Cinq étapes clés pour réussir la migration de Hadoop vers l'architecture Lakehouse
par Harsh Narula
La décision de migrer depuis Hadoop vers une architecture cloud moderne telle que l'architecture lakehouse est une décision commerciale et non technologique. Dans un article de blog précédent, nous avons exploré les raisons pour lesquelles chaque organisation doit réévaluer sa relation avec Hadoop. Une fois que les parties prenantes des secteurs de la technologie, des données et du métier ont pris la décision de faire migrer l'entreprise hors de Hadoop, plusieurs éléments doivent être pris en compte avant de commencer la transition effective. Dans ce blog, nous nous concentrerons spécifiquement sur le processus de migration en lui-même. Vous découvrirez les étapes clés d'une migration réussie et le rôle que joue l'architecture lakehouse pour susciter la prochaine vague d'innovation data-driven.
Les étapes de la migration
Appelons un chat un chat. Les migrations ne sont jamais faciles. Toutefois, les migrations peuvent être structurées pour minimiser leur impact négatif, assurer la continuité des activités et gérer efficacement les coûts. Pour ce faire, nous vous suggérons de décomposer votre migration hors de Hadoop en ces cinq étapes clés :
- Administration
- Migration des données
- Traitement des données
- Sécurité et gouvernance
- Couche SQL et BI
Étape 1 : Administration
Examinons certains des concepts essentiels de Hadoop du point de vue de l'administration, et en quoi ils se comparent et s'opposent à Databricks.
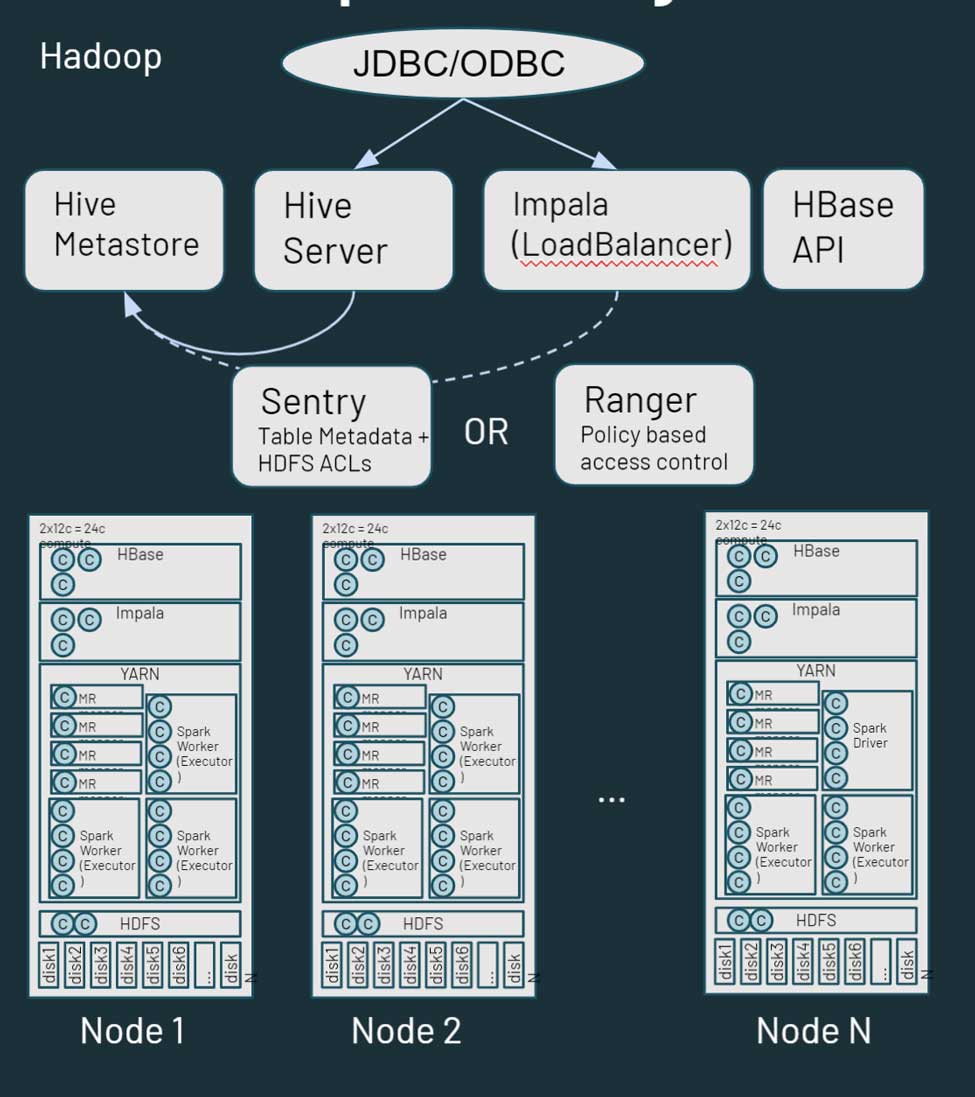
Hadoop est essentiellement une plateforme de stockage et de compute distribuée monolithique. Il se compose de plusieurs nœuds et serveurs, chacun disposant de son propre stockage, CPU et mémoire. Le travail est réparti sur tous ces nœuds. La gestion des ressources s'effectue via YARN, qui s'efforce de garantir que les charges de travail obtiennent leur part de compute.
