Présentation d'Apache Spark 3.0
Désormais disponible dans Databricks Runtime 7.0
par Matei Zaharia, Reynold Xin, Xiao Li, Wenchen Fan et Yin Huai
Nous sommes ravis d'annoncer que la version Apache SparkTM 3.0.0 est disponible sur Databricks dans le cadre de notre nouveau Databricks Runtime 7.0. La 3.0.0 Cette version inclut plus de 3 400 correctifs et constitue l'aboutissement de contributions considérables de la part de la communauté open source, apportant des avancées majeures aux fonctionnalités Python et SQL et mettant l'accent sur la facilité d'utilisation, tant pour l'exploration que pour la production. Ces initiatives reflètent l'évolution du projet pour répondre à davantage de cas d'utilisation et à un public plus large, cette année marquant son 10e anniversaire en tant que projet open source.
Voici les principales nouvelles fonctionnalités de Spark 3.0 :
- Performances 2x supérieures sur TPC-DS par rapport à Spark 2.4, grâce à l'exécution adaptative des requêtes, l'élagage dynamique des partitions et d'autres optimisations
- Conformité ANSI SQL
- Améliorations significatives des API pandas, notamment les indicateurs de type Python et des UDF pandas supplémentaires
- Meilleure gestion des erreurs Python, simplification des exceptions PySpark
- Nouvelle interface utilisateur pour le streaming structuré
- Accélérations jusqu'à 40x pour l'appel de fonctions R définies par l'utilisateur
- Plus de 3 400 tickets Jira résolus
Aucune modification majeure du code n'est requise pour adopter cette version d'Apache Spark. Pour plus d'informations, veuillez consulter le guide de migration.
Célébration des 10 ans de développement et d'évolution de Spark
