Techniques de modélisation d'entreposage de données et leur implémentation sur la plateforme Lakehouse Databricks
Utilisation des Data Vaults et des Schémas en Étoile sur le Lakehouse
par Soham Bhatt et Deepak Sekar
Le lakehouse est un nouveau paradigme de plateforme de données qui combine les meilleures caractéristiques des data lakes et des data warehouses. Il est conçu comme une plateforme de données d'entreprise à grande échelle capable de prendre en charge de nombreux cas d'utilisation et produits de données. Il peut servir de référentiel de données d'entreprise unifié pour tous vos :
- domaines de données,
- cas d'utilisation de streaming en temps réel,
- data marts,
- data warehouses disparates,
- stores de caractéristiques pour la science des données et sandboxes pour la science des données, et
- sandboxes d'analyse en libre-service départementales.
Compte tenu de la variété des cas d'utilisation, différents principes d'organisation des données et techniques de modélisation peuvent s'appliquer à différents projets sur un lakehouse. Techniquement, la Databricks Lakehouse Platform peut prendre en charge de nombreux styles de modélisation de données différents. Dans cet article, nous visons à expliquer la mise en œuvre des principes d'organisation des données Bronze/Silver/Gold du lakehouse et comment différentes techniques de modélisation de données s'intègrent dans chaque couche.
Qu'est-ce qu'un Data Vault ?
Un Data Vault est un modèle de conception de données plus récent utilisé pour construire des data warehouses pour l'analyse à l'échelle de l'entreprise, comparé aux méthodes Kimball et Inmon.
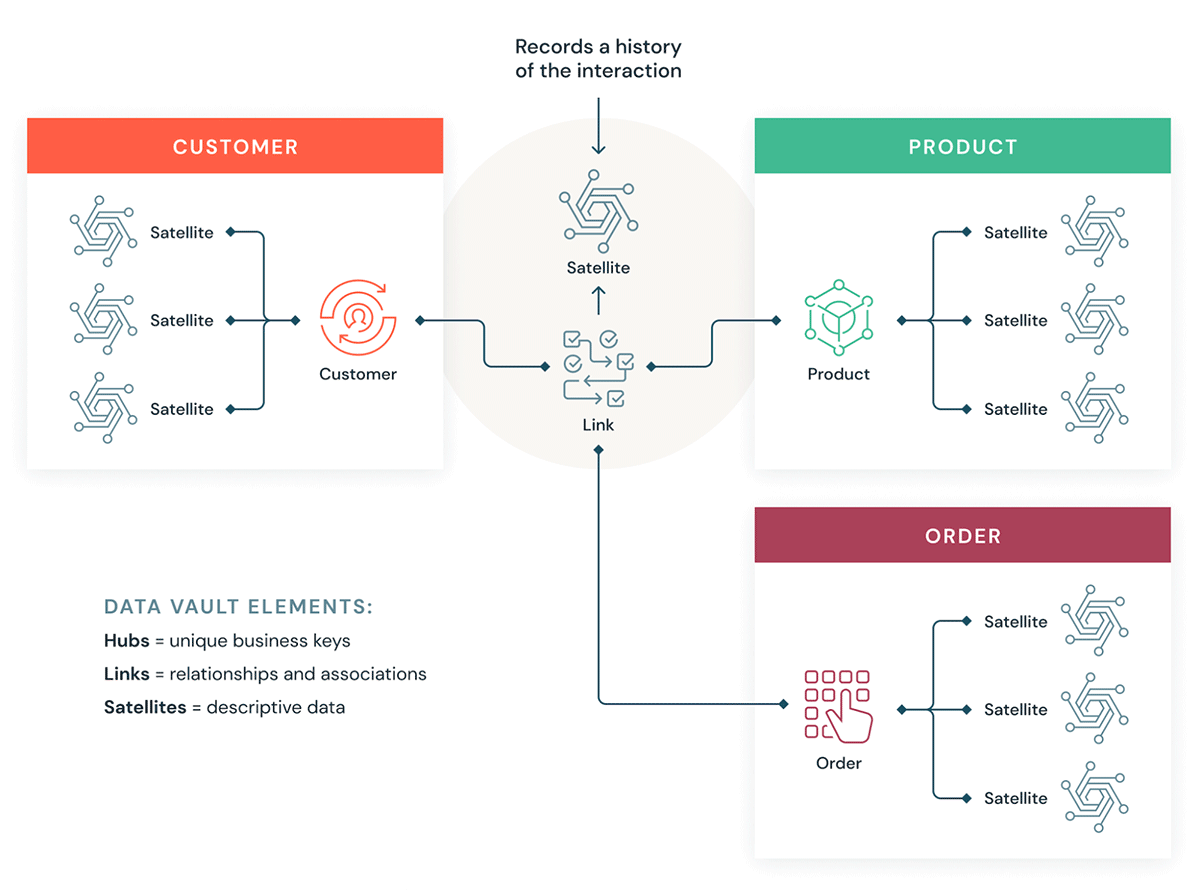
Les Data Vaults organisent les données en trois types : hubs, links et satellites. Les hubs représentent les entités commerciales principales, les links représentent les relations entre les hubs, et les satellites stockent les attributs des hubs ou des links.