Hadoop contient également des informations de métadonnées. Il existe un Hive metastore, qui contient des informations structurées sur vos ressources stockées dans HDFS. Vous pouvez utiliser Sentry ou Ranger pour contrôler l'accès aux données. Du point de vue de l'accès aux données, les utilisateurs et les applications peuvent soit accéder aux données directement via HDFS (ou les CLI/API correspondantes), soit via une interface de type SQL. L'interface SQL, à son tour, peut passer par une connexion JDBC/ODBC utilisant Hive pour le SQL générique (ou dans certains cas des scripts ETL) ou Hive sur Impala ou Tez pour les requêtes interactives. Hadoop fournit également une API HBase et des services de source de données associés. Plus d'informations sur l'écosystème Hadoop ici.
Voyons maintenant comment ces services sont mappés ou traités au sein de la Databricks Lakehouse Platform. Dans Databricks, l'une des premières différences à noter est que vous avez affaire à plusieurs clusters dans un environnement Databricks. Chaque cluster peut être utilisé pour un cas d'utilisation spécifique, un projet spécifique, une business unit, une équipe ou un groupe de développement. Plus important encore, ces clusters sont destinés à être éphémères. Pour les clusters de jobs, la durée de vie des clusters correspond à la durée du workflow. Il exécutera le workflow et, une fois celui-ci terminé, l'environnement sera automatiquement détruit. De même, si vous pensez à un cas d'utilisation interactif, où vous disposez d'un environnement compute partagé entre les développeurs, cet environnement peut être lancé au début de la journée de travail, les développeurs exécutant leur code tout au long de la journée. Pendant les périodes d'inactivité, Databricks l'arrêtera automatiquement via la fonctionnalité d'arrêt automatique (configurable) intégrée à la plateforme.
Contrairement à Hadoop, Databricks ne fournit pas de services de stockage de données comme HBase ou SOLR. Vos données résident dans votre stockage de fichiers, au sein du stockage d'objets. De nombreux services comme HBase ou SOLR ont des alternatives ou des offres technologiques équivalentes dans le cloud. Il peut s'agir d'une solution cloud native ou ISV.