Spark a été créé au sein de l'AMPlab de l'UC Berkeley, un laboratoire de recherche spécialisé dans l'informatique à haute intensité de données. Les chercheurs de l'AMPlab collaboraient avec de grandes entreprises de l'internet sur leurs problématiques de données et d'IA, mais ont constaté que ces mêmes problèmes seraient également rencontrés par toutes les entreprises disposant de volumes de données importants et croissants. L'équipe a développé un nouveau moteur pour gérer ces nouvelles charges de travail et rendre simultanément les APIs de traitement du Big Data nettement plus accessibles aux développeurs.
Les contributions de la communauté ont rapidement permis d'étendre Spark à différents domaines, avec de nouvelles fonctionnalités autour du streaming, de Python et de SQL. Ces modèles constituent désormais certains des cas d'utilisation dominants de Spark. Cet investissement continu a permis à Spark de devenir ce qu'il est aujourd'hui, à savoir le moteur de facto pour les charges de travail de traitement des données, de Data Science, de machine learning et d'analytique de données. Apache Spark 3.0 poursuit cette tendance en améliorant considérablement la prise en charge de SQL et de Python -- les deux langages les plus utilisés avec Spark aujourd'hui -- ainsi que par des optimisations des performances et de l'opérabilité dans le reste de Spark.
Amélioration du moteur Spark SQL
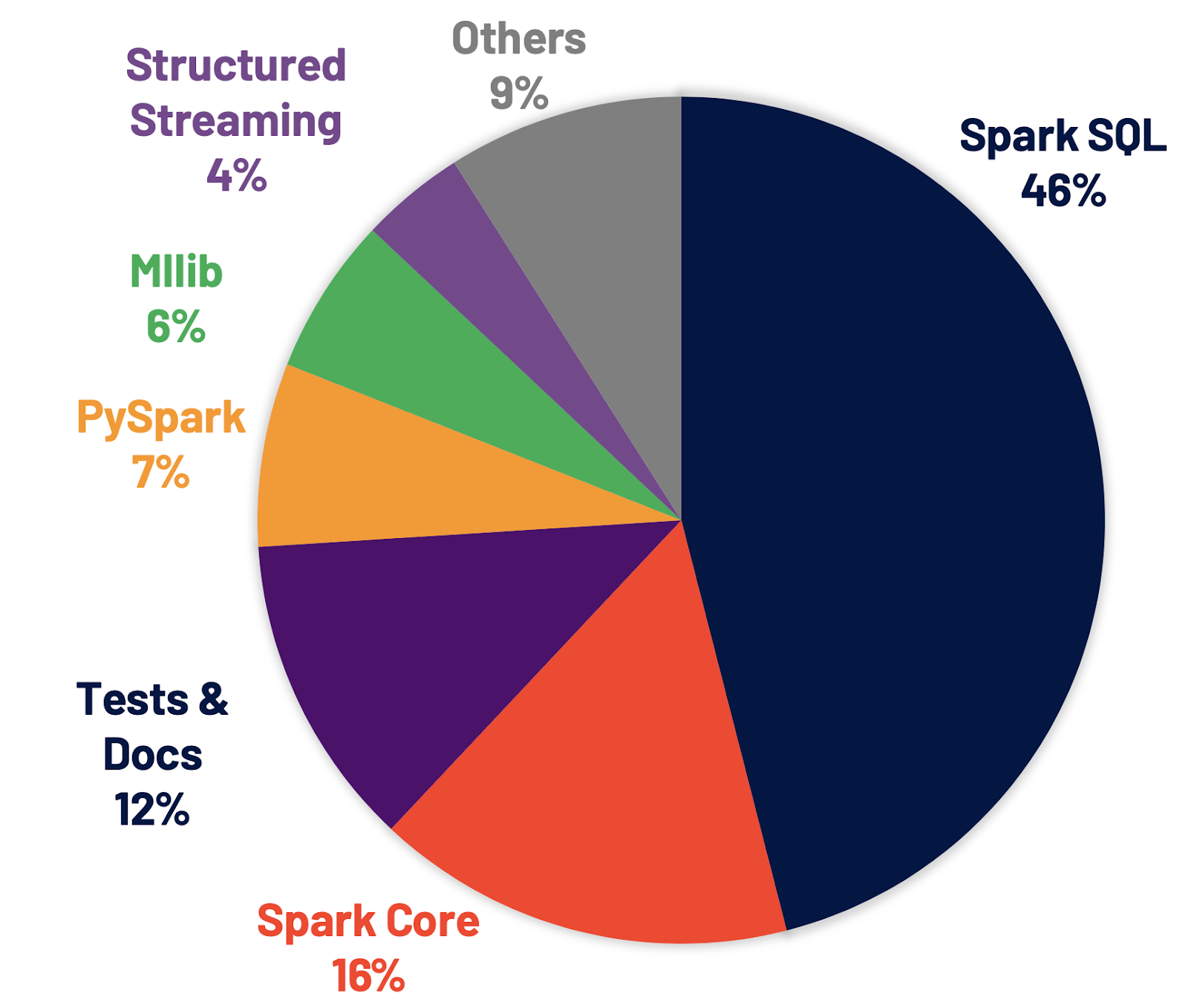
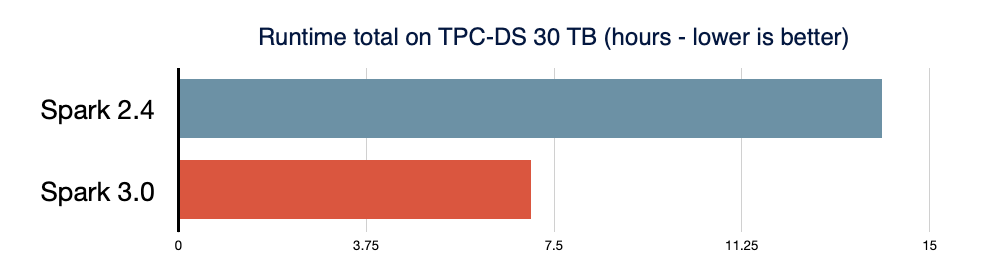
Spark SQL est le moteur qui sous-tend la plupart des applications Spark. Par exemple, sur Databricks, nous avons constaté que plus de 90 % des appels d'API Spark utilisent les API DataFrame, dataset et SQL ainsi que d'autres bibliothèques optimisées par l'optimiseur SQL. Cela signifie que même les développeurs Python et Scala font passer une grande partie de leur travail par le moteur Spark SQL. Dans la version Spark 3.0, 46 % de tous les correctifs contribués concernaient SQL, améliorant à la fois les performances et la compatibilité ANSI. Comme illustré ci-dessous, Spark 3.0 a obtenu des performances environ 2 fois meilleures que Spark 2.4 en termes de temps d'exécution total. Ensuite, nous expliquons quatre nouvelles fonctionnalités dans le moteur Spark SQL.