Le Data Vault se concentre sur le développement agile de data warehouses où la scalabilité, l'intégration des données/ETL et la vitesse de développement sont importantes. La plupart des clients ont une zone d'atterrissage (landing zone), une zone Vault et une zone data mart, qui correspondent aux paradigmes organisationnels de Databricks : les couches Bronze, Silver et Gold. Le style de modélisation Data Vault avec des tables hubs, links et satellites s'intègre généralement bien dans la couche Silver du Databricks Lakehouse.
Apprenez-en davantage sur la modélisation Data Vault sur Data Vault Alliance.
Qu'est-ce que la Modélisation Dimensionnelle ?
La modélisation dimensionnelle est une approche ascendante (bottom-up) de conception de data warehouses afin de les optimiser pour l'analyse. Les modèles dimensionnels sont utilisés pour dénormaliser les données métier en dimensions (comme le temps et le produit) et faits (comme les transactions en montants et quantités), et différentes zones de sujets sont connectées via des dimensions conformes pour naviguer vers différentes tables de faits.
La forme la plus courante de modélisation dimensionnelle est le schéma en étoile. Un schéma en étoile est un modèle de données multidimensionnel utilisé pour organiser les données afin qu'elles soient faciles à comprendre et à analyser, et très faciles et intuitives pour générer des rapports. Les schémas en étoile de style Kimball ou les modèles dimensionnels sont pratiquement la référence pour la couche de présentation dans les data warehouses et les data marts, et même pour les couches sémantiques et de reporting. La conception du schéma en étoile est optimisée pour l'interrogation de grands ensembles de données.
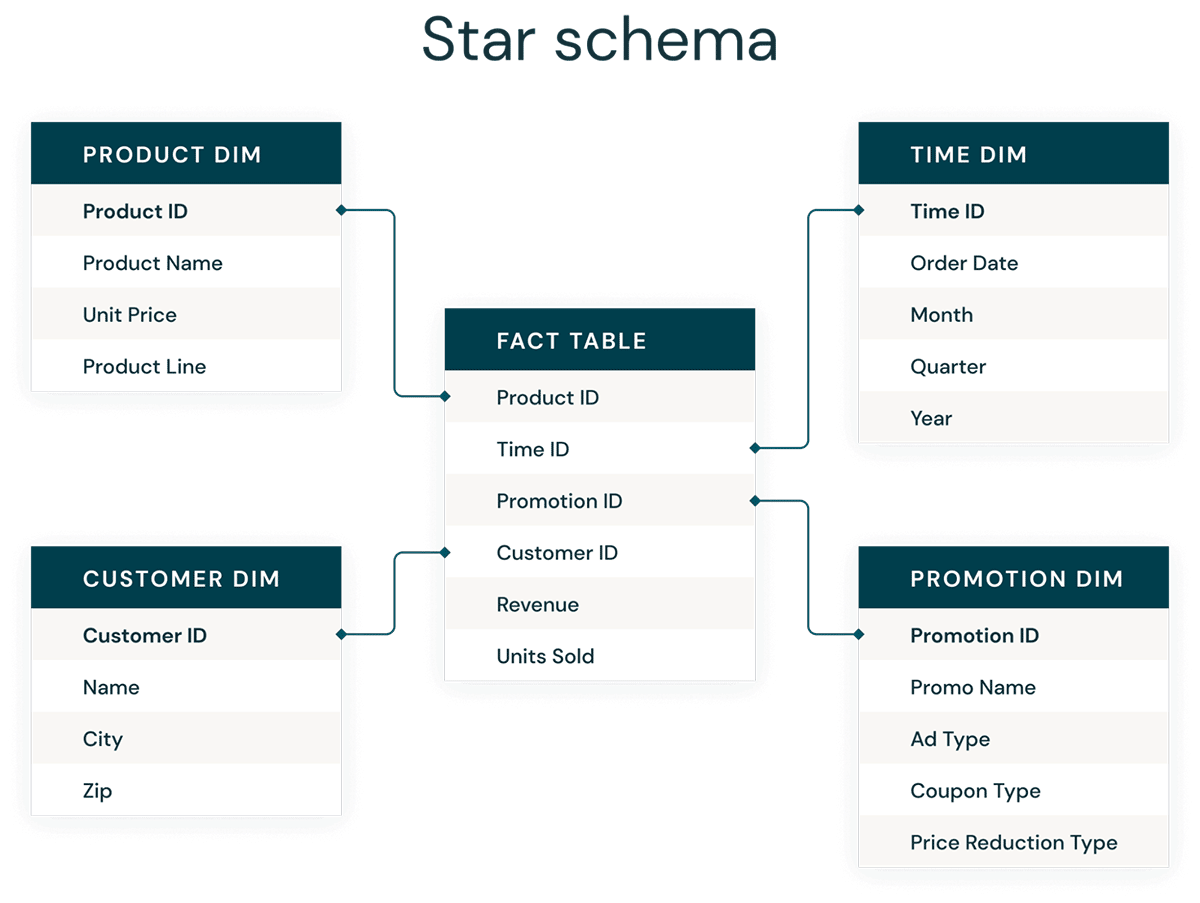
Les deux styles de modélisation de données, Data Vault normalisé (optimisé en écriture) et modèles dimensionnels dénormalisés (optimisés en lecture), ont leur place dans le Databricks Lakehouse. Les hubs et satellites du Data Vault dans la couche Silver sont utilisés pour charger les dimensions du schéma en étoile, et les tables de liens du Data Vault deviennent les tables clés pour charger les tables de faits dans le modèle dimensionnel. Apprenez-en davantage sur la modélisation dimensionnelle auprès du Kimball Group.
Principes d'organisation des données dans chaque couche du Lakehouse