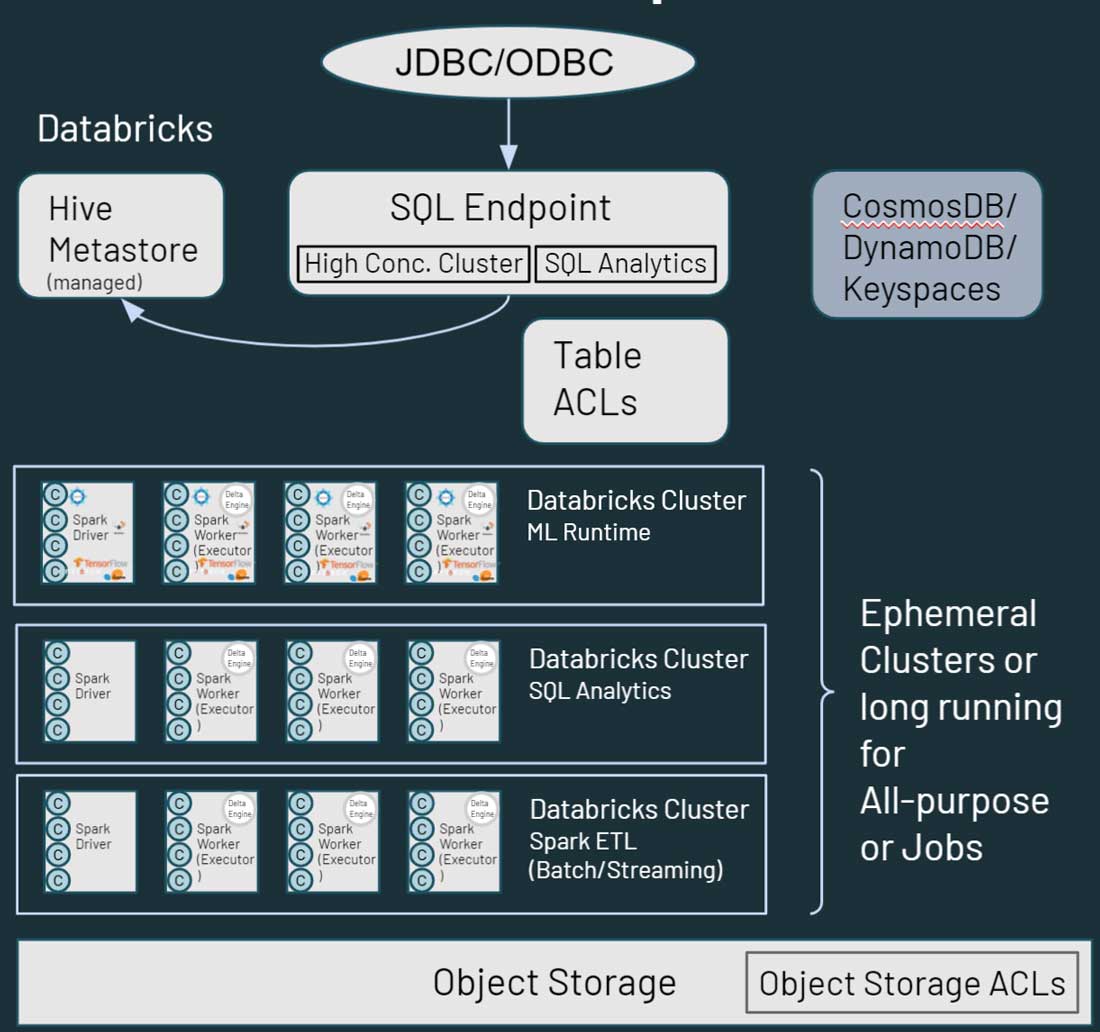
Comme vous pouvez le voir dans le diagramme ci-dessus, chaque nœud de cluster dans Databricks correspond soit à un driver Spark, soit à un worker. L'élément clé ici est que les différents clusters Databricks sont complètement isolés les uns des autres. Cela vous permet de garantir que des SLA stricts peuvent être respectés pour des projets et des cas d'utilisation spécifiques. Vous pouvez véritablement isoler les cas d'utilisation de streaming ou en temps réel des autres charges de travail orientées batch, et vous n'avez pas à vous soucier d'isoler manuellement les Jobs de longue durée qui pourraient monopoliser les ressources du cluster pendant une longue période. Vous pouvez simplement lancer de nouveaux clusters en tant que compute pour différents cas d'utilisation. Databricks découple également le stockage du calcul, et vous permet de tirer parti du stockage cloud existant tel qu'AWS S3, Azure Blob Storage et Azure Data Lake Store (ADLS).