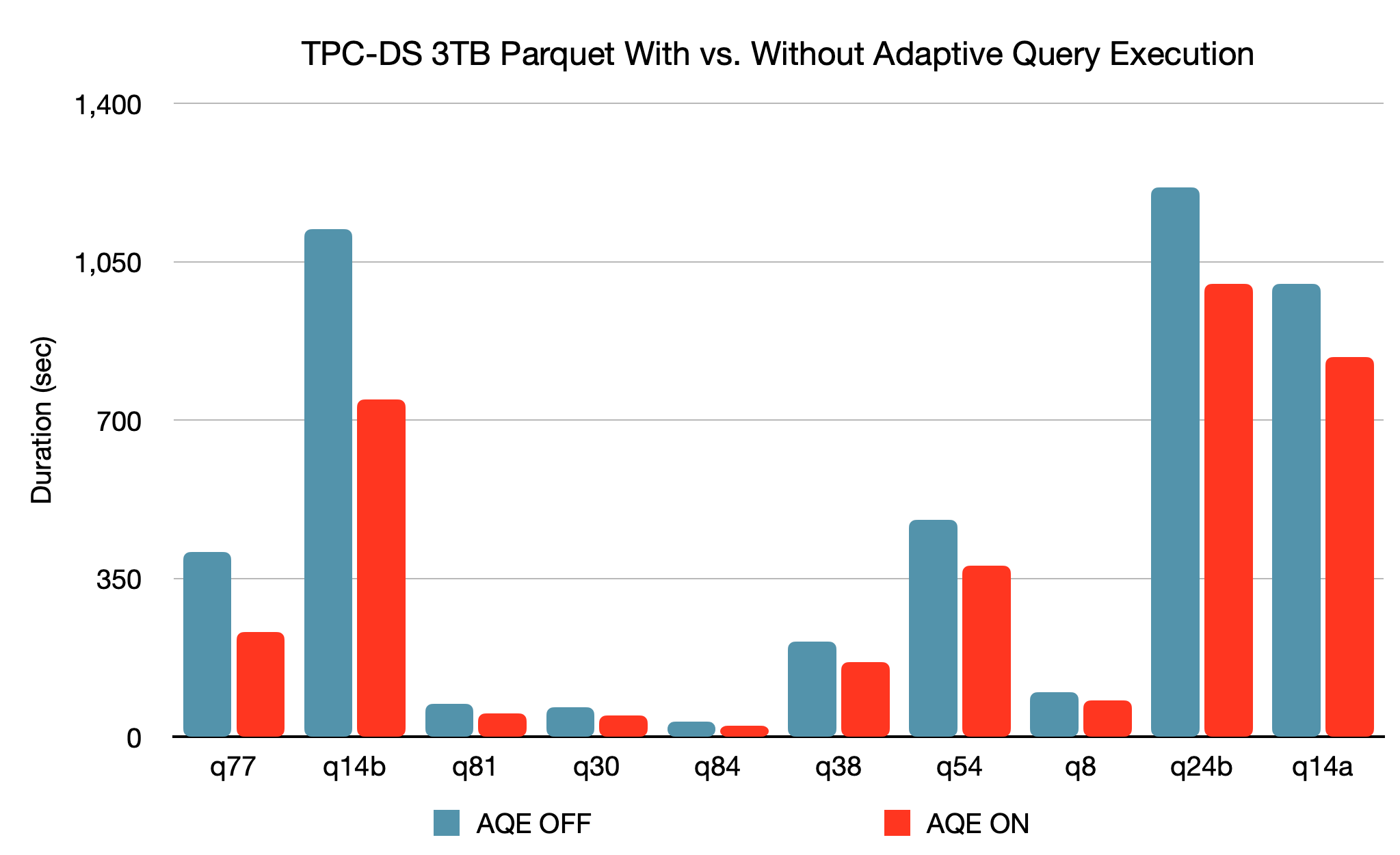
Le nouveau framework Adaptive Query Execution (AQE) améliore les performances et simplifie l'optimisation en générant un meilleur plan d'exécution au moment de l'exécution, même si le plan initial n'est pas optimal en raison de statistiques de données absentes ou inexactes et de coûts mal estimés. En raison de la séparation du stockage et du compute dans Spark, l'arrivée des données peut être imprévisible. Pour toutes ces raisons, l'adaptabilité au moment de l'exécution devient plus essentielle pour Spark que pour les systèmes traditionnels. Cette version introduit trois optimisations adaptatives majeures :
- La fusion dynamique des partitions de shuffle simplifie, voire évite, l'ajustement du nombre de partitions de shuffle. Les utilisateurs peuvent définir un nombre relativement élevé de partitions de shuffle au début, et AQE peut ensuite combiner les petites partitions adjacentes en partitions plus grandes à l'exécution.
- Le changement dynamique des stratégies de jointure évite partiellement l'exécution de plans sous-optimaux en raison de statistiques manquantes et/ou d'une mauvaise estimation de la taille. Cette optimisation adaptative peut convertir automatiquement une jointure sort-merge en jointure broadcast-hash au moment de l'exécution, ce qui simplifie encore le réglage et améliore les performances.
- L'optimisation dynamique des jointures asymétriques est une autre amélioration essentielle des performances, car les jointures asymétriques peuvent entraîner un déséquilibre extrême de la charge de travail et dégrader considérablement les performances. Une fois que l'AQE a détecté une asymétrie à partir des statistiques du fichier de shuffle, il peut diviser les partitions asymétriques en partitions plus petites et les joindre aux partitions correspondantes de l'autre côté. Cette optimisation peut paralléliser le traitement de l'asymétrie et obtenir de meilleures performances globales.