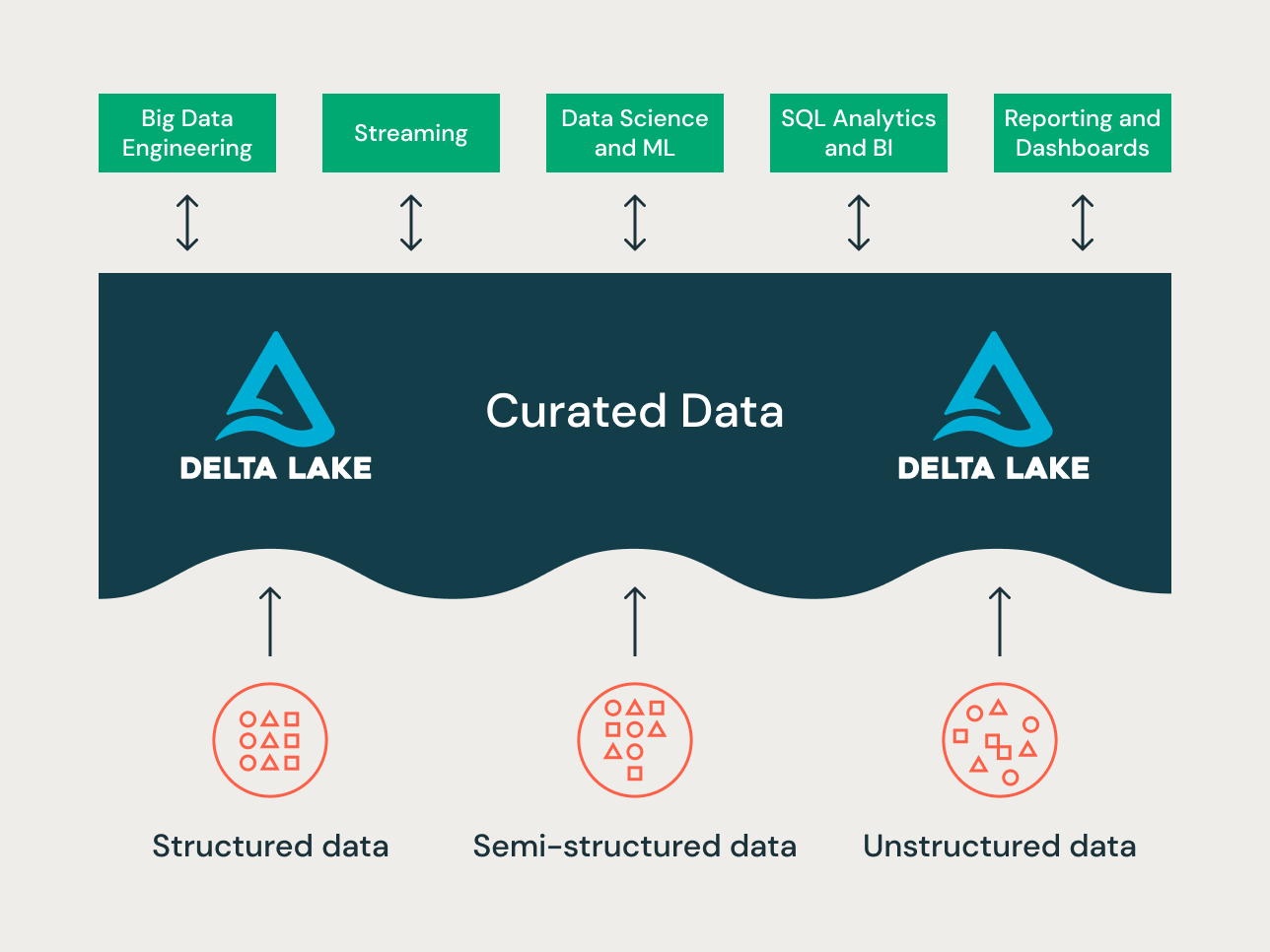
Un lakehouse moderne est une plateforme de données d'entreprise globale. Il est hautement évolutif et performant pour toutes sortes de cas d'utilisation tels que l'ETL, la BI, la science des données et le streaming qui peuvent nécessiter différentes approches de modélisation de données. Voyons comment un lakehouse typique est organisé :
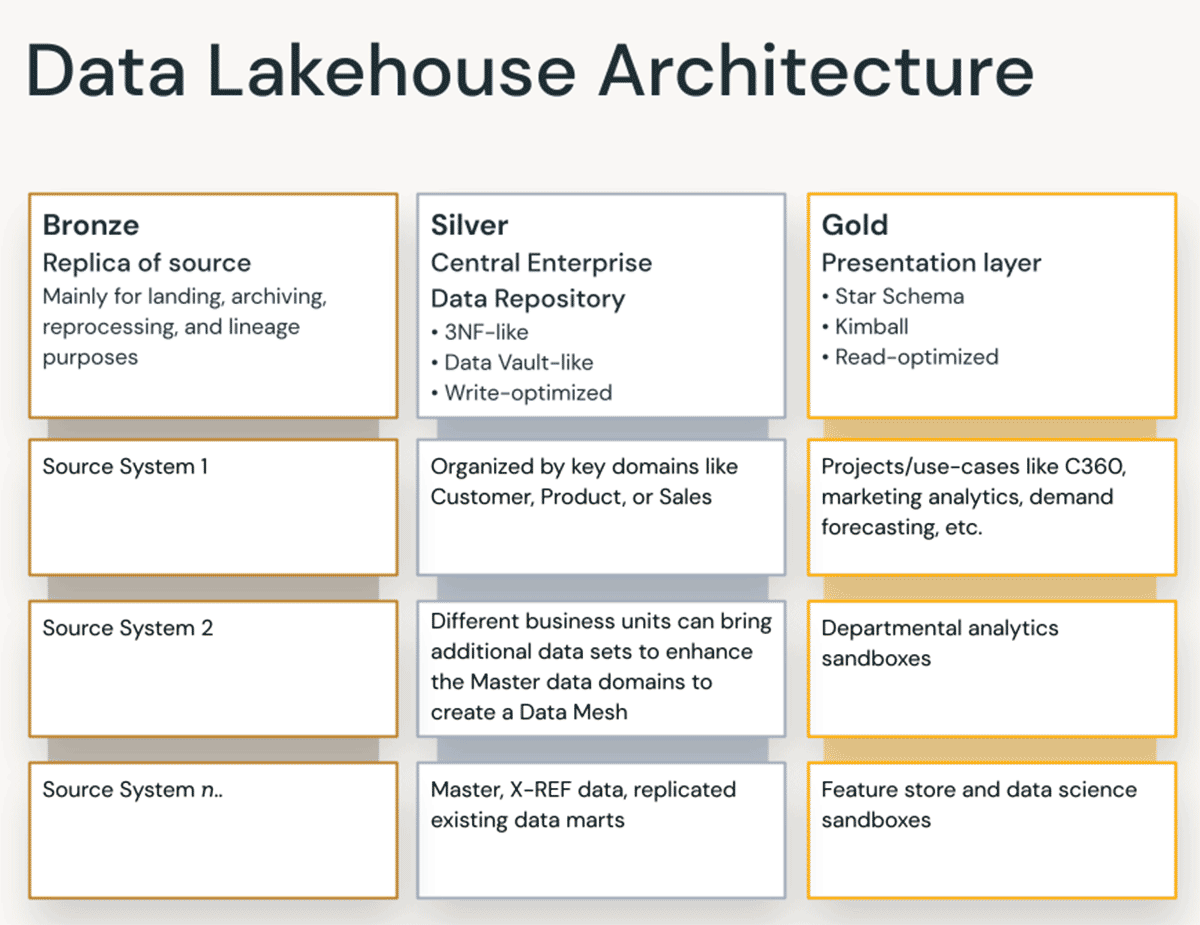
Couche Bronze — la Zone d'Atterrissage
La couche Bronze est l'endroit où nous réceptionnons toutes les données des systèmes sources. Les structures de table dans cette couche correspondent aux structures de table du système source « telles quelles », à l'exception des colonnes de métadonnées facultatives qui peuvent être ajoutées pour capturer la date/heure de chargement, l'ID du processus, etc. L'objectif de cette couche est la capture des changements de données (CDC), et la capacité de fournir une archive historique des données sources (stockage à froid), la lignée des données, l'auditabilité et le retraitement si nécessaire — sans relire les données du système source.
Dans la plupart des cas, il est judicieux de conserver les données de la couche Bronze au format Delta, afin que les lectures ultérieures de la couche Bronze pour l'ETL soient performantes — et que vous puissiez effectuer des mises à jour dans Bronze pour écrire les changements CDC. Parfois, lorsque les données arrivent au format JSON ou XML, nous voyons des clients les faire atterrir dans le format de données source d'origine, puis les mettre en scène en les convertissant au format Delta. Nous voyons donc parfois des clients manifester la couche Bronze logique dans une zone d'atterrissage et de mise en scène physique.
Le stockage des données brutes dans le format de données source d'origine dans une zone d'atterrissage aide également à la cohérence lorsque vous ingérez des données via des outils d'ingestion qui ne prennent pas en charge Delta comme destination native ou lorsque les systèmes sources déversent des données directement sur des stockages d'objets. Ce modèle s'aligne également bien avec le framework d'ingestion autoloader où les sources font atterrir les données dans la zone d'atterrissage pour les fichiers bruts, puis Databricks AutoLoader convertit les données en couche de mise en scène au format Delta.