Databricks dispose également d'un Hive metastore géré par default, qui stocke des informations structurées sur les assets de données résidant dans le stockage cloud. Il prend également en charge l'utilisation d'un metastore externe, tel que AWS Glue, Azure SQL Server ou Azure Purview. Vous pouvez également spécifier des contrôles de sécurité tels que des ACL de table dans Databricks, ainsi que des autorisations de stockage d'objets.
En matière d'accès aux données, Databricks propose des fonctionnalités similaires à Hadoop quant à la manière dont vos utilisateurs interagissent avec les données. Les données stockées dans le stockage cloud sont accessibles via plusieurs chemins dans l'environnement Databricks. Les utilisateurs peuvent utiliser les SQL Endpoints et Databricks SQL pour les requêtes interactives et l'analytique. Ils peuvent également utiliser les notebooks Databricks pour l'ingénierie des données et le Machine Learning sur les données stockées dans le stockage cloud. HBase dans Hadoop correspond à Azure CosmosDB ou AWS DynamoDB/Keyspaces, qui peuvent être utilisés comme couche de service pour les applications en aval.
Étape 2 : Migration des données
Ayant une expérience avec Hadoop, je suppose que la plupart d'entre vous connaissent déjà HDFS. HDFS est le système de fichiers de stockage utilisé avec les déploiements Hadoop, qui exploite les disques des nœuds du cluster Hadoop. Ainsi, lorsque vous montez en charge HDFS, vous devez ajouter de la capacité à l'ensemble du cluster (c'est-à-dire que vous devez monter en charge le compute et le stockage ensemble). Si cela implique l'acquisition et l'installation de matériel supplémentaire, cela peut demander un temps et des efforts considérables.
Dans le cloud, vous disposez d'une capacité de stockage quasi illimitée sous la forme de stockage cloud tel qu'AWS S3, Azure Data Lake Storage, Blob Storage ou Google Storage. Aucune maintenance ni aucun contrôle de santé n'est nécessaire, et il offre une redondance intégrée ainsi que des niveaux élevés de durabilité et de disponibilité dès son déploiement. Nous vous recommandons d'utiliser les services cloud natifs pour migrer vos données. Pour faciliter la migration, il existe plusieurs partenaires/ISV.
Alors, par où commencer ? L'approche la plus couramment recommandée est de commencer par une stratégie de double ingestion (c'est-à-dire ajouter un flux qui upload des données dans le stockage cloud en plus de votre environnement on-premise). Cela vous permet de start avec de nouveaux cas d'utilisation (qui exploitent de nouvelles données) dans le cloud sans affecter votre configuration existante. Si vous cherchez à obtenir l'adhésion d'autres groupes au sein de l'organisation, vous pouvez, pour commencer, présenter cela comme une stratégie de sauvegarde. Traditionnellement, la sauvegarde de HDFS représente un défi en raison de sa taille et de l'effort considérables qu'elle implique. La sauvegarde des données dans le cloud peut donc s'avérer être une initiative productive.
Dans la plupart des cas, vous pouvez utiliser les outils de livraison de données existants pour dupliquer le flux et écrire non seulement sur Hadoop, mais aussi sur le stockage cloud. Par exemple, si vous utilisez des outils/frameworks comme Informatica et Talend pour traiter et écrire des données sur Hadoop, il est très facile d'ajouter une étape supplémentaire pour qu'ils écrivent également sur le stockage cloud. Une fois les données dans le cloud, il existe de nombreuses façons de les exploiter.
En ce qui concerne la direction des données, les données peuvent être soit extraites de l'on-premise vers le cloud, soit poussées vers le cloud depuis l'on-premise. Parmi les outils qui peuvent être utilisés pour transférer les données vers le cloud figurent des Solutions cloud natives (Azure Data Box, AWS Snow Family, etc.), DistCP (un outil Hadoop), d'autres outils tiers, ainsi que des frameworks développés en interne. L'option push est généralement plus simple pour obtenir les approbations nécessaires des équipes de sécurité.
Pour extraire les données vers le cloud, vous pouvez utiliser le streaming Spark/Kafka ou des pipelines d'ingestion par lots déclenchés depuis le cloud. Pour le traitement par lots, vous pouvez soit ingérer des fichiers directement, soit utiliser des connecteurs JDBC pour vous connecter aux plateformes technologiques en amont pertinentes et extraire les données. Bien sûr, des outils tiers sont également disponibles pour cela. L'option push est la plus largement acceptée et comprise des deux, alors examinons plus en détail l'approche pull.