D'après un benchmark TPC-DS de 3 To, par rapport à une exécution sans AQE, Spark avec AQE peut améliorer les performances de plus de 1,5x pour deux requêtes et de plus de 1,1x pour 37 autres requêtes.
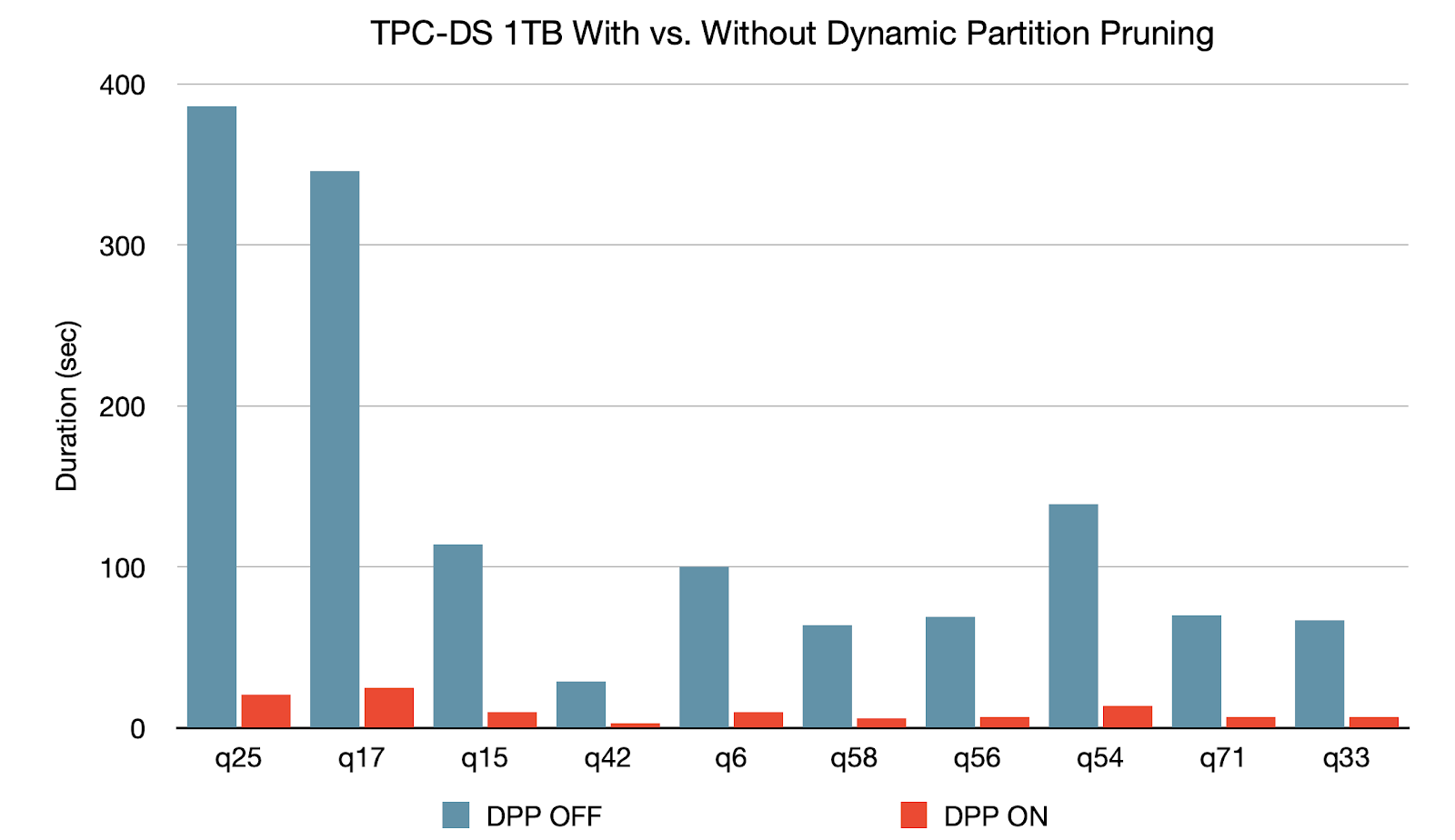
L'élagage dynamique des partitions est appliqué lorsque l'optimiseur n'est pas en mesure d'identifier au moment de la compilation les partitions qu'il peut ignorer. Ce n'est pas rare dans les schémas en étoile, qui se composent d'une ou plusieurs tables de faits référençant un certain nombre de tables de dimension. Dans de telles opérations de jointure, nous pouvons élaguer les partitions que la jointure lit à partir d'une table de faits, en identifiant les partitions qui résultent du filtrage des tables de dimension. Dans un benchmark TPC-DS, 60 des 102 requêtes affichent une accélération significative entre 2x et 18x.
