Pipelines de données en streaming à faible latence avec Delta Live Tables et Apache Kafka
par Frank Munz
Delta Live Tables (DLT) est le premier framework ETL qui utilise une approche déclarative simple pour créer des pipelines de données fiables et gère entièrement l'infrastructure sous-jacente à grande échelle pour les données par lots et les données en streaming. De nombreux cas d'utilisation nécessitent des insights exploitables dérivés de données quasi en temps réel. Delta Live Tables permet des pipelines de données en streaming à faible latence pour prendre en charge ces cas d'utilisation avec de faibles latences en ingérant directement des données à partir de bus d'événements tels que Apache Kafka, AWS Kinesis, Confluent Cloud, Amazon MSK, ou Azure Event Hubs.
Cet article vous guidera dans l'utilisation de DLT avec Apache Kafka tout en fournissant le code Python requis pour ingérer des flux. L'architecture système recommandée sera expliquée et les paramètres DLT pertinents à considérer seront explorés en cours de route.
Plateformes de streaming
Les bus d'événements ou bus de messages découplent les producteurs de messages des consommateurs. Un cas d'utilisation de streaming populaire est la collecte de données de clics à partir d'utilisateurs naviguant sur un site Web où chaque interaction utilisateur est stockée sous forme d'événement dans Apache Kafka. Le flux d'événements de Kafka est ensuite utilisé pour l'analyse de données en streaming en temps réel. Plusieurs consommateurs de messages peuvent lire les mêmes données de Kafka et utiliser ces données pour en apprendre davantage sur les intérêts de l'audience, les taux de conversion et les raisons de rebond. Les données d'événements en streaming en temps réel provenant des interactions utilisateur doivent souvent également être corrélées avec les achats réels stockés dans une base de données de facturation.
Apache Kafka
Apache Kafka est un bus d'événements open source populaire. Kafka utilise le concept de topic, un journal distribué d'événements en mode ajout seul où les messages sont mis en mémoire tampon pendant une certaine période. Bien que les messages dans Kafka ne soient pas supprimés une fois consommés, ils ne sont pas non plus stockés indéfiniment. La rétention des messages pour Kafka peut être configurée par topic et est de 7 jours par défaut. Les messages expirés seront éventuellement supprimés.
Cet article est centré sur Apache Kafka ; cependant, les concepts abordés s'appliquent également à de nombreux autres bus d'événements ou systèmes de messagerie.
Pipelines de données en streaming
Dans un pipeline de flux de données, Delta Live Tables et leurs dépendances peuvent être déclarés avec une instruction standard SQL Create Table As Select (CTAS) et le mot-clé DLT "live".
Lors du développement de DLT avec Python, le décorateur @dlt.table est utilisé pour créer une Delta Live Table. Pour garantir la qualité des données dans un pipeline, DLT utilise des attentes qui sont de simples clauses de contraintes SQL définissant le comportement du pipeline avec les enregistrements invalides.
Étant donné que les charges de travail de streaming impliquent souvent des volumes de données imprévisibles, Databricks emploie une mise à l'échelle automatique améliorée pour les pipelines de flux de données afin de minimiser la latence de bout en bout tout en réduisant les coûts en arrêtant l'infrastructure inutile.
Delta Live Tables sont entièrement recalculées, dans le bon ordre, exactement une fois pour chaque exécution de pipeline.
En revanche, les Delta Live Tables en streaming sont stateful, calculées de manière incrémentielle et ne traitent que les données ajoutées depuis la dernière exécution du pipeline. Si la requête qui définit une table live en streaming change, les nouvelles données seront traitées en fonction de la nouvelle requête, mais les données existantes ne seront pas recalculées. Les tables live en streaming utilisent toujours une source de streaming et ne fonctionnent qu'avec des flux en mode ajout seul, tels que Kafka, Kinesis ou Auto Loader. Les DLT en streaming sont basées sur Spark Structured Streaming.
Vous pouvez chaîner plusieurs pipelines en streaming, par exemple, des charges de travail avec un très grand volume de données et des exigences de faible latence.
Ingestion directe à partir de moteurs de streaming
Delta Live Tables écrites en Python peuvent ingérer directement des données à partir d'un bus d'événements comme Kafka en utilisant Spark Structured Streaming. Vous pouvez définir une courte période de rétention pour le topic Kafka afin d'éviter les problèmes de conformité, de réduire les coûts, puis de bénéficier du stockage économique, élastique et gouvernable que Delta offre.
Comme première étape du pipeline, nous recommandons d'ingérer les données telles quelles dans une table bronze (brute) et d'éviter les transformations complexes qui pourraient supprimer des données importantes. Comme toute Delta Table, la table bronze conservera l'historique et permettra d'effectuer des tâches de conformité GDPR et autres.