Couche Silver — le Référentiel Central d'Entreprise
Dans la couche Silver du Lakehouse, les données de la couche Bronze sont mises en correspondance, fusionnées, conformées et nettoyées (« juste assez ») afin que la couche Silver puisse fournir une « vue d'entreprise » de toutes ses entités commerciales clés, concepts et transactions. Ceci est similaire à un Enterprise Operational Data Store (ODS) ou à un référentiel central ou à des domaines de données d'un Data Mesh (par exemple, clients maîtres, produits, transactions non dupliquées et tables de référence croisée). Cette vue d'entreprise rassemble les données de différentes sources et permet l'analyse en libre-service pour le reporting ad hoc, l'analyse avancée et le ML. Elle sert également de source pour les analystes départementaux, les ingénieurs de données et les scientifiques des données afin de créer davantage de projets de données et d'analyses pour répondre aux problèmes métier via des projets de données d'entreprise et départementaux dans la couche Gold.
Dans le paradigme d'ingénierie des données du Lakehouse, la méthodologie ELT (Extract-Load-Transform) est généralement suivie par rapport à l'ETL (Extract-Transform-Load) traditionnel. L'approche ELT signifie que seules des transformations et des règles de nettoyage de données minimales ou « juste assez » sont appliquées lors du chargement de la couche Silver. Toutes les règles « au niveau de l'entreprise » sont appliquées dans la couche Silver, par opposition aux règles de transformation spécifiques au projet, qui sont appliquées dans la couche Gold. La vitesse et l'agilité pour ingérer et livrer les données dans le Lakehouse sont priorisées ici.
D'un point de vue de la modélisation des données, la couche Silver a davantage de modèles de données similaires à la 3ème forme normale. Des architectures et des modèles de données performants en écriture, similaires au Data Vault, peuvent être utilisés dans cette couche. Si vous utilisez une méthodologie Data Vault, le Data Vault brut et le Business Vault s'intégreront dans la couche Silver logique du lac — et les vues de présentation Point-In-Time (PIT) ou les vues matérialisées seront présentées dans la couche Gold.
Couche Gold — la Couche de Présentation
Dans la couche Gold, plusieurs data marts ou data warehouses peuvent être construits selon la méthodologie de modélisation dimensionnelle/Kimball. Comme mentionné précédemment, la couche Gold est destinée au reporting et utilise des modèles de données plus dénormalisés et optimisés en lecture avec moins de jointures par rapport à la couche Silver. Parfois, les tables de la couche Gold peuvent être complètement dénormalisées, typiquement si les scientifiques des données le souhaitent ainsi pour alimenter leurs algorithmes d'ingénierie des caractéristiques.
Les règles ETL et de qualité des données « spécifiques au projet » sont appliquées lors de la transformation des données de la couche Silver vers la couche Gold. Les couches de présentation finales telles que les entrepôts de données, les data marts ou les produits de données comme l'analyse client, l'analyse produit/qualité, l'analyse des stocks, la segmentation client, les recommandations de produits, l'analyse marketing/ventes, etc. sont livrés dans cette couche. Les modèles de données basés sur le schéma en étoile de style Kimball ou les Data Marts de style Inmon s'intègrent dans cette couche Gold du Lakehouse. Les laboratoires de science des données et les bacs à sable départementaux pour l'analytique en libre-service appartiennent également à la couche Gold.