La conformité à la norme ANSI SQL est essentielle pour la migration des charges de travail d'autres moteurs SQL vers Spark SQL. Pour améliorer la conformité, cette version passe au calendrier grégorien proleptique et permet également aux utilisateurs d'interdire l'utilisation des mots-clés réservés d'ANSI SQL comme identifiants. De plus, nous avons introduit la vérification du dépassement de capacité à l'exécution dans les opérations numériques et l'application du typage au moment de la compilation lors de l'insertion de données dans une table avec un schéma prédéfini. Ces nouvelles validations améliorent la qualité des données.
Indications de jointure: Bien que nous continuions à améliorer le compilateur, rien ne garantit qu'il puisse toujours prendre la décision optimale dans toutes les situations — la sélection de l'algorithme de jointure est basée sur des statistiques et des heuristiques. Lorsque le compilateur est incapable de faire le meilleur choix, les utilisateurs peuvent utiliser des indications de jointure pour influencer l'optimiseur afin qu'il choisisse un meilleur plan. Cette version étend les indicateurs de jointure existants en ajoutant de nouveaux indicateurs : SHUFFLE_MERGE, SHUFFLE_HASH et SHUFFLE_REPLICATE_NL.
Python est aujourd'hui le langage le plus utilisé sur Spark et, par conséquent, a été un axe de développement majeur pour Spark 3.0. 68 % des commandes de notebook sur Databricks sont en Python. PySpark, l'API Python d'Apache Spark, enregistre plus de 5 millions de downloads mensuels sur PyPI, le Python package Index.
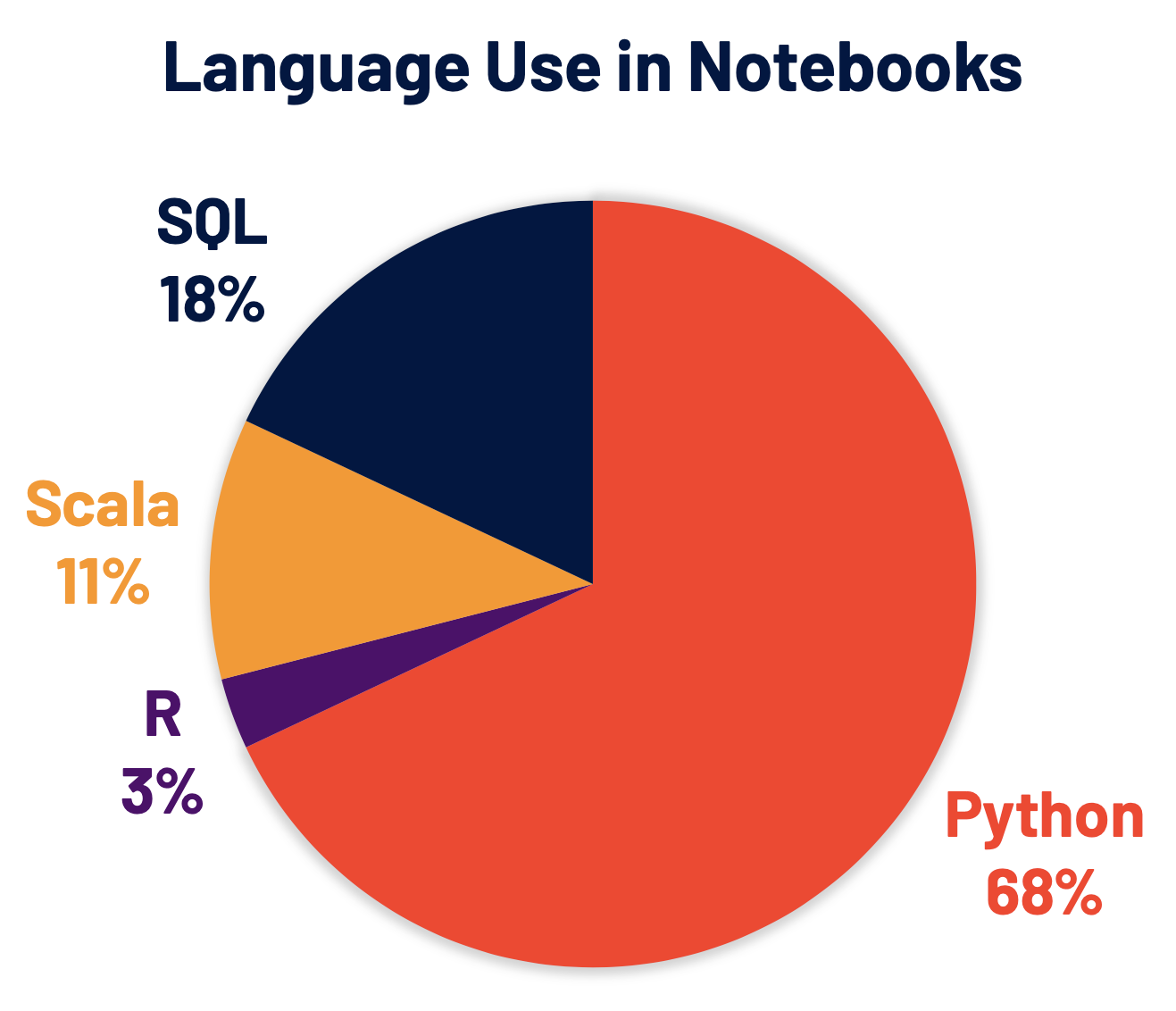
De nombreux développeurs Python utilisent l'API pandas pour les structures de données et l'analyse de données, mais elle est limitée au traitement sur un seul nœud. Nous avons également continué à développer Koalas, une implémentation de l'API pandas sur Apache Spark, pour rendre les data scientists plus productifs lorsqu'ils travaillent avec le big data dans des environnements distribués. Koalas élimine le besoin de créer de nombreuses fonctions (par ex., la prise en charge du traçage) dans PySpark, pour atteindre des performances efficaces sur un cluster.
