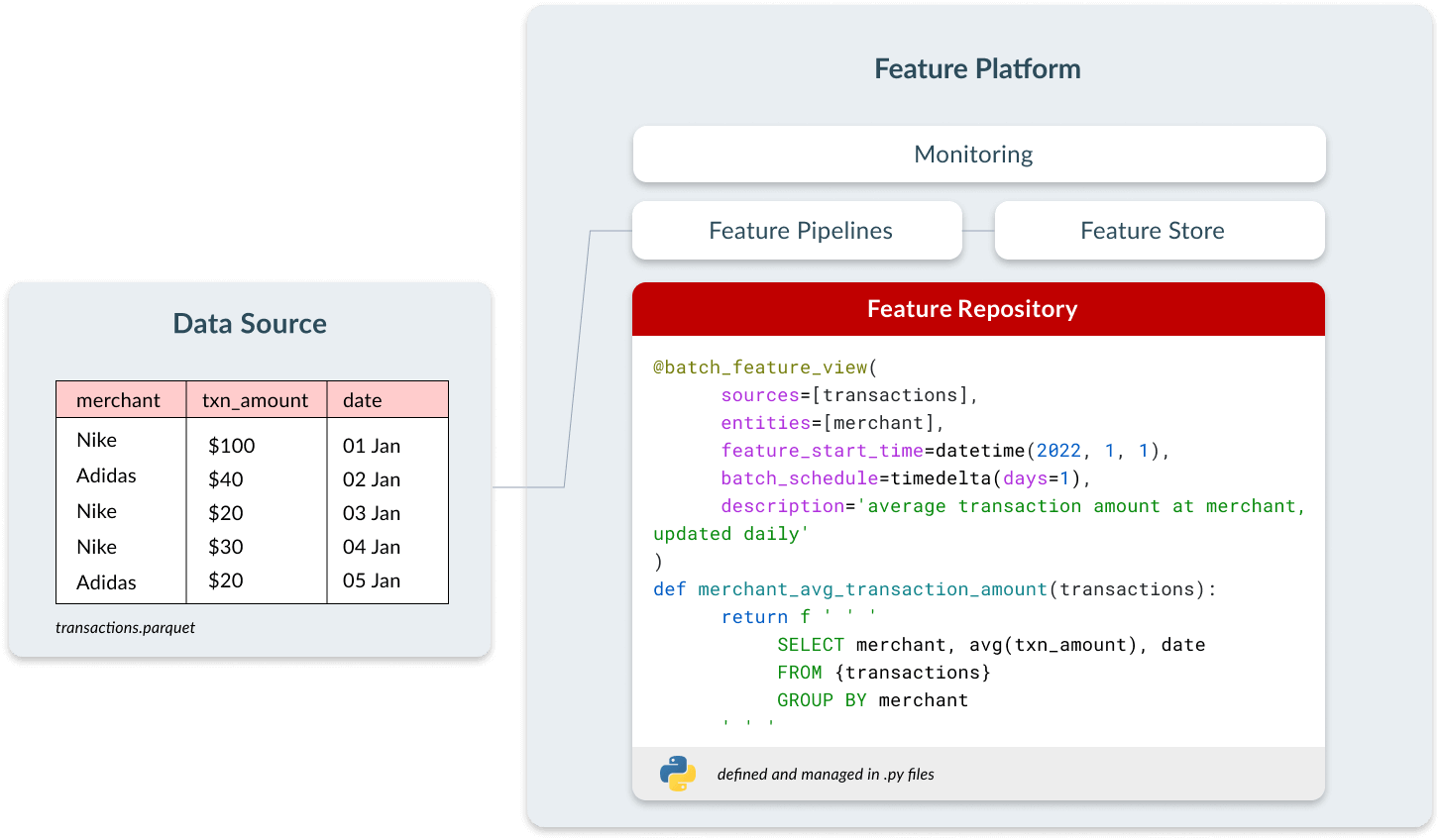
Diese Features stehen dann zentral allen Teams zur Verfügung, um sie zu entdecken und in ihren eigenen Modellen zu verwenden. Das spart Entwicklungszeit, schafft teamübergreifende Konsistenz und spart Rechenkosten, da Features nicht mehrmals für verschiedene Anwendungsfälle berechnet werden müssen.