Pour commencer, vous devrez configurer la connectivité entre votre environnement on-premise et le cloud. Ceci peut être réalisé avec une connexion Internet et une passerelle. Vous pouvez également exploiter des options de connectivité dédiées telles qu'AWS Direct Connect, Azure ExpressRoute, etc. Dans certains cas, si votre organisation n'est pas novice en matière de cloud, il se peut que cela ait déjà été configuré, vous pouvez donc le réutiliser pour votre projet de migration Hadoop.
Une autre considération est la sécurité au sein de l'environnement Hadoop. S'il s'agit d'un environnement kerbérisé, il peut être pris en charge côté Databricks. Vous pouvez configurer des scripts d'initialisation Databricks qui s'exécutent au startup du cluster, installent et configurent le client Kerberos nécessaire, accèdent aux fichiers krb5.conf et keytab stockés dans un emplacement de stockage cloud, et enfin exécutent la fonction kinit(), ce qui permettra au cluster Databricks d'interagir directement avec votre environnement Hadoop.
Enfin, vous aurez également besoin d'un metastore externe partagé. Bien que Databricks dispose d'un service de metastore déployé par défaut, il prend également en charge l'utilisation d'un service externe. Le metastore externe sera partagé par Hadoop et Databricks, et peut être déployé soit on-premise (dans votre environnement Hadoop), soit dans le cloud. Par exemple, si vous avez des processus ETL existants qui s'exécutent dans Hadoop et que vous ne pouvez pas encore les migrer vers Databricks, vous pouvez utiliser cette configuration avec le metastore on-premise existant pour que Databricks consomme le dataset final organisé depuis Hadoop.
Étape 3 : Traitement des données
L'essentiel à retenir est que, du point de vue du traitement des données, tout dans Databricks s'appuie sur Apache Spark. Tous les langages de programmation Hadoop, tels que MapReduce, Pig, Hive QL et Java, peuvent être convertis pour s'exécuter sur Spark, que ce soit via Pyspark, Scala, Spark SQL ou même R. En ce qui concerne le code et l'IDE, les Notebooks Apache Zeppelin et Jupyter peuvent être convertis en Notebooks Databricks, mais il est un peu plus facile d'importer les Notebooks Jupyter. Les notebooks Zeppelin devront être convertis en Jupyter ou Ipython avant de pouvoir être importés. Si votre équipe de data science souhaite continuer à coder dans Zeppelin ou Jupyter, elle peut utiliser Databricks Connect, qui vous permet d'exploiter votre IDE local (Jupyter, Zeppelin ou même IntelliJ, VScode, RStudio, etc.) pour exécuter du code sur Databricks.
Lors de la migration de Jobs Apache Spark™, le principal facteur à prendre en compte est la version de Spark. Votre cluster Hadoop on-premise exécute peut-être une ancienne version de Spark, et vous pouvez utiliser le guide de migration Spark pour identifier les modifications apportées et voir les impacts éventuels sur votre code. Un autre aspect à prendre en compte est la conversion des RDD en dataframes. Les RDD étaient couramment utilisés avec les versions de Spark jusqu'à la 2.x, et bien qu'ils puissent toujours être utilisés avec Spark 3.x, cela peut vous empêcher de tirer pleinement parti des capacités de l'optimiseur Spark. Nous vous recommandons de convertir vos RDD en dataframes chaque fois que cela est possible.
Enfin et surtout, l'un des pièges courants que nous avons rencontrés avec nos clients lors de la migration concerne les références codées en dur à l'environnement Hadoop local. Celles-ci devront, bien sûr, être mises à jour, sans quoi le code ne fonctionnera plus dans la nouvelle configuration.