Après plus d'un an de développement, la couverture de l'API Koalas pour pandas est proche de 80 %. Le nombre de téléchargements mensuels de Koalas sur PyPI a rapidement atteint 850 000, et Koalas évolue rapidement avec un rythme de publication toutes les deux semaines. Bien que Koalas soit peut-être le moyen le plus simple de migrer votre code pandas mono-nœud, beaucoup utilisent encore les API PySpark, qui gagnent également en popularité.
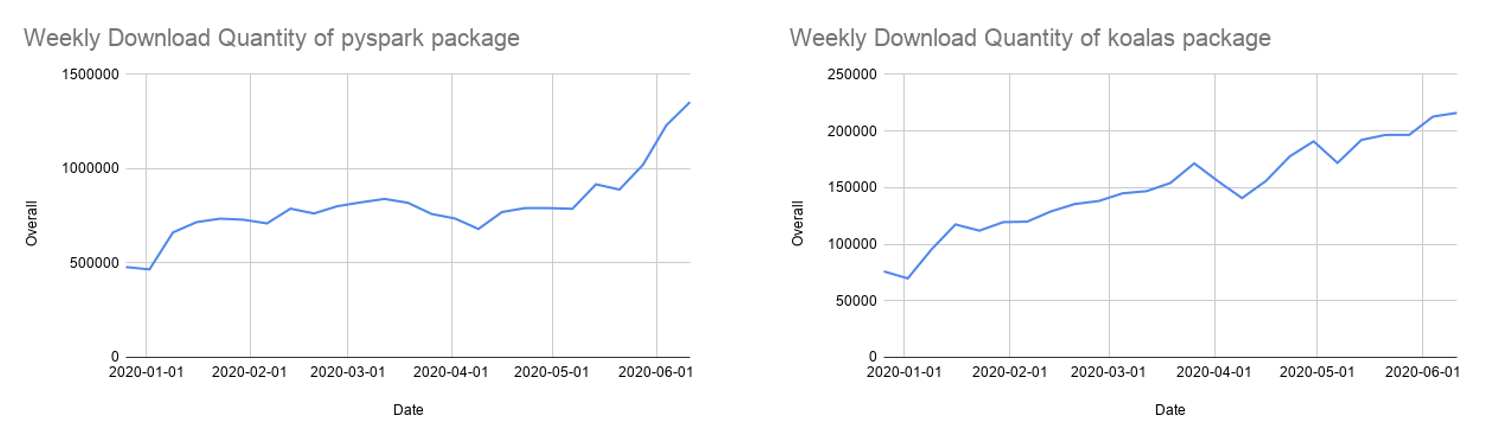
Spark 3.0 apporte plusieurs améliorations aux APIs PySpark :
- Nouvelles API pandas avec indicateurs de type : les UDF pandas ont été initialement introduites dans Spark 2.3 pour faire évoluer les fonctions définies par l'utilisateur dans PySpark et intégrer les API pandas dans les applications PySpark. Cependant, l'interface existante est difficile à comprendre lorsque d'autres types d'UDF sont ajoutés. Cette version introduit une nouvelle interface UDF pandas qui exploite les indicateurs de type Python pour répondre à la prolifération des types d'UDF pandas. La nouvelle interface devient plus pythonique et autodescriptive.
- Nouveaux types de fonctions UDF pandas et d'API de fonctions pandas : cette version ajoute deux nouveaux types de fonctions UDF pandas, itérateur de séries à itérateur de séries et itérateur de plusieurs séries à itérateur de séries. Ceci est utile pour le préchargement des données et l'initialisation coûteuse. De plus, deux nouvelles APIs de fonctions pandas, map et co-grouped map, sont ajoutées. Plus de détails sont disponibles dans cet billet de blog.
