Referenzarchitektur für die Datenaufnahme
Diese Referenzarchitektur für die Datenaufnahme bietet eine vereinfachte, einheitliche und effiziente Grundlage für das Laden von Daten aus verschiedenen Unternehmensquellen in die Databricks Data Intelligence Plattform.
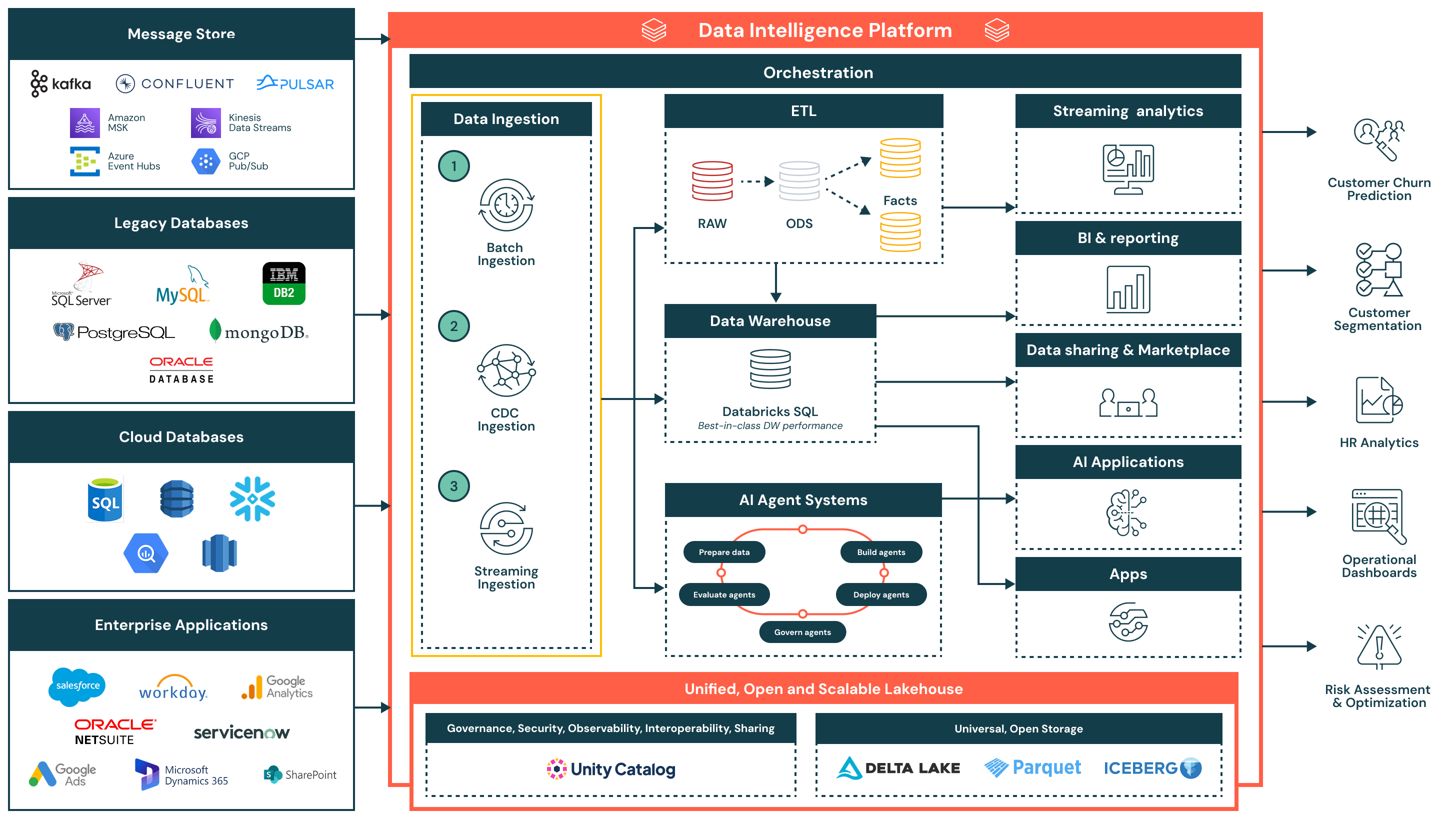
Zusammenfassung der Architektur
Die Referenzarchitektur für die Datenaufnahme unterstützt eine breite Palette von Aufnahmemustern - einschließlich Batch, Change Data Capture (CDC) und Streaming - und gewährleistet dabei Governance, Leistung und Interoperabilität. Nach der Aufnahme werden die Daten verfeinert und für Analysen, KI und sicheres Datenteilen innerhalb der Organisation verfügbar gemacht.
Diese Architektur ist ideal für Organisationen, die ihre Datenpipelines modernisieren und operationalisieren möchten, während sie die Komplexität und den Integrationsaufwand reduzieren. Es basiert auf drei Schlüsselprinzipien:
- Einfach und wartungsarm: Ingestion-Pipelines sind einfach zu erstellen und zu verwalten, was eine schnellere Wertschöpfung, weniger betriebliche Engpässe und einen breiteren Zugang zu Daten über Teams hinweg ermöglicht
- Vereinheitlicht mit der Lakehouse-Architektur: Die Daten fließen direkt in das Lakehouse ein, wobei sie offene Formate verwenden und vom Unity-Katalog gesteuert werden - dies gewährleistet Konsistenz über BI, KI und operative Anwendungsfälle hinweg
- Effizienter End-to-End-Fluss: Von der Ingestion bis zur Transformation und Lieferung unterstützt die Plattform effiziente, inkrementelle Verarbeitung, die Duplizierung, Latenz und Ressourcenverbrauch minimiert
Anwendungsfälle
Technischer Anwendungsfall
- Periodische Batch-Ingestion aus flachen Dateien, Exporten oder APIs in Staging-Zonen
- Change Data Capture (CDC) Aufnahme zur inkrementellen Synchronisation von Updates aus Transaktionssystemen wie Oracle oder PostgreSQL
- Streaming-Aufnahme von Echtzeitereignissen aus Kafka oder Nachrichtenwarteschlangen für den Einsatz in Live-Dashboards oder Alarmierungssystemen
- Harmonisierung der Datenaufnahme über Alt-Systeme, Cloud-native Datenbanken und Enterprise SaaS-Anwendungen
- Fütterung von kuratierten und transformierten Daten in Data Warehouses, AI-Anwendungen und externe APIs
Geschäftliche Anwendungsfälle
- Vorhersage von Kundenabwanderung durch Aufnahme von Verhaltens-, Transaktions- und Supportdaten
- Versorgung von Executive Dashboards mit aktuellen Betriebsmetriken aus ERP- und CRM-Systemen
- Kunden segmentieren durch Kombination von Kampagnen-, Verkaufs- und Produktverwendungsdaten
- Durchführung von HR-Analysen durch Integration von Daten aus Workday und Produktivitätsplattformen
- Durchführung von Risikobewertungen durch Analyse von Transaktionen und Alarmfeeds in nahezu Echtzeit