Le paradigme d'organisation des données du Lakehouse
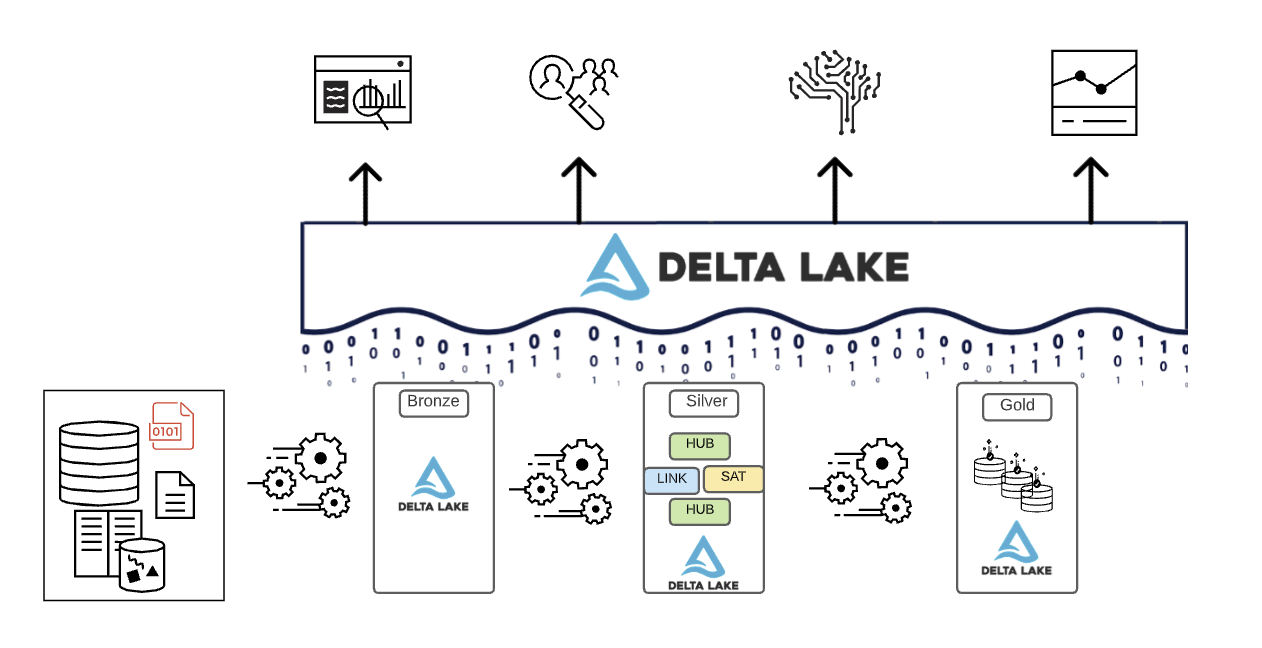
Pour résumer, les données sont organisées au fur et à mesure qu'elles traversent les différentes couches d'un Lakehouse.
- La couche Bronze utilise les modèles de données des systèmes sources. Si les données sont chargées dans des formats bruts, elles sont converties au format Delta Lake dans cette couche.
- La couche Silver rassemble pour la première fois les données de différentes sources et les harmonise pour créer une vue d'entreprise des données — en utilisant généralement des modèles de données plus normalisés et optimisés pour l'écriture, qui ressemblent généralement à la 3ème forme normale ou à Data Vault.
- La couche Gold est la couche de présentation avec des modèles de données plus dénormalisés ou aplatis que la couche Silver, utilisant généralement des modèles dimensionnels de style Kimball ou des schémas en étoile. La couche Gold abrite également des bacs à sable départementaux et de science des données pour permettre l'analytique en libre-service et la science des données dans toute l'entreprise. La fourniture de ces bacs à sable et de leurs propres clusters de calcul séparés empêche les équipes métier de créer leurs propres copies de données en dehors du Lakehouse.
Cette approche d'organisation des données du Lakehouse vise à briser les silos de données, à rassembler les équipes et à leur permettre d'effectuer l'ETL, le streaming, la BI et l'IA sur une seule plateforme avec une gouvernance appropriée. Les équipes de données centrales devraient être les moteurs de l'innovation dans l'organisation, en accélérant l'intégration des nouveaux utilisateurs en libre-service, ainsi que le développement de nombreux projets de données en parallèle — plutôt que le processus de modélisation des données ne devienne le goulot d'étranglement. Le Unity Catalog de Databricks fournit la recherche et la découverte, la gouvernance et la lignée sur le Lakehouse pour assurer une bonne cadence de gouvernance des données.
Créez vos Data Vaults et entrepôts de données en schéma étoile avec Databricks SQL dès aujourd'hui.
Pour en savoir plus :
- Cinq étapes simples pour implémenter un schéma en étoile dans Databricks avec Delta Lake
- Bonnes pratiques pour implémenter un modèle Data Vault sur la plateforme Databricks Lakehouse
- Bonnes pratiques de modélisation dimensionnelle et implémentation sur un Lakehouse moderne
- Les colonnes d'identité pour générer des clés substituts sont maintenant disponibles dans un Lakehouse près de chez vous !
- Chargez un modèle dimensionnel EDW en temps réel avec Databricks Lakehouse
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.