- Meilleure gestion des erreurs : la gestion des erreurs de PySpark n'est pas toujours conviviale pour les utilisateurs de Python. Cette version simplifie les exceptions PySpark, masque la trace de pile JVM inutile et les rend plus Pythoniques.
L'amélioration du support et de l'ergonomie de Python dans Spark reste l'une de nos plus grandes priorités.
Hydrogen, streaming et extensibilité
Avec Spark 3.0, nous avons finalisé les composants clés du projet Hydrogen et introduit de nouvelles fonctionnalités pour améliorer le streaming et l'extensibilité.
- Planification tenant compte des accélérateurs : le projet Hydrogen est une initiative majeure de Spark visant à mieux unifier le deep learning et le traitement des données sur Spark. Les GPU et autres accélérateurs sont largement utilisés pour accélérer les charges de travail du deep learning. Pour que Spark tire parti des accélérateurs matériels sur les plateformes cibles, cette version améliore le planificateur existant afin de rendre le gestionnaire de cluster compatible avec les accélérateurs. Les utilisateurs peuvent spécifier des accélérateurs via la configuration à l'aide d'un script de découverte. Les utilisateurs peuvent alors appeler les nouvelles API RDD pour tirer parti de ces accélérateurs.
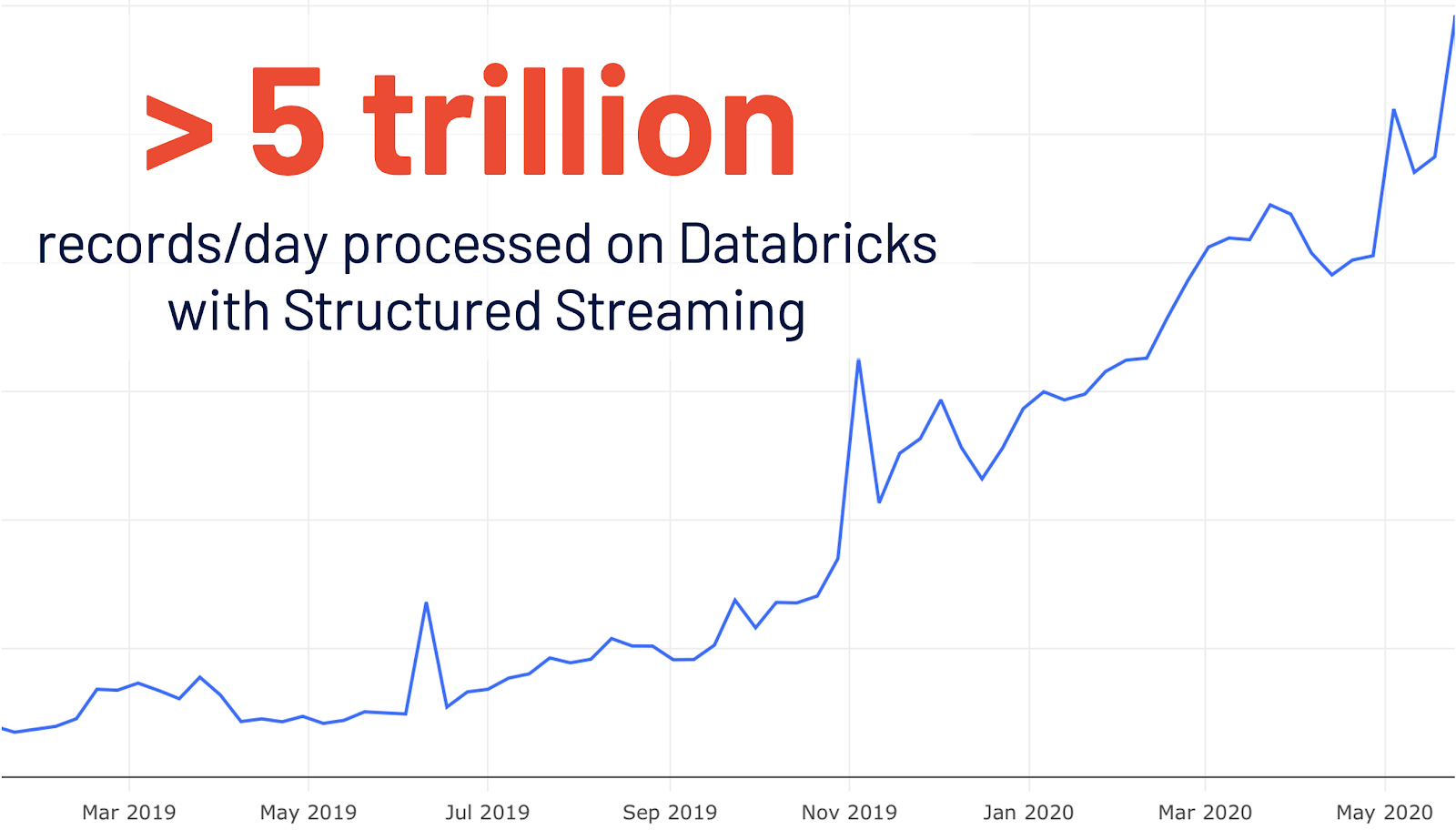
- Nouvelle interface utilisateur pour le streaming structuré : le streaming structuré a été initialement introduit dans Spark 2.0. Après une croissance de son utilisation de 4x d'une année sur l'autre sur Databricks, plus de 5 billions d'enregistrements par jour sont traités sur Databricks avec le streaming structuré. Cette version ajoute une nouvelle interface utilisateur Spark dédiée à l'inspection de ces Jobs de streaming. Cette nouvelle interface utilisateur offre deux ensembles de statistiques : 1) des informations agrégées sur les Jobs de requête de streaming terminés et 2) des informations statistiques détaillées sur les requêtes de streaming.