Ensuite, parlons de la conversion des charges de travail non-Spark, ce qui implique pour la plupart de réécrire le code. Pour MapReduce, dans certains cas, si vous utilisez une logique partagée sous la forme d'une bibliothèque Java, le code peut être exploité par Spark. Cependant, vous devrez peut-être encore réécrire certaines parties du code pour qu'elles s'exécutent dans un environnement Spark plutôt que MapReduce. Sqoop est relativement facile à migrer, car dans les nouveaux environnements, vous exécutez un ensemble de commandes Spark (par opposition aux commandes MapReduce) à l'aide d'une source JDBC. Vous pouvez spécifier des paramètres dans le code Spark de la même manière que vous les spécifiez dans Sqoop. Pour Flume, la plupart des cas d'utilisation que nous avons vus concernent la consommation de données depuis Kafka et leur écriture dans HDFS. Il s'agit d'une tâche qui peut être facilement accomplie à l'aide de Spark streaming. La tâche principale lors de la migration de Flume est que vous devez convertir l'approche basée sur un fichier de configuration en une approche plus programmatique dans Spark. Enfin, nous avons Nifi, qui est principalement utilisé en dehors d'Hadoop, surtout comme un outil d'ingestion en libre-service par glisser-déposer. Nifi peut également être exploité dans le cloud, mais nous voyons de nombreux clients profiter de l'occasion de la migration vers le cloud pour remplacer Nifi par d'autres outils plus récents disponibles dans le cloud.
La migration de HiveQL est peut-être la tâche la plus facile de toutes. Il existe un degré élevé de compatibilité entre Hive et Spark SQL, et la plupart des requêtes devraient pouvoir s'exécuter sur Spark SQL en l'état. Il existe quelques modifications mineures dans le DDL entre HiveQL et Spark SQL, comme le fait que Spark SQL utilise la clause « USING » tandis que HiveQL utilise la clause « FORMAT ». Nous vous recommandons de modifier le code pour utiliser le format Spark SQL, car cela permet à l'optimiseur de préparer le meilleur plan d'exécution possible pour votre code dans Databricks. Vous pouvez toujours exploiter les SerDes et les UDF Hive, ce qui simplifie encore plus la migration de HiveQL vers Databricks.
En ce qui concerne l'orchestration des workflows, vous devez envisager les changements potentiels dans la manière dont vos jobs seront soumis. Vous pouvez continuer à utiliser la sémantique de soumission Spark, mais il existe également d'autres options disponibles, plus rapides et intégrées de manière plus transparente. Vous pouvez utiliser les jobs Databricks et Delta Live Tables pour un ETL sans code afin de remplacer les jobs Oozie, et définir des pipelines de données de bout en bout dans Databricks. Pour les workflows impliquant des dépendances de traitement externes, vous devrez créer les workflows/pipelines équivalents dans des technologies comme Apache Airflow, Azure Data Factory, etc. pour l'automatisation/la planification. Avec les API REST de Databricks, presque n'importe quelle plateforme de planification peut être intégrée et configurée pour fonctionner avec Databricks.
Il existe également un outil automatisé appelé MLens (créé par KnowledgeLens), qui peut vous aider à migrer vos charges de travail de Hadoop vers Databricks. MLens peut aider à migrer le code PySpark et HiveQL, y compris la traduction de certaines spécificités de Hive en Spark SQL, afin que vous puissiez tirer parti de l'ensemble des fonctionnalités et des avantages en termes de performances de l'optimiseur Spark SQL. Ils prévoient également de prendre bientôt en charge la migration des workflows Oozie vers Airflow, Azure Data Factory, etc.
Étape 4 : Sécurité et gouvernance
Jetons un coup d'œil à la sécurité et à la gouvernance. Dans le monde Hadoop, nous disposons d'une intégration LDAP pour la connectivité aux consoles d'administration comme Ambari ou Cloudera Manager, ou même Impala ou Solr. Hadoop dispose également de Kerberos, qui est utilisé pour l'authentification auprès d'autres services. Du point de vue de l'autorisation, Ranger et Sentry sont les outils les plus couramment utilisés.
