Produktions-ETL mit Lakeflow-Declarative-Pipelines erstellen
Diese Architektur für moderne Analysen und KI bietet eine skalierbare Basis zur Erstellung und Automatisierung von ETL-Pipelines für Batch- und Streaming-Daten.
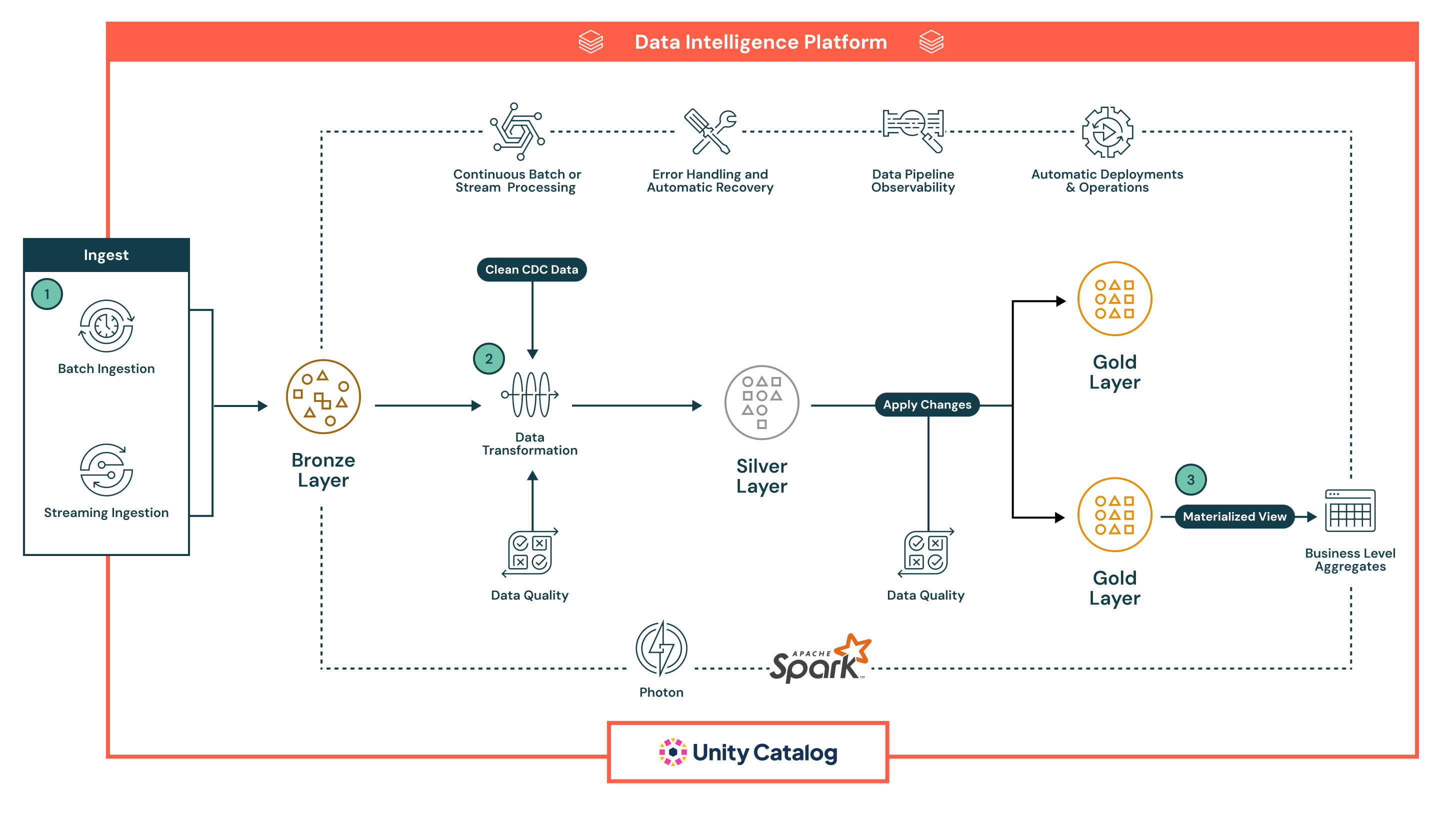
Zusammenfassung der Architektur
Diese Referenzarchitektur eignet sich gut für Organisationen, die Batch- und Streaming-Pipelines unter einem einzigen deklarativen Framework vereinen möchten, während sie die Datenzuverlässigkeit, -qualität und -governance auf jeder Stufe gewährleisten. Sie nutzt die Databricks Data Intelligence Plattform, um die Pipeline-Verwaltung zu vereinfachen, Datenanforderungen durchzusetzen und Echtzeit-Einblicke mit eingebauter Beobachtbarkeit und Automatisierung zu liefern.