Feature-Pipelines
Operative Machine-Learning-Anwendungen erfordern eine kontinuierliche Verarbeitung neuer Daten, damit Modelle Vorhersagen auf der Grundlage einer aktuellen Weltansicht treffen können. Sobald ein Benutzer das Feature im Repository definiert hat, verarbeitet die Feature-Plattform automatisch die Datenpipelines, um dieses Feature zu computen.
Es gibt drei Arten von Datentransformationen, die eine Feature-Plattform unterstützen muss:
| Transformation | Definition | Datenquelle | Beispiel |
|---|---|---|---|
| Batch | Transformationen, die nur auf Data at Rest angewendet werden | Data Warehouse, Data Lake, Datenbank | Durchschnittlicher Transaktionsbetrag pro Händler, täglich aktualisiert |
| Streaming | Transformationen, die auf Streaming-Quellen angewendet werden | Kafka, Kinesis, PubSub, Flink | Anzahl der Transaktionen eines Nutzers in den letzten 30 Minuten, jede Sekunde aktualisiert |
| On-demand | Transformationen, die zur Erzeugung von Features auf der Grundlage von Daten verwendet werden, die nur zum Zeitpunkt der Vorhersage verfügbar sind. Diese Features können nicht vorberechnet werden. | Benutzerorientierte Anwendung, APIs für RPC-Dienste, In-Memory-Daten | Ist der aktuelle Transaktionsbetrag mehr als zwei Standardabweichungen höher als der durchschnittliche Transaktionsbetrag des Nutzers, berechnet zum Zeitpunkt der Transaktion |
Diese Transformationen werden auf Datenverarbeitungs-Engines (Spark, Snowflake, Python) ausgeführt, mit denen die Feature-Plattform verbunden ist. Die Feature-Plattform übergibt den benutzerdefinierten Transformationscode 1:1 an die zugrunde liegende Datenverarbeitungs-Engine. Das bedeutet, dass die Feature-Plattform keinen eigenen benutzerdefinierten SQL-Dialekt oder keine eigene benutzerdefinierte Python-DSL haben sollte. Dies vereinfacht sowohl das Onboarding auf die Feature-Plattform als auch das Debugging.
Batch-Transformationen sind einfach auszuführen – sie können durch eine SQL-Abfrage an ein Data Warehouse oder durch die Ausführung eines Spark-Jobs ausgeführt werden. Operative ML-Anwendungen profitieren jedoch am meisten von aktuellen Informationen, auf die nur durch Streaming und On-Demand-Transformationen zugegriffen werden kann. Im Beispiel der Betrugserkennung enthalten die Features, die dem Modell die beste Vorhersage ermöglichen, Informationen über die aktuelle Transaktion, wie z. B. Betrag, Händler und Standort, oder Informationen über Transaktionen, die innerhalb der letzten Minuten stattgefunden haben.
Jedes Team, mit dem wir sprechen, ist sich einig, dass der Zugriff auf aktuelle Daten die Performance der meisten ihrer Modelle verbessern würde. Die meisten Unternehmen verwenden immer noch nur Batch-Transformationen, weil die Verwaltung von Streaming- und On-Demand-Transformationen komplex ist. Eine Feature-Plattform abstrahiert diese Komplexität und ermöglicht es einem Benutzer, die Transformationslogik zu definieren und auszuwählen, ob sie als Batch-, Streaming- oder On-Demand-Transformation ausgeführt werden soll.
Wenn in der Entwicklungsphase an neuen Features iteriert wird, müssen Daten nachgetragen werden, um Trainingsdatensätze zu generieren. Zum Beispiel könnten wir heute ein neues Feature merchant_fraud_rate entwickeln, das für das gesamte Zeitfenster, für das wir das Modell trainieren möchten, nachgetragen werden muss. Feature-Plattformen führen diese Transformationen bei der Definition neuer Features automatisch aus und ermöglichen so schnelle Iterationszyklen im Entwicklungsprozess.