Ablauf und Schlüsselkompetenzen der Datenaufnahme
- Batch-Ingestion
- Lädt Daten zu geplanten Intervallen oder auf Anfrage aus Quellen wie Flachdateien, APIs oder Datenbankexporten
- Geeignet für tägliche Berichte, historische Datenlasten und System-of-Record-Snapshots
- Unterstützt sowohl vollständige als auch inkrementelle Ladungen, mit nativer Planung, Wiederholungslogik und Transformation mit SQL oder Python
- Datenaufnahme durch Erfassung von Datenänderungen (CDC)
- Erfasst inkrementelle Änderungen von Transaktionssystemen wie Oracle, PostgreSQL und MySQL
- Hält Lakehouse-Tabellen ohne vollständige Neuladungen aktuell, was die Effizienz und Datenaktualität verbessert
- Ermöglicht nahezu Echtzeit-Datensynchronisation für Faktentabellen, Audit-Trails und Berichtsebenen
- Streaming-Ingestion
- Verarbeitet kontinuierlich Daten von Ereignisquellen wie Kafka, Kinesis, Pub/Sub oder Event Hubs
- Ideal für Echtzeit-Dashboards, Alarmierungssysteme und Anomalieerkennung
- Strukturiertes Streaming verwaltet Zustand, Fehlertoleranz und Durchsatz, wodurch der Betriebsaufwand reduziert wird
Zusätzliche Plattformfähigkeiten
- Einheitliche Governance
- Unity Katalog bietet einheitliche Governance, einschließlich Zugriffskontrolle, Herkunftsnachweis und Audit-Tracking
- Daten werden in offenen, interoperablen Formaten gespeichert mit Delta Lake und Apache Iceberg™, was Flexibilität und Interoperabilität über Tools und Umgebungen hinweg gewährleistet
- Eine zentralisierte Orchestrierungsschicht verwaltet die Pipeline-Planung, Abhängigkeiten, Überwachung und Wiederherstellung
- Lakehouse-Architektur: Eingehende Daten werden transformiert und in die Medaillon-Architektur (Bronze, Silber und Gold) modelliert, was leistungsstarke Abfragen in Databricks SQLermöglicht
- Orchestrierung: Die eingebaute Orchestrierung verwaltet Datenpipelines, KI-Workflows und geplante Jobs über Batch- und Streaming-Workloads hinweg, mit nativer Unterstützung für Abhängigkeitsmanagement und Fehlerbehandlung
- KI und Agentensysteme: Daten fließen in Agentensysteme ein, um Merkmale vorzubereiten, Modelle zu bewerten und KI-gestützte Anwendungen zu implementieren
- Downstream-Konsum:
- Streaming-Analytik: Echtzeit-Visualisierung von Schlüsselmetriken und Betriebssignalen
- BI/Analytik: Kuratierte Datensätze, die Tools wie Power BI, Lakeview und SQL-Clients zur Verfügung gestellt werden
- AI-Anwendungen: Regulierte Datensätze, die von Trainingspipelines und Inferenzmotoren verbraucht werden
- Datenaustausch und Marktplatz: Sicherer interner und externer Datenaustausch über Delta Sharing
- Betriebsanwendungen: Eingebettete Intelligenz und kontextbezogene Einblicke in Unternehmenswerkzeuge
Empfohlen

Referenzarchitektur

Referenzarchitektur

Branchenarchitektur

Branchenarchitektur
Referenzarchitektur