Sie unterstützt eine breite Palette von Datenengineering- und Analyse-Szenarien, von der Datenaufnahme und -transformation bis hin zu komplexen Workflows mit Echtzeit-Qualitätschecks, Geschäftslogik und automatischer Wiederherstellung. Organisationen, die diese Architektur übernehmen, streben oft danach, veraltete ETL zu modernisieren, den Betriebsaufwand zu reduzieren und die Bereitstellung von kuratierten, hochwertigen Daten für Business Intelligence, maschinelles Lernen und operative Anwendungen zu beschleunigen.
Technischer Anwendungsfall
- Diese Architektur ermöglicht Change Data Capture (CDC) Pipelines, die inkrementell Updates von Quellsystemen in das Lakehouse einpflegen
- Daten-Ingenieure können langsam wechselnde Dimensionen (SCD) Muster erstellen, um dimensionale Modelle in Analyseebenen zu verwalten
- Streaming-Pipelines können widerstandsfähig gebaut werden, um außerhalb der Reihenfolge liegende Ereignisse und verspätet eintreffende Daten mit Wasserzeichen und Checkpoints zu verarbeiten.
- Daten-Ingenieure können Schema-Evolution und automatisierte Qualitätsregeln mit deklarativen Einschränkungen durchsetzen
- Dateningenieure können die Nachverfolgung der Datenherkunft und die Protokollierung von Audits über die gesamte Pipeline automatisieren, ohne manuelle Instrumentierung
Geschäftliche Anwendungsfälle
- Einzelhandels- und Konsumgüterunternehmen (CPG) können diese Architektur nutzen, um Echtzeit-Dashboards zu erstellen, die Verkäufe, Lagerbestände und Kundenverhalten über mehrere Kanäle verfolgen
- Durch die Integration von Daten aus Transaktionen, digitalen Interaktionen und CRM-Systemen können Finanzinstitute Betrugserkennung und Kundensegmentierung unterstützen
- Gesundheitsorganisationen können medizinische Gerätedaten und Patientenakten verarbeiten und normalisieren, um klinische Erkenntnisse und Compliance-Berichte zu erstellen
- Hersteller können IoT-Sensordaten mit historischen Logs kombinieren, um vorausschauende Wartung und Optimierung der Lieferkette zu ermöglichen
- Telekommunikationsanbieter können CRM- und Netzwerk-Telemetriedaten vereinheitlichen, um Kundenabwanderung und Nutzungsverhalten in nahezu Echtzeit zu modellieren
Schlüsselkompetenzen
- Entwicklung von deklarativen Pipelines: Definieren Sie Pipelines mit SQL oder Python und abstrahieren Sie die Orchestrierungslogik
- Unterstützung für Batch- und Streaming: Behandeln Sie sowohl Echtzeit- als auch geplante Workloads in einem einheitlichen Framework
- Durchsetzung der Datenqualität: Wenden Sie Erwartungen direkt in der Pipeline an, um schlechte Daten zu erkennen, zu blockieren oder in Quarantäne zu setzen
- Beobachtbarkeit und Herkunft: Integriertes Monitoring, Alarme und visuelles Tracking der Datenherkunft verbessern Transparenz und Fehlerbehebung
- Fehlerbehandlung und Wiederherstellung: Automatische Erkennung und Wiederherstellung von Fehlern in jeder Phase der Pipeline
- Governance mit Unity Catalog: Durchsetzung von feingranularen Zugriffskontrollen, Audit der Datennutzung und Aufrechterhaltung der Datenklassifizierung über den gesamten Stack
- Optimierte Ausführung: Nutzen Sie Spark und Photon unter der Haube für skalierbare, leistungsstarke Verarbeitung
- Automatisierte Abläufe: Pipelines können versioniert, bereitgestellt und über CI/CD verwaltet werden, mit Unterstützung für Planung und Parametrisierung
Datenfluss
Die Architektur folgt einer robusten, mehrschichtigen Medaillon-Architektur, die durch die eingebauten Fähigkeiten der Lakeflow's Declarative Pipelines für Automatisierung, Governance und Zuverlässigkeit verbessert wird. Jede Phase der Pipeline ist deklarativ, beobachtbar und sowohl für Batch- als auch für Streaming-Anwendungsfälle optimiert:
- Lakeflows Deklarative Pipelines unterstützen sowohl Batch als auch Streaming Ingestion und bieten eine einheitliche und automatisierte Möglichkeit, Daten in das Lakehouse zu bringen.