Feature-Store
Feature-Stores haben zunehmend an Beliebtheit gewonnen, seit wir das Konzept 2017 mit Uber Michelangelo erstmals eingeführt haben. Sie dienen zwei Zwecken: Features über Offline-Trainings- und Online-Inferenzumgebungen hinweg konsistent zu speichern und bereitzustellen.
Wenn Features nicht konsistent in beiden Umgebungen gespeichert werden, können die Features, mit denen das Modell trainiert wird, subtile Unterschiede zu den Features aufweisen, die es für die Online-Inferenz verwendet. Dieses Phänomen wird als Train-Serve-Skew bezeichnet und kann die Performance eines Modells auf stille und katastrophale Weise beeinträchtigen, was extrem schwer zu debuggen ist. Ein Feature Store löst dieses Problem, indem er für konsistente Daten in beiden Umgebungen sorgt.
Für das Offline-Training müssen Feature-Stores Daten von mehreren Monaten oder Jahren enthalten. Diese werden in Data Warehouses oder Data Lakes wie S3, BigQuery, Snowflake oder Redshift gespeichert. Diese Datenquellen sind für den Abruf großer Datenmengen optimiert.
Für die Online-Inferenz müssen Anwendungen extrem schnellen Zugriff auf kleine Datenmengen haben. Um Lookups mit geringer Latenz zu ermöglichen, werden diese Daten in einem Online-Store wie DynamoDB, Redis oder Cassandra gespeichert. Nur die neuesten Feature-Werte für jede Entität werden im Online-Store aufbewahrt.

Um Daten offline abzurufen, wird üblicherweise über ein Notebook-freundliches SDK auf Feature-Werte zugegriffen. Für die Online-Inferenz liefert ein Feature Store einen einzelnen Vektor von Features, der die aktuellsten Daten enthält. Obwohl die Datenmenge bei jeder dieser Anfragen klein ist, muss ein Feature Store für Tausende von Anfragen pro Sekunde skalierbar sein. Diese Antworten werden über einen REST-Endpunkt in Millisekunden für Live-Anwendungen bereitgestellt. Leistungsstarke Feature Stores müssen SLAs für Verfügbarkeit und Latenz bereitstellen.

Monitoring
Wenn in einem operativen ML-System etwas schief geht, handelt es sich normalerweise um ein Datenproblem. Da Feature-Plattformen den Prozess von den Rohdaten bis zu den Modellen verwalten, sind sie bestens dafür geeignet, Datenprobleme zu erkennen. Es gibt zwei Arten von Monitoring, die von Feature-Plattformen unterstützt werden:
Überwachung der Datenqualität
Feature-Plattformen können die Verteilung und Qualität der eingehenden Daten nachverfolgen. Gibt es signifikante Verschiebungen in der Datenverteilung, seit wir das Modell das letzte Mal trainiert haben? Treten plötzlich mehr fehlende Werte auf? Wirkt sich das auf die Performance des Modells aus?
Operatives Monitoring
Beim Betrieb von Produktionssystemen ist es auch wichtig, die operativen Metriken zu überwachen. Merkmalsplattformen verfolgen die Veralterung von Features, um zu erkennen, wenn Daten nicht mit der erwarteten Rate aktualisiert werden, zusammen mit anderen Metriken zur Feature-Speicherung (Verfügbarkeit, Kapazität, Auslastung) und zur feature serving (Durchsatz, Latenz, Abfragen pro Sekunde, Fehlerraten). Eine Feature-Plattform überwacht auch, dass Feature-Pipelines ihre Jobs wie erwartet ausführen, erkennt, wenn Jobs nicht erfolgreich sind, und behebt Probleme automatisch.