Avec Databricks, l'intégration de Single Sign On (SSO) est disponible avec n'importe quel fournisseur d'identité prenant en charge SAML 2.0. Cela inclut Azure Active Directory, Google Workspace SSO, AWS SSO et Microsoft Active Directory. Pour l'autorisation, Databricks fournit des ACL (listes de contrôle d'accès) pour les objets Databricks, ce qui vous permet de définir des autorisations sur des entités comme les Notebooks, les Jobs et les clusters. Pour les autorisations sur les données et le contrôle d'accès, vous pouvez définir des ACL de table et des vues pour limiter l'accès aux colonnes et aux lignes, ainsi qu'utiliser un mécanisme comme le « credential passthrough », avec lequel Databricks transmet vos identifiants de connexion au workspace à la couche de stockage (S3, ADLS, Blob Storage) pour déterminer si vous êtes autorisé à accéder aux données. Si vous avez besoin de fonctionnalités comme les contrôles basés sur les attributs ou le masquage de données, vous pouvez utiliser des outils partenaires comme Immuta et Privacera. Du point de vue de la gouvernance d'entreprise, vous pouvez connecter Databricks à un data catalog d'entreprise tel que AWS Glue, Informatica Data Catalog, Alation et Collibra.
Étape 5 : Couche SQL & BI
Dans Hadoop, comme nous l'avons vu précédemment, vous disposez de Hive et d'Impala en tant qu'interfaces pour effectuer l'ETL, ainsi que des queries ad hoc et des analytiques. Dans Databricks, vous disposez de fonctionnalités similaires via Databricks SQL. Databricks SQL offre également des performances extrêmes via le moteur Delta, ainsi qu'une prise en charge des cas d'utilisation à haute simultanéité avec des clusters à mise à l'échelle automatique. Le moteur Delta inclut également Photon, un nouveau moteur MPP développé à partir de zéro en C++ et vectorisé pour exploiter le parallélisme de données et d'instructions.
Databricks fournit une intégration native avec des outils de BI tels que Tableau, PowerBI, Qlik et Looker, ainsi que des connecteurs JDBC/ODBC hautement optimisés qui peuvent être exploités par ces outils. Les nouveaux pilotes JDBC/ODBC ont une très faible surcharge (¼ s) et un taux de transfert 50 % plus élevé grâce à Apache Arrow, ainsi que plusieurs Opérations sur les métadonnées qui permettent d'accélérer considérablement leur récupération. Databricks prend également en charge le SSO pour PowerBI, ainsi que pour d'autres outils de BI/tableaux de bord qui seront bientôt disponibles.
Databricks dispose d'une UX SQL intégrée en plus de l'expérience de notebook mentionnée ci-dessus, qui offre à vos utilisateurs SQL leur propre environnement avec un workbench SQL, ainsi que des fonctionnalités légères de création de tableaux de bord et d'alertes. Cela permet d'effectuer des Transformations de données basées sur SQL et de l'analytique exploratoire sur les données au sein du data lake, sans avoir besoin de les déplacer en aval vers un data warehouse ou d'autres plateformes.
Étapes suivantes
Alors que vous réfléchissez à votre parcours de migration vers une architecture cloud moderne comme l'architecture lakehouse, voici deux choses à retenir :
- N'oubliez pas d'impliquer les principales parties prenantes de l'entreprise dans le projet. Il s'agit tout autant d'une décision de Technologie que d'une décision commerciale, et vos parties prenantes de l'entreprise doivent adhérer au projet et à sa finalité.
- N'oubliez pas non plus que vous n'êtes pas seul et qu'il existe des ressources compétentes chez Databricks et nos partenaires qui ont suffisamment d'expérience pour élaborer des bonnes pratiques reproductibles, ce qui permet aux entreprises d'économiser du temps, de l'argent et des ressources, tout en réduisant le stress général.
- Download le guide de migration technique de Hadoop vers Databricks pour obtenir des instructions pas à pas, des Notebooks et du code pour commencer votre migration.
Pour en savoir plus sur la manière dont Databricks augmente la valeur commerciale et commencer à planifier votre migration depuis Hadoop, rendez-vous sur www.databricks.com/solutions/migration.

Guide de migration : de Hadoop à Databricks
Libérez tout le potentiel de vos données grâce à ce playbook autoguidé.
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.