- Batch-Eingabe lädt Daten nach einem Zeitplan oder Auslöser, ideal für periodische ETL-Workflows. Es unterstützt vollständige und inkrementelle Ladungen aus Cloud-Speicher und Datenbanken. Im Gegensatz zu traditionellen Tools verwaltet Declarative die Orchestrierung, Wiederholungen und Schemaevolution nativ, wodurch die Notwendigkeit für externe Planer oder Skripte reduziert wird.
- Streaming-Ingestion verarbeitet kontinuierlich Daten von Quellen wie Kafka und Event Hubs mit Structured Streaming. Declarative Pipelines kümmert sich um Checkpointing, Zustandsverwaltung und automatische Skalierung, was die manuelle Konfiguration, die normalerweise in Streaming-Pipelines erforderlich ist, überflüssig macht.
Alle Daten landen zuerst in der Bronze-Schicht in roher Form, was eine vollständige Herkunft, Nachverfolgbarkeit und sichere Wiederbearbeitung ermöglicht. Die deklarative Herangehensweise der Pipelines, eingebaute Qualitätskontrollen und automatische Infrastrukturverwaltung reduzieren die betriebliche Komplexität erheblich und erleichtern den Aufbau von widerstandsfähigen, produktionsreifen Pipelines — etwas, mit dem die meisten herkömmlichen ETL-Tools nativ zu kämpfen haben.
- Nach der Erfassung können die Daten in der Silber-Schicht verarbeitet werden, wo sie gereinigt, verbunden und angereichert werden, um sie für den nachgelagerten Verbrauch vorzubereiten.
- Pipelines werden mit deklarativen SQL oder Python definiert, was die Transformationen leicht lesbar, wartbar und versionierbar macht. Transformationen werden mit Apache Spark™ mit Photon ausgeführt, was eine skalierbare und leistungsstarke Verarbeitung ermöglicht.
- Datenqualitätsprüfungen werden inline mit Erwartungen, einer nativen Funktion von Declarative Pipelines, angewendet, die es Teams ermöglicht, Validierungsregeln durchzusetzen (z.B. Nullprüfungen, Datentypen, Bereichsgrenzen). Ungültige Daten können so konfiguriert werden, dass sie entweder schlechte Datensätze abwerfen, sie in Quarantäne stellen oder die Pipeline fehlschlagen lassen — dies stellt sicher, dass nachgelagerte Systeme nur vertrauenswürdige Daten erhalten.
- Die Pipeline handhabt automatisch die Verfolgung von Job-Abhängigkeiten, Task-Wiederholungen und Fehlerisolierung, wodurch der Betriebsaufwand reduziert wird. Dies stellt sicher, dass die in der Silber-Schicht verarbeiteten Daten genau, konsistent und produktionsbereit sind — während die betriebliche Einfachheit erhalten bleibt.
- In der Gold-Schicht, erzeugt die Pipeline geschäftsbezogene Aggregatwerte und kuratierte Datensätze, die zum Verbrauch bereit sind.
- Diese Ausgaben sind optimiert für den Einsatz in BI-Dashboards, Machine-Learning-Funktionen und Betriebssystemen.
- Declarative Pipelines unterstützt zeitliche Tabellen und SCD-Logik, was fortgeschrittene Anwendungsfälle wie historisches Tracking und Audit-Berichterstattung ermöglicht
- In allen Schichten bietet Declarative Pipelines reiche Beobachtbarkeit und Pipeline-Herkunft.
- Die Benutzeroberfläche zeigt Datenflussdiagramme, Betriebsmetriken und Qualitäts-Dashboards an, um eine schnelle Fehlerbehebung und Compliance-Berichterstattung zu unterstützen
- Mit der Integration des Unity-Katalogs wird jede Tabelle, jede Spalte und jede Transformation durch zentralisierte Zugriffskontrolle, Audit-Protokollierung und Datenklassifizierung gesteuert.
- Pipelines sind von Design aus produktionsbereit.
- Teams können Declarative Pipelines mit versionskontrollierten Definitionen, planen sie über Lakeflow-Jobs und verwalten sie mit CI/CD-Tools wie GitHub Actions oder Azure DevOps
- Diese Automatisierung ersetzt zerbrechliche Skripting und komplexe Orchestrierungssetups und hilft Datenteams, sich auf die Geschäftslogik statt auf die Infrastruktur zu konzentrieren.
Empfohlen

On-Demand-Video

On-Demand-Video
Produkttour

Branchenarchitektur