Feature-Plattformen stellen diese Metriken der bestehenden Monitoring-Infrastruktur zur Verfügung. Operative ML-Anwendungen müssen wie alle anderen Produktionsanwendungen nachverfolgt werden, die mit bestehenden Observability-Tools verwaltet werden.
Zusammenführung
Ein Teil der Magie einer Feature-Plattform besteht darin, dass sie es ML-Teams ermöglicht, neue Features schnell in Produktion zu bringen. Zu einer wahren Wert-Explosion kommt es jedoch, wenn die Feature-Plattform von mehreren Teams genutzt wird und mehrere Anwendungsfälle unterstützt.

Eine Feature-Plattform ermöglicht es Data Engineers, eine größere Anzahl von Data Scientists zu unterstützen, als sie es sonst könnten. Wir haben mit vielen Teams gesprochen, die 2 Data Engineer brauchten, um 1 Data Scientist ohne eine Feature-Plattform zu unterstützen. Eine Feature-Plattform ermöglichte es ihnen, dieses Verhältnis mehr als umzukehren. Sobald eine Feature-Plattform umfassend eingeführt wurde, können Data Scientists bereits berechnete Features einfach in ihre Modelle einfügen. Wir haben immer wieder dasselbe Muster beobachtet: Teams benötigen einige Monate für die vollständige Bereitstellung ihres ersten Anwendungsfalls, einige Wochen für den zweiten und danach nur noch wenige Tage, um neue Anwendungsfälle bereitzustellen oder bestehende zu überarbeiten.
Wann eine Feature-Plattform eingeführt werden sollte (und wann nicht)
Ich habe diesen Artikel damit begonnen zu beschreiben, wie schwierig es ist, mit dem gesamten Ökosystem von MLOps-Tools, das in den letzten Jahren entstanden ist, Schritt zu halten. In Wirklichkeit sollten Sie Ihren Stack so einfach wie möglich halten und Tools nur dann einsetzen, wenn sie wirklich notwendig sind.
Wir stellen fest, dass Teams von einer Feature-Plattform profitieren, wenn sie:
- Erfahrung mit dem Übergabeprozess zwischen Data Scientists und Data Engineers und den damit verbundenen Schwierigkeiten bei der Neuimplementierung von Datenpipelines für die Produktion.
- Bereitstellung operativer Machine-Learning-Anwendungen, die strenge SLAs erfüllen, Scale erreichen und in der Produktion nicht ausfallen dürfen.
- Mehrere Teams möchten standardisierte Feature-Definitionen haben und Features modellübergreifend wiederverwenden.
Teams sollten die Einführung einer Feature-Plattform vermeiden, wenn sie:
- Befinden sich in der Konzeptions- oder Entwicklungsphase und sind nicht bereit für die Überführung in die Produktion.
- Nur ein einziges Team, das ausschließlich mit Batch-Daten arbeitet.
Erste Schritte
Für den Start gibt es mehrere Möglichkeiten:
- Tecton ist eine verwaltete Feature-Plattform. Es umfasst alle oben beschriebenen Komponenten, und unsere Kunden entscheiden sich für Tecton, weil sie produktionsreife SLAs und Unternehmensfunktionen benötigen, ohne die Lösung selbst verwalten zu müssen. Tecton wird von ML-Teams genutzt, die von Tech-Startups bis hin zu mehreren Fortune-500-Unternehmen reichen.
- Feast ist der beliebteste Open-Source- Feature-Store. Es ist eine großartige Option, wenn Sie bereits über Transformations-Pipelines zum Compute Ihrer Features verfügen und diese Features in der Produktion speichern und bereitstellen möchten. Mit der Zeit wird Feast weiterhin Feature-Pipeline- und Monitoring-Funktionen hinzufügen, was es zu einer vollständigen Feature-Plattform macht.
Ich habe diesen Blogpost geschrieben, um eine einheitliche Definition für Feature-Plattformen zu liefern, da sie sich mittlerweile als Kernkomponente des Stacks für operative Machine-Learning-Anwendungen etabliert haben.
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.