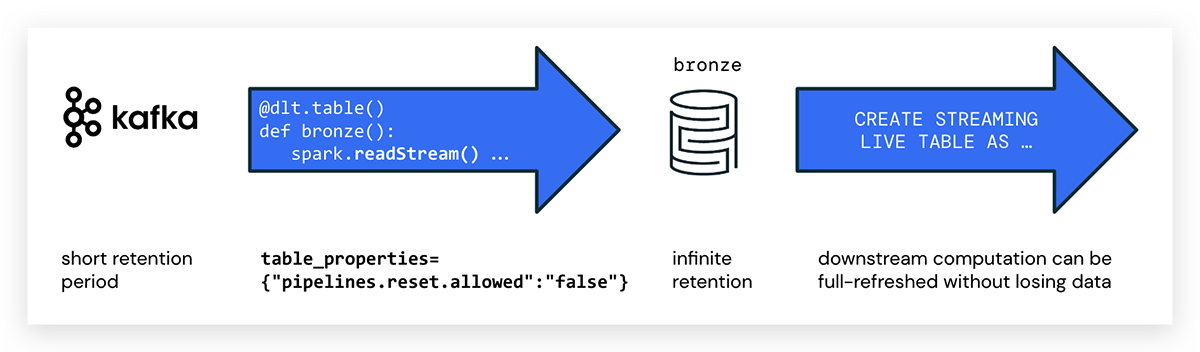
Lorsque vous écrivez des pipelines DLT en Python, vous utilisez l'annotation @dlt.table pour créer une table DLT. Il n'y a pas d'attribut spécial pour marquer les DLT en streaming en Python ; utilisez simplement spark.readStream() pour accéder au flux. Voici un exemple de code pour créer une table DLT nommée kafka_bronze qui consomme des données d'un topic Kafka :
pipelines.reset.allowed
Notez que les bus d'événements expirent généralement les messages après une certaine période, tandis que Delta est conçu pour une rétention infinie.
Cela peut avoir pour effet que les données sources sur Kafka ont déjà été supprimées lors de l'exécution d'un rafraîchissement complet d'un pipeline DLT. Dans ce cas, toutes les données historiques ne pourront pas être rechargées à partir de la plateforme de messagerie, et des données manqueront dans les tables DLT. Pour éviter la perte de données, utilisez la propriété de table DLT suivante :
pipelines.reset.allowed=false
Définir pipelines.reset.allowed sur false empêche les rafraîchissements de la table, mais n'empêche pas les écritures incrémentielles dans les tables ni l'arrivée de nouvelles données dans la table.
Checkpointing
Si vous êtes un développeur expérimenté en Spark Structured Streaming, vous remarquerez l'absence de checkpointing dans le code ci-dessus. Dans Spark Structured Streaming, le checkpointing est nécessaire pour persister les informations de progression sur les données qui ont été traitées avec succès et, en cas d'échec, ces métadonnées sont utilisées pour redémarrer une requête échouée exactement là où elle s'était arrêtée.
Alors que les checkpoints sont nécessaires pour la récupération après échec avec des garanties exactly-once dans Spark Structured Streaming, DLT gère l'état automatiquement sans aucune configuration manuelle ni checkpointing explicite requis.
Mélanger SQL et Python pour un pipeline DLT
Un pipeline DLT peut se composer de plusieurs notebooks, mais un notebook DLT doit être entièrement écrit en SQL ou en Python (contrairement aux autres notebooks Databricks où vous pouvez avoir des cellules de différents langages dans un seul notebook).
Maintenant, si votre préférence est SQL, vous pouvez coder l'ingestion de données depuis Apache Kafka dans un notebook en Python, puis implémenter la logique de transformation de vos pipelines de données dans un autre notebook en SQL.
Mapping de schéma
Lors de la lecture de données à partir d'une plateforme de messagerie, le flux de données est opaque et un schéma doit être fourni.
L'exemple Python ci-dessous montre la définition du schéma des événements d'un tracker de fitness, et comment la partie valeur du message Kafka est mappée à ce schéma.
Avantages
La lecture de données en streaming dans DLT directement à partir d'un courtier de messages minimise la complexité architecturale et offre une latence de bout en bout plus faible, car les données sont directement transmises depuis le courtier de messages et aucune étape intermédiaire n'est impliquée.
Ingestion en continu avec un intermédiaire de magasin d'objets cloud
Pour certains cas d'utilisation spécifiques, vous pouvez vouloir décharger des données d'Apache Kafka, par exemple en utilisant un connecteur Kafka, et stocker vos données en continu dans un intermédiaire d'objet cloud. Dans un espace de travail Databricks, le magasin d'objets spécifique au fournisseur cloud peut ensuite être mappé via le Databricks Files System (DBFS) comme un dossier indépendant du cloud. Une fois les données déchargées, Databricks Auto Loader peut ingérer les fichiers.