- Métriques observables : Le monitoring continu des modifications de la qualité des données est une fonctionnalité très recherchée pour la gestion des pipelines de données. Cette version introduit le monitoring des applications batch et en streaming. Les métriques observables sont des fonctions d'agrégation arbitraires qui peuvent être définies sur un query (DataFrame). Dès que l'exécution d'un DataFrame atteint un point d'achèvement (par exemple, termine une requête batch ou atteint une époque de streaming), un événement nommé est émis qui contient les métriques pour les données traitées depuis le dernier point d'achèvement.
- Nouvelle API de plug-in de catalogue : L'API de source de données existante ne permet pas d'accéder aux métadonnées des sources de données externes ni de les manipuler. Cette version enrichit l'API de source de données V2 et introduit la nouvelle API de plug-in de catalogue. Pour les sources de données externes qui implémentent à la fois l'API de plug-in de catalogue et l'API de source de données V2, les utilisateurs peuvent manipuler directement les données et les métadonnées des tables externes via des identifiants multipartites, une fois que le catalogue externe correspondant est enregistré.
Autres mises à jour de Spark 3.0
Spark 3.0 est une version majeure pour la communauté, avec plus de 3 400 tickets Jira résolus. C'est le résultat des contributions de plus de 440 contributeurs, y compris des particuliers ainsi que des entreprises comme Databricks, Google, Microsoft, Intel, IBM, Alibaba, Facebook, Nvidia, Netflix, Adobe et bien d'autres. Nous avons mis en évidence plusieurs avancées clés de Spark en matière de SQL, de Python et de streaming dans ce billet de blog, mais de nombreuses autres fonctionnalités de cette version 3.0 majeure ne sont pas abordées ici. Apprenez-en plus dans les notes de version et découvrez toutes les autres améliorations apportées à Spark, notamment les sources de données, l'écosystème, le monitoring et plus encore.
Démarrez avec Spark 3.0 dès aujourd'hui
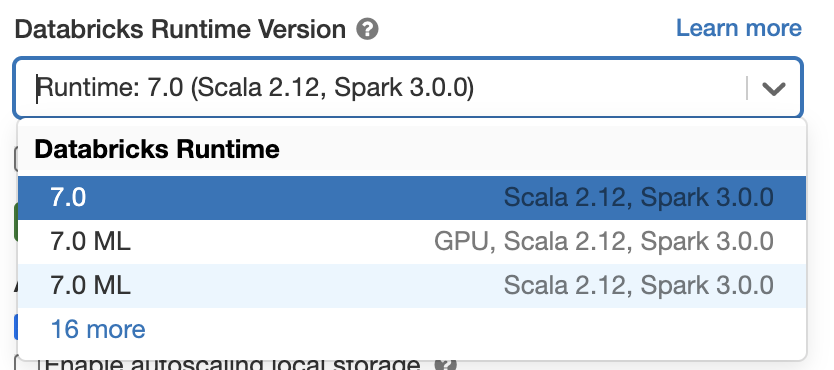
Si vous souhaitez essayer Apache Spark 3.0 dans Databricks Runtime 7.0, inscrivez-vous pour un compte d'Essai gratuit et lancez-vous en quelques minutes. Utiliser Spark 3.0 est aussi simple que de sélectionner la version « 7.0 » lors du lancement d'un cluster.
En savoir plus sur les fonctionnalités et les détails de la version :
- O’Reilly's New Learning Spark, 2nd Edition download gratuit de l'ebook
- blogs sur l'Exécution adaptative des queries
- Article de blog : UDF Pandas et indicateurs de type Python
- Spark 3.0 Preview, webinar à la demande
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.