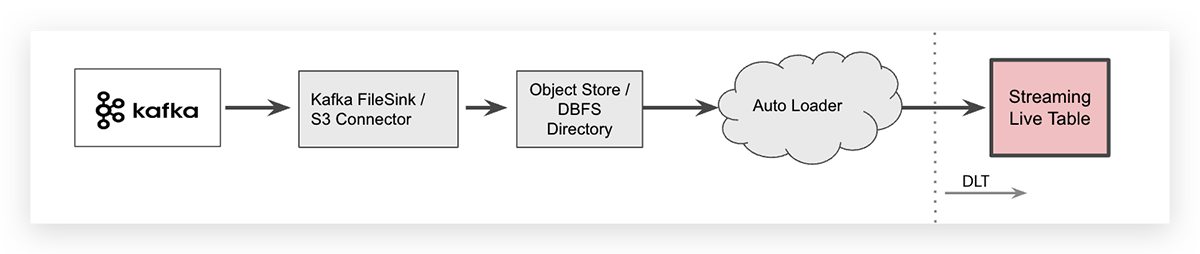
Auto Loader peut ingérer des données avec une seule ligne de code SQL. La syntaxe pour ingérer des fichiers JSON dans une table DLT est montrée ci-dessous (elle est répartie sur deux lignes pour plus de lisibilité).
Notez qu'Auto Loader lui-même est une source de données en continu et que tous les nouveaux fichiers arrivés seront traités exactement une fois, d'où le mot-clé streaming pour la table brute qui indique que les données sont ingérées de manière incrémentielle dans cette table.
Étant donné que le déchargement des données en continu vers un magasin d'objets cloud introduit une étape supplémentaire dans votre architecture système, cela augmentera également la latence de bout en bout et créera des coûts de stockage supplémentaires. Gardez à l'esprit que le connecteur Kafka écrivant les données d'événements dans le magasin d'objets cloud doit être géré, ce qui augmente la complexité opérationnelle.
Par conséquent, Databricks recommande, comme meilleure pratique, d'accéder directement aux données du bus d'événements à partir de DLT en utilisant Spark Structured Streaming comme décrit ci-dessus.
Autres bus d'événements ou systèmes de messagerie
Cet article est centré sur Apache Kafka ; cependant, les concepts abordés s'appliquent également à d'autres bus d'événements ou systèmes de messagerie. DLT prend en charge toute source de données que Databricks Runtime prend directement en charge.
Amazon Kinesis
Dans Kinesis, vous écrivez des messages dans un flux sans serveur entièrement géré. Comme Kafka, Kinesis ne stocke pas les messages de manière permanente. La rétention par défaut des messages dans Kinesis est d'un jour.
Lors de l'utilisation d'Amazon Kinesis, remplacez format("kafka") par format("kinesis") dans le code Python pour l'ingestion en continu ci-dessus et ajoutez les paramètres spécifiques à Amazon Kinesis avec option(). Pour plus d'informations, consultez la section sur l'intégration Kinesis dans la documentation Spark Structured Streaming.
Azure Event Hubs
Pour les paramètres d'Azure Event Hubs, consultez la documentation officielle de Microsoft et l'article Recettes Delta Live Tables : Consommation depuis Azure Event Hubs.
Résumé
DLT est bien plus que le simple "T" d'ETL. Avec DLT, vous pouvez facilement ingérer à partir de sources en continu et par lots, nettoyer et transformer des données sur la Lakehouse Platform de Databricks sur n'importe quel cloud avec une qualité de données garantie.
Les données d'Apache Kafka peuvent être ingérées en se connectant directement à un broker Kafka depuis un notebook DLT en Python. La perte de données peut être évitée pour un rafraîchissement complet du pipeline, même lorsque les données sources dans la couche de streaming Kafka ont expiré.
Démarrage
Si vous êtes un client Databricks, suivez simplement le guide pour commencer. Lisez les notes de mise en production pour en savoir plus sur ce qui est inclus dans cette version GA. Si vous n'êtes pas un client Databricks existant, inscrivez-vous pour un essai gratuit, et vous pouvez consulter notre tarification DLT détaillée ici.
Rejoignez la conversation dans la Communauté Databricks où des pairs passionnés de données discutent des annonces et des mises à jour du Data + AI Summit 2022. Apprenez. Réseautez.
Enfin, profitez de la session Plongez dans l'ingénierie des données du sommet. Dans cette session, je vous guide à travers le code d'un autre exemple de données en continu avec un flux Twitter en direct, Auto Loader, Delta Live Tables en SQL et l'analyse de sentiments Hugging